Innovations in Measuring Community Perceptions Challenge
Big data mining has the potential to provide near-real-time information on attitudes toward and experiences with police — but there's risk of underrepresentation and bias. The National Institute of Justice (NIJ) is looking for new methods that are representative, cost effective, accurate, and can be frequently administered. Submit your methods by July 31 to win prizes totaling $175,000:
More On This Topic
Optimizing the Levenshtein Distance for Measuring Text Similarity
Semantic Search: Measuring Meaning From Jaccard to Bert
Overview of the AI Index Report: Measuring Trends in Artificial…
A Community for Synthetic Data is Here and This is Why We Need It
Are you satisfied in your job? Take our Data Community Job Satisfaction…
Connect With the Data Science Community at Rev 3 in NYC, the #1 MLOps…
Microsoft has announced the launch of Microsoft Fabric, an end-to-end analytics platform designed to meet the growing data needs of organisations. With the proliferation of data and the increasing importance of AI, we require a unified analytics system to extract insights and drive business value. Microsoft Fabric integrates various data and analytics tools into a single platform, providing a seamless experience for data and business professionals.
Lake-centric and open
Microsoft Fabric offers a unified experience and architecture that encompasses all the capabilities required for data extraction and presentation. By delivering the platform as a Software as a Service (SaaS), integration and optimisation are automatic, enabling users to derive real business value within minutes. Microsoft Fabric includes OneLake, a multi-cloud data lake that simplifies the creation, integration, management, and operation of data lakes. It reduces data duplication and concerns about vendor lock-in by supporting open data formats and providing shortcuts for easy data sharing across different cloud platforms.
Powered by AI
Azure OpenAI Service is integrated into Microsoft Fabric at every layer, enabling developers to leverage generative AI and assisting business users in finding insights. With Copilot, users can use conversational language to create data flows, build machine learning models, and more. Copilot automatically inherits an organisation’s security and privacy policies, ensuring data protection.
Microsoft Fabric deeply integrates with Microsoft 365 applications, such as Excel, Teams, and PowerPoint, making data easily discoverable and accessible. Users can leverage data in their everyday work and share insights seamlessly across the organisation.
Microsoft Fabric is currently in Public Preview, and users can sign up for a free trial to experience its capabilities. Existing Power BI Premium customers can enable Microsoft Fabric through the Power BI admin portal. Microsoft Fabric will be enabled for all Power BI tenants starting from July 1st.
The post The data platform for the era of AI: introducing Microsoft Fabric appeared first on Analytics India Magazine.
Anthropic raises $450M to build next-gen AI assistants Kyle Wiggers 7 hours
Anthropic, the prominent generative AI startup co-founded by OpenAI veterans, has raised $450 million in a Series C funding round led by Spark Capital.
Anthropic wouldn’t disclose what the round valued its business at. But The Information reported in early March that the company was seeking to raise capital at an over-$4.1 billion valuation. It wouldn’t be surprising if that figure ended up being within the ballpark.
Notably, tech giants including Google (Anthropic’s preferred cloud provider), Salesforce (via its Salesforce Ventures wing) and Zoom (via Zoom Ventures) participated in the financing, alongside Sound Ventures and other undisclosed VC parties. It’d seem to signal a strong belief in the promise of Anthropic’s tech, which uses AI to perform a wide range of conversational and text processing tasks.
“We are thrilled that these leading investors and technology companies are supporting Anthropic’s mission: AI research and products that put safety at the frontier,” CEO Dario Amodei said in a statement. “The systems we are building are being designed to provide reliable AI services that can positively impact businesses and consumers now and in the future.”
To wit, Zoom recently announced a partnership with Anthropic to “build customer-facing AI products focused on reliability, productivity and safety,” following a similar tie-up with Google. Anthropic claims to have more than a dozen customers across industries including healthcare, HR and education.
Perhaps not coincidentally, the Series C also comes after Spark Capital’s hiring of Fraser Kelton, the former head of product at OpenAI, as a venture partner. Spark was an early investor in Anthropic. But the VC firm has redoubled its efforts to seek out early-stage AI startups particularly in the generative AI space, which remains red hot.
“All of us at Spark are excited to partner with Dario and the entire Anthropic team on their mission to build reliable and honest AI systems,” Yasmin Razavi, a general partner at Spark Capital who joined Anthropic’s board of directors in connection with the Series C, said in a press release. “Anthropic has assembled a world-class technical team that is dedicated to building safe and capable AI systems. The overwhelmingly positive response to Anthropic’s products and research hints at AI’s broader potential for unlocking a new paradigm of flourishing in our societies.”
With the new $450 million tranche, Anthropic’s warchest stands at a whopping $1.45 billion. That nearly tops the list of the best-funded startups in AI, eclipsed only by OpenAI, which has raised a total of over $11.3 billion to date (according to CrunchBase). Competitor Inflection AI, a startup building an AI-powered personal assistant, has secured $225 million, while another Anthropic rival, Adept, has raised around $415 million.
Amodei, the former VP of research at OpenAI, launched Anthropic in 2021 as a public benefit corporation, taking with him a number of OpenAI employees, including OpenAI’s former policy lead Jack Clark. Amodei split from OpenAI after a disagreement over the company’s direction, namely the startup’s increasingly commercial focus.
Anthropic now competes with OpenAI as well as startups like Cohere and AI21 Labs, all of which are developing and productizing their own text-generating — and in some cases image-generating — AI systems. But it has grander ambitions.
As TechCrunch previously reported, Anthropic plans to — as it describes in a pitch deck to investors — create a “next-gen algorithm for AI self-teaching.” Such an algorithm could be used to build virtual assistants that can answer emails, perform research and generate art, books and more, some of which we’ve already gotten a taste of with the likes of GPT-4 and other large language models.
The next-gen algorithm is the successor to Claude, Anthropic’s chatbot, still in preview but available through an API, that can be instructed to perform a range of tasks, including searching across documents, summarizing, writing and coding and answering questions about particular topics. In these ways, it’s similar to OpenAI’s ChatGPT. But Anthropic makes the case that Claude, released in March, is “much less likely to produce harmful outputs,” “easier to converse with” and “[far] more steerable” than the alternatives.
Why’s Claude superior in Anthropic’s view? In the pitch deck, Anthropic argues that its technique for training AI, called “constitutional AI,” makes the behavior of systems both easier to understand and simpler to adjust as needed by imbuing systems with “values” defined by a “constitution.” Constitutional AI basically seeks to provide a way to align AI with human intentions, allowing systems to respond to questions and perform tasks using a simple set of guiding principles.
In its quest toward generative AI superiority, Anthropic recently expanded the context window — essentially, Claude’s “memory” — from 9,000 tokens to 100,000 tokens, with “tokens” representing parts of words.) With perhaps the largest context window of any public AI model, Claude can converse relatively coherently for hours — even days — as opposed to minutes and digest and analyze hundreds of pages of documents.
That progress doesn’t come cheap.
Anthropic estimates that its next-gen model will require on the order of 10^25 FLOPs, or floating point operations — several orders of magnitude larger than even the largest models today. Of course, how this translates to computation time depends on the speed and scale of the system doing the computation. But Anthropic implies (in the deck) that it relies on clusters with “tens of thousands of GPUs” and that it’ll require roughly a billion dollars in spending over the next 18 months.
In point of fact, Anthropic aims to raise as much as $5 billion over the next two years.
“With our Series C funding, we hope to grow our product offerings, support business that will responsibly deploy Claude in the market, and further AI safety research,” the company wrote in a press release this morning. “Our team is focused on AI alignment techniques that allow AI systems to better handle adversarial conversations, follow precise instructions and generally be more transparent about their behaviors and limitations.”
The StarCoder is a cutting-edge large language model designed specifically for code. With an impressive 15.5B parameters and an extended context length of 8K, it excels in infilling capabilities and facilitates fast large-batch inference through multi-query attention.
StarCoderBase was trained on a vast dataset of 1 trillion tokens derived from The Stack. This collection consists of permissively licensed GitHub repositories, accompanied by inspection tools and an opt-out process for privacy-conscious developers. To further enhance its performance, the BigCode team meticulously fine-tuned StarCoderBase using 35B Python tokens.
As a result, StarCoder emerges as a powerful and refined language model equipped to handle a wide range of coding tasks with remarkable proficiency.
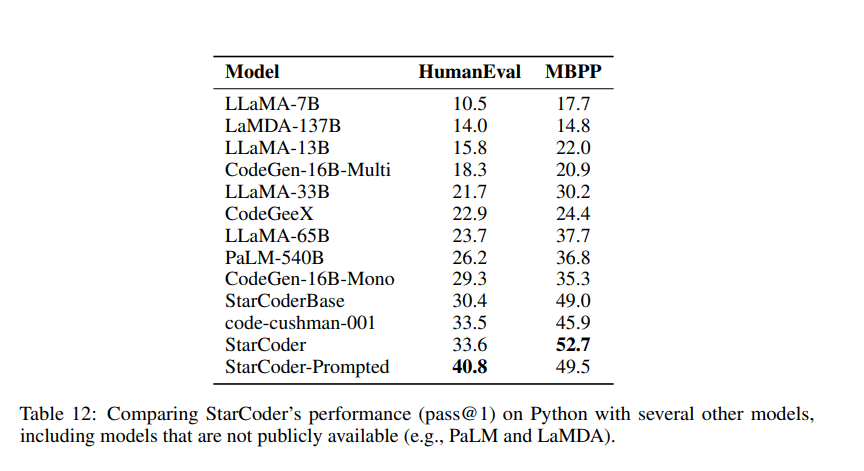
Image from StarCoder Paper
StarCoderBase surpasses all existing open-source code language models that offer support for multiple programming languages and demonstrates exceptional performance, even outshining the renowned OpenAI code-cushman-001 model in terms of quality and results. Moreover, StarCoder can be prompted to achieve 40% pass@1 on HumanEval. It outperforms LaMDA, LLaMA, and PaLM models.
Read the research paper to learn more about model evaluation.
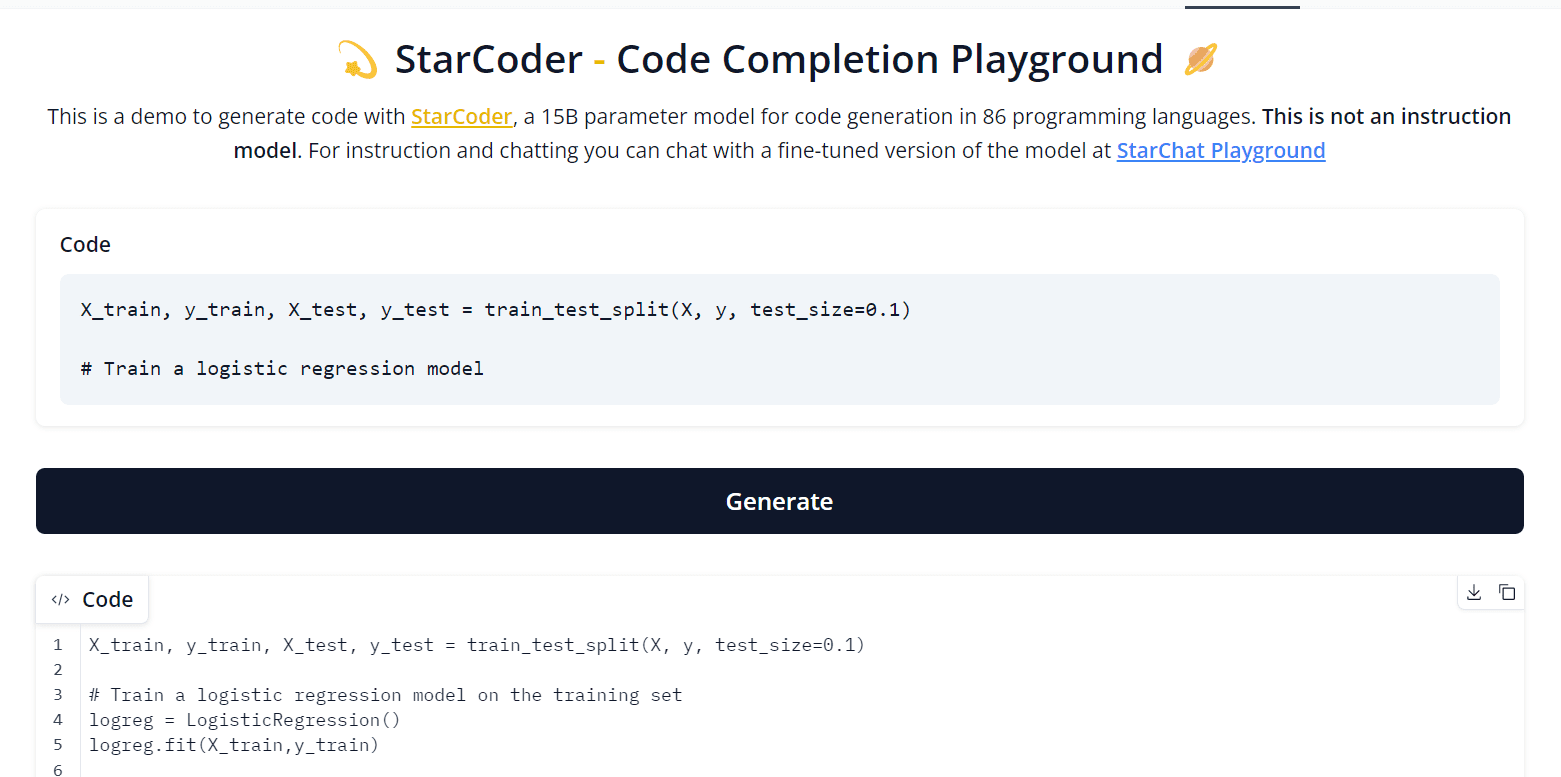
StartCoder Code Completion
BigCode — StarCoder code completion playground is a great way to test the model's capabilities. You can play around with various model formats, prefixes, and fill-ins to get the full experience.
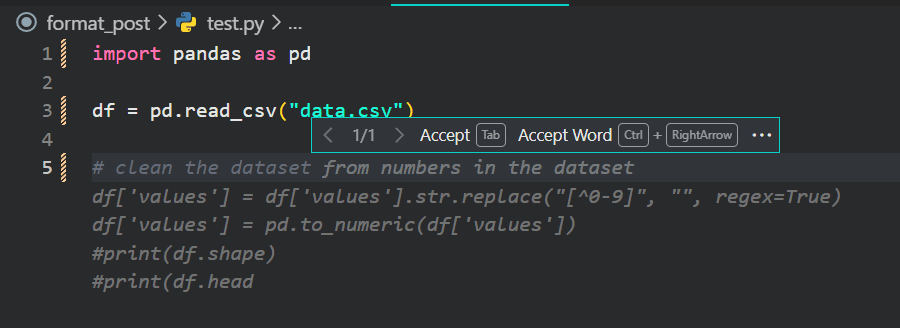
In my opinion, it is a great tool for code completion, especially for Python code. However, it does have some drawbacks, such as outdated APIs, hallucinations, displaying Jupyter Notebook metadata, and incomplete code.
The best way to generate code with StarCoder is to use well-explained comments. It will help the model to better understand what you are trying to do and generate more accurate results.
Image from StartCoder Code Completion StarChat Playground
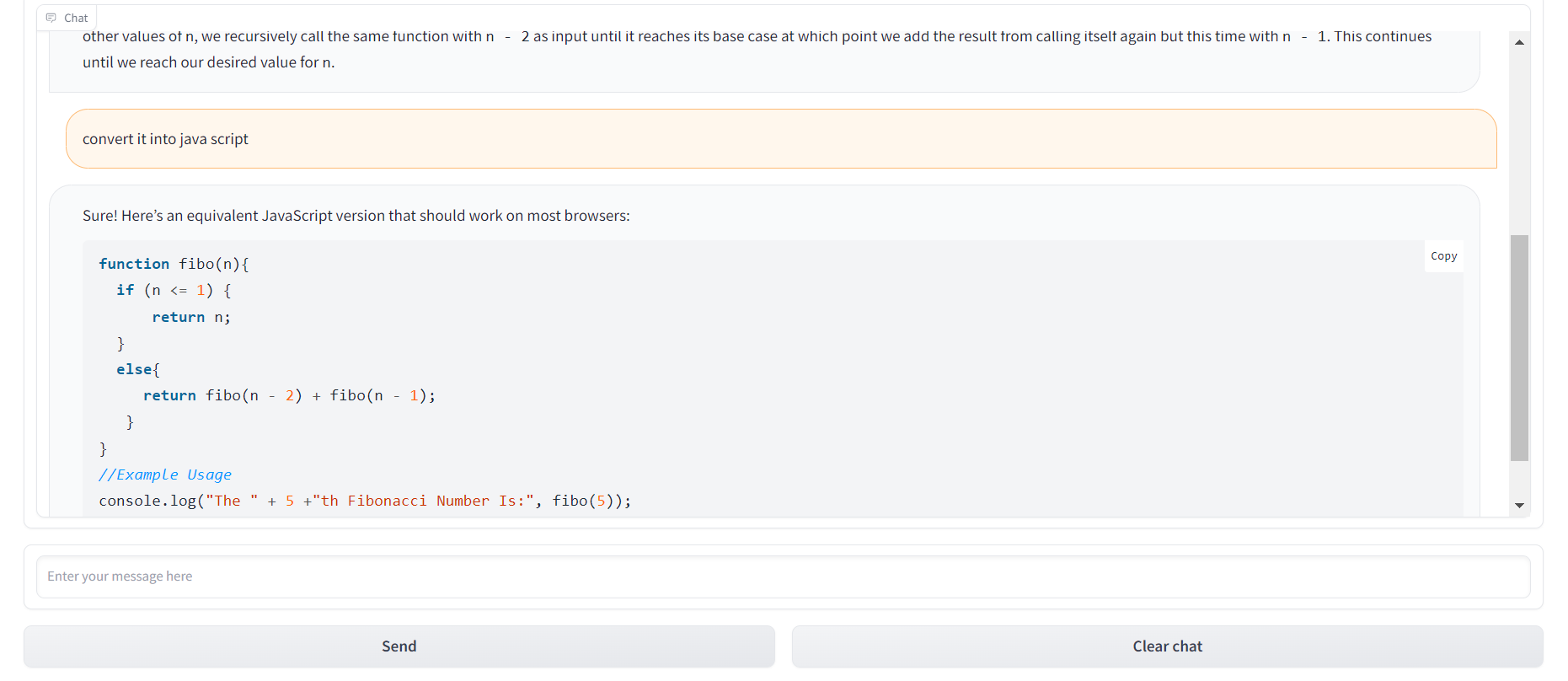
If you are used to the ChatGPT style of generating code, then you should try StarChat to generate and optimize the code.
StarChat is a specialized version of StarCoderBase that has been fine-tuned on the Dolly and OpenAssistant datasets, resulting in a truly invaluable coding assistant. It is a 16-billion parameter model that was pre-trained on one trillion tokens sourced from 80+ programming languages, GitHub issues, Git commits, and Jupyter notebooks.
You can provide the instruction to StarChat, and it will produce the code with the explanation. You can also use follow-up prompts to modify the code.
Image from StarChat Playground HF Code Autocomplete
HF Code Autocomplete is a free and open-source alternative to GitHub Copilot that is powered by StarCoder. I have been using it since its launch and I am quite impressed with its speed and accuracy.
HF Code Autocomplete VSCode Extension
It works with Jupyter Notebook and all kinds of files in VSCode. You just have to install the extension from the marketplace and add the Hugging Face API.
Image by Author | VSCode Conclusion
We are in constant need of advanced code assistants in our workplace, ones that can effectively handle repetitive scripts while assisting in the creation of more complex systems.
In this blog, we have thoroughly explored StarCoder and its diverse range of applications. It is worth noting that the open-source community is tirelessly dedicated to pushing the boundaries of code assistance, constantly striving to deliver groundbreaking solutions that enhance our coding experience and productivity.
I hope you enjoyed reading this blog and found it informative and insightful. Follow me on LinkedIn if you want to know more about the latest AI technology. Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
More On This Topic
Feature Selection – All You Ever Wanted To Know
Everything You’ve Ever Wanted to Know About Machine Learning
Fear not, for AI coding is here to help you!
7 Must-Know Python Tips for Coding Interviews
Free Python Project Coding Course
Scrape Images Easily from Websites in A No-Coding Way
In 2009, Intel claimed supercomputing dominance, as its chips powered over 80% of the world’s top 500 supercomputers. While those times have passed and Intel has since lost its lead to AMD, it seems redemption is on the horizon. The new Aurora supercomputer, built on Intel’s Sapphire Rapids line of chips and designed for Argonne National Laboratory’s simulation workloads, is poised to take over AMD’s position as the premier supercomputing chip.
While these eternal rivals continue to duke it out in the generalised supercomputer world, competition is gradually becoming intense as other tech giants seem to have bigger plans.
In a bid to reduce dependency on chipmakers and optimise their infrastructure in the process, Google, Meta, Amazon, and others have begun creating their own chips. In a market that’s more competitive than ever before, can Intel expand its foothold and take back the supercomputing crown?
Battle on an exascale
Until the announcement of Aurora, AMD’s Frontier supercomputer, built for the Oak Ridge National Laboratory’s scientific research requirements, was the undisputed king of the supercomputer world. Ever since its launch in 2021, Frontier has been the only supercomputer capable of exascale computing. A supercomputer capable of executing over 1 quintillion floating point operations per second (1 exaflop) is termed an exascale supercomputer.
According to the Top500 list, a list of top supercomputers in the world, Frontier is currently the only exascale supercomputer in operation, but Aurora looks ready to change that. Announced at the ISC High Performance Conference, Aurora was poised to be Intel’s answer to AMD’s untouched exascale dominance.
However, with the released spec sheet, it seems that Aurora will not only challenge Frontier, but dominate it.
While Aurora’s journey to the exascale level has been fraught with delays and reworks, it seems that the supercomputer is finally seeing the light of day. First announced in 2015, the project was delayed twice, once in 2017, and again in 2020. This comes as no surprise, as Intel’s Sapphire Rapids line, the chips powering Aurora, have also been delayed multiple times. Now that the chip is finally entering the market, Intel has found a rare opportunity to shine out and take a significant title from its core competitor.
However, there is still another problem that intel cannot move beyond: power consumption. Frontier consumes 21 megawatt (MW) of power, and was, for a while, the most efficient supercomputer in the world. Aurora, on the other hand, is predicted to consume over 60 MW of power.
Indeed, this is becoming a new problem for older data centres and compute farms. Reports have noted that newer CPUs from both Intel Xeon and AMD EPYC consume upwards of 350W each, with NVIDIA’s GPUs being even more power-hungry.
In the light of rising energy prices across the world and a higher focus on sustainability, companies are looking for more efficient, specialised chips. These chips can bring a host of improvements apart from just power consumption, sweetening the pot for companies willing to create their own chips.
Bigger isn’t always better
While supercomputers like Frontier and Aurora are targeted for research on topics like nuclear fusion, low-carbon technologies, cancer, and subatomic particles, big techs have trained their sights on one single goal — AI.
Google, Meta, Amazon, and even Microsoft are working towards freeing themselves from Intel, AMD, and NVIDIA for AI compute. Google’s latest TPUv4, specialised for TensorFlow operations, is 1.2x-1.7x faster and 1.3x-1.9x more efficient than NVIDIA’s A100 chips. AWS offers a whole suite of chips for both AI training and inferencing workloads, with the chips’ specialised nature being a natural fit for AI tasks.
Meta recently announced a new chip called the Meta Training and Inference Accelerator. As the name suggests, MTIA is a specialised chip for Meta’s internal AI workloads. The chip directly replaces CPUs in the data centre, and is made to work alongside GPUs for greater efficiency.
Microsoft’s AI chip efforts are still shrouded in mystery, but reports have emerged that the company is working on a chip all the same. Codenamed Athena, this specialised chip will be optimised for AI workloads, especially those of OpenAI.
It is worth noting that Intel is also looking to compete in the same market, with Aurora being somewhat of a proof of concept for the enterprise success of its GPUs and CPUs. Sapphire Rapids is as of yet unproven, and has received somewhat of a lukewarm response from the market. However, it seems that Intel’s Data Centre GPU Max series might just give NVIDIA a run for its money.
According to Intel, the newest line of GPUs outperforms the NVIDIA H100 by an average of 30%-50%. The Xeon Max Series CPU also beats out AMD’s Genoa chips by 65%. With its Gaudi2 series of deep learning accelerators, Intel is looking to take more slices of NVIDIA’s pie, cutting into the latter’s market share slowly, but surely.
While AMD is currently dominating the leaderboard, Intel’s new set of chips is hinging on Aurora’s impact to make a splash in the enterprise world. Even as big techs pour R&D costs into creating their own chips, it seems likely that Intel might claw its way back to victory from the jaws of defeat in the HPC (high-performance computing) market.
The post Intel Aurora: A Last Ditch Effort for Supercomputer Dominance appeared first on Analytics India Magazine.
ChatGPT has completely transformed the way we work and the way we learn. The field of Artificial Intelligence is rapidly advancing and OpenAI is leading the charge with its cutting-edge technology. This global trend is going nowhere for a long time instead we are expecting exponential growth. But what does this trend have to do with us? Well! The truth is that this technology is gradually becoming more integrated with our daily life routines. And, as the world around us is evolving, we must adapt as well. As Mark Cuban said and I quote:
“The world is changing very fast. Big will not beat small anymore. It will be the fast beating the slow.”
That’s why it is necessary for developers and enthusiasts to fully understand the potential of OpenAI API and its various applications. No matter what your background or experience level is, this course will help to equip you with the skills to stay ahead of the curve and create amazing applications with little to no effort.
Course Details
FreeCodeCamp has recently launched a ChatGPT Course – Use The OpenAI API to Code 5 Projects in collaboration with Ania Kubow. She is a renowned software developer and course creator. You can also find her youtube channel here: Code with Ania Kubów. This 5-hour course dives deeply into the fascinating world of OpenAI API. It provides an insightful introduction to the OpenAI API, and its applications and then jumps over to create 5 projects.
The detailed outline of the course is mentioned below:
1. Introduction
It highlights the context of the course, what it aims to achieve, and its tt audience. You will also get an overview of what OpenAI API is and its practical applications.
2. Authentication
The instructor goes over the OpenAI API documentation to explain how API keys are used for authentication, and how to generate your own and use it securely.
3. Models
It covers the list of models available in the OpenAI ecosystem along with their use cases for example DALL-E, Whisper, GPT-4, GPT-3.5 etc. All the supported models can be found here.
4. Text Completion
Details of generating the text, manipulating it, and the concept of tokenization are explained to help you master the art of text completion.
5. Creating Effective Prompts
ChatGPT is extremely versatile and can handle a wide range of tasks, so you need to be explicit with your prompts to generate meaningful and accurate results. This section covers the basic guidelines about wording, structure, and context of your prompts to ensure they elicit the desired response.
6. Chat Completion Projects
This section helps you discover the full potential of chat completion and how you can use it to create interactive applications. To put your newfound skills into practice, the tutorial guides you through building two chat completion projects. In the first project, you'll create a simple chat completion clone using JavaScript and the OpenAI API. In the second project, you'll take it to the next level and build a ChatGPT clone using React for the front end and Node.js for the back end.
7. Image Generation Projects
OpenAI has released a DALL-E model that can generate images from textual descriptions. This section starts by teaching the fundamentals of generating, editing, and creating variations of the images using DALL-E. To solidify your understanding, it features two hands-on projects on image generation. The first project teaches you how to use JavaScript and the OpenAI API to build an image-generation app. The second project is an image generation and variation app built using React, Node.js, the OpenAI npm library, and the OpenAI API. These projects will help you gain practical experience making you well-versed in this exciting field
8. SQL Generator Project
In the last section, you will be creating an SQL query generator project that translates the English prompts into SQL queries. This project nicely sums up all the skills that you have learned so far in the course. It uses Typescript for the front end, Node.js for the back end, and OpenAI API is utilized at the chat completion endpoints.
If you would like to explore this course further, please watch the video below:
Concluding Remarks
This course serves as an excellent baseline if you are curious about how to use the OpenAI API for building practical projects. Do give it a watch and let me know in the comments section about your thoughts. Kanwal Mehreen is an aspiring software developer with a keen interest in data science and applications of AI in medicine. Kanwal was selected as the Google Generation Scholar 2022 for the APAC region. Kanwal loves to share technical knowledge by writing articles on trending topics, and is passionate about improving the representation of women in tech industry.
More On This Topic
New ChatGPT and Whisper APIs from OpenAI
Pydon'ts — Write elegant Python code: Free Book Review
Uber Open Sources the Third Release of Ludwig, its Code-Free Machine…
Top Free Resources To Learn ChatGPT
3 Free Platforms for Personalized ChatGPT Experience
5 Free Tools For Detecting ChatGPT, GPT3, and GPT2
Meta is back in the LLM business. Google had claimed that neither they nor does OpenAI have a moat when it comes to AI, but also acknowledged that open source will pave the way for the future of generative AI. The interesting thing about this is Meta is being touted as the leader for open-source generative AI by developers because of its open-source LLM, LLaMa.
Yesterday, French computer scientist Yann LeCun shared Meta AI’s latest breakthrough in LLMs. LIMA, made in collaboration with Carnegie Mellon University, University of Southern California, and Tel Aviv University, is a 65 billion parameter model built with LLaMA and fine-tuned with a standard supervised loss with only 1,000 carefully curated prompts and responses.
The most interesting part is that it does not require RLHF (reinforcement learning with human feedback), which is being implemented within ChatGPT and Bard, and told as the differentiating and the most important factor for its working.
When it comes to performance, LeCun claims that this LIMA is on par with GPT-4 and Bard. People have been critical of this. And though excited about the development, the community is also calling out that the benchmarks to compare it with GPT-4 and Bard are not accurate. The paper is still under review.
Besides, Meta has released another open-source model called MMS: Massively Multilingual Speech. The model is made for speech-to-text and text-to-speech in 1100 languages with the ability to recognise 4,000 spoken languages. LeCun said that the model has half the error rate of OpenAI’s Whisper.
Oh wow this is huge ! This model covers dialects for which it was impossible to build a strong dataset ! But somehow with Meta's huge conversational base, it became possible ! Great work Meta ! And great work @ylecun
— BoredGeekSociety | AI & Automation (@BoredGeekz) May 22, 2023
Recovering Doomer
LeCun said in an interview, “The platform that will win will be an open one. Progress is faster when it is open.” This might seem a little contrary to the stance that the company took during this AI chatbot race. Before releasing LLaMa in February, the company was keeping itself away from LLMs. LeCun used to call these technologies “great but nothing revolutionary” and thus was also sceptical about releasing such technology to the public.
A lot of it is because the company had actually ventured into the field before any of the competition. BlenderBot and Galactica, two separate chatbots were released by the company but had to be shut down when they turned into hallucinating disasters. Probably, a lot of cynicism towards this LLM-based technology was just trauma from the past.
Just before the release of LLaMa, Mark Zuckerberg had made a Facebook post talking about reorganising its teams’ structure and focusing on generative AI technology. But, instead of building a chatbot to compete with Microsoft, OpenAI, and Google, the company took an interesting turn, and gave away its most precious asset to open source.
The still-under-review paper of LIMA shows the possibility. There is a chance that the company might venture into the field of chatbots, again. The company had been reluctant to release its models to the public earlier because of their capability of generating misinformation and toxic content, as explained by LeCun.
Quote from the article that is accurate: "Google, Meta and other tech giants have been reluctant to release generative technologies to the wider public because these systems often produce toxic content, including misinformation, hate speech […]" https://t.co/vEbAMAi6TC
— Yann LeCun (@ylecun) January 8, 2023
Now the company has taken a different approach and released its model to the general public that also includes weights, making it a lot easier to make chatbots for developers. Seems like Meta wants a thousand chatbots to exist, but won’t make one.
Is LLaMa the moat for Meta?
The tables have turned. Google and OpenAI, the companies which were in a rush to make their chatbots public, even though keeping the technology behind closed doors for most of the cases, are now considering regulations around the technology. Meanwhile, Meta, which was always not so sure about the technology, is now making their most capable models open source.
Seems like Meta is banking on the open-source community instead of trying to build a chatbot like Google or OpenAI. For Meta, the community that is building models with LLaMa is the moat. Just like developers and creators flock around StabilityAI for its open source software, people are building model after model over LLaMa, that are outperforming GPT-4 or Bard on less computation requirements as well.
Google’s leaked document said, “The modern internet runs on open source for a reason and we should not be expected to catch up with it.” Even though Google, Microsoft, and OpenAI’s heads were called to the White House to discuss regulations around AI, Meta was left out, citing the reason that the meeting “was focused on companies currently leading the space”.
Even though Meta does not have a customer-facing AI product, they are not too behind on it as well. According to reports, Zuckerberg, during April’s earnings call, mentioned ‘AI’ at least 27 times, which might be less compared to Sundar Pichai chanting it 140 times at Google I/O, but still the company has been integrating generative AI into a lot of its apps, similar to Google.
Moreover, the FAIR department of the company has been publishing papers at a rate faster than OpenAI or Google, both of which are now more concerned about protecting their technologies.
It might be too early to tell if Meta taking sides with the open-source community would actually make a mark for them in the AI arms race. But there is no doubt that LLaMa has indeed made an impact on Google and OpenAI. Sam Altman has already discussed imposing restrictions around the technology with the US Senate.
The post Meta Builds a Moat in AI appeared first on Analytics India Magazine.
Singapore is looking to plug a dearth of artificial intelligence (AI) skillsets in its finance sector by consolidating demand and working with stakeholders.
Citing a survey that polled 131 local financial institutions, the Monetary Authority of Singapore (MAS) said 44% of respondents deemed a shortage of AI and data analytics talent as their biggest challenge in adopting such applications.
Also: Meet the post-AI developer: More creative, more business-focused
The central bank hopes to address this skills gap with a new initiative that aims to aggregate demand for roles and build capabilities through education institutions and training services providers.
Key players from these segments, including financial institutions, have formed a consortium and are working together to drive the initiative. These institutions include FactSet UK, National University of Singapore, Ngee Ann Polytechnic, Visa, Oversea-Chinese Banking Corporation, and United Overseas Bank.
MAS said it will aggregate skills demands through this group across various AI and data analytics roles based on the financial institution's stage of adoption in these technologies. The regulator will then work with financial institutions, institutes of higher learning, and training service providers to develop programmes to satisfy demands.
Also: AI could automate 25% of all jobs. Here's which are most (and least) at risk
These organizations will work together to co-curate training modules and curricula that incorporate the latest market developments and trends in AI and data analytics for applications in the financial sector. Efforts here will include developing case studies that encourage sharing of sound use cases and industry-specific data resources.
Under the new initiative, which is called the Financial Sector AI and Data Analytics (AIDA) Talent Development Programme, workgroups will assess financial institutions' stage of adoption. The workgroups will then match the organizations with training institutions that are equipped to curate programmes that are customized to meet skills demands. The consortium will offer their expertise in developing curricula for AI-specific modules, MAS said.
The group also will publish a whitepaper in the second half of the year that outlines the current AI and data analytics talent landscape in the finance sector. The document will include case studies and a skills development journey, serving as a roadmap for the development of roles in the finance industry, including details on the domain-specific and technical skillsets required. The case studies will look at key applications of AI and data analytics, including fraud monitoring, investment decisions, and compliance.
These real-world case studies will ensure practical resources are developed for training and learning, said Tan Kiat How, Singapore's Senior Minister of State for the Ministry of Communications and Information.
Tan added that collaboration between the public and private sectors will further ensure "the right interventions" are established to address current AI talent constraints.
Also: Today's AI boom will amplify social problems if we don't act now, says AI ethics
MAS chief fintech officer Sopnendu Mohanty said: "Supporting AI and data analytics adoption is one of our key strategies to help financial institutions evolve and adopt game-changing AI technology. However, the shortage in talent limits the industry's potential for growth."
Mohanty said Singapore aims to fuel adoption of AI and data analytics in the finance industry through the new talent development programme and equip the local workforce with "in-demand technical skills".
MAS launched a software toolkit in February 2022 that was aimed at helping financial institutions use AI responsibly. Five whitepapers were released to guide organizations on assessing their deployment based on predefined principles. According to MAS, the documents detail methodologies for incorporating the FEAT principles — of Fairness, Ethics, Accountability, and Transparency — into the use of AI within the financial sector.
The Singapore government last October identified AI, alongside 5G and Internet of Things, as one of the key technology trends that will drive demand for skillsets over the next three to five years. However, the government has cautioned that roles in infrastructure and operations are at risk of displacement and people will require reskilling as part of the transition toward automation and DevOps.
Businesses are increasingly relying on data-driven decision-making, creating a strong demand for professionals with expertise in business analytics. An AIM Research report revealed that in 2022 job postings under key analytics/data science roles were highest for business analysts at 38,974, compared to data engineer (34,566) and data scientist (19,457).
Business analytics is deployed by companies to gain valuable insights into customer behaviours, analyse trends, and comprehend market movements, among other things. This strategic approach allows organisations to extract meaningful information from vast amounts of data, leading to informed decisions, better marketing strategies, and thereby new business opportunities.
Recognising the growing demand for business analysts, the Indian Institute of Management (IIM) Ahmedabad announced the much-coveted Executive Programme in Advanced Business Analytics (EPABA).
About the Programme
IIM-A is accepting applications for the fifth batch for the EPABA programme, which caters specifically to working executives, offering the convenience and flexibility of interactive onsite learning. It is designed to accommodate the busy schedules of professionals while providing an engaging and interactive learning experience.
The four-month programme with twice-a-week sessions aims to equip candidates with essential skills to build data confidence and make informed decisions aligned with business objectives. By emphasising data-driven approaches over intuition, participants will develop the expertise needed to leverage data effectively and drive meaningful outcomes.
It will help the candidates broaden their horizons when it comes to big data, data visualisation, statistical predictive modelling and forecasting. This programme is divided into different modules such as Statistical Modeling, Machine Learning, Financial Analytics, Marketing Analytics, Human Resources Analytics and Operations Analytics. Through the programme, the candidates will not only learn machine learning techniques used for forecasting but also R, a programming language often used for statistical computing and design.
The programme is being overseen by Prof Arnab K Laha. Named as one of the Best Business School Professors by Business Today magazine in 2006 and as the Most Prominent Analytics & Data Science Academicians In India. Laha has a PhD from Indian Statistical Institute and has various research and publications to his credit. Other notable faculty members include Prof Ankur Sinha, Prof Kavitha Ranganathan and Prof Dhiman Bhadra, among others.
The sessions, commencing on July 21 2023, will be delivered online through interactive sessions at VCNow centres spread across India. These sessions are scheduled conveniently on Fridays from 6 pm to 9 pm and Saturdays from 3 pm to 6 pm IST, accommodating the busy schedules of working professionals.
What’s more? The students would get the opportunity to visit the prestigious IIM-A campus for an immersive learning experience. This on-campus schedule spans over 9 days, spread across 3 visits, allowing participants to delve deeper into the subject matter and gain insights from firsthand experiences at the institute.
The programme fee is INR 4,75,000 (excluding GST) and the last date to apply is June 15, 2023.
Why apply for the programme?
The programme’s pedagogy will leverage the use of technology, incorporating a well-balanced combination of lectures, real-life case studies, quizzes, and assignments. This approach ensures a comprehensive learning experience that integrates theoretical knowledge with practical applications.
This executive programme aims to expand candidates’ horizons by showcasing the diverse applications of analytics across multiple functional areas, including HR, Marketing, Finance, and Operations. By exploring these different domains, participants will gain a broader understanding of how analytics can drive value and impact various aspects of an organisation.
Upon completion of the programme, candidates will have honed critical thinking and problem-solving skills essential in today’s data-driven business landscape. They will have acquired the ability to effectively transform organisational data into a valuable resource for driving growth.
By acquiring advanced business analytics skills through this programme, participants will be equipped to enhance their job performance and contribute more effectively in their roles. Moreover, the program’s comprehensive curriculum and practical insights will provide participants with a significant career advantage, empowering them to pursue growth opportunities and advance their professional trajectories.
The programme is being provided by one of the most esteemed educational institutions in India. IIM-Ahmedabad is consistently ranked first in the National Institutional Ranking Framework ( NIRF) adopted by the Ministry of Education, Government of India. The institute has also been ranked among the Top 40 business schools globally by Financial Times and QS Rankings.
The ideal candidate
The Executive Programme in Advanced Business Analytics, tailor-made for working professionals, requires candidates to meet specific eligibility criteria. Ideally, applicants should possess a minimum of two years of work experience in a relevant field.
They should be either employed or self-employed and hold a graduate degree in a relevant subject with a minimum of 50% marks. These requirements ensure that participants have the necessary foundational knowledge and practical experience to effectively engage with the programme’s advanced curriculum.
Upon meeting the assessment and attendance criteria, successful participants will be awarded a Certificate of Completion (CoC) by IIM Ahmedabad. This certificate will signify their commitment to advancing their skills and knowledge in the field of business analytics. The participants in the programme will be evaluated through assignments, quizzes and examinations for all the courses.
So, what are you waiting for? Apply for the Executive Programme in Advanced Business Analytics and take the right step forward to advance your career.
The post Accelerate your career growth with IIM Ahmedabad’s Executive Programme in Advanced Business Analytics appeared first on Analytics India Magazine.
AI has the potential to revolutionise the way humans interact with their devices, especially for those with health conditions and physical impairments. Whether it’s text-to-speech models in screen readers for people with visual impairments, or intelligent accessibility changes for those with mobility issues, accessibility for all is an important part of software development and AI innovation.
To raise awareness on this issue, entrepreneurs Joe Devon and Dennison Asuncion launched Global Accessibility Awareness Day (GAAD) in 2012. Yesterday marked the 11th anniversary of GAAD, and keeping in line with this theme, both Google and Apple released new AI-powered accessibility features for their devices. Out of all the battlefields tech giants can pick, this is likely one for the best cause.
AI for all
On the occasion of GAAD, Google, in a blog post detailed a host of improvements it has made across its product lineup. Firstly, it spoke about Google Lookout, an app launched in 2019 to help visually impaired individuals navigate the world with image recognition algorithms. Targeted at visually-impaired individuals, this application is now getting an upgrade that uses AI to generate alt text for images on the internet that don’t have it.
Android’s AI-powered Live Caption feature also got an update with the feature being rolled out to more phones over the summer. In addition to this, speech-impaired users can use Live Caption to type back responses over calls and have the response read aloud to the other caller.
Apple, on the other hand, released one of the most revolutionary accessibility improvements to their devices. Made for users diagnosed with ALS (amyotrophic lateral sclerosis) or other conditions that impact speech ability, Apple released a feature called Personal Voice. By reading aloud 15 minutes of randomised text prompts, users can train an AI model to sound exactly like them.
To keep the process secure and private, all machine learning processing is done on-device. Personal Voice is also integrated with Live Speech, another accessibility feature that allows users to convert text to audio on phone and FaceTime calls.
Additionally, Apple also introduced a feature for the visually impaired. Adding to the detection mode in iPhone’s Magnifier, Apple introduced another feature, known as Point and Speak. It uses image recognition algorithms to process data from the camera on the device to announce images and text to users.
While a majority of these features reduce the barrier to entry for individuals with disabilities, integrating AI in this field must be done with a measured approach, lest it raises security concerns later down the line.
Balancing harm and benefit
The primary exhibit here is Apple’s Personal Voice feature, which, on a surface level, is a life-changer for those who wish to interact with the world in their own voice. However, on the flip side, it can also be used for malicious purposes. Suppose a mal-intentioned party got a user to go through the 15-minute prompt required to train the personal voice, the output can be used as a method to launch a social engineering attack on the person.
While the current crop of AI-powered accessibility features come with on-device ML processing, the issue of data privacy also tends to arise in such matters. If the accessibility data is not processed on the device and it is uploaded to the cloud, it means that a majority of the users’ data is exposed, leading them to sacrifice accessibility for privacy.
AI bias is another issue when it comes to accessibility services. Due to the lack of data on individuals with disabilities, AI algorithms can be biased or under-fitted for this demographic. Even though these accessibility models are a good step forward in using AI to enable technology usage for all, there still needs to be many steps taken for safe and responsible AI in accessibility.
The post Google and Apple Compete for AI-Powered Accessibility appeared first on Analytics India Magazine.