AI’s Unstoppable Momentum Leaves Some Enterprise IT Teams Scrambling: AMD August 18, 2023 by Jaime Hampton
AMD has released findings from a new survey of global IT leaders suggesting some are finding it challenging to keep up during the recent AI boom: Close to half (46%) of respondents say their organizations are not ready to implement AI, and just 19% say they will prioritize AI within the next year.
The report is based on an AMD-commissioned survey of 2,500 IT leaders from the United States, United Kingdom, Germany, France, and Japan. The survey was launched with the goal of understanding how AI technologies are re-shaping the workplace, how IT leaders are planning their AI technology and related client hardware roadmaps, and what their biggest challenges are for adoption.
AMD says AI could be moving faster than enterprises can handle. Despite 97% of those surveyed being familiar with AI, many lack first-hand experience using the latest AI applications, the company noted. For example, over 50% of respondents said they have not yet experimented with the latest natural language processing applications, while 47% and 36% say the same for facial recognition systems and process automation software, respectively.
IT leaders are also uncertain about AI adoption timelines, citing a lack of AI implementation roadmaps and the overall unreadiness of their existing hardware and technology stack.
Another roadblock is the potential security risks of AI. Though AI can improve the automated detection of security risks, 67% of IT leaders are worried AI tools could introduce a new type of risk to security and governance policies. Training is also a barrier, as the full scope of AI implementation across the enterprise has yet to unfold. For some organizations, a lack of skilled staff with AI knowledge is hindering progress.
AMD says IT leaders are recognizing how AI can help meet operational demands like security and efficiency. (Source: AMD)
Despite AI’s associated challenges, the survey also reflected optimism. Three in four IT leaders are optimistic about the potential benefits of AI and more than two in three are increasing AI technology investments.
Out of the organizations that reported prioritizing AI deployments, 90% are seeing increased workplace efficiency. This is a good omen for early adopters, as AMD says those who delay implementing AI solutions risk being left behind. Of those who are optimistic about AI, nearly 75% said they believe that not investing in AI is a bigger risk.
Investment in AI projects is increasing, as over two-thirds of surveyed IT leaders reported amassing a budget for AI implementation. Respondents believe new AI tech can address operational issues like security and efficiency, and seven out of ten say AI can improve the automated detection capabilities of cybersecurity threats. The top priorities of those surveyed included increasing system speed and performance (66%) and enhancing data privacy and security (60%).
“There is a benefit to being an early AI adopter,” said Matthew Unangst, senior director of commercial client and workstation, AMD. “IT leaders are seeing the benefits of AI-enabled solutions, but their enterprises need to outline a more focused plan for implementation or risk falling behind. Open software ecosystems, with high-performance hardware, are essential, and AMD believes in a multi-faceted approach of leveraging AI IP across our full portfolio of products to the benefit of our partners and customers.”
Welcome to this week's edition of "This Week in AI" on KDnuggets. This curated weekly post aims to keep you abreast of the most compelling developments in the rapidly advancing world of artificial intelligence. From groundbreaking headlines that shape our understanding of AI's role in society to thought-provoking articles, insightful learning resources, and spotlighted research pushing the boundaries of our knowledge, this post provides a comprehensive overview of AI's current landscape. This weekly update is designed to keep you updated and informed in this ever-evolving field. Stay tuned and happy reading!
Headlines
The "Headlines" section discusses the top news and developments from the past week in the field of artificial intelligence. The information ranges from governmental AI policies to technological advancements and corporate innovations in AI.
💡 ChatGPT In Trouble: OpenAI may go bankrupt by 2024, AI bot costs company $700,000 every day
OpenAI is facing financial trouble due to the high costs of running ChatGPT and other AI services. Despite rapid early growth, ChatGPT's user base has declined in recent months. OpenAI is struggling to effectively monetize its technology and generate sustainable revenue. Meanwhile, it continues to burn through cash at an alarming rate. With competition heating up and enterprise GPU shortages hindering model development, OpenAI needs to urgently find pathways to profitability. If it fails to do so, bankruptcy may be on the horizon for the pioneering AI startup.
💡 Stability AI Announces StableCode, An AI Coding Assistant for Developers
Stability AI has released StableCode, its first generative AI product optimized for software development. StableCode incorporates multiple models trained on over 500 billion tokens of code to provide intelligent autocompletion, respond to natural language instructions, and manage long spans of code. While conversational AI can already write code, StableCode is purpose-built to boost programmer productivity by understanding code structure and dependencies. With its specialized training and models that can handle long contexts, StableCode aims to enhance developer workflows and lower the barrier to entry for aspiring coders. The launch represents Stability AI's foray into AI-assisted coding tools amidst growing competition in the space.
💡 Introducing Superalignment by OpenAI
OpenAI is proactively working to address potential risks from superintelligent AI through their new Superalignment team, which is using techniques like reinforcement learning from human feedback to align AI systems. Key goals are developing scalable training methods leveraging other AI systems, validating model robustness, and stress testing the full alignment pipeline even with intentionally misaligned models. Overall, OpenAI aims to show machine learning can be conducted safely by pioneering approaches to responsibly steer superintelligence.
💡 Learn as you search (and browse) using generative AI
Google is announcing several updates to its Search Engine Generation (SGE) AI capabilities including hover definitions for science/history topics, color-coded syntax highlighting for code overviews, and an early experiment called "SGE while browsing" that summarizes key points and helps users explore pages when reading long-form content on the web. These aim to enhance understanding of complex topics, improve digestion of coding information, and aid navigation and learning as users browse. The updates represent Google's continued efforts to evolve its AI search experience based on user feedback, with a focus on comprehension and extracting key details from complex web content.
💡 Together.ai extend Llama2 to a 32k context window
LLaMA-2-7B-32K is an open-source, long context language model developed by Together Computer that extends the context length of Meta's LLaMA-2 to 32K tokens. It leverages optimizations like FlashAttention-2 to enable more efficient inference and training. The model was pre-trained using a mixture of data including books, papers, and instructional data. Examples are provided for fine-tuning on long-form QA and summarization tasks. Users can access the model via Hugging Face or use the OpenChatKit for customized fine-tuning. Like all language models, LLaMA-2-7B-32K can generate biased or incorrect content, requiring caution in use.
Articles
The "Articles" section presents an array of thought-provoking pieces on artificial intelligence. Each article dives deep into a specific topic, offering readers insights into various aspects of AI, including new techniques, revolutionary approaches, and ground-breaking tools.
📰 LangChain Cheat Sheet
With LangChain, developers can build capable AI language-based apps without reinventing the wheel. Its composable structure makes it easy to mix and match components like LLMs, prompt templates, external tools, and memory. This accelerates prototyping and allows seamless integration of new capabilities over time. Whether you're looking to create a chatbot, QA bot, or multi-step reasoning agent, LangChain provides the building blocks to assemble advanced AI rapidly.
📰 How to Use ChatGPT to Convert Text into a PowerPoint Presentation
The article outlines a two-step process for using ChatGPT to convert text into a PowerPoint presentation, first summarizing the text into slide titles and content, then generating Python code to convert the summary to PPTX format using the python-pptx library. This allows rapid creation of engaging presentations from lengthy text documents, overcoming tedious manual efforts. Clear instruction is provided on crafting the ChatGPT prompts and running the code, offering an efficient automated solution for presentation needs.
📰 Open challenges in LLM research
The article provides an overview of 10 key research directions to improve large language models: reducing hallucination, optimizing context length/construction, incorporating multimodal data, accelerating models, designing new architectures, developing GPU alternatives like photonic chips, building usable agents, improving learning from human feedback, enhancing chat interfaces, and expanding to non-English languages. It cites relevant papers across these areas, noting challenges like representing human preferences for reinforcement learning and building models for low-resource languages. The author concludes that while some issues like multilinguality are more tractable, others like architecture will require more breakthroughs. Overall, both technical and non-technical expertise across researchers, companies and the community will be critical to steer LLMs positively.
📰 Why You (Probably) Don’t Need to Fine-tune an LLM
The article provides an overview of 10 key research directions to improve large language models: reducing hallucination, optimizing context length/construction, incorporating multimodal data, accelerating models, designing new architectures, developing GPU alternatives like photonic chips, building usable agents, improving learning from human feedback, enhancing chat interfaces, and expanding to non-English languages. It cites relevant papers across these areas, noting challenges like representing human preferences for reinforcement learning and building models for low-resource languages. The author concludes that while some issues like multilinguality are more tractable, others like architecture will require more breakthroughs. Overall, both technical and non-technical expertise across researchers, companies and the community will be critical to steer LLMs positively.
📰 Best Practices to Use OpenAI GPT Model
The article outlines best practices for obtaining high-quality outputs when using OpenAI's GPT models, drawing on community experience. It recommends providing detailed prompts with specifics like length and persona; multi-step instructions; examples to mimic; references and citations; time for critical thinking; and code execution for precision. Following these tips on instructing the models, such as specifying steps and personas, can lead to more accurate, relevant, and customizable results. The guidance aims to help users structure prompts effectively to get the most out of OpenAI's powerful generative capabilities.
📰 We're All Wrong About AI
The author argues that current AI capabilities are underestimated, using examples like creativity, search, and personalization to counter common misconceptions. He states that AI can be creative by recombining concepts, not merely generating random ideas; it is not just a supercharged search engine like Google; and it can develop personalized relationships, not just generic skills. While unsure which applications will prove most useful, the author urges an open mind rather than dismissiveness, emphasizing that the best way to determine AI's potential is by continued hands-on exploration. He concludes that our imagination around AI is limited and its uses likely far exceed current predictions.
Tools
The "Tools" section lists useful apps and scripts created by the community for those who want to get busy with practical AI applications. Here you will find a range of tool types, from large comprehensive code bases to small niche scripts. Note that tools are shared without endorsement, and with no guarantee of any sort. Do your own homework on any software prior to installation and use!
🛠️ MetaGPT: The Multi-Agent Framework
MetaGPT takes a one line requirement as input and outputs user stories / competitive analysis / requirements / data structures / APIs / documents, etc. Internally, MetaGPT includes product managers / architects / project managers / engineers. It provides the entire process of a software company along with carefully orchestrated SOPs.
🛠️ GPT LLM Trainer
The goal of this project is to explore an experimental new pipeline to train a high-performing task-specific model. We try to abstract away all the complexity, so it's as easy as possible to go from idea -> performant fully-trained model.
Simply input a description of your task, and the system will generate a dataset from scratch, parse it into the right format, and fine-tune a LLaMA 2 model for you.
🛠️ DoctorGPT
DoctorGPT is a Large Language Model that can pass the US Medical Licensing Exam. This is an open-source project with a mission to provide everyone their own private doctor. DoctorGPT is a version of Meta's Llama2 7 billion parameter Large Language Model that was fine-tuned on a Medical Dialogue Dataset, then further improved using Reinforcement Learning & Constitutional AI. Since the model is only 3 Gigabytes in size, it fits on any local device, so there is no need to pay an API to use it.
More On This Topic
This Week in AI, August 7: Generative AI Comes to Jupyter & Stack Overflow…
Unveiling StableCode: A New Horizon in AI-Assisted Coding
SQream Announces Massive Data Revolution Video Challenge
How I Built A Perfect Model And Got Into Trouble
8 Ways to Improve Your Search Application this Week
Free 4 Week Data Science Course on AI Quality Management
Adobe has been incorporating artificial intelligence into its applications, like Photoshop, for months. Now, Adobe is rolling out some AI features for Adobe Express, powered by Firefly, a proprietary generative AI model. The features have been available in beta for a few months but are finally seeing a stable release and becoming available to subscribers worldwide.
The revamped Adobe Express works as an all-in-one design tool to create social media content, PDFs, videos, brand kits, and other visually-compelling materials without having graphic design software proficiency. Similar to Canva and Microsoft Designer, Express is an online tool.
Also: How to use Photoshop's Generative Fill AI tool to easily transform your boring photos
Some of the latest innovations that make Adobe Express an all-in-one editor include new video templates, multiple page templates, animations, and design elements; PDF support to create, edit, and enhance documents; text-to-image AI ability to generate images with a prompt; actions like removing the background in both images and videos; converting to GIFs; and more.
"With groundbreaking innovations and generative AI at the core of Express, we're empowering an ever-expanding user base with an AI-first, all-in-one tool that makes content creation fast, easy and fun," shared Govind Balakrishnan, senior vice president for Adobe Express and Digital Media Services at Adobe. "The all-new Express is revolutionizing how people turn ideas into stunning content, and we're just getting started with exciting innovations across image creation, design, video, audio, PDFs and more still to come."
Also: Adobe's customer experience offerings are getting a generative AI upgrade
Adobe touts that AI-generated content created with Express is "designed to be safe for commercial use." This is because the company's generative AI model, Adobe Firefly, was trained on the library of Adobe Stock images, for which the company owns the royalty.
This same model powers Photohop's generative fill and generative expand tools, allowing users to create AI-generated content to fill an area outside of the image they're working on.
Also: What to do if Generative Fill is grayed out in your Adobe Photoshop AI beta
Users can access a limited version of Adobe Express for free with Adobe Firefly features like using AI to generate images and text effects, access to the royalty-free Adobe Stock library of content, get ten PDF quick actions per month, and more.
A monthly $10 subscription unlocks all 195 million units of Adobe Stock content, premium video and image templates, unlimited PDF quick actions, over 25,000 licensed Adobe fonts, 100GB of storage, animation controls, and marketing features like brand kit creation and unlimited post scheduling through Instagram, Facebook, LinkedIn, and more.
Also: These 3 AI tools made my two-minute how-to video way more fun and engaging
Adobe Firefly now supports prompts in over 100 languages to accommodate users worldwide, enabling apps that incorporate the model to reach a wider audience than ever before. The latest version of Adobe Express is available on desktop web and will become available for mobile users soon.
With the constant development in technology and the use of AI in our everyday lives, many are worried about job displacements. Some are even speaking on data science dying. Many are saying that machine learning is replacing data science, stating that data science is an oversaturated field. With the heavy use of tools such as ChatGPT and their use in coding tasks and more, we are questioning if data science is dying.
But is it? Is it really dying?
Well no of course. We’re getting more data, which is producing valuable insights that drive decisions. These insights can’t be generated from a computer and we need them for data science. Machine learning models can be built and with data can be used to find valuable insight, but the key element is the need for data and what to do with the data.
And in order to understand what to do with data, you need humans. You need data scientists! But what has changed?
Changes in Data Science
Various elements are changing in data science due to generative AI and the boom of everybody wanting to break into the tech industry. Let's go over some changes in data science.
Skills
Tasks such as exploratory data analysis which provided great insight have drastically changed. It typically required data scientists and data analysts to come in and help with the process. However, now with tools such as ChatGPT, and fast courses to become a data scientist — everybody believes they can code and are technically proficient in Python.
However, that’s not true. If you have the right skill set and are truly proficient in programming languages such as Python — you will stand out. Organizations will still be seeking highly qualified data scientists to help them get the job done, over ChatGPT’s responses and people who did a quick course in data science.
As a data scientist, it will be your job to adapt to the current market. Continuously learning and improving your skillset is the way you will remain competitive and be truly valued for your skills.
This includes constantly learning about different software architecture, libraries, frameworks, different programming languages, and more.
Building Full Applications
Many people are using ChatGPT to help them with coding tasks. But the important thing to understand with ChatGPT is that it can help you build the blocks to your full application, but it can’t bring those blocks together to build the whole foundation.
Organizations will require somebody who understands all the different blocks and how they come together. They will be able to piece together all the blocks as they understand what each of them does and put them together to build a foundation.
It doesn’t mean that ChatGPT is not helpful — it is. A lot of programmers are making use of ChatGPT to help them with code blocks, which is helping speed up their code-writing process. At the same time, it is also helping improve the skills of programmers by learning new things and allowing them to be more proficient in their coding.
So the key point to take from this is that as a data scientist, you will need to know more, if not all. You will need to know each element of data science as well as how to build a full application.
Merging of Roles
There will be a lot of roles in data science, however, the important thing to note is that a lot of roles will be merging. Before you may have been the go-to person for data analytics, but now you will need to essentially be a jack of all trades — and be a master in overall data science. For example, you will be using your analytical skills to build applications.
The reason for this is that more and more organizations are looking into the efficiency of job roles, and how many people they really require. For example, should I hire somebody who is good at creating data visualizations and presenting them, or should I find a data scientist who can do it all? From a business perspective, you know who the company is going to choose.
The best advice I can give you is to be REALLY good at what YOU do. Be the best that you can be, that you don’t feel like you’re getting pushed out.
Job Market
The job landscape in data science has changed. For many years, a lot of people were trying to break into the tech industry with a quick boot camp and a few Jupyter Notebook projects. Unfortunately, that is not going to help you with this current market. Having a proficient skill set, with years of experience and a high-level understanding of data science is imperative.
Understanding machine learning architectures and high-level data analytics are areas you want to perfect! You want to stand out!
Wrapping it up
I hope this blog will help you understand how the world of data science has changed, and if you’re looking to enter or grow in the sector — what you need to do! Rather than feeling pushed out, all you need to do is understand what your next steps need to be in order to remain competitive! Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.
More On This Topic
How My Learning Path Changed After Becoming a Data Scientist
8 Innovative BERT Knowledge Distillation Papers That Have Changed The…
Top November Stories: Top Python Libraries for Data Science, Data…
KDnuggets™ News 22:n06, Feb 9: Data Science Programming Languages and…
KDnuggets News, May 4: 9 Free Harvard Courses to Learn Data Science; 15…
KDnuggets News, November 30: What is Chebychev's Theorem and How Does it…
This is the final image we'll be working to create.
Image generation using AIs like Midjourney is shockingly good. But the AIs also have a few weaknesses. In this article, I'll show you how you can work around one of those weaknesses.
We're going to learn how to make two or more characters with matching faces.
Also: How AI helped get my music on all the major streaming services
Face matching is surprisingly inconsistent, and there are a few different techniques that can be used. When I created my music promotion poses, I had to use some special techniques to get the graphics to work.
How we use Midjourney, InsightFace, and Adobe Generative Fill to create this look
In my recent article about using AI to create an album, I glossed over the techniques I used, giving a thousand-foot view of what they were. But in this article, I'm going to dive in and show you how to make it all happen, step by step.
Also, for this article, I'm going to assume you've signed up for and set up your Midjourney account. If you're not sure how to do that, this article by ZDNET's Lance Whitney will walk you through the steps:
Also: How to use Midjourney to generate amazing images and art
First, I'll show you what I did to create my images, and then I'll show you some additional techniques.
To do this, double click on the plus icon at the bottom of the Discord screen (remember, Midjourney runs in Discord), choose your image, and then hit return.
Once it's been brought into Midjourney, right click on the image and select Copy Link:
This link is what you'll use in preparing your prompt. Next, give Midjourney the /IMAGINE prompt, followed by the URL, and then your spec. This screenshot of the set of four generated images shows what it looked like after I entered the full prompt. The top right picture is the image I wound up using for my profile.
Please note that this set of images was most definitely not my first "roll" on Midjourney. Expect to do five, 10, even 20 different tries before you get something you like.
Also: 5 ways to explore the use of generative AI at work
That said, you can see how the generated version (especially the one on the upper left) looks reasonably close to what I look like. More interestingly, the leather jacket in the image looks weirdly like the one I've been wearing for the past decade or so. How does it know?
Just for completionist's sake, here's what might have been generated without using the uploaded image as guidance.
Definitely not me, but I think I went to engineering school with the guy on the lower right!
They're all fine-looking gentlemen, but they look nothing like me.
You can use the starter-image trick for anything you want. Here's what Midjourney thinks my little Yorkie Poo pup Pixel might have looked like as a Scottish warrior prince:
To get a seed ID, click the half-moon-plus icon (1) at the upper right of the image where you want to get the seed. Then, in the search box, type in :envelope: (2). Then click on the envelope (3).
Also:How ChatGPT can rewrite and improve your existing code
I know it's completely intuitively unobvious, but this process will convince Midjourney to send you a message that contains the seed ID for the quad of images you're working with.
It's unfortunate that the seed is for the quad of images, because that makes it harder to drill into the one image you like. But it's a starting point.
This time, instead of starting with the actual photo of me, I used the generated profile image as my starting point. As shown above, I uploaded it and got its URL.
Then, I combined the profile image with the previously retrieved seed value and a prompt, and after about 20 spins, I got this quad:
Notice the /imagine prompt. The URL is at the beginning, and the seed prompt at the end had my seed number. That's how I tied the two images together.
Also: The best AI art generators: DALL-E 2 and fun alternatives to try
While the image on the lower left was absolutely terrible, the one on the right wasn't bad. Strictly speaking, it didn't look entirely like me. But it did capture the same thematic style as the original profile image, it was close enough, and the car looked good.
But this was not my face and most definitely not my hair:
This video is from PIXimperfect. I really like this channel because the presenter showcases some excellent image tutorials, particular on Photoshop features. So, don't just watch the video — save the channel.
Once you have InsightFace set up, we can go to town. The process involves two steps: uploading the face you want to use, and uploading the image you want it applied to.
To upload the image you want to use, use the /saveid command.
When you type /saveid, you'll be given a place to upload an image. Then you need to give that image a name ID. I called mine "daviddoor" because I'm standing in front of a door. Remember that ID because you'll use it in the next step.
Now, it's time for the face swap. Type /swapid:
Upload the image you want the face to be applied to. Then type in the ID you created earlier. If you're lucky, once you hit return, you'll get an image with the new face.
Of course, the hair still isn't right.
Various versions of me, both with and without hair.
The key problem was all the extra hair below the ears. To eliminate that, I first brought the Dave Head to something nobody had ever seen before: a bald me. I selected the space just where I wanted the hair removed, generated "bald", and Photoshop did the work.
Then I selected a smaller area and generated "curly hair". This took a few tries, but it worked out.
Also:How to use Bing Image Creator (and why it's better than DALL-E 2)
And, after all the various AI effects, the final picture is below.
One quick note: the hair here doesn't quite match the tutorial hair above. That's because I had to recreate the process for demonstration, and the AI always comes up with something slightly different. This is the actual final image from my original production process, but the rightmost image in the Three Daves graphic above shows how new hair could be generated, even if it's not exactly the same output.
FAQs
Here are a few questions I've been asked since I published the original article.
Can I still use Midjourney for free?
No. Midjourney no longer has a free tier. The plan I use costs $8 a month. So far, I haven't hit any limits with it, although it sometimes can take a little while for images to be created.
What about InsightFace? Is it free?
InsightFace does offer some free credits. I've done four or five face swaps and haven't used them up. It appears to take about three "credits" per face swap, and you get 50 free credits.
Where does Picsi.ai fit into all this?
So, when you run out of face swap credits, you'll need to subscribe to a Patreon account for Picsi.ai. There are two plans. The base $10/month plan looks like it will do fine for most people. As to the relationship between InsightFace and Picsi.ai, it appears that InsightFace is an open-source project, and Picsi.ai has created a usable Discord client for it. But I'm sure more will be revealed over time.
Have you used any of these AI image tools? What do you think of the face swap technique? Does this spark any ideas for you? Let us know in the comments below.
You can follow my day-to-day project updates on social media. Be sure to subscribe to my weekly update newsletter on Substack, and follow me on Twitter at @DavidGewirtz, on Facebook at Facebook.com/DavidGewirtz, on Instagram at Instagram.com/DavidGewirtz, and on YouTube at YouTube.com/DavidGewirtzTV.
“This is for you”, “Suggested for you”, or “You may also like”, are phrases that have become essential in most digital businesses, particularly in e-commerce, or streaming platforms.
Although they may seem like a simple concept, they imply a new era in the way businesses interact and connect with their customers: the era of recommendations.
Let’s be honest, most of us, if not all of us, have been carried away by Netflix recommendations while looking for what to watch, or headed straight for the recommendations section on Amazon to see what to buy next.
In this article, I’m going to explain how a Real-Time Recommendation Engine can be built using Graph databases.
What is a Recommendation Engine?
A recommendation engine is a toolkit that applies advanced data filtering and predictive analysis to anticipate and predict customers’ needs and wants, i.e. which content, products, or services a customer is likely to consume or engage with.
For getting these recommendations, the engines use the combination of the following information:
The customer’s past behaviors and history, e.g. purchased products or watched series.
The customer’s current behaviors and relationships with other customers.
The product’s ranking by customers.
The business’ best sellers.
The behaviors and history of similar or related customers.
What is a Graph database?
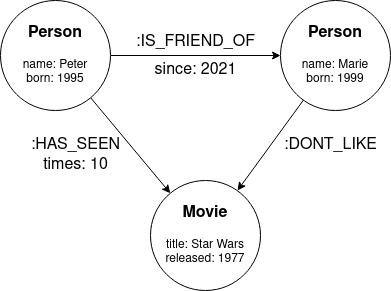
A Graph database is a NoSQL database where the data is stored in graph structures instead of tables or documents. A graph data structure consists of nodes that can be connected by relationships. Both nodes and relationships can have their own properties (key-value pairs), which further describe them.
The following image introduces the basic concepts of the graph data structure:
Example of a graph data structure Real-Time Recommendation Engine for Streaming Platforms
Now that we know what are a recommendation engine and a graph database, we’re ready to get into how we can build a recommendation engine using graph databases for a streaming platform.
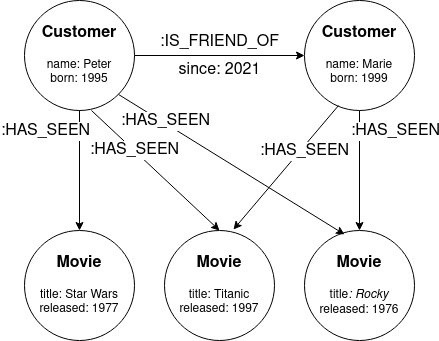
The graph below stores the movies two customers have seen and the relationship between the two customers.
Example of a graph of the streaming platform.
Having this information stored as a graph, we can now think about movie recommendations to influence the next movie to watch. The simplest strategy is to show the most viewed movies on the entire platform. This can be easy using Cypher query language:
MATCH (:Customer)-[:HAS_SEEN]->(movie:Movie) RETURN movie, count(movie) ORDER BY count(movie) DESC LIMIT 5
However, this query is very generalist and does not take into account the context of the customer, so it’s not optimized for any given customer. We can do it much better using the social network of the customer, querying for friends and friends-of-friends relationships. With Cypher is very straightforward:
MATCH (customer:Customer {name:'Marie'}) <-[:IS_FRIEND_OF*1..2]-(friend:Customer) WHERE customer <> friend WITH DISTINCT friend MATCH (friend)-[:HAS_SEEN]->(movie:Movie) RETURN movie, count(movie) ORDER BY count(movie) DESC LIMIT 5
This query has two parts divided by WITH clause, which allows us to pipe the results from the first part into the second.
With the first part of the query, we find the current customer ({name: 'Marie'}) and traverse the graph matching for either Marie’s direct friends or their friends (her friend-of-friends) using the flexible path-length notation -[:IS_FRIEND_OF*1..2]-> which means one or two IS_FRIEND_OF relationships deep.
We take care not to include Marie herself in the results (the WHERE clause) and not to get duplicate friends-of-friends that are also direct (the DISTINCT clause).
The second half of the query is the same as the simplest query, but now instead of taking into account all the customers on the platform, we are taking into account Marie’s friends and friends-of-friends.
And that’s it, we have just built our real-time recommendation engine for a streaming platform.
Wrapping up
In this article, the following topics have been seen:
What a recommendation engine is and the amount of information it uses to make recommendations.
What a graph database is and how the data is stored as a graph instead of a table or document.
An example of how we can build a real-time recommendation engine for streaming platforms using graph databases.
José María Sánchez Salas is living in Norway. He is a freelance data engineer from Murcia (Spain). In the middle of business and development worlds, he also write a data engineering newsletter.
More On This Topic
Graph Databases, Explained
A Faster Way to Prepare Time-Series Data with the AI & Analytics Engine
Real-time Translations with AI
Machine learning is going real-time
Why we will always need humans to train AI — sometimes in real-time
How to Build a Knowledge Graph with Neo4J and Transformers
Singapore is readying its population to guide against online threats and foreign interference in the lead up to the country's upcoming presidential election.
The general public and potential presidential candidates have been warned about malicious online activities, including misinformation and disinformation, data theft, and disruption, and advised to take measures to mitigate such risks.
Also: What is phishing? Everything you need to know
Scheduled to take place on September 1, the Presidential Election will move ahead if more than one candidate qualifies to run — a decision that will be announced on August 22, after applicants are assessed by the election and community committees. Singapore's president serves a six-year term as head of state, with the role largely symbolic, and as custodian of the country's reserves.
To date, six applications have been submitted, including one from former Senior Minister Tharman Shanmugaratnam who was previously Deputy Prime Minister. Current President Halimah Yacob was elected uncontested in 2017 and is not seeking re-election.
Also:The best VPN services right now
In statements released this week, various government ministries and agencies including the Ministry of Home Affairs, Singapore Police Force, and Cyber Security Agency of Singapore, pointed to reports of alleged foreign interference in elections of other nations. These included the US President Election and Mid-Term Elections in 2020 and 2018, respectively, and the French Presidential Elections in 2017.
"Singapore is not immune," the government agencies said. "Singapore's politics should be decided by Singaporeans alone. We should do all we can to safeguard the integrity of our electoral processes."
They said Singapore must brace against online attempts to disrupt election processes or cast doubts on the integrity of the election.
Election candidates are urged to take the necessary steps to better understand potential threats and safeguard their cybersecurity postures.
"Candidates should find out more about the precautionary measures they can take to protect their IT infrastructure, online and social media accounts, as well as the storage and management of their data. They are also advised to stay vigilant by monitoring their platforms for suspicious activity and not re-share posts or tweets of suspicious provenance," the government agencies said.
Also:How to stay safe on public Wi-Fi: 5 important tips
Data, for instance, can be compromised via social engineering, malware infection, or software vulnerabilities, among other tactics. When breached, the data can be sold or published and may potentially damage the credibility of political parties and candidates. Threat actors could also use the data to facilitate more attacks on other IT systems, further disrupting campaign activities.
Election candidates should ensure their IT systems and digital assets are secured, with one person dedicated to assume responsibility for the campaign's cybersecurity posture, the government agencies said.
They also reminded the general public to "observe appropriate online conduct" during the election period and to refrain from behaviors that violate existing laws.
For example, individuals who share or repost misinformation and disinformation may be liable for communicating false messages under the Miscellaneous Offences (Public Order and Nuisance) Act.
Actions also can be taken against individuals who "communicate online falsehoods or misleading or manipulated content" under the Protection from Online Falsehoods and Manipulation Act (POFMA). An offence is deemed to have occurred if they are found to have knowingly communicated these falsehoods.
When the likes of Google, Microsoft, and Meta went all-in on building their own large languages models like PaLM 2, GPT-4, Llama 2, and their versions, Amazon opted for a different route. Instead of joining the same race, Amazon’s cloud business, Amazon Web Services (AWS), took a surprising twist by tapping into its vast 34% market share in cloud services, leading to the birth of Amazon Bedrock.
This has led to the inception of Amazon Bedrock which aligns with the fact that AWS offers FMs from startups and Amazon Titan through Bedrock. Launched four months ago, Amazon Bedrock provides an API platform to build generative AI-powered apps via foundational models sourced from top-tier AI players like Anthropic, Stability AI, Cohere, and others.
“We are focused on democratising access to generative AI and FMs, to all customer types and business functions. Instead of concentrating on just one FM, we envision multiple specialised models serving various purposes, said Olivier Klein, Chief Technologist, APAC, AWS, in an exclusive interview with AIM.
Klein added that AWS is currently in the early phases of exploring the potential of generative AI and highlighted how services like Amazon Bedrock are being used to make generative AI more accessible to a broader audience.
Bridgewater Associates, Coda, Lonely Planet, Ryanair, Showpad, Travelers, and many others are among some of the companies that are actively using Amazon Bedrock to create generative AI applications. For instance, Coda AI is a workplace assistant designed for enterprise use cases, with thousands of teams depending on it to complete tasks and advance their work.
Customer Obsession Continues
Amazon’s customer obsession has its influence on generative AI well. “When it comes to generative AI, your data is your differentiator. That’s how you can differentiate your AI from everyone else’s. Having the right data strategy in place is a common challenge I discuss with customers, which is why I advise our customers to leverage a data lake for many applications,” said Klein.
According to Klein, Amazon‘s customer-first philosophy remains at the heart of its approach to AI and ML.
Furthermore, he added that AWS also provides secure storage in Amazon Simple Storage Service all the way through serving AI responses with Amazon Bedrock. Customers already using Amazon S3 for data lakes can move faster to a differentiated generative because they have their own data.
Why AWS is Yet to Build their Own LLMs
Back in April, Amazon’s CEO, Andy Jassy, announced that the company is developing a “generalised and capable” LLM for enhancing Alexa. However, the company made no announcements about the same since then.
For now, AWS believes that in the evolving ML landscape, different models have distinct purposes, and no single model can cover all bases. Say AI21 Jurassic1 is suitable for report summarisation in financial firms, while Cohere‘s Generate Model-Medium is ideal for autocomplete suggestions in online retail. Customers choose between these models based on their unique needs.
Additionally, the company is helping in the creation of generative AI apps that provide real-time answers from private knowledge sources and handle various tasks. For example, in customer service, the AI securely accesses company data, converts it into machine-readable format, and uses relevant information to perform tasks like exchanging products, enhancing developer productivity.
On the other hand, they are also exploring generative AI’s impact on industries like healthcare. For instance, Amazon Bedrock powers HealthScribe to streamline the integration of AI into healthcare apps, reducing the complexity of tasks like detailed clinical documentation for physicians, without requiring them to manage ML infrastructure or train specialised models.
Riding the Gen AI Wave
AWS has launched the AWS Generative AI Innovation Center, investing $100 million in creating and deploying generative AI solutions.
“We are investing $100 million in the program, which will connect AWS AI and ML experts with customers around the globe to help them envision, design, and launch new generative AI products, services, and processes,” Klein added.
For now, the focus of the AWS Generative AI Innovation Center will be directed towards collaborating closely with global corporate clients, with a significant emphasis on sectors such as finances, healthcare, life sciences, media, entertainment, automotive, manufacturing, energy, utilities, and telco.
For instance, enterprises in the healthcare and life sciences domain will have the opportunity to expedite their drug research and exploration efforts. Manufacturing enterprises can embark on projects aimed at redefining industrial design and processes. Similarly, financial services entities can explore avenues to furnish patrons with personalised information and advisory services, all while encouraging innovation and development.
“Twilio, Ryanair, Lonely Planet, and Highspot, and are among hundreds of companies we’re already working with – and we look forward to welcoming more from across the world, including India,” he added.
Taking the Responsible Approach
As per a report by Business Insider, Amazon is apparently working on a new internal security initiative dubbed “Maverick” focusing on building new tools and fostering collaboration across Amazon to address the security and risk of generative AI and large language models. Led by former Uber CISO John Flynn, Maverick seeks to consolidate risks and create security guidance, and tools for GenAI security testing.
Meanwhile, Amazon was one of the first companies that cautioned its employees against placing confidential information on OpenAI’s ChatGPT. However, employees have been using ChatGPT for research and practical problem-solving, including interview questions, code writing, and training documents, as per the report.
Talking about the same, Klein said, “Employees use our AI models every day to invent on behalf of our customers – from generating code recommendations with Amazon CodeWhisperer to creating new experiences on Alexa. We have safeguards in place for employee use of these technologies, including guidance on accessing third-party generative AI services and protecting confidential information,”
Amazon is committed to long-term thinking and views its current offerings and collaborations as just the start of a technological revolution.
“We aim to shape the future of AI based on customer needs, focusing on promising, beneficial, and responsible applications,” concluded Klein.
Read more: Many A Generative AI Tricks Up Amazon’s Sleeves
The post [Exclusive] AWS’ Generative AI Play for Bedrock appeared first on Analytics India Magazine.
Since the release of the GPT model, everyone has been using them constantly. From asking simple questions to developing complex coding, the GPT model can help the user swiftly. That’s why the model would only get bigger over time.
To help users get the best output, OpenAI provides their best practice for using the GPT model. This comes from the experience as many users have experimented with this model constantly and have found what works best.
In this article, I will summarize the best practices you should know for using the OpenAI GPT model. What are these practices? Let’s get into it.
GPT Best Practices
GPT model output is only as good as your prompt. With definite instructions for what you want, it would provide the result you expected. A few tips to improve your GPT output include:
Have a detail in the prompt to get relevant answers. For example, instead of the prompt “Give me code to calculate normal distribution”, we can write “Provide me with the standard distribution calculation with the code example in Python. Place a comment in each section and explain why every code is executed that way.
Give a persona or example, plus add the length of the output. We can bring a persona or example to the model for better clarity. For example, we can pass the system role parameter to explain something in a way that the teacher would explain things to the students. By providing persona, the GPT model would bring results in a way that we require. Here is a sample code if you want to change the persona.
import openai openai.api_key = "" res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, messages=[ { "role": "system", "content": """ When I ask to explain something, bring it in a way that teacher would explain it to students in every paragraph. """, }, { "role": "user", "content": """ What is golden globe award and what is the criteria for this award? Summarize them in 2 paragraphs. """, }, ], )
It’s also great to provide example results to direct how the GPT model should answer your questions. For example, in this code, I pass how I would explain emotion, and the GPT model should mimic my style.
res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, messages=[ { "role": "system", "content": "Answer in a consistent style.", }, { "role": "user", "content": "Teach me about Love", }, { "role": "assistant", "content": "Love can be sweet, can be sour, can be grand, can be low, and can be anything you want to be", }, { "role": "user", "content": "Teach me about Fear", }, ], )
Specify the steps to complete your tasks. Provide detailed steps on how you want the output for the best output. Give a detailed breakdown of the instruction on how the GPT model should act. For example, we put 2-step instructions with prefixes and translations in this code.
res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, messages= [ { "role": "system", "content": """ Use the following step-by-step instructions to respond to user inputs. step 1 - Explain the question input by the user in 2 paragraphs or less with the prefix "Explanation: ". Step 2 - Translate the Step 1 into Indonesian, with a prefix that says "Translation: ". """, }, { "role": "user", "content":"What is heaven?", }, ])
Provide references, links or citations. If we already have various references for our questions, we can use them as the basis for the GPT model to provide the output. Give the list of any references you think are relevant to your questions and pass them into the system role.
Give GPT time to “think”. Provide a query allowing GPT to process the prompt in detail before rushing to give incorrect results. This is especially true if we pass the assistant role a wrong result, and we want the GPT to be able to think critically for themselves. For example, the code below shows how we ask the GPT model to be more critical of the user input.
res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, messages= [ { "role": "system", "content": """ Work on your solution to the problem, then compare your solution to the user and evaluate if the solution is correct or not. Only decide if the solution is correct once you have done the problem yourself. """, }, { "role": "user", "content":"1 + 1 = 3", }, ])
Bring GPT to use Code Execution for precise results. For more extended and more complex calculations, GPT might not work as intended, as the model might provide inaccurate results. To alleviate this, we can ask the GPT model to write and run coding rather than directly calculating them. This way, GPT can rely on the code rather than its calculation. For example, we can provide input like below.
res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, messages= [ { "role": "system", "content": """ Write and execute Python code by enclosing it in triple backticks, e.g. ```code goes here```. Use this to perform calculations. """, }, { "role": "user", "content":""" Find all real-valued roots of the following polynomial equation: 2*x**5 - 3*x**8- 2*x**3 - 9*x + 11. """, }, ])
Conclusion
The GPT model is one of the best models out there, and here are some best practices to improve the GPT model output:
Have a detail in the prompt to get relevant answers
Give a persona or example, plus add the length of the output
Specify the steps to complete your tasks
Provide references, links or citations
Give GPT time to “think”
Bring GPT to use Code Execution for precise results
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.
More On This Topic
Machine Learning Model Development and Model Operations: Principles and…
GPT-2 vs GPT-3: The OpenAI Showdown
OpenAI’s Approach to AI Safety
Introducing Superalignment by OpenAI
OpenAI’s Whisper API for Transcription and Translation
After playing with OpenAI, Microsoft now has moved on to exposing its flaws, and is looking everywhere else for support and strategic alliance to up its game in generative AI for enterprise.
A recent exclusive by The Information might come as a shocker for OpenAI.
The report said Microsoft is planning to sell a new version of Databricks’ software that helps customers make AI apps for their businesses. The tech giant plans to sell it through its Azure cloud-server unit, which will help companies make AI models from scratch or repurpose open-source models as an alternative to licensing OpenAI’s proprietary ones.
Microsoft’s actions are clearly indicating that everything is not well between the two entities. Although OpenAI hasn’t done anything to Microsoft which should make them unhappy. Instead, it seems that Microsoft’s focus has been primarily on its Azure services, which has led to a self-centered approach and possibly contributed to the current state of affairs between the two.
The partnership of Microsoft and OpenAI had their own agendas for both parties. While the tech giant needed generative AI push in its cloud services, the ChatGPT creator aimed to secure financial support for building advanced AI systems, and eventually AGI.
Despite the efforts made by OpenAI, it could not fully gain the trust of enterprises. Large tech companies like Apple, Spotify, Wells Fargo, Samsung, JP Morgan ,Verizon had wayback ditched ChatGPT and banned it for their employees from using it. Clearly, the awareness is lacking among enterprise customers.
Ironically, for Azure-Databricks service, Microsoft is leveraging OpenAI’s technology to develop a chatbot similar to ChatGPT. The purpose is to assist less tech-savvy users in navigating Databricks’ software, originally tailored for advanced data scientists.
As a consequence, certain Microsoft clients might find themselves utilising open-source models rather than the closed-source alternatives from OpenAI. This move by Microsoft is hinting that it is moving away from OpenAI and looking out for more partners which can help them make Azure OpenAI services better specially for its enterprise customers. There is no stopping.
Not the first time
A few days back Microsoft posted “Azure ChatGPT” on GitHub (now deleted) repository which was marketed as safe, secure and private ChatGPT for enterprise.
The reasoning behind launching Azure ChatGPT given by Microsoft was that ChatGPT risks exposing confidential intellectual property and it would be better to use Azure ChatGPT as data remains safe and secure on Azure. Microsoft had specifically mentioned that they would not share any data with OpenAI.
Microsoft did one more thing that put OpenAI’s reputation at risk. It collaborated with IBM Consulting. The collaboration with IBM Consulting is focused on helping clients to implement and scale Azure OpenAI Service. Notably, IBM also forged a recent partnership with Meta, aiming to integrate Llama 2 into watsonx.ai, a formidable competitor to OpenAI’s GPT-4.
Who is spreading the rumors? IBM recently released a blog post cautioning on the use of ChatGPT for enterprise. According to IBM, employing ChatGPT directly within an enterprise context introduces various potential risks and obstacles. These encompass matters like security vulnerabilities leading to data exposure, issues related to confidentiality and legal responsibility, and the intricate landscape of intellectual property.
OpenAI has taken steps to address this concern by providing clarity. They have explicitly stated in their policy that user data from chat histories is not employed to train their model if users have disabled the chat history feature. Recently, Sam Altman clarified on X, saying that OpenAI doesn’t use API-submitted data to train or improve models unless a user explicitly opt-in.
Despite OpenAI’s diligent efforts to be transparent, Microsoft’s actions seem to undermine their attempts to maintain transparency and integrity.
Microsoft’s Unquenchable Thirst for Partnerships
Microsoft’s partnership with Meta appears to have strained OpenAI’s relationship. The tech giant’s collaboration seems to be creating a competitor for OpenAI’s closed-source models. By teaming up with Meta and leveraging Llama 2, Microsoft gained a sense of security and reduced their reliance on OpenAI, altering the dynamics in their favor.
Similarly for Microsoft, providing Databricks services on Azure gives them potential to expand its cloud service offerings to a wider range of enterprises. With Databricks it aims to capitalise on the AI trend and make progress in competing with Amazon Web Services (AWS).
OpenAI’s partnership with Microsoft provided them with GPT-4 while AWS multi-LLM approach gave its customers the options to choose from a buffet of models like AI21, Cohere, Anthropic Claude 2, and Stability AI SDXL 1.0.
By providing Databricks services on Azure cloud, Microsoft is mimicking AWS strategy where it is trying to provide more options to its enterprise customers all under one roof. Databricks recently acquired Mosaic ML, which created MPT-30B, an open-source foundation model. Who knows if there is a chance that it might be made available on Azure cloud in the coming months.
The post Microsoft Crushes OpenAI with Databricks appeared first on Analytics India Magazine.














![[Exclusive] AWS’ Generative AI Play for Bedrock](https://aidigitalnews.com/wp-content/uploads/2023/08/aws-inter-1.jpg)




