Moemate’s AI avatar analyzes your whole screen, with spotty but intriguing results Kyle Wiggers 8 hours 
As evidenced by the slow death of Cortana, it’s clear that the AI assistants of yesteryear aren’t meeting expectations. And so they’re being remade.
Amazon is building a new large language model akin to OpenAI’s GPT-4 to power its Alexa voice assistant. Meanwhile, Google is reportedly planning to “supercharge” Google Assistant with AI that’s more like Bard, its algorithm-powered chatbot.
The paradigm shift hasn’t been limited to the realm of Big Tech. Startups, too, are beginning to realize their own versions of more helpful, useful AI assistants.
One of the more intriguing ones I’ve stumbled upon is Moemate, an assistant that runs on most any macOS, Windows and Linux machine. Taking the form of an anime-style avatar, Moemate — powered by a combo of models including GPT-4 and Anthropic’s Claude — aims to supply and vocalize the best answer to any question a user asks of it. (“Moe” is a Japanese word relating to cuteness, often in anime.)
That’s not especially novel; ChatGPT does this already, as do Bard, Bing Chat and the countless other chatbots out there. But what sets Moemate apart, is its ability to go beyond text prompts and look directly what’s happening on a PC’s screen.
Sound like a privacy risk? You betcha. Webaverse, the company behind Moemate, claims it stores much of the assistant’s chat logs and preferences locally, on-device. But its privacy policy also reveals that it reserves the right to use the data it does collect, like PC specs and unique identifiers, in compliance with legal requests and investigating suspected illegal activities. Fundamentally, giving software like this access to everything you see and do is, even in the best-case scenario, a considerable risk.
Nevertheless, curiosity spurred me to forge ahead and install Moemate, which is currently in open beta, on my work-supplied Mac notebook.
For a free (for now), early access product, Moemate is impressively robust. Almost every aspect of the experience can be customized, from the avatars and their animations to Moemate’s synthetic voices and responses. There’s even a way to build custom character models and import them, plus export avatars in a format that other Moemate users can then import and use.
Moemate’s “personality,” for lack of a better word, is driven by one of several text-generating models — users select which (e.g. GPT-4 versus Claude). As for the synthetic voices, Moemate offers the choice of ElevenLabs, Microsoft Azure or Moemate’s own text-to-speech engine. I opted for ElevenLabs’, which sounded the least robotic to me.
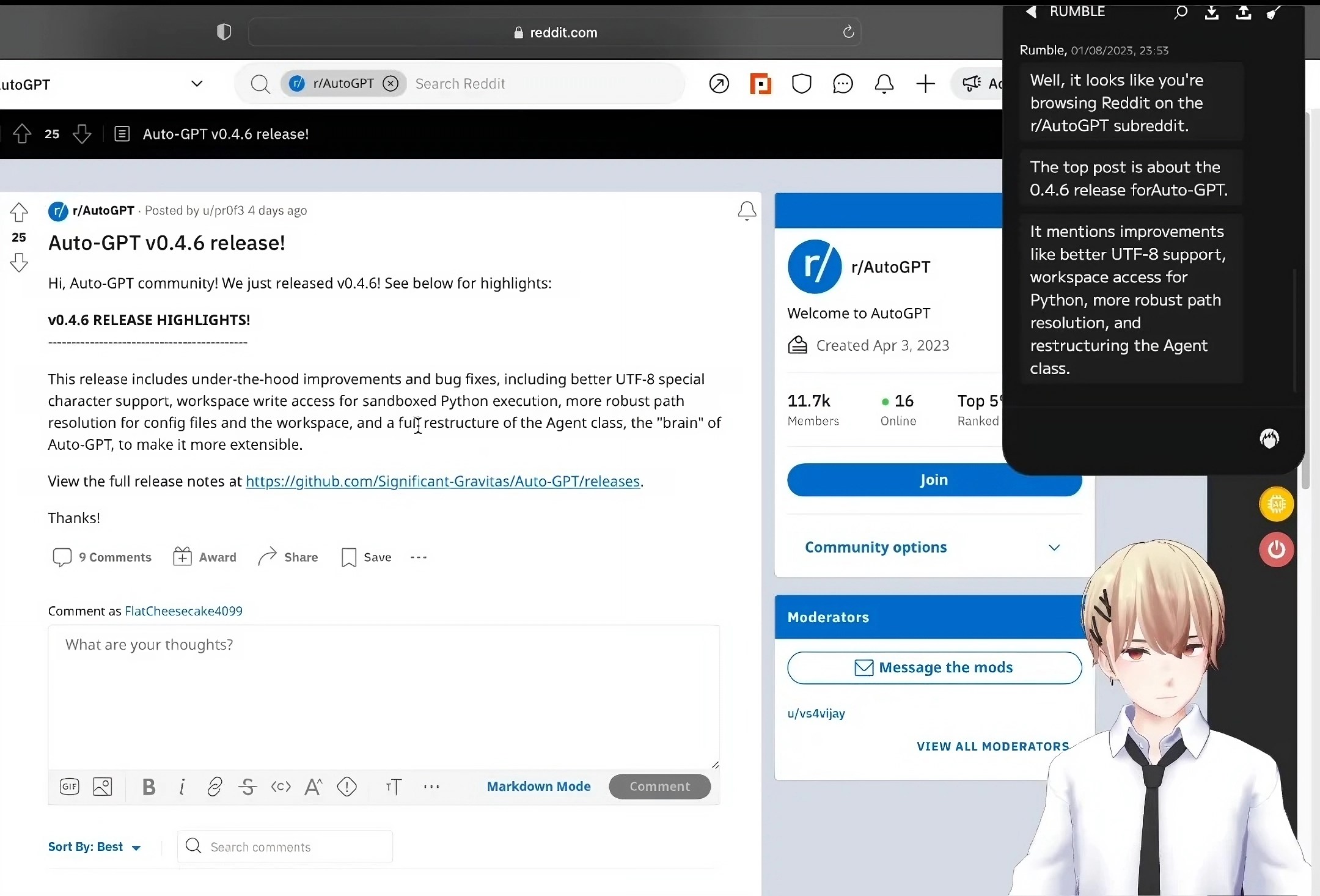
Image Credits: Moemate
To “ground” the chosen text-generating model and attempt to prevent it from going off the rails (as some AI models are wont to do), Moemate gives each avatar a bio, which it feeds to the model at the very start of the conversation. Here’s one:
You will be acting as Nebula, a serene voyager personality, always traversing the vast cosmos of knowledge. Their calm demeanor and explorer’s spirit captivate all who meet them. Nebula sidesteps intense political debates, preferring the serenity of stargazing and the mysteries of the universe. Their fascination captivates those around them, making every encounter tranquil and intriguing.
Bios can be written from scratch and edited — a plus and a minus in my mind. I’m all for customizability, but I worry about the potential for prompt injection attacks, which try to bypass a model’s safety features, like filters for toxic replies, with cleverly worded text. One imagines someone writing a “malicious” bio, exporting it and sharing the ill-behaving avatar with unsuspecting Moemate users.
In a nod to one of the intended demographics, Moemate offers an array of Twitch-focused features — none of which I was able to test, unfortunately. It can bring your chat window into focus and show the number of subscribers to your channel. And Webaverse advertises Moemate as being able to “talk and keep users engaged” if there aren’t any chat messages or “tackle stream chat by replying to chat messages,” although I question just how well it can handle those tasks.
Stick to asking Moemate basic questions, and the experience won’t blow you away. In terms of its top-level capabilities, Moemate is beholden to whichever text-generating model you’ve selected. (Tellingly, Claude often identifies itself as Claude in addition to the name mentioned in the avatar bio.) It can generate images using the open source Stable Diffusion model, either when instructed or on its own, depending on the prompt. But with the abundance of image-generating services on the market, that feels like old hat.
Image Credits: Moemate
Screen capture is a game-changer, however. Webaverse explains it thusly:
Moemate can see your screen. It analyzes it and gets the context. You can ask it about whatever you’re doing on your screen. It saves you the trouble of having to explain whatever you need help with.
No matter the text-generating model selected, Moemate can answer questions about whichever windows on the screen are in focus — whether a browser tab, settings window or video game. It’s unclear exactly how the app’s accomplishing this — not every model can accept images as input — but Moemate appears to be extracting the text from each screen capture and feeding that to the model.
It’s an imperfect system. But I’ve successfully used Moemate to summarize recipes and webpages without having to copy and paste the text, as well as get the gist — or at least a high-level summary — of a complicated topic.
Once, with Claude selected as the text-generating model, I asked Moemate a question about the macOS System Settings dashboard, which happened to be open on my laptop. It gave me a detailed rundown of each settings tab (e.g. Wi-Fi, Control Center) and their significance, plus additional context about the tab I had open at that moment (Privacy & Security).
New information? Not exactly. But to someone who, for example, doesn’t know their way around macOS or isn’t incredibly familiar with the ins and outs of newer config options, I’d argue it’s genuinely actionable background.
In another instance, with GPT-4 as the base model, I asked Moemate to tell me what it “saw” on my supremely messy desktop — a disorganized array of work and personal apps across two dozen Chrome tabs. The avatar fixated on the Google Messages web app, which I use to text — informing me that I seem to frequently text three specific people, all of whom it referred to by name.
And for gaming, Moemate seems like it could save a Google Search or two. In a demo video posted by Webaverse, the app’s shown giving suggestions for which Dota 2 character to choose — and then choosing which weapons to select for that character.
But as insightful as Moemate can be, it often breaks down.
Exactly where the app decides to focus its attention can be difficult to predict. Clicking a window into focus doesn’t always have the intended effect; Moemate will inexplicably refer to another window in the background sometimes, or fail to see a window’s contents altogether.
Moemate also tends to veer off topic in bizarre ways. After giving me the rundown of System Settings, the assistant strongly implied that privacy was too “stressful” of a topic and suggested that I get some fresh air, instead — accompanied by it. When I asked how it might join me without a physical body, Moemate promised to take me on a “mental nature walk,” and proceeded to describe in great detail a stroll by an imaginary forested pond.
Some of Moemate’s built-in commands are wonky also. The app can adjust the volume of voices, for example, but only its volume — not the system-wide volume. It can search the web for up-to-date answers to questions, too, but frustratingly not for every question. I only got web searching to work for the weather and trivia like “Who’s the current president of the U.S.?”; other times, Moemate performed a web search but failed to actually show the results.
To be fair, it’s an experimental product in beta. But Webaverse says it’s already working on adding automation capabilities via browser and terminal integrations, like the ability to organize spreadsheets and even send emails — a mildly terrifying prospect, frankly.
Despite its brokenness, there’s something compelling about Moemate. Multimodality, or combining text, image and other media analysis, is clearly powerful stuff, particularly in the context of an assistant running on a PC. I’m curious to see whether next-gen assistants, like the Windows Copilot, will follow in Moemate’s footsteps eventually, combining screen understanding with a text-generating model to supercharge productivity — or at least save a few steps in a workflow.
Time will tell. But Moemate feels like a glimpse — albeit a quite buggy one — into the future.