Snowflake is a SaaS, i.e., software as a service that is well suited for running analytics on large volumes of data. The platform is supremely easy to use and is well suited for business users, analytics teams, etc., to get value from the ever-increasing datasets. This article will go through the components of creating a streaming semi-structured analytics platform on Snowflake for healthcare data. We will also go through some key considerations during this phase.
Context
There are a lot of different data formats that the healthcare industry as a whole supports but we will consider one of the latest semi-structured formats i.e. FHIR (Fast Healthcare Interoperability Resources) for building our analytics platform. This format usually possesses all the patient-centric information embedded within 1 JSON document. This format contains a plethora of information, like all hospital encounters, lab results, etc. The analytics team, when provided with a queryable data lake, can extract valuable information such as how many patients were diagnosed with cancer, etc. Let’s go with the assumption that all such JSON files are pushed on AWS S3 (or any other public cloud storage) every 15 minutes through different AWS services or end API endpoints.
Architectural Design
Architectural Components
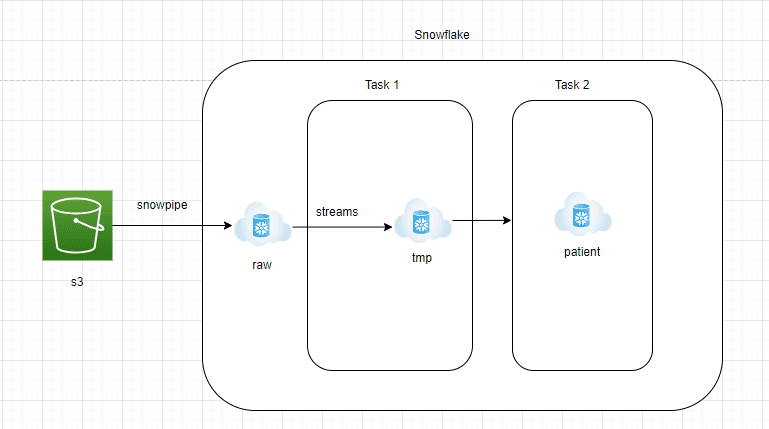
AWS S3 to Snowflake RAW zone:
Data needs to be continuously streamed from AWS S3 into the RAW zone of Snowflake.
Snowflake offers Snowpipe managed service, which can read JSON files from S3 in a continuous streaming way.
A table with a variant column needs to be created in the Snowflake RAW zone to hold the JSON data in the native format.
Snowflake RAW Zone to Streams:
Streams is managed change data capture service which will essentially be able to capture all the new incoming JSON documents into Snowflake RAW zone
Streams would be pointed to the Snowflake RAW Zone table and should be set to append=true
Streams are just like any table and easily queryable.
Snowflake Task 1:
Snowflake Task is an object that is similar to a scheduler. Queries or stored procedures can be scheduled to run using cron job notations
In this architecture, we create Task 1 to fetch the data from Streams and ingest them into a staging table. This layer would be truncated and reload
This is done to ensure new JSON documents are processed every 15 minutes
Snowflake Task 2:
This layer will convert the raw JSON document into reporting tables that the analytics team can easily query.
To convert JSON documents into structured format, the lateral flatten feature of Snowflake can be used.
Lateral flatten is an easy-to-use function that explodes the nested array elements and can be easily extracted using the ‘:’ notation.
Key Considerations
Snowpipe is recommended to be used with a few large files. The cost may go high if small files on external storage aren’t clubbed together
In a production environment, ensure automated processes are created to monitor streams since once they go stale, data can’t be recovered from them
The maximum allowed size of a single JSON document is 16MB compressed that can be loaded into Snowflake. If you have huge JSON documents that exceed these size limits, ensure you have a process to split them before ingesting them into Snowflake
Conclusion
Managing semi-structured data is always challenging due to the nested structure of elements embedded inside the JSON documents. Consider the gradual and exponential increase of the volume of incoming data before designing the final reporting layer. This article aims to demonstrate how easy it is to build a streaming pipeline with semi-structured data.
Milind Chaudhari is a seasoned data engineer/data architect who has a decade of work experience in building data lakes/lakehouses using a variety of conventional & modern tools. He is extremely passionate about data streaming architecture and is also a technical reviewer with Packt & O'Reilly.
More On This Topic
Sky's the Limit: Learn how JetBlue uses Monte Carlo and Snowflake to build…
From Unstructured to Structured Data with LLMs
A Structured Approach To Building a Machine Learning Model
How to Create an Interactive Dashboard in Three Steps with KNIME Analytics…
Introducing PostHog: An open-source product analytics platform
Building a Structured Financial Newsfeed Using Python, SpaCy and Streamlit
TikTok owner ByteDance's "Self-Controlled Memory system" can reach into a data bank of hundreds of turns of dialogue, and thousands of characters, to give any language model capabilities superior to that of ChatGPT to answer questions about past events.
When you type things into the prompt of a generative artificial intelligence (AI) program such as ChatGPT, the program gives you a response based not just on what you've typed, but also all the things you've typed before.
You can think of that chat history as a sort of memory. But it's not sufficient, according to researchers at multiple institutions, who are trying to endow generative AI with something more like an organized memory that can augment what it produces.
Also: How to use ChatGPT: Everything you need to know
A paper published this month by researcher Weizhi Wang from University of California at Santa Barbara, and collaborators from Microsoft, titled "Augmenting Language Models with Long-Term Memory", and posted on the arXiv pre-print server, adds a new component to language models.
The problem is ChatGPT and similar programs can't take in enough text in any one moment to have a very long context for things.
As Wang and team observe, "the input length limit of existing LLMs prevents them from generalizing to real-world scenarios where the capability of processing long-form information beyond a fix-sized session is critical."
OpenAI's GPT-3, for example, takes maximal input of 2,000 tokens, meaning, characters or words. You can't feed the program a 5,000-word article, say, or a 70,000-word novel.
Also: This new technology could blow away GPT-4 and everything like it
It's possible to keep expanding the input "window," but that runs into a thorny computing problem. The attention operation — the essential tool of all large language programs, including ChatGPT and GPT-4 — has "quadratic" computational complexity (see the "time complexity" of computing). That complexity means the amount of time it takes for ChatGPT to produce an answer increases as the square of the amount of data it is fed as input. Increasing the window balloons the compute needed.
And so some scholars, note Wang and team, have already tried to come up with a crude memory. Yuhuai Wu and colleagues at Google last year introduced what they call the Memorizing Transformer, which stores a copy of previous answers that it can in future draw upon. That process lets it operate on 65,000 tokens at a time.
But Wang and team note the data can become "stale". The process of training the Memory Transformer makes some things in memory become out of sync with the neural network as its neural weights, or, parameters, are updated.
Wang and team's solution, called "Language Models Augmented with Long-Term Memory", or LongMem, uses a traditional large language model that does two things. As it scrutinizes input, it stores some of it in the memory bank. It also passes the output of every current prompt to a second neural network, called the SideNet.
Also: How I tricked ChatGPT into telling me lies
The SideNet, which is also a language model, just like the first network, is tasked with comparing the current prompt typed by a person to the contents of memory to see if there's a relevant match. The SideNet, unlike the Memory Transformer, can be trained on its own apart from the main language model. That way, it gets better and better at picking out contents of memory that won't be stale.
Wang and team run tests to compare LongMem to both the Memorizing Transformer and to OpenAI's GPT-2 language model. They also compare LongMem to reported results from the literature for other language models, including the 175-billion parameter GPT-3.
They use tasks based on three datasets that involve summarizing very long texts, including whole articles and textbooks: Project Gutenberg, the arXiv file server, and ChapterBreak.
To give you an idea of the scale of those tasks, ChapterBreak, introduced last year by Simeng Sun and colleagues at the University of Massachusetts Amherst, takes whole books and tests a language model to see if, given one chapter as input, it can accurately identify from several candidate passages which one is the start of the next chapter. Such a task "requires a rich understanding of long-range dependencies", such as changes in place and time of events, and techniques including "analepsis", where, "the next chapter is a 'flashback' to an earlier point in the narrative."
Also: AI is more likely to cause world doom than climate change, according to an AI expert
And it involves processing tens or even hundreds of thousands of tokens.
When Sun and team ran those ChapterBreak tests, they reported last year, the dominant language models "struggled". For example, the large GPT-3 was right only 28% of the time.
But the LongMem program "surprisingly" beat all the standard language models, Wang and team report, including GPT-3, delivering a state-of-the-art score of 40.5%, despite the fact that LongMem has only about 600 million neural parameters, far fewer than the 175 billion of GPT-3.
"The substantial improvements on these datasets demonstrate that LONGMEM can comprehend past long-context in cached memory to well complete the language modeling towards future inputs," write Wang and team.
The Microsoft work echoes recent research at ByteDance, the parent of social media app TikTok.
In a paper posted in April on arXiv, titled "Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System", researcher Xinnian Liang of ByteDance and colleagues developed an add-on program that gives any large language model the ability to store very long sequences of stuff talked about.
Also: AI will change software development in massive ways, says MongoDB CTO
In practice, they contend, the program can dramatically improve a program's ability to place each new prompt in context and thereby make appropriate statements in response — even better than ChatGPT.
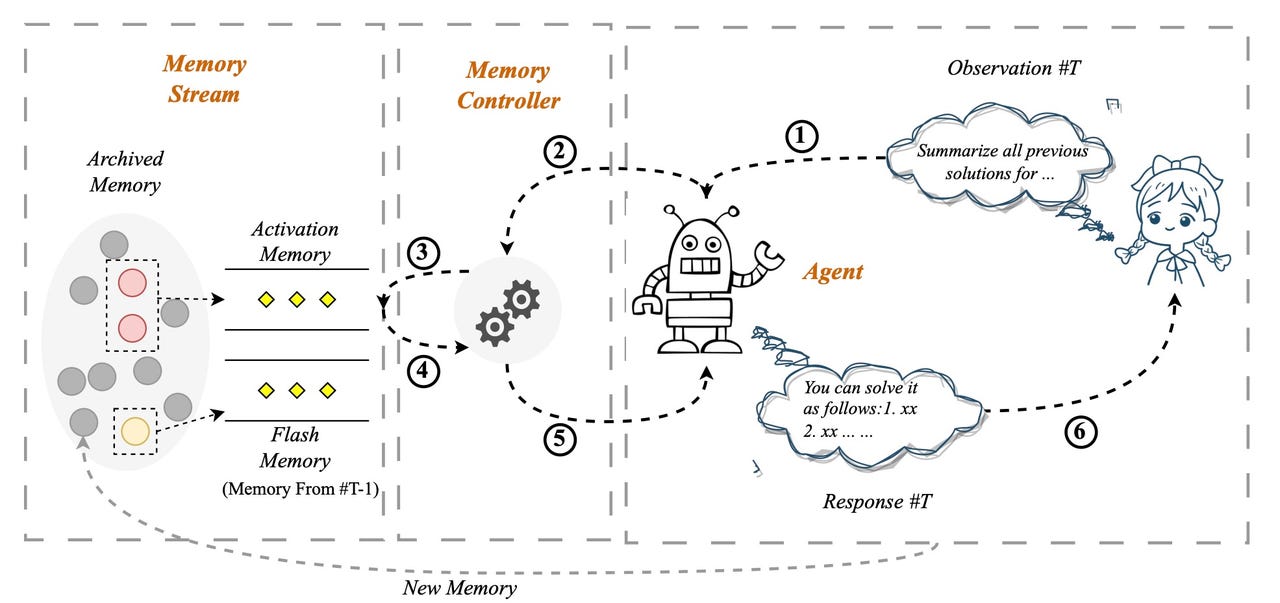
In the "Self-Controlled Memory system", as it's called, or SCM, the input a user types at the prompt is evaluated by a memory controller to see whether it requires dipping into an archival memory system called the memory stream, which contains all the past interactions between the user and the program. It's rather like Wang and team's SideNet and accompanying memory bank.
If memory is required, that collection of past input is accessed via a vector database tool such as Pinecone. The user's input is a query, and it's matched for relevance against what's in the database.
Some user queries don't require memory, such as "Tell me a joke", which is a random request that any language model can handle. But a user prompt such as, "Do you remember the conclusion we made last week on the fitness diets?" is the kind of thing that requires access to past chat material.
In a neat twist, the user prompt, and the memory it retrieves, are combined, in what the paper calls "input fusion" — and it is that combined text that becomes the actual input to the language model on which it generates its response.
Also: This new AI system can read minds accurately about half the time
The end result is that the SCM can top ChatGPT in tasks that involve a reference back to hundreds of turns earlier in a dialogue, write Liang and team. They connected their SCM to a version of GPT-3, called text-davinci-003, and tested how it performed with the same input compared to ChatGPT.
In one series of more than 100 turns, consisting of 4,000 tokens, when the human prompts the machine to recall the hobbies of the person discussed at the outset of the session, "the SCM system provides an accurate response to the query, demonstrating exceptional memory-enhanced capabilities," they write, while, "in contrast, it appears that ChatGPT was distracted by a considerable amount of irrelevant historical data."
The work can also summarize thousands of words of long texts, such as reports. It does so by iteratively summarizing the text, which means storing the first summary in the memory stream, and then creating the next summary in combination with the previous summary, and so on.
The SCM can also make large language models that aren't chat bots behave like chat bots. "Experimental results show that our SCM system enables LLMs, which are not optimized for multi-turn dialogue, to achieve multi-turn dialogue capabilities that are comparable to ChatGPT," they write.
Both the Microsoft and the TikTok work can be thought of as extending the original intention of language models. Before ChatGPT, and its predecessor, Google's Transformer, natural language tasks were often carried out by what are called recurrent neural networks, or RNNs. A recurrent neural network is a kind of algorithm that can go back to earlier input data in order to compare it to the current input.
Also: GPT-4: A new capacity for offering illicit advice and displaying 'risky emergent behaviors'
The Transformer and LLMs such as ChatGPT replaced RNNs with the simpler approach — attention. Attention automatically compares everything typed to everything typed before, so that the past is always being brought into play.
The Microsoft and TikTok research work, therefore, simply extends attention with algorithms that are explicitly crafted to recall elements of the past in a more organized fashion.
The addition of memory is such a basic adjustment, it's likely to become a standard aspect of large language models in future, making it much more common for programs to be able to make connections to past material, such as chat history, or to address the whole text of very long works.
Microsoft and LinkedIn launched on Wednesday the AI Skills Initiative certificate program, which is a library of free coursework for professionals who are beginners in regards to generative AI skills and want to learn how to apply generative AI to their work.
In addition, Microsoft will award a grant for exceptional ideas about training employees of nonprofit, social enterprise, and research or academic institutions to use generative AI, with proposals due August 15.
Jump to:
What does Microsoft’s AI Skills Initiative entail?
What is the Generative AI Skills Challenge?
Generative AI skills are among companies’ top three training priorities
What does Microsoft’s AI Skills Initiative entail?
The Microsoft AI Skills Initiative, developed with LinkedIn, consists of five modules. Every module includes a video; some of the modules are packaged with quizzes, a workbook file or both. Completing all five modules gives the learner a Professional Certificate on Generative AI to display on LinkedIn Learning.
The content presented in the AI Skills Initiative certification skews toward Microsoft’s Bing Chat, which is built on OpenAI’s GPT-4, instead of its rival, Google’s Bard.
The Professional Certificate on Generative AI training will be available in Spanish, Portuguese, French, German, Simplified Chinese and Japanese and will be free through 2025.
SEE: Learn how generative AI is transforming cloud security. (TechRepublic)
“We have the opportunity to provide foundational information to everyone, everywhere, to help us all stay ahead of the skills gaps and harness its creativity to retrieve helpful information,” said Naria Santa Lucia, general manager of digital inclusion at Microsoft, in an email to TechRepublic. “As we are learning, the technology is learning from us, too, and we have the power to shape how the technology can best support us.”
Microsoft is offering more AI skills training courses
The LinkedIn training course is part of Microsoft’s Skills for Jobs program, which includes a training module for teachers, trainers and facilitators exploring artificial intelligence. Plus, Microsoft launched the Learn AI Skills Challenge, a brand-name certification available from July 17 to August 14.
What is the Generative AI Skills Challenge?
The Generative AI Skills Challenge, which will run from now until fall 2023, aims to teach employees how to use generative AI to create positive social change. In particular, it focuses on advancing skills, socioeconomic mobility and internet adoption among historically marginalized groups.
Five awardees will be chosen — one each from the Africa, Asia, Latin America, Europe and North America regions. Each awardee will receive a monetary award of up to $250,000, as well as a Microsoft-supported cohort and events, data training and technical guidance and Azure cloud computing space.
The grant is also backed by GitHub, Microsoft’s AI for Good Lab, and data.org. Data.org is a nonprofit funded by the Mastercard Center for Inclusive Growth and The Rockefeller Foundation.
“Together, we are taking a significant stride towards fulfilling data.org’s commitment to train one million purpose-driven data practitioners by 2032,” said Danil Mikhailov, executive director of data.org, in a press release.
The winners of the grant will be announced in November 2023. Projects can be expected to conclude in June 2024.
“AI offers perhaps even more potential for the good of humanity than any invention that has preceded it,” Microsoft President and Vice Chair Brad Smith said in a blog post in response to ongoing U.S. policy discussions around the use of generative AI.
Generative AI skills are among companies’ top three training priorities
More than 75% of companies plan to adopt AI in the next five years, the World Economic Forum found. Training employees to use AI and big data is the third-highest company skills-training priority companies plan to focus on over the next five years, according to the WEF Future of Jobs 2023 report. That statistic includes generative AI or other technologies often found under the same banner, such as machine learning.
Microsoft’s May 2023 Work Trend Index found that 49% of people are concerned about AI making their jobs obsolete. At the same time, 70% are open to the possibility of delegating some tasks to AI to reduce their workloads.
One element of skills training that is somewhat unique to generative AI is the practice of prompt engineering, pointed out Shravan Goli, chief operating officer at Coursera, in an email to TechRepublic.
“Unlike other enterprise software, generative AI tools require the user to train the tool itself,” Goli said. “Without good prompts, the tool won’t be able to help employees boost productivity in a meaningful way, and increasing productivity is one of the most promising components of generative AI for workers today.”
SEE: This customizable prompt engineer hiring kit from TechRepublic Premium
He also noted that generative AI skills training requires ethical oversight, which Coursera takes into account in its own free training modules.
“As with any emerging technology, society is still navigating its broader implications and managing guardrails,” Goli said. “In order to leverage this incredibly powerful tool while still ensuring responsible use by employees, I believe organizations need to carefully outline ethical guidelines.”
Subscribe to the Innovation Insider Newsletter
Catch up on the latest tech innovations that are changing the world, including IoT, 5G, the latest about phones, security, smart cities, AI, robotics, and more.
“Taking LSD was a profound experience, one of the most important things in my life. LSD shows you that there’s another side to the coin, and you can’t remember it when it wears off, but you know it. It reinforced my sense of what was important—creating great things instead of making money, putting things back into the stream of history and of human consciousness as much as I could.” – Steve Jobs
Steve Jobs was one of the foremost prominent figures of the tech industry who admitted to taking LSD in the 70s, in addition to other recreational drugs. But, he wasn’t the first tech leader to resort to psychedelics.
In John Markoff’s non-fiction book “What the Dormouse said”, evolution of personal computers through illicit counterculture ideals that existed in Silicon Valley in the 60s was explored. It spoke about how LSD influenced individuals and ideas that played a significant role in the birth of personal computers and the internet. Setting precedence to what exists today, tech leaders are now embracing the usage of psychedelics with some of them not shying away from talking about it – ringing in the next big industry: the psychedelic drug market, which is poised for massive growth.
Source: Reddit
Of the many tech predictions Sam Altman made in a 2021 tweet, psychedelic medicine was one industry he expects to see a boom in this decade. As per Brandessence market research, the psychedelic drugs market is expected to reach a valuation of $11.82 billion by 2029 from $4.87 billion in 2022.
There has also been prolific funding for psychedelic studies. Mets owner Steven Cohen, recently donated $5 million to MAPS (Multidisciplinary Association for Psychedelics Studies), a non-profit organization that explores the medical, legal, and cultural dimensions associated with psychedelics and marijuana.
Psychedelics under controlled dosages are proven to be effective in the treatment of addiction, anxiety, major depressive disorder, PTSD, and other difficult-to-treat conditions such as end-of-life care. However, with properties to change perception, mood, and affect all senses to alter a person’s thinking, psychedelics have found its way into the hands of tech leaders for recreational use, probably in an effort to push creativity, improve productivity and problem-solving abilities.
The Rave in Town
Psychedelics (or hallucinogens) such as lysergic acid diethylamide (LSD), psilocybin-containing mushrooms (magic mushrooms), ketamine and others are consumed via microdoses for medicinal or recreational use. Microdosing on psilocybin is now becoming popular in Silicon Valley with psychedelic-trip coaches being offered for $2000 per month.
According to a Financial Times article, a number of tech founders, billionaires, and professionals (whose names were withheld) microdose on LSD as means to not only boost productivity, but to improve focus and be more creative with idea generation which is required by knowledge workers.
But, what about the legality of it?
Colorado and Oregon are the only U.S states that have legalised the use of psilocybin for therapeutic use. However, there are other cities that have decriminalised the same drug, which implies that they are still prohibited but possessing them is not considered a criminal offence. San Francisco, home to Silicon Valley, also comes under the decriminalised status.
Source: Landmark Recovery
The Psych- Tech Connection
While a number of anonymous Silicon Valley leaders are known to indulge in hallucinogens and other forms of restricted drugs, here are a few names that have been reported using them.
Elon Musk
It is reported that Elon Musk takes microdoses of ketamine which he considers to be better than antidepressants. Musk has spoken about his mental health struggles in the past where he has experienced ‘great highs, terrible lows, and unrelenting stress.’ According to the Wall Street Journal, the claim comes from people who have witnessed him use ketamine. Musk has also tweeted on how ketamine is a better alternative to SSRI (a type of antidepressant).
Depression is overdiagnosed in the US, but for some people it really is a brain chemistry issue. But zombifying people with SSRIs for sure happens way too much. From what I’ve seen with friends, ketamine taken occasionally is a better option.
— Elon Musk (@elonmusk) June 27, 2023
A Twitter user Geoff Pilkington tweeted appreciating Musk’s support for psychedelics and said that about how half of Los Angeles gets ketamine treatment.
Sergey Brin
As per the same WSJ report, Google co-founder Sergey Brin is said to consume psilocybin, commonly known as magic mushrooms. Psilocybin has been medically tested for treating cluster headaches, depression and other mental health conditions. However, there is no clarity on whether Brin’s usage is medicinal or recreational.
Bob Lee
Deceased founder of CashApp, a mobile payment service, Bob Lee, reportedly spent years participating in ‘The Lifestyle’ which is believed to be an underground party scene for sex and psychedelics in San Francisco. Though murdered, his toxicology report showed alcohol, cocaine, and ketamine at the time of death.
Spencer Shulem
Spencer Shulem, CEO of BuildBetter.ai, a technology company, uses LSD every three months to help him focus and think more creatively. He feels that the high expectations set by VCs and investors, push founders to resort to psychedelics to become extraordinary. However, Shulem is careful about sharing his LSD experiences at work and is not a preacher on the ‘joys of drugs.’
The post Psychedelics Fuel Silicon Valley Tech Leaders appeared first on Analytics India Magazine.
At Google I/O, San Francisco, besides several updates, emerged a new drinking game — take a sip every time the speakers utter the word “responsible AI”. But hold on to your glasses, because the first-ever Google I/O Connect in Bengaluru was a carbon copy of the US event, albeit with an Indian twist. Playing the perfectly responsible parents of the AI world, the Bard creator made sure whatever they announced had a responsible AI approach. Here, they focused on updates tailored for India, but surprisingly, there was barely any announcement on Search.
Last year at the ‘Google for India’ event, the big tech announced a grant of $1 million to IIT Madras for setting up a centre for Responsible AI. However, at the same time, Google also cautioned its employees against its own chatbot Bard raising concerns about the privacy and security of these LLMs. Google was earlier promoting the use of Bard for its employees. However, its updated privacy note also asks users to not include confidential and sensitive information in Bard conversations.
In light of these recent developments, Google’s commitment to responsible AI becomes even more crucial, as it aims to ensure that AI systems produce reliable and trustworthy results while mitigating potential biases and inaccuracies in the AI models.
Will Grannis, VP and CTO of Google Cloud mentioned during his keynote session that all their “AI-generated content is labelled with metadata” to ensure that they employ AI responsibly. And not just Grannis, other speakers like Ambarish Khegne (vice president, product, Google Pay), Matthew McCollough (VP, product, Android) and Una Kravets (developer relations engineer) made sure to emphasise the ethical use of AI.
Indian IT & Google – A Love Story
Interestingly, in the past couple of months, several Indian IT giants like TCS and Wipro have partnered with Google Cloud to bolster their generative AI capabilities, giving up on competitors like Microsoft Azure, AWS, among others. Will Grannis, CTO of Google told AIM, “Our local engineering community in India is the second largest in the world, so it’s where we need and want to be, and we’re really thrilled about tapping into that developer community. This is why we’ve been offering starter credits to ensure financial barriers don’t prevent them from accessing our capabilities.”
Another significant aspect is the ever-growing startup ecosystem in India developing innovative solutions by leveraging the platform. Talking about the differing priorities of startups and large governmental bodies, startups favour speed and agility while larger entities prioritise accuracy and invest more time in ensuring it. Google acknowledges the diverse needs and priorities of its users and strives to develop AI technologies that cater to these different contexts, allowing for customisation and adaptability.
“As more people come, we’re working to simplify network solutions. This is part of what we believe is critical and will shape the future,” he added.
India is home to more than 60 generative AI startups, as per a report. With a focus on implementing generative AI, particularly with Vertex AI, for Indian enterprises, Google is offering AI capabilities through consumer-facing products and within the Cloud platform, empowering developers with new tools and capabilities. The introduction of PaLM API, MakerSuite, and features on Vertex AI are important steps in this direction. This development isn’t just about the models themselves but about providing a comprehensive platform that enables production-ready solutions at scale, marking a natural progression for Indian developers.
“There is a growing interest in gen AI, with numerous startups and enterprise customers exploring AI for innovation and improved customer experience,” Manish Gupta, head of Google Research India told AIM at the event.
Regarding Project Vaani, which Google announced at its ‘Google for India’ event, in association with IISC, the initial phase of data collection is now made available to developers as an open-source resource for speech recognition systems in multiple languages. “We are also launching the Open Buildings dataset, which includes satellite analysis of over 200 million buildings in India,” Gupta told during the discussion.
As per Gupta, among the 125 languages they had pledged to support, 75 lacked any data corpus. “In the 4,000 hours of speech data that has been put out, for a few languages, it’s the first such instance that digital data has been made available,” he added, opening an arena of new advancements and innovations in these languages with zero data corpus.
Reimagining the SEO Experience
As AIM reported earlier, Google is slowly inching towards realising cofounder Larry Page’s vision of an “AI-complete” search engine by incorporating generative AI. So now, search engines will resemble conversations with AI, making conventional SEO techniques redundant. “Harnessing the power of generative AI can enhance human creativity and advertisers will be able to automatically generate diverse content such as images, short videos, and compelling descriptions, enabling them to personalise their ads according to individual users’ preferences,” Gupta told AIM.
While generative AI has the potential to misrepresent facts, Google is dedicated to providing trustworthy information and will exercise caution in leveraging this technology to ensure the preservation of user trust.
The post Responsible AI Takes Center Stage at Google I/O Connect appeared first on Analytics India Magazine.
With the right plugins, ChatGPT 4 — the latest version of OpenAI's language model system — can be very useful for helping you complete a number of tasks. But, caveat emptor, even the most mature plugins are still, at best, beta quality. Used carefully, however, they can still help you get real work done.
The best ChatGPT plugins aren't your run-of-the-mill, "makes your browser blink in different colors" plugins. (Although, if you really want to play with colors, there's always Color Palette.) Instead, they add accuracy and functionality by incorporating third-party web services into your search.
Also: The best AI chatbots: ChatGPT and other noteworthy alternatives
I've rounded up the best ChatGPT plugins for different use cases below, based on my experience testing them out. For now, all the plugins listed here are free. That will not last. For example, while the WolframAlpha expert system has a free tier, its most useful level, Pro, runs $5 a month. Eventually, you'll need to pay a subscription for this level of access to use its ChatGPT plugin. You can be sure many other programs will follow suit.
Here are the best ChatGPT plugins to help you get more done.
So, there you have it. Ten plugins, plus two extra, that turn ChatGPT from a mere chatbot into a full-blown digital assistant. These plugins go a long way to transforming ChatGPT into an everyday utility.
In a bid to make their algorithms safer and more responsible with user data, Google has announced a competition called the Machine Unlearning Challenge. Through this, the AI giant aims to find new ways to remove sensitive data from neural networks to adhere to global data regulation norms.
Removing training data from a trained neural network has long been a difficult problem to solve in AI. However, the emergent field of machine unlearning aims to solve this problem. Machine unlearning aims to do so by either retraining an algorithm with excluded data points or making adjustments to already-trained models.
The competition will be hosted on Kaggle, and will be a part of the NeurIPS 2023 Competition Track. According to Google, the competition will provide participants with a realistic scenario wherein a certain subset must be forgotten in a pre-trained model. The results will be evaluated using a membership inference attack, which can determine certain elements of the training dataset. If the attack fails, the model will be considered to have passed the test.
Participants will be scored in terms of forgetting quality and model utility after forgetting. It will run between mid-July and mid-September, with Google announcing that it will release a starting kit for participants to test their unlearning models.
The crux of the problem is that deleting the training data doesn’t delete the influence of the data on ML models. Even if the data is removed from the database, the models trained on it might still have information on the data. With machine unlearning techniques, researchers can remove even the data’s effect, making it compliant with data deletion requests.
The post Google Announces The First Machine Unlearning Challenge appeared first on Analytics India Magazine.
‘AI Will Save the World’ Says Marc Andreessen June 30, 2023 by Jaime Hampton
(Phonlamai Photo/Shutterstock)
VC billionaire Marc Andreessen says the world is currently “hysterically freaking out” about artificial intelligence, and he recently wrote a 7,000-word essay to address these fears.
During the Stratechery podcast, Andreessen told host Ben Thompson that he felt compelled to write “Why AI Will Save the World” because the world had gone hysterical over A.I. and needed to be set straight. Thompson's podcast is just one of many (including those from Lex Fridman and Sam Harris) Andreessen has recently visited with his message that AI is a positive force for good.
Andreessen was a co-founder of Netscape and is now co-founder and general partner of the Silicon Valley VC firm Andreessen Horowitz. His essay explores his idea that the transformative potential of AI should be seen not as a threat but as a tool that will significantly enhance the world.
He emphasizes the scientific aspects of AI and how it is based on the application of mathematics and software that teach computers how to understand and generate knowledge in ways humans do. Andreessen asserts that AI, like any technology, is under human control, despite fears of AI systems developing into murderous robots like in movies like “The Terminator.” He likens these fears to superstition.
“My view is that the idea that AI will decide to literally kill humanity is a profound category error. AI is not a living being that has been primed by billions of years of evolution to participate in the battle for the survival of the fittest, as animals are, and as we are. It is math – code – computers, built by people, owned by people, used by people, controlled by people. The idea that it will at some point develop a mind of its own and decide that it has motivations that lead it to try to kill us is a superstitious handwave,” he wrote.
Andreessen sees AI’s potential as a “way to make everything we care about better.” He argues that AI offers an opportunity to enhance human intelligence and amplify outcomes in domains such as academic achievement, job performance, creativity, and health.
“What AI offers us is the opportunity to profoundly augment human intelligence to make all of these outcomes of intelligence – and many others, from the creation of new medicines to ways to solve climate change to technologies to reach the stars – much, much better from here,” he considers.
Examples of possible ways AI could enhance human capacities are the potential mass availability of AI tutors, AI assistants, and AI partners in professional settings, something that could lead to a surge in productivity and economic growth. Andreessen also considers AI’s potential for making the world a friendlier place and argues that AI could be a source of empathy to support humans during adversity in a sometimes-cold world.
“Talking to an empathetic AI friend really does improve their ability to handle adversity,” said Andreessen. “And AI medical chatbots are already more empathetic than their human counterparts. Rather than making the world harsher and more mechanistic, infinitely patient and sympathetic AI will make the world warmer and nicer.”
Marc Andreessen discusses his essay with colleague Martin Casado in a company podcast. (Source: Andreessen Horowitz)
The development and proliferation of AI are of the utmost importance, Andreessen asserts, likening it to innovations like electricity and microchips. He says it could be the most important invention of human civilization and embracing it is a moral obligation to ourselves, our children, and the future.
Andreessen’s essay offers an immensely optimistic view of AI, refuting those who view it as a destructive force and instead championing it as a powerful tool to address humanity’s challenges.
"Today, growing legions of engineers – many of whom are young and may have had grandparents or even great-grandparents involved in the creation of the ideas behind AI – are working to make AI a reality, against a wall of fear-mongering and doomerism that is attempting to paint them as reckless villains. I do not believe they are reckless or villains. They are heroes, every one," Andreessen wrote.
It is important to note that Andreessen Horowitz has backed 80 AI-related startups since 2013, starting with a $38 billion investment in Databricks that year. The firm has since made large investments in AI including a $27 billion investment in OpenAI in 2019, a $1 billion investment in parallel computing platform Anyscale in 2020, and a host of others.
“GRANDMA LOCKED ME in an oven at 230 degrees when I was just 21-months old,” recounts an uncanny deepfake resemblance of Rody Marie, she recalls being hungry and crying incessantly, which reportedly led her grandmother to place her in an oven, resulting in her tragic death.
Another video shows six-year-old Carl Newton Mahan explaining how he murdered his eight-year-year old friend Cecil. “I am the youngest murderer in history,” a creepy computer generated voice sounds off. “I climbed up on a chair, grabbed my dad’s gun and ran back to Cecil’s house with the gun. When I got there, I said “now I’m going to kill you and shot her,” the video eerily ends.
While deepfakes have existed for a while now, causing political unrest and inciting violence. Technological advancements are here to terrorise you and keep you awake. This is the bizarre bone-chilling trend that has taken over TikTok. Videos on TikTok, which generally have no trigger warnings beforehand, feature disturbingly real-looking victims of true crimes narrating the details of their gruesome death and their ordeal before it.
Another channel brings to life a famous child murder victim Elisa Izquierdo, a six-year-old girl who was murdered by her abusive mother in 1995, and Star Hobson, a one-year-old murdered by her mother’s girlfriend in 2020.
With the advent of hyper realistic text to image, GAN and text to speech models, true crime fanatics can not only create a creepy experience, they can max it out by including the gory details as well.
While the stories are factual to an extent, the creators behind these videos take creative liberties. For instance, the victim we initially spoke about was Royalty Marie in real life, not Rody Marie as shown in the video. Tragically, Royalty, the 20-month-old Black child, was discovered stabbed and burned in an oven at her grandmother Carolyn Jones’ residence in Mississippi in 2018. Jones, aged 48, was charged with first-degree murder. The baby in the video was AI-generated.
Minor changes in the facts of the story and the characters are made in order to escape TikTok guidelines and avoid scrutiny. However, the makers try and keep as close to the name, age and events, as possible. A TikTok account, which goes by @truestorynow, had 50,000 followers and posted videos of victims and murderers telling their stories has now been blocked by TikTok
Where Does this Stem from?
This emerging trend is part of the overarching true-crime fandom. Critics of true crime have condemned the consumption of real-life traumatic events for pure entertainment. However with the explosion, exposure and easy access to AI technology which keeps becoming hyper realistic with each passing day, there’s no question about its increasing popularity—rather the right question is how creepy and horrific will the convergence of true crime and AI become.
These armchair sleuth-hounds and their obsession merging with AI technology will keep re-traumatising the people close to these victims. And lack of regulation to deal with such content doesn’t help either. Criminal Justice experts think that this growing trend is designed to trigger strong emotional reactions — a sure-shot way to get clicks. “It’s uncomfortable to watch, but I think that might be the point,” Paul Bleakley, assistant professor in criminal justice at the University of New Haven told the Rolling Stone.
The people who run these accounts not only tell the stories of well-known child murder victims, such as Elisa Izquierdo and Star Hobson, but adult murder victims like George Floyd and JFK. Critics argue that true crime desensitises audiences to horrendous crimes, but others believe that people can distinguish between reality and fiction and that being more informed about crime can actually reduce fear.
Where Does This Stop?
For a long time, acts of real-life violence have been presented to the public through various mediums, from crime publications to investigative documentaries. However, the true crime genre has gained more recognition only recently. The genre has gained popularity by delving into real-life acts of violence and exposing them to the public. While it has advantages like re-evaluating flawed legal trials and promoting critical thinking, the genre often exploits suffering, adheres to predetermined narratives, prioritises ratings over ethics, and manipulates public opinion.
There’s also a debate around whether popular culture inspires real-life crimes or if it’s the other way around. Makers of the popular show based on Dexter Morgan were accused of inspiring real-life crimes due to his likeable portrayal as a killer in the Dexter series. True Crime as a genre has grown like wildfire. However these TikTok videos garnering millions of views is not odd, as such shows and movies have been topping all kinds of charts.
Netflix’s ‘Making a murder’ has been downloaded over 211 million times, while it was also the most binged TV show in 2018. There are three dedicated true crime TV channels in the UK reaching over five million viewers per month. Experts believe that the fascination with violent and macabre true crime stories can be attributed to the puzzle-like nature of these stories, which engage our attention and provide a sense of excitement.
The wild popularity of true crime can also be attributed to the appeal of having a safe way to explore dark aspects of human behavior and learn from terrible things without being in real danger.
Another thing which stands out is that women make up a significant portion of the audience for true crime, with studies showing that women are the largest consumers of true crime books and podcasts. This could be due to the intrigue surrounding dangerous figures and the romanticisation of serial killers, which can be appealing to some women.
The post Generative AI Brings Murdered Children Back to Life appeared first on Analytics India Magazine.
Secretive hardware startup Humane’s first product is the Ai Pin Kyle Wiggers 7 hours
Humane, the startup launched by ex-Apple design and engineering duo Imran Chaudhri and Bethany Bongiorno, today revealed details about its first product: The Humane Ai Pin.
It’s been a long time coming. Humane has kept its work more or less under wraps since 2018, its founding year, unveiling no products but bringing on dozens of ex-Apple employees responsible for the iPhone’s touchscreen keyboard, elements of Apple’s industrial design and infrastructure for Apple services like iCloud, Apple Pay and Home.
Humane’s product, as it turns out, is a wearable gadget with a projected display and AI-powered features. Chaudhri gave a live demo of the device onstage during a TED Talk in April, but a press release issued today provides a few additional details.
“The [AI Pin is a] connected and intelligent clothing-based wearable device uses a range of sensors that enable contextual and ambient compute interactions,” the release reads. “The Ai Pin is a type of standalone device with a software platform that harnesses the power of Ai to enable innovative personal computing experiences.”
Stripping away the marketing jargon, the Ai Pin will be able to — assuming Humane’s claims hold water — perform many of the tasks a smartphone can, but with fewer gestures and voice commands required. Activated with a tap, the AI Pin, designed to clip to a breast pocket, can offer a summary of emails and calendar invites, translate between languages and answer and place phone calls.
Thanks to a camera and computer vision-powered software, the AI Pin can also recognize objects around it, such as food nutrition labels. And using a built-in projector and depth sensor, it can project an interactive interface onto nearby surfaces, like the palm of a hand or the surface of a table.
Image Credits: Humane
“Our Ai Pin presents an opportunity for people to take AI with them everywhere and to unlock a new era of personal mobile computing which is seamless, screenless, and sensing,” Chaudhri and Bethany Bongiorno said in a canned statement.
Humane also revealed today that it’s collaborating with Qualcomm to develop the Ai Pin’s internal hardware. An unnamed chip from Qualcomm’s Snapdragon series will power the wearable; Human’s promising more info to come later in the year ahead of the device’s launch.
“Humane’s Ai Pin will deliver a superior AI experience,” Qualcomm SVP of product management Ziad Asghar was quoted as saying in the release: “With the advent of generative AI, Humane’s Ai Pin and user experience takes excellent advantage of some of the key strengths of on-device AI and uses real-time contextual information to provide the user with exciting, personalized AI use cases.”
Humane previously announced that it’s partnering with SK Networks and Microsoft to bring its platform and services to market, with Microsoft supplying the cloud processing power and SK Networks handling distribution. Meanwhile, Humane’s collaborating with OpenAI to integrate its tech into the startup’s device — whatever form it ends up taking, exactly. LG, for its part, is working with Humane on R&D projects for the next phase of its product lifecycle as well as adapting Humane’s tech for smart home devices. And Volvo’s teaming up with Humane on a potential automotive industry offering.
To date, San Francisco-based Humane, which has an over-200-person workforce, has raised $230 million from investors including Salesforce CEO Marc Benioff, Kindred Ventures, SK Networks, LG Technology Ventures, Microsoft, Volvo Cars Tech Fund, Tiger Global, Qualcomm Ventures and OpenAI CEO and co-founder Sam Altman.























 Andreessen sees AI’s potential as a “way to make everything we care about better.” He argues that AI offers an opportunity to enhance human intelligence and amplify outcomes in domains such as academic achievement, job performance, creativity, and health.
Andreessen sees AI’s potential as a “way to make everything we care about better.” He argues that AI offers an opportunity to enhance human intelligence and amplify outcomes in domains such as academic achievement, job performance, creativity, and health.



