Intel Kills ‘Blockscale’ Bitcoin Chip April 19, 2023 by Agam Shah
An interview with Intel CEO Pat Gelsinger from just last year already hasn't aged well. In the interview, Gelsinger decries the energy consumption of Bitcoin mining ("a climate crisis") moments before announcing Intel's own Bitcoin mining product, Blockscale 1000, which Gelsinger claims is "dramatically better" than other power-guzzling chips that take over energy grids. Now, Blockscale is no more, with Gelsinger chopping off the product as part of its cost-cutting efforts to save $10 billion by 2025. The news was originally reported by Tom's Hardware.
“As we prioritize our investments in IDM 2.0, we have end-of-lifed the Intel Blockscale 1000 Series ASIC while we continue to support our Blockscale customers,” Intel told HPCwire in an email.
The Blockscale chip was released last year with expectations that it would serve the fast-growing mining and digital transactions market. Intel sold its chips to infrastructure companies like Argo Blockchain, GRIID Infrastructure and Block.The blockchain chip received support from Raja Koduri, who formerly led Intel's accelerated computing division, but resigned late last year.
Intel has now posted a document notifying customers of Blockscale’s cancellation.
The last orders for the product will be taken in October this year, with the last shipments going out in April next year. The document also revealed that Intel had three versions of the Blockscale chip.
Cryptocurrencies like Ethereum have converted to a proof-of-stake model, which reduces the strain on GPUs to mine cryptocurrencies. It was a shift from the older proof-of-work model, which awarded coins to the most powerful miners throwing the most hardware resources to solve complex math. That resulted in the buildup of GPU factories to mine cryptocurrency. The proof-of-stake model and its lower reliance on hardware led many miners to repurpose existing GPUs for the purposes of cloud and acceleration of applications.
In a way, Gelsinger has righted the ship by cutting the Bitcoin chip, which stood out like a sore thumb in Intel’s chip lineup. It was introduced almost as an afterthought to serve a highly volatile market, and it went against Gelsinger’s resolve to focus on engineering and a renewed focus on highly targeted markets.
Hive Blockchain, a company that mines bitcoins, in a March filing with the U.S. Securities and Exchange Commission said it expected to receive 645 mining devices called BuzzMiners, and also mentioned the devices were powered by the Intel Blockscale ASIC. It said the number of BuzzMiners in its arsenal would total 6,300 in the coming months. This week, a filing from Hive said the company had received 5,600 BuzzMiners, but made no mention of Intel Blockscale. It also did not mention the number of chips it expected to receive.
Hive also uses GPUs for Bitcoin mining, but given the energy prices and difficulty mining Bitcoin, Hive is trying to broaden its GPUs in data centers to run cloud and accelerated computing applications. The company is running a GPU high-performance computing pilot that is "generating approximately $1,800/MWh of revenue."
"These advancements and agility allow us to generate positive gross mining margin during a crypto mining bear market," Hive wrote in the April filing.
The market volatility also affected Nvidia and AMD, which could not forecast GPU revenue because of the boom-and-bust nature of the crypto market. During the GPU shortage and Bitcoin boom, miners scalped up most of the available GPUs, which caused prices to skyrocket. Nvidia and AMD were trying to target GPUs at gamers and business users, and ultimately locked out the mining features from its GPUs.
Sundar Pichai Interview Stokes Debate on True Capabilities of AI Chatbots April 19, 2023 by Jaime Hampton
Has artificial intelligence left the realm of fantasy to become a disruptor of reality? Are AI models now learning and thinking on their own, heralding the age of artificial general intelligence? If you caught last weekend’s "60 Minutes," you might think so.
In the April 16 episode, CBS host Scott Pelley interviewed Google CEO Sundar Pichai and other developers about new and emerging AI technology and the future of AI.
“In 2023 we learned that a machine taught itself how to speak to humans like a peer, which is to say with creativity, truth, error, and lies,” Pelley says of AI chatbots, comparing this moment to the discovery of fire or invention of agriculture.
Pichai carries an optimistic yet concerned outlook and warns that “profound technology” like Google’s chatbot, Bard, will “impact every product across every company.”
In the interview, Pichai acknowledges the rapid pace of AI development and the challenges it presents, admitting that these concerns sometimes keep him up at night. He also acknowledges the technology’s propensity for creating fake news and images, saying, “On a societal scale, you know, it can cause a lot of harm.”
Google introduced Bard, somewhat hesitantly, following Microsoft’s launch of a Bing search engine version that utilizes OpenAI's large language models, the same technology responsible for the widely known ChatGPT. Google has thus far released Bard with limited capabilities, but Pichai mentions the company is reserving a more powerful Bard, pending more testing.
Pelley: Is Bard safe for society?
Pichai: The way we have launched it today, as an experiment in a limited way, I think so. But we all have to be responsible in each step along the way.
Narrator: Pichai told us he's being responsible by holding back for more testing, advanced versions of Bard, that, he says, can reason, plan, and connect to internet search.
Pelley: You are letting this out slowly so that society can get used to it?
Pichai: That's one part of it. One part is also so that we get user feedback. And we can develop more robust safety layers before we build, before we deploy more capable models.
CBS "60 Minutes" host Scott Pelley interviews Google CEO Sundar Pichai about the future of AI. (Source: CBS)
Chatbots like Bard and ChatGPT are prone to fabricating information while sounding completely plausible, something the 60 Minutes team witnessed firsthand when Google SVP of Technology and Society James Manyika asked Bard about inflation in a demo. The chatbot recommended five books that do not exist but sound like they could, like the title "The Inflation Wars: A Modern History" by Peter Temin. Temin is an actual MIT economist who studies inflation and has written several books, just not that one.
Narrator: This very human trait, error with confidence, is called, in the industry, hallucination.
Pelley: Are you getting a lot of hallucinations?
Pichai: Yes, you know, which is expected. No one in the field has yet solved the hallucination problems. All models do have this as an issue.
Pelley: Is it a solvable problem?
Pichai: It's a matter of intense debate. I think we'll make progress.
Some AI ethicists are concerned, not only with the hallucinations, but with how humanizing AI may be problematic. Emily M. Bender is a professor of computational linguistics at the University of Washington, and in a Twitter thread turned blog post, she accuses CBS and Google of “peddling AI hype” on the show, calling it “painful to watch.”
Specifically, Bender’s post highlights a segment where Bard’s “emergent properties” are discussed: “Of the AI issues we talked about, the most mysterious is called emergent properties. Some AI systems are teaching themselves skills that they weren't expected to have. How this happens is not well understood,” narrates Pelley.
During the show, Google gives the example of one of its AI models that seemed to learn Bengali, a language spoken in Bangladesh, all on its own after little prompting: “We discovered that with very few amounts of prompting in Bengali, it can now translate all of Bengali. So now, all of a sudden, we now have a research effort where we’re now trying to get to a thousand languages,” said Manyika in the segment.
Bender calls the idea of its translating “all of Bengali” disingenuous, asking how it would even be possible to test the claim. She points to another Twitter thread from AI researcher Margaret Mitchell who asserts that Google is choosing to remain ignorant of the full scope of the model’s training data, asking, “So how could it be that Google execs are making it seem like their system ‘magically’ learned Bengali, when it most likely was trained on Bengali?” Mitchell says she suspects the company literally does not understand how it works and is incentivized not to.
Pichai: There is an aspect of this which we call— all of us in the field call it a "black box." You know, you don't fully understand. And you can't quite tell why it said this, or why it got wrong. We have some ideas, and our ability to understand this gets better over time. But that's where the state of the art is.
Pelley: “You don’t fully understand how it works, and yet you’ve turned it loose on society?”
Pichai: “Let me put it this way: I don’t think we fully understand how a human mind works, either.”
Bender calls Pichai’s reference to the human mind a “rhetorical sleight of hand,” saying, “Why would our (I assume, scientific) understanding of human psychology or neurobiology be relevant here? The reporter asked why a company would be releasing systems it doesn’t understand. Are humans something that companies ‘turn loose’ on society? (Of course not.)”
By inviting the viewer to “imagine Bard as something like a person, whose behavior we have to live with or maybe patiently train to be better,” Bender asserts that Google is either evading accountability or hyping its AI system to be more autonomous and capable than it actually is.
(Source: Twitter)
Bender was co-author of a research paper that led to the 2020 firing of Mitchell and Timnit Gebru, co-leads of Google’s Ethical AI team. The paper argues that bigger is not always better when it comes to large language models, and the more parameters on which they are trained, the more intelligent they can appear, when in reality, they are “parrots” that do not actually understand language.
In the interview, Pelley asks Pichai how Bard could convincingly discuss painful human emotions as it had during a demo where it wrote a story about the loss of a child: “How did it do all of those things if it's just trying to figure out what the next right word is?”
Pichai says the debate is ongoing, noting, “I have had these experiences talking with Bard as well. There are two views of this. You know, there are a set of people who view this as, look, these are just algorithms. They’re just repeating what [they’ve] seen online. Then there is the view where these algorithms are showing emergent properties, to be creative, to reason, to plan, and so on, right? And personally, I think we need to approach this with humility.”
“Approaching this with humility would mean not putting out unscoped, untested systems and just expecting the world to deal. It would mean taking into consideration the needs and experiences of those your tech impacts,” wrote Bender.
We have reached out to Google and Emily Bender for comment and will update the story as we learn more.
Self-Regulation Is the Standard in AI, for Now April 19, 2023 by Alex Woodie
Are you worried that AI is moving too fast and may have negative consequences? Do you wish there was a national law to regulate it? Well, that’s a club with a fast-growing list of members. Unfortunately, if you reside in the United States, there are no new laws designed to restrict the use of AI, leaving self-regulation as the next-best thing for companies adopting AI—at least for now.
While it’s been many years since “AI” replaced “big data” as the biggest buzzword in tech, the launch of ChatGPT in late November 2022 kicked off an AI goldrush that has taken many AI observers by surprise. In just a few months, a bonanza of powerful generative AI models have captured the world’s attention, thanks to their remarkable capability to mimic human speech and understanding.
Fueled by ChatGPT’s emergence, the extraordinary rise of generative models in mainstream culture has led to many questions about where this is all going. The astonishment that AI can generate compelling poetry and whimsical art is giving way to concern about the negative consequences of AI, ranging from consumer harm and lost jobs all the way to false imprisonment and even annihilation of the human race.
This has some folks very worried. And last month, a consortium of AI researchers sought a six-month pause on the development of new generative models bigger than GPT-4, the massive language model unfurled by OpenAI last month.
“Advanced AI could represent a profound change in the history of life on Earth, and should be planned for and managed with commensurate care and resources,” states an open letter signed by Turing Award winner Yoshua Bengio and OpenAI co-founder Elon Musk, among others. “Unfortunately, this level of planning and management is not happening.”
Elon Musk says AI could lead to "civilization destruction" (DIA TV/Shutterstock)
Not surprisingly, calls for AI regulation are on the rise. Polls indicate that Americans view AI as untrustworthy and want it regulated, particularly for impactful things such as self-driving cars and receiving government benefits. Musk said that AI could lead to “civilization destruction.”
However, while there are several new local laws targeting AI—such as the one in New York City that focuses on use of AI in hiring, enforcement for which was delayed until this month—there are no new federal regulations specifically targeting AI nearing the finish line in Congress (although AI falls under the rubric of laws already in the books for highly regulated industries like financial services and healthcare).
With all the excitement of AI, what’s a company to do? It’s not surprising that companies want to partake of the positive benefits of AI. After all, the urge to become “data-driven” is viewed as a necessity for survival in the digital age. However, companies also want to avoid the negative consequences—whether real or perceived—that can result from using AI poorly in our litigious and cancel-loving culture.
“AI is the Wild West,” Andrew Burt, founder of AI law firm BNH.ai, told Datanami earlier this year. “Nobody knows how to manage risk. Everybody does it differently.”
With that said, there are several frameworks available that companies can use to help manage the risk of AI. Burt recommends the AI Risk Management Framework, which comes from the National Institute of Standards (NIST) and which was finalized earlier this year.
"When it is OK to give somebody more than somebody else"? asks AI expert Cathy O'Neil
The RMF helps companies think through how their AI works and what the potential negative consequences might be. It uses a “Map, Measure, Manage, and Govern” approach to understanding and ultimately mitigating risks of using AI in a variety of products.
While companies are worried about the legal risk of using AI, those worries are currently outweighed by the upside of using the tech, Burt says. “Companies are more excited than they are worried,” he says. “But as we’ve been saying for years, there’s direct relationship between the value of an AI system and the risk it poses.”
Another AI risk management framework comes from Cathy O'Neil, CEO of the O'Neil Risk Consulting & Algorithmic Auditing (ORCAA) and a 2018 Datanami Person to Watch. ORCAA has proposed a framework called Explainable Fairness (which you can see here).
The Explainable Fairness provides a way for organizations to not only test their algorithms for bias, but also to work through what happens when differences in outcomes are detected. For example, if a bank is determining eligibility for a student loan, what factors can be legitimately used to approve or reject the loan or charge a higher or lower interest?
Obviously, the bank must use data to answer those questions. But which pieces of data—that is, what factors reflecting the loan applicant—can they use? Which factors should they be legally allowed to use, and which factors should not be used? Answering those questions is not easy or straightforward, O’Neil says.
“That’s the whole point of this framework, is that those legitimate factors have to be legitimized,” O’Neil said during a discussion at Nvidia’s GPU Technology Conference (GTC) held last month. “What counts as legitimate is extremely contextual…When it is OK to give somebody more than somebody else?”
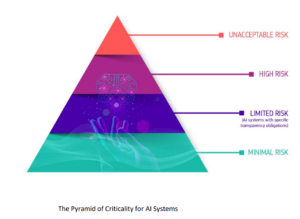
The European Union categorizes potential AI harms on the "Pyramid of Criticality"
Even without new AI laws in place, companies should start to begin asking themselves how they can implement AI fairly and ethically to abide by existing laws, says Triveni Gandhi, the responsible AI lead at data analytics and AI software vendor Dataiku.
“People have to start thinking about, OK how do we take the law as it stands and apply it to AI use cases that are out there right now?” she says. “There are some regulations, but there’s also a lot of people who are thinking about what are the ethical and value oriented ways we want to build AI. And those are actually questions that companies are starting to ask themselves, even without overarching regulations.”
Gandhi encourages the use of frameworks to help companies get started on their ethical AI journeys. In addition to the NIST RMF framework, there is also the
“There are any number of framework and ways of thinking that are out there,” she says. “So you just need to pick one that’s most applicable to you and start working with it.”
Gandhi encourages companies to start exploring the frameworks and becoming familiar with the different questions, because that will get them on their way on their own ethical AI journey. The worst thing they can do is delay getting started in search of the “perfect framework.”
“The roadblock comes because people expect perfection right away,” she says. “You’re never going to start with a perfect product or pipeline or process. But if you start, at least that’s better than not having anything."AI regulation in the United States is likely to be a long and winding road with an uncertain destination. But the European Union is already moving forward with its own regulation, termed the AI Act, which could go into effect later this year.
The AI Act would create a common regulatory and legal framework for the use of AI that impacts EU residents, including how it’s developed, what companies can use it for, and the legal consequences of failing to adhere to the requirements. The law will likely require companies to receive approval before adopting AI for some use cases, outlaw certain other AI uses deemed too risky.
A global AI regulation would be desireable, says Fractal's Sray Agarwal (Zia-Liu/Shutterstock)
If US states follows Europe’s lead on AI, as California did with the California Consumer Privacy Act (CCPA) and the EU’s General Data Protection Act (GDPR), then it’s likely that the AI Act could be a model for American AI regulation.
That could be a good thing according to Sray Agarwal, a data scientist and principal consultant at Fractal, who says we need global consensus on AI ethics.
“You never want a privacy law or any kind of ethical law in the US to be opposite of any other country which it trades with,” says Agarwal, who has worked as a pro bono expert for the United Nations on topics of ethical AI. “It has to have a global consensus. So forums like OECD, World Economic Forum, United Nations and many other such international body needs to sit together and come out with consensus or let’s say global guidelines which needs to be followed by everyone.”
But Agarwal isn’t holding his breath that we’re going to have that consensus anytime soon. “We are not there yet. We are not anywhere [near] responsible AI,” he says. “We have not even implemented it holistically and comprehensively in different industries in relatively simple machine learning models. So talking about implementing it in ChatGPT is a challenging question.”
However, the lack of regulation should not prevent companies from moving forward with their own ethical practices, Agarwal says. In lieu of government or industry regulation, self-regulation remains the next-best option.
The Industrial Metaverse Takes Hold Sponsored Content by Microsoft/NVIDIA April 20, 2023
Industrial metaverse applications built on NVIDIA Omniverse running on Azure offer an immersive and highly collaborative environment for developers and companies to improve their operations.
There is no doubt the concept of a metaverse, the 3D evolution of the internet, has great appeal to industrial enterprises. Recent efforts by NVIDIA and Microsoft Azure on an AI-powered industrial metaverse demonstrate the role such an environment can play and the value it can deliver to developers and companies today.
This collaboration has several aspects that help make the industrial metaverse a reality. Microsoft Azure will host two new cloud offerings from NVIDIA: NVIDIA Omniverse™ Cloud, a platform-as-a-service giving instant access to a full-stack environment to design, develop, deploy, and manage industrial metaverse applications; and NVIDIA DGX™ Cloud, an AI supercomputing service that gives companies immediate access to the infrastructure and software needed to train advanced models for generative AI and other applications.
Additionally, the companies announced they were bringing together their productivity and 3D collaboration platforms by connecting Microsoft 365 applications — such as Teams, OneDrive, and SharePoint — with NVIDIA Omniverse™, a platform for building and operating 3D industrial metaverse applications. The collaboration will accelerate the ability of enterprise teams to digitalize operations, engage in the industrial metaverse, and train advanced models for generative AI and other applications.
Synergies abound
The combination of the NVIDIA Omniverse solutions, Azure services, and Microsoft 365 applications allows companies to create immersive environments for rich collaborative and realistic industrial simulations, such as digital twins.
When announcing the most recent partnership details at the NVIDIA GTC event in April, Satya Nadella, chairman and CEO of Microsoft, said, “Together with NVIDIA, we're focused on both building out services that bridge the digital and physical worlds to automate, simulate, and predict every business process and bringing the most powerful AI supercomputer to customers globally."
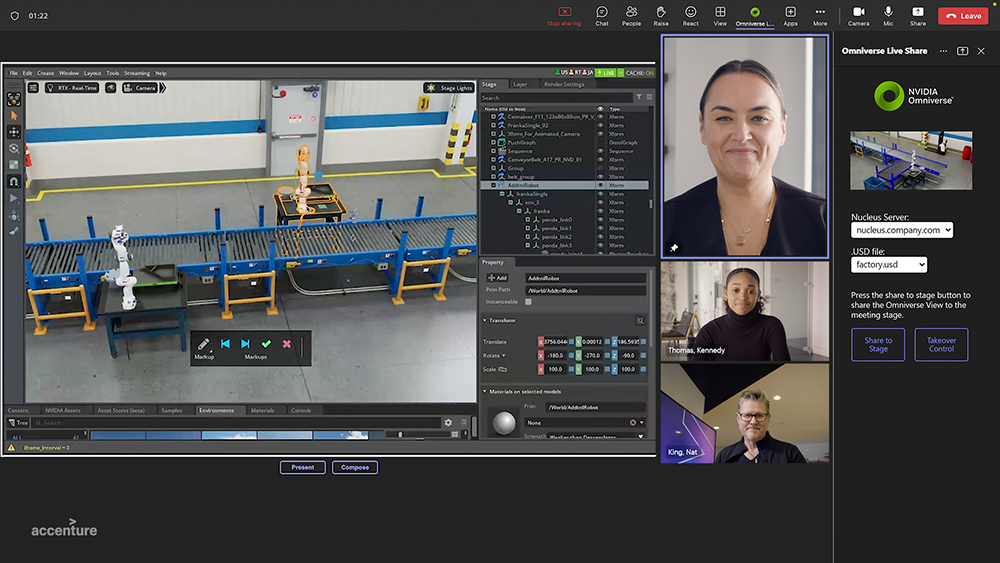
A GTC keynote demo presented by Accenture showed how the integration of NVIDIA Omniverse with Microsoft Teams could be used to enable real-time 3D collaboration. Running on Omniverse Cloud and leveraging a Teams Meeting featuring Live Share, the Accenture demo showcased how the integration can shorten the time between decision-making, action, and feedback.
In the demonstration, participants in a Teams meeting had an Omniverse application added to the meeting. At that point, everyone had a shared view of a segment of an assembly line that included industrial robots. Within that environment, a participant could move a robot to a new location along the line, add another robot to the operation, and more. As each change or addition was made, everyone in the Teams meeting saw the impact that change would have on the real system. And knowing this, all participants could make comments or suggestions.
The capabilities of such an immersive environment need an infrastructure, such as NVIDIA DGX Cloud and NVIDIA OVX running in Azure, that can assure the scalability of AI systems supporting the digital models. Such an infrastructure uses parallel processing power, low latency, and interconnected GPUs to train and inference complex AI models.
Enabling a real-world industrial metaverse
One prime capability enabled by the joint Microsoft Azure and NVIDIA Omniverse effort is moving the industrial metaverse from concept to reality. The foundation of such an environment is built on AI-driven digital twin technology where factories and facilities are physically accurate, providing a trustworthy simulation on which technical practitioners and business stakeholders can make accurate planning and operational decisions.
With Omniverse connected to Azure Digital Twins and Internet of Things Cloud Services, companies can link real-time data from sensors in the physical world to their digital replicas. Azure provides the cloud infrastructure and capabilities needed to deploy enterprise services at scale, including security, identity, and storage, while Omniverse provides the comprehensive 3D representation.
The bridging of the digital and physical worlds enabled here takes digital twins to a new level, helping companies build and operate more accurate, dynamic, fully functional 3D digital twins that automatically respond to and report changes in their physical environments.
Additionally, the benefits apply to the physical entities, too. Discovering an issue in a realistic digital twin, a company could run simulations to see how to avoid the problem or minimize its impact. For example, if welds on an auto assembly line are found to be defective at a higher rate than neighboring lines, the problem could be traced, in the digital twin, to a specific robotic welder. In turn, that welder could then be manually inspected or replaced. So, based on the findings of the simulations, a physical device’s state could be altered to improve overall operations.
One fear companies and developers often have is a lack of interoperability or openness between their software tools and systems and monolithic platforms that offer limited choices in capabilities, tools, and more. That is not the case here. Both Microsoft and NVIDIA have extensive ecosystems that complement their core offerings.
For example, the Omniverse platform is built entirely on Universal Scene Description (USD), an open 3D standard that provides a common language for 3D and simulation tools to connect and interchange data. Omniverse serves as a connecting fabric between leading enterprise tools such as Autodesk Maya, Revit, 3ds Max, ESRI CityEngine, Unreal Engine, McNeel Rhino, Siemens Xcelerator, and more.
Similarly, numerous applications and tools work in and integrate with Azure. For example, an integration between ScaleOut Software’s Digital Twin Streaming Service, an in-memory computing platform running on Microsoft Azure, and Azure Digital Twins service provides real-time streaming analytics for digital twins.
A final word
The promise of the industrial metaverse is being realized through partnerships like the ones between Microsoft and NVIDIA. Together they are making it possible for developers and companies to design, build, operate and optimize industrial metaverse applications such as digital twins at scale.
Such an industrial metaverse allows real-time, trustworthy decisions in both the physical and digital worlds. And it allows users to create creative environments for rich, immersive simulations to optimize processes and improve operational productivity.
Learn more about HPC and AI infrastructure from Microsoft and NVIDIA.
Esperanto Works to Fill the Software Gap for RISC-V AI Servers April 21, 2023 by Agam Shah
Esperanto Technologies is working to accelerate software support for its novel, high-performance AI chips. The company has ported a large-language model (LLM) from Meta to its RISC-V-based ET-SoC-1, which includes 1,088 cores. This gives researchers the option to evaluate powerful LLMs on servers that are not based on x86 or Arm architectures.
RISC-V is an emerging architecture that can be licensed for free and which is noted for its ground-up design and minimalist approach. Apple and Nvidia include RISC-V controllers in their chips, and Qualcomm has talked about the architecture’s promise for mobile chips. Intel has helped create computing boards based on RISC-V, though recently pulled financial support for the architecture as part of its cost-cutting effort. RISC-V cores are popular in microcontroller applications, where it is eroding the market share of aging Arm-based designs. Esperanto is among a handful of companies trying to push RISC-V into the high-performance computing space. The company was founded by Dave Ditzel, who previously founded Transmeta.
But RISC-V is facing an uphill battle moving up to performance applications such as PCs and servers, as a lack of software support has limited adoption. Getting the hardware is easy, but building the software and data around the hardware is a challenge, explained Roger Kay, principal analyst at Endpoint Technology Associates.
Now, Esperanto is working to fill that software gap with its homegrown AI tools.
The ET-SoC-1 silicon. Image courtesy of Dave Ditzel/Esperanto Technologies.
The company has ported Meta’s Open Pre-Trained Transformer model – which is considered roughly equivalent in size and performance to OpenAI’s GPT-3 – to its chips. The model is designed to run on evaluation servers with 8 or 16 ET-SoC-1 cards that can be plugged into PCIe slots, which provides acceleration from up to ~17,000 total cores.
Esperanto's software will provide customers the tools needed to try a different AI hardware product, said Jim McGregor, principal analyst at Tirias Research. The servers will be used for inferencing, and customers will get a better sense of performance and power consumption, McGregor added.
Companies backing RISC-V have marketed the architecture as a low-power option for high-performance computing applications. AI is ruled by Nvidia, and some companies may be interested in checking out the power and performance provided by RISC-V, McGregor argued.
The experimental AI servers include dual Intel Xeon host processors, though further specifics were not available. Esperanto did not respond to requests to talk to company representatives about the hardware and software. The servers will run all standard industrial AI models, and customers will have the "ability to bring their own models and data," the company said in a statement.
RISC-V is still many years away from being a viable alternative at scale to x86 or Arm in supercomputing or AI. Intel has reiterated that it will provide the ability to build RISC-V CPUs alongside GPUs in its chiplet designs, but that's quite a ways away. The European Processor Initiative (EPI) is funneling money to develop RISC-V chips through research centers like the Barcelona Supercomputing Centre (BSC). But SiPearl, which is building supercomputing chips for Europe’s first exascale supercomputers, says RISC-V isn’t ready for primetime.
Small chip companies are dropping like flies amid the funding crunch and a challenging economic environment, and are taking extra steps to make their chips attractive to hyperscalers and customers, McGregor said.
AI accelerators typically have matrix multipliers, and the ET-SoC-1 has vector and tensor instructors for AI. "The ET-SoC-1 chip is designed to compute at peak rates between 100 and 200 TOPS and to be able to run ML recommendation workloads while consuming less than 20 W of power," the company said in a slide deck presented at Hot Chips 33.
Intel’s TDX Goes Through the Grind Ahead of Mass Release to Cloud April 25, 2023 by Agam Shah
Cloud providers are stress-testing Intel's confidential computing technology in its Sapphire Rapids chips before putting it in cloud services. Microsoft said it was previewing Intel's Trusted Domain Extensions (TDX) technology in its DCesv5-series and ECesv5-series virtual machine offerings, the company announced in a blog entry on Monday.
Separately, Google announced it worked with Intel to strengthen TDX by closing security vulnerabilities. Given TDX is meant to thwart data theft and attacks, researchers from Intel and Google tested various attack models that included malicious hardware and code, as well as attacks from previous vulnerabilities such as Spectre and Meltdown.
Google identified defects and weaknesses that were remediated by Intel, and the company said it was confident in TDX. "A secondary goal was to have a better understanding of the expected threat model for Intel TDX and identify limitations in the design and implementation that would better inform Google's deployment decisions," Google researchers said in a blog entry published on Monday.
What is TDX?
With confidential computing emerging as an important security mechanism for AI, Intel's TDX technology is intended to protect and authenticate data as it moves from storage into the processing phase. This ensures that data is not exposed to hackers in transit or during execution. TDX provides the hooks to encrypt and lock down data in secure vaults. Recipients need specific keys to unlock the data; if the keys don't match, or if code changes are detected, access is locked out.
Xeon chips already have security safeguards in the form of technologies like SGX, but TDX is more relevant to cloud computing, where companies rent hardware instead of owning it. Some customers have private clouds to secure data and are concerned about theft once the data is released to public clouds. TDX makes sure data is secure at all points in the cloud. Microsoft's VMs provide a trusted execution environment, which is invisible to the hypervisor.
Intel's Sapphire Rapids chip. Image courtesy of Intel.
Availability
TDX is a new feature in the 4th Gen Xeon chips, codenamed Sapphire Rapids, which became available in January. But through Microsoft's preview and Google’s testing, the technology is being put through its paces before making it is made widely available on the cloud.
"Intel TDX helps assure workload integrity and confidentiality by mitigating a wide range of software and hardware attacks, including intrusion or inspection by software running in other VMs," Microsoft said in its blog entry.
Microsoft benchmarked its TDX-powered DCesv5-series VM versus a D16sv5 general-purpose VM, but found no difference in the price-performance ratio. However, It is worth noting that the TDX-powered VM is powered by Sapphire Rapids chips, and it is being compared to a general-purpose VM powered by prior-gen Ice Lake chips. This is not an apples-to-apples comparison, and Intel executives have acknowledged that security features like TDX could slow down performance on Sapphire Rapids.
In the blog entry, Microsoft also indicated it would support Intel's Project Amber, which is the chip maker's independent attestation service for organizations to verify trust in several areas from edge to cloud. The project's goal is to establish a trust boundary to maintain the integrity of data moving along a wide network.
Use cases and similar solutions
The new virtual machines were announced the same week at the RSA Security Conference, which is currently being held in San Francisco. Many panels and keynotes at the show are focused on healthcare and finance, which are heavily regulated around security and data privacy. This, in turn, ties back in to use cases for TDX. For example, TDX could help banks authenticate datasets on borrowing or purchasing patterns before integration into proprietary learning models. The security measures could also help banks bring in third-party data sets to improve the learning models.
Microsoft already supports its homegrown Azure Attestation, which is available for free and uses technologies like Intel's SGX. Azure Attestation is also the foundation for Microsoft's efforts to move Windows to the cloud with Windows 365, and the attestation technology is being constructed so only authorized users can log into the cloud-based OS.
Mark Russinovich, the chief technology officer of Microsoft Azure, has been an outspoken proponent of confidential computing, and has driven chip makers to pay more attention to the technology. Microsoft was an early adopter of AMD's SEV-SNP technology, which encrypts data and also uses attestation to authenticate data and its trustworthiness. The SEV-SNP was an early iteration of confidential computing before the technology even gained attention.
Last year, Microsoft and Google threw their weight behind Open Compute Project's specification called Caliptra, which is a confidential computing technology that establishes a hardware root of trust by baking a secure kernel directly into silicon.
Nvidia’s AI Safety Tool Protects Against Bot Hallucinations April 25, 2023 by Agam Shah
Early large-language models have proven to be triple-threat AIs – Bing and ChatGPT are entertaining, and can generate artificial love, hate, and even dance.
But in the process of testing large-language models, one thing became obvious very quickly: AI models can make up stuff, and conversations can veer off track easily.
The risk posed by the LLMs prompted IT leaders, including Elon Musk and Steve Wozniak, to issue a letter to halt the giant AI experiments.
The propensity for chatbots to hallucinate is a problem that OpenAI, Microsoft, and Google are trying to solve. The fundamental effort is around building a mechanism so artificial intelligence systems can be trusted, and to try and drive down the rate at which an AI goes off on a tangent and creates illusions.
But Nvidia on Tuesday took a practical approach to the problem by releasing a programmable tool that can act as an intermediary so large-language models stay on track and provide relevant answers to queries.
The open-source tool, called NeMo Guardrails, monitors the conversation between a user and the LLM, and that helps keep the conversation on track.
"It tracks the state of the conversation – who said what, what are we talking about now, what were we talking about before – and it provides a programmable way for developers to implement guardrails," said Jonathan Cohen, vice president of applied research at Nvidia, in a press briefing.
The guardrails can act as a form of enforcement so conversations remain within the context of the topic. The tool quickly implements AI safety rules for organizations looking to save time and extract more productivity from AI systems, Cohen said.
There are no AI safety plug-in tools available in the market today, and Cohen indicated that something is better than nothing.
For example, NeMo Guardrails can be plugged into a customer service chatbot to only answer questions about a company's products, and decline conversations about competitive products. The guardrail can also steer a conversation back to the company's products.
A guardrail can be programmed to include safety response systems for fact-checking routines, and to detect and mitigate hallucinations.
The tool can also be used to detect jailbreaks when automating coding, which helps safely execute code. For example, it can check if an API conforms to a company's security model. "We can place it on an allow list and allow an LLM to only interact with APIs on this list," Cohen said.
Enforcing guardrails is especially important in specialized domains such as finance or health care, which is highly regulated. A guardrail can include code to recognize contextual queries – for example, it can tell users something like “I am a healthcare chatbot, but this is not a healthcare question. Please reframe your question.”
The tool is being released on the Github repository, and will be available with Nvidia's software offerings.
"We think that the problem of AI safety and guardrails is one that the community needs to work on together and so we've decided to make our tool kit open source. It is designed to interoperate with all tool kits and all major language models today," Cohen said.
NeMo Guardrails sits in between humans and large-language models. Once the user submits a query at the prompt, it goes through the guardrail, which checks it for context. The query is then passed on to open-source tools such as LangChain, which is used to develop applications that harness the capability of language models.
After the LLM generates a response, it goes back to LangChain, and is evaluated by NeMo Guardrails before presenting the answer to a user. If the response is not good, the guardrail can send it back to the original LLM or a different large-language model to regenerate an answer. The response needs to pass the guardrail’s checks before it can be presented to a user.
"The reason we made it a programmable system is precisely so that you have total control over what this logic is," Cohen told EnterpriseAI.
The toolkit is a complete system that is available in Github, which includes the runtime and APIs to run it. Nvidia has developed a programming tool called Colang that controls the behavior of this runtime, which can be accessed through Python.
“The NeMo Guardrails system is a client Python library, you can take the library and do what you want with it,” Cohen said, later adding that “it includes inside it an interpreter for the Colang language,” Cohen said.
The Colang runtime executes on CPUs, so the NeMo Guardrails toolkit is not hamstrung by CUDA, which is Nvidia’s proprietary AI programming framework. Most of Nvidia’s CUDA codebase can execute only on the company’s GPUs.
"The hardware requirements are going to depend on the service you're calling, or if it's a language model that you're running locally. It is whatever LangChain supports, we work with automatically," Cohen said.
Nvidia's toolkit is being published as debates around AI regulation and safety heat up in Washington DC and the tech industry. There is no known standard or implementation around AI safety, and Nvidia is open-sourcing the toolkit to get the conversation going.
"There's an emerging open-source community like LangChain. It is emerging as a very popular API for interacting with all these things. That is one of the reasons we built our system on top of LangChain," Cohen said.
The fluency of tools like ChatGPT is quite stunning, but it is also a wakeup call on building resilient systems and trustworthy AI, said Kathleen Fisher, who is a director at DARPA, during Nvidia's GPU Technology Conference last month.
"You could build kind of belts and suspenders or other things on top that might catch the problems and drive the occurrence rate down… I think we are going to see really fast movement in this space and it will be interesting and terrifying at the same time," Fisher said.
Other companies are approaching AI safety differently. Microsoft previously halted hallucinatory answers by limiting the number of questions users could ask its BingGPT, which is based on OpenAI's GPT-4.
OpenAI earlier this month said GPT-4 provides 40% more accurate answers than its GPT-3.5. OpenAI is advocating better training, more data, responsible governance, and industry cooperation to help improve AI safety.
Sam Altman Debunks GPT-5 Rumors, Shifts Focus to Improving Existing Models April 26, 2023 by Jaime Hampton
Those anticipating an eventual GPT-5 release may have a long time to wait. The current trend of developing ever-larger AI models like GPT-4 may soon come to an end, according to OpenAI CEO Sam Altman.
“I think we’re at the end of the era where it’s going to be these, like, giant, giant models. We’ll make them better in other ways,” he said on a Zoom call at an MIT event earlier this month.
Scaling up these GPT language models with increasingly larger training datasets has led to an impressive array of AI language capabilities, but Altman believes that continuing to grow the models will not necessarily equate to further advancements. Some have taken this statement to mean that GPT-4 may be the final significant breakthrough to result from OpenAI’s current approach.
During the event, Altman was asked about the recent letter asking to pause AI research for six months, signed by 1,200 professionals in the AI space, that alleged the company is already training GPT-5, the presumed successor to GPT-4.
“An earlier version of the letter claimed we were training GPT-5. We are not and we won’t be for some time, so in that sense, it was sort of silly, but we are doing other things on top of GPT-4 that I think have all sorts of safety issues that are important to address and were totally left out of the letter.”
OpenAI CEO Sam Altman
Altman did not elaborate on what those other projects could be but said it will be important to focus on increasing the capabilities of the technology as it stands. While it is known that OpenAI’s previous model, GPT-3.5, was trained on 175 billion parameters, the company did not release the parameter count for GPT-4, citing concerns over sensitive proprietary information. Altman says increasing parameters should not be the goal: “I think it’s important that what we keep the focus on is rapidly increasing capability. If there’s some reason that parameter count should decrease over time, or we should have multiple models working together, each of which are smaller, we would do that. What we want to deliver to the world is the most capable and useful and safe models,” he said.
Since its release in November, the world has been enamored with ChatGPT, the chatbot enabled by OpenAI’s large language models. Tech giants like Google and Microsoft have scrambled to either incorporate ChatGPT into their own products or speed up the development of similar technology. Several startups are competing to build their own LLMs and chatbots, such as Anthropic, a company seeking to raise $5 billion for the next generation of its Claude AI assistant.
It would make sense to focus on making LLMs better in their current form, as there are valid concerns with their accuracy, bias, and safety. GPT-4’s accompanying technical paper acknowledges this: “Despite its capabilities, GPT-4 has similar limitations to earlier GPT models: it is not fully reliable (e.g., can suffer from “hallucinations”), has a limited context window, and does not learn. Care should be taken when using the outputs of GPT-4, particularly in contexts where reliability is important,” the paper states.
The GPT-4 paper also cautions again overreliance on the model’s output, something that could increase as the model’s size and power grows: “Overreliance is a failure mode that likely increases with model capability and reach. As mistakes become harder for the average human user to detect and general trust in the model grows, users are less likely to challenge or verify the model’s responses,” it says.
Overall, Altman’s shift in focus to improving LLMs over continuing to scale them mirrors the sentiment that other AI researchers have raised concerning model size in the past. Google infamously fired members of its Ethical Artificial Intelligence Team for their work on a research paper that asked, “How big is too big?” when it comes to LLMs. The paper looks at how these models are “stochastic parrots” in how they cannot assign meaning or understanding to the statistics-driven text outputs they create and examined the social and environmental risks involved with their development. The paper mentions that the larger these models grow, the harder it will be to mitigate these issues.
This article originally appeared on sister site Datanami.
A major concern with generative AI, and specifically ChatGPT, is what happens to user data from users' interactions with the AI model.
The Mar. 20 ChatGPT incident which allowed some users to see other users' chat histories only exacerbated privacy and security concerns. This event even motivated Italy to ban ChatGPT in its entirety.
Also:This new technology could blow away GPT-4 and everything like it
On Tuesday, OpenAI unveiled some changes to ChatGPT which will address privacy concerns by giving user's more control of their own data and their chat history.
Users will now be able to turn off their chat history which will prevent their data from being used to train and improve OpenAI's AI models.
The downside of turning off the chat history is that users will not be able to see previous chats in the sidebar, making it impossible to revisit past conversations.
Also: Nvidia says it can prevent chatbots from hallucinating
The new controls begin rolling out to users on Apr. 25, and can be found in ChatGPT's settings.
Even when chat history is disabled, ChatGPT will still retain new conversations for 30 days and will be used for review only in the case of abuse monitoring. After 30 days, the conversations will be permanently deleted.
OpenAI also integrated a new export option in settings that will allow users to export their ChatGPT data and, as a result, better understand what information ChatGPT is actually storing, according to the release.
Also:This AI chatbot can sum up any PDF and answer questions about it
Lastly, OpenAI shared that it is working on a new ChatGPT Business subscription for professionals who need more control to protect confidential company data and enterprises who need to manage end users.
Modern IT companies widely use virtualization due to advantages such as scalability, rational consumption of resources, and convenient backup. This article explains how Policy-Based Data Protection, a feature in NAKIVO Backup & Replication software, works, makes managing VM data protection more accessible, and outlines its benefits.
What Is Policy-Based Data Protection?
Policy-Based Data Protection is a feature that allows you to protect VMs matching policy rules. For protecting VMs by making backups, replicas, backup copies, etc., you need to create a job when using VMware backup from NAKIVO. You can add items matching the particular criteria to a job by using this feature – for example, consider adding VMs that contain “Linux” in their names that are in a powered-on state and are located in the specified storage area.
When Can It Be Used?
Companies can use Policy-Based Data Protection for dynamically changing virtual environments where VMs frequently migrate from one host to another or migrate between data stores. Here, you can delete some VMs and deploy new VMs instead of the deleted VMs, and VMs can change the networks to which they are connected. This feature is especially helpful in large environments with many VMs that need to be protected, where managing VMs manually takes a long time.
The Working Principle
Once a policy is created, all VMs that match the rules set by the policy are added to a job automatically. When some parameter is changed, you can exclude a VM added to the job and include the new matching VM not added to the job. Imagine that you have a policy with the rule for which the VMs with names starting with “Linux” must be added to a job. If a VM named LinuxUbuntu16 is renamed to Ubuntu16, the VM will be excluded from the current job. Inversely, if a VM named OpenSUSE is renamed to LinuxSUSE, such a VM would automatically be added to the job.
Similarly, if you have a policy-based job with a rule according to which the VMs located on the datasore1 must be added to a job, then VMs located on other data stores will not be added to the job. If a VM located on the datastore1 is migrated to another datastore, then such VM will be excluded from the current job. Inversely, the VMs migrated to the datastore1 will be added to the job automatically.
You can also add multiple rules to a policy-based job. The maximum number of policy rules per job is 50. The limit of max source objects (such as VMs) is 500 for each job. If this number is exceeded, then a warning message is displayed: “The maximum number of job objects has been reached.”
There are two logical (AND / OR) conditions that you can use when you add multiple rules to a policy-based job.
If you need all rules to be matched, select the AND condition. This includes items to a job if all rules are matched.
If you require matching of a particular rule, select the OR condition. This includes items if any one rule is matched.
For example, you can create a policy with two rules to add VMs that contain names that start with “Linux” AND are located on the datastore1. Another case is developing a policy with two rules to add VMs that contain names that start with Linux OR which names start with FreeBSD for creating a job that would be used for Linux and FreeBSD virtual machines (the VMs must be named accordingly).
The inventory must be refreshed before changes in your virtual environment can be noticed by the product. The default auto-refresh interval is 60 minutes. The minimal available inventory refresh interval is 5 minutes.
A new policy view is available on the first step of a new job wizard and on the first step of editing job options. You can enable the policy view in the dropdown menu, where you can also select Hosts & Clusters or VMs & Templates view modes. Switching to a different view will reset your current selection. When you select the policy view, you can select a condition, a rule, a search option, and search criteria. Let’s explore search options and search criteria deeper.
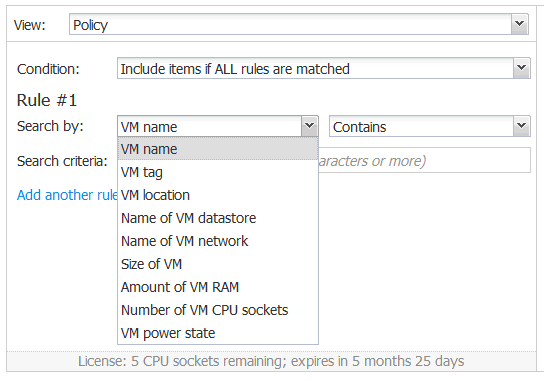
Search Options
Nine search options are available for VMware jobs, eight for Hyper-V jobs, and eight for Amazon EC2 jobs (see the table below). Each search option includes some criteria consisting of at least three characters. Select a search option from the “Search by” dropdown menu.
Let’s review the policy job search options on an example of VMware jobs.
VM Name
The VM name search option is the first option on the list. Six parameters are available for this option.
Contains (is selected by default). The names of VMs contain the characters defined as the search criteria. For example, if you type ubuntu16 in the search criteria field, the VMs like these would be added to the job: full_ubuntu16, Ubuntu16.04, Xubuntu16, Xubuntu16-master. Search criteria for “Contains” and “Doesn’t contain” options are not case-sensitive.
Doesn’t contain. Adds the VMs whose names do not contain the string defined as the search criteria. For example, you may need to add source VMs, but not VM replicas to a job. Enter replica in the text field of the “Doesn’t contain” search criteria (If you use NAKIVO Backup & Replication, the -replica string is appended to the names of VM replicas by default).
Equals. You must enter the exact Name of the VM that will be added to a job. The search criteria for this option are case-sensitive. If there is a VM named Xubuntu16 in your inventory, entering Xubuntu or Xubuntu16 in the search criteria field won’t add the Xubuntu16 VM to the job. You must manually enter Xubuntu16 in this case because all characters must match.
Doesn’t equal. The exact Name of the VM must be entered manually as the search criteria if you would like to prevent adding a particular VM to the job. For example, to avoid adding a VM named Win7-replica, you should enter Win7-replica in the search criteria text field. Entering -replica or win7-replica will not work in this case.
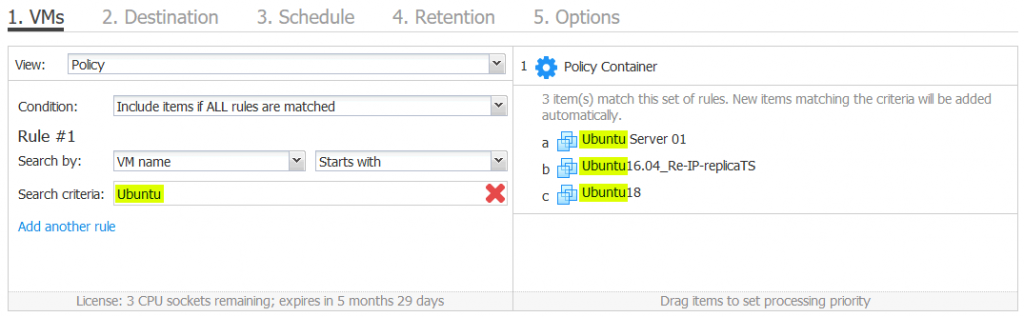
Starts with. This option is useful when you add VMs whose names start with the string defined as the search criteria. For example, if you enter Ubuntu in the search criteria text field, the VMs named Ubuntu Server 01, Ubuntu16.04, and Ubuntu18 will be added to a job. The VMs named full_ubuntu16 and Xubuntu16 will not be added to the job in this case. Search criteria for “Starts with” and “Ends with” options are case-sensitive.
Ends with. Adds the VMs whose names end with the string defined as search criteria. For example, if you want to add VMs with Linux operating systems of the Ubuntu 16 family (Ubuntu, Kubuntu, Xubuntu), you may enter u16 in the text field of the search criteria. As a result, VMs named a_ubu16, full_ubuntu16, and Xubuntu16 will be added to the job.
VM Tag
Tags allow you to attach metadata to VMs and other objects of your virtual infrastructure, such as ESXi hosts, data centers, clusters, etc., and sort tags by categories. More than one tag can be assigned to a VM. Using tags helps select VMs located on specific ESXi hosts with a common purpose. You may assign VM tags to VMs without signs of their purpose in the VM names. Below you can see an example of creating tags for virtual machines:
Dev, Test, Prod – tags for VMs categorized by operation type.
Linux, Windows, FreeBSD, Solaris – tags for VMs categorized by the operating system type.
Backed up VMs, Replicated VMs, non-protected VMs – tags for VMs categorized by their protection level.
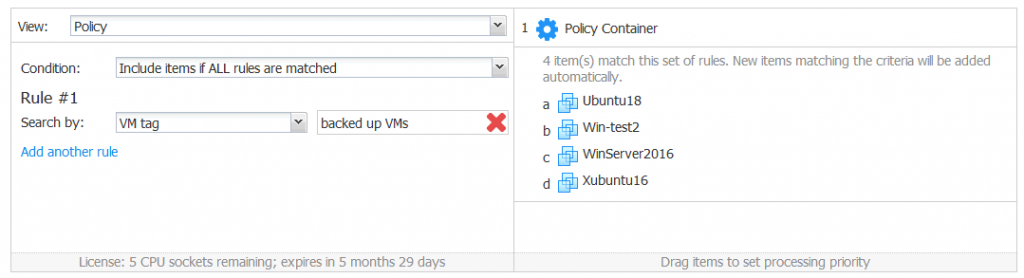
The VM tag option allows you to add VMs with the appropriate VM tag to the policy-based job. Let’s imagine that users of some departments assign the “backed up VMs” tag to VMs that must be backed up. The tag is assigned to a VM when users create VMs or when VMs’ importance status is changed. The system administrator may not know whether a new VM of that department must be backed up, but he or she can create a policy-based backup job with NAKIVO Backup & Replication to automatically gather all VMs from that department (a datacenter in vSphere can use the Name of the department) that have the “backed up VMs” tag to a single backup job.
Search criteria for the “VM tag” option are not case-sensitive. The VM tag is not available for Hyper-V.
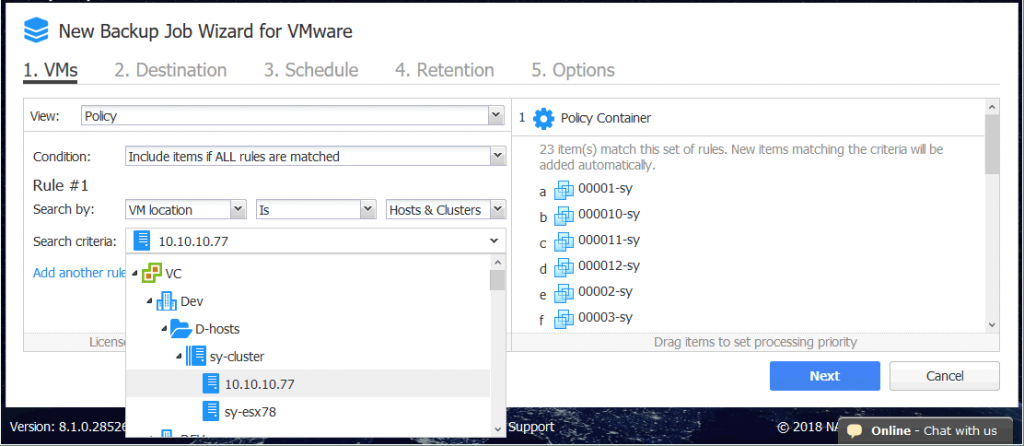
VM Location
Search by VM location allows you to add VMs located in the same data center, VM folder, host, or cluster to a job. VM location must be selected from the drop-down menu where VMware, Hyper-V, or EC2 objects are displayed.
The logic of this rule has two options and is the following:
If the VM location is the defined parameter, VMs that meet the condition are added to the job.
If the VM location is not the defined parameter, then VMs not located in the specified object are added to the job.
For VMware jobs, you can switch between Host & Clusters and VMs & Templates modes if you use the policy view when configuring a job. A rule that uses the VM location policy option can be helpful with other rules.
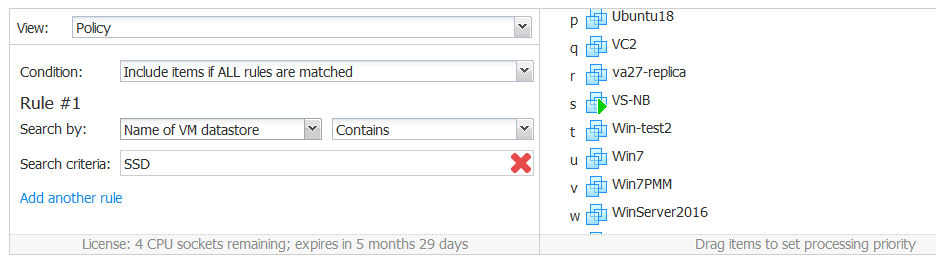
Name of VM Datastore
This option allows you to select VMs that are located or not located on the data stores specified by the policy.
These are the following search parameters for searching VMs by the Name of VM datastore:
Contains
Doesn’t contain
Equals
Doesn’t equal
Starts with
Ends with
The logic of using these parameters is similar to the logic of using said parameters for the VM name option. The difference is that the search criteria are used for specifying the datastore Name instead of VM name. VMs located on multiple data stores can be selected by using the Name of datastore policy option. This option is not available for Amazon EC2 jobs.
Example. Imagine that you have three ESXi hosts – ESXi1, ESXi2 and ESXi3. Each host has two data stores that are named according to the host names and disk types. The datastores’ names are ESXi1-HDD, ESXi1-SSD, ESXi2-HDD, ESXi2-SSD, ESXi3-HDD, ESXi3-SSD. You have a free hour for lunch and should schedule a backup of VMs located on SSD datastores for all hosts between 1:00 and 2:00 PM. Backing up VMs located on HDD-based data stores requires more time (due to the larger amount of data stored on HDD-based datastores) and, for this reason, you want to backup that VMs at night during non-working hours. You should create two policy-based backup jobs.
Job1. Rule1. Search by the Name of VM datastores that contains the SSD string in the text field of the search criteria. Schedule starting the job at 1:00 PM and ending at 2:00 PM for working days.
Job2. Rule1. Search by the Name of VM datastores containing the HDD string in the search criteria text field. Schedule starting the job at 8:00 PM for working days.
Name of VM Network
With this policy option, you can select all VMs connected to virtual networks specified by the policy.
Search parameters are the same as the search parameters of the Name of VM datastore policy option:
Contains
Doesn’t contain
Equals
Doesn’t equal
Starts with
Ends with
Logics of using these search parameters are also similar. Let’s explain an example of when this policy option can be used.
Example. A VM can have multiple virtual network adapters, each of which can be connected to a different network. A VM can be connected to the internal and external networks, to the test or production network. Imagine that you want to back up VMs connected to the production network named VM Network 2 (the VMs are running on different ESXi hosts). To make this, you need to create a policy-based backup job and add a rule that can search by the Name of the VM network that equals VM Network 2.
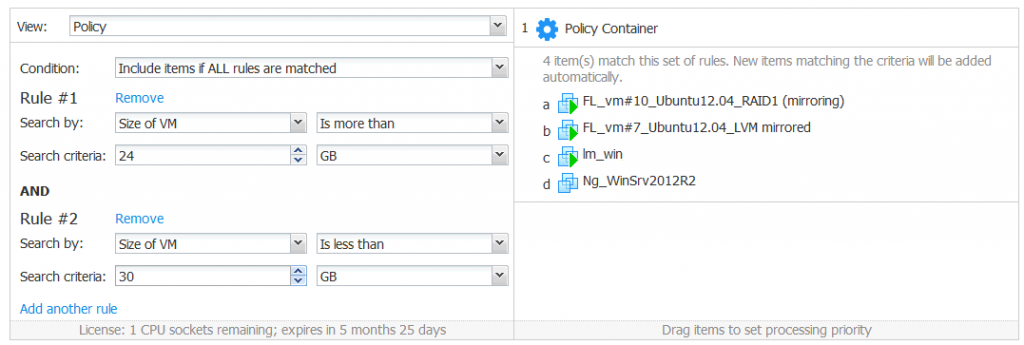
Size of VM
This policy option allows you to search VMs by the size of a particular VM if the size of the VM:
Is more than [search criteria] [units]
Is less than [search criteria] [units]
Equals [search criteria] [units]
Does not equal [search criteria] [units]
The search criteria must be only digital (at least one digit). Units can be Megabytes (MB), Gigabytes (GB), and Terabytes (TB) and can be selected from the dropdown menu.
The size of the VM policy option can be helpful for replication. You should replicate small VMs to the small data stores on ESXi servers and large VMs to large data stores. For example, you should replicate VMs whose size is less than 4 GB to the datastore1, whose size is 1 TB, while the VMs whose size is more than 4 GB would be replicated to the 10TB datastore2. You may also need to select VMs that, for example, consume more than 24 GB and less than 30 GB of disk space.
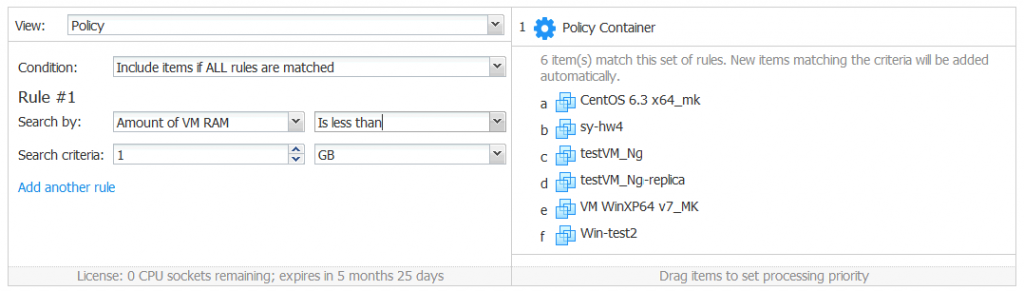
Amount of VM RAM
This policy option allows you to add the VMs with the appropriate amount of VM memory to a job. VMs are added to the job if the amount of VM RAM:
Is more than [search criteria] [units]
Is less than [search criteria] [units]
Equals [search criteria] [units]
Does not equal [search criteria] [units]
You must enter at least one digit in the search criteria field. Units can be MB or GB and can be selected from the dropdown menu.
The amount of VM RAM policy option can be helpful for replication jobs. For example, you have limited RAM on an ESXi host deployed on a disaster recovery site. This host doesn’t have enough memory to run memory-hungry VM replicas after a failover. You can create a policy-based replication job and replicate VMs whose VM RAM is less than 4 GB to that ESXi host. VMs that consume more RAM can be replicated to another powerful ESXi host with another policy-based replication job.
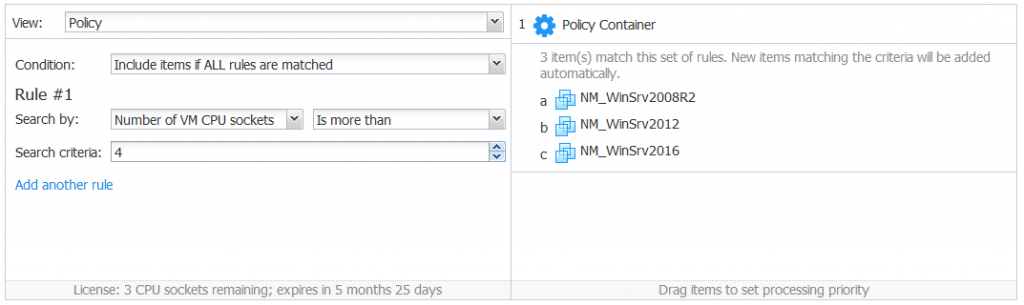
Number of VM CPU Sockets
This policy option allows you to add the VMs with the appropriate number of CPU sockets to a job. VMs are added to the job if the number of VM CPU sockets:
Is more than [search criteria]
Is less than [search criteria]
Equals [search criteria]
Does not equal [search criteria]
The search criteria is the number that must consist of at least one digit.
The Number of VM CPU sockets policy option can be helpful in replication jobs, similar to the Amount of VM RAM policy option.
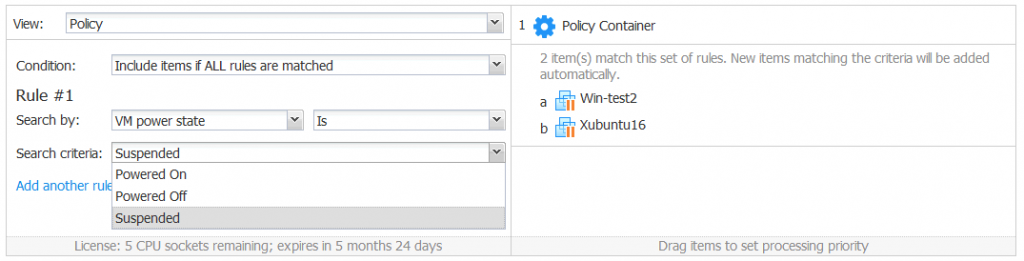
VM Power State
By using this policy option, you can add VMs to a job depending on their power state that is (or is not):
Powered On (Running)
Powered Off (Off/Stopped)
Suspended (Saved)
Let’s see the use cases.
Example 1. Imagine that you want to back up VMs with the enabled VMware Changed Block Tracking feature. VMware Changed Block Tracking can be used only for backing up (replicating) the VMs that are in the Powered On state. In this case, you can create a policy-based job to automatically add the powered-on VMs to the job.
Example 2. You need to back up VMs with some applications that are not supported by application-aware VM backup. Hence, VMs with such applications should be powered off to ensure data and application consistency. In this case, you can create a policy-based VM backup job and configure the automatical adding the powered-off VMs to that job.
Configuration Examples with Multiple Rules
You can create different combinations of rules in policy-based jobs. Let’s see some examples of policies with multiple rules for VMware VMs.
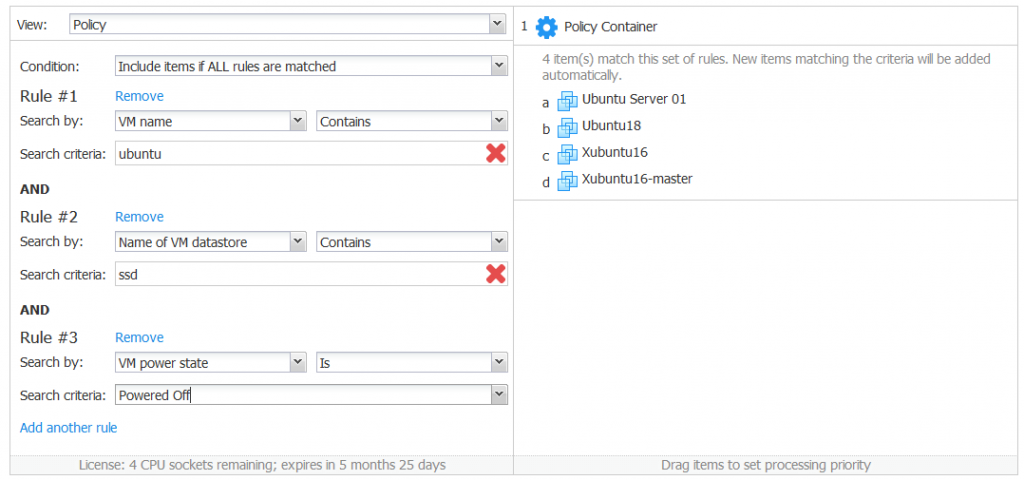
Example 1. You need to back up Ubuntu-like Linux VMs that are stored on SSD datastores and are powered off. You know that the names of your VMs contain the Name of the OS and that the names of your data stores contain the disk type. Create a policy-based VMware backup job, select the Include items if ALL rules are matched condition, and add three rules.
Rule 1. Search by: VM name contains Ubuntu.
Rule 2. Search by: Name of VM datastore contains ssd.
Rule 3. Search by: VM power state is Powered Off.
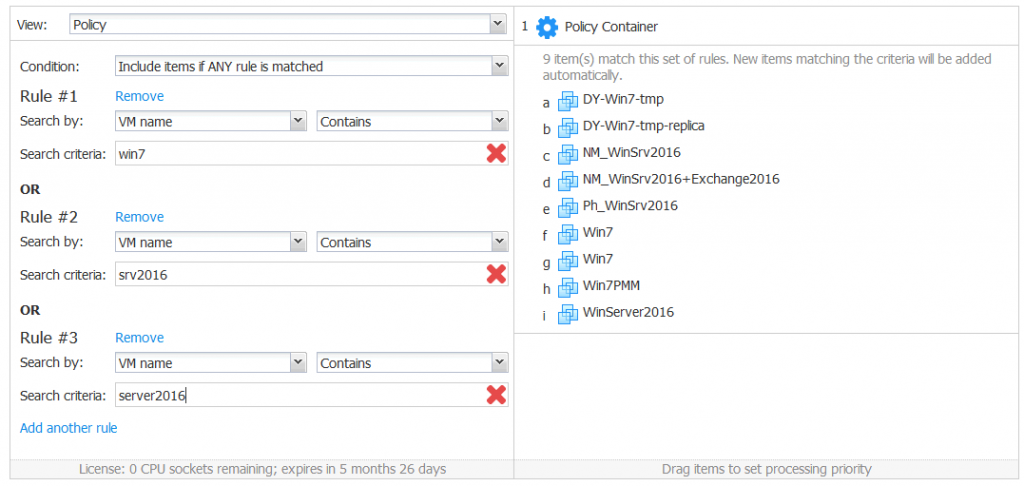
Example 2. You need to back up all VMs with Windows 7 and Windows Server 2016 operating systems installed. You know that the names of your VMs contain a part of the OS name. Create a policy-based VMware backup job, select the Include items if ANY rule is matched condition, and add rules as follows.
Rule 1. Search by: VM name contains win7.
Rule 2. Search by: VM name contains srv2016.
Rule 3. Search by: VM name contains server2016.
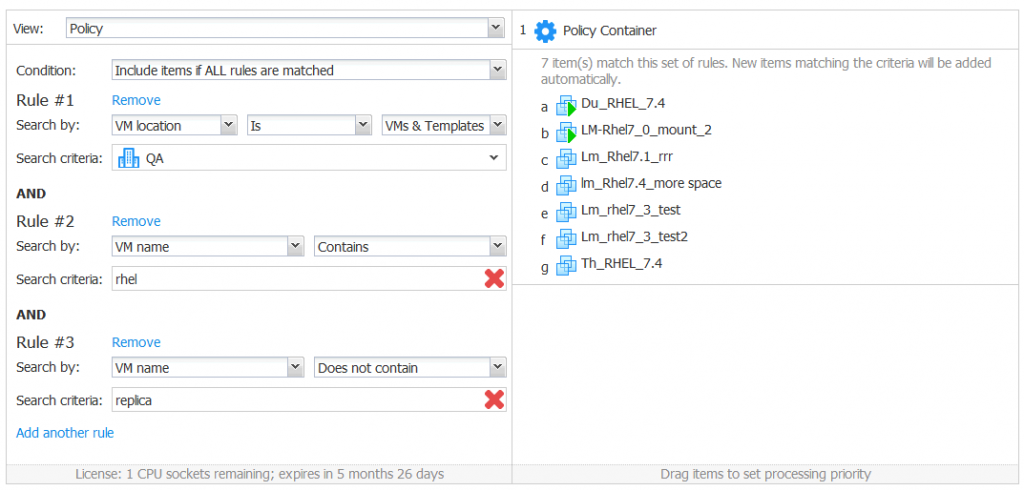
Example 3. You need to back up VMs from the QA data center with Red Hat Enterprise Linux installed (you know that VMs contain RHEL in their names). Create a policy-based VMware backup job, select the Include items if ALL rules are matched condition, and add rules as follows.
Rule 1. Search by: VM location is [VM & Templates] QA.
Rule 2. Search by: VM name contains rhel.
Rule 3. Search by: VM name does not contain replica.
Advantages of Using Policies
As you can see, policy-based data protection provides more possibilities for configuring jobs in NAKIVO Backup & Replication. The main advantages of using policy-based jobs are:
Time-saving. Manual VM management is time-consuming for large virtual infrastructures. Manual searching of the VMs for adding them to a job requires significant human attention and time. Policies allow you to simplify configuring VM protection jobs. You can save time when you need to add multiple objects that have different locations but have some common criteria, such as a VM name, datastore Name, hostname, power state, size of VM, etc.
Automation. Some items may go unnoticed and, as a result, can be missed when they are added manually. You can avoid adding VMs to a job manually since, with policies, you can set conditions and search criteria for adding the matching items to the job automatically.
Flexibility. You can use different approaches that are suitable for an environment that is dynamically changing for adding items to a job. When new VMs are frequently added, you don’t need to manually update the existing job; just wait for inventory updates, and matching items will be added automatically.
Conclusion
Policy-Based Data Protection is a valuable feature that is now available in NAKIVO Backup & Replication 8.1 and can be used for VMware, Hyper-V, and Amazon EC2 data protection jobs. This feature is handy for large, dynamically changing environments, providing greater simplicity, flexibility, time-saving, and automation. The policy view can be selected on the first step of configuring a job. In combination with other great features provided by NAKIVO Backup & Replication, you get a powerful all-in-one data protection solution for your virtualized or cloud environment.





 During the show, Google gives the example of one of its AI models that seemed to learn Bengali, a language spoken in Bangladesh, all on its own after little prompting: “We discovered that with very few amounts of prompting in Bengali, it can now translate all of Bengali. So now, all of a sudden, we now have a research effort where we’re now trying to get to a thousand languages,” said Manyika in the segment.
During the show, Google gives the example of one of its AI models that seemed to learn Bengali, a language spoken in Bangladesh, all on its own after little prompting: “We discovered that with very few amounts of prompting in Bengali, it can now translate all of Bengali. So now, all of a sudden, we now have a research effort where we’re now trying to get to a thousand languages,” said Manyika in the segment.







 A GTC keynote demo presented by Accenture showed how the integration of NVIDIA Omniverse with Microsoft Teams could be used to enable real-time 3D collaboration. Running on Omniverse Cloud and leveraging a Teams Meeting featuring Live Share, the Accenture demo showcased how the integration can shorten the time between decision-making, action, and feedback.
A GTC keynote demo presented by Accenture showed how the integration of NVIDIA Omniverse with Microsoft Teams could be used to enable real-time 3D collaboration. Running on Omniverse Cloud and leveraging a Teams Meeting featuring Live Share, the Accenture demo showcased how the integration can shorten the time between decision-making, action, and feedback.








 The GPT-4 paper also cautions again overreliance on the model’s output, something that could increase as the model’s size and power grows: “Overreliance is a failure mode that likely increases with model capability and reach. As mistakes become harder for the average human user to detect and general trust in the model grows, users are less likely to challenge or verify the model’s responses,” it says.
The GPT-4 paper also cautions again overreliance on the model’s output, something that could increase as the model’s size and power grows: “Overreliance is a failure mode that likely increases with model capability and reach. As mistakes become harder for the average human user to detect and general trust in the model grows, users are less likely to challenge or verify the model’s responses,” it says.