The gold rush in Generative AI is well and truly underway. Generative AI (GenAI) is now creating content — words, images, videos, and audio — that is often indistinguishable from that produced by humans. Writing, visual design, coding, marketing, game production, music composition, and product design are just a few of the areas of human creativity that are being rapidly impacted by GenAI. As creative services are integrated into products like Microsoft Office 365, Slack, Discord, Salesforce Cloud, and Gmail, GenAI will increase the productivity of billions of people before we know it. We will all soon use GenAI to create our first drafts of anything and everything.
So who will make money from GenAI? I asked OpenAI’s Dall-E-2 text-to-image service that question, and it produced the image below. Not bad.

Dall-E-2 prompt “Who will make money from Generative AI?”
In 2018, I wrote a popular blog post on Who is going to make money in AI. Here’s my follow-up post on the billions being invested in GenAI across thousands of new use cases. In essence, there are five ‘layers’ of potential value capture in this gold rush:
1. Infrastructure – the companies offering chips and cloud infrastructure that will run the massive underlying GenAI computer models.
2. Foundational Models — the companiesbuilding the huge text, image, audio, and other models that generate creative output.
3. Applications — the large and small firms that are building apps that will be used by consumers, businesses, and governments for creative tasks.
4. Industry and organizations — that, as part of their creative activities, will extract value from GenAI applications, tools, and platforms.
5. Countries — that will create, export, and deploy GenAI technologies both within and across national borders.
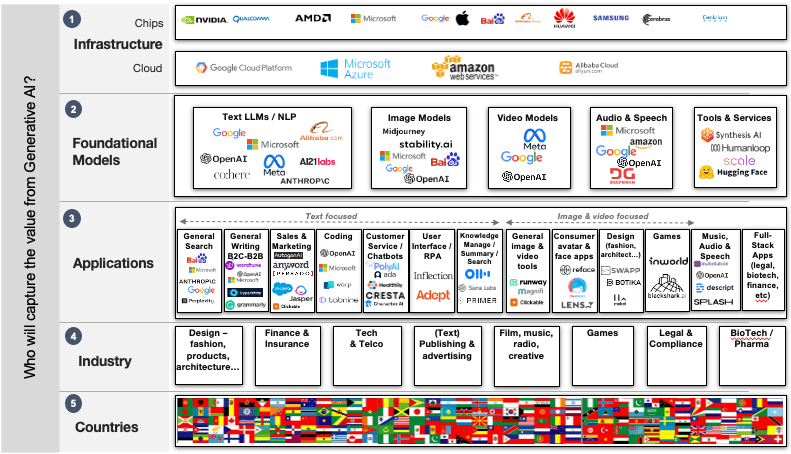
© The five layers of value capture in Generative AI
In each of these layers who will be the winners?
1. GenAI Infrastructure
BigTech companies already dominate in GenAI infrastructure with their cloud services and hardware chips.

Examples of BigTech and chip companies that will provide the GenAI infrastructure
Microsoft and Google are well-positioned in the US cloud market, while Baidu and Alibaba are well-positioned in China. Their massive supercomputer cloud infrastructure is engineered to run GenAI’s complex, expensive, large text, visual, and audio Foundational Models. There are already many developers using their cloud AI API services and tools to build apps, and this trend is expected to accelerate as entrepreneurs rush to address virtually limitless GenAI use cases. Amazon has been quiet on Foundational Models, so a big question is how will they respond.
GenAI uses massive amounts of computational power to generate creative outputs. Sam Altman, CEO of OpenAI, said:
we will have to monetize it [ChatGPT and Dall-E-e] somewhat at some point; the computer costs are eye-watering.”
Rumour has it that Open AI’s GPT-3 training cost USD$12 million in energy bills alone. No surprises that OpenAI took a further $10 billion investment from Microsoft in early 2023, much of which will be in the form of access credits to Microsoft Azure’s supercomputing infrastructure.
The chip makers are salivating over the need for supercomputer power. With a market cap of over half a trillion dollars, NVIDIA’s (NASDAQ: NVDA) stock price has risen from $60 in 2018 to $240 in early 2023. BigTech is also investing in their own AI-optimized chips. The recent US export ban on advanced AI chips to China will accelerate Chinese State aid and domestic investment in their semiconductor industry (as well as raise geopolitical tensions). Given the amount of investment required, the winners in this space will be those who are or are backed by big players.
2. Foundational Models
BigTech’s size and scope give them a competitive edge when it comes to developing GenAI Foundational Models. These models are trained on vast amounts of data, utilizing BigTech’s vast computational resources. For example, OpenAI’s GPT-3 text model, known as a Large Language Model (LLM), was trained on about 45 terabytes of textual data representing half a trillion words that were “hoovered up” from much of the English-speaking internet. Similarly, OpenAI’s Dall-E-2 text-to-image based model was trained on 650 million image-caption pairs.
BigTech does not want to lose its leadership in cloud services by failing to capture the enormous revenue streams generated by the billions of end users of these Foundational Models in the future. Microsoft has partnered with OpenAI, and Google recently launched its Bard language chatbot which complements its Imagen model for creating photorealistic images from input text.
Chinese BigTech is also not standing still. Alibaba is testing an in-house chat service. Baidu already provides ERNIE-ViLG, a text-to-image parameter model, and is currently testing a new chatbot service. BigTech’s size gives it several advantages that startups will find difficult to replicate.

Examples of Foundational Model providers of text, image, video and audio, as well as tools and services
BigTech has the advantage of scale to address issues of truth, bias, and toxicity in Foundational Models
BigTech may be the only players capable of dealing with GenAI’s darker side. Although GenAI is still in its infancy, problems with Foundational Models are becoming apparent. The issues range from truth (GenAI producing content that is simply wrong), bias (prejudice against specific groups) and toxicity (e.g. racist, misogynistic, or hate speech). In early 2023, a massive $100 billion was knocked off Alphabet’s market cap as the financial markets took fright at the erroneous and offensive answers Google’s Bard chatbot service gave. Microsoft’s limited release Bing chatbot also displayed troubling (and even racist) responses from users jailbreaking the safeguards, though its share price did not fall as precipitously. There is also a new type of cyberattack known as prompt injections which can circumvent guardrails by injecting malicious instructions.
The challenge for those developing these Foundational Models will be ensuring that their output is both responsible and accurate. Foundational Models cannot simply regurgitate biased and toxic content that has been scraped from the far reaches of the internet. These models are also hallucinatory. This means they confidently deliver well-constructed and eloquent answers to questions that may be factually incorrect. As Noam Shazeer, co-founder of Character.AI, stated in the New York Times:
“…these systems are not designed for truth. They are designed for plausible conversation.”
Or put another way they are confident bullshit artists.
BigTech cannot afford the reputational, financial, and strategic risks that Model failures could bring. They are building supervisory oversight systems that include guardrails and model tuning. To build trust with users and meet likely regulatory requirements, BigTech will need to engineer solutions for model transparency, explainability, and citation of sources. Reinforcement learning from human feedback (RLFH) will require a veritable army of people to review and rate model answers to questions. These are not simple problems to solve at scale. Once again, BigTech is well positioned due to its access to capital, engineering talent, datasets, and the scale of its human feedback loops that comes with having billions of users.
BigTech Models are not well suited for every situation
Despite their size and scale, BigTech will not be able to control the entire Foundational Model gold rush. Their models are broadly horizontal and well suited to answering, if not correctly, any conceivable consumer question. They are not, however, always as well suited to the needs of the enterprise with vertical tasks. Why? BigTech’s horizontal models (1) do not always perform well on specialist tasks, (2) frequently do not protect enterprise proprietary data, (3) are not trained on non-English languages, (4) lack transparency and explainability, (5) are not as well suited for use on edge devices and on-premise, (6) can be expensive to run in their cloud, and (7) create company dependence on BigTech.
A few, extremely well-funded startups are offering alternatives to BigTech Foundational Models
BigTech Foundational Models are not for everyone. This leaves room for a few extremely well-funded startups that have raised hundreds of millions of dollars, if not billions.
- Anthropic, founded in 2021 is focused on more reliable, explainable and steerable LLMs, and has raised over $1 billionwith the most recent investment of $300 million coming from Google.
- AI21labs has raised $119 million for its Jurassic-1 text model. With over 178 billion parameters, Jurassic-1 is similar in size to GPT-3.
- Cohere has raised $165 millionfor LLMs and natural language processing (NLP) as a service.
- BLOOM is a private–public research LLM project supported by private sector Hugging Face and European research institutes to create an open source LLM with 176 billion parameters. It is has been trained on 46 human languages, including twenty African languages that are underrepresented in most LLMs.
- UK based Stability AI recently raised a whopping $100 million for a valuation north of $1 billion for its open-sourced image generation service, Stable Diffusion.
BigTech is aware of their model limitations, particularly Microsoft, which recently announced that enterprises will be able to “fine-tune” their models without fear of proprietary data being shared in order to build a better model for all.
However, these steps will not satisfy everyone. Adelph Alpha, a German startup that has raised $31 million, is addressing enterprise concerns about BigTech Foundational Models with its own “European” centric models. But, it is unclear whether they will be able to compete at scale.
BigTech will win the race for horizontal Foundational Models, leaving room for a few highly capitalized startup alternatives. Perhaps open-source models like BLOOM and Stable Diffusion will get scale or at least find a niche existence. As is customary, there will be tools and service providers who profit from making it easier to work with these Foundational Models. But overall:
BigTech’s market dominance will be amplified by their ability to effectively give away their Foundational Models for free because they will make the majority of their money from their underlying cloud services.
3. Generative AI Applications
While BigTech will win the picks and shovels of the GenAI gold rush, the application layer is much more of a level playing field. Existing enterprise software companies, “full stack” startups, and thousands of startups enabled by these Foundational Models will offer new GenAI applications.
Traditional enterprise software companies, such as Salesforce and Microsoft, will organically or thought acquistion bring GenAI capabilities to their billions of users. Microsoft is also integrating its GenAI chatbot service into its Bing search application, directly challenging Google’s search hegemony.
A small number of well-funded startups will offer specialized “full stack” applications. In domains with specialized data, sequences, and computational requirements, these companies will develop their own underlying Foundational Models. For example, GenAI could revolutionize drug discovery and materials science by building their own models with applications. Investors will be drawn to these startups as they could offer substantial financial rewards as well as strong competitive defensibility.
Adept AI, for example, has raised $65Mto develop the next generation of robotic process automation (RPA) with natural language interfaces based on LLMs. In stealth mode, Inflection.ai is doing something similar. Character.AI, a chatbot that adopts the voice and knowledge of characters, raised $200M — $250M at a circa $1 billionvaluation for a full-stack implementation of specialized LLMs to support live-agent enterprise applications.
The adoption of GenAI will be extremely fast. If afirst draft of, say, an AI generated marketing pitch isn’t perfect, then it is simple to edit. ChatGPT was the fastest growing consumer app in history, with over 100 million monthly active users in just over two months after launch. This means that the battle for the nearly infinite number of GenAI creative applications will be fierce and fast.

Examples of primarily startups that provide apps to address major GenAI use cases
There will be a “Copilot” GenAI app for every imaginable use case
Putting GenAI to use will see consumers, businesses, and organizations around the world use applications enabled by startups built on top of these Foundational Models. Many GenAI startups will use the “Copilot for X” business model to assist users with “creative” tasks like writing or coding, as well as repetitive tasks like data entry or form filling. Here are a few of the startups competing to make money in various vertical use cases.
- General text writing startups are assisting users in real-time with day-to-day writing tasks such as email composition, document creation, and text form completion. AI21labs’s Wordtune will “rewrite your text as if it were a professional copywriter.” The king of writing assistants is Grammarly who has banked over $400 million. The list of writing startups is long and includes Lex, HyperWrite, Compose AI, and Rytr.
- Sales and marketing startups include the mammoth Jasper.ai which has raised $145M. Anyword has raised over $45 million to provide “high-converting textual content for sales.” Persadoraised over $66 million for language generation and “outperforms your best copy 96% of the time.” Startups are increasingly specializing in specific tasks such as writing product marketing descriptions.
- Image generation startups are being powered by Open AI’s DALL-E-2, Stability AI’s Stable Diffusion, and Midjourney’s text-to-image Foundational Models. Startups include Art Breeder that helps users create collages.
- Consumer facial and avatar startups include Lightricks’s Facetune app that assists in creating the “perfect’ Instagram image.” Lightricks has raised $350 million. Individual “magic avatars” can be created by users of the very popular Lensa AI app. Reface, which lets users swaptheir faces into different settings, has raised $5.5 million.
- Product design startups include Botika who is “reinventing fashion shoots” with hyper-realistic images of models dressed in high-quality clothing in various settings. Maket assists in “generating architectural plans from text prompts in minutes, not months.” Tailorbird expedites the creation of floor plans for homeowners looking to renovate. Swapp has raised $7 million to help automate construction documents for projects. TestFit has raised $22 million to aid inreal-estate design.
- Video focusedstartups offer video ideation, generation, editing, and workforce collaboration tools. Runway is the most well-funded with nearly $100 million in the bank. Magnifi has raised over $60 million for video editing, while InVideo has raised over $53 million. Several startups, including Hour One, which has raised $26 million, provide text-to-video services. Synthesia, based in London,has raised over $67 million for its avatar video creation platform. Overall NFX is tracking 54 companies that have raised a total of $0.5 billion for generative video startups.
- Audio GenAI startups include music creation companies Soundraw, Boomy and Aiva. Splash has raised $23 million and allows users to create original music and sing lyrics to any melody. DupDub has raised over $250 million for voice overservices and claims a million users. Descript has raised over $100 million and provides voice cloning for audio transcription, podcasting, screen recording, audio, and video editing. Deepgram’s speech to text servicecompetes with BigTech and OpenAI’s Whisper and has received over $87 million in funding.
- Games generation startups hope to save production studios $100s millions in production costs. Masterpiece Studio has raised $6 million tocreate 2D to 3D models. Replica has raised $5 million to focus on AI voices actors for games, films and the meta-verse. Latitude/AI Dungeon is a game studio that has raised $4 million for text based game generation. VoiceMod has raised over $7 million to provide real-time voice changing in games like Fortnite and apps like Skype. Ponzu is a startup for creating 3D surface textures, and Charisma AIis a startup for creating non-player creation (NPC) virtual characters. Inworld has raised $70 million for its AI developer platform for the “creation of immersive realities, virtual characters, and metaverse spaces”. Overall A16Z currently tracks more than 50 startups in the games industry.
- Chatbot and conversational AI startups include vertical health symptom checkers ada, which has raised $190 million, and UK-based Healthily, whichhas raised about $70 million. Given that AI could save call centre businesses $80B annually, startups are raising massive sums. Cresta AI has raised more than $150 million, and London based PolyAI has raised $68 million for its “superhuman voice assistants.”
- Coding co-pilot startups are following the lead of Microsoft’s GitHub Copilot, whichclaims that up to 40% of code can be generated automatically. Warp, a company that that converts natural language into computer commands, has raised $70 million. Tabnine has raised $30 million.
- Knowledge management, summarization, and enterprise search startups include Primer AI, which has raised $168 million, and Otter which has raised $63 million. Sana Labs, a Stockholm based startups,has raised $54.6 million to facilitate the discovery, sharing, and repurposing of information within organizations.
So which startups will win?
There is no shortage of capital flowing into GenAI application startups. Full stack startups will raise large sums of money in vertical domains such as drug discovery, where they will create highly specialized models and applications. In the broader B2B space, the race will be horizontal and vertical, with copilot business models at the centre. On the one hand horizontal startups will provide services across industries, such as Jasper’s sales and marketing assistant. On the other hand, startups are increasingly vertically focused by industry, function, and task.
Winners will achieve scale and defensibility by implementing the following:
- Strong ROI — for their use case, as well as a short time to proof of value.
- Proprietary and customized Foundational Models — “fine tuned” for specific audiences using localized, specialized, and proprietary company data.
- Workflows — proving usability and deep integration into customer processes, making it difficult to remove once installed.
- Feedback loops — from reinforcement learning from human feedback (RLFH), for example, to improve model alignment with user intent.
- Flywheel dynamics — the moreRLFH and other feedback, the better the model performance through “fine tuning”, the greater the usage, and thus momentum grows.
- Scale and speed of investment — with lower profit margins as much as much of the IP belongs in the Foundational Models, the game is all about scale. Those who can quickly build their brand and attract a high numbers of users and customers to get the flywheel spinning will thrive as category leader.
In the B2C GenAI consumer space, horizontal players with speed and massive consumer acquistion budgets are likely to win their race.
AutogenAI, based in the UK, is anexample of a B2B startup company that is well positioned to win its category of bid management copilot. They’ve spent the last two years developing an app that helps businesses save time, money while also improving the quality of bids, tenders, and proposals. They have “fine-tuned” the OpenAI LLM using examples of company website content, winning and losing sales bids, marketing copy and annual reports. They also provide a human-machine supervisory user interface to assist in reviewing the source and accuracy of generated content and facts. This also provide a critical human reinforcement learning loop with increased usage. Customers are increasingly using their application as a next generation knowledge management and search tool, making it stickier.
A few GenAI startups will be acquired and become features in larger enterprise and consumer applications. For example, largesocial media companies with millions of users will acquire the latest face and avatar creation startups. Incumbent graphic design software companies will acquire the most promising image and video editing startups. Microsoft, for example, is now offering GenAI “Microsoft Dynamics 365 Copilot” natively as part of its CRM and ERP applications.
In short, a few lucky and brave startups will hit pay dirt if they can quickly build scale and a flywheel for their copilot use cases. Similarly, a few full stack startups will prosper in specialized use cases like drug discovery. Due to their large fundraising rounds, uniforms markets, and quick adoption of innovation by people, businesses, and governments, US startups will dominate. But, the majority of startups will go home empty-handed having contributed to the profits of the providers of the picks and shovels of this gold rush —predominantly American BigTech.
This is the first in a series of posts about who will make money from Generative AI. In subsequent posts I will discuss which organizations will benefit the most from GenAI, as well as which countries and citizens will benefit the most from this technology.
I welcome your feedback.
Simon Greenman is a pioneer in artificial intelligence and technology innovation. As co-founder of MapQuest, he helped launch one of the first internet and AI brands. Currently a Partner at Best Practice AI advising on AI strategy, technology, and governance, he recently served on the World Economic Forum's Global AI Council, contributing to their Board and C-Suite AI toolkits. Simon has spent over a decade as Chief Digital Officer leading digital transformations of directory companies and was CEO of HomeAdvisor Europe that offers leading marketplaces for tradespersons. He worked with prominent companies like Bowers & Wilkins, AOL, and Accenture. He is active in the UK start-up ecosystem and holds an MBA from Harvard Business School as well as a BA in Computing and Artificial Intelligence from the University of Sussex. He is a Fellow of the Royal Geographic Society.
Original. Reposted with permission.
More On This Topic
- 5 Lessons McKinsey Taught Me That Will Make You a Better Data Scientist
- ChatGPT, GPT-4, and More Generative AI News
- Are Data Scientists Still Needed in the Age of Generative AI?
- Synthetic Data Platforms: Unlocking the Power of Generative AI for…
- Free From Google: Generative AI Learning Path
- Whose Responsibility Is It To Get Generative AI Right?
 AI is the latest in that long line of hopefuls. Indeed, it has pretty much earned its place: Large language models are incredibly interesting and can serve a host of new and existing applications. Invariably, that has spurred public-market investors to expect tech companies to unlock new opportunities for growth from AI. Tech CEOs feel the same way, as do venture capitalists.
AI is the latest in that long line of hopefuls. Indeed, it has pretty much earned its place: Large language models are incredibly interesting and can serve a host of new and existing applications. Invariably, that has spurred public-market investors to expect tech companies to unlock new opportunities for growth from AI. Tech CEOs feel the same way, as do venture capitalists.

 https://t.co/fDHYNpGrta
https://t.co/fDHYNpGrta pic.twitter.com/dOXDWOLKSY
pic.twitter.com/dOXDWOLKSY