PyTorch yesterday announced the release of ExecuTorch alpha, a new tool focused on deploying large language models and large ML models to edge devices. The release, which comes just a few months after the 0.1 preview in collaboration with partners at Arm, Apple, and Qualcomm Technologies, Inc., aims to stabilise the API surface and improve installation processes.
ExecuTorch alpha brings several key features that allow running LLMs efficiently on mobile devices, which are highly constrained for compute, memory, and power. It supports 4-bit post-training quantisation using GPTQ and provides broad device support on CPU through dynamic shape support and new dtypes in XNNPack.
These improvements allow running models like Llama 2 7B and early support for Llama 3 8B on various edge devices, including iPhone 15 Pro, iPhone 15 Pro Max, Samsung Galaxy S22, S23, and S24 phones.
The release also expands the list of supported models across NLP, vision, and speech, with traditional models expected to function seamlessly out of the box. The ExecuTorch SDK has been enhanced with better debugging and profiling tools, allowing developers to map from operator nodes back to original Python source code for efficient anomaly resolution and performance tuning.
PyTorch’s collaborations with partners such as Arm, Apple, Qualcomm Technologies, Google, and MediaTek have been crucial in bringing ExecuTorch to fruition. The framework has already seen production usage, with Meta using it for hand tracking on Meta Quest 3, various models on Ray-Ban Meta Smart Glasses, and integration with Instagram and other Meta products.
Recently PyTorch released 2.3 introducing several features and improvements for performance and usability of large language models and sparse inference. The release allows tensor manipulations across GPUs and hosts, integrating with FSDP (Fully Sharded Data Parallel) for efficient 2D parallelism.
The post PyTorch Releases ExecuTorch Alpha for Deploying LLMs for Edge Devices appeared first on Analytics India Magazine.
It is hard to imagine what today’s operating systems will mean to developers 37 years in the future. Going back 37 years to 1986, when MS DOS version 4.0 was released, computers were less complex and more open to modifications at a fundamental level.
Microsoft, embracing the open source movement, released version 1.1 and 2.0 in 2014. Last week, the company, along with IBM, which was closely associated with building the 4.0 version of DOS, made the source code available on GitHub.
Open sourcing MS-DOS 4.0 // fun to see. This might underplay the confusion and lack of success of 4.0 which was a weird release that was based on the 2.0 code and didn’t offer much for the 386 processor that was already working through new PCs. It was even confusing to OEMs who… pic.twitter.com/go3gHwTIul
— Steven Sinofsky (@stevesi) April 26, 2024
The open source release also included the beta build and scanned documentation of MT-DOS 4.0 built primarily by Microsoft. MT-DOS introduced multi-tasking, which allowed certain programs to run in the program. This version didn’t see commercial release but was quickly overshadowed by OS/2 which improved upon the feature.
Microsoft claims to have ‘lost’ its source code.
It was unearthed by Connor ‘Starfrost’ Hyde, who discovered unreleased beta binaries of DOS 4.0 among former Microsoft CTO Ray Ozzie’s collection.
He worked to publish the code on GitHub along with Scott Hanselman, the VP of developer community, and Jeff Wilcox, head of OS programs office, who reported they will “continue to explore the archives and may update this release if more is discovered”.
In 2001, Bill Gates announced, “Today it really is actually the end of the MS DOS era.” DOS, which ran underneath Windows 3.1, Windows 95, and Windows 98, was being replaced by Windows XP.
At the time of the announcement, DOS was running on over 400 million PCs worldwide.
But the popularity of vintage games built on DOS has retained old timers and children. There are plenty of games still being released on DOS barring the limitations of memory management.
Developers, who reminisced about the time they worked with DOS, were enthusiastic about experimenting with the release and found a few inconsistencies in it.
Hackers and tinkerers who grew up with DOS are eagerly digging into the source code, reliving their early computing experiences. As one HackerNews user exclaimed, “Holy cow, this is huge! DOS 1.x and 2.x are too old to run a lot of vintage DOS software, but 4.x would run just about everything.”
Nostalgia and the present!
The average person doesn’t often come in contact with systems run on DOS. Apart from George RR Martin, who wrote A Game of Thrones books on DOS, the US Navy that used it till 2011, or old-time nerds who are the market for DOSBox to play retro video games on, the operating system is practically defunct.
George R.R. Martin writes A Game of Thrones in the DOS word processor WordStar 4.0 pic.twitter.com/bVumMzaFM9
— Retro Tech Dreams (@RetroTechDreams) August 24, 2023
Right after the open source release, developers took to social media to discuss the times they spent working on DOS when alternatives were sparse. While modern operating systems are complex and allow a wide range of functions, they’re more closed and secure.
A user wrote, “They (kids) can play with code in various sandboxes locally and on the web, but the computer fundamentally belongs to someone else today.”
Although slow with less memory, the device would allow for programming in languages like C to directly compile on the device itself, and modify the core software.
This is in contrast to many modern systems, which often restrict such low-level access to enhance security and stability.
Using the source code, one developer built his own version of the DOS. Though he mentioned the difficulties in compiling the code, he successfully demonstrated running various commands and utilities, showing the functionality of the built operating system within the FreeDOS environment.
Bryan Lunduke, a former software engineer of Microsoft, who attempted to compile the source code, found that several files, including GETMSG.ASM and USA.INF, were “mangled” and could not be properly compiled.
A software engineer and historian, Michal Necasek, who runs the OS/2 Museum blog, found that shoving the source code into GitHub caused irreversible damage, such as loss of timestamps and corruption of files that used code page 437 characters.
Necasek argued that for practical purposes, old source files should be treated as binary and must be preserved without modification. These changes raise concerns about the integrity and historical accuracy of the released source code.
Despite the issues with the release, many in the community are excited to dig into this piece of computing history.
As one developer commented on HackerNews, “Even just seeing some of these filenames is a major blast from the past! Love it,” listing off familiar file names like ‘CPY.BAT’, ‘MAKEFILE’, ‘RUNME.BAT’, and ‘SETENV.BAT.’
The Future is Retro
While the released version of MS-DOS 4.0 may not have much practical use today, the publicly available source code has allowed hackers to explore the inner workings of the operating system that defined their early computing experiences.
Another user shared, “I never thought I would be able to build DOS from scratch, but here we are!” The real value is in preserving this important part of the history of personal computing.
Jim Hall, the founder and project coordinator of FreeDOS, explained that the move to use the MIT licence allows developers to freely study, modify and distribute the code.
Modern developers’ fascination with retro computing extends beyond MS-DOS, as seen in the rise of retrocomputing. One user on X posted, “We completely missed out on the days of programming in C for MS-DOS back when things were so much simpler.”
Engaging with classic operating systems’ source code and retro media allows developers to gain insights into computing’s evolution, informing future innovations.
The series ‘Fallout’, for instance, draws inspiration from vintage technology, MS-DOS 4.0 release exemplifies this retro revolution, inspiring a new generation to embrace the hacker legacy.
Bojan Tunguz aptly said, “The future is here and it’s totally retro.”
The future is here and it’s totally retro. pic.twitter.com/tBOcMpFZxv
— Bojan Tunguz (@tunguz) April 30, 2024
The post Open-Source MS-DOS 4.0 Inspires Aspiring Developers to Embrace Retro Revolution appeared first on Analytics India Magazine.
Rakuten India is announcing the much-anticipated fourth edition of Rakuten Product Conference (RPC) ’24 in partnership with Analytics India Magazine. The event, themed ‘Innovation Reimagined: Enterprise SaaS & AI’, will be held virtually on May 21 and 22 and is poised to be a premier product conference for data scientists, AI evangelists, and innovators worldwide.
The third edition of RPC ’23, held in May 2023, was successfully hosted around the theme ‘Generative AI and the Future of Cloud’. It attracted a whopping 6,300 participants from around the world, echoing the global significance of the rapidly evolving technology.
RPC ’24 will focus on two dominant technological paradigms: Enterprise SaaS and Artificial Intelligence. These topics will take centre stage, offering actionable insights, thought-provoking discussions, and a holistic perspective on the future of technology.
The world of enterprise SaaS has undergone substantial transformations, profoundly influencing businesses across various sectors. The Rakuten Product Conference aims to unite industry pioneers, offering speaker sessions and panel discussions that delve into the latest developments in enterprise SaaS solutions and the primary providers in the field.
Over two days, this virtual conference will attract esteemed professionals, including data science professionals, SaaS practitioners, and decision-makers leading cloud initiatives within their organisations.
Participants will have an excellent opportunity to exchange ideas, explore innovative solutions, and collaborate toward a more promising future. The conference will feature a diverse range of engaging sessions, panel discussions, and presentations delivered by renowned experts in the field.
“At Rakuten India, we believe that innovation isn’t solely about cutting-edge algorithms or machines; it’s about cultivating meaningful human connections and teamwork. We’re genuinely excited to host the fourth edition of Rakuten Product Conference, emphasising Enterprise SaaS and AI. In this gathering, we prioritise not just the advancements in technology but also the essence of connection and collaboration that drives transformative change,” said Anirban Nandi, Head of AI Products & Analytics (Vice President) at Rakuten India.
RPC 2024 is designed for CIOs, CTOs, AI experts, innovation heads, professionals in enterprise space, and tech enthusiasts of all fields.
At this two-day virtual conference focused on enterprise SaaS and AI, attendees will gain valuable knowledge from industry experts and have networking opportunities with professionals.
For more information about Rakuten Product Conference ’24, including registration details and the conference agenda, please visit here.
The post Rakuten India Announces the 4th Edition of RPC ’24 in Collaboration with AIM appeared first on Analytics India Magazine.
OpenAI may be the more well-known name when it comes to commercial generative AI, but Meta has successfully clawed out a place through open sourcing powerful large language models. Meta revealed its largest generative AI model yet, Llama 3, on April 18, which outperforms GPT04 on some standard AI benchmark tests.
What is Llama 3?
Llama 3 is an LLM created by Meta. It can be used to create generative AI, including chatbots that can respond in natural language to a wide variety of queries. The use cases Llama 3 has been evaluated on include brainstorming ideas, creative writing, coding, summarizing documents and responding to questions in the voice of a specific persona or character.
The full Llama 3 model comes in four variants:
8 billion parameters pretrained.
8 billion parameters instruction fine-tuned.
70 billion parameters pretrained.
70 billion parameters instruction fine-tuned.
Llama 3’s generative AI capabilities can be used in a browser, through AI features in Meta’s Facebook, Instagram, WhatsApp and Messenger. The model itself can be downloaded from Meta or from major enterprise cloud platforms.
When will Llama 3 be released and on what platforms?
Llama 3 was released on April 18 on Google Cloud Vertex AI, IBM’s watsonx.ai and other large LLM hosting platforms. AWS followed, adding Llama 3 to Amazon Bedrock on April 23. As of April 29, Llama 3 is available on the following platforms:
Databricks.
Hugging Face.
Kaggle.
Microsoft Azure.
NVIDIA NIM.
Hardware platforms from AMD, AWS, Dell, Intel, NVIDIA and Qualcomm support Llama 3.
Is Llama 3 open source?
Llama 3 is open source, as Meta’s other LLMs have been. Creating open source models has been a valuable differentiator for Meta.
There is some debate over how much of a large language model’s code or weights need to be publicly available to count as open source. But as far as business purposes go, Meta offers a more open look at Llama 3 than its competitors do for their LLMs.
Is Llama 3 free?
Llama 3 is free as long as it is used under the terms of the license. The model can be downloaded directly from Meta or used within the various cloud hosting services listed above, although those services may have fees associated with them.
The Meta AI start page on a browser offers options for what to ask Llama 3 to do. Image: Meta / Screenshot by Megan Crouse
Is Llama 3 multimodal?
Llama 3 is not multimodal, which means it is not capable of understanding data from different modalities such as video, audio or text. Meta plans to make Llama 3 multimodal in the near future.
Llama 3’s improvements over Llama 2
To make Llama 3 more capable than Llama 2, Meta added a new tokenizer to encode language much more efficiently. Meta souped Llama 3 up with grouped query attention, a method of improving the efficiency of model inference. The Llama 3 training set is seven times the size of the training set used for Llama 2, Meta said, including four times as much code. Meta applied new efficiencies to Llama 3’s pretraining and instruction fine-tuning.
Since Llama 3 is designed as an open model, Meta added guardrails with developers in mind. A new guardrail is Code Shield, which is intended to catch insecure code the model might produce.
What’s next for Llama 3?
Meta plans to:
Add multiple languages to Llama 3.
Expand the context window.
Generally boost the model’s capabilities going forward.
Meta is working on a 400B parameter model, which may help shape the next generation of Llama 3. In early testing, Llama 3 400B with instruction tuning scored 86.1 on the MMLU knowledge assessment (an AI benchmark test), according to Meta, making it competitive with GPT-4. Llama 400B would be Meta’s largest LLM thus far.
Llama 3’s place in the competitive generative AI landscape
Llama 3 competes directly with GPT-4 and GPT-3.5, Google’s Gemini and Gemma, Mistral AI’s Mistral 7B, Perplexity AI and other LLMs for either individual or commercial use to build generative AI chatbots and other tools. About a week after Llama 3 was revealed, Snowflake debuted its own open enterprise AI with comparable capabilities, called Snowflake Arctic.
The increasing performance requirements of LLMs like Llama 3 are contributing to an arms race of AI-enabled PCs that can run models at least partially on-device. Meanwhile, generative AI companies may face increased scrutiny over heavy compute needs, which could contribute to worsening climate change.
Llama 3 vs GPT-4
Llama 3 outperforms OpenAI’s GPT-4 on HumanEval, which is a standard benchmark that compares the AI model’s ability to generate code with code written by humans. Llama 3 70B scored 81.7, compared to GPT-4’s score of 67.
However, GPT-4 out-performed Llama 3 on the knowledge assessment MMLU with a score of 86.4 to Llama 3 70B’s 79.5. Llama 3’s performance on more tests can be found on Meta’s blog post.
This is not a repository of traditional questions that you can find everywhere on the Internet. Instead, it is a short selection of problems that require outside-the-box thinking. They come from my own projects, focusing on recent methods not taught anywhere. Some are related to new, efficient algorithms, sometimes not yet implemented by large companies. I also provide my answers. It would be interesting to compare them to OpenAI answers.
1. How to build knowledge graphs with embedded dictionaries in Python?
One way to do it is to have a hash (dictionary in Python, also called key-value table) where the key is a word, token, concept, or category, for instance “mathematics”. The value — one per key — is itself a hash: the nested hash. The key in the nested hash is also a word, for instance a word such as “calculus”, related to the parent key in the parent hash. And the value is a weight: high for “calculus” since “calculus” and “mathematics” are related and frequently found together, and conversely, low for “restaurants” as “restaurants” and “mathematics” are rarely found together.
In LLMs, the nested hash may be an embedding. Because the nested hash does not have a fixed number of elements, it handles sparse graphs far better than vector databases or matrices. It leads to much faster algorithms requiring very little memory.
2. How to perform hierarchical clustering when the data consists of 100 million keywords?
You want to cluster keywords. For each pair of keywords {A, B}, you can compute the similarity between A and B, telling how similar the two words are. The goal is to produce clusters of similar keywords.
Standard Python libraries such as Sklearn offer agglomerative clustering, also called hierarchical clustering. However, they would typically need a 100 million x 100 million distance matrix in this example. This won’t work. In practice, random words A and B are rarely found together, thus the distance matrix is extremely sparse. The solution consists of using methods adapted to sparse graphs, using for instance the nested hashes discussed in question 1. One such method is clustering based on detecting the connected components in the underlying graph.
3. How to crawl a large repository such as Wikipedia, to retrieve the underlying structure, not just separate entries?
These repositories all have structural elements embedded into the web pages, making the content a lot more structured than it seems at first glance. Some structure elements are invisible to the naked eye, such as metadata. Some are visible and also present in the crawled data, such as indexes, related items, breadcrumbs, or categorization. You can retrieve these elements separately to build a good knowledge graph or a taxonomy. But you may need to write your own crawler from scratch rather than relying on (say) Beautiful Soup. LLMs enriched with structural information, such as xLLM (see here), offer superior results. What’s more, you can use the structure retrieved from an external source, to augment your crawled data if your repository truly lacks any structure. This is called structure augmentation.
4. How to enhance LLM embeddings with long and contextual tokens?
Embeddings consists of tokens; these are among the smallest text elements that you can find in any document. But it does not need to be that way. Instead of having two tokens, say ‘data’ and ‘science’, you could have four: ‘data^science’, ‘data’, ‘science’, and ‘data~science’. The last one indicates that the whole word ‘data science’ was found. The first one means that both ‘data’ and ‘science’ were found, but at random locations in (say) a given paragraph, not at adjacent locations. Such tokens are called multi-tokens or contextual tokens. They offer some good redundancy, but if you are not careful, you can end up with gigantic embeddings. The solution consists of purging useless tokens (keeping the longest ones) and working with variable size embeddings, see here. Contextual contents can reduce LLM hallucinations.
5. How to implement self-tuning to eliminate many issues connected to model evaluation and training?
This works with systems based on explainable AI, by contrast to neural network black boxes. Allow the user of your app to select hyperparameters and flag those that he likes. Use that information to find ideal hyperparameters and set them as default. This is automated reinforcement learning based on user input. It also allows the user to choose his favorite sets depending on the desired results, making your app customizable. In LLMs, allowing the user to choose a specific sub-LLM (based for instance on the type of search or category), further boosts performance. Adding a relevancy score to each item in the output results, also help fine-tuning your system.
6. How to increase the speed of vector search by several orders of magnitude?
In LLMs, working with variable-length embeddings dramatically reduces the size of the embeddings. Thus, it accelerates search to find back-end embeddings similar to those captured in the front-end prompt. However, it may require a different type of database, such as key-value tables. Reducing the size of the token and embedding tables is another solution: in a trillion-token system, 95% of the tokens are never fetched to answer a prompt. It is just noise: get rid of them. Working with contextual tokens (see question 4) is another way to store information in a more compact way. In the end, you use approximate nearest neighbor search (ANN) on compressed embeddings to do the search. A probabilistic version (pANN) can run a lot faster, see here. Finally, use a cache mechanism to store the most frequently accessed embeddings or queries, to get better real-time performance.
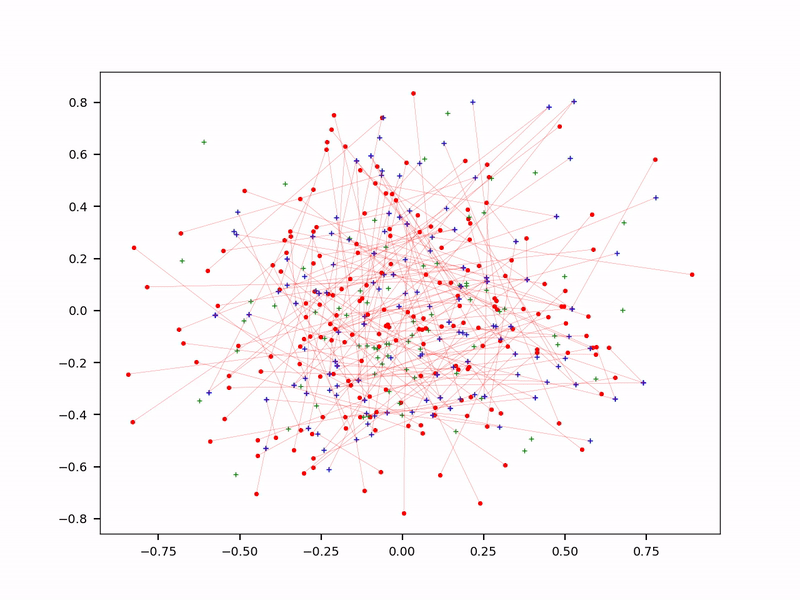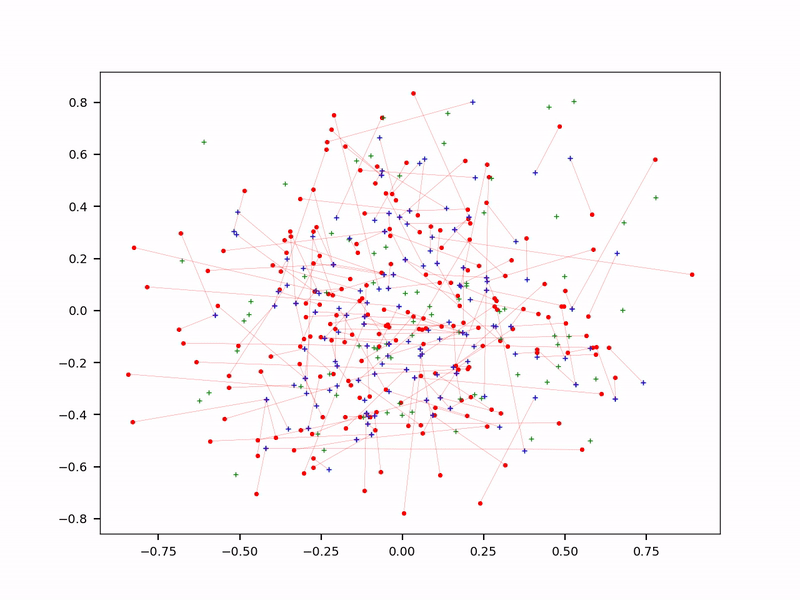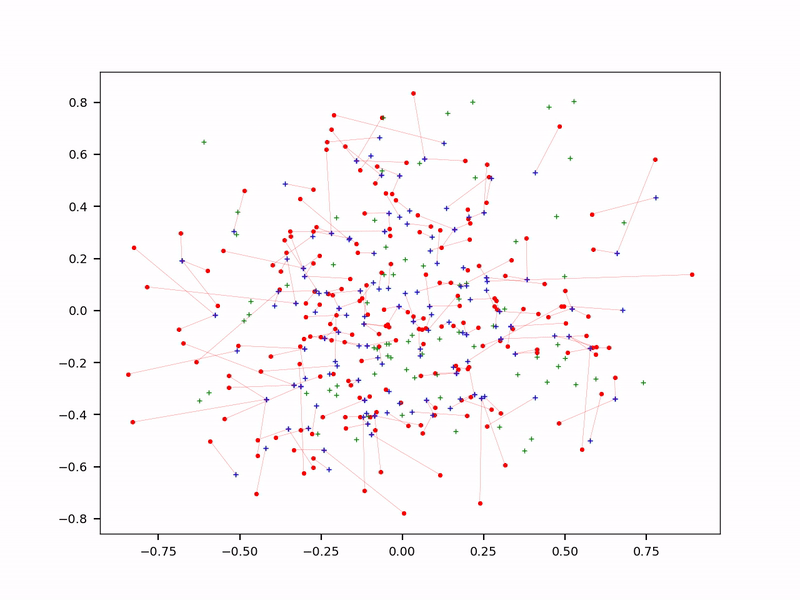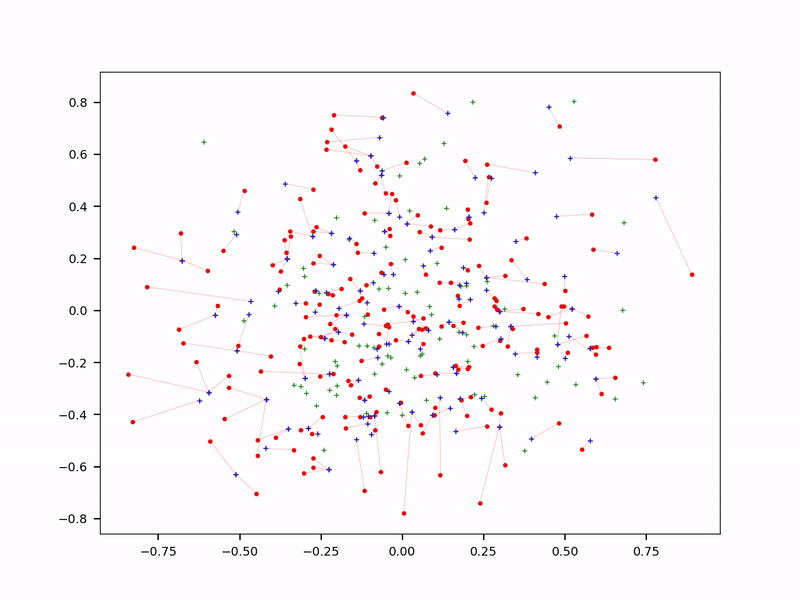
Probabilistic approximate nearest neighbor search (see question 6)
In some of my applications, reducing the size of the training set by 50% led to better results, with less overfitting. In LLMs, choosing a few great input sources does better than crawling the whole Internet. And having a specialized LLM for each top category, as opposed to one-size-fits-all, further reduces the number of embeddings: each prompt targets a specific sub-LLM, not the entire database.
7. What is the ideal loss function to get the best results out of your model?
The best solution is to use the model evaluation metric as the loss function (when possible, in supervised learning). The reason why this is rarely if ever done is because you need a loss function that can be updated extremely fast each time a neuron gets activated in your neural network. Another solution, in the context of neural networks, consists in computing the evaluation metric after each epoch, and keep the solution generated at the epoch with best evaluation score, as opposed to the epoch with minimal loss.
I am currently working on a system where the evaluation metric and loss function are identical. Not based on neural networks. Initially, my evaluation metric was the multivariate Kolmogorov-Smirnov distance (KS), based on the difference between two empirical cumulative distributions: observed in the training set, versus generated. It is extremely hard to make atomic updates to KS, on big data, without massive computations. It makes KS unsuitable as a loss function because you need billions of atomic updates. But by changing the cumulative distribution to the probability density function with millions of bins (the actual change is more complicated than that), I was able to come up with a great evaluation metric, which also works very well as a loss function.
Author
Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
Soket AI Labs has introduced Pragna-1B, India’s first open-source multilingual model designed to cater to the linguistic diversity of the country.
Available in Hindi, Gujarati, Bangla, and English, Pragna-1B represents a significant step towards inclusive AI technology, transcending linguistic barriers and enhancing user engagement across diverse linguistic landscapes.
Click here to check out the model on Hugging Face.
Pragna-1B features a Transformer Decoder-only model with 1.25 billion parameters and a context length of 2048 tokens. Pragna-1B’s training involved 1.25 billion parameters, focusing on Hindi, Bangla, and Gujarati, processing approximately 150 billion tokens.
It is engineered for efficient deployment on-device, Pragna-1B delivers state-of-the-art performance for vernacular languages in a small form factor.
Despite its modest parameter count, Pragna-1B’s performance matches that of larger 7 billion parameter models, offering comprehensive multilingual support for English, Hindi, Bangla, and Gujarati.
The model is meticulously trained on curated datasets specifically designed to encompass the Indian context, Pragna-1B ensures accurate and culturally relevant outputs.
Pragna-1B is a decoder-only transformer model inspired by TinyLlama, with the following specifications:
Layers: 22
Attention Heads: 32
Context Length: 2048
Hidden Dimension: 2048
Expansion Dimension: 5632
Vocabulary Size: 69632
Pragna employs a Byte-Pair Encoding (BPE) tokenizer, specifically trained for handling Indian languages, achieving a vocabulary size of 69,632.
Soket AI Labs created “Bhasha,” a series of high-quality datasets specifically designed for training Indian language models.
Bhasha-wiki: Includes 44.1 million articles translated from English Wikipedia into six Indian languages.
Bhasha-wiki-indic: A refined subset of Bhasha-wiki, focusing on content relevant to India.
Bhasha-SFT: Facilitates the development of language models for various NLP tasks.
The researchers are also experimenting with a Mixture of experts model, expanding the languages, along with different architectures for increasing optimisation.
The post Soket AI Labs Unveils Pragna-1B, Multilingual Indic Language Model appeared first on Analytics India Magazine.
Chinese tech giant Huawei has introduced Kangaroo, a framework designed to accelerate the inference process of LLMs while maintaining a consistent sampling distribution. This development represents a leap forward in computational efficiency and speed, promising to enhance a wide range of applications that rely on rapid natural language processing.
Kangaroo utilises a novel self-speculative decoding framework that leverages a fixed shallow sub-network of an LLM as a self-draft model. This approach eliminates the need for training separate draft models, which is often costly and resource-intensive.
Instead, Kangaroo introduces a lightweight and efficient adapter module that bridges the gap between the shallow sub-network and the larger model’s full capabilities.
Key Features of Kangaroo
Double Early Exiting Mechanism: Kangaroo incorporates an innovative double early exiting strategy. The first exit occurs when the self-draft model, derived from the shallow layers of the LLM, reaches a predefined confidence threshold, which prevents further unnecessary computation. The second exit is employed during the drafting phase to halt the prediction process early if the subsequent token’s confidence falls below a certain threshold.
Efficiency and Speed: In benchmark tests conducted on Spec-Bench, Kangaroo has achieved speedups up to 1.68 times compared to existing methods. This is achieved with 88.7% fewer parameters than similar frameworks like Medusa-1, highlighting Kangaroo’s superior efficiency.
Scalability and Ease of Integration: The self-speculative framework is designed to be easily integrated into existing LLM infrastructures without significant modifications. This scalability ensures that Kangaroo can be deployed across various platforms and applications, broadening its usability in the industry.
Why Is This Development Important?
The development of Kangaroo addresses one of the key challenges in the deployment of LLMs: the trade-off between speed and accuracy.
By reducing the computational overhead and enhancing the inference speed, Kangaroo allows for more responsive and efficient use of LLMs in real-time applications. These include but are not limited to automated content generation, real-time translation services, and advanced data analysis tools.
The post Huawei Launches Kangaroo, Cutting Down on AI Inference Delays with Self-Speculative Decoding appeared first on Analytics India Magazine.
Certainly, Intel is sorting out its AI strategy by investing in AI accelerators and expanding on its existing customers. One can say, apart from AMD building the whole architecture, none of the OEM providers can build a PC, or AI PC, without utilising the blue-chip company’s CPU.
But talking about the AI strategy again, is Intel in denial? In a recent interview, Patrick Gelsinger, the CEO of Intel, confirmed that the company was on track with its investment, when it comes to AI. Even though the demand for its Gaudi accelerators are rising, it is minuscule compared to AMD and NVIDIA’s GPUS.
Gaudi is on track for around 500 million of sales in 2024. This is several times less than AMD’s MI300X’s demand for $3.5 billion and the NVIDIA’s H100 and H200’s $40 billion demand. When probed on this, Gelsinger said Intel’s Vision 2024 event saw the announcement of 20+ customers for its AI accelerator, which highlights the company’s strength.
Is the CPU approach for AI viable?
“We’re really starting to see that pipeline of activity convert,” said Gelsinger. Some say that Intel is completely living in denial with its current AI strategy. One of the biggest reasons for this is that Intel has always been the biggest proponent of pushing CPUs for AI workloads.
But Intel’s biggest bet is on edge use cases, which is through its Core mobile processors and Xeon processors. With smaller language models increasing in the AI space, these mobile processors are currently in the perfect space. While NVIDIA is also delivering this with Arm-based processors on mobile devices, these are still incapable of running on laptops without an Intel CPU.
Recently, a team of researchers at Hugging Face published a blog that said they were able to train an LLM based on Microsoft Phi-2 model on Intel Meteor Lake, which is now renamed to Core Ultra, specifically built for high performance laptops consisting of 16 cores. The interesting part is that it comes with an integrated GPU, called iGPU with 16 Xe Vector Engines.
Moreover, Intel’s introduction of the Neural Processing Unit (NPU) marks a significant milestone for its architectures. This dedicated AI engine is tailored for efficient client AI, allowing it to handle demanding AI computations with greater efficiency compared to using the main CPU or integrated graphics (iGPU).
By offloading AI tasks to the NPU, users can free up the main CPU and graphics for other tasks, resulting in improved power efficiency.
The blog ends with: “Thanks to Hugging Face and Intel, you can now run LLMs on your laptop, enjoying the many benefits of local inference, like privacy, low latency, and low cost.” This is what Intel is aiming for as well.
Furthermore, when it comes to India, Intel has a buzzing partner ecosystem with Infosys, Bharti Airtel, Ola Krutrim, Zoho, and L&T announcing partnerships with the company. Intel is betting big on India, which is not that new. Providing cheaper alternatives when it comes to data centres and powering enterprise solutions, Intel has always been the go to choice for Indian companies.
“AI does not just require big GPUs to solve the problem. There are a lot of different models that can run on Xeon. Innovation at scale can happen with Xeon. We are working with several large customers. Gaudi 2 is available, Gaudi 3 comes in the second half. You will see some of those products coming into India through these customers as well,” said Santosh Viswanathan, VP and MD of Intel in India.
Ushering the era of AI PCs
One can even say that Intel is living in the future when it comes to building AI PCs. Though Jensen Huang, the NVIDIA chief, has said that everyone would be a gamer in the future using their GPUs, Intel’s approach towards building AI PCs makes a lot of sense as well.
Intel also has a bunch of partnerships for its AI PC goals. At the AI Everywhere event in December, Gelsinger and his team announced the launch of Intel Core Ultra and Intel Arc GPUs for pushing the goal of making every PC in the world an AI PC.
This would be achieved through its partnership with Dell, Lenovo, HP, Supermicro, and Microsoft, for bringing the hardware onto their devices. This was further solidified at the Intel Vision event in April.
Intel anticipates shipping 40 million AI PCs in 2024, featuring over 230 designs spanning from ultra-thin PCs to handheld gaming devices.
Looking ahead, Intel’s roadmap includes the launch of the next-generation Intel Core Ultra client processor family, codenamed Lunar Lake, in 2024. This lineup is projected to deliver more than 100 platform tera operations per second (TOPS) and over 45 neural processing unit (NPU) TOPS, ushering in a new era of AI-centric computing.
The rivalry between Intel and NVIDIA, encompassing both CPUs and GPUs, is poised to intensify, potentially reshaping the landscape of AI and HPC. It’s widely believed that Intel is the best CPU to buy, and NVIDIA, the best GPU to buy.
But this might take a turn soon given that the conversation about computing has almost shifted around AI. There are no PCs without Intel – that’s for sure.
The post Is Intel Living in Denial? appeared first on Analytics India Magazine.
Banks that move quickly to scale generative AI across their organizations could increase their revenues by up to 600 bps in three years, according to Accenture research.
Using publicly available employee data, Accenture analysed banking tasks to estimate how generative AI could impact bank employees’ time by function and then modeled the financial implications for banks over three years, using existing financial data from more than 150 large banks globally, including public and private sector banks in India.
The analysis found that banks which effectively adopt and scale generative AI could increase employee productivity by up to 30%, streamlining numerous language-related tasks.
Operating income could increase by around 20%, while return on equity levels could rise by 300 bps. By helping banks operate more efficiently, the technology could lead to 1%-2% in cost savings, with cost- to-income ratios declining by up to 400 bps.
The report further revealed that generative AI could help evolve the 20 largest roles across banks. These roles fall into three categories:
Roles with a high potential for automation: 41% of all banking occupations have a high potential for automation. Roles that primarily involve collecting and processing data could greatly benefit from automation as their routine tasks could be supported by generative AI. This could improve speed and accuracy, reduce costs and relieve employees of the more tedious aspects of their jobs.
Roles with a high potential for augmentation: 34% of bank employees whose work involves a high measure of judgement, including credit analysts and relationship managers, could be empowered by generative AI tools.
Roles that could potentially benefit equally from automation and augmentation: 25% of all bank employees will similarly benefit from both automation and augmentation, including customer service agents who spend time responding to inquiries, explaining services and preparing documentation.
To carry out the research, Accenture used data from the US Bureau of Labor Statistics and the Occupational Information Network to analyse 2.7 million banking employees in the US as well as the 170 roles and 3,500 tasks they perform to assess the impact of generative AI on labour productivity.
Accenture tagged each task and the time employees spend in performing it in one of four categories: high potential for automation, high potential for augmentation, low potential, or no language tasks.
The post Gen AI Could Boost Bank Revenues by 6% in the Next 3 Years: Accenture appeared first on Analytics India Magazine.
MathCo announced the appointment of NV Tyagarajan, aka Tiger Tyagarajan, as a board member, effective April 2024.
Tyagarajan brings a wealth of invaluable experience and visionary leadership to MathCo. Renowned as an industry luminary, Tiger has a distinguished track record of steering companies toward success through future-proof business strategies, promising to enhance its client offerings significantly.
His appointment as a board member signifies a pivotal moment in MathCo’s journey, as the company looks forward to leveraging Tiger’s profound insights and industry acumen to propel its growth trajectory.
“Having studied MathCo’s journey since its inception, I have been thoroughly impressed by its evolution into a mature and resilient organisation, delivering impactful solutions to leading global enterprises.
“Their strategy of building and deploying a proprietary platform, NucliOS, with pre-built workflows and reusable plug-and-play modules that empower clients to achieve the vision of connected data-driven intelligence, is truly impressive. I am delighted to join MathCo’s board and eager to collaborate with Sayandeb, Aditya, Anuj, and the passionate MathCo team,” Tyagarajan said.
Tiger is best known for his pivotal role in transforming a division of General Electric (GE Capital International Services) into Genpact and his thirteen-year tenure as CEO of the company.
His influence extends across leading consulting, AI, and technology firms, where he serves as an advisor, contributing to shaping organisational futures, fostering sustainable growth, and championing transformative initiatives.
The post Tiger Tyagarajan Joins MathCo as Board Member appeared first on Analytics India Magazine.