OpenAI launched ChatGPT Enterprise this week to give businesses access to its popular chatbot technology with added protections and capabilities. Among its first customers is a bank.
If you are a fan of "buy now, pay later" services, you are likely familiar with Klarna. The company offers flexible payment options for online shoppers and deal recommendations.
Also: The moment I realized ChatGPT Plus was a game-changer for my business
Now, Klarna is the only bank among ChatGPT Enterprise's launch customers.
Klarna is using ChatGPT Enterprise to bring the power of AI to all Klarna employees, taking advantage of the added security measures and higher speed made available through the enterprise version of the chatbot.
Klarna isn't new to using AI for its business model. In addition to its own AI-based tools, such as its AI-product recommendation engine, the company implemented OpenAI's API, which 2,500 Klarna employees have leveraged for a variety of use cases. These include AI-powered shopping recommendations and even customer service, according to the company.
Also:How to use Claude AI (and how it's different from ChatGPT)
Although 2,500 employees is a significant amount of employees implementing ChatGPT into their workflows, it accounts for only 50% of Klarna employees. Klarna CEO Sebastian Siemiatowski wants to ensure that more employees use the technology.
"So even though we push everyone to test, test, test and explore, still only 50 percent of our employees use it daily," said Siemiatowski. "That's why we have to find new ways to get more people to use OpenAI's fantastic tech."
The hope is that by implementing ChatGPT Enterprise, that number will increase from 2,500 employees to everyone at Klarna, ensuring all employees can access and use ChatGPT.
Also: Meta uses your Facebook data to train its AI. Here's how to opt out (sort of)
"With the integration of ChatGPT Enterprise, we're aimed at achieving a new level of employee empowerment, enhancing both our team's performance and the customer experience," said Sebastian Siemiatkowski, CEO of Klarna.
The optimism and commitment Siemiatkowski has in regard to expanding AI usage at Klarna is notable because it differs from most banks' strategies, including Bank of America, Citigroup, JPMorgan Chase, Goldman Sachs, and Wells Fargo, which have taken an entirely different approach by reportedly banning AI usage entirely.
These banks' decisions to ban generative AI chatbots are likely motivated by concerns about privacy and data security, especially because generative AI models notoriously use user data inputs to train their models further.
Also: Only 18% of Americans have ever used ChatGPT, according to Pew Research
Clearly these concerns aren't stopping Klarna or other early users of ChatGPT Enterprise, such as Block, Canva, Carlyle, The Estée Lauder Companies, PwC, and Zapier, from adopting the technology. If these companies' implementations are successful, they will likely help build trust and encourage other companies to adopt ChatGPT Enterprise as well.
Generative AI tools have the ability to assist employees with multiple elements of their workflow, including writing, coding, organizing, brainstorming, and more. Despite the many benefits, many employees refrain from using AI due to concerns about what it will say about their work ethic, a study shows.
Asana issued its "The State of AI at Work" report in which the company surveyed 4,500 contributors, including middle and senior managers, and executives in the US and UK regarding their thoughts about AI at work.
Also: Klarna is all in on ChatGPT Enterprise. Here's why it's so surprising
Out of the people surveyed, 26% of workers said they were worried they would be viewed as lazy for using AI, while one in five workers admitted they would feel like frauds for using the technology.
Even more alarming is that a whopping 92% are concerned about AI being used unethically. All three of these findings show the need for clear AI policies that define what is allowed and encouraged.
When the respondents were asked about their companies' AI policies, only 30% of US knowledge workers said their company has established policies or guidance around AI usage at work. The number was even lower for UK knowledge workers at 20%.
Similar issues have been highlighted by other surveys, too, indicating a need for strong AI leadership.
Also: The moment I realized ChatGPT Plus was a game-changer for my business
As previously reported on by ZDNET, Salesforce surveyed 4,000 desk workers, of which 62% of respondents said they don't have the skills to effectively and safely use generative AI.
"Employees can't navigate this AI shift alone," said Saket Srivastava, Asana CIO. "They need clear guidelines to understand AI's role in their functions, along with tailored training and accessible technologies to fully harness AI's capabilities."
Despite the concerns, there is still a strong sense of optimism regarding the potential of AI in the workplace. Most of the employees (52%) believe that AI will help their company hit its objectives more effectively, including 61% of executives and 46% of individual contributors.
At the recent Google Cloud Next event in San Francisco, Google surprised everyone by announcing that they’re offering Llama 2 and Code Llama from Meta, as well as Falcon LLM on Google Cloud’s Vertex AI. This was unexpected because Google was the only cloud service provider that hadn’t partnered with rival institutions to host Llama 2 or any other open source LLM models before this.
It appears this decision by Google has been taken keeping enterprises in mind who are staple customers of Vertex AI but are looking for more options. If we go by the trend, after GPT-4, Llama 2 is the most sought after large language model, considering it is open-sourced and commercially available. In the case of Llama 2, Google said that it is the only cloud provider offering both adapter tuning and RLHF.
Despite being ad rivals, Meta and Google have put aside their competition when it comes to large language models. Meta directly does not want to compete with anyone in the LLM business and is happy to provide Llama 2 to everyone. Now with Google Cloud having Llama 2, Meta has conquered every territory possible. In fact, didn’t Meta just reverse the saying: “If you are good at something, never do it for free”?
However, Google accepting Llama 2 raises one question: Is PaLM 2 not capable enough? Google Bard currently uses PaLM 2 and it seems like it isn’t a favourite among enterprises as they cannot customise it according to their requirements, in addition to its poor responses when compared to ChatGPT.
The tech giant claims that its Model Garden has a collection of 100+ models including enterprise-ready foundation model APIs, open source models, and task-specific models from Google and third parties. Google should understand that when it comes to LLMs, it’s not about the quantity but about the quality.
Recently OpenAI also took cues from Meta’s approach and is now working to provide customisation options for GPT-4 and GPT-3.5 while avoiding open sourcing. To achieve this, the creator of ChatGPT recently introduced the GPT-3.5 Turbo API for fine-tuning. Additionally, it has partnered with Scale to fine-tune GPT-3.5, in order to woo enterprises.
LLM Cloud Battle Begins
Google might have been late to the game, but there is still hope, following the AWS route. Google has understood the importance of hosting multiple LLMs, much like Amazon’s Bedrock platform. Currently, Bedrock hosts models from AI21, Cohere, Anthropic Claude 2, and Stability AI SDXL 1.0.
At present, Microsoft is actively exploring different LLMs. Microsoft Azure currently encompasses all OpenAI services via APIs, including the Azure OpenAI Service. This empowers enterprises and developers to create applications using GPT, DALL·E, and Codex.
When Llama 2 was launched by Meta, Azure was announced as the preferred partner for Llama 2. It seems like Microsoft is not going to stop here, as it further plans to sell a new version of Databricks’ software on Azure that will help customers make AI apps for their businesses. This new service will help companies make AI models from scratch or repurpose open-source models as an alternative to licensing OpenAI’s proprietary ones.
In the latest quarter, Azure emerged as the winner with 26% revenue growth, thanks to Azure OpenAI services. However, now with Llama 2 being the common factor among all three clouds, it will be intriguing to witness who will lead the LLM cloud game in the upcoming quarter.
What about Gemini? As Vertex AI now hosts Llama 2 and has shifted its focus to smaller models, similar to the approaches of Microsoft and AWS, it raises the question of the feasibility of creating Gemini to take on GPT-5. This consideration is particularly relevant as OpenAI has also redirected its focus towards serving enterprises.
Not to forget, Google’s Codey has a new rival called Code Llama, only time will tell who codes better, alongside its adoption among the enterprise customers and developers.
The post Google Cloud Tames Llama 2 with RLHF appeared first on Analytics India Magazine.
China's autonomous vehicle maker Baidu has released its generative artificial intelligence (AI) model to the general public, in the hopes of gathering user feedback to improve the platform.
Currently available only in its domestic market, Ernie Bot can be downloaded via local app stores or accessed via Baidu's site.
Also:A new role emerges for software leaders: Overseeing generative AI
The Chinese tech giant also plans to release AI-native apps that it said will deliver four key capabilities of generative AI: Encompassing reasoning, memory, generation, and understanding.
With Ernie Bot now available to China's vast internet community, Baidu hopes to gather "real-world" user feedback to improve its foundation AI model, said its co-founder and CEO Robin Li. It also will be able to more quickly push out further iterations of the chatbot for better user experience, according to Li.
First released in March this year with limited access, Ernie Bot is built on a foundation AI model that Baidu said has topped more than 10 local and international evaluations. The AI model previously was available to users with invitation codes, with its API accessible via Baidu AI Cloud.
Also:The best AI chatbots
Ernie Bot, among other touted capabilities, can generate text, images, audio, and video given a text prompt, and can deliver voice in several local Chinese dialects, including Sichuan. Since its introduction in March, the AI model has gained proficiency in more than 200 genres of writing, clocking a 1.6-fold increase in content quality, according to Baidu. Five plugins were also added to Ernie Bot this month, including Baidu Search, data analytics and visualization, and text-to-video.
The Chinese vendor said it had invested 140 billion yuan ($19.22 billion) in research and development over the past 10 years and offers an AI portfolio that includes applications, models, and chips.
With its public launch Thursday, Baidu's Ernie Bot is among the first generative AI apps to be made available to the general public in China, where other local AI vendors reportedly are set to follow suit with their own offerings.
Zhipu Ai, SenseTime, and Baichuan Intelligence Technology are among those to introduce generative AI products after also securing government approval to do so, reported Reuters. Citing local media, the news wire added that 11 companies got the go-ahead to launch AI products locally, including ByteDance.
Also:Everyone wants responsible AI, but few people are doing anything about it
Several Chinese market players in recent months have unveiled generative AI models, primarily for enterprise deployment. E-commerce giant JD.com last month launched its large language model ChatRhino, which it said is customized to support verticals such as logistics, retail, health care, and finance.
Tencent and Alibaba also announced efforts to offer or integrate generative AI into their products. Alibaba Cloud in April unveiled its large language AI platform, called Tongyi Qianwen, which is currently available to customers in China for beta testing and as an API to developers. The Chinese cloud vendor also introduced a partnership program to fuel the development of AI applications for verticals, including finance and petrochemicals.
The accelerated drive toward AI comes amid interim regulations in China, which were pushed out to ensure the healthy development of the technology and safeguard both national security and public interests, the Chinese government said.
Also:AI safety and bias: Untangling the complex chain of AI training
Effective from Aug. 15, the interim legislation outlines various measures that aim to facilitate these objectives, including steps to be taken to improve the quality of training data, such as its accuracy, objectivity, and diversity. Generative AI service providers also assume legal responsibility for the information generated and its security, and they must sign service-level agreements with users of their service, clarifying each party's rights and obligations.
Generative AI developers have to ensure their pre-training and model optimization processes are carried out in compliance with the law. These include using data from legitimate sources that adhere to intellectual property rights. Should personal data be used, the individual's consent must be obtained or it must be done in accordance with existing regulations.
Google TPU v5e AI Chip Debuts after Controversial Origins August 31, 2023 by Agam Shah
The dominance of Nvidia GPUs has companies scrambling to find non-GPU alternatives, and another mainstream option has emerged with Google’s TPU v5e AI chip.
The TPU v5e is also Google’s first AI chip being mainstreamed with a suite of software and tools for large-scale orchestration of AI workloads in virtual environments. The AI chip is now available in preview to Google Cloud customers.
The new AI chip succeeds the previous-generation TPUv4, which was used to train the newer PaLM and PaLM 2 large language models used in Google search, mapping, and online productivity applications.
Google has often compared its TPUs to Nvidia’s GPUs but was cautious with the TPU v5e announcement. Google stressed it was focused on offering a variety of AI chips to its customers, with Nvidia’s H100 GPUs in the A3 supercomputer and TPU v5e for inferencing and training.
The Cloud TPU v5e is also the first Google AI chip available outside the US. The TPUv4 was available only in North America. The TPU v5e computers will be installed in the Netherlands for the EMEA (Europe, Middle East, and Africa) markets and in Singapore for the Asia-Pacific markets.
The origins of TPU v5 were mired in controversy. Researchers at Google informally announced TPU-v5 in June 2021 and, in a paper, said AI was used to design the chip. Google claimed that AI agents helped floor-plan the chip in under six hours faster than human experts. There were internal debates on the claims made in the paper, and Google fired one researcher ahead of the paper’s appearance in Nature magazine.
Academic researchers also called out Google’s claims and criticized the company for not opening it up for public scrutiny. A researcher, Andrew B. Kahng, from the University of California, San Diego, later reverse-engineered Google’s chip-design techniques and found that human chip designers and automated tools were sometimes faster than Google’s AI-only technique.
Google has maintained a silence on that controversy but has moved ahead and is building an AI empire around TPUs. The company’s large-language models are optimized to run on TPUs, and the new chips are critical to Google’s data centers as the company infuses AI features across product lines.
The performance numbers point to the TPU v5e being adapted for inferencing instead of training. The chip offers a peak performance of 393 teraflops of INT8 performance per chip, which is better than 275 petaflops on TPU v4.
The new Google TPU v5e is more efficient and more scalable than v4, Google says.
But the TPU v5e scores poorly on BF16 performance, with its 197 teraflops falling short of the 275 teraflops on the TPU v4.
But TPU v5e could outperform the TPU v4 when conjoined in clusters. The TPU v4 could be configured in clusters of 4,096 chips, but TPU v5e can expand to hundreds or thousands more configurations and tackle even larger training and inferencing models.
Google Cloud executives Amin Vahdat and Mark Lohmeyer, in a blog entry said “the size of the largest jobs at a maximum slice size of 3,072 chips for TPU v4,” and not 4,096 chips, as previously claimed. But with TPU v5e, the company has introduced a technology called “Multislice,” which can network hundreds of thousands more AI chips together in a cluster.
Multislice “allows users to easily scale AI models beyond the boundaries of physical TPU pods — up to tens of thousands of Cloud TPU v5e or TPU v4 chips,” Google executives said.
Google has also finetuned virtual machines for TPU v5e so chips can process multiple virtual machines simultaneously. Google announced the availability of the Kubernetes service for Cloud TPU v5e and v4, which will help orchestrate AI workloads across the TPUs.
Google said the largest configuration could deploy 64 virtual machines across 256 TPU v5e clusters. The TPUs work with machine-learning frameworks that include Pytorch, JAX, and TensorFlow.
“TPU v5e is also incredibly versatile, supporting eight different virtual machine configurations, ranging from one chip to more than 250 chips within a single slice. This feature allows customers to choose the right configurations to serve a wide range of LLM and gen AI model sizes,” Google execs wrote.
Each TPU v5e chip has four matrix multiplication units, a vector, and a scalar processing unit, which are all connected to HBM2 memory.
Google’s data centers have a swap-in, swap-out high-bandwidth infrastructure with optical switches that link up AI chips and clusters. The optical interconnect allows each rack to operate independently and interconnected on the fly, and technology allows Google to quickly reconfigure the network topology depending on the application.
Google provided interesting performance comparisons to TPU v4 based on cost. The benchmark is a practical assumption of the cost of training and the size of a model. Microsoft and Google are investing billions in their data center infrastructure so companies can train and deploy larger AI models
For every dollar, the TPU v5e is up to two times faster in training and 2.5 times inferencing times. The TPU v5e is priced at $1.2 per chip hour, while the TPU v4 is about $3.2 per hour.
“At less than half the cost of TPU v4, TPU v5e makes it possible for more organizations to train and deploy larger, more complex AI models,” the Google executives said in the blog.
Google has shared the TPU v5e configurations on its website, which are broken up into training and inference pages.
The training model is for “transformer, text-to-image, and Convolutional Neural Network (CNN) training, finetuning, and serving,” Google said on its website.
Google separately announced that the A3 supercomputer, which has up to 26,000 Nvidia H100 GPUs, will be generally available next month. The A3 is designed for companies working with massive large-language models, including financial, pharmaceutical, and engineering firms.
Google’s TPU compute infrastructure was mentioned as an ace up its sleeve by research firm SemiAnalysis in a post on August 27. The post largely addressed “GPU Poors,” or companies that do not have ready access to GPUs that are in heavy demand. The post elicited an unprovoked response from Sam Altman, the CEO of OpenAI, who wrote, “Incredible google got that SemiAnalysis guy to publish their internal marketing/recruiting chart lol.” The exchange was largely friendly banter with no serious punches thrown.
OpenAI’s infrastructure is swimming in GPUs in part thanks to Microsoft’s AI infrastructure, which has doubled down on graphics chips from Nvidia. Cloud providers charge a significant premium to access Nvidia’s A100 and H100 GPUs. But unlike Microsoft, Google is not putting its eggs in one basket, and adding TPUs allows a range of AI offerings at multiple price points.
Amazon AWS has also integrated its homegrown Trainium and Inferentia chips for training and inferencing. Intel has a $1 billion pipeline of orders for its AI chips, which include Gaudi2 and Gaudi3 chips.
This article first appeared on sister site HPCwire.
Google overlooking the transformers paper in 2017 has cost them a staggering $6.2 billion – a collective valuation of all the AI startups built on transformers by the foundation team. Now, the last of the eight authors of the pivotal paper is (also) leaving the Big Tech to start his own company. Llion Jones said he will be joining his fellow ex-Google research scientist David Ha in the new endeavour to start Sakana AI.
The paper titled ‘Attention Is All You Need’ was ‘born’ when the authors were, at Google’s meal time, discussing ways to make computers generate text efficiently. After running tests for the next five months, the team wrote the paper having no idea of what’s coming next. Their work made the once-dominant architecture Recurrent Neural Nets (RNNs) in language processing largely obsolete.
Notably, the transformer architecture represents the T in ChatGPT and chatbots akin. The 2017 paper laid the foundation to the generative AI wave initiated by OpenAI after making GPT models accessible to the public (and enterprises). Jones, along with the co-authors, are finally getting the due credit for their billion dollar paper that Google misjudged six years ago.
“It’s only recently that I’ve felt … famous?” Jones recently told The Washington Post. “No one knows my face or my name, but it takes five seconds to explain: ‘I was on the team that created the ‘T’ in ChatGPT’.”
The $6.2 billion-worth underdogs
One standout is ‘Cohere’, founded in 2019 by Aidan N Gomez, Ivan Zhang and Nick Frosst. This NLP-focused enterprise startup has soared to a valuation of $2.2 billion. Reports reveal that Tiger Global, having invested initially, will sell a stake, reaping a 40% markup on the current valuation — reflecting on the startup’s rise.
‘Adept’, another fledgling startup with just a year under its belt, has not only secured a valuation of $1 billion but has also managed to raise an impressive $350 million in venture capital this year. Founded by lead author Ashish Vaswani and Niki Parmar, the startup’s minimalist workforce of 25 belies its profound impact. The duo’s entrepreneurship goes beyond Adept. Their undisclosed startup, still in stealth mode, has raked in $8 million in funding led by Thrive Capital.
Noam Shazeer, another author of the transformative paper, co-founded ‘Character.AI’, a chatbot startup that rose to a valuation of $1 billion. A $150 million funding round led by Andreessen Horowitz solidified the company’s status as a unicorn earlier in 2023.
The narrative doesn’t end here. Illia Polosukhin founded the high-performance blockchain called ‘NEAR Protocol’ in 2017, which has a valuation of $2 billion. The latest fundraising tally of $350 million was the second nine-figure raise within four months by Polosukhin’s brainchild.
Jakob Uszkoreit, who came up with the name Transformer, founded Inceptive in 2021 to use deep learning and learn life’s languages. During his 13-year stint as a senior software engineer, he built the language understanding team of the Google Assistant and worked on Google Translate during its early days. Inceptive’s value currently remains undisclosed. As recognition finally trickles in, it is a fitting closure to see Lukasz Kaiser, one of the eight author of the paper, find his place as a member of the technical staff at OpenAI two years ago.
Attention was all they needed
Back in 2017, least did Google know that its paper would eventually be cited around 90,000 times by other researchers, and the transformer architecture would underpin ChatGPT, Midjourney and the rest. While Google shared the discovery with the world, the company itself didn’t put the content generation technology to use straight away. Google kept it in hibernation till CEO Sundar Pichai took the stage at Google I/O 2021 to announce LaMDA. The company did not strike gold unlike OpenAI due to the ‘Is AI sentient?’ controversy that summer.
The Washington Post pointed out that the company went wrong with its scaling strategy. Out of the estimated 140,000 employees, over 7000 people are dedicatedly working on AI as per BloombergOpinion. Comparatively, OpenAI has a much smaller workforce — about 150 AI researchers out of the approximately 375 employees in 2023.
The company’s gigantic workforce added to certain layers to sign off on ideas half-a-decade ago, several former employees have confessed. Furthermore, the search giant has a very high bar for turning ideas into products, Polosukhin said in an interview. The company’s inertia and intolerance towards experiments with dead ends and iterations is another reason the transformers team decided to walk through the exit door. Moreover, there were more exciting innovations happening outside the Mountain View HQ which led to the talent exodus.
While the company has been experimenting with models like PaLM, LaMDA and Bard, there is still no hint of a significant product. While Google stashed it away, startups capitalised on the technology to remove language barriers between humans and machines. The ground-breaking paper overlooked by the company has made Google a victim of its own success.
The post Google’s $6.2-Billion Missed AI Opportunity appeared first on Analytics India Magazine.
The Burtch Works 2023 Data Science & AI Professionals salary report utilizes proprietary data to explore demographic, geographic, industry, and compensation trends, offering valuable perspectives for professionals shaping their careers and for leaders seeking to attract, hire, and retain top-notch Data Science and AI talent for their teams.
Report highlights include:
2023 Salary Data: Gain valuable insights into the current salary trends and compensation benchmarks for data science and AI professionals across all job levels and expertise.
Hiring Changes and Marketplace Trends: Discover how the hiring landscape has evolved over the past year and learn about the various factors influencing hiring in the data science and AI industry.
Compensation Changes Over Time: Understand how compensation packages have changed over the years, enabling more informed decisions for career navigation or talent acquisition strategies.
Get your copy now, and update your compensation trends knowledge.
DOWNLOAD HERE
More On This Topic
2021 Data Engineer Salary Report Shares Insights on a Swiftly Evolving…
H1 2023 Analytics & Data Science Spend & Trends Report
2023 AI Index Report: AI Trends We Can Expect in the Future
Data Science Curriculum for Professionals
KDnuggets News, May 11: SQL Notes for Professionals; How To Structure a…
Saturnin Pugnet, founding member of Tools for Humanity, the company behind Worldcoin, has started the AGI conversation claiming that “Fusion and AGI are probably happening by 2030″. Stating that unlimited energy and intelligence will come to fruition by the end of the decade, instantly takes you back to what OpenAI CEO Sam Altman had predicted a couple of years ago. He said that the costs of intelligence and energy are going on a path towards near-zero and that by 2030 “AI revolution and renewable + nuclear energy will get us there”.
The AI-Energy Discussion
The AGI conversation continues with everyone working towards achieving it but none having made any actual progress on the same. However, it is interesting that fusion energy and AGI have been clubbed together in conversations. In a recent tweet, Altman mentioned that building AGI is a scientific problem and superintelligence is an engineering problem.
Altman has been actively investing in nuclear energy companies such as Helion Energy and Okla Inc where the latter has been merged with AltC, a company where Altman is the CEO. With abundant energy being required for computing, creating a path for energy becomes evident. Furthermore, with big tech companies actively investing in nuclear energy, fusion energy is highly sought after.
Interestingly, Pugnet’s project Worldcoin has been designed to cater to a future where AGI or AI will create an employment deficit in the far future, where universal basic income (UBI) will be provided through the project. Considering how Altman has invested in Worldcoin and nuclear energy, a tweet by Pugnet that resonates with Altman’s thoughts is not surprising.
The post AGI Likely to Happen by 2030 appeared first on Analytics India Magazine.
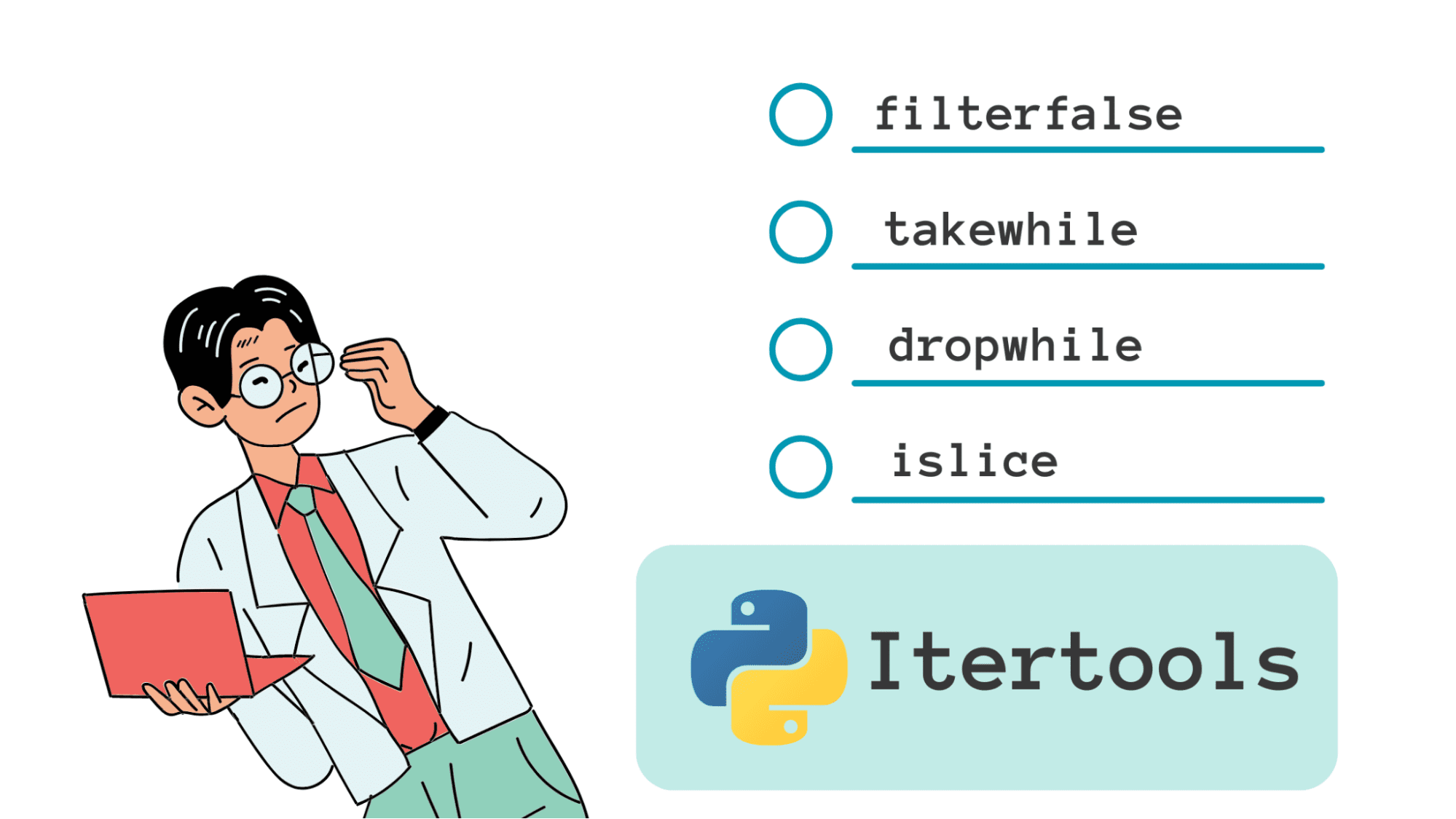
In Python, iterators help you write more Pythonic code—and work more efficiently—with long sequences. The built-in itertools module provides several helpful functions that create iterators.
These are especially helpful when you want to just loop through the iterator, retrieve elements in the sequence, and process them—all without having to store them in memory. Today we’ll learn how to use the following four itertools filter functions:
filterfalse
takewhile
dropwhile
islice
Let's get started!
Before You Begin: A Note on Code Examples
In this tutorial:
All the four functions that we’ll discuss give iterators. For clarity, we’ll work with simple sequences and use list() to get a list containing all the elements returned by the iterator. But refrain from doing so—unless necessary—when working with long sequences. Because when you do so, you’ll lose the memory savings that iterators give you.
For simple predicate functions, you can also use lambdas. But for better readability, we’ll define regular functions and use them as predicates.
1. filterfalse
If you’ve been programming in Python for a while, you’ll have likely used the built-in filter function with the syntax:
filter(pred,seq) # pred: predicate function # seq: any valid Python iterable
The filter function gives an iterator that returns elements from the sequence for which the predicate returns True.
Now let’s learn about filterfalse. We’ll import the filterfalse function (and all other functions that we’ll discuss) from the itertools module.
As the name suggests, filterfalse does the opposite of what the filter function does. It gives an iterator that returns elements for which the predicate returns False. Here’s the syntax to use the filterfalse function:
from itertools import filterfalse filterfalse(pred,seq)
The function is_even returns False for all odd numbers in nums. So the nums_odd list obtained using filterfalse is the list of all odd numbers in nums:
from itertools import filterfalse nums_odd = filterfalse(is_even, nums) print(list(nums_odd))
Output >>> [1, 3, 5, 7, 9]
2. takewhile
The syntax to use the takewhile function is:
from itertools import takewhile takewhile(pred,seq)
The takewhile function gives an iterator that returns elements so long as the predicate function returns True. It stops returning elements when the predicate returns False for the first time.
For an n-length sequence, if seq[k] is the first element for which the predicate function returns False, then the iterator returns seq[0], seq[1],…, seq[k-1].
Consider the following nums list and predicate function is_less_ than_5. We use the takewhile function as shown:
Here, the predicate is_less_than_5 returns False—for the first time—for the number 5:
Output >>> [1, 3]
3. dropwhile
Functionally, the dropwhile function does the opposite of what the takewhile function does.
Here's how you can use the dropwhile function:
from itertools import dropwhile dropwhile(pred,seq)
The dropwhile function gives an iterator that keeps dropping elements—so long as the predicate is True. Meaning the iterator does not return anything until the predicate returns False for the first time. And once the predicate returns False, the iterator returns all the subsequent elements in the sequence.
For an n-length sequence, if seq[k] is the first element for which the predicate function returns False, then the iterator returns seq[k], seq[k+1],…, seq[n-1].
Because the predicate function is_less_than_5 returns False—for the first time—for the element 5, we get all the elements of the sequence starting from 5:
Output >>> [5, 2, 4, 6]
4. islice
You’ll already be familiar with slicing Python iterables like lists, tuples, and strings. Slicing takes the syntax: iterable[start:stop:step].
However, this approach of slicing has the following drawbacks:
When working with large sequences, each slice or subsequence is a copy that takes up memory. This can be inefficient.
Because the step can also take negative values, using the start, stop, and step values affects readability.
The islice function addresses the above limitations:
It returns an iterator.
It doesn’t allow negative values for the step.
You can use the islice function like so:
from itertools import islice islice(seq,start,stop,step)
Here are a few different ways you can use the islice function:
Using islice(seq, stop) returns an iterator over the slice seq[0], seq[1],…, seq[stop - 1].
If you specify the start and the stop values: islice(seq, start, stop) the function returns an iterator over the slice seq[start], seq[start + 1],…, seq[start + stop - 1].
When you specify the start, stop, and step arguments, the function returns an iterator over the slice seq[start], seq[start + step], seq[start + 2*step],…, seq[start + k*step]. Such that start + k*step < stop and start + (k+1)*step >= stop.
Let’s take an example list to understand this better:
Now let's use the islice function with the syntax we have learned.
Using Only the Stop Value
Let’s specify only the stop index:
from itertools import islice # only stop sliced_nums = islice(nums, 5) print(list(sliced_nums))
And here’s the output:
Output >>> [0, 1, 2, 3, 4]
Using the Start and Stop Values
Here, we use both the start and stop values:
# start and stop sliced_nums = islice(nums, 2, 7) print(list(sliced_nums))
The slice starts at index 2 and extends up to but not including index 7:
Output >>> [2, 3, 4, 5, 6]
Using the Start, Stop, and Step Values
When we use the start, stop, and step values:
# using start, stop, and step sliced_nums = islice(nums, 2, 8, 2) print(list(sliced_nums))
We get a slice starting at index 2, extending up to but not including index 8, with a step size of 2 (returning every second element).
Output >>> [2, 4, 6]
Wrapping Up
I hope this tutorial helped you understand the basics of itertools filter functions. You’ve seen some simple examples to understand the working of these functions better. Next, you can learn how generators generator functions and generator expressions work as efficient python iterators. Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more.
More On This Topic
7 Things You Didn't Know You Could do with a Low Code Tool
3 things you didn’t know about the SAS Academy for Data Science
Behind OpenAI Codex: 5 Fascinating Challenges About Building Codex You…
5 Pandas Plotting Functions You Might Not Know
Top Five SQL Window Functions You Should Know For Data Science Interviews
KDnuggets™ News 22:n03, Jan 19: A Deep Look Into 13 Data Scientist…
In this article, we're going to discuss some amazing things you can do with ChatGPT Plus and OpenAI's Code Interpreter add-on. But first, we need to discuss the giant purple elephant that's about to blink into the room.
What is that giant purple elephant, you ask? Data security. Specifically, we need to discuss your (and, in this case, my) proprietary data. Here's the thing. For ChatGPT Plus to be able to mine your data, it has to have access to it.
Also: 7 advanced ChatGPT prompt-writing tips you need to know
See where I'm going here? To do everything I'm about to tell you about, I had to upload a 22,797 record data set exported from my company's servers. What will OpenAI and ChatGPT do with that data? I have no idea. That's a big risk.
In my case, it's more important to share the process of data analysis with you than safeguard my data. But that's my decision to make. It's my data. I know that I won't be violating any disclosure agreements, or putting my company at risk by sharing it with ChatGPT (and, by extension due to this article, with you).
Also: How does ChatGPT actually work?
But if you use these techniques — and make no mistake, they are gobsmackingly powerful — you'll need to decide whether you and your company can comfortably share that data with an AI, and possibly, the rest of the entire internet.
ChatGPT Enterprise
There is a possible way to disinvite the elephant. OpenAI has introduced a new tier of purchasable ChatGPT service: ChatGPT Enterprise. This service tier solves many of the concerns I listed above. Specifically, "Customer prompts and company data are not used for training OpenAI models." It's also providing data encryption for both data in transit and at rest.
Also: OpenAI finally introduces a business version of ChatGPT
This would allow you to more safely upload data like the example I'll be showing, without concern that your proprietary data will get loose in the wild. The catch? Pricing data hasn't been disclosed. OpenAI is using the dreaded "a salesperson will call" as a substitute for a published price. Most likely, any ChatGPT Enterprise service will be priced out of the range of smaller companies. That said, OpenAI has also promised, "Availability for all team sizes: a self-serve ChatGPT Business offering for smaller teams."
So, there's that. No details on when that will happen, or its price, but the company does say, "We'll launch them as soon as they're ready."
And with that, let me show you why this is exciting.
What are we looking at?
The data set I'm using is uninstall data, gathered when users uninstall my WordPress plugins. Here's how that works.
When a user chooses to uninstall either Seamless Donations or My Private Site, they're presented with the above dialog. Data from each of those uninstalls is sent to my server, where it's stored.
Up until now, I've been able to see the data represented in tabular form, like this:
But that's about as good as it got. I never had the time to build any detailed analytics to chart or create pivot tables. So I could thumb back a few pages and get a rough feel for what was happening with recent uninstalls, but I had no thousand-foot view with which to derive overall insights.
Until now.
Preparing ChatGPT for your file upload
You'll need ChatGPT Plus, which is the version of ChatGPT available via a $20/month subscription.
Also: GPT-3.5 vs GPT-4: Is ChatGPT Plus worth its subscription fee?
You'll also need to go to your ChatGPT settings, and switch on Code Interpreter from the Beta Features tab:
And, finally, when you begin a session, you'll need to select GPT-4 and Code Interpreter. If you do all that, you're set.
The next thing you'll need to do is upload your data. By this point, I'm assuming you and your management team have thought through the giant purple elephant implications (okay, now I'm just doing it for the lulz), and you're okay with uploading data to Skynet. If so, here goes.
Click the plus sign at the bottom of your session screen:
Click Upload to upload your file. When you're done, hit return.
Once that was done, ChatGPT showed me how many records were in the file. To be sure it was able to read what I uploaded, I asked it to describe the fields.
Let's make data analytics magic together
When using Code Interpreter, ChatGPT is…chatty. It's like that enthusiastic geek friend who can't get to the point and has to share everything about how they got to the answer, before giving you an answer — or like that article writer who takes a few thousand words to give you essential backstory before finally getting to the few key "how to" instructions.
Also: How to use ChatGPT to write code
Because ChatGPT is so chatty, I'm going to show you screenshots of its answers. I'm going to cut out all the extended information provided before and after the answers. Otherwise, these screenshots would be a mile long.
And with that, I asked a simple question and got a clear answer.
How many records are there for each product?
To be fair, creating that calculation wouldn't be hard to code, but it would be time-consuming. ChatGPT? 15 seconds, on the fly. Boom.
What percentage of records contain comments?
Most users don't leave comments, and those that do are those who chose to select "Other" rather than one of the pre-defined uninstall reasons. Even so, check out what two simple questions were able to extract from all that raw data.
Examine all relevant comments and conduct a thematic analysis to identify common trends and patterns
For each product, describe the prevalent functionality issues described in the comments.
Based on what I know of my users, that analysis is pretty much spot-on. But more to the point, wow! I mean, this thing chugged through 22,797 records and presented overall issues. And it did it in less than a minute. Do you have any idea how long that would have taken to tabulate by hand or to code? Days.
Also: The best AI chatbots to try right now
To be fair, ChatGPT didn't just generate the most helpful answer right away. I had to negotiate with it, trying a bunch of different prompts until I found the ones that worked. But even so, that process took less than an hour vs. days.
Want some pie?
Next, I decided to see if I could get some charts. The uninstall reasons come in a set of pre-defined categories, so I wanted to see how they compared. I also wanted to see if the uninstall reasons changed over the years. I fed the AI this prompt:
For each product and then for each year, draw a pie chart of uninstall reason codes. Do not include other, nan, and temporary-deactivation. At the end, note any trends or insights observed.
I actually got back the eight pie charts I expected, but I'm only showing one here. Of particular note is that my data was recorded in 2020, 2021, 2022, and 2023. So why did ChatGPT talk about 2017 and 2018?
The charts were drawn for the correct years, and the data it showed makes sense. I first started using My Private Site because I wanted to block a test site I created for grad school from everyone but me and my professors. Once I graduated, I no longer needed the plugin for that purpose. A lot of people probably download it, and use it on a project basis.
The AI also generated some conclusions derived from the data.
The product-specific patterns it identified were fascinating. This is a large language model that theoretically knows nothing of my software apps. Yet its analysis was absolutely spot on. Those two patterns are directly reflective of what I've seen in managing those products.
They don't hate it. They really don't hate it.
Back in February, I shipped a major change in how Seamless Donations handles payment gateways. That version, 5.2, has worried me ever since. I haven't had a lot of user feedback, so it's been hard to tell if users liked it, or hated it, or if it caused them to abandon the product. Usually, when users dislike an upgrade, they're very vocal. But this was huge, and you could hear crickets.
Also: 6 helpful ways to use ChatGPT's Custom Instructions
One of the fields in the uninstall data set is for the version number. So I had ChatGPT do some sentiment analysis to see if users who uninstalled from 5.2 onward were doing so because of something new. Let's look at what the AI was able to tell me.
Comparing all data (including whatever comments are available), do users seem more or less satisfied with Seamless Donations from 5.2 onward? Provide details and insights.
Here's what I got back:
Take a moment to appreciate this. I wrote two sentences and the AI looked through 22,797 records and performed a very detailed analysis, all to conclude that users seemed to have a "slight increase in positive sentiment" in the new release.
Also: How this simple ChatGPT prompt tweak can help refine your AI-generated content
If I'd had to write the code to do the amount of work the AI did, to process the amount of data involved, it would have taken forever. The level of effort in terms of programming I would have had to do to get this information would have been off the charts. Instead, all I had to do was write two prompts.
Sure, if I were a product manager for IBM, I might have been able to bring Watson into the picture and use data-crunching teams to create a product analysis. But as one guy, writing two sentences, and getting insights as valuable as this — just wow!
I am blown away.
This is a real tool
There is no doubt room for concern about uploading corporate data to ChatGPT Plus. But for data where such concern doesn't exist (like my data set), this is no longer a novelty. It's not just a fun parlor trick.
Also: How I used ChatGPT to write a custom JavaScript bookmarklet
This is a real productivity tool. This is something we can use to get real work done, that accomplishes something we might not otherwise be able to do, and it does it well. Sure, there's always the concern that the results are wrong, but that's also a fair concern if someone had written a custom program to generate this information.
I paid twenty bucks and did all of this analysis in the space of a few hours (I was kicked off after having asked too many questions and had to come back a few hours later). The amount of work it would have taken and the expense it would have cost to get the insights I got from my sessions with ChatGPT are almost incalculable by comparison.
Also: How I used ChatGPT and AI art tools to launch my Etsy business fast
This is real, folks. Add it to your toolbox alongside your other powerful productivity tools. And try not to think about purple elephants.
Do you have data you feel safe sharing with ChatGPT? Do you have data where you really want it to provide you with some answers? Have you used ChatGPT in this way before? Discuss with us in the comments below.
You can follow my day-to-day project updates on social media. Be sure to subscribe to my weekly update newsletter on Substack, and follow me on Twitter at @DavidGewirtz, on Facebook at Facebook.com/DavidGewirtz, on Instagram at Instagram.com/DavidGewirtz, and on YouTube at YouTube.com/DavidGewirtzTV.










 For every dollar, the TPU v5e is up to two times faster in training and 2.5 times inferencing times. The TPU v5e is priced at $1.2 per chip hour, while the TPU v4 is about $3.2 per hour.
For every dollar, the TPU v5e is up to two times faster in training and 2.5 times inferencing times. The TPU v5e is priced at $1.2 per chip hour, while the TPU v4 is about $3.2 per hour.