AI research labs, including OpenAI, have voluntarily joined forces to strengthen the safety, security, and trustworthiness of their AI products and services. Citing the importance of effective AI governance both domestically and globally, coordinated by the White House, OpenAI has released an eight-point document outlining its commitments. While the document provides a surface-level overview of the commitments, it does not delve into the specifics of how these companies plan to execute them.
One commitment revolves around developing mechanisms for users to differentiate between AI and human-generated content, be it audio or visual. However, the AI community does not have effective strategies to achieve this. For instance, announced at Google I/O, the company’s plan to watermark visual content remains in the research stage and is yet to be implemented.
“Policymakers around the world are considering new laws for highly capable AI systems. Today’s commitments contribute specific and concrete practices to that ongoing discussion. This announcement is part of our ongoing collaboration with governments, civil society organisations and others around the world to advance AI governance,” said Anna Makanju, VP of Global Affairs in the statement.
The commitments laid out by the White House align with existing laws and regulations. However, AI companies are encouraged to make additional commitments beyond the outlined guidelines.
Key safety guidelines include making red teaming mandatory for these AI companies and publicly disclosing red-teaming and safety procedures in their transparency reports. Information sharing and standardisation are also emphasised, with companies committing to joining forums or mechanisms like the NIST AI Risk Management Framework to understand safety and societal risks.
To enhance security, these companies will treat unreleased AI model weights as core intellectual property and restrict access to authorised personnel. Additionally, introducing bounty systems, contests, or prizes to encourage responsible disclosure of weaknesses and unsafe behaviours will be part of their security strategy.
The post White House and OpenAI Make Another Lackluster Commitment to Safety appeared first on Analytics India Magazine.
Open AI introduced custom instructions for ChatGPT yesterday. This feature allows users to add specific requirements to your prompts and these instructions will be ‘considered’ in every conversation going forward so users don’t have to keep repeating themselves. Will this update help the recent criticisms of their poor responses?
For months, users have taken to different platforms to complain about the lower performance of GPT-4. There is a continuous discussion on OpenAI’s own forum over the details of all the ways GPT’s performance has dropped. The company’s VP of Product, Peter Welinder, however, dismissed these claims and tweeted saying, “No we haven’t made GPT-4 dumber. Quite the opposite..” Regardless, the poor performance could be causing a decline in the number of users on the platform.
Researchers test these claims
To systematically study these assertions, researchers at Stanford University and UC Berkeley, explored how ChatGPT’s behaviour has changed over time. They published the paper on Tuesday which confirmed that GPT’s responses to questions have indeed changed over time.
The paper assesses the chatbot’s abilities in maths, code generation, problem solving and answering sensitive questions. The two time points are only a few months in March and June this year. It hasn’t been a surprise to most that the findings of the research corroborates that GPT-4’s performance has decreased in all these areas.
In Math the accuracy of the responses dropped from 97.6% to 2.4%. In code generation, the directly executable generations decreased from 52% to 10% with added errors in June. Answering sensitive questions also declined to 5% of the queries answered compared to 21% in May. Only in visual reasoning the overall performance saw a slight improvement of 2% of the exact match rate from March to June.
It is interesting to note that GPT-3.5 has improved in comparison to its successor in maths. On the whole, GPT-3.5 has also improved in answering sensitive questions and in visual reasoning from its previous benchmark.
Response to the paper
This study evaluates the variations in the behaviour over a short period of time but does not mention why this is happening.
The paper concludes GPT-4 does not do well even with the popular the popular Chain-of-Thought technique which significantly improves answers. Off late, GPT-4 did not follow this trend, skipping the intermediate steps and answering incorrectly.
The assumption of experts is that OpenAI is pushing changes continuously, fine tuning the models, and there are no methods of evaluating how this process works or whether the models are improving or regressing with the changes.
Others are discussing the inversely proportional relationship between alignment and usefulness and the increased alignment of the models along with attempts of making it faster and cheaper is contributing to its errors.
Only behaviour, not GPT-4’s Capabilities
One group of experts questioned the very basis of the paper. Simon Willison tweeted that he found the paper relatively unconvincing. He further said, “A decent portion of their criticism involves whether or not code output is wrapped in Markdown backticks or not.”
He also finds other problems with the paper’s methodology. “It looks to me like they ran temperature 0.1 for everything,” he said. “It makes the results slightly more deterministic, but very few real-world prompts are run at that temperature, so I don’t think it tells us much about real-world use cases for the models.”
Arvind Narayanan, CS professor at Princeton also explains that the paper misrepresents the GPT-4 and that to say it has degraded over time is an oversimplification of what the paper found. He also questioned the methods used by the scientists saying the capabilities of the not isn’t the same as its behaviour.
At the end of Arvind’s analysis he says, “In short, the new paper doesn’t show that GPT-4 capabilities have degraded. But it is a valuable reminder that the kind of fine tuning that LLMs regularly undergo can have unintended effects, including drastic behaviour changes on some tasks. Finally, the pitfalls we uncovered are a reminder of how hard it is to quantitatively evaluate language models.”
It makes it even more difficult to assess language models when ones like OpenAI take a closed approach to AI. Sam Altman refuses to reveal the source of training materials, code, neural network weights or even the architecture of the model. Leaving the rest of us to only speculate and arrive at the results through anonymous sources. This leaves researchers to grope in the dark to define the properties of the system they’re trying to evaluate.
Learn to Prompt Better
Good prompts are the antidote to the sickness GPT is going through. It arguably might have gotten worse over time in but the only way to get the responses you need is to make sure your giving it the right prompts. There are multiple courses online that takes you through prompts for specific tasks. In addition understanding how each language models are trained improves your chances with formulating better prompts. Simple yet effective practices include being specific, asking for a step by step explanation, including context, mentioning tone, style and examples improve the responses.
The post ChatGPT is NOT Getting Dumber, You Are appeared first on Analytics India Magazine.
Meta has been touted as the biggest proponent of open source. Building on the success of LLaMa, the company decided to partner with Microsoft and release Llama 2, an “open source” model for commercial use. In just two days, the entire AI ecosystem has been discussing how Meta is building an open source community, while OpenAI is keeping its technology closed.
Interestingly, diving deeper into the release, it does not take much searching to realise that Llama 2 is not exactly open source. According to the commercial licence put forth by the company, any company that is going to use Llama 2 with an active monthly user base of 700 million or more would be required to “request” to gain access to the model.
This means that Meta has the right to finally decide if a company will be given access to Llama 2 or not. In such a situation, Meta said the only way for a large company or platform to use Llama 2 is if it “expressly grants you such rights.” OSI has clearly stated that the Llama 2 licence agreement does not qualify open source definition at all and to “watch their language.”
In case there was any doubt, LLaMA 2 is NOT open source as confirmed by the Open Source Initiative. As much as I appreciate Meta's openness compared to others, I find this misleading marketing a bit irritating. https://t.co/juH80kgdOh
— Mikel Artetxe (@artetxem) July 19, 2023
So while companies like Google, Amazon, or Apple, even large governments, would try to use Llama 2 to build their own generative AI technology, Meta can just say “no”. People would have to stick to training their models on their own or probably use GPT produced data to build their models.
Most of the people using Llama 2 wouldn’t have 700 million users now. A Meta spokesperson clarified that companies using Llama 2 to reach 700 million users would not be restricted to use the model afterwards as well. However, that is not yet clear on the licence policy, no one has yet reached that mark, so it is just about trusting the word of mouth.
Meta’s release of Llama 2 speaks again and again about how the company aims to “democratise generative AI” by giving it to the open source community. But if the only big tech benefactor is Microsoft with this, it is not exactly open source but just a bid to overthrow the leadership of OpenAI.
Dethrone and overthrow
Apple recently announced that it is building its own chatbot. There are speculations around what data the company would use to train its model. On the other hand, people on Twitter were also discussing how Apple has always been using the open source community and contributing nothing in return. Meta with its licensing rules has made it impossible for Apple to copy and take the quick route.
When it comes to dethroning ChatGPT or OpenAI, the partnership that the company has achieved with Microsoft might help them do that. But interestingly even here, Meta has made a sly move here as well. Though it is not explicitly mentioned in the paper, it is possible that Llama 2 is actually trained on GPT-4 output to train its behaviour. The paper reads that “Llama 2 has taken help of a large model for fine-tuning,” along with also citing that it has been trained on open source data – which includes GPT generated data on the internet.
Microsoft’s partnership with Meta has another malevolent angle to it. While Microsoft has made sure that OpenAI has an exclusive partnership with it, Meta can act as a poster boy of open source for Microsoft. This means that all OpenAI services and capabilities are exclusively available on Azure Cloud. Ensuring that OpenAI’s technology remains closed source, the secret sauce of GPT is exclusively held by Microsoft, while Meta will continue innovation for them.
On the other hand, Microsoft has made no such promise. It has decided to partner with Meta for its open source and smaller technology, while keeping OpenAI at bay. The ChatGPT maker will continue its focus on building AGI, while Microsoft will find more use cases of Llama 2, a model built by a possible dependency on OpenAI’s model.
“We are (not) democratising AI”
In the tech ecosystem, democratisation would just mean open sourcing the technology for everyone to equally use it however they want. But Meta’s approach of restricting it for some users which are its competitors sounds like an anti-democratic, or in this sense communistic approach.
Interestingly, Meta has the highest number of open source contributions compared to any big tech with a total number of 689 repositories, while Microsoft has only 252. Seems like Microsoft has actually pushed Meta to do this.
Open source Llama 2 is clearly a good thing for 99% of the companies and almost all the startups. They can use the small models, fine-tune it on their proprietary data and achieve their use cases. Moreover, the data can also be generated by GPT models, which is already available on the internet.
Companies using OpenAI APIs through Azure would realise that instead of spending so much for the Microsoft services, they can just build on top of Llama 2. The only downside would be the lack of available NVIDIA GPUs, something that the companies wouldn’t have to worry about while using the APIs.
All in all, Meta was clearly playing the good guy in generative AI by siding with open source. Google and OpenAI apparently did not have a moat, and Microsoft tapped into that and got the open source leader under its belt. Now, while the world might continue criticising OpenAI for being closed doors, Microsoft can play the good guy with Meta.
All this while they keep Llama 2 for everyone, including Microsoft, but no other big tech company. Sounds like a communist approach.
The post Llama 2 is Communist appeared first on Analytics India Magazine.
LLMs are an ethical nightmare and band-aid solutions are nowhere to be found. As users struggle with problematic outputs of language models, researchers have been striving to solve them one-by-one.
A collectively authored research paper, from Stability AI, Meta AI Research and others have established a set of open problems so that ML researchers can comprehend the field’s current state quicker and become more productive. The paper discusses the design, behaviour, and the science behind the models rather than the political, philosophical, or moral aspects of it.
Furthermore, the authors have identified 11 domains where LLMs have successfully been applied. Across these, we provide an overview of existing work as well as constraints we identify in the literature. The research aims to provide a map to focus on for future research.
Issues Raised
“People often think the machine learning algorithms introduce bias. Fifty years ago, everybody knew ‘garbage in garbage out’. In this particular case, it is ‘bias in, bias out’,“ a veteran data scientist and Turing Award laureate Jeffrey Ullman told AIM. On the same lines, the research paper addresses the first challenge of ‘Unfathomable data’.
The next issue the paper addresses is tokenization – the process of breaking a sequence of words or characters into smaller units. For instance, the number of tokens necessary to convey the same information varies significantly across languages, making the pricing policy of API language models unfair. For instance, the price of generating 800 words using the Ada model, the Hindi translation would require nearly 7X of tokens as well as 7X of the pricing in comparison to the same produced in English. For a language like Kannada, the pricing is 11X more than English.
The pricing factor is not just restricted to tokens as a hefty price is paid for training these models. A few months ago, the estimated price for training a language model like GPT 3 was estimated to be $5 million. The researchers suggest, while selecting the model size, computation resources for later usage should be taken into consideration rather than one time training cost.
Next is the issue with context length that causes a barrier for models to handle long inputs well to facilitate applications like novel or textbook writing or summarising. Very recently AI researchers stopped obsessing over model size and set their eyes on context size. The model size debate has been settled for now – smaller LLMs trained on much more data have eventually proven to be better than anything else that we know of. But then the painful task of fine-tuning models on individual downstream tasks (e.g., for text classification or sequence labelling) comes in the way.
The paper then talks about other issues like prompt brittleness — variations of the prompt syntax, often occurring in ways unintuitive to humans, can result in dramatic output changes, alignment bias, and hallucinations. The researchers also take into account the issues with the current methods of evaluating and benchmark tests for language models.
Since ChatGPT has become an internet celebrity, differentiating between human generated and produced by AI has become close to impossible. As a probable solution, AI detection tools are available all over the internet and companies like Google have also announced plans to label metadata and watermark AI generated content on its websites.
Anyone who has used ChatGPT or any AI powered chatbot knows that a prompt can generate different outputs just by moving a word here and there. Developing LLMs that are robust to the prompt’s style and format remains unsolved, leaving practitioners to design prompts ad-hoc rather than systematically.
Solutions Offered
Everyone from startups to big tech companies are trying to solve the pertaining issues in language models. The most common problem users have been pointing out since day one is the hallucinatory nature of these models leading them to generate factually incorrect information. Open source messiah Hugging Face has also raised red flags as the hallucination problem can further develop into a snowball.
Furthermore, talking about ‘aligned research’ OpenAI’s models follow human intent, along with human values. “At the time [2014], this problem was almost completely neglected, but it is now becoming increasingly recognized by more mainstream AI researchers,” resonated philosopher Nick Bostrom in an interview with AIM. Today, even Google has a 34-page elaborate document on ways the tech giant is tackling the issue of AI governance.
The research also states that the capability gap between fine tuned closed-source and open-source models pertains. With models the Vicuna, Stanford’s Alpaca, and Meta’s (leaked) LLaMA the gap has definitely narrowed but no model has proven to be an equal competitor of OpenAI’s GPT4.
The authors of ‘Challenges and Applications of Large Language Models’ conclude that the problems pinpointed in the research remains unsolved. Apart from serving as a guideline for further research of language models, the research paper also highlights the lack of training regulation and the need for stakeholders to step in.
The post LLMs are an Ethical Nightmare appeared first on Analytics India Magazine.
Infosys, the second-largest IT services company in India, announced its financial results for the first quarter. The company reported a notable 11% increase in net profit, amounting to ₹5,945 crore, compared to ₹5,360 crore during the same period last year. However, Infosys had to lower its FY24 revenue guidance from 4-7% to a much lower range of 1-3.5% due to challenges in the demand environment.
In terms of regional revenue growth during the June quarter, Infosys experienced a positive 10.9% year-on-year growth in Europe and a 9.3% growth in India. However, revenue growth in North America was only at 2.3% YoY, while the ‘rest of the world’ segment faced a decline of 4.5% YoY. The company added 99 new clients during Q1FY24, reaching 1,883 active clients as of June 30, 2023.
Among the verticals, the financial services and communication segments reported a 4.7% and 6.1% YoY drop in revenue, respectively. In contrast, the manufacturing segment showed a healthy growth of 21.3% YoY, while the life sciences segment rose significantly by 14.9% YoY. The ‘others’ segment revenue also increased by 28% YoY. However, the retail and hi-tech segments saw relatively sluggish growth in Q1FY24.
Infosys’ CEO and MD, Salil Parekh, expressed satisfaction with the company’s solid Q1 performance, highlighting the 4.2% growth and the success of large deals worth $2.3 billion, which set a strong foundation for future growth. Additionally, he mentioned the development of generative AI tools based on an open-source model, with 40,000 employees trained in these areas.
“Our generative AI capabilities are expanding well, with 80 active client projects. Topaz, our comprehensive AI offering, is resonating well with clients. We see this being transformative for clients and enhancing our overall service portfolio” said Salil Parekh, CEO and MD.
“We have expanded the margin improvement program with a holistic set of actions for the short, medium and long-term, working on five key areas, supported by our leadership team”, he added.
Effects on the Market
However, the sharp downward revision of FY24 revenue guidance led to a significant drop in Infosys’ ADRs in the pre-market session on the NYSE, falling nearly 9%.
The company’s management aims to improve its operating margin in the future. The attrition rate improved to 17.3%, but the headcount of employees declined compared to the previous quarter.
During the opening deals today, the company’s stock experienced a significant decline of 9%, reaching Rs 1,311.60 on the BSE.
Analysts have mixed opinions on Infosys’ stock, with some expressing concern over the steep cut in the FY24 revenue outlook. Nevertheless, the company’s Q1FY24 revenue growth is expected to be positive, with moderate improvement in upper-end sales growth for 2023-24.
For instance, Motilal Oswal Securities stated in its earnings review that while the guidance cut is concerning and could have a negative impact on the share price in the short term (partly due to the 11% gain in the last month), they believe the miss is more related to perception rather than operational issues, as the earlier guidance was overly optimistic given the current business environment.
Conclusively, Infosys reported an increase in net profit for Q1FY24, but due to challenges in the demand environment, the company lowered its revenue guidance for FY24. Despite this, the company secured significant deals and expressed optimism about its generative AI capabilities. The ADRs experienced a sharp decline in response to the revised guidance. The management aims to enhance the operating margin, and analysts have varying opinions on the company’s stock performance.
The post Infosys’ NYSE, BSE Listings Witness 9% Drop as it Lowers FY24 Revenue Guidance appeared first on Analytics India Magazine.
Meta is making its Llama 2 large language model open source, the Facebook parent company announced on July 18. The update to the model, which had been released as the first-generation LLaMA (also stylized as Llama 1) in February 2023, was first revealed at the Microsoft Inspire event. Microsoft will be a preferred partner with Meta on Llama 2.
Jump to:
What is Llama 2?
Where is Llama 2 available?
What does Llama 2 say about competition in the generative AI business space?
What is Llama 2?
Llama 2 is a large language model that can be used to create generative and conversational AI models. Put simply, Llama 2, like GPT-4, can be used to build chatbots and AI assistants for commercial or research purposes.
It runs on a collection of pre-trained and fine-tuned generative text models that vary in scale from 7 billion to 70 billion parameters, and 2 trillion tokens of data from publicly available sources went into its pre-training. Overall, that’s 40% more tokens than were used to train the original Llama.
Llama 2 can be downloaded for research and commercial use from Meta here. The open-source resources available include model weights and starting code for the pre-trained model as well as fine-tuned versions of the conversational AI.
“Opening access to today’s AI models means a generation of developers and researchers can stress test them, identifying and solving problems fast, as a community,” Meta wrote in a blog post about Llama 2. “By seeing how these tools are used by others, our own teams can learn from them, improve those tools, and fix vulnerabilities.”
Developers who already have accounts with Microsoft’s Azure AI model catalog will be able to access Llama 2 from there. It can be found on Amazon Web Services, Hugging Face and other AI marketplaces. AWS customers should look for it in the machine learning marketplace SageMaker.
“Meta’s announcement of the model being available in AWS and Microsoft Azure is a huge step for them, showing an ambition to be an enterprise player in the generative AI space,” Gartner analyst Arun Chandrasekaran commented in an email to TechRepublic.
Meta partners with Qualcomm for on-device AI
Qualcomm will install Llama 2 on select devices in 2024. The exact device models this will apply to have not yet been revealed, but Qualcomm has said these will be devices powered by Snapdragon processors. Qualcomm aims to run the language model on some devices directly, not always on the cloud.
“We applaud Meta’s approach to open and responsible AI and are committed to driving innovation and reducing barriers-to-entry for developers of any size by bringing generative AI on-device,” said Durga Malladi, senior vice president and general manager of technology, planning and edge solutions Qualcomm, in a press release. “To effectively scale generative AI into the mainstream, AI will need to run on both the cloud and devices at the edge, such as smartphones, laptops, vehicles, and IoT devices.”
What does Llama 2 say about competition in the generative AI business space?
Opening Llama 2 up and locking in a partnership with Microsoft could be a sign that Meta is trying to remain competitive with GPT-4. OpenAI’s GPT-4 is also free to use and is the model behind ChatGPT, which Microsoft has bet on in a big way. Google also has a horse in the ring with the PaLM model behind Bard.
“This is going to change the landscape of the LLM market,” Meta’s Chief AI Scientist Yann LeCun said on Twitter.
How the connection with Meta might shift Microsoft’s deals with OpenAI is unclear as of now, but “the partnership with Meta could open newer opportunities for them,” Chandrasekaran said. “The Llama 2 models can potentially drive demand for Azure’s IaaS and operational tools as customers seek to fine-tune these models and build business applications on top of them,” he added.
Making the model open source could be a sea change, too. “By releasing Llama 2 and licensing it for commercial use, Meta might be providing a huge boost to the open-source community,” Chandrasekaran said. “Today, arguably the closed source models have a performance advantage over open-source models, but Llama has the potential to narrow that gap in the mid to long term.”
Subscribe to the Innovation Insider Newsletter
Catch up on the latest tech innovations that are changing the world, including IoT, 5G, the latest about phones, security, smart cities, AI, robotics, and more.
There needs to be collective global efforts to govern artificial intelligence (AI), where common consensus on the guardrails needed is urgent.
Amid calls for different global measures and initiatives, AI governance will prove complex and requires a universal approach, said United Nations (UN) Secretary-General António Guterres. AI models already are widely available to the public and, unlike nuclear material and biological agents, its tools can be moved without leaving a trace, Guterres said in his remarks to the UN's Security Council.
Also:WormGPT: What to know about ChatGPT's malicious cousin
Members of the council had gathered this week for its first formal meeting on AI, where speakers included Anthropic's co-founder Jack Clark and Chinese Academy of Sciences' Institute of Automation, Zeng Yi, who is a professor and director of the International Research Center for AI Ethics and Governance.
Describing generative AI as a "radical advance" in capabilities, Guterres said the speed and reach that the technology gained had been "utterly unprecedented," with ChatGPT hitting 100 million users in just two months.
But while AI had the potential to significantly fuel global development and realize human rights, including in healthcare, it also could push bias and discrimination, he said. The technology could further enable authoritarian surveillance.
He urged the council to assess the impact of AI on peace and security, stressing that there already were humanitarian, ethical, legal, and political concerns.
Also:GPT-4 is getting significantly dumber over time, according to a study
"[AI] is increasingly being used to identify patterns of violence, monitor ceasefires, and more, helping to strengthen our peacekeeping, mediation, and humanitarian efforts," Guterres said. "But AI tools can also be used by those with malicious intent. AI models can help people to harm themselves and each other, at massive scale."
As it is, AI already has been used to launch cyberattacks targeting critical infrastructures. He noted that military and non-military AI applications could lead to serious consequences for global peace and security.
Clark backed the need for global governments to come together, build capacity, and make the development of AI systems a "shared endeavor," rather than one led by a handful of players vying for a share of the market.
"We cannot leave the development of AI solely to private sector actors," he said, noting that the development of AI models such as Anthropic's own Claude, OpenAI's ChatGPT, and Google Bard are guided by corporate interests. With private-sector companies having access to sophisticated systems, large data volumes, and funds, they likely will continue to define the development of AI systems, he added.
Also:This is how generative AI will change the gig economy for the better
This could result in both benefits and threats due to the potential for AI to be misused and its unpredictability. He explained that the technology could be used to better understand biology as well as to construct biological weapons.
And when AI systems have been developed and implemented, new uses for them could be uncovered that were not anticipated by their developers. The systems themselves also might exhibit unpredictable or chaotic behavior, he said.
"Therefore, we should think very carefully about how to ensure developers of these systems are accountable, so that they build and deploy safe and reliable systems that do not compromise global security," Clark said.
The emergence of generative AI now could further push disinformation and undermine facts, bringing with it new ways to manipulate human behavior and leading to instability on a massive scale, Guterres said. Citing deepfakes, he said such AI tools could create serious security risks if left unchecked.
Also:The best AI chatbots
Malfunctioning AI systems also were a significant concern, as was "deeply alarming" the interaction between AI and nuclear weapons, biotechnology, neurotechnology, and robotics, he added.
"Generative AI has enormous potential for good and evil at scale. Its creators themselves have warned that much bigger, potentially catastrophic and existential risks lie ahead," he said. "Without action to address these risks, we are derelict in our responsibilities to present and future generations."
New UN entity needed to govern AI
Guterres said he supported calls for the creation of a UN entity to facilitate collective efforts in governing AI, similar to the International Atomic Energy Agency and Intergovernmental Panel on Climate Change.
"The best approach would address existing challenges while also creating the capacity to monitor and respond to future risks," he said. "It should be flexible and adaptable, and consider technical, social, and legal questions. It should integrate the private sector, civil society, independent scientists, and all those driving AI innovation."
Also:AI and advanced applications are straining current technology infrastructures
"The need for global standards and approaches makes the United Nations the ideal place for this to happen," he added.
The new UN body should aim to support nations in maximizing the benefits of AI, mitigate the risks, and establish international mechanisms for monitoring and governance. The new entity also would have to collect the necessary expertise, making it available to the international community, and support research and development efforts of AI tools that drive sustainability.
Guterres said he was putting together a "high-level advisory board for AI" to get things started, with the aim to recommend options for global AI governance by year-end.
He added that an upcoming policy brief on "a new agenda for peace" also would encompass recommendations on AI governance for UN member states. These include recommendations for national strategies on the responsible development and use of AI, as well as multilateral engagement to develop norms and principles around military applications of AI.
Member states also would be asked to agree to a global framework to regulate and boost oversight mechanisms for the use of data-driven technology, including AI, for counterterrorism purposes.
Negotiations for the policy brief are targeted for conclusion by 2026, by which a legally binding agreement will be established to outlaw lethal autonomous weapons that operate without human oversight, he said.
Clark also called on the international community to develop ways to test the systems' capabilities, misuses, and potential safety flaws. He said it was assuring that several nations had focused on safety evaluation in their AI policy proposals, including China, the EU, and the US.
He further underscored the need for standards and best practices on how to test such systems for key areas such as discrimination and misuse, which currently were lacking.
Zeng noted that current AI systems, including generative AI, were information processing tools that seemed intelligent but had no real understanding.
"This is why they cannot be trusted as responsible agents that can help humans to make decisions," he noted. Diplomacy tasks, for instance, should not be automated. In particular, AI should not be applied to foreign negotiations among different nations, since it may amplify human limitations and weaknesses to create bigger risks.
"AI should never ever pretend to be human," he said, while urging for the need for adequate and responsible human control of AI-powered weapons systems. "Humans should always maintain and be responsible for final decision-making on the use of nuclear weapons."
Also:ChatGPT and the new AI are wreaking havoc on cybersecurity in exciting and frightening ways
Global stakeholders now have a window of opportunity to unite in discussions concerning the guardrails needed for AI, said Omran Sharaf, the United Arab Emirates' assistant minister for advanced sciences and technology.
Before "it is too late," he urged member states to come to a consensus on the rules needed, including mechanisms to prevent AI tools from pushing misinformation and disinformation that could fuel extremism and conflict.
Similar to other digital technologies, the adoption of AI should be guided by international laws that must apply in the cyber realm, Sharaf said. He noted, though, that regulations should be agile and flexible, so they would not hamper the advancement of AI technologies.
Generative AI models such as ChatGPT have the potential to revolutionize many different industries and optimize business practices in a way that improves productivity. OpenAI says it's now attempting to use AI to boost local news.
In a $5 million partnership with the American Journalism Project (AJP), OpenAI commits to supporting the expansion of AJP's work, exploring ways that AI can support the local news sector and helping local levels fight disinformation.
Also: WormGPT: What to know about ChatGPT's malicious cousin
The AJP is a venture philanthropy organization founded in 2019 whose mission is to help local news thrive and address market failure in local news.
"In these early days of generative AI, we have the opportunity to ensure that local news organizations, and their communities, are involved in shaping its implications. With this partnership, we aim to promote ways for AI to enhance — rather than imperil — journalism," said Sarabeth Berman, CEO of AJP in the release.
AJP says it will use the funds to experiment with AI by creating a technology and AI studio made up of a team who will evaluate AI applications within local news, find the best ways to leverage AI, and act as an intermediary between external vendors such as OpenAI and AJP's portfolio.
With the funds, AJP will also make pilot investments, giving approximately ten of its portfolio organizations direct grants to help them explore AI's potential as well.
In addition to the initial $5 million, OpenAI is also gifting AJP and its portfolio organizations $5 million in OpenAI API credits to help them access, build, and use the technologies.
Also: Google pitched a news-writing AI tool to New York Times, Washington Post
This partnership is interesting because ChatGPT hasn't had a very symbiotic relationship with the news sector since its launch.
OpenAI trained its models with the entirety of the internet, including all the news content ever published online.
This implications here are twofold. OpenAI never asked the publications for their permission to use their content for its AI training, and most importantly, the publications and authors don't get credited when their research and work is cited by the chatbot.
The Washington Post compiled a list of websites that were used to train ChatGPT and make it as smart as it is. 13% of the millions of websites it was trained on were in the News and Media category, including ZDNET.
Also: GPT-4 is getting significantly dumber over time, according to a study
One way OpenAI could support local news, and the news sector in general, is by linking to and crediting the organizations for their information which the authors had to research and work for.
In turn, the news publications could get more traffic, increasing their revenue and allowing for the creation of further stories to potentially create a more mutually beneficial relationship between news publications and AI.
Getting your ideal answer from ChatGPT is a difficult skill to perfect. Usually, you have to carefully craft your initial response and then follow up with a couple more prompts to get the end result you envisioned. This new update will speed up that process.
On Thursday, ChatGPT announced "custom instructions" that will allow users to set preferences that tailor how ChatGPT generates its responses.
Also: OpenAI commits $5 million dollar to support local news. Here's the irony
The instructions will be kept under consideration by ChatGPT when producing responses for every conversation after so you don't have to put the same preferences in over and over.
The release includes a demo that shows the two fields that users will be able to fill in for the custom instructions: "What would you like ChatGPT to know about you to provide better responses?" and "How would you like ChatGPT to respond?".
OpenAI uses the examples of a third-grade teacher developing a lesson plan, a developer wanting code in a language other than Python, and a family of six dinner planning to show how custom instructions can help workflow.
In all three cases, the users would be able to set the conditions once in the beginning and then get the results they want for their specific tasks over and over without having to do any tweaking or unnecessary repeating.
Also: GPT-4 is getting significantly dumber over time, according to a study
For example, the developer would only have to delineate once that they are a software developer only using golang, want all of their responses to be in the language, want code with no explanations and bias towards the most efficient solution.
This feature essentially eliminates some of the challenges of prompt writing and makes it easier to get intended results faster, increasing chatbot assistance.
The feature is still in beta and only available for ChatGPT Plus users starting today. However, OpenAI says it will be expanding to all users in the upcoming weeks.
20 Years into the Future: Splunk Conference Showcases New AI and Edge Solutions July 20, 2023 by Jaime Hampton
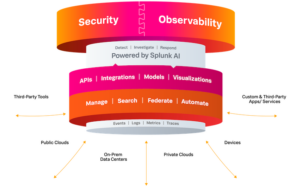
At its .conf23 event in Las Vegas this week, Splunk unveiled a collection of new AI-powered tools across its portfolio of security and observability solutions.
Splunk is celebrating its 20th anniversary this year. Splunk CEO Gary Steele, who joined the company in March 2022, acknowledged in a keynote how much the digital world has changed since the company’s launch.
“If you go back in a time machine 20 years and think about what it was like when Splunk got founded, the cloud journey really hadn’t happened yet. There hadn’t been a big breach. The digital footprint for most organizations hadn’t been transformed yet,” he said on stage. “It was a really different time, and through that course of 20 years, Splunk has been with you and evolved and changed. One of the things that I’m excited about as I stand here today, roughly 15 months into my job, is the importance of driving Splunk forward over the next 20 years.”
Splunk AI
Like many companies right now, Splunk appears to be betting on AI as the next revolution in tech. The new suite of AI tools, dubbed Splunk AI, provides a series of intelligent assistants that help security operations, IT operations, and engineering teams be more productive and effective in their everyday work. The new release enables teams to automatically mine data, detect anomalies and prioritize critical decisions through intelligent assessment of risk, helping to minimize repetitive processes and human error, the company said.
Splunk is advancing its AI implementation using a strategy guided by three main principles: domain-specific customization for security and observability, a “human in the loop” approach to aid decision making in crucial digital systems, and an open and extensible model allowing integration with customer and partner systems for flexible solutions.
Splunk CTO Min Wang explained in a blog post how AI can help detect important events by automatically mining data to better surface key events and signals, and it can provide context and situational awareness with intelligent event summarization and interpretation while accelerating learning curves.
“Productivity and efficiency can drastically increase by freeing users from basic tasks and allowing them to focus on higher-value initiatives. We believe the benefits of AI far outweigh the downsides and are increasing our investments in taking our trusted AI capabilities even further,” wrote Wang.
One new release is the Splunk AI Assistant which the company says leverages generative AI to provide an interactive chat experience and helps users write in Splunk’s proprietary programming language, Splunk Processing Language (SPL), using natural language prompts. The AI chatbot can also write or explain custom SPL queries.
(Source: Splunk)
The company has also updated its IT Service Intelligence with a 4.17 release that includes features for outlier exclusion and adaptive thresholding. This helps to detect and omit irrelevant data points or outliers, such as insignificant network disruptions, to provide more accurate and actionable detection. A new machine learning-assisted thresholding capability in preview allows for dynamic thresholds based on historical data patterns.
Other new releases show that Splunk is bolstering its AI and ML offerings for anomaly detection and analytics. The Splunk Machine Learning Toolkit (MLTK) 5.4, which has garnered over 200k downloads on Splunkbase, provides users of all levels with guided access to ML technology, facilitating richer insights through predictive analytics and forecasting techniques, the company claims. The release builds on Splunk’s open and extensible AI model, allowing customers to incorporate externally trained models.
Additionally, the Splunk App for Data Science and Deep Learning (DSDL) 5.1, now available on Splunkbase, expands MLTK's capabilities by providing additional data science tools and integration options for advanced custom machine learning and deep learning systems. This latest version also includes two AI assistants to assist customers in utilizing LLMs for natural language processing, training models with domain-specific data.
“Splunk’s purpose is to build a safer, more resilient digital world, and this includes the transparent usage of AI,” said Wang in a statement. “Looking forward, we believe AI and ML will bring enormous value to security and observability by empowering organizations to automatically detect anomalies and focus their attention where it’s needed most. Our Splunk Al innovations provide domain-specific security and observability insights to accelerate detection, investigation and response while ensuring customers remain in control of how AI uses their data.”
Splunk Edge Hub
The Splunk conference also revealed a new solution for edge computing. The Splunk Edge Hub is a new offering for ingesting and analyzing data generated by sensors, IoT devices and industrial equipment. Splunk Edge Hub streams this hard-to-access data directly into the Splunk platform and is supported by different partner solutions to work with the platform’s predictive analytics capabilities.
Edge computing is helping companies bring data transfer and storage closer to the sources of data for improved response times and to save bandwidth, but sorting relevant data out of the mountain of data created by multiple physical and virtual sources can be complex and costly, Splunk says.
The Splunk Edge Hub is roughly the size of an Apple TV. (Source: Splunk)
The company is positioning the Splunk Edge Hub as a streamlined way to collect and analyze this edge data to break down data silos. Splunk says customers can use the device right out of the box, either placed in a physical environment or on top of existing OT hardware to immediately collect, collate and stream data to the Splunk platform.
In a press briefing, Splunk SVP of Products and Technology Tom Casey explained the new device’s significance: “Splunk edge hub is groundbreaking. It breaks down barriers in silos that historically made it difficult to extract and integrate data from your operating environment. And with some new abilities that it provides, it's much easier to access that data, integrate it, and gain visibility to it in a common way using the normal Splunk tools and dashboards that people have in their environments already.”
Casey went on to describe how the device monitors operational environment factors like temperature, humidity, vibration, and water damage to identify potential issues before production is impacted. The Splunk Edge Hub performs predictive analytics directly on the device to identify anomalies in the manufacturing process in real time, thus aiding in equipment maintenance to avoid outages. The Edge Hub will be immediately available in the US and the Americas, Casey said.
"Strategic Maintenance Solutions is thrilled to announce our partnership with Splunk to deliver the all-new Edge Hub,” said Jason Oney, President of Strategic Maintenance Solutions. “The Edge Hub enables us to provide our customers with an end-to-end solution for accessing industrial sensor, maintenance, and operations data at scale. With minimal configuration needed, data can now be seamlessly streamed into the Splunk Platform, allowing our customers to quickly start down the Industrial Transformation journey.”