In this session, you’ll review the zero trust framework from the National Institute of Standards and Technology (NIST) and the Cisco approach to zero trust security. See Cisco’s approach to XDR that enables automation and monitoring across your infrastructure, in action with demos and customer case studies.
A well-designed data architecture enables effective data management, fosters a modern data-driven work culture, and delivers analytics to help organizations make smarter business decisions. This is a straightforward concept, but there are several considerations and steps for creating a successful data architecture. Attend the three-day Data Architecture Best Practices summit for expert insights and resources to help you build and manage a data architecture that leverages data intelligence to solve the business problems of today and the future.
Redefining “No-Code” Development Platforms
I recently watched a video from Blizzard Entertainment Game Director Wyatt Cheng on ChatGPT’s ability to create a simple video game from scratch. While the art assets were not created by ChatGPT, the AI program Midjourney created the program using rough sketches and text prompts. Cheng created this challenge for himself with the restriction that the AI language model would write every line of code. As seen in the video, ChatGPT was capable of creating a six-step plan to create a functional game based on Cheng’s initial input. Cheng outlined the broad features he was asking for, and AI provided step-by-step instructions for how to implement each step. This is not surprising — ChatGPT’s coding capabilities have been demonstrated numerous times in various applications. What is surprising, is ChatGPT’s ability to make revisions and iterate on that original code like a human would. In a few cases, Cheng asked the AI to change how a feature functioned and pointed out errors in logic. Despite some cases where AI has shown to be stubborn or unable to accept new information, ChatGPT recognized the flaws and amended them in the code. In the end, Cheng and ChatGPT were able to create a game that played like the 2013 game Flappy Bird using only basic text inputs, while refining the game required simply asking it to function differently. Cheng was already familiar with coding games with the Unity game engine, but this demonstration shows how this is changing with the power of AI. The ability for a non-developer to brainstorm a design and tell AI tech, “write me a program that does X, Y, and Z” is a huge step towards increasing accessibility and creating pathways for non-technical users to enter the programming space. Scott Thompson Associate Editor
Contact The DSC Team if you are interested in contributing.
DSC Featured Articles
VM Data Protection: Automate VM Backup and Replication in a Few Clicks April 11, 2023 at 2:42 pm by Nakivo Backup & Replication
Smart on Wheels: The Emergence of Connected Cars April 11, 2023 at 2:38 pm by Nikita Godse
Machine Learning and AI: The Future of SIEM Alternatives in Cybersecurity April 11, 2023 at 2:34 pm by Evan Morris
Agile Testing Method and Best Practices April 11, 2023 at 2:32 pm by Edward Nick
Digital Healthcare Trends: Emergence of Automated Data Entry in Healthcare April 10, 2023 at 2:05 pm by Ovais Naseem
How to Migrate (Successfully) to the Cloud April 10, 2023 at 1:03 pm by Alyssa Dolan
DSC Weekly 4 April 2023 – Show Your Work with XAI April 4, 2023 at 7:35 pm by Scott Thompson
How Data-Driven Analytics Can Improve Workplace Safety April 4, 2023 at 3:17 pm by Elis Enano
Reshaping Financial Processes with AI-based Data Extraction April 4, 2023 at 3:00 pm by Ovais Naseem
Enterprise Data Is Broken – Here’s How to Fix It April 4, 2023 at 2:43 pm by Alisha Alvarez
We are entering a new era of communication, with the introduction of ChatGPT (Generative Pre-trained Transformer) technology. This revolutionary platform offers highly personalized conversations that can generate natural language responses tailored to the user’s unique context and experience.
While this technology is incredibly powerful, it also presents significant cybersecurity risks that must be addressed in order to protect users and their data. Here, we’ll discuss 12 of the most common cybersecurity risks associated with ChatGPT, as well as best practices for keeping your data safe.
1. Unsecured Data
With ChatGPT technology, unsecured data can be easily exploited by malicious actors. To ensure your data is safe from prying eyes, it’s important to implement strong encryption protocols and ensure all data is securely stored.
This is why things like crypto lending or staking use a decentralized ledger so that it’s impossible for malicious actors to access the data within.
This is especially safe with ChatGPT because of how quickly it can process and store large amounts of data. It’s important to ensure your data is encrypted both in transit and at rest so that even if a malicious actor was able to gain access, they would be unable to read or exploit the information.
2. Bot Takeovers
A bot takeover is when a malicious actor is able to gain control of ChatGPT and use it for their own purposes. This can be done by exploiting vulnerabilities in the code, or by simply guessing the user’s password.
ChatGPT bots are great for automating certain tasks, but they can also provide an avenue for remote attackers to take control of them. To protect against this possibility, it’s essential to secure your systems with strong authentication protocols and regularly patch any known software vulnerabilities.
For example, you should use multi-factor authentication whenever possible, and regularly change your passwords to ensure they remain secure. Additionally, it’s important to keep up with security updates and patch any software vulnerabilities that are discovered.
3. Data Leakage
Data leakage is a common risk when using ChatGPT technology. Whether it’s due to improper configuration or malicious actors, data can easily be exposed or stolen from ChatGPT systems.
To protect against this possibility, it’s important to implement strong access controls so only authorized personnel can access the system and its resources. Additionally, regular monitoring of all activity on the system is essential for detecting any suspicious behavior or incidents in a timely manner.
Finally, setting up regular backups of all data stored in the system will ensure that even if a breach does occur, you’ll still be able to quickly recover any lost information.
A vulnerable user interface can leave users open to attack. To protect against this risk, make sure the front end of your ChatGPT platform is secure and regularly updated with the latest security patches.
4. Malware Infections
As with any software platform, malicious code can be introduced into a ChatGPT system through user input or downloads from third-party sources. Regularly scan your system for malware and install protective measures such as anti-virus software to detect and remove threats before they become an issue.
5. Unauthorized Access
To ensure only authorized users have access to the system, put preventive measures in place that require strong passwords and two-factor authentication. This is especially important when it comes to ChatGPT because of how sophisticated the phishing capabilities are.
Imagine that you are using a ChatGPT to talk to your customers, and you have a customer who accidentally clicks on a malicious link. The attacker could then gain access to the system and cause damage or steal data.
By requiring strong passwords and two-factor authentication for all users, you can reduce the chances of this happening. Additionally, regularly audit user accounts to ensure no unauthorized users are accessing the system.
6. Brute Force Attacks
The brute force capabilities that cybercriminals now have with chatGPT are more sophisticated than ever before. To protect against these attacks, you should use strong passwords and two-factor authentication for all users on the system. Additionally, set up automated monitoring to detect any suspicious activities or attempts to brute force their way into the system.
For example, if someone tries to access the system with an incorrect password too many times, the system should automatically lock them out and alert the administrators.
7. DDoS & Spam Attacks
Distributed Denial of Service (DDoS) and spam attacks are other common forms of cyber attack that can be used against ChatGPT systems. To protect against these threats, it’s important to monitor network traffic for any suspicious or abnormally high levels of activity.
Additionally, use a web application firewall (WAF) to filter malicious requests before they reach your server. Finally, make sure you have a plan in place to respond quickly if an attack were to occur.
8. Information Overload & Limitations
The sheer amount of information that is generated by ChatGPT can be overwhelming at times, and some systems may not be able to handle the load. Make sure your system has adequate resources available to deal with high levels of traffic without being overwhelmed.
Additionally, consider using analytics tools and other artificial intelligence technologies to help manage the data overload issue.
9. Phishing
If you thought phishing was bad now and getting increasingly harder to confront and combat, wait until it gets rolling with the new chatGPT technology.
Cybercriminals now have more sophisticated methods of targeting unsuspecting users, such as natural language processing (NLP) and artificial intelligence.
To protect against phishing attacks, it’s important to train your team how to spot a potential attack before it happens. Additionally, use two-factor authentication whenever possible to add an extra layer of security and prevent malicious actors from accessing the system.
10. Privacy & Confidentiality Issues
ChatGPT systems can be vulnerable to privacy and confidentiality issues if not properly secured. To ensure that user data remains private, make sure you are using a secure communication protocol (SSL/TLS) and encrypting any sensitive data being stored on the server.
Also, put in place controls for who can access and use the data, such as requiring user authentication before granting access.
11. Supply Chain Risks
Like any other system, ChatGPT is only as secure as its weakest link. This means that if one of your suppliers or vendors is compromised, your entire system could be vulnerable to attack.
To protect against this risk, it’s important to vet all third-party providers and perform regular security audits on their systems to ensure they are taking appropriate measures to protect your data.
12. Insufficient Logging & Auditing
Without proper logging and auditing of user activity, it can be difficult to track would-be attackers and their activities. Implement comprehensive logging systems that capture information such as IP addresses, timestamps, user accounts and more so that any suspicious activity can quickly be identified.
Conclusion
These are just a few of the most common cyber security risks associated with ChatGPT technology – there are many others that must be taken into consideration when developing or using this type of platform.
Working with an experienced team of cybersecurity professionals can help ensure all potential threats are addressed before they become a problem. Investing in effective cybersecurity solutions is key to keeping your data safe and protecting your organization’s reputation.
Taking the necessary steps now can save time and money down the road.
By investing in strong cybersecurity measures and training users on best practices for keeping their data secure, you can keep your ChatGPT platform functioning safely and securely.
Continue to monitor your system regularly and stay up-to-date on the latest cyber security news and trends to ensure your platform remains secure. With the right steps in place, you can ensure your ChatGPT platform is safe and protected from potential threats.
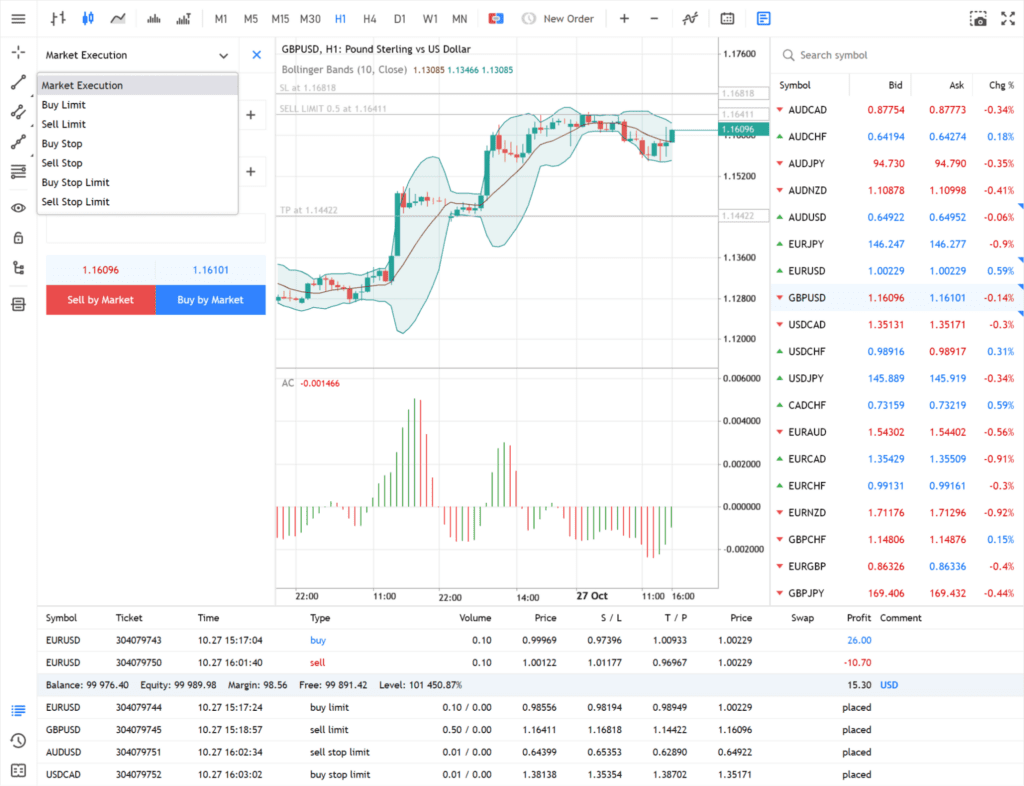
Trading remains a popular activity among many users across the world. Recent trends indicate that this will not change anytime soon. The global trading market is projected to grow by nearly 7% over the next year, continuing a relatively stable trend over the last years. Web terminals have started to establish a firm position for themselves in the current landscape as well. They bring various benefits to the table, and some traders have started to switch to exclusively using web terminals for their daily operations at this point.
Reduced Latency
Since trades are executed on a remote server and not on the trader’s machine, this allows for a severely reduced latency in the trading experience. In fact, in some cases latency can be eliminated almost completely. Low-latency trading relies on a specifically developed infrastructure, which is probably why it took some time for it to become so widespread. Some companies on the market have been actively trying to get their servers closer to major exchanges to further reduce the latency in their operations.
Advanced Solutions for Risk Management
Working closely with an expert is no longer necessary for reducing the risk associated with trading. Platforms like the MetaTrader 5 Web Terminal have introduced various solutions for tackling certain risky operations, including stop loss, stop limits, and guaranteed stops.
These features – and others – can help users navigate the market with more confidence, knowing that there’s a lower risk of suffering from a sudden downturn.
Cross-platform Support
Traders are no longer limited to working on a specific machine either. Thanks to the remote nature of web trading terminals, users can now take advantage of their platform of choice regardless of their physical location or device availability. This has enabled traders to work on the go and take advantage of sudden changes in the market environment without compromising anything. And given the growing popularity of mobile devices compared to desktops, this change has been welcomed by a large number of users.
Low System Requirements
On a related note, traders don’t need access to powerful computers to perform their trades anymore. All complex operations are handled remotely on the web terminal’s server, meaning that the user only needs a basic device that can connect to the internet and browse sites.
This can promote easy scalability of trading operations as well. Traders can easily deploy multiple instances of a platform when they want to collaborate, instead of being limited to one or two devices with a limited processing capacity.
Improved Security
Sensitive data is no longer stored directly on the trader’s computer, making the overall experience more secure and reliable. Traders don’t need to worry about backing up their information either, as they know it’s stored remotely at all times. The importance of proper cybersecurity practices has been becoming growing over the last years, partly due to the popularity of trading platforms themselves and the increased attention to them from malicious actors. Currently, users only need to secure their login credentials and don’t have to worry about the rest of their related data.
Closing Thoughts
Using a web terminal for trading has many advantages, some of which will continue to develop over the next years as the technology improves even further. While traditional trading terminals are likely not going away completely anytime soon, their market share is gradually getting taken over by web terminals and this will probably continue to be the case for some time.
Snowflake is a cutting-edge cloud-based data warehouse and analytics platform that offers a user-friendly, flexible, secure, and cost-effective solution for managing vast amounts of structured and unstructured data. For it to be effective for modern data environments, data teams need to focus on data reliability to ensure they can take advantage of the plethora of features such as scalability, high availability, and performance optimization. Enterprises that prioritize data reliability will experience how Snowflake empowers organizations to unlock actionable insights throughout the entire data process, from data ingestion to consumption.
The key to harnessing the full potential of data lies in its accuracy and timeliness. When data is reliable, it enables enterprises to gain a competitive advantage and become truly data-driven organizations. Achieving data reliability requires continuous data observability into the efficacy of data and data pipelines, enabling organizations to detect and address issues early in the data journey.
By prioritizing data reliability, organizations can optimize their data performance and unlock the true value of their data assets.
Data reliability is critical for Snowflake environments
Managing complex Snowflake environments requires more than just data quality alone. To effectively address data issues across all areas of Snowflake operations, data teams need a data reliability-driven data observability platform that is optimized to enhance the Snowflake experience. To better understand where data issues may arise, it’s crucial to examine the structure of Snowflake.
Snowflake’s Data Quality Framework
A robust data quality framework is essential for organizations to ensure the accuracy, reliability, and security of their data. Snowflake provides guidance on a data quality framework, which, when combined with an effective data reliability approach that’s developed for modern data stacks, empowers data teams to optimize their Snowflake environments by ensuring timely, fresh, and high-quality data.
Identifying and understanding Snowflake data reliability
Snowflake, the leading cloud-based data warehouse, provides the Snowflake Connector for Python, allowing data professionals to create custom Python applications that connect to Snowflake for seamless data operations. This enables organizations to leverage their expertise in the Python scripting language to develop their own data quality framework with tailored rules and specifications to achieve their data quality goals.
Snowflake Data Governance Accelerated Program
Recognizing the significance of data quality and data governance, Snowflake has launched the Snowflake Data Governance Accelerated program. This program is designed for Snowflake data governance partners who have developed solutions that integrate with Snowflake to enhance its already robust governance capabilities. This empowers organizations to further strengthen their data governance practices and ensure data accuracy, reliability, and security.
Data Profiling with Snowflake
Data profiling is a crucial step in ensuring data accuracy and reliability. Snowflake provides access to open-source libraries such as Pandas-Profiling and the data-profiling Github library, which enable quick and efficient profiling of datasets without the need for custom code. Snowflake also offers a ‘Profile Table’ feature that provides an overview of all columns within a table, including type, size, null value counts, and more, helping identify potential issues with the dataset before further analysis.
Snowflake Data Governance
Snowflake Data Governance is a comprehensive cloud-based platform that equips organizations with tools for managing their data assets securely and compliantly. The platform allows users to define policies for access control, audit trails, encryption, masking, classification labels, and more. It also offers an intuitive user interface for creating catalogs of data sources and visualizing relationships between them, facilitating effective data governance practices.
Ensuring Data Freshness with Snowflake
Snowflake Data Governance offers real-time observability tools that enable organizations to monitor changes in datasets over time, ensuring data freshness. This allows quick identification of discrepancies between different versions of datasets, ensuring accuracy across all reports and documents produced within the organization. This eliminates the need for manual reconciliation of differences between dataset versions, saving time and effort.
Maximizing Data Insights with Snowflake
Leveraging Snowflake data types categorization and Snowflake data visualization can provide enhanced visibility into data analysis. However, managing Snowflake monitoring and data sharing can be challenging. A data observability solution can help democratize access to critical insights, empowering organizations to optimize their data performance and gain valuable insights from their Snowflake environment.
Learn more about how data leaders are prioritizing data observability for their Snowflake environments with the report, The Snowflake Data Experience.
I have been thinking of how to learn prompt engineering. At one level, prompt engineering is a natural and intuitive task. But as the domain matures, we are seeing more awareness of the need for a formal process. The key point is to develop a creative/prompt engineering mindset. This is not a technical role but rather a creative (and iterative) process. This makes prompt engineering different to traditional technical skills we are familiar with such as MLOps. With this background, I list a set of resources and strategies to learn prompt engineering for technical people.
Prompt engineering mindset
I believe that the mindset is key. There are a number of strategies for developing a prompt engineering mindset aka working with the machine to get the best possible outcomes. Some of these include:
“Describe like it already exists”
“Provide Instructions and Guidance, not a Formula.”
“Think and Describe in Analogies.”
“Genius in a Room.”
Source: Four Tips for Developing A Prompt Engineering Mindset
Foundations
Large Language Models
LLM technology foundations – ex transformers
LLM model choices
Modalities(code, images and language)
Components of LLMs
LLM architectures
Prompt workflow
where do we start
Overall workflow
How are LLMs trained?
Prompting and Fine-Tuning
Prompting strategies
Role Prompting
Few shot prompting
Combining Techniques
Chain of Thought Prompting
Zero Shot Chain of Thought
LLM applications
Legal AI Prompts, Startup AI Prompts, Sales AI Prompts, Content Writing AI Prompts , E-Commerce AI Prompts, Education AI Prompts, Customer Service AI Prompts, Human Resources AI Prompts, Product Management AI Prompts, Development AI Prompts , Design AI Prompts , Marketing AI Prompts, Finance AI Prompts
To excel in any career path, it is very important to continuously keep on upgrading with the required skills. And so is the case with Data Scientists as well. With industries heavily relying on data-driven decision-making processes, the role of Senior Data Scientists has become more important than ever. He leads data-driven projects, manages teams, and communicates insights to stakeholders. To succeed in this role, you need diverse technical, managerial, and interpersonal skills. While you can acquire many skills through senior Data Scientist certification, many skills can be learned via experience, and enhance your thinking and decision-making capabilities. In this article, let’s explore the top skills you’ll need to thrive as a senior data scientist.
Top Skills Needed to Become a Successful Data Scientist
Advanced Statistical Analysis
The most important part of the senior Data Scientist’s job role is to convert raw data into meaningful insights that help in making an informed business decision. Therefore Data Scientists should be proficient in statistical and analytical skills. They must know Regression Analysis, Time Series Analysis, and Hypothesis Testing to properly analyze the huge amount of data.
Machine Learning
Machine learning is a subset of artificial intelligence that involves building models that can learn from data and make predictions or decisions. Senior Data Scientists should have a strong foundation in machine learning including supervised and unsupervised learning, deep learning, etc. to develop predictive models, perform data clustering, and identify anomalies in data.
Big Data Technologies
The technical know-how of big data like Hadoop, Spark, and NoSQL Databases is a must for Data Scientists of the present generation. With the amount of data increasing at an unprecedented rate, there is an absolute need for skills about tools that can efficiently handle such a huge amount of data. These data cannot be handled by traditional data processing tools. A certification program for Senior Data Scientists empowers professionals to use such complex tools to effectively carry out their day-to-day operations.
Data Visualization
The graphical and pictorial representation of data is clear to understand and easy to work upon. Having efficient data visualization skills, Senior Data Scientists can convey complex information in a simpler way to the stakeholders. Therefore, Data Scientists must be well-versed in charting, graphing, interactive visualizations, and storytelling with data.
Business Acumen and Industry Knowledge
Understanding business goals, knowledge of industry trends, and entrepreneurial mindset prove to be a great advantage for data science professionals. Having a strong domain knowledge expertise, Data Scientists can find the relevant data, and make decisions that are most suitable to meet the business goals. With strong business skills, they can also predict future market trends and stay ahead of their competitors.
Project Management and Leadership
Project management is a crucial part of the Data Scientist’s job role. They must be able to complete the project with the limited resources available, on time, and within budget. Uncompetitive project management can lead to huge losses to the company as well. Right from project planning to stakeholder management, they should display excellent leadership skills and lead their team to develop successful data science projects.
Communication and Presentation Skills
Senior data scientists are often responsible for communicating complex data insights to stakeholders with varying levels of technical expertise. This requires strong communication and presentation skills to ensure that the message is clear, concise, and actionable.
Critical Thinking and Problem-Solving
While developing a data science project, many types of problems can occur which are not pre-scripted. Be it technical or business-related problems, senior Data Science professionals need to show a creative approach to solve those problems. They should have critical and out-of-the-box thinking skills to find the right and effective solution.
Time Management and Prioritization A data scientist has to juggle multiple projects and priorities all at once. This requires strong time management and prioritization skills to ensure that they can meet deadlines and deliver high-quality work. They must know what to delegate and when.
Mentoring and Collaboration Several junior team members idolize Senior Data Scientists in their career aspirations. Therefore, it becomes the responsibility of the Senior Data Scientists to mentor the young members and help them climb the ladder in the field of data science. Also, they must be flexible in collaborating with colleagues on other projects and departments to effectively get the work done and also build a strong data-driven culture within the organization.
Conclusion
Most of the skills listed above are interpersonal skill and varies from individual to individual. Since these are not inherent skills and can be learned over time, professionals must always work to upscale and achieve their personal career ambitions. How fast and how dedicatedly you learn decides how far you can go in your data science career. Apart from that, Senior Data Scientist Certifications from institutes like USDSI® are also available which are designed to enhance your data science skills. These programs ensure you are up to date with all the latest skills and technology required to become a successful Data Scientist. So which skill are you working on now?
The healthcare sector is a complex ecosystem consisting of different stakeholders- patients, hospitals, physicians, healthcare staff, pharmacies, and laboratories.
As one of the most restricted sectors, the healthcare industry has remained sluggish in adopting technological advancements. However, the recent pandemic age has changed the story completely. Today, we see a radical change in the traditional doctor-patient approach.
Technology has penetrated deep into the healthcare sector thanks to tech-savvy patients and healthcare professionals. As a result, the healthcare sector puts emphasis on promoting healthy attitudes and giving better experiences to the patient.
Here, seamless and real-time access to information about the patient’s condition plays a vital role.
In this article, we are going to see the benefits of big data analytics in ensuring better data access and analysis for improved healthcare services. Before moving ahead, let’s understand the importance of big data analytics in this rapidly thriving sector.
What is Big Data Analytics in Healthcare?
The modern healthcare system puts the patient in the center and considers the physician as a partner who strives to accomplish the therapeutic process.
Electronic Health Records (EHRs) and other digital data of patients keep on coming into the healthcare organization in huge quantities every day. Such a massive amount of data requires the assistance of technological advancements for effective and accurate analysis. Here, big data analytics comes into the picture.
Big data refers to the huge quantity of information that comes from various sources like EHRs, pharmaceutical research, medical devices, and wearables.
Thanks to evolving technology, we have many advanced tools available to analyze this data thoroughly and get useful insights. These outcomes of big data analytics help the healthcare sector prevent the spread of epidemics, find remedies for various diseases, and bring various costs down to keep their services affordable for patients.
As per the report, the size of big data analytics in the global healthcare market is expected to reach $67.82 billion by the end of 2025. It will show a CAGR of 19.1% during the forecast period of 2018 to 2025.
Let’s dig deep into the major benefits of big data analytics for healthcare organizations.
Key Benefits of Big Data Analytics for the Healthcare Sector
Leveraging big data analytics can bring many benefits to the healthcare sector. Here we mention a few of them.
Improves Healthcare Services
This is one of the most noteworthy benefits of big data analytics for the healthcare sector. It offers excellent clinical insights to healthcare professionals and enables them to improve patient care. Physicians can prescribe effective medications and make more accurate decisions based on these insights.
Also, big data analytics can help companies implement AI technology in the healthcare sector successfully by eliminating several challenges through these valuable insights.
Enhances Patient Diagnosis
EHR is the most important digital health record of the patient. It includes the demographics, medical history, diagnostic test results, and allergies of the patient. Physicians and other healthcare professionals can access EHRs in a secure way.
Also, they cannot alter the patient’s personal information but can update the diagnosis and medication. With big data analytics, EHRs can trigger notifications and alert patients about their visits, and track their prescriptions.
Reduce Overall Costs
Another major benefit of big data analytics is a reduction in various costs. For example, healthcare providers can identify large patterns in the patient’s condition with the help of big data analytics. It helps them cut costs by eliminating the unnecessary hospitalisation of the patient and service providers can focus more on other patients where care is essential.
Also, big data with predictive analytics enables healthcare organisations to estimate the patient cost and maximise efficiency by planning their treatment carefully.
Predicts Higher Risks
Predictive analytics is an AI and ML-powered concept and when it combines with Big Data, the combination can be a game-changer in healthcare. Both data sets and data annotation can build healthcare AI and predictive analytics can strengthen it by predicting patients with higher risks quickly.
As a result, physicians and healthcare service providers can intervene early to save them. This prediction is categorically useful for patients with chronic diseases.
Integrates Fitness Devices
Fitbits, Apple Watch, and other fitness devices can keep track of the patient’s physical activity levels. The data collected from numerous wearable devices is sent to cloud-based servers, and physicians can use it to know the overall health condition of the patient. It also assists them to make an individual wellness program for the patient.
Fitness products with built-in analytics features can analyze the user’s data that physicians can access to know the user’s physical activities and health patterns.
Offers Real-time Alerts
Specific medical decision support software analyzes medical data in real-time to give instant alerts. These alerts help healthcare service providers make better decisions in writing prescriptions.
Doctors insist on using wearable that can collect the patient’s data continuously and send the same to the cloud. Doctors can access this data as and when necessary to prescribe medicines.
How to Ensure Data Security in the Healthcare Industry
Data security remains a top concern in a highly regulated healthcare sector. Though this industry has strict laws regarding data storage and access, it is one of the biggest victims of data breaches and leaks in various industry sectors. When we implement big data analytics in the healthcare sector, it is necessary to address the challenge of protecting the security and privacy of the patient’s confidential data.
Big data analytics service providers can establish necessary configurations, perform risk assessments, conduct audits, and give training to healthcare employees on the best practices to safeguard confidential data in the healthcare organisation.
Concluding Remarks
Big data analytics and other emerging technologies like AI and ML can provide healthcare institutions with real-time patient insights from huge data.
You can reduce overall expenses and improves healthcare services significantly with the help of actionable insights generated by big data analytics. When it comes to enhancing diagnosis and generating real-time alerts, big data analytics can remain useful. However, big data analytics service providers need to ensure the security of EHRs and other confidential data of patients by using several proven techniques and practices.
About Author:
Vipul Makwana is a Digital Marketing Strategist at Silver Touch, a leading digital transformation consulting company that provides end-to-end AI/ML, Blockchain, Big Data, and Analytics solutions. He’s keen on reading about new technology and marketing.
Artificial Intelligence (AI) is sweeping the globe, leaving no stone unturned as it reshapes industries far and wide. OpenAI, a trailblazer in AI research, is leading the charge by creating powerful AI models that are breathing new life into the way we work.
The marketing and sales arena is ripe for AI-powered disruption. Enter OpenAI technology, which tackles time-consuming content creation, data analysis snags, and the challenges of deciphering consumer behavior. Businesses that tap into these exciting AI tools can craft razor-sharp marketing strategies that boost revenue and deliver more value to customers than ever before.
In this article, we bring you five groundbreaking marketing tools that harness the might of AI – specifically, OpenAI technology – to transform the marketing landscape. Let’s get into it.
Walnut Ace
Walnut Ace is an advanced product suite from the interactive demo platform, Walnut, meticulously crafted to help sales teams enhance workflows and improve overall efficiency. By seamlessly integrating OpenAI, Slack, and Gmail, Walnut Ace equips sales teams with the ability to work at a faster pace, respond more quickly, and deliver highly engaging product demos.
The integration of OpenAI allows Walnut Ace’s AI assistant to provide support in various tasks, such as refining presenter notes, crafting insightful scripts, and addressing questions or queries, ultimately resulting in superior product presentations and increased revenues for businesses.
Jasper
Jasper is an intelligent AI writing assistant that harnesses the power of OpenAI technology to enable marketers to produce engaging content swiftly and effortlessly. By automating the research and structuring tasks, Jasper allows writers to concentrate on developing powerful and captivating messages
The AI engine guarantees the ethical use of language by identifying and flagging offensive or inappropriate content before it reaches its intended audience. With Jasper, marketers can create enthralling content that resonates with their customers, proving the effectiveness of AI in streamlining and enhancing the creative process.
GrowthBar
GrowthBar cranks content creation up a notch with its trailblazing use of OpenAI’s GPT-3 technology. This clever tool streamlines the content development process by suggesting keywords, setting word count, supplying links and images, and much more. The result? High-quality content in a snap to meet your SEO needs. GrowthBar’s advanced backlinking capabilities and detailed outlines make perfecting the content creation process a breeze.
With its handy Chrome extension, GrowthBar is always within reach. This AI-powered dynamo empowers businesses to create impactful content that resonates with their target audience, proving AI’s transformative effect on digital writing.
Poll the People
Poll the People is a game-changing market research tool that fuses human smarts with cutting-edge AI analysis. OpenAI’s technology supercharges this tool, providing invaluable insights with astonishing speed. Dive into a wealth of options, including audience demographics, data visualization, and AI-generated word clouds.
The ‘Insights’ tab dishes up comprehensive analysis, arming decision-makers with the data they need to call the shots. Poll the People helps businesses hit the bullseye with product design, boosting sales and customer satisfaction. This tool underscores AI’s immense impact on market research and paves the way for savvy decision-making.
Crayon
Crayon, an AI-powered market intelligence platform, taps into OpenAI’s natural language processing prowess to track trends, analyze customer preferences, and keep an eye on competitors. Stay ahead of the curve with easy-to-digest analytics and actionable insights.
Crayon’s natural language processing and machine learning capabilities make short work of filtering and categorizing data from diverse sources.
This powerhouse tool pinpoints trends and shifts that could shake up the market, helping decision-makers stay one step ahead of the competition. Crayon showcases how AI technology can help businesses adapt and flourish in a dynamic market landscape by offering valuable insights and cues for intelligent investments.
The Final Takeaway
The rise of Walnut Ace, Jasper, GrowthBar, Poll the People, and Crayon is a testament to the game-changing potential of OpenAI technology in the marketing and sales world. By embracing these innovative tools, businesses can effectively unlock the true power of AI, propelling their success and revolutionizing the way they operate and engage with customers.
As OpenAI technology continues to evolve, we can anticipate even more groundbreaking tools to emerge, further transforming the realms of data science and marketing. So buckle up and watch this space – the AI revolution is just getting started!
Over the years of working on commercial AI projects, I have come across various products and business domains that have adopted machine learning algorithms. This experience helped me form some best practices for selecting the right algorithms for different types of business tasks. In this article, I will share some valuable insights from my experience regarding how to work with them in the most efficient way to meet the client’s business needs.
1. Regression
Regression is a well-known ML algorithm for exploring the relationship between independent variables or features (predictors) and a dependent variable (target) or output. Regression is usually used to explain or predict a specific numerical value based on using historical data.
How does it work in practice? Imagine that your client is a real estate business owner who wants to set the price for apartments and houses they are selling based on the best relation between price and time to sell houses. You can develop a regression model that will be able to predict the price per specified house/apartment based on various provided features in this case to have some kind of baseline recommended price.
To develop a reliable AI model, you will need to provide it with the following historical data:
Various features that describe houses/apartments that need to be sold: the number of rooms, floors, bedrooms, and so on
Geographical characteristics: f.e. houses in capitals are much more expensive compared with other cities
Population, how trendy this place is, and other information that could influence price
So, let’s try to build a regression model. Given that in real life there is quite rarely a linear correlation between the target variable and all other features, let’s build polynomial regression to model a nonlinear relationship between the features and the target variable. By creating polynomial features, we can create a more complex model that can capture these nonlinear relationships.
First of all, let’s import all necessary modules and datasets that we will use for training the polynomial regression:
from sklearn.datasets import fetch_california_housing from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error house_dataset = fetch_california_housing() X = house_dataset.data y = house_dataset.target
We will use the California Housing dataset, where the target variable is the median house value for California districts, expressed in hundreds of thousands of dollars ($100,000).
Then, as usual, we need to split the dataset into training and testing parts and create polynomial features. In this case, we’re using a degree of 2, which means we’ll create quadratic features.
Then we need to train our model and make predictions on the test set that the model didn’t see during the training process.
model = LinearRegression() model.fit(X_train_poly, y_train) y_pred = model.predict(X_test_poly)
The final and obligatory step is to evaluate the model with the evaluation metric that was chosen. For our purpose, we selected MSE metrics that measure the average squared difference between the predicted and actual values. It gives higher weights to large errors, which can make it useful for detecting outliers or data points with large errors.
In comparison to running a classical linear regression model without using polynomial features, the MSE error is lower (classical model has MSE = 0.53) and it has proved that you can experiment with these techniques even more for obtaining better model productivity.
2. Classification
Classification is utilized for categorizing both unstructured and structured data. Among the most common use cases of this algorithm are spam filtering, visual classification, auto-tagging, and defect detection. What other types of projects can you use it in?
Let’s say your client has a customer service department with thousands of requests per day. Helpdesk gives tags to each of the interactions with the customers. This is done for better and quicker navigation of customers’ requests and for grouping requests by topics.
To help your client to achieve their business goals, you can create a multi-label classification model that will automate the process of assigning several tags to new customer requests. The business solution will be based on previously tagged clients’ data. As a result, customer service specialists will not spend time on this activity, concentrating on more important tasks instead.
One of the problems you can face while working with the classification task in a real-life situation is unbalanced classes. An imbalance occurs when one or more classes have very low proportions in the training data as compared to the other classes. How can you combat this? There are several strategies depending on what kind of data you are working with.
When it comes to numeric values, the problem can be solved by oversampling. Oversampling involves randomly selecting examples from the minorclass, with replacement and slight modifications, and adding them to the training dataset.
An additional idea to overcome this issue is assigning higher weights to the minority class. So, briefly speaking, you can define the proportions of classes to improve the results.
Let’s focus on overcoming unbalancing problems in practice.
For this example, I have generated an imbalanced dataset with 64 features and 10,000 samples, where 70% of the samples belong to the majority class [0] and 30% belong to the minor class [1].
Quite a classical solution for performing classification problems could look like this:
With the resampling technique, you can oversample the minority class, undersample the majority class, or use a combination of both. This can be achieved using libraries like imbalanced-learn. Let’s look at this sample of the code with applied resampling techniques:
We used ‘RandomOverSampler()’ from the ‘imblearn’ library to oversample the minority class in the training data. This helps balance the classes by generating synthetic data points for the minority class.
In addition to this approach, you can assign higher weights to the minority class and lower weights to the majority class. This can be done using the ‘class_weight’ parameter in the classifier. Let’s look at this part of the code:
Here we calculate the class weights using the ‘compute_class_weight()’ function from ‘sklearn.utils.class_weight’. Then we need to use these class weights to train our classifier.
Let’s summarize and look at the code snippet for the classification problem with resolving the problem of unbalanced classes:
As you can see, comparing results obtained with and without applying techniques for preventing problems with imbalancing classes, with the second approach the metrics overall became more reliable.
3. Clustering
When it comes to clustering, this ML algorithm defines and groups unlabeled examples in datasets. Clustering uses unsupervised machine learning. This way large structured datasets can be efficiently processed and managed. At MobiDev, we commonly use clustering algorithms to bring valuable insights to businesses.
Imagine that the business owner of a supermarket chain wants to analyze employees’ performance and identify who works better and who underperforms. Numerous employees work in different supermarkets, so the owner needs to observe a full picture of employees’ performance while reducing operational costs.
To achieve this business goal, you can build a clustering model for anomaly detection. The anomaly activity is identified if employees’ behavior is uncommon (differs from all of the rest). By using the clustering model, it’s possible to identify workers whose behavior patterns are different from the rest of the employees. In this case, clustering is the first stage of the analysis to manage performance issues and productivity optimization, though a business has enough room for the implementation of other ML algorithms.
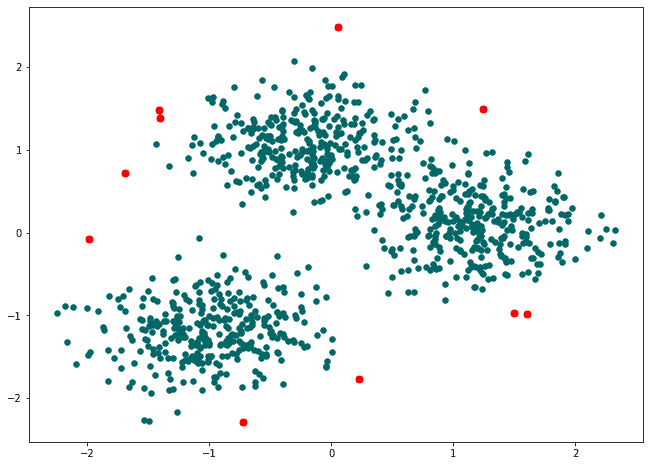
Let’s consider how anomaly detection works using clustering approaches in practice.
In the code example below, we first generate a demo dataset with 1000 samples, 3 centers, and cluster_std equals 2.5 using the ‘make_blobs()’ function from the ‘scikit-learn’ library. Then, we scale the data using the ‘StandardScaler()’ to ensure that all the features are on the same scale – it is important for the algorithms that are working based on distance.
import numpy as np import pandas as pd from sklearn.cluster import DBSCAN from sklearn.datasets import make_blobs from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt # Generate a random dataset X, y = make_blobs(n_samples=1000, centers=3, cluster_std=2.5, random_state=42) scaler = StandardScaler() X = scaler.fit_transform(X)
Next, we create a DBSCAN model with an ‘eps’ value of 0.3 and a ‘min_samples’ value of 5. We fit the model to the data and get the cluster labels and the number of clusters.
‘eps’ (short for epsilon) is the radius of the neighborhood around each data point. Points within this radius are considered neighbors of each other.
‘min_samples’ is the minimum number of points required to form a dense region. If a point has at least ‘min_samples’ neighbors within a distance of ‘eps’, then it is considered to be part of a dense region.
Then let’s plot results for validation to be sure that the algorithm worked as we expected.
# Plotting data with anomalies marked with red color anomaly_color = '#ff0000' plt.scatter(X[:, 0], X[:, 1], color='#006666', s=20) plt.scatter(X[labels == -1, 0], X[labels == -1, 1], color=anomaly_color, s=40) plt.show()
As we can see from the plot, it makes sense that anomaly detection algorithms based on clustering approach filtered out these data, so you then can remove it from dataset to clean your data before training.
Finally, we will identify the anomalies and print out the amount of anomalies that were detected.
# Identify anomalies anomalies = X[labels == -1] print(f"Number of anomalies: {len(anomalies)}") >>> Number of anomalies: 10
Please note that the choice of ‘eps’ and ‘min_samples’ values will depend on the specifics of the dataset and problem at hand. You may need to experiment with different values to find the best results.
If you want to use the clustering model for identifying common patterns, anomalies can prevent your model from being effective. They can blur the whole picture, and in some cases, they need to be excluded from the model. In other words, not only identifying anomalies but also grouping the data can help to improve your model and achieve the client’s business goals.
Before Using an ML Algorithm for a Project
While the world of machine learning algorithms is exciting, it’s also full of surprises. The client doesn’t always understand what the process of turning an AI idea into a real product looks like. Here is how things can happen in the first stage of the project.
I have several tips that can help you avoid the most common pitfall of ML algorithms adoption:
Runtime is always important, even when a client didn’t tell you about it.
Think about speed during development. It is better to write optimized code from scratch.
Use GPU / CPU resources at a maximum.
Multiprocessing is a great option for parallelization.
Write a project with the pipeline running approach — make life easier in the future when your model will be deployed.
With all the opportunities of ML algorithms, you should be really careful about how you implement them. Whichever model you choose, remember that better data is of greater significance than an algorithm, which can be enhanced by extending the training time. Good luck!
Author
Anastasiia Molodoria AI/ML Team Leader at MobiDev.
Three years after the outbreak of the COVID-19 pandemic, the lingering impacts of the viral outbreak and the risk of another deadly pathogen spreading around the world remain. The pandemic challenged every health system in the world, stressing facilities, medical equipment suppliers, and medical personnel. Public health authorities tracked disease transmission, modeled forecasts across multiple waves of the pandemic, and distributed available vaccines. In the United States, the virus also put a significant drain on many facets of the country’s budget, especially the budgets for Medicare and Medicaid programs.
The role of health and clinical informatics was critical in the system’s response to the pandemic. Informatics, along with machine learning (ML) models and artificial intelligence (AI), show tremendous potential. The pandemic underscored the opportunity and importance of the informatics discipline, as demonstrated by the widespread utilization of health informatics applications like telehealth, remote patient monitoring, patient engagement, AI-based drug discovery, precision medicine, and clinical decision support. To better respond to a similar or worse event in the future, countries must ensure that they are better prepared to deal with pandemics with a foundation in sound data collection, analysis, and more effective decision-making.
The Role of Healthcare Informatics
Healthcare informatics is the analysis of health and clinical data to deliver better care to patients and plays an important role in interconnecting hospitals, insurance providers, doctors, and the government. Informatics is becoming more integrated into various aspects of the healthcare industry, from electronic health records to tracking resources across provider networks.
Healthcare informatics allows organizations and providers to analyze and manage health records to better understand disease spread and patient numbers. Also, it enables hospitals and pharmacies to identify patterns to anticipate and address supply demands, ensuring they are better prepared for healthcare crises. Further, informatics plays a significant role in supporting the growing demand for telemedicine, for example, by developing programs and software and providing secure access to health information and records. In addition, as AI and ML grow more ubiquitous, informatics will leverage these tools for more significant forecasting, preparation, and resource distribution to better understand health trends and provide support during healthcare disasters.
Informatics During the COVID-19 Pandemic
The field of health and clinical informatics contributed to meeting the challenges posed by the COVID-19 pandemic. Informatics helped healthcare providers follow state and federal protocols, conduct data analysis, and interconnect different organizations and systems for years, but during the pandemic providers and government organizations were also able to identify and monitor the spread of different variants of the virus and track common symptoms at the local, state, and national level.
By connecting different healthcare companies and government agencies, informatics enabled these organizations to share resources and data. In the early months of the pandemic, for example, ventilators, oxygen, and personal protective equipment (PPE) were in short supply; healthcare informatics allowed different hospitals to share resources as needed by identifying supply and demand more quickly.
Informatics also assisted public health communication through information portals that tracked and shared information daily information about case numbers, testing rates, and vaccine rollouts. Aspects of informatics are seen in care today and range from submitting an insurance claim to a provider’s ability to view the patient’s symptoms or disease in a larger context by connecting with other organizations.
Machine Learning and Artificial Intelligence
The goal of each healthcare organization is to use its raw data for forecasting. To make meaningful predictions, it is vital for data to be first cleaned and processed. This is where ML and AI shine. When trained properly on their use, providers can leverage ML and AI to sort through the data they collect. Each company and organization’s immense troves of data are in raw format and, to be of use, it must be cleaned up and sorted, which is an immense task for a human. With the help of technologies like AI and ML, faster, more accurate. and large-scale data processing is possible.
Some of the most exciting impacts of these tools are the ability to generate better predictions and identify new methods of diagnosis, and the COVID-19 pandemic offered a testing ground for these applications. In early February 2020, with the COVID-19 pandemic just starting to make global waves, engineers at MIT began using data on the virus’ spread and implemented a ML algorithm to predict when infection rates would drop in different countries, based on that country’s quarantine protocols. Other researchers associated with MIT developed an AI model able to identify asymptomatic COVID-19 patients from healthy individuals through forced-cough recordings with 98.5 percent accuracy. The model was trained using thousands of samples of both speech and forced coughs.
To unlock the full potential of AI and ML, it’s important to remember that they are technical tools requiring domain-level knowledge. Depending on the challenges these tools are applied to, it is essential for doctors and nurses, insurance professionals, and those familiar with healthcare’s complex set of regulations to partner with healthcare informatics specialists familiar with the technical aspects of these tools.
Preparing for the Next Pandemic
In the face of a global health crisis, it is vital for the healthcare industry to respond quickly. Healthcare and clinical informatics help organizations manage and process their data ahead of health crises. When powered by ML and AI, informatics can quickly and accurately generate models to help professionals understand the disease, make informed decisions, and act swiftly in line with state and federal governments. Communication is key during a global pandemic, and informatics can facilitate this by sharing data with other organizations, regulatory or government bodies, and the public in a timely manner.
Still, without alignment between state and federal regulations, the industry response will remain limited. Variations in the protocols and rules between states and federal Medicare and Medicaid programs, for example, can be an impediment to interconnecting different agencies and organizations with health informatics. An article published in the Journal of American Medical Informatics Association argues that current regulations require modernization to eliminate conflict at the federal and state levels and suggests changes to HIPAA could facilitate better communication among healthcare organizations. Finally, given the potential benefits AI and ML can provide, organizations should begin leveraging these tools now, rather than trying to catch up when the next health crisis arrives. Pairing technical expertise and domain-level knowledge will enable organizations to make full use of these technologies, so they should invest time and resources in recruiting the right people.
While the COVID-19 public health crisis is ending in the United States, future pandemics are inevitable. The level at which governments and healthcare organizations are prepared to respond to these threats is key to managing the spread of disease, reducing loss of life, and minimizing long-term economic and health impacts for millions of people around the world. Clinical and health informatics played a critical role in the healthcare industry’s response to COVID-19, in part due to the expansion of technologies like telemedicine, AI, and ML. Data and how it is used are at the heart of modern healthcare, and investing now in informatics and analytics could make all the difference in the next pandemic.
About the Author:
Bhavini Kaneria is a senior analytics manager and leader in informatics, machine learning, and artificial intelligence. Bhavini has worked extensively on different campaigns in Medicare, Medicaid, Dual Eligible Special Needs Plans, and Community Care. In early 2020, Bhavini created an algorithm to track COVID-19 spread in different communities and identify the effects of the virus on members with chronic conditions, providing this data to DHS weekly. Bhavini holds an MBA from Middlesex University, U.K., and an MS from Virginia Commonwealth University, U.S. For more information, contact [email protected].