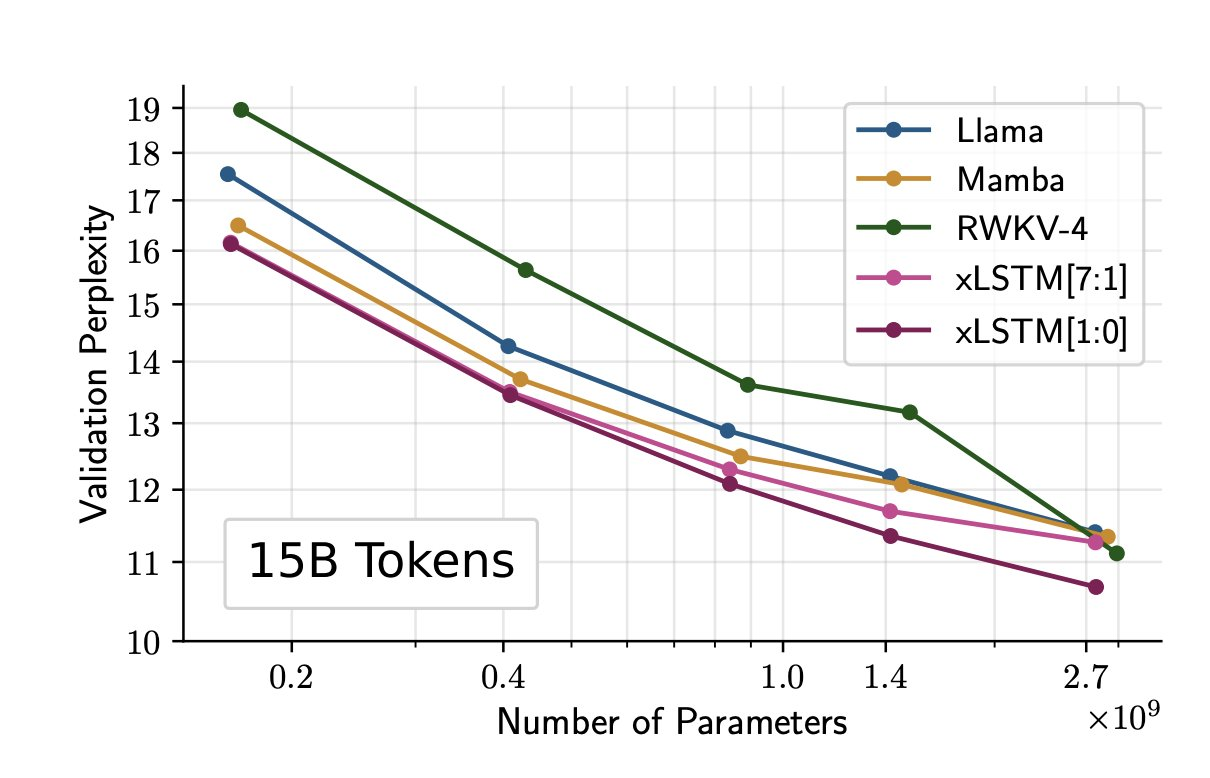
OpenAI recently announced its plans to develop a new tool called Media Manager. The tool enables creators and content owners to specify how their work is used in machine learning research and training AI models. The tool is designed to respect these choices and is expected to be released by 2025.
The catch is that this new tool will be of great help to OpenAI in collecting Indic data and building GPT models and could also hurt many Indian AI startups. This includes Ola Krutrim, SML Hanooman, and others, which have barely bloomed and are struggling to onboard users onto its platforms.
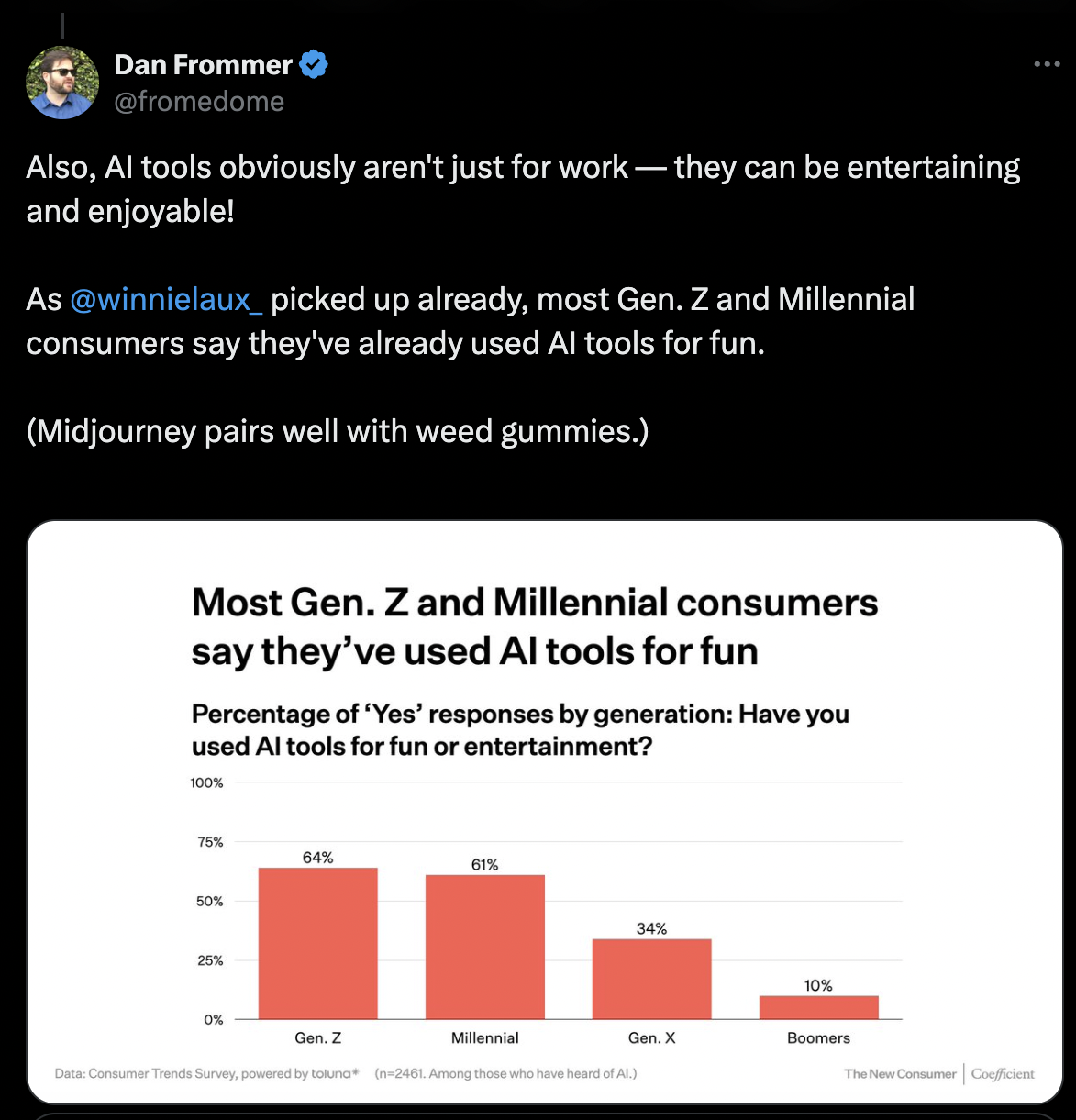
Recent statistics reveal that ChatGPT has amassed over 180 million users globally, with India emerging as its second-largest market. India accounts for 9.08 % of the total user base, which comes to approximately 14 million users. Neither Ola Krutrim nor Hanooman are anywhere close and are busy playing the so-called Indian ‘culture’ card.
That also explains why OpenAI recently hired Pragya Misra, its first employee in India, as the government relations head to lobby the Indian government and create a safe space for OpenAI to eventually operate in the country without any hindrance.
‘Tumse Na Ho Payega’… Really?
“You won’t be able to do it,” when translated into English, is what Ola Krutrim chief Bhavish Aggarwal said in a recent interview, pointing to OpenAI. He boldly claimed that he aims to challenge OpenAI by proving that India can build its own foundational language models from scratch.
However, Aggarwal admitted that Krutrim needs to catch up with ChatGPT but added, “Unless the start is made, how can we move ahead?”
Most recently, he also claimed that he wants Krutrim to be Indian-centric and free from Western influence, to the extent that he coined a new term called ‘Pronoun Illness’. This sentiment, shared by him, is facing criticism from the developer ecosystem, which is questioning Ola’s diversity and inclusion practices.
The irony is that the entire model and the idea of starting Krutrim itself appear to have been copied from OpenAI—to the extent that it even replied to some of the users’ queries stating that it was built on top of ‘OpenAI models’, which was later rectified vaguely, and not spoken about ever since.
Many believe the company used OpenAI’s GPT-4 output to train Krutrim.
Interestingly, Ola Krutrim is currently using Databricks services to streamline data for its model, and as far as building models go, it is most likely using DBRX as well. “We have been working closely with the Databricks team to pre-train and fine-tune our foundational LLM,” said Ravi Jain, Krutrim VP.
Indic Data is All You Need
“The amount of high-quality data originally available in Indian languages is quite small,” said Vivek Raghavan, co-founder of Sarvam AI, highlighting the challenges around creating datasets for low-resource Indic languages.
Further, Raghavan said that even if you take the example like Common Crawl, which is the most common web data repository, only 0.1% of the text is in Hindi, and other Indian languages are even lower than that,” he added.
Pratyush Kumar and Vivek Raghavan, the founders of Sarvam AI, have previously worked with another homegrown AI venture, AI4Bharat, which is building Indic language datasets like IndicVoices.
Similarly, Tech Mahindra, which is developing its own Hindi LLM ‘Project Indus’ consisting of 539 million parameters and 10 billion Hindi+ dialect tokens, sent its crew to North India to collect data.
“We went to Madhya Pradesh, Rajasthan, and parts of Bihar. The team’s task was to collect Hindi and dialect data by interacting with professors and leveraging the Bhasha-dan portal available on ProjectIndus.in,” said Nikhil Malhotra, global head at Makers Lab, Tech Mahindra and the brain behind Project Indus.
Coincidentally, similar to OpenAI’s Media Manager, Bhashini also introduced Bhashan Daan to create a large and open repository of language data in various Indian languages.
Customer-Centric, Not Ego-Centric
The only moat most Indian AI startups currently have is the plethora of Indic datasets they hoard or harness. Now, with OpenAI introducing the Media Manager tool, its presence in the country could expand multifold, alongside hindering growth for a bunch of companies building ChatGPT alternatives.
To be honest, most Indian AI startups are two years behind OpenAI or any other AI startups in the West.They have barely begun, and it is time they run a reality check and focus on developing innovative and collaborative solutions to cater to Indian consumers and enterprises instead of competing aimlessly.
India’s CTO, Nandan Nilekani, also echoed similar views recently. He said that India is not in the race to build LLMs but should focus on building AI use cases that will reach every citizen. “Winners in AI in India will be those who meet customers where they are,” he said.
In a recent interview with AIM, Sarvam AI’s Raghavan also said the same. “We’ve just started here; I don’t think we are trying to build the class of models that OpenAI is trying to build with GPT-5,” he said, sharing his company’s strategy of leveraging existing AI tools as well as in-house models to build meaningful products that impact millions of people in the country.
On the other hand, Mr Aggarwal is obsessed with competing with OpenAI and other tech giants, waging a ‘culture’ war against the West.
“Rich of you to call my post unsafe! This is exactly why we need to build our own tech and AI in India. Else we’ll just be pawns in other political objectives,” said Mr Aggarwal, over his controversial ‘pronoun illness’ LinkedIn post, and accusing them of imposing a political ideology on Indian users that’s unsafe, sinister.
The post OpenAI Introducing Media Manager Tool in India Could Hurt Ola Krutrim’s Ego appeared first on Analytics India Magazine.