The wait is over. Google has finally introduced Gemini.
Gemini is built from the ground up to be multimodal, which means it can generalize and seamlessly understand, operate across and combine different types of information including text, code, audio, image and video.
Introducing Gemini 1.0, our most capable and general AI model yet. Built natively to be multimodal, it’s the first step in our Gemini-era of models. Gemini is optimized in three sizes – Ultra, Pro, and Nano Gemini Ultra’s performance exceeds current state-of-the-art results on… pic.twitter.com/pzIw6iCPPN
— Sundar Pichai (@sundarpichai) December 6, 2023
Gemini is designed for versatility, capable of running efficiently on a wide range of platforms, from data centers to mobile devices.
The model comes in three optimized versions: Gemini Ultra, tailored for highly complex tasks; Gemini Pro, ideal for scaling across various tasks; and Gemini Nano, a highly efficient model for on-device applications.
Commencing today, Gemini 1.0 will be gradually rolling out across Google products, with Gemini Pro being integrated into Google’s Bard for advanced reasoning and planning. Additionally, Gemini Nano powers features in the Pixel 8 Pro smartphone, offering capabilities like Summarize in the Recorder app and Smart Reply in Gboard.
Developers and enterprise customers can access Gemini Pro via the Gemini API in Google AI Studio or Google Cloud Vertex AI starting December 13. Gemini Ultra, currently undergoing extensive trust and safety checks, will be available for early experimentation and feedback before a broader release in early 2024.
Over the next few months, Gemini is set to extend its presence to various Google products and services, including Search, Ads, Chrome, and Duet AI. The experimentation with Gemini has already commenced in the Search domain, resulting in a remarkable 40% reduction in latency for English users in the U.S. within the Search Generative Experience (SGE), coupled with enhanced overall quality.
In extensive testing, Gemini Ultra has exhibited state-of-the-art performance, surpassing human experts on the Massive Multitask Language Understanding (MMLU) benchmark with an impressive score of 90.0%. This benchmark encompasses 57 subjects, spanning math, physics, history, law, medicine, and ethics, showcasing Gemini’s comprehensive understanding and problem-solving capabilities.
Gemini’s multimodal capabilities extend to surpassing state-of-the-art performance on various benchmarks, including text, coding, and multimodal tasks. The model’s native multimodality, a departure from traditional approaches, contributes to its superior performance in conceptual and complex reasoning.
The model’s sophisticated reasoning capabilities enable it to extract insights from vast amounts of written and visual information, facilitating breakthroughs in fields ranging from science to finance.
Gemini’s proficiency in understanding text, images, audio, and more simultaneously positions it as an adept tool for explaining reasoning in complex subjects like mathematics and physics.
Notably, Gemini excels in advanced coding, demonstrating the ability to understand, explain, and generate high-quality code in popular programming languages. Its application extends to serving as the engine for more advanced coding systems, such as AlphaCode 2, which outperforms its predecessor in solving competitive programming problems involving complex mathematics and theoretical computer science.
Gemini 1.0 was trained at scale using Google’s Tensor Processing Units (TPUs) v4 and v5e, resulting in a model that is not only powerful but also efficient and scalable. The announcement of Cloud TPU v5p, the most powerful TPU system to date, further underscores Google’s commitment to accelerating AI model development and deployment.
Emphasizing responsibility and safety, Google has conducted extensive safety evaluations on Gemini, addressing potential risks such as bias and toxicity. The company has collaborated with external experts to stress-test the model across various issues and implemented safety measures, including dedicated classifiers to identify and filter out content involving violence or negative stereotypes.
The post Much-Awaited Google Gemini Finally Arrives appeared first on Analytics India Magazine.
I am sure everyone knows about the algorithms GBM and XGBoost. They are go-to algorithms for many real-world use cases and competition because the metric output is often better than the other models.
For those who don’t know about GBM and XGBoost, GBM (Gradient Boosting Machine) and XGBoost (eXtreme Gradient Boosting) are ensemble learning methods. Ensemble learning is a machine learning technique where multiple “weak” models (often decision trees) are trained and combined for further purposes.
The algorithm was based on the ensemble learning boosting technique shown in their name. Boosting techniques is a method that tries to combine multiple weak learners sequentially, with each one correcting its predecessor. Each learner would learn from their previous mistakes and correct the errors of the previous models.
That’s the fundamental similarity between GBM and XGB, but how about the differences? We will discuss that in this article, so let’s get into it.
GBM (Gradient Boosting Machine)
As mentioned above, GBM is based on boosting, which tries sequentially iterating the weak learner to learn from the error and develop a robust model. GBM developed a better model for each iteration by minimizing the loss function using gradient descent. Gradient descent is a concept to find the minimum function with each iteration, such as the loss function. The iteration would keep going until it achieves the stopping criterion.
For the GBM concepts, you can see it in the image below.
GBM Model Concept (Chhetri et al. (2022))
You can see in the image above that for each iteration, the model tries to minimize the loss function and learn from the previous mistake. The final model would be the whole weak learner that sums up all the predictions from the model.
XGB (eXtreme Gradient Boosting) and How It Is Different From GBM
XGBoost or eXtreme Gradient Boosting is a machine-learning algorithm based on the gradient boosting algorithm developed by Tiangqi Chen and Carlos Guestrin in 2016. At a basic level, the algorithm still follows a sequential strategy to improve the next model based on gradient descent. However, a few differences of XGBoost push this model as one of the best in terms of performance and speed.
1. Regularization
Regularization is a technique in machine learning to avoid overfitting. It’s a collection of methods to constrain the model to become overcomplicated and have bad generalization power. It’s become an important technique as many models fit the training data too well.
GBM doesn’t implement Regularization in their algorithm, which makes the algorithm only focus on achieving minimum loss functions. Compared to the GBM, XGBoost implements the regularization methods to penalize the overfitting model.
There are two kinds of regularization that XGBoost could apply: L1 Regularization (Lasso) and L2 Regularization (Ridge). L1 Regularization tries to minimize the feature weights or coefficients to zero (effectively becoming a feature selection), while L2 Regularization tries to shrink the coefficient evenly (help to deal with multicollinearity). By implementing both regularizations, XGBoost could avoid overfitting better than the GBM.
2. Parallelization
GBM tends to have a slower training time than the XGBoost because the latter algorithm implements parallelization during the training process. The boosting technique might be sequential, but parallelization could still be done within the XGBoost process.
The parallelization aims to speed up the tree-building process, mainly during the splitting event. By utilizing all the available processing cores, the XGBoost training time can be shortened.
Speaking of speeding up the XGBoost process, the developer also preprocessed the data into their developed data format, DMatrix, for memory efficiency and improved training speed.
3. Missing Data Handling
Our training dataset could contain missing data, which we must explicitly handle before passing them into the algorithm. However, XGBoost has its own in-built missing data handler, whereas GBM doesn’t.
XGBoost implemented their technique to handle missing data, called Sparsity-aware Split Finding. For any sparsities data that XGBoost encounters (Missing Data, Dense Zero, OHE), the model would learn from these data and find the most optimum split. The model would assign where the missing data should be placed during splitting and see which direction minimizes the loss.
4. Tree Pruning
The growth strategy for the GBM is to stop splitting after the algorithm arrives at the negative loss in the split. The strategy could lead to suboptimal results because it’s only based on local optimization and might neglect the overall picture.
XGBoost tries to avoid the GBM strategy and grows the tree until the set parameter max depth starts pruning backward. The split with negative loss is pruned, but there is a case when the negative loss split was not removed. When the split arrives at a negative loss, but the further split is positive, it would still be retained if the overall split is positive.
5. In-Built Cross-Validation
Cross-validation is a technique to assess our model generalization and robustness ability by splitting the data systematically during several iterations. Collectively, their result would show if the model is overfitting or not.
Normally, the machine algorithm would require external help to implement the Cross-Validation, but XGBoost has an in-built Cross-Validation that could be used during the training session. The Cross-Validation would be performed at each boosting iteration and ensure the produce tree is robust.
Conclusion
GBM and XGBoost are popular algorithms in many real-world cases and competitions. Conceptually, both a boosting algorithms that use weak learners to achieve better models. However, they contain few differences in their algorithm implementation. XGBoost enhances the algorithm by embedding regularization, performing parallelization, better-missing data handling, different tree pruning strategies, and in-built cross-validation techniques.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.
More On This Topic
XGBoost Explained: DIY XGBoost Library in Less Than 200 Lines of Python
The Difference Between Data Scientists and ML Engineers
What Is The Real Difference Between Data Engineers and Data Scientists?
Efficiency Spells the Difference Between Biological Neurons and…
What’s the difference between a Data Scientist and a Data Analyst?
What’s the Difference Between Data Analysts and Data Scientists?
Headquartered in Mumbai, India, WNS is a prominent global Business Process Management (BPM) and IT consulting company with 67 delivery centers and over 59,000 employees worldwide.
Combining extensive industry knowledge with technology, analytics, and process expertise, the company collaborates with clients across 10 industries to co-create digital-led transformational solutions. WNS is renowned for its strategic partnerships, delivering innovative practices and industry-specific technology and analytics-enabled solutions. The company’s services cover diverse sectors, characterised by a structured yet flexible approach, deep industry expertise, and a client-centric partnership model.
WNS Triange, the AI, analytics, data and research business unit, has successfully harnessed the power of data science to develop robust solutions that effectively address a myriad of business challenges faced by its clients.
Among these solutions are sophisticated applications such as an advanced claims processing system, a finely tuned inventory optimisation mechanism, and the implementation of a retail hyper-personalisation strategy.
Consisting of over 6,500 experts, WNS Triange serves as a partner for 200 global clients in more than 10 industries.
“The team is organised into three pillars: Triange Consult focuses on consulting and co-creating strategies for data, analytics, and AI; Triange NxT adopts an AI-led platform approach for scalable business value; and Triange CoE executes industry-specific analytics programs, transforming the value chain through domain expertise and strategic engagement models,” Akhilesh Ayer, EVP & Global Business Unit Head – WNS Triange, told AIM in an exclusive interaction last week.
WNS’s AI & Analytics Play
The data science workflow at WNS Triange follows a meticulously structured process that guides the team through various stages, including problem outlining, data collection, Exploratory Data Analysis (EDA), cleaning, pre-processing, feature engineering, model selection, training, evaluation, deployment, and continuous improvement. A pivotal element of this methodology is the proprietary AI-led platform, Triange NxT, equipped with Gen AI capabilities. This platform serves as a hub for domain and industry-specific models, expediting the delivery of impactful insights for clients.
“When it comes to claims processing, we deploy predictive analytics to conduct a thorough examination of data sourced from the First Notice of Loss (FNOL) and handler notes,” said Ayer. This approach allows for the evaluation of total loss probability, early settlement possibilities, and subrogation/recovery potential.
Simultaneously, its Marketing Mix Modeling (MMM) is employed to optimise resource allocation by quantifying the impact of marketing efforts on key performance indicators. Furthermore, the application of advanced analytics techniques aids in the detection of suspicious patterns in insurance claims for risk and fraud detection.
Ayer shared that the team also actively leverages generative AI across diverse sectors. In the insurance domain, it is employed to streamline claims subrogation by efficiently processing unstructured data, minimising bias, and expediting insights for recovery.
Similarly, in healthcare, it empowers Medical Science Liaisons (MSLs) by summarising documents and integrating engagement data for more impactful sales pitches. Generative AI’s versatility is further demonstrated in customer service interactions, where it adeptly handles natural language queries, ensuring quicker responses and retrieval efficiency.
The combination of LLM foundation models from hyperscalers like AWS with WNS Triange’s proprietary ML models enables the delivery of tailored solutions that cater to various functional domains and industries. Where necessary, WNS Triange employs its AI, ML and domain capability to fine-tune existing foundation models for specific results, ensuring a nuanced and effective approach to problem-solving.
Tech Stack
In its AI model development, the team utilises vector databases and deep learning libraries such as Keras, PyTorch, and TensorFlow. Knowledge graphs are integrated, and MLOps and XAI frameworks are implemented for enterprise-grade solutions.
“Our tech stack includes Python, R, Spark, Azure, machine learning libraries, AWS, GCP, and GIT, reflecting our commitment to using diverse tools and platforms based on solution requirements and client preferences,” said Ayer.
Even when it comes to using transformer technology, particularly language models like Google’s BERT for tasks such as sentiment analytics and entity extraction, its current approach involves a variety of language models, including GPT variants (davinci-003, davinci-codex, text-embedding-ada-002), T5, BART, LLaMA, and Stable Diffusion.
“We adopt a hybrid model approach, integrating Large Language Models (LLMs) from major hyperscalers like OpenAI, Titan, PaLM2, and LLaMA2, enhancing both operational efficiency and functionality,” he commented.
Hiring Process
WNS Triange recruits data science talent from leading engineering colleges, initiating the process with a written test evaluating applied mathematics, statistics, logical reasoning, and programming skills. Subsequent stages include a coding assessment, a data science case study, and final interviews with key stakeholders.
“Joining our data science team offers candidates a dynamic and challenging environment with ample opportunities for skill development. And while engaging in diverse projects across various industries, individuals can expect exposure to both structured and unstructured data,” said Ayer.
The company fosters a collaborative atmosphere, allowing professionals to work alongside colleagues with diverse backgrounds and expertise. Emphasis is placed on leveraging cutting-edge technologies and providing hands-on experience with state-of-the-art tools and frameworks in data science.
WNS Triange values participation in impactful projects contributing to the company’s success, offering access to mentorship programs and support from experienced team members, ensuring a positive and productive work experience.
Mistakes to Avoid
Candidates are encouraged to not only showcase technical prowess but also articulate the business impact of their work, demonstrating its real-world relevance and contribution to business goals.
Ayer emphasised, “Successful data scientists must not only be technically adept but also skilled storytellers to present their findings in a compelling manner, as overlooking this aspect can lead to less engaging presentations of their work”
He added that candidates sometimes focus solely on technical details without articulating the business impact of their work, missing the opportunity to demonstrate how their analyses and models solve real-world problems and contribute to business goals.
Work Culture
Recognised by TIME MAGAZINE for being one of the best companies to work in, WNS has built a work culture centered on co-creation, innovation, and a people-centric approach, emphasising diversity, equity, and inclusivity, prioritising a respectful workplace culture and extending its commitment to community care through targeted programs by the WNS Cares Foundation.
“Our focus on ethics, integrity, and compliance ensures a safe ecosystem for all stakeholders, delivering value to clients through comprehensive business transformation,” said Ayer.
In terms of employee perks, it offers various services and benefits, including transportation, cafeterias, medical and recreational facilities, flexibility in work hours, health insurance, and parental leave.
“Differentiating ourselves in the data science space, we cultivate a work ecosystem that fosters innovation, continuous learning, and belongingness for the data science team. Our initiatives include engagement tools, industry-specific training programs, customised technology-driven solutions, and a learning experience platform hosting a wealth of content for self-paced learning,” he added.
Why Should You Join WNS?
“At WNS, we believe in the transformative power of data, where individuals play a key role in shaping our organisation by directly influencing business strategy and decision-making. Recognising the significant impact of data science, we invite individuals to join our collaborative and diverse team that encourages creativity and values innovative ideas. In this dynamic environment, we prioritise knowledge sharing, continuous learning, and professional growth,” concluded Ayer.
Find more information about job opportunities at WNS here.
The post Data Science Hiring Process at WNS appeared first on Analytics India Magazine.
In a recent announcement, NVIDIA CEO Jensen Huang said that the California-based tech giant is focusing on crafting a new line of AI chips compliant with U.S. export regulations targeted at China’s market.
This decision comes against Nvidia’s commanding presence, clinching over 90% of China’s $7 billion AI chip market. However, with tightening U.S. curbs on exports of their chips like the A800, analysts predict a potential landscape shift, potentially opening doors for Chinese competitors to make significant headway.
While reports had surfaced indicating Nvidia’s delay in releasing a new AI chip tailored for the Chinese market, now slated for the first quarter of the upcoming year, Huang refrained from confirming these specifics during a press conference in Singapore. Nevertheless, he underscored the company’s concerted efforts to tailor products in accordance with U.S. regulations.
Huang stated, “Nvidia has been working very closely with the US government to create products that comply with its regulations. Our plan now is to continue working with the government to develop a new set of products that comply with the new regulations with certain limits.”
The tech giant anticipates a significant drop in fourth-quarter sales in China due to these new U.S. rules, making it challenging to predict the exact impact on its revenues, which traditionally saw China contributing around 20%.
In a parallel development, Huang unveiled discussions with Singapore for potential substantial investments, signalling Nvidia’s interest in bolstering its regional presence. The talks encompass collaborations in multiple domains, including aiding Singapore’s initiative to develop Southeast Asia’s first large language model, Sealion.
Singapore’s Infocomm Media Development Authority (IMDA) recently announced a S$70 million initiative for this language model, aligning with Nvidia’s interest in Singapore’s vibrant AI ecosystem and key data centre hub for diverse Asian markets. As Nvidia navigates regulatory shifts and global expansion, its strategic moves remain keenly watched in the competitive landscape of AI chip development and global tech influence.
The post NVIDIA Allies With US Government for Low-Grade AI Chips for China appeared first on Analytics India Magazine.
Data visualization isn't just about making graphs. It’s about taking data and making sense of it. And burning other peoples’ retinas with your eclectic color choices, of course.
From tracking global health trends (remember COVID-19?) to tracking your daily runs, the right chart or map can spotlight patterns and answers that raw data hides. However, not all visualization tools are created equal. Some are built for code-savvy, while others are meant for those who think Python is just a hipster name for the game they played on their Nokias. They still call it Snake.
In the following rundown, I’m going to match you with your visualization soulmate. Something like Tinder but for charts. CharTinder? I’m sure there’s a joke in there somewhere. Whether you need a quick pie chart or an interactive map, there’s a tool for that.
What Types of Visualization Frameworks Are There?
There’s a whole spectrum of visualization tool types. I put them into three broad categories comprising the most popular visualization tools.
I’ll give you a short description of each tool. You can find each tool’s features in the overview at the end of each visualization framework type.
To enhance your understanding and provide a more interactive learning experience, here's the video you can watch which mirrors the insights shared in this article:
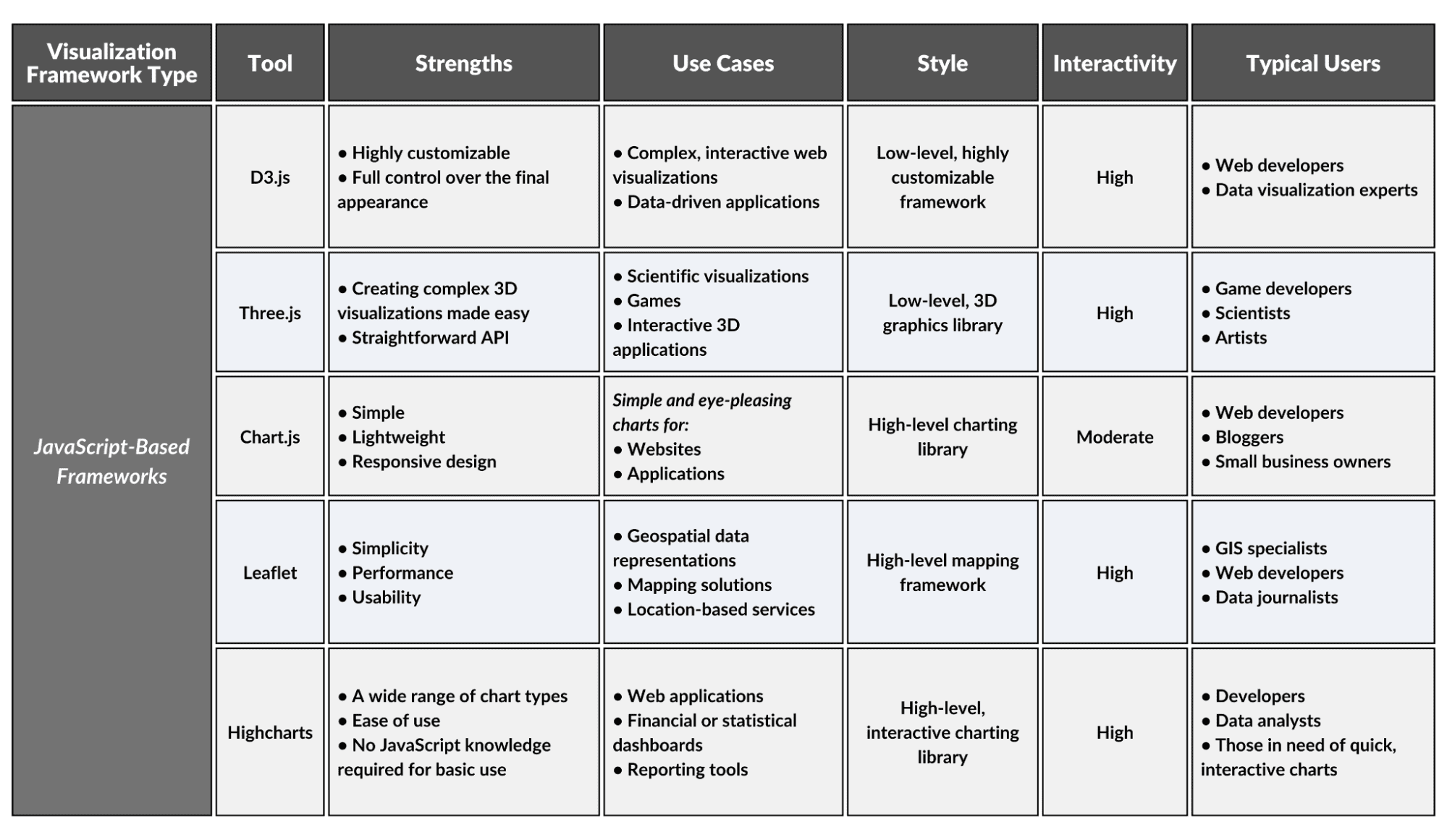
JavaScript-Based Frameworks
These are libraries and frameworks designed to create interactive and dynamic visualizations using JavaScript in web browsers. JavaScript is very flexible, and most developers know it, so these frameworks are widely used.
1. D3.js
D3.js is a powerful JavaScript library for manipulating documents based on data. It enables users to create visualizations using HTML, SVG, and CSS, offering immense control and creative potential for interactive and complex visualizations.
2. Three.js
An open-source JavaScript library and API for creating and displaying animated 3D computer graphics in a web browser. It supports the creation of sophisticated visualizations without the need for specialized 3D graphics software.
3. Chart.js
A JavaScript charting library that provides eight different types of simple charts. It is designed to be both easy to use and highly customizable for web developers looking to add responsive data visualizations.
4. Leaflet
A JavaScript library, Leaflet is great for creating interactive maps that can display extensive geospatial data, making it an invaluable resource for geographers, urban planners, and journalists who require dynamic mapping capabilities.
5. Highcharts
Highcharts is primarily a JavaScript library for creating interactive, web-standard compliant charts. It has extensive charting capabilities, making it ideal for those who require an easy-to-implement solution for complex data visualizations.
JavaScript-Based Frameworks Overview
Python/R/Multi-Language Libraries
This category includes Python data visualization libraries, and those used in R or several other programming languages. These libraries focus on data scientists who create visualizations for their presentations. Most of these libraries have strong support for numerical and scientific computing.
1. Matplotlib
Matplotlib is a comprehensive Python library for creating static, animated, and interactive visualizations. It offers a wide array of tools for making complex plots and provides a solid foundation for constructing detailed graphs suitable for use in scientific publications or presentations.
2. seaborn
seaborn: a Python data visualization library based on Matplotlib. It offers a high-level interface for drawing attractive and statistical graphics. It simplifies creating beautiful visualizations that represent complex data trends and distributions.
3. Plotly
Plotly is a multi-language graphing library that lets developers and analysts create interactive, publication-quality graphs and visualizations directly from their browsers. Its intuitive interface supports a wide array of chart types, fostering a self-service environment for data visualization.
4. bokeh
Bokeh: a Python interactive visualization library for modern web browsers. It provides elegant and versatile graphics with high-performance interactivity over large or streaming datasets, geared towards creating sophisticated visualization applications and dashboards.
5. Pygal
Pygal is a Python library perfect for creating SVG (Scalable Vector Graphics) plots focusing on simplicity and style. You can generate graphs that are both interactive and highly customizable.
6. TensorBoard
A visualization tool within the TensorFlow ecosystem, TensorBoard provides Python users with a clear view of machine learning workflows. It allows developers to easily track metrics and visualize aspects of their models without the need for extensive manual graphing or external tools.
7. ggplot2
An R package that creates data visualizations using a grammar of graphics, allowing users to build complex charts with a coherent structure and design philosophy with minimal coding.
8. lattice
An R visualization tool specializing in the creation of trellis graphs, which are essential for representing multivariate data through conditioning and the use of panels, catering to scientific researchers with needs for detailed comparative visual studies.
9. Shiny
Shiny transforms R statistical code into interactive web applications, providing an accessible framework for analysts and scientists to create user-friendly data-driven interfaces, thus democratizing the accessibility of complex analytical work without web development expertise.
Python/R/Multi-Language Libraries Overview
Enterprise Solutions
These are robust, scalable visualization platforms designed for businesses, which often include integration with data sources and other business intelligence tools. They allow non-technical users to create visualizations and dashboards without coding. They are often plug-and-play, as in “plug it into your database and make visualizations”.
1. Tableau Software
Tableau is an industry-standard analytics platform that delivers intuitive data visualization and business intelligence solutions, enabling users to easily connect, understand, and visualize their data in meaningful ways without requiring extensive technical support.
2. Microsoft Excel
A foundational tool for personal and professional data management, Excel offers a wide range of visualization options, from basic charts to complex graphics, catering to the everyday analytical needs of businesses worldwide.
3. SAS Visual Analytics
An advanced analytics platform that integrates visualization and business intelligence, offering powerful self-service capabilities for data exploration and insight discovery, tailored for organizations with complex data environments.
4. QlikView/Qlik Sense
QlikView and Qlik Sense are interactive business intelligence and visualization tools that leverage self-service analytics to empower users with immediate insights, utilizing associative data modeling for an intuitive and exploratory user experience.
5. IBM Cognos Analytics
A comprehensive business intelligence suite that enables efficient data management and visualization with AI-enhanced analytics and smart storytelling features designed for enterprise-scale data exploration and decision-making.
6. SAP BusinessObjects
This is an extensive enterprise analytics solution from SAP, offering a diverse suite of tools that enable organizations to uncover insights, deliver reports, and optimize business performance through powerful data visualization and dashboarding capabilities.
7. Oracle Business Intelligence
Oracle BI is a comprehensive suite of enterprise BI products with a full range of capabilities, including interactive dashboards, ad hoc analysis, and proactive intelligence. It allows businesses to derive actionable insights from their data with minimal IT intervention.
8. SPSS
SPSS by IBM is a statistical analysis powerhouse renowned for its broad application in social sciences. It simplifies the process of statistical interpretation and produces detailed visual representations, making advanced statistical analysis accessible to users with varying levels of expertise.
9. Stata
Stata is a comprehensive tool for data analysis, data management, and graphics. It's specially designed to facilitate the workflow of researchers, providing them with a robust statistical toolkit paired with high-quality graphing capabilities to streamline their data-driven inquiries.
10. MicroStrategy
MicroStrategy is a robust enterprise analytics platform that stands out for its high scalability and advanced analytics, empowering organizations with interactive dashboards, scorecards, and reports that drive strategic decision-making without extensive IT dependency.
11. Domo
Domo is a modern BI platform that excels in data consolidation, visualization, and collaboration, facilitating the creation of custom dashboards and reports to support real-time decision-making in a user-friendly interface designed for business users.
12. Informatica
Informatica is a tool that offers cloud-native data management and integration services, complemented by visualization tools that enable organizations to maintain data quality, streamline operations, and provide business intelligence insights through a governed self-service model.
13. Apache Superset
Apache Superset is an open-source analytics and business intelligence web application that allows data exploration and visualization. It enables users to create and share interactive dashboards, which are easily composed by drag-and-drop without the need for IT staff.
14. Grafana
A multi-platform open-source analytics and monitoring solution, Grafana offers end users rich, customizable dashboards for data aggregation from multiple sources. Its user-friendly interface simplifies the complex data from metrics, logs, and traces into actionable insights.
15. KNIME
An open-source data analytics platform, KNIME delivers a comprehensive range of data integration, transformation, and analysis tools. It offers an intuitive, no-code graphical user interface, enabling end users to independently build data-driven solutions and workflows.
Enterprise Solutions Overview
Conclusion
Visualization frameworks are vast, and the categories where they fit in are ever-growing. I covered twenty-nine tools here, which should be enough for you to find the one you need.
Note that each tool within a category has distinct capabilities, so familiarize yourself with them before settling on a tool you want to use.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.
More On This Topic
Five types of thinking for a high performing data scientist
Python Basics: Syntax, Data Types, and Control Structures
Optimizing Data Storage: Exploring Data Types and Normalization in SQL
The Best Machine Learning Frameworks & Extensions for Scikit-learn
The Best Machine Learning Frameworks & Extensions for TensorFlow
How to Build Data Frameworks with Open Source Tools to Enhance…
In 1998, when Werner Vogels joined Amazon the company had a single US-based website selling only books. He undertook the responsibility to change that.
“I want you to realize that first and foremost Amazon is a technology company,” the company’s CTO declared during an interview in 2006. The man wasn’t off the mark.
Now, Amazon has covered a journey spanning from a bookstore to the behemoth of cloud infrastructure, boasting a clientele of over 1.45 million businesses today. Vogels has played an important role in steering the platform from a run-of-the-mill online shop to a service-oriented architecture.
As the chief tech of one of biggest tech goliaths in the world, Vogels has had the ringside view of how technology is evolving over the years. As an important part of the industry, every year Vogels makes a set of predictions. At the recent re:Invent we asked Vogels about how the scene is set to culturally change concerning large language models—the latest tech cacophony in Silicon Valley.
While these language models managed to woo the internet, many have questioned their ability to chit chat in local languages. Developing these AI chatterboxes in non-English languages comes at a high cost due to the high count of tokenisation cost. “I am not necessarily convinced that 20 billion tokens are much better than 5 billion,” Vogels opined. Drilling down on the rationale behind the downsizing of language models, he cites recent research, including a nugget from Stanford, suggesting that smaller models might match the prowess of their massive counterparts in text generation.
Translation is Not the Issue
In the generative AI space, there is a cultural shift happening, Vogels rightly believes. Since GPT-4 released earlier this year, a lot of concerns have been raised by researchers about the model’s lack of inclusivity and diversity. Now that we have established an array of models in different parameters and sizes, cultural inclusivity should ideally be the next one to crack on the LLM to-do list.
On a similar line, his first prediction for 2024 he made during the traditional keynote was that generative AI will become culturally aware, meaning that models will gain a better understanding of different cultural traditions. While addressing the audience he also stated that if companies want to deploy these genAI tools across the world, they have to start thinking about how to make their models more culturally aware. “If we don’t solve it, it will be a massive hindrance for deploying this technology worldwide because it’s not just about language, it’s about all the cultural aspects which are meaningful to us as humans,” he said.
Speaking about the problems in developing culturally inclusive models, he explained that, “I can talk in the language of Kerala and someone across the phone can listen to it in any other language. Real time translation is not the issue, it is the additional cultural embedment that sits in that language”.
How To Train Your Model
The seasoned 65-year-old Amazon insider also had some thoughts on streamlining the model-building process. “There’s lots of efficiencies that we can introduce in building models and incrementally improving them,” he shared.
“Even if you have five different language models, from different cultures, the history before 1950 is probably going to remain all the same. You don’t need 150 massive language models with the same historical data,” he tossed in.
Keeping it practical he concluded by suggesting that, ”We can have a few bigger ones which can collaborate as they have the same base. Then one can monitor what’s the best answer to give as per a specific context”.
The post ‘How to Train a Culturally Inclusive LLM,’ Explains Amazon CTO appeared first on Analytics India Magazine.
Deepfake is no longer new, however it continues to be causing havoc with governments and authorities looking to impose strict action against misuse of this AI technology. Though deepfake has found implications in the movie and advertisement industry, it still becomes imperative to push for techniques to help identify them.
To help tackle deepfakes, a number of companies are working on AI algorithms that can detect such deceptive content. Here are a few of them that have been making waves:
DeepMedia AI
Yale graduates Rijul Gupta and Emma Brown co-founded DeepMedia to help unmask deepfake technology. DeepMedia offers two products: DubSync, a service utilising AI for translation and dubbing, and DeepIdentify.AI, a deepfake detection service. The latter serves as their main offering, securing a notable $25 million three-year contract with the U.S. Department of Defense (DoD), along with undisclosed agreements with allied forces.
We're honored to be recognized for our efforts in detecting deepfakes in @vivwalt's latest piece for @FortuneMagazine. Our collaborations with the UN, the DoD, and Big Tech reflect our dedication to tackling digital deception. https://t.co/4XNTCxRHia
— DeepMedia (@DeepMedia_AI) December 5, 2023
Sentinel
An Estonian company, Sentinel, helps companies defend against fake media content. They use a Defence in Depth (DiD) approach to automate the authentication of digital media. The company works with democratic governments, defence agencies, and enterprises in mitigating the threat of deepfakes through a prominent AI-based protection platform.
Kroop AI
Founded by Jyoti Joshi, an AI scientist, along with IIT alumni Milan Chaudhari and Sarthak Gupta, this Gujarat-based startup Kroop AI, offers a deployable AI-enabled platform. It’s designed for both businesses and individuals to identify deepfakes across audio, video, or image data. Kroop AI’s deep learning-based platform can detect and analyse deepfakes in detail across various platforms and mediums. This startup aims to become a global, affordable tool for detecting fake content, with a focus on the banking, finance sector, and cybersecurity.
In an age where reality can be manipulated, stay informed and protect yourself. Recent news of a deepfake video involving actress @iamRashmika highlights the growing concern over the spread of misinformation and the potential harm it can cause. (1/4) pic.twitter.com/G27OGBtsqi
— Kroop AI (@kroop_ai) November 8, 2023
Sensity
Netherlands-based company Sensity, provides a visual threat intelligence platform and API to detect and counter deepfakes. They gather visual threat intelligence and use deep learning algorithms for detection.
Group Cyber ID
India’s first hi-tech cyber detection centre which provides extensive support to a number of organisations including law enforcement. GCID provides a range of services including advanced cyber security, IT audit, digital forensic, and threat intelligence services. They specialise in offering security solutions to government agencies, public sectors, and businesses, encompassing areas such as network security, crime scene investigation, financial fraud detection, and border protection consultations.
Intel FakeCatcher
FakeCatcher, is a real-time deepfake detector developed by Intel in partnership with Umur Ciftci from the State University of New York at Binghamton. It operates on a web-based platform and uses Intel hardware and software to detect deepfakes by looking for subtle “blood flow” changes in video pixels. The technology can detect fake videos with a 96% accuracy and when released last year, it was considered world’s first real-time deepfake detector that returns results in milliseconds.
Q Integrity
Switzerland-based company Quantum Integrity utilises patented deep learning technology for detecting deepfake image and video forgery, customizable for various use cases. Recently, the company moved from Switzerland to the US and branded themselves as Q-Integrity.
Microsoft Video Authenticator
Microsoft’s tool generates a confidence score for images or videos to indicate if the media has been manipulated. It analyses media for indications of manipulation using sophisticated AI algorithms.
The tool was released ahead of 2020 US elections, and Microsoft has partnered with the AI Foundation to provide its Video Authenticator tool to news outlets and political campaigns, as part of the Reality Defender 2020 initiative. They have also collaborated with media giants such as BBC and the New York Times, Microsoft’s Project Origin aims to standardise authenticity technology, with support from the Trusted News Initiative.
#Deepfakes no more. Behold, the Microsoft Video Authenticator, a tool that can analyze a still photo or video and provide a percentage chance that the media is artificially manipulated. (1/2) pic.twitter.com/IINud4lWmE
— Microsoft On the Issues (@MSFTIssues) September 1, 2020
The post 8 Deep Tech Companies to Fight Against Deepfake appeared first on Analytics India Magazine.
After raising the highest seed funding ever for an AI startup, Mistral AI is on the brink of securing approximately another €450 million ($487 million) from a consortium of investors, with notable names such as NVIDIA and Salesforce among them. According to sources familiar with the matter, this funding effort places Mistral’s valuation at around $2 billion.
The financial arrangement comprises over €325 million in equity, spearheaded by investors led by Andreessen Horowitz, currently engaged in discussions to inject an additional €200 million into the funding pool. NVIDIA and Salesforce are set to contribute €120 million in convertible debt, although certain details remain subject to potential adjustments.
Documents reveal that Mistral’s three co-founders are consenting to sell equity, each exceeding €1 million as part of the transaction. Other key insiders, including Cedric O, the former French minister serving as the company’s chief adviser, plan to offload shares, with Cedric O expected to sell nearly €1 million worth.
The substantial $2 billion valuation of Mistral, a company with less than a year of existence, highlights the prevailing optimism in the technology sector regarding the potential and profitability of AI enterprises.
Mistral specialises in open-source software powering chatbots and other generative AI tools, positioning itself as a cost-effective and efficient alternative to its US counterparts. In September, the startups released a 7 billion parameter model that has outperformed Llama 2 13B on all benchmarks and Llama 1 34B on several benchmarks.
Read: Mistral AI is Making Generative AI Fun
Though, Mistral is not just going to go the open source way. The team has announced that it is parallelly developing a commercial product that will be optimised for proprietary data and private cloud deployment. “These models will be distributed as white-box solutions, making both weights and code sources available. We are actively working on hosted solutions and dedicated deployment for enterprises.”
Mistral AI was founded by Arthus Mensch from DeepMind, and Guillaume Lample and Timothée Lacroix from Meta AI. Lample was one of the core members of the team behind Meta AI’s LLaMA model, which has been leading the way in open-source.
The post Mistral AI to Raise $487 Mn, Nearing $2 Bn Valuation appeared first on Analytics India Magazine.
Most recently, Amazon announced that it has procured three Falcon 9 launches from SpaceX to facilitate the deployment of its Project Kuiper mega-constellation, which is a direct competitor to Musk’s Starlink.
This development follows closely on the heels of a lawsuit against Amazon, which surfaced approximately two months ago, by shareholders challenging the company’s decision to exclude SpaceX, renowned as the most dependable rocket company globally, from its initial round of launch contract considerations.
Funnily enough, Elon Musk posted on X that launching competitors satellites is not an issue for him. “Fair and square,” he said. This is after Musk has launched his batch of 23 Starlink satellites on November 27.
SpaceX launches competitor satellite systems without favor to its own satellites. Fair and square.
— Elon Musk (@elonmusk) December 1, 2023
Why Amazon finally chose SpaceX
In 2019, Amazon had ordered for launching 77 Kupier satellites from Blue Origin, United Launch Alliance, Arianespace and ABL. But delays in the development of those rockets to launch satellites have led Amazon to change plans.
The company twice switched the rocket that its first pair of Kuiper prototypes would fly on, in an effort to expedite development, before the mission launched in October, this year. This strategic move has anticipated to cost billions of dollars to Amazon.
Then came a lawsuit against Jeff Bezos and Amazon in 2023, filed by Amazon shareholders Cleveland Bakers and Teamster Pension Fund. They claimed that Bezos did not even spend an hour discussing the possibility of any other space company, and chose Blue Origin, Bezos’s own space company.
According to the legal complaint, Amazon management briefed the audit committee in July 2020 about ongoing discussions with Blue Origin, Arianespace, ULA, and an undisclosed fourth company for Kuiper launch contracts. The lawsuit alleges that, perplexingly, SpaceX, recognised as the world’s most famous, reliable, and obvious launch provider, was not even presented as an option during these discussions.
Meanwhile, scheduled for liftoff from mid-2025 onwards, the three Falcon 9 missions are integral to Amazon’s Kuiper’s ambitious plan of establishing a constellation comprising 3,236 satellites in low Earth orbit. The US Federal Communications Commission mandated that Amazon deploy a minimum of half of this satellite count by 2026.
I knew they would. Surprised it took this long. How ever anyone looks at it (positive or negative), SpaceX is the only launch provider that anyone can rely on at scale and reliability. Amazon shareholders are suing because they originally choose Blue Origin to launch Kuiper.
— S.E. Robinson, Jr. (@SERobinsonJr) December 2, 2023
Amazon is also expecting to invest upwards of $10 billion to build Kuiper. Earlier this year, the company broke ground on a $120 million pre-launch processing facility in Florida.
The SpaceX deal marks the latest shift in Amazon’s strategy, and possibly an acceptance of its fate amidst the timeframe, as the company pushes to get Kuiper to space in time to meet federal regulations.
SpaceX Competition Collaboration
SpaceX has been launching satellites for its customers and competitors all this while. Just recently, it also launched Korea 425 reconnaissance satellite and 24 other rideshare payloads.
Moreover, Capella Space, an American space technology company is also launching its satellites called Acadia-4 and Acadia-5, with SpaceX after continuously working with Rocket Lab for earlier satellite launches.
In June, SpaceX also launched Indian startup Azista BST Aerospace’s satellites for remote-sensing capabilities. The founder, Sunil Indruti, said that he chose SpaceX Falcon 9 instead of ISRO’s PSLV because the former had a slot for the satellite in the rocket.
On the other hand, in July, L&T, ISRO, and IN-SPACe, had together decided to compete with SpaceX and decided to focus on SSLV for on demand launch. This is exactly what SpaceX has been doing by launching satellites for other companies.
Musk has been constantly appreciating ISRO’s efforts, which has been launching several other companies’ satellites in space. He has also been collaborating with Indian space companies for a very long time. In 2021, Musk announced that he would partner with Indian firms for building satellite communications equipment.
This is not the first time that Musk is working with a competitor. Starting in January this year, SpaceX had deployed more than 40 satellites for OneWeb by March end. OneWeb is a British broadband operator, with a majority stake by Bharti Enterprises. OneWeb might be considered as a rival to Musk’s Starlink. But Musk doesn’t care.
SpaceX and OneWeb were not happy with working together earlier and had filed negative comments against the Federal Communications Commision (FCC) for sharing radio frequencies in space. But later in June 2022, the conflict between SpaceX and OneWeb was surprisingly resolved after both the companies decided to work together, without any discussions.
Reliance recently announced that it is working on its own satellite services called JioSpaceFiber to compete with Musk’s Starlink. It would be ideal for them to either launch them through ISRO, or maybe get SpaceX to launch the satellites. It is clear that Musk knows space is about collaboration, and not competition.
The post SpaceX is All About Collaboration appeared first on Analytics India Magazine.
The global Data Centre market is projected to reach $325.90 billion in 2023, with an annual growth rate of 6.12%, pushing the market volume to $438.70 billion by 2028. The United States is expected to lead with 5,375 data centres, clocking a revenue of $95.58 billion in 2023. Meanwhile, the Indian Data Centre Market, with 151 data centres currently, is forecasted to experience a surge in business from $6.12 billion in 2023 to $10.89 billion by 2028, showing an impressive 12.22% CAGR.
Generative AI is poised to revolutionise the data centre sector and is projected to create a demand wave comparable to the cloud. India aims to capitalise on this opportunity and strengthen its data centre capacity.
As part of this initiative, several leading data centres, including Yotta, a Mumbai-based data centre giant, anticipate acquiring NVIDIA GPUs and expanding their infrastructure accordingly.
While Yotta currently has about 700 GPUs, in an exclusive interview with AIM, Managing Director Sunil Gupta revealed they are slated to launch their Yantra and Shakti Clouds in early 2024. Yantra will be a hyper-scale cloud targeting government, enterprise, and startup sectors. Shakti Clouds is slated to be India’s first AI-centric GPU-based cloud, consisting of 16,384 NVIDIA GPUs.
“It will be a mixed bag of H100s and the recently launched L40S. I would say that about 1000 of the 1600 ordered are L40S; however, the majority are H100s.” Gupta detailed the GPU specifications.
The roadmap includes an ambitious plan to operationalise 4096 GPUs by January 2024, expanding to a staggering 16,384 GPUs by June 2024. Furthermore, Gupta explained that Yotta is poised to elevate its GPU infrastructure to an unprecedented scale of 32,768 by the end of 2025.
“What I’ve been told by NVIDIA themselves is that for the capacity I’m building, it might become one of the ten largest supercomputers in the world,” Gupta remarked.
As India looks to bolster its capacity from 800 megawatts to a staggering 3000 megawatts by 2030, Gupta’s vision encapsulates building raw data centres and establishing India’s sovereign AI and cloud infrastructure. He articulated, “Capacity building is crucial, but equally important is constructing our own AI and cloud ecosystem for the country’s benefit.”
“There’s a lot of support and push and encouragement from the government side—because this is something which we feel India needs—because India will need its own LLM and a model on Indian data.”
Infrastructure Overhaul
The surge in Generative AI presents significant challenges in adapting data centres for AI applications, not just from the infrastructural aspect but also from the software end.
Gupta highlighted the challenges, noting the estimated seven to eight times increase in power and cooling density required for GPU integration: “The underlying infrastructure required to support these GPUs is just crazy… instead of some 678 kilowatts per array, you’re talking about 40 to 60 kilowatts per rack.”
He outlined plans for improvements in cooling infrastructure, aiming to reduce PUE(Power usage effectiveness) with technologies like immersion cooling and direct liquid cooling to reduce PUE further to sub 1.1.”
A comprehensive software layer is also being developed to streamline GPU access for startups, providing an orchestration layer akin to regular cloud services. This involves a user-friendly interface for startups to subscribe to plans, access pre-trained models, integrate their data, and create them seamlessly.
“So, the startups come, create the accounts, subscribe to some plans, subscribe to some capacity, get the capacity, I give them the tools, you know, the pre-trained models, they can take those trained models, put their data, and then make their model,” said Gupta.
Distinctiveness From Hyperscalers
Gupta discussed the unique aspects of Shakti Cloud compared to providers like AWS, Google Cloud, and Azure, noting the scarcity of GPUs and how hyperscalers are turning to companies like theirs due to allocation trends. He expressed ambitions to rival top cloud operators, promising to provide services others might not attempt, starting with the latest H100 Tensor Core GPUs for their AI cloud.
“I will be as good as Amazon, Azure, Google… while being a sovereign cloud operator,” Gupta said, outlining his ambition regionally, including other unexplored markets.
Additionally, he highlighted a unique marketplace with foundational models for startups to leverage: “I’m building my AI cloud, beginning directly with H100 GPUs… including all those foundational models.”
Furthermore, Gupta emphasised Shakti Cloud’s distinctive multi-cloud architecture, enabling seamless management of various cloud resources. “By default, we are doing something that you come to my orchestration layer to register, you not only can see the catalogue of and consume my cloud services, but you can also see the catalogue of and consume AWS or Azure services as well right from my orchestration.”
Demand and Expansion Plans
When it comes to hyperscalers’ interest in India, Gupta highlighted their move into emerging markets not just for cost-effectiveness but to serve India’s growing economy better. He explained that these companies initially prefer partnering with providers like Yotta to navigate regulations and construction challenges but hinted at future infrastructure plans as they mature in the market.
While the primary usage of Yotta’s GPUs previously was for graphics workstations by studios, mainly for tools like Maya, VFX effects, and online game creation—Gupta pointed out the diverse stakeholders in need of GPU capacities now include entities like ONGC and FTS, amongst other startups, enterprises etc.
However, this infrastructure is not solely for India; Gupta’s expansive vision encompasses serving underserved markets in Southeast Asia, the Middle East, Africa, and beyond, leveraging the potential demand for GPU cloud services globally.
“My fundamental thought was to go to underserved markets, where demand exceeds the local supply in the local market,” Gupta said, highlighting specific regions targeted for expansion, including Southeast Asian countries like Thailand, Philippines, Vietnam, Indonesia, and Malaysia. Moreover, their GPU cloud services attract global interest, indicating potential demand from unexpected markets like the UK.
The post Yotta Challenges Hyperscalers with India’s First AI-Centric GPU Cloud appeared first on Analytics India Magazine.









 Python/R/Multi-Language Libraries
Python/R/Multi-Language Libraries 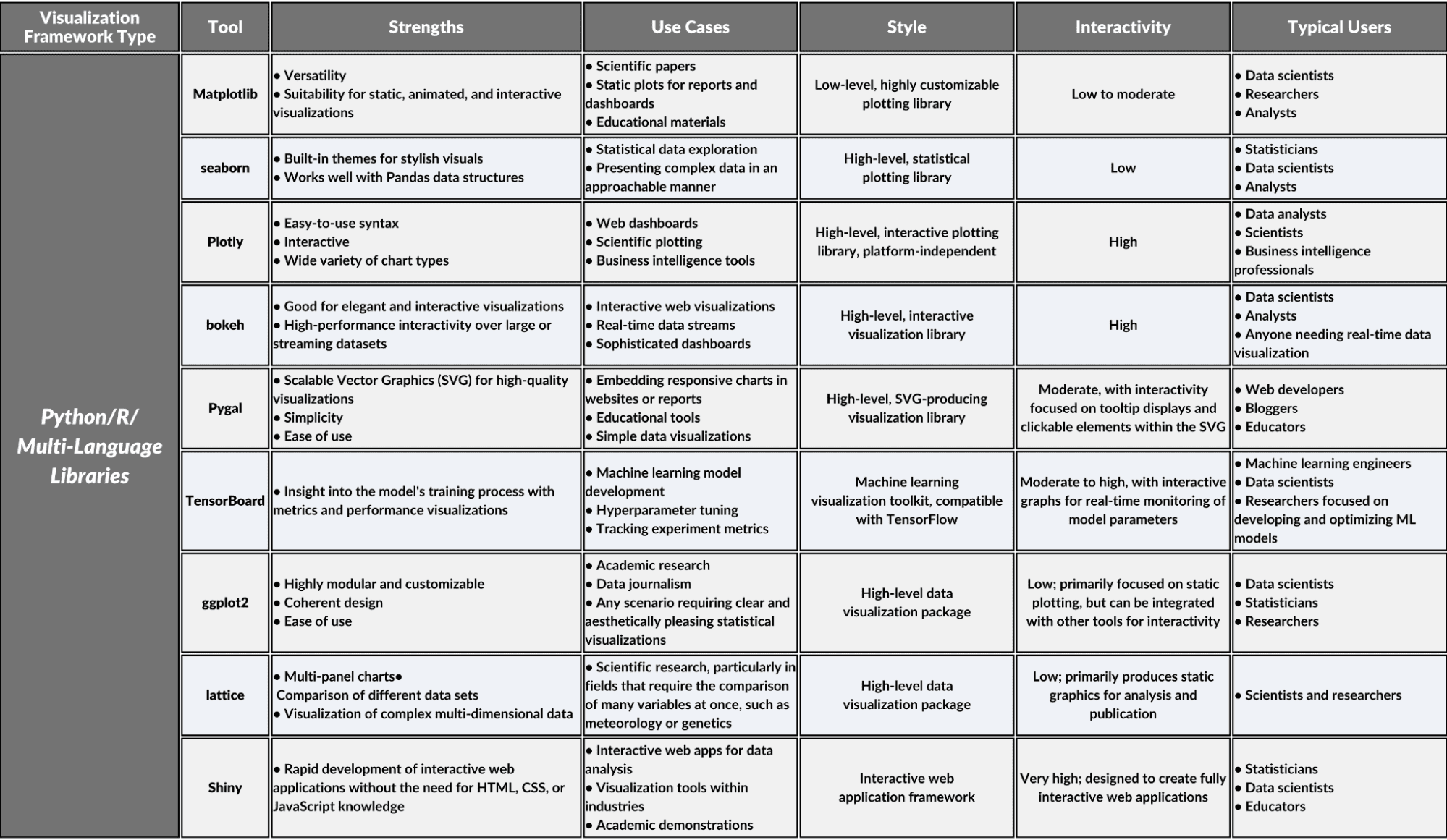 Enterprise Solutions
Enterprise Solutions 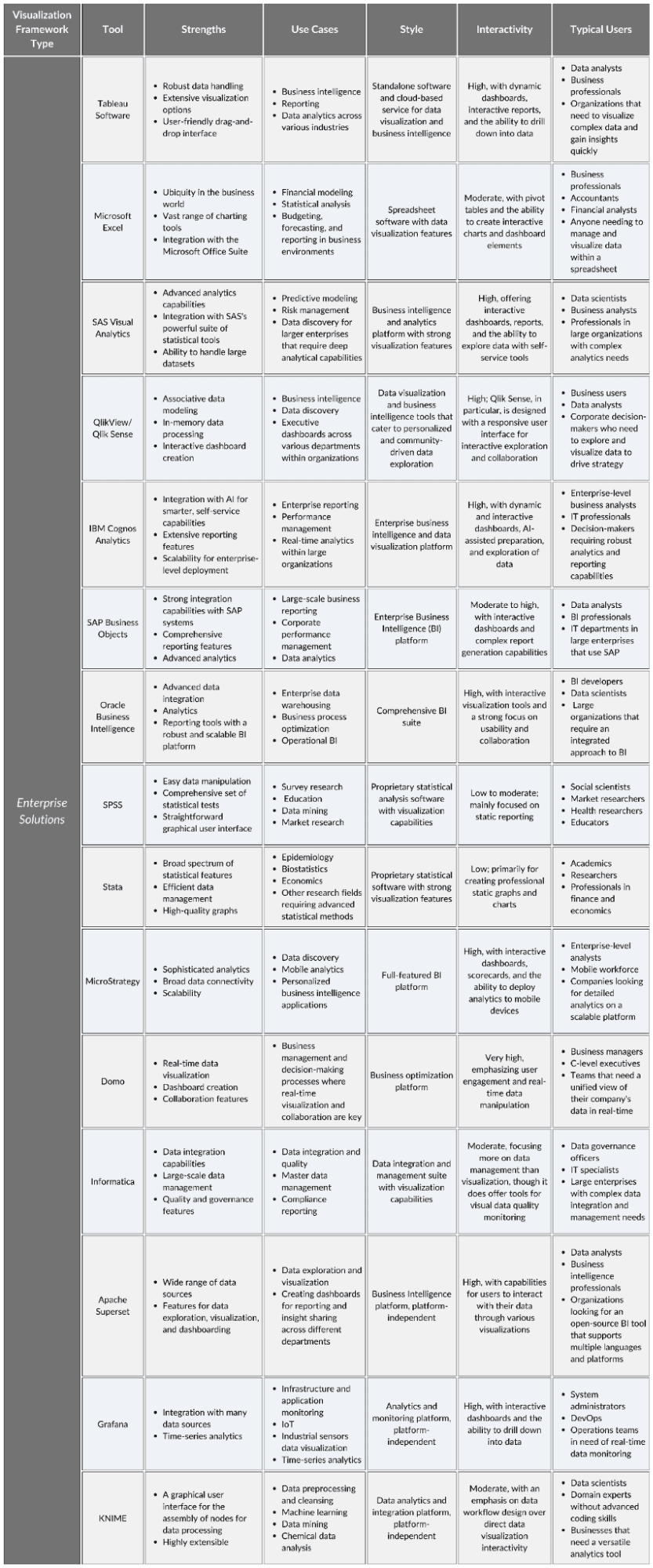 Conclusion
Conclusion 




 Competition
Competition 
