Image by Author
Ever wondered how the newer, more advanced GPT-4 compares to its predecessor, ChatGPT 3.5?
What is it about GPT-4 that makes it stand out, and where does it reach its limitations?
As we delve into the limitations of language models and their potential applications, it's crucial to comprehend these nuances.
In this journey through the landscape of artificial intelligence, we’ll highlight the distinctive features of ChatGPT 4, its innovative plug-ins, and how they are revolutionizing the way we solve technical questions and problems in the field of data science.
From addressing the complexity of statistics and probability to wrestling with complex modeling problems and coding queries in Python, SQL, or R, we'll explore all the ways GPT-4 can assist in data science.
So, buckle up as we embark on this explorative journey, peeling back the layers of GPT-4 and its capacity to reshape our approach to data science!
ChatGPT 3.5 and ChatGPT 4
GPT-3.5, also known as ChatGPT, was made public by OpenAI in November 2022.
It became popular immediately worldwide. It even became so popular that it exceeded server capacity at times, which led OpenAI to introduce a paid version, ChatGPT Plus, to manage the demand.
Moving on from GPT-3.5, GPT-4 was released on 14 March, and it has a significant upgrade.
It has advanced reasoning capabilities, and even if it can generate meaning from data instead of text (like pictures), the current version of ChatGPT+ is still text output only.
The problem-solving capability of GPT-4 is more accurate than GPT-3.5.
Currently, the paid version of ChatGPT+ costs $20 per month. Yet it has its restrictions, like the cap of 25 messages every 3 hours.
Also, Microsoft’s search engine Bing has been running a customized version of GPT-4.
For more information, here is the official blog post about GPT-4 on the OpenAI website.
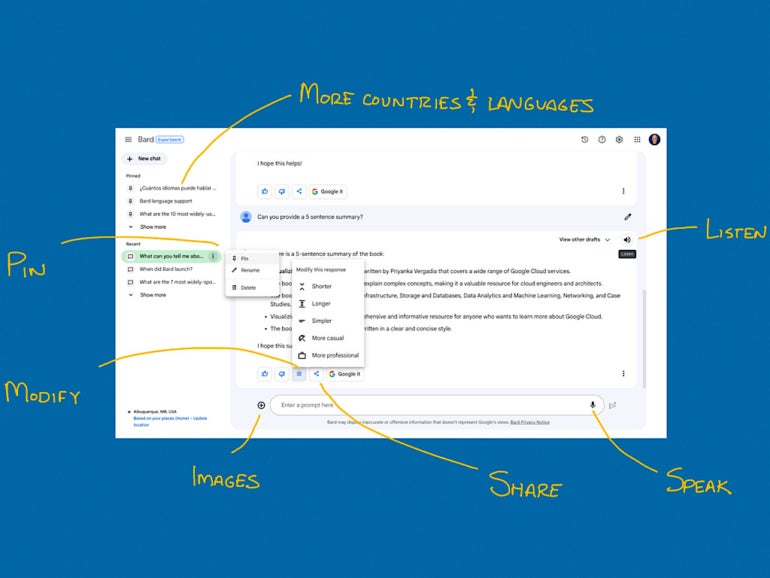
ChatGPT Plug-ins 
Source: https://chat.openai.com/
OpenAI unveiled a new feature for ChatGPT — plugins — on March 23.
These tools are designed to augment the language model's capabilities, allowing it to access the most recent information and perform computations.
The rollout of these plugins is being done gradually to assess their practical use, impact, and potential safety and alignment issues.
Various companies, including KAYAK, Klarna, Milo, Shopify, Slack, Speak, Wolfram, Zapier, and more, have developed the initial set of plugins.
These plugins offer a broad spectrum of functionalities, such as trip planning, grocery ordering, computation access, and real-time data retrieval.
OpenAI also provides two plugins: a web browser and a code interpreter.
While the web browser allows you to reach the web with the power of the GPT model, a code interpreter will help you manipulate and analyze your data by just prompting.
Some of these plug-ins, like Noteable and Wolfram, are especially useful in data science.
These plugins are intended to increase the utility of ChatGPT.
Can GPT4 Be Used to Answer Technical Questions in Data Science?
We can divide data science questions into non-coding and coding interview questions.
By testing ChatGPT4’s ability in these sections, we’ll better understand how ChatGPT4 can be used to answer technical questions in data science.
Let’s start with the non-coding questions.
Non-coding Questions
Here, we will divide the non-coding questions into statistics, probability, and modeling.
Image by Author
Statistics
Statistics is vital to data science, encompassing data gathering, analysis, interpretation, display, and organization.
GPT-4 is equipped to answer questions about statistical concepts, offering a comprehensive understanding of complex statistical principles.
Using the GPT-4 this way can improve the understanding of statistical theories and empower data scientists to extract meaningful insights from data.
Here is the statistics question that we’ll use for testing the Chat’s abilities. We are going to use the Wolfram plug-in, which assists users when doing calculations.
Also, one important note when using ChatGPT-4 and its plugins: They might be good, but they’re not perfect so, always, always double-check the output because it can be wrong.
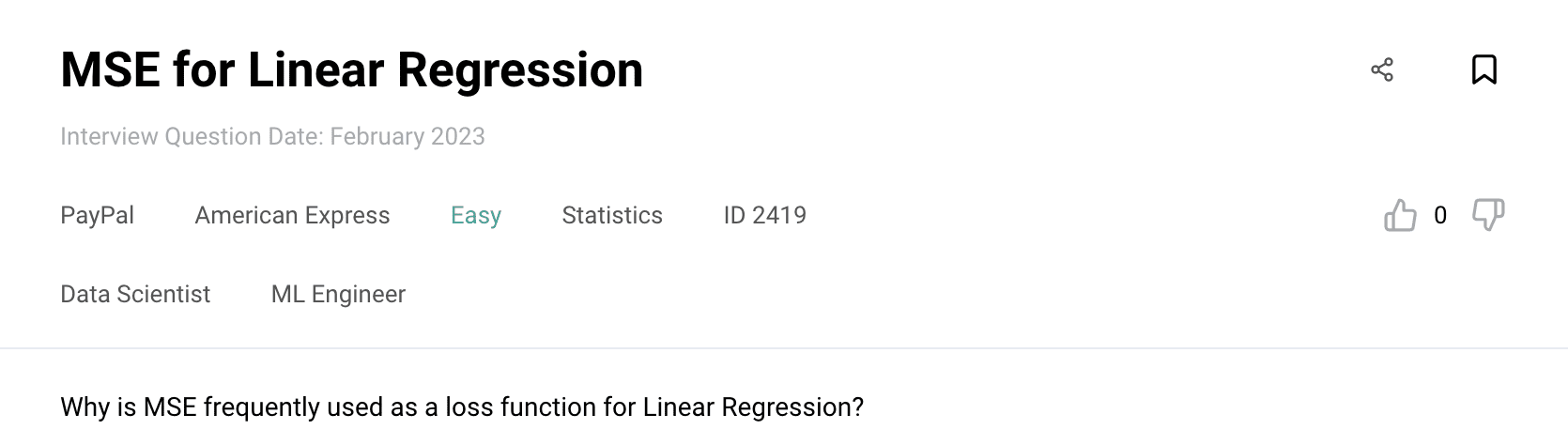
Prompt: Why is MSE frequently used as a loss function for Linear Regression?
(Use Wolfram Plug-in, provide formulas)
ChatGPT : The formula for MSE is:

where:
 is the number of observations
is the number of observations -
 is the actual value and
is the actual value and
-
 is the predicted value.
is the predicted value.
Here are the reasons why MSE is commonly used:
- Differentiability: MSE is a smooth and differentiable function. This is important because optimization algorithms, like gradient descent, rely on the function's derivative to find the minimum.
- Sensitivity to outliers: The squaring term in MSE gives higher weight to larger errors. This means the model will be more sensitive to outliers and will try to minimize large errors.
- Interpretability: MSE is easy to interpret as it represents the average squared difference between the predicted and actual values. A lower MSE indicates a better fit of the model to the data.
- Convexity: MSE leads to a convex loss landscape. Convex problems have a single global minimum, making them easier to solve using optimization algorithms.
- Consistency with OLS: In the case of linear regression, minimizing the MSE is equivalent to minimizing the residuals in Ordinary Least Squares (OLS), which is the standard method for estimating the parameters of a linear regression model.
Note from the author: Even though MSE has these advantages, it's not always the best choice for every regression problem. Depending on the specific characteristics of the data and the problem at hand, other loss functions might be more appropriate.
Control
The ChatGPT’s answer is detailed and correct.
Probability
Probability is integral to data science as it offers a structure for making data predictions and comprehending uncertainty. It can illustrate these concepts in detail, explaining the mathematical computations and logic behind the likelihood of a specific event.
This assists data scientists in building models and making intelligent decisions grounded in probabilistic reasoning.

Here is the probability question ChatGPT will try to solve.
Prompt: You are playing a game with a friend where you roll two fair six-sided dice. If the sum of the two dice is 7 or 11, you win; otherwise, your friend wins. What is the probability that you win on your first roll?
ChatGPT: To determine the probability of winning on your first roll, we need to calculate the number of favorable outcomes (winning outcomes) and divide it by the total number of possible outcomes.
In this case, there are 6 possible outcomes for each die since they are fair six-sided dice. Therefore, the total number of outcomes when rolling two dice is: 66 =36
To win on the first roll, the sum of the two dice must be either 7 or 11. We can calculate the number of favorable outcomes as follows:
- Sum of 7: There are 6 ways to achieve this outcome: (1, 6), (2, 5), (3, 4), (4, 3), (5, 2), and (6, 1).
- Sum of 11: There are 2 ways to achieve this outcome: (5, 6) and (6, 5).
Therefore, there are a total of 6 + 2 = 8 favorable outcomes.
Now, we can calculate the probability of winning on the first roll by dividing the number of favorable outcomes by the total number of possible outcomes:
Probability of winning on the first roll = Number of favorable outcomes / Total Numbers of Possible Outcomes = 8 / 22 = 2 / 9 = 0,222
So, the probability that you win on your first roll is approximately 0.222 or 22.2%.
Control
The output is correct and matches the solution from the platform.
Modeling
Modeling is the process of forming a mathematical depiction of a system to analyze and forecast behavior.
It can help data scientists comprehend concepts, assumptions, implementation, and interpretation of their results. This leads to improved predictions and comprehension of the data.

Here is the modeling question we are going to test.
Prompt : How does the K-means algorithm work?
ChatGPT : The K-means algorithm is an iterative clustering algorithm that aims to partition a given dataset into K clusters, where K is a user-defined parameter.
It works as follows:
- Initialization: Randomly select K data points from the dataset as the initial centroids (representative points) of the clusters.
- Assignment: Assign each data point to the nearest centroid based on a distance metric, usually the Euclidean distance. This step forms K clusters.
- Update: Recalculate the centroids of the clusters by taking the mean of all data points assigned to each cluster. This step aims to find better centroids that represent the center of each cluster.
- Iteration: Repeat the assignment and update steps iteratively until convergence. Convergence occurs when either the centroids stop changing significantly or the maximum number of iterations is reached.
- Output: The algorithm returns the final K clusters, where each data point belongs to the cluster with the nearest centroid.
The K-means algorithm seeks to minimize the within-cluster sum of squared distances, also known as the inertia or the total intra-cluster variance. It assumes that the clusters are spherical and have equal variance. However, the algorithm may converge to suboptimal solutions depending on the initialization of centroids.
To enhance the performance of K-means, various techniques can be applied, such as using multiple initializations, performing smarter centroid initialization methods (e.g., K-means++), or using the Elbow method to determine the optimal value of K.
It's important to note that K-means is sensitive to the initial choice of centroids and may struggle with datasets containing non-linear or irregularly shaped clusters. In such cases, alterntive clustering algorithms like DBSCAN or Gaussian Mixture Models (GMM) may be more suitable.
Control
The ChatGPT’s answer is detailed and correct.
Coding Questions
Coding is mandatory for data scientists. It includes using Python for data wrangling and machine learning, SQL for database handling, and R for statistical computations. GPT-4 can assist in resolving coding issues.
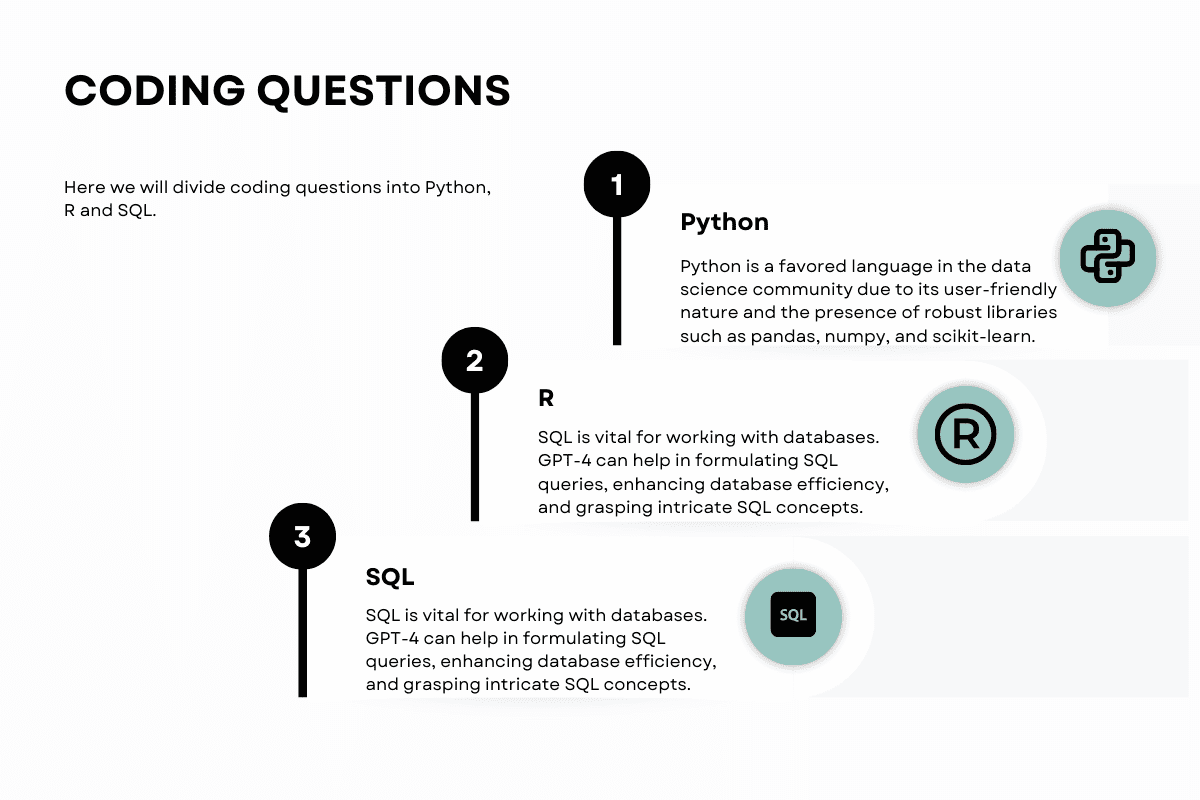
Image by Author
Let’s test ChatGPT-4 on coding questions, starting with Python.
Python
Python is a favored language in the data science community due to its user-friendly nature and the presence of robust libraries such as pandas, numpy, and scikit-learn.
GPT-4 can assist in debugging Python code, recommending best coding practices, and even producing code snippets for particular tasks.
Now let’s try it with the following question.

Question 1
Here is the question.
Prompt:
My dataset name is airbnb_search_details and here is more information;
Unnamed: 0:int64
id:int64
price:float64
property_type: object
room_type: object
amenities:object
accommodates:int64
bathrooms:int64
bed_type:object
cancellation_policy:object
cleaning_fee:bool
city:object
host_identity_verified:object
host_response_rate:object
host_since:datetime64[ns]
neighbourhood:object
number_of_reviews:int64
review_scores_rating:float64
zipcode:int64
bedrooms:int64
beds:int64
The question is: Find all searches for accommodations where the number of bedrooms is equal to the number of bathrooms. Make sure that the expected output type is a dataframe.
Note from the author: To feed the dataset into the Chat, just copy it from the platform like shown below.
ChatGPT: To find all searches for accommodations where the number of bedrooms is equal to the number of bathrooms, you can use the following code in Python:
import pandas as pd # Assuming 'airbnb_search_details' is the DataFrame containing your dataset # Replace 'airbnb_search_details' with the actual name of your DataFrame if different # Filter the DataFrame based on the condition: number of bedrooms == number of bathrooms result = airbnb_search_details[airbnb_search_details['bedrooms'] == airbnb_search_details['bathrooms']] # Display the resulting DataFrame print(result)
Control
Actually, most of ChatGPT’s answer is true except then the last line. There is no need to print out the result dataframe using the print function, so the solution works when the code is updated as follows.
import pandas as pd # Assuming 'airbnb_search_details' is the DataFrame containing your dataset # Replace 'airbnb_search_details' with the actual name of your DataFrame if different # Filter the DataFrame based on the condition: number of bedrooms == number of bathrooms result = airbnb_search_details[airbnb_search_details['bedrooms'] == airbnb_search_details['bathrooms']] # Display the resulting DataFrame result
Question 2
Here is the question from LeetCode I’ll feed into the ChatGPT-4.

I am going to basically copy and paste all the information in my prompt.
Prompt:
Given an integer array nums and an integer val, remove all occurrences of val in nums in-place. The order of the elements may be changed. Then return the number of elements in nums which are not equal to val.
Consider the number of elements in nums which are not equal to val be k, to get accepted, you need to do the following things:
Change the array nums such that the first k elements of nums contain the elements which are not equal to val. The remaining elements of nums are not important as well as the size of nums.
Return k.
Custom Judge:
The judge will test your solution with the following code:
int[] nums = […]; // Input array
int val = …; // Value to remove
int[] expectedNums = […]; // The expected answer with correct length.
// It is sorted with no values equaling val.
int k = removeElement(nums, val); // Calls your implementation
assert k == expectedNums.length;
sort(nums, 0, k); // Sort the first k elements of nums
for (int i = 0; i < actualLength; i++) {
assert nums[i] == expectedNums[i];
}
If all assertions pass, then your solution will be accepted.
Example 1:
Input: nums = [3,2,2,3], val = 3
Output: 2, nums = [2,2,_,_]
Explanation: Your function should return k = 2, with the first two elements of nums being 2.
It does not matter what you leave beyond the returned k (hence they are underscores).
Example 2:
Input: nums = [0,1,2,2,3,0,4,2], val = 2
Output: 5, nums = [0,1,4,0,3,_,_,_]
Explanation: Your function should return k = 5, with the first five elements of nums containing 0, 0, 1, 3, and 4.
Note that the five elements can be returned in any order.
It does not matter what you leave beyond the returned k (hence they are underscores).
Constraints:
0 <= nums.length <= 100
0 <= nums[i] <= 50
0 <= val <= 100
The solution format ;
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
ChatGPT: Here's the solution in Python:
class Solution: def removeElement(self, nums: List[int], val: int) -> int: k = 0 # Counter for elements not equal to val # Iterate through the array for i in range(len(nums)): if nums[i] != val: nums[k] = nums[i] # Move the element to the kth position k += 1 return k
The solution uses a two-pointer approach to modify the nums array in-place and count the number of elements that are not equal to val. The variable k is used to keep track of the position where the next non-val element should be placed.
The algorithm iterates through the array and whenever it encounters an element that is not equal to val, it is moved to the kth position, and k is incremented. In the end, k represents the number of elements not equal to val.
You can test the solution using the provided custom judge code to verify if it produces the expected output for the given examples and passes the assertions.
Control
The code is working perfectly without needing any updates.
SQL
SQL is vital for working with databases. GPT-4 can help formulate SQL queries, enhance database efficiency, and grasp intricate SQL concepts.
Question 1
Here is the SQL question we’ll try to solve.
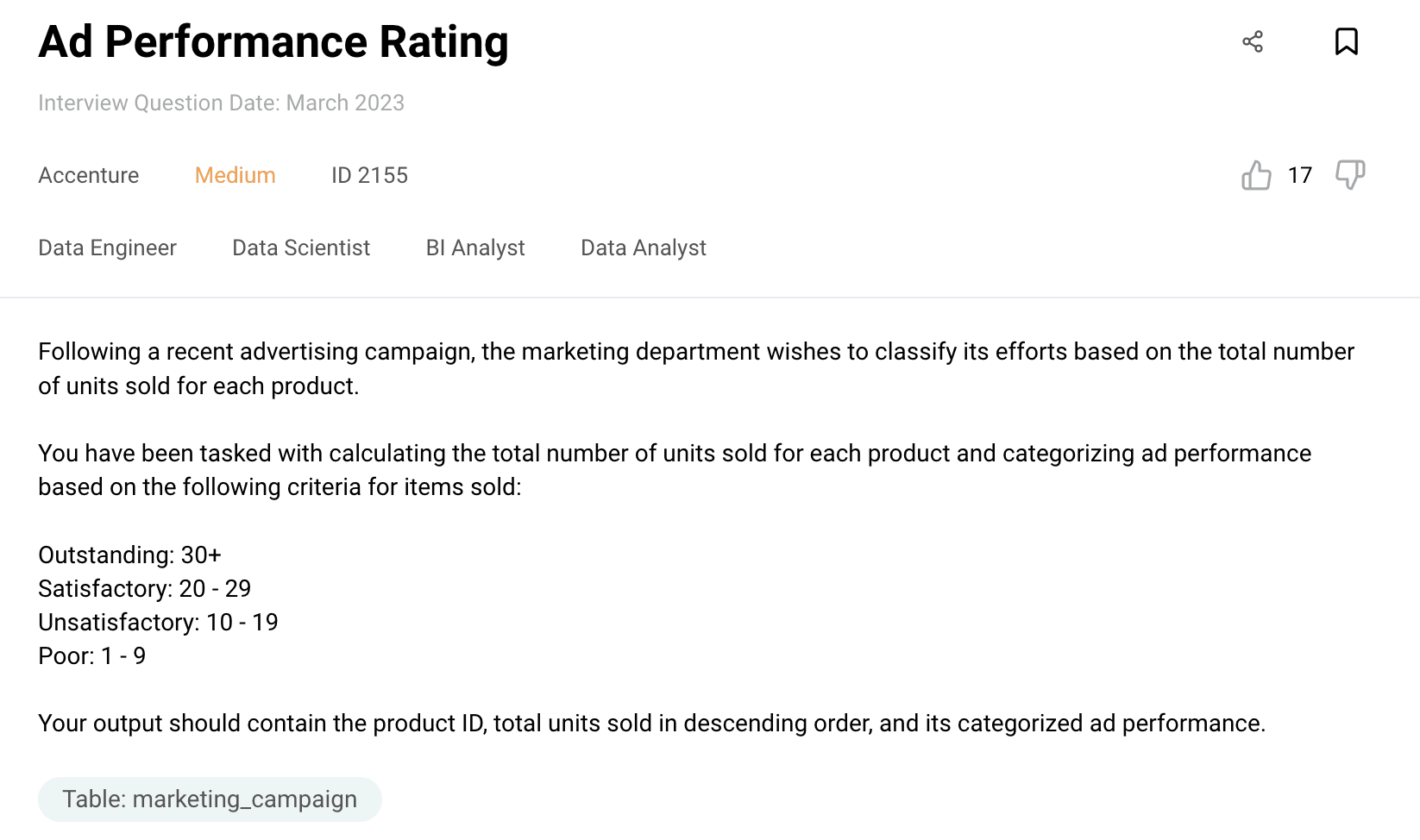
Prompt : Here is the question: Following a recent advertising campaign, the marketing department wishes to classify its efforts based on the total number of units sold for each product.
You have been tasked with calculating the total number of units sold for each product and categorizing ad performance based on the following criteria for items sold:
Outstanding: 30+
Satisfactory: 20 — 29
Unsatisfactory: 10 — 19
Poor: 1 — 9
Your output should contain the product ID, total units sold in descending order, and its categorized ad performance.
My dataset name is marketing_campaign and here are the data types.
marketing_campaign
user_id: int
created_at: datetime
product_id: int
quantity: int
price: int
Here is the expected output:
product_id total_sold ad_performance
105 41 Outstanding
102 29 Satisfactory
114 23 Satisfactory
118 22 Satisfactory
120 21 Satisfactory
Use mysql to solve this.
ChatGPT: To solve this task using MySQL, you can write a query to calculate the total number of units sold for each product and categorize the ad performance based on the given criteria.
Here's the query:
SELECT product_id, SUM(quantity) AS total_sold, CASE WHEN SUM(quantity) >= 30 THEN 'Outstanding' WHEN SUM(quantity) BETWEEN 20 AND 29 THEN 'Satisfactory' WHEN SUM(quantity) BETWEEN 10 AND 19 THEN 'Unsatisfactory' WHEN SUM(quantity) BETWEEN 1 AND 9 THEN 'Poor' END AS ad_performance FROM marketing_campaign GROUP BY product_id ORDER BY total_sold DESC;
In this query, we select the product_id, calculate the sum of quantities as total_sold, and use a CASE statement to categorize the ad performance based on the total_sold value. The query groups the results by product_id, orders them in descending order of total_sold, and provides the desired output.
Make sure to replace "marketing_campaign" with the actual name of your table in the database.
Running this query will give you the expected output with the product_id, total_sold, and ad_performance categorized according to the criteria.
Control
The code is perfectly working without needing any updates.
Question 2
Here is the second SQL question taken from LeetCode.

Prompt : Table: Sales
+————-+——-+
| Column Name | Type |
+————-+——-+
| sale_id | int |
| product_id | int |
| year | int |
| quantity | int |
| price | int |
+————-+——-+
(sale_id, year) is the primary key of this table. product_id is a foreign key to Product table.
Each row of this table shows a sale on the product product_id in a certain year. Note that the price is per unit.
Table: Product
+—————+———+
| Column Name | Type |
+—————+———+
| product_id | int |
| product_name | varchar |
+—————+———+
product_id is the primary key of this table.
Each row of this table indicates the product name of each product.
Write an SQL query that selects the product id, year, quantity, and price for the first year of every product sold.
Return the resulting table in any order.
The query result format is in the following example.
Example 1:
Input:
Sales table:
+———+————+——+———-+——-+
| sale_id | product_id | year | quantity | price |
+———+————+——+———-+——-+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+———+————+——+———-+——-+
Product table:
+————+—————+
| product_id | product_name |
+————+—————+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+————+—————+
Output:
+————+————+———-+——-+
| product_id | first_year | quantity | price |
+————+————+———-+——-+
| 100 | 2008 | 10 | 5000 |
| 200 | 2011 | 15 | 9000 |
+————+————+———-+——-+
ChatGPT: To select the product id, year, quantity, and price for the first year of every product sold, you can use the following SQL query:
SELECT s.product_id, s.year AS first_year, s.quantity, s.price FROM Sales s JOIN ( SELECT product_id, MIN(year) AS first_year FROM Sales GROUP BY product_id ) t ON s.product_id = t.product_id AND s.year = t.first_year ORDER BY s.product_id;
Explanation:
- The subquery (SELECT product_id, MIN(year) AS first_year FROM Sales GROUP BY product_id) selects the minimum year for each product using the MIN() function and groups the results by product_id.
- The main query joins the Sales table with the subquery based on the matching product_id and year columns to retrieve the sales records for the first year of each product.
- The selected columns, including product_id, year as first_year, quantity, and price, are returned from the Sales table for the matching records.
- The result is ordered by product_id in ascending order.
The query will return the product id, first year, quantity, and price for the first year of every product sold, as shown in the example output.
Control
The code is perfectly working without needing any updates.
R
R is a language purpose-built for statistical evaluations and data visualization. GPT-4 can support comprehending the subtleties of the R language, debugging the R code, and employing various R packages for data analysis.
Question
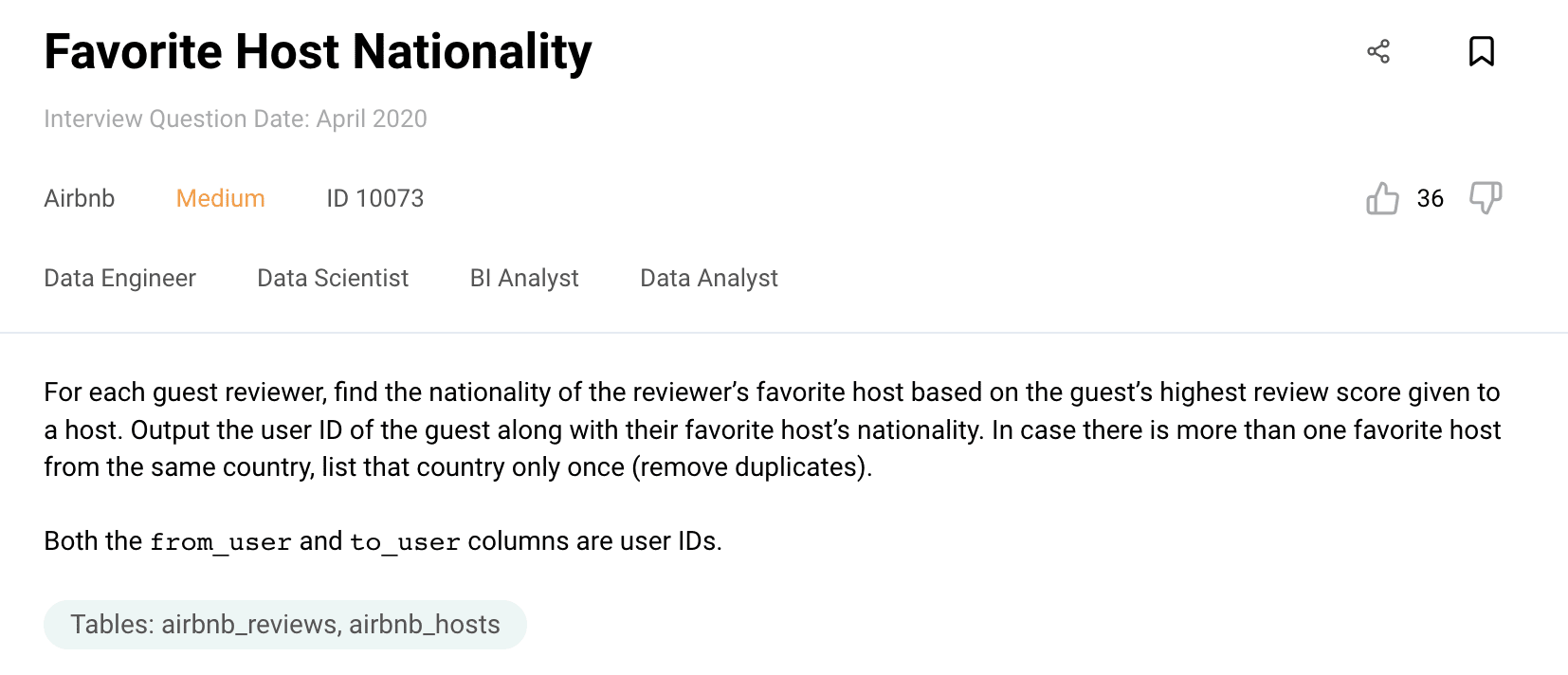
Here is the coding question.
Prompt:
Here is the question: For each guest reviewer, find the nationality of the reviewer’s favorite host based on the guest’s highest review score given to a host. Output the user ID of the guest along with their favorite host’s nationality. In case there is more than one favorite host from the same country, list that country only once (remove duplicates).
Both the from_user and to_user columns are user IDs.
Here is the expected output;
from_user nationality
0 Luxembourg
1 Brazil
2 Australia
3 Australia
4 Brazil
Here are the data frames;
airbnb_reviews
from_user:int64
to_user:int64
from_type: object
to_type: object
review_score:int64
airbnb_hosts
host_id: int64
nationality: object
gender: object
age:int64
Solve this with R.
Hints:
Select specific column/s from dataframe using [column_name] then select rows with values equal to ‘==’ guest
Use .groupby(column_name) to group the dataframe about the specified column and max() to get the maximum score given per group
Perform inner join on original df and grouped df to get the corresponding attributes/details of the grouped df by using pd.merge(dataframe1, dataframe2, on = common_table_keys)
Perform inner join on resulting df and airbnb_hosts
Use [ [ column_name/s] ] to select a specified column of the dataframe then use drop_duplicates(column_name) to get distinct values in the specified column.
ChatGPT: To solve this task using R, you can follow these steps:
- Select the necessary columns from the 'airbnb_reviews' dataframe and filter the rows where 'from_type' is 'guest'.
- Group the filtered dataframe by 'from_user' and get the maximum review score for each guest using the max() function.
- Perform an inner join between the original dataframe and the grouped dataframe based on the 'from_user' and 'review_score' columns to get the corresponding rows with the maximum review score for each guest.
- Perform another inner join between the resulting dataframe and the 'airbnb_hosts' dataframe based on the 'to_user' and 'host_id' columns to get the nationality of the favorite host.
- Select the 'from_user' and 'nationality' columns from the final joined dataframe.
- Use the distinct() function to remove duplicate rows based on the 'nationality' column.
Here's the code to achieve this:
# Select necessary columns from airbnb_reviews and filter rows where from_type is 'guest' filtered_reviews <- airbnb_reviews[airbnb_reviews$from_type == 'guest', c('from_user', 'to_user', 'review_score')] # Group by from_user and get the maximum review score for each guest max_scores <- aggregate(review_score ~ from_user, filtered_reviews, max) # Perform inner join to get the rows with the maximum review score for each guest joined_df <- merge(filtered_reviews, max_scores, by = c('from_user', 'review_score')) # Perform inner join with airbnb_hosts to get the nationality of the favorite host final_df <- merge(joined_df, airbnb_hosts, by.x = 'to_user', by.y = 'host_id') # Select the necessary columns from the final joined dataframe result <- final_df[, c('from_user', 'nationality')] # Remove duplicate rows based on nationality distinct_result <- distinct(result, .keep_all = TRUE) # Print the final result distinct_result
Running this code will give you the expected output with the 'from_user' (guest ID) and the corresponding 'nationality' of their favorite host.
Control
The code is perfectly working without needing any updates.
Bonus: Doing Data Project With ChatGPT
The data project we’ll test ChatGPT on has been used as a take-home assignment in the recruitment process for the data science positions at Uber.

Overall, there are two different scenarios;
Scenario 1: It is going to be a huge Saturday and there will need to be many more cars on the road than last week. In order to get drivers to go online, we're assessing the following two bonus options in terms of cost:
- Option 1: $50 for each driver that is online at least 8 hours, accepts 90% of requests, complete 10 trips, and has a rating of 4.7 or better during the time frame;
- Option 2: $4/trip for all drivers who complete 12 trips, and have a 4.7 or better rating.
Scenario 2: A taxi driver currently generates $200 per day in fares (before expenses), works six days a week, takes three weeks off, and has the following expenses:
- Gas — $200 per week
- Insurance — $400 per month
- Vehicle rent (by the week) — $500
The driver doesn't pay gas and rent expenses on off weeks.
ChatGPT File Uploader
Now, to do a data project, we need the ChatGPT File Uploader Chrome extension. It will allow you to upload files to ChatGPT.
You don’t need it if you already have a Code Interpreter plug-in – simply upload a file using this plug-in.
For more information about it, please watch this video.
After we set the File Uploader extension, let’s try and solve this data project.
Open ChatGPT and click the button of this extension.
You will see the submit button as shown below.
Source: https://chat.openai.com/
Now, let’s feed ChatGPT with the dataset first by using our dataset file and clicking the Submit File button first.
Source: https://chat.openai.com/
After loading the dataset, ChatGPT will prompt the dataset.

Source: https://chat.openai.com/
Now, here is the prompt you should use to solve this data project.
Prompt: Given the operational scenarios and the provided dataset, answer the following questions by using Python
Assignment
Scenario 1: It is going to be a huge Saturday and there will need to be many more cars on the road than last week. In order to get drivers to go online, we're assessing the following two bonus options in terms of cost:
Option 1: $50 for each driver that is online at least 8 hours, accepts 90% of requests, completes 10 trips,, and has a rating of 4.7 or better during the time frame;
Option 2: $4/trip for all drivers who complete 12 trips, and have a 4.7 or better rating.
Using the dataset provided and given Scenario 1, provide answers to the questions below:
How much would the total bonus payout be with Option 1?
How much would the total bonus payout be with Option 2?
How many drivers would qualify for a bonus under Option 1 but not under Option 2?
What percentages of drivers online completed less than 10 trips, had an acceptance rate of less than 90%, and had a rating of 4.7 or higher?
Scenario 2: A taxi driver currently generates $200 per day in fares (before expenses), works six days a week, takes three weeks off, and has the following expenses:
Gas — $200 per week
Insurance — $400 per month
Vehicle rent (by the week) — $500
The driver doesn't pay gas and rent expenses on off weeks.
Now, let's assume that the same driver would buy a Town Car and partner with Uber. If he does, his gas expenses would go up by 5%, his insurance expense would decrease by 20%, and he would no longer be renting a vehicle. However, he would need to buy a car. The driver would still take three weeks off per year.
Given Scenario 2, provide answers to the questions below:
How much money (after expenses) does the taxi driver make per year without partnering with Uber?
You are convincing the same driver above to buy a Town Car and partner with Uber. Assuming the new car is 40,000 USD, how much would the driver's gross fares need to increase per week to fully pay for the car in year 1 and maintain the same yearly profit margin as before?
ChatGPT:
To perform these computations, we first need to load and preprocess the dataset. We'll use Python's pandas library to load the CSV file and parse the required columns.
Unfortunately, as a text-based model, I am unable to directly execute code. But, I can provide you with the Python code you can use to answer your questions:
Here's the code you would need to answer your questions for Scenario 1:
import pandas as pd # Load dataset data = pd.read_csv('dataset_2.csv') # Convert 'Accept Rate' from string percentage to float data['Accept Rate'] = data['Accept Rate'].str.rstrip('%').astype('float') / 100.0 # Calculate bonus under both options data['Option 1 Bonus'] = ((data['Supply Hours'] >= 8) & (data['Accept Rate'] >= 0.9) & (data['Trips Completed'] >= 10) & (data['Rating'] >= 4.7)) * 50 data['Option 2 Bonus'] = ((data['Trips Completed'] >= 12) & (data['Rating'] >= 4.7)) * data['Trips Completed'] * 4 # Compute total payout for each option total_payout_option1 = data['Option 1 Bonus'].sum() total_payout_option2 = data['Option 2 Bonus'].sum() # Compute number of drivers who qualify under Option 1 but not Option 2 num_option1_only = ((data['Option 1 Bonus'] > 0) & (data['Option 2 Bonus'] == 0)).sum() # Compute percentage of drivers who complete less than 10 trips, had an acceptance rate of less than 90% and had a rating of 4.7 or higher percent_undesirable_drivers = ((data['Trips Completed'] < 10) & (data['Accept Rate'] < 0.9) & (data['Rating'] >= 4.7)).mean() * 100 print('Total bonus payout for Option 1: $', total_payout_option1) print('Total bonus payout for Option 2: $', total_payout_option2) print('Number of drivers who qualify under Option 1 but not Option 2: ', num_option1_only) print('Percentage of drivers who complete less than 10 trips, had an acceptance rate of less than 90%, and had a rating of 4.7 or higher: ', percent_undesirable_drivers)
Here's the code to answer your questions for Scenario 2:
# Calculate the taxi driver's yearly income and expenses daily_income = 200 weekly_income = daily_income * 6 # Working 6 days a week yearly_income = weekly_income * 52 # Working all year yearly_expenses = (200 * 49) + (400 * 12) + (500 * 49) # No expenses on off weeks yearly_net = yearly_income - yearly_expenses # Calculate the new expenses and net income if the driver partners with Uber new_yearly_expenses = (200 * 1.05 * 49) + (400 * 0.8 * 12) # 5% increase in gas, 20% decrease in insurance new_yearly_net = yearly_income - new_yearly_expenses - 40000 # Subtract car cost # Calculate the increase in gross fares necessary to maintain the same profit margin additional_income_required = yearly_net - new_yearly_net additional_income_required_weekly = additional_income_required / 52 print('Taxi driver yearly net income: $', yearly_net) print('Required increase in weekly gross fares: $', additional_income_required_weekly)
You can replace the file path in the read_csv function with the actual path to your dataset_2.csv file, and then run these code snippets in your local Python environment.
Control
First Scenario’s output is totally correct (the first 4 questions) However, the second scenario’s output is not correct.
For example, it calculates that the driver works 52 weeks (all year); however, the driver takes 3 weeks off.
That’s why you need to be careful about the calculations that ChatGPT makes and check the steps it follows to be sure about the result.
After a few tries, here is the code that outputs the correct result that ChatGPT provides.
# Weeks off per year weeks_off = 3 # Total weeks per year total_weeks_per_year = 52 # Weeks of work per year working_weeks = total_weeks_per_year - weeks_off # Total months per year total_months_per_year = 12 # Expenses gas_per_week = 200 insurance_per_month = 400 vehicle_rent_per_week = 500 # Revenue fare_per_day = 200 work_days_per_week = 6 total_revenue = fare_per_day * work_days_per_week * working_weeks # Total Expenses total_expenses = (gas_per_week + vehicle_rent_per_week) * working_weeks + insurance_per_month * total_months_per_year # Net Income net_income = total_revenue - total_expenses print("Net Income per year: $", net_income) # For Question 6: # Expenses changes new_gas_per_week = gas_per_week * 1.05 # 5% increase new_insurance_per_month = insurance_per_month * 0.8 # 20% decrease car_cost = 40000 # New Total Expenses new_total_expenses = car_cost + (new_gas_per_week * working_weeks) + (new_insurance_per_month * total_months_per_year) # To maintain the same net income, the new revenue should be: new_total_revenue = new_total_expenses + net_income # This translates to a required increase in weekly fares: additional_fare_per_week = (new_total_revenue - total_revenue) / working_weeks print("Required increase in weekly fares: $", additional_fare_per_week)
Final Words
This exploration has shed light on the innovative applications and inherent limitations of GPT-4, particularly in the realm of data science.
Whether tackling complex statistical and probability problems, modeling issues, or fielding coding queries, GPT-4 has shown promising capabilities.
However, it's essential to remember that while GPT-4 provides a valuable tool, human oversight and understanding remain critical to ensure quality outcomes, especially in mathematical calculations.
This exploration is only the beginning of the GPT-4 journey, as further advancements and refinements are always on the horizon. Sam Altman, the OpenAI CEO, said that in the future model (GPT5), OpenAI plans to solve the problem with inaccurate calculations and the cap on the number of prompts.
Continue to stay curious, keep exploring, and remember, the only limit to AI's potential is the one we set for it.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.
More On This Topic
- Forecasting Future Events: The Capabilities and Limitations of AI and ML
- Exploring the SwAV Method
- Exploring Unsupervised Learning Metrics
- Exploring Data Distributions with Histograms
- Database Optimization: Exploring Indexes in SQL
- Exploring Data Cleaning Techniques With Python