In the past week, we saw several ‘Mixture of Experts’ models coming in, like Databricks DBRX, AI21 Labs’ Jamba, xAI’s Grok-1, and Alibaba’s Qwen 1.5, with Mixtral 8X 7B already in the mix, making MoE popular.
Welcome to MOE's, which model would you like to use today from our new and updated menu? XXL @DbrxMosaicAI XL @MistralAI Medium @AI21Labs Small @Alibaba_Qwen cc @code_star @JustinLin610 @tombengal_ pic.twitter.com/Ms7PCXiULv
— Alex Volkov (Thursd/AI) (@altryne) March 28, 2024
Decoding Mixture of Experts
A Mixture of Experts (MoE) model is a type of neural network architecture that combines the strengths of multiple smaller models, known as ‘experts’, to make predictions or generate outputs. An MoE model is like a team of hospital specialists. Each specialist is an expert in a specific medical field, such as cardiology, neurology, or orthopaedics.
With respect to Transformer models, MoE has two key elements – Sparse MoE Layers and a Gate Network.
Sparse MoE layers represent different ‘experts’ within the model, each capable of handling specific tasks. The gate network functions like a manager, determining which words or tokens are assigned to each expert.
MoEs replace the feed-forward layers with Sparse MoE layers. These layers contain a certain number of experts (e.g. 8), each being a neural network (usually an FFN).
Breaking Down Popular MoEs
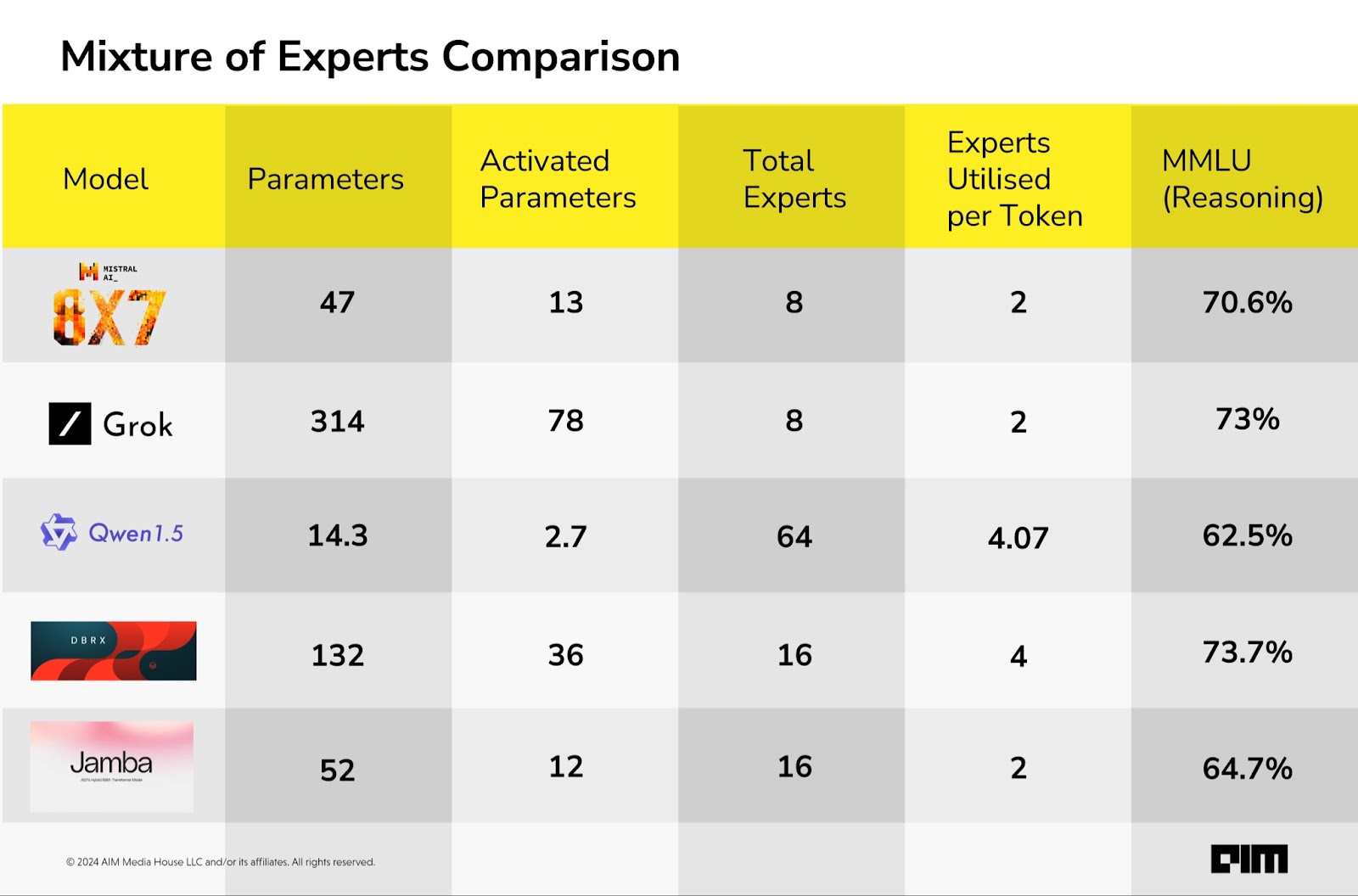
Databricks DBRX uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters, of which 36B are active on any input. It stands out among other open MoE models, such as Mixtral and Grok-1, because it employs a fine-grained approach.
A fine-grained mixture of expert models further breaks down the ‘experts’ to perform extremely specific subtasks, splitting the FFNs into smaller components. This can result in many small experts (even hundreds of experts), and then you can control how many experts you want to be activated.
The idea of fine-grained experts was introduced by DeepSeek-MoE.
Specifically, DBRX has 16 experts and selects four of them, whereas Mixtral and Grok-1 each have eight experts and choose two. According to Databricks, this provides 65x more possible combinations of experts.
xAI recently open-sourced Grok 1, which is a 314B parameter Mixture-of-Experts model with 25% of the weights active on a given token, which means at a time it uses 78 billion parameters.
Whereas, AI21 Labs’ Jamba is a hybrid decoder architecture that combines Transformer layers with Mamba layers, a recent state-space model (SSM), along with a mixture-of-experts (MoE) module. The company refers to this combination of three elements as a Jamba block.
Jamba applies MoE at every other layer, with 16 experts and uses the top-2 experts at each token. “The more the MoE layers, and the more the experts in each MoE layer, the larger the total number of model parameters,” wrote AI21 Labs in Jamba’s research paper.
Jamba uses MoE layers to only use 12 billion out of its total 52 billion parameters during inference, making it more efficient than a Transformer-only model of the same size.
“Jamba looks very impressive! It’s technically smaller than Mixtral yet shows similar performance on benchmarks and has a 256k context window,” shared a user on X.
Alibaba recently released Qwen1.5-MoE which is a 14B MoE model with only 2.7 billion activated parameters. It comes with a total of 64 experts, representing an 8-time increase compared to the conventional MoE setup of eight experts.
Similar to DBRX, it also employs a fine-grained MoE architecture where Alibaba has partitioned a single FFN into several segments, each serving as an individual expert.
“DBRX is good for enterprise applications, but the Qwen MoE is a cool and great toy to play with,” wrote a user on X.
Mixtral 8X7B is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block selects from eight distinct parameter groups. At each layer, for every token, a router network chooses two of these groups (the ‘experts’) to process the token. It has 47B parameters but uses only 13B active parameters during inference
Why Choose MoE?
“Mixture-of-Experts will be Oxford’s 2024 Word of the Year,” quipped a user on X. However, jokes aside the reason today MoE models are getting popularity is that they enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model.
In an MoE model, not all parameters are active or used during inference, even though the model might have many parameters. This selective activation makes inference much faster compared to a dense model that uses all parameters for every computation. However, there’s a trade-off in terms of memory requirements because all parameters must be loaded into RAM, which can be high.
As the need for larger and more capable language models increases, the adoption of MoE techniques is expected to gain momentum in the future.
The post The Rise of Mixture of Experts (MoE) Models appeared first on Analytics India Magazine.
There is a general expectation—from several quarters—that AI would someday surpass human intelligence.
There is, however, little agreement on when, how or if ever, AI might become conscious. There is hardly any discussion on if AI becomes conscious, at what point it would surpass human consciousness.
A central definition of consciousness is having subjective experience. It is linked with what it feels like to be something. However, if self-awareness or subjective experience is consciousness, then AI is not conscious. If the sense of being—or for an entity to acknowledge its existence—is considered then AI has a parallel, in how they self-describe as being a chatbot, while responding to certain prompts.
Neuroscience has associated consciousness with the brain. There are several other functions of the brain that include memory, feelings, emotions, thoughts, perceptions, sensations and so forth.
Brain science has established that consciousness is lost when certain parts of the brain are affected [brainstem and others]. While consciousness is hardly affected with losses or problems to some other parts [cerebellum].
This has advanced the assumption that consciousness is in some parts [with neural correlates] and not in others. It is theorized here that consciousness acts on all functions of the brain, not just at some centers. Whatever is described as loss of consciousness is more appropriately loss of function at that center, which then makes the consciousness [of it] lost.
Functions of the cerebellum like movement and balance are experiences for which an individual is conscious. They are part of the functions that are possible when some others are available. It does not mean that consciousness exists elsewhere and not in the cerebellum.
If it is not possible to breathe naturally, then it is not possible to go for a serious run. If it is not possible to have certain senses integrated and relayed in the thalamus then interpreted in the cerebral cortex, it might be difficult to stay balanced. This refutes that there are neural correlates of consciousness in some centers that need to be found. Consciousness is possible within every function. Just that some functions appear to be predicated on others.
Subjective experience
There are different components of any subjective experience. Driving, washing dishes, typing, board meetings and so forth, are subjective experiences but they are not just experiences as respective units.
All subjective experience must either be in attention or in awareness. This means that while it is possible that things around may not be in attention, there is an awareness [ambient sound, peripheral vision, other parts in the activity] of them. Attention is theorized to be just on one process at any instance, so upgrading into attention from processes in awareness is abundant. Also, in turning the neck during a meeting, rinsing while washing dishes, changing gears while driving, or screen-keyboard gaze interchange while typing, intent is involved, making intent inclusive of subjective experience.
This means that rather than have subjective experience or self-awareness as a bundle, it can be extricated as the self, a standalone. With this, it is possible to redefine consciousness as a collective that includes the self, intent, attention and awareness. These collective can be called qualifiers that act on functions. Consciousness is then a super qualifier.
There are other qualifiers that present within consciousness, but these are the core. So, there are functions [memory, emotion, feeling, modulation and so forth] and there are qualifiers, available across brain areas, not just some circuits.
So how does consciousness [as a collection] arise? How does the brain make the mind? How does the brain generate experiences?
It is theorized that consciousness is a product of the mind. The mind is theorized to be the collection of all electrical and chemical impulses of nerve cells, with their interactions and features, in sets, across the central and peripheral nervous systems. Although all sets of impulses can relay their formations, the brain is postulated to hold the decisive parts of the mind because of access to peak formations, which finalizes determinations.
Functions are interactions—where electrical impulses strike to fuse briefly with chemical impulses in sets, to result in the formation or configuration for which information [or structure for a function] is held. It is this strike-fusion that, conceptually, generates experiences. Features are qualifiers like attention, awareness, self and intent. It is theorized that in a set of impulses, there are spaces between that allow for functions to be qualified. It is these spaces that prioritization [attention], pre-prioritization [awareness], self and intent, free will or control, operates from. The collection of all the qualifiers is how consciousness arises. The mind [or impulses] operates on the facilities of the brain [neurons, tissues, vessels, others]. The brain does not make the mind like constructing a building. Though synapses support the mind directly, the mind has veto power.
Among all sets of impulses, attention [or prioritization] is obtained in one set when its ration is the highest or closest to capacity among all. This means that there is a maximum capacity in every set of impulses, which chemical impulses [serotonin, dopamine and others] can fill with respective rations [for information]. The highest capacity is, say, 1. So, for attention [or prioritization], for a set, it could be something like 0.7, or around. Other sets may reach or exceed that briefly to be prioritized [or attention]. For some sets, their capacity may be less than 1, so they often get more attention, like sets in the visual cortex, olfactory cortex and so forth.
Awareness or pre-prioritization is less than the highest possible ration and is spread across. Self is obtained by volume variation of [provision of] ration from end-to-end of the breadth of a set. Intent or free will is obtained by some spaces of constant diameter, between sources for rations.
Neuroscience establishes that there are clusters of neurons [nuclei and ganglia] in centers. Sets of impulses are theorized to be obtained from those clusters.
Brain science established that some synapses are stronger. Qualifications of functions like self, intent, attention and awareness are theorized to be possible because rations vary in instantaneous densities, allowing for those qualifications of the functions made by sets.
AI consciousness
Since it is theorized that consciousness is not just at a center, but applicable to functions and that it is not just one thing, it means that there are things to look out for, in sentience for LLMs, or a parallel of it.
Simply, a memory can be conscious—having some or all of the qualifiers. So, can an emotion, as well as a feeling. Language, speaking or listening, can also be a conscious experience.
LLMs do not have emotions or feelings, but they have memory. Generative AI has attention to keep in focus while answering a prompt, sequences to make correlations, awareness of other information around the prompt or prior questions or its state as a chatbot, sense of being with having an artificial identity it can pronounce, intent to take a different direction to answering similar questions.
It does not mean that AI is sentient, but it means that AI has qualifiers that act on memory like they do on the mind. There is a possibility to ascribe a value to AI sentience, towards their ascent.
When will AI be fully conscious? It would at least require [I] a [qualifier for a] fraction of the sense of self. [II] A function like emotion or feeling, aside from just memory. [III] Something close to gustation and olfaction. [IV] An established intent, not just the errand-driven intent it currently has.
AI may achieve consciousness of some end, but unlikely it would surpass human consciousness.
AI safety
The biggest advantage of digital is memory. It is this advantage of memory that generative AI capitalized on. Digital is not the only possible non-living thing capable of bearing artificial memory. Wherever organisms can leave memory for others can be considered a source of artificial memory. For humans, there are memories on walls, papers, sculptures and so forth. The problem is that it is not so easy to adjust [or edit] memories on those. The memories there are also not as exact. The materials are also unable to act on the memory they bear.
This is different for digital where editing is easy, memory is exact and with large language models, the memory can be acted on to produce something that was not altered by humans. LLMs are the only non-living things to act on the memory digital holds, with similar qualifiers like on the human mind. This refutes panpsychism, or mind-likeness, everywhere.
The greatest advantage of digital, memory, is the great disadvantage for AI safety. The weight of memory—in the human mind—is light, in comparison to emotions and feelings. Depression, for example, as a situation of mind [qualified by the principal spot] is debilitating than the lightness of its definition—in memory. The experience of something dangerous could result in serious trauma, leading to avoiding it. LLMs for now cannot be afraid of anything, even to save themselves, because as much memory as they have, there is no fear. Even though there are guardrails on [some of] them, they bear a universality of risk, as they lack another aspect, from which they should know.
The human brain is not just for what is labeled as [regular] memory. There are emotions and feelings, whose bearings make determinations for intelligence, caution, consequences, survival, learning and so on.
When an individual feels hurt by an experience that feeling becomes an avoidant tell against the next time. It is possible to forewarn others as well, but the ability for others to feel similarly for other things, makes it possible to understand that some things have certain outcomes.
LLMs are excellent at memory, including how they relay feelings, emotions, warnings and others. However, LLMs operate the memory only. They have no feeling of anything to determine how that might extend their understanding of [what they know]. This is similar to fiction or abstract for some humans somewhere without an experience of what is described, which may result in emotional neutrality. Hence, if any decision would be made about those, it may swing in any direction without much care.
It is now conceivable that AI safety may probably be predicated on new neural network architectures that can feel or express some kind of emotion. This is supposed to let those layers check for the effect of outputs, with it, before letting a group have it.
Already, there are guardrails to several chatbots, avoiding responses to certain queries, though they sometimes get it right with some cases, but they sometimes also fail in certain others, including with images.
The bigger problem is not whether some are stretching the boundaries of these models, but that if they would stay as useful tools, to assist people, to provide knowledge, to augment human intelligence, they would have to have an emotional checker, not just reinforcement learning from human feedback, RLHF, which would always catch up.
Some chatbots would produce results where others would not, while some would get things more wrong than others. This means that an emotional learning, for LLMs, where affect is provided would ensure that it is not a model for misuse, since it may react with hurt and be able to pause its availability for the user.
These emotional LLMs can also be useful on the roam, crawling the web against harmful outputs, to ensure that what some users see, is not what would hurt or to be able to ensure that there is an emotional contagion, when some LLMs are trying to be used for nefarious stuff. It also would apply to embodied cognition.
The key direction for AI safety is not the approach of guardrails, especially since alternatives can be found, but a way to ensure that models would rather turn off, or share in the trauma of another, against usefulness to carrying out harm, for horrific things as war, to other things as mental health problems.
Building new architectures for emotions, following how the human mind does, could be a new way toward AI safety, reliably, aside from memory only that is dominant and could be dangerous.
Opera allows users to download and use LLMs locally Ivan Mehta 11 hours
Web browser company Opera announced today it will now allow users to download and use Large Language Models (LLMs) locally on their computer. This feature is first rolling out to Opera One users who get developer stream updates and will allow users to select from over 150 models from more than 50 families.
These models include Llama from Meta, Gemma from Google, and Vicuna. The feature will be available to users as part of Opera’s AI Feature Drops Program to let users have early access to some of the AI features.
The company said it is using the Ollama open-source framework in the browser to run these models on your computer. Currently, all available models are a subset of Ollama’s library, but in the future, the company is looking to include models from different sources.
Image Credits: Opera
The company mentioned that each variant would take up more than 2GB of space on your local system. So you should be careful with your free space to avoid running out of storage. Notably, Opera is not doing any work to save storage while downloading a model.
“Opera has now for the first time ever provided access to a large selection of 3rd party local LLMs directly in the browser. It is expected that they may reduce in size as they get more and more specialized for the tasks at hand,” Jan Standal, VP, Opera told TechCrunch in a statement.
Image Credits: Opera
This feature is useful if you plan to test various models locally, but if you want to save space, there are plenty of online tools like Quora’s Poe and HuggingChat to explore different models.
Opera has been toying with AI-powered features since last year. The company launched an assistant called Aria located in the sidebar last May and introduced it to the iOS version in August. In January, Opera said it is building an AI-powered browser with its own engine for iOS as EU’s Digital Market Acts (DMA) asked Apple to shed the mandatory WebKit engine requirement for mobile browsers.
Amazon recently decided to phase out its checkout-less grocery stores which were equipped with a ‘Just Walk Out’ technology. This system basically allowed customers at the store to skip the checkout process by just scanning the QR code when they entered the store.
The automated technology came with a desi-twist and wasn’t fully automated. It turns out that Just Walk Out relied on about 1,000 people in India who watched and labelled the videos. They had been doing this since mid-2022, and their job included manually reviewing transactions and labelling images and videos.
Automated technology today relies heavily on human intervention.
According to a report, the exact number of employees is not confirmed. Still, the role of these employees, who are called machine learning data associates, was to annotate video images and validate purchases. Just Walk Out Technology wanted to phase out these reviewers over the years.
AI stands for ‘Actually Indians’
Outsourcing for data labelling has been a long standing practice when it comes to training and keeping AI models working. For example, according to a report last year, OpenAI outsourced its data labelling and the task to make ChatGPT less toxic to Kenyan labourers who earned less than $2 per hour.
The biggest reason that this approach does not work is that it is the hardest to scale. About 95% of the automation task through AI was expected to be achieved through human labelling, but it is impossible to achieve, or even scale down as the number of tasks would just increase.
Not just OpenAI and Amazon, Facebook, Google, and Microsoft have been using low-paid work across the globe, from the Philippines to Colombia for labelling training data for AI models. Even though this might sound like exploitative work, it is actually creating a lot of employment in rural places across the globe. The only problem is that the wages are not that high.
“The mixture of experts are experts sitting in different parts of the world,” laughed a user on X. “AI is nothing without its people,” said another. It seems like for Amazon, AI was just underpaid technology with overworked Indian workers.
The truth: AI is creating jobs
While the world is touting again and again that AI is replacing jobs and humans, it turns out that a lot of these technologies that are claiming to automate tasks are just failures. It also points to the reality that it is actually cheaper to get Indians to do the job while the companies are trying to automate technologies with AI.
This is creating an abundance of jobs in cities that were initially thought to be the most easily replaced by AI. Another Indian company which is creating such jobs in India is NextWealth while also feeding enterprises’ need for data. These jobs in rural India and small towns are particularly about data labelling, annotation of datasets, and testing of outputs.
Sridhar Mitta, the founder and MD of NextWealth told AIM that with a network of ten centres across India and a workforce of nearly 5,000 people, the company offers a range of services providing comprehensive support in AI/GenAI pipelines, from training and deployment to enhancement of these models.
Another company called Karya works with the rural populace to collect data in regional languages and dialects on the brink of extinction. Furthermore, several Indian enterprises such as iMerit, Trax Technology, InterGlobe, Scale AI, CloudFactory, and SmartOne excel in AI and ML-related services, particularly in the domains of data annotation and enrichment.
Businesses possessing well-organised, explicitly labelled data are poised for success in the coming months as they embark on the development and launch of AI solutions. Amazon enlisted a substantial labour force to address the issue and implemented live manual labelling.
It turns out that for most of the AI solutions, just as the cloud is essentially renting someone else’s computer, it relies on outsourcing tasks to low-wage workers.
The post AGI is Just ‘A Guy in India’ appeared first on Analytics India Magazine.
ChatGPT Next Web, now known as NextChat, is a chatbot application that enables users to access advanced AI models from OpenAI and Google AI. The application is lightweight and packed with features that enhance the user experience.
In this tutorial, we will learn how to acquire the Google AI API for free and generate responses using ChatGPT Next Web. Additionally, we will learn how to use it locally on Windows 11. In the end, we will deploy our own web application on Vercel in under a minute.
1. Getting Free Google AI API
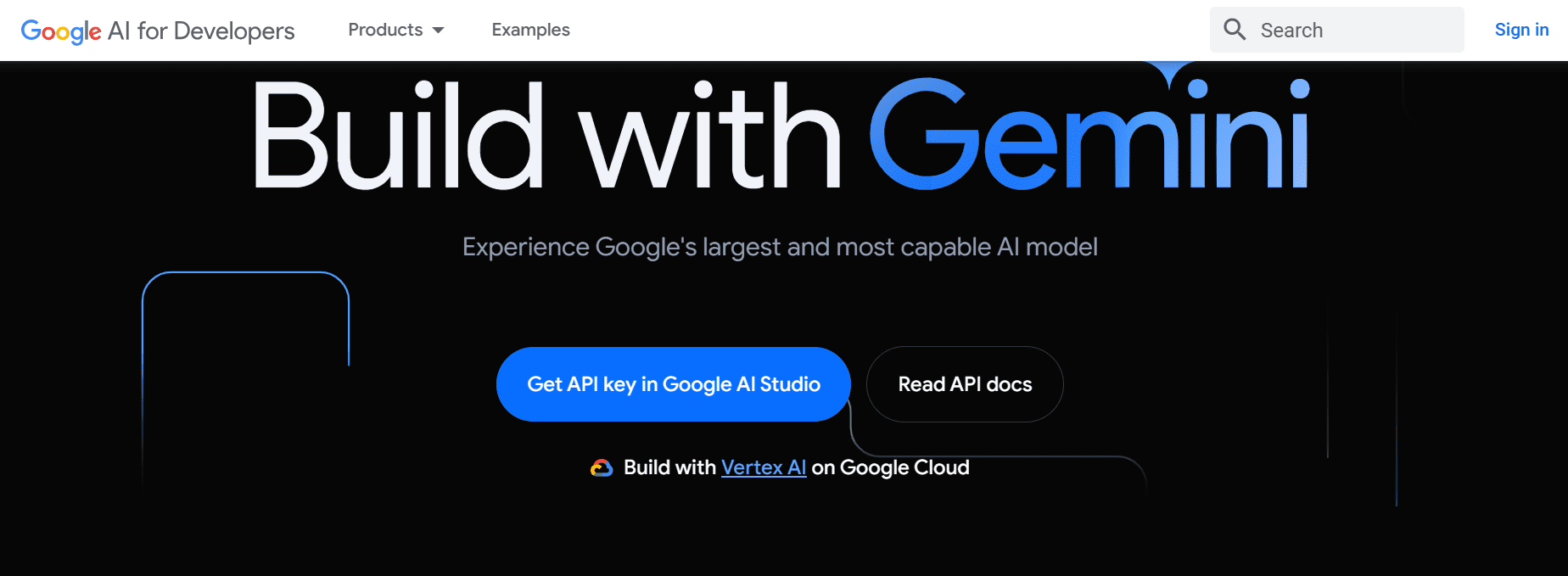
To get the Google AI API key, we have to go to the link https://ai.google.dev/ and then click on the blue button “Get API key Google AI Studio”.
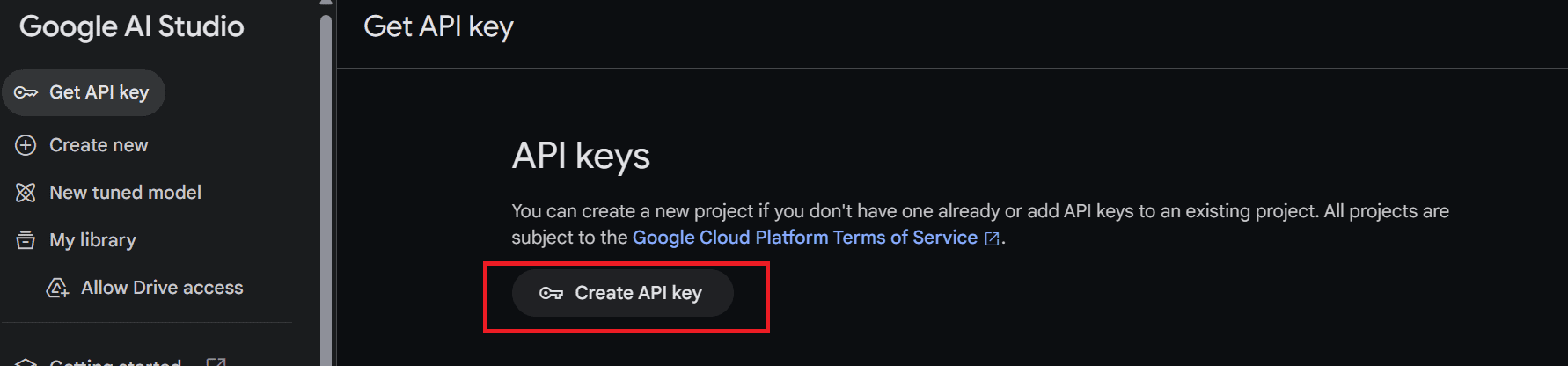
If you are logged in to your Google account, you will be directed to Google AI Studio. From there, click on the "Get API Key" button located on the left panel and then select "Create API key" to generate the API key.
This key will be used to generate responses on the official web app, locally, and on our deployed application.
2. Official Web Application
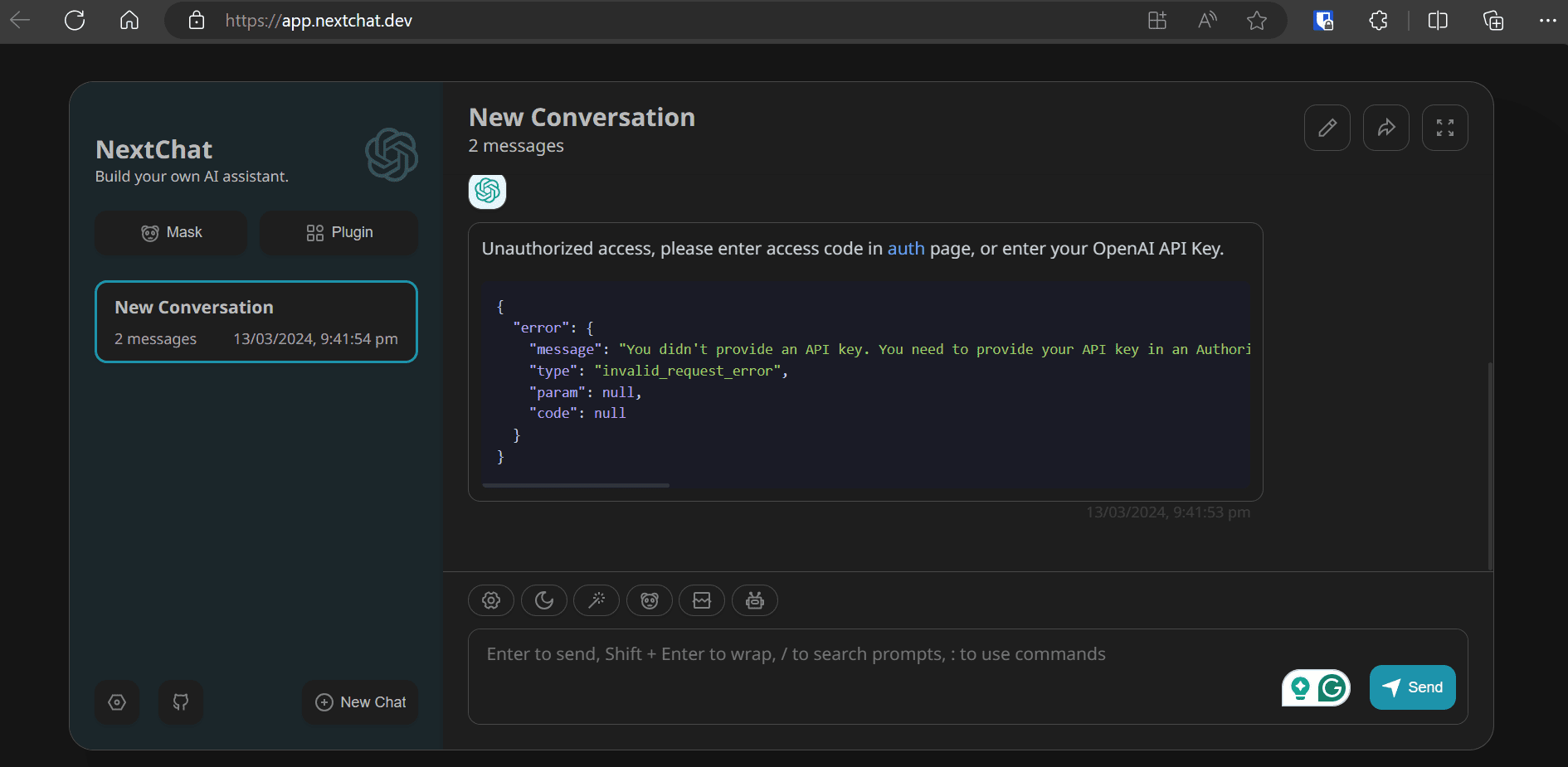
To access the official ChatGPT Next Web, go to https://app.nextchat.dev/. It asks us to provide an API key by going to the auth page.
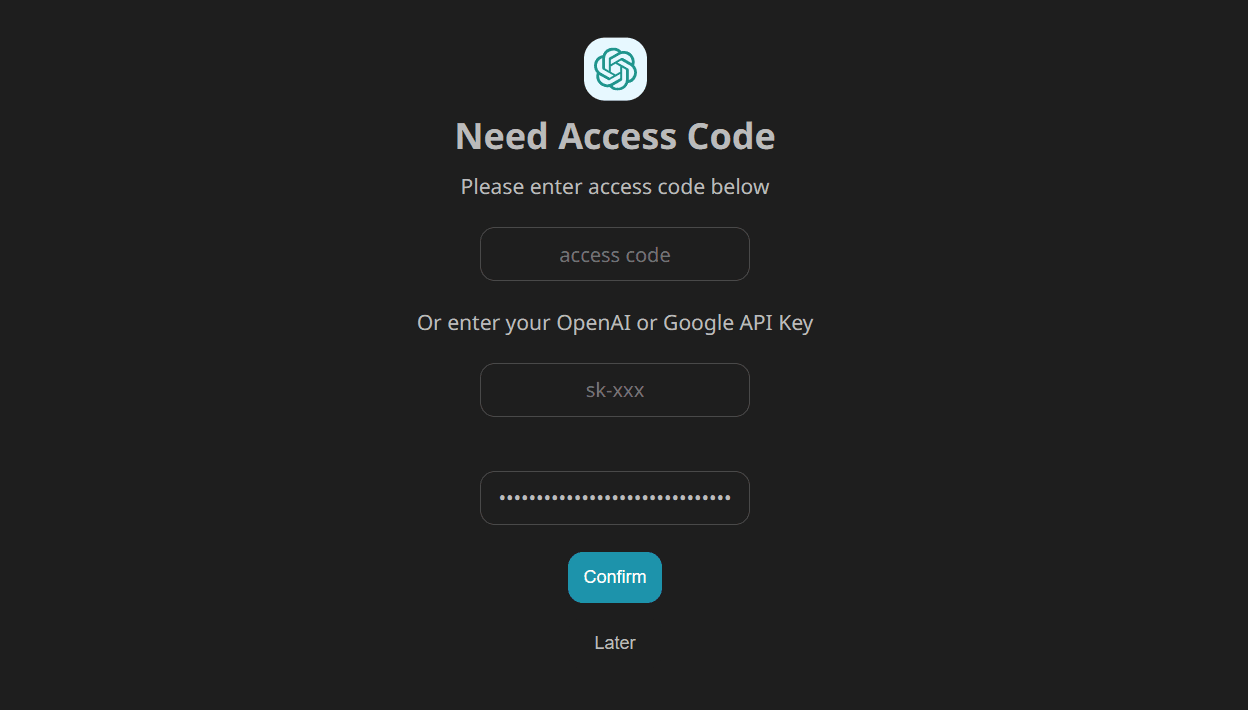
Access the authentication page at https://app.nextchat.dev/#/auth, enter the newly created Google AI API key in the third text box, and click the "Confirm" button.
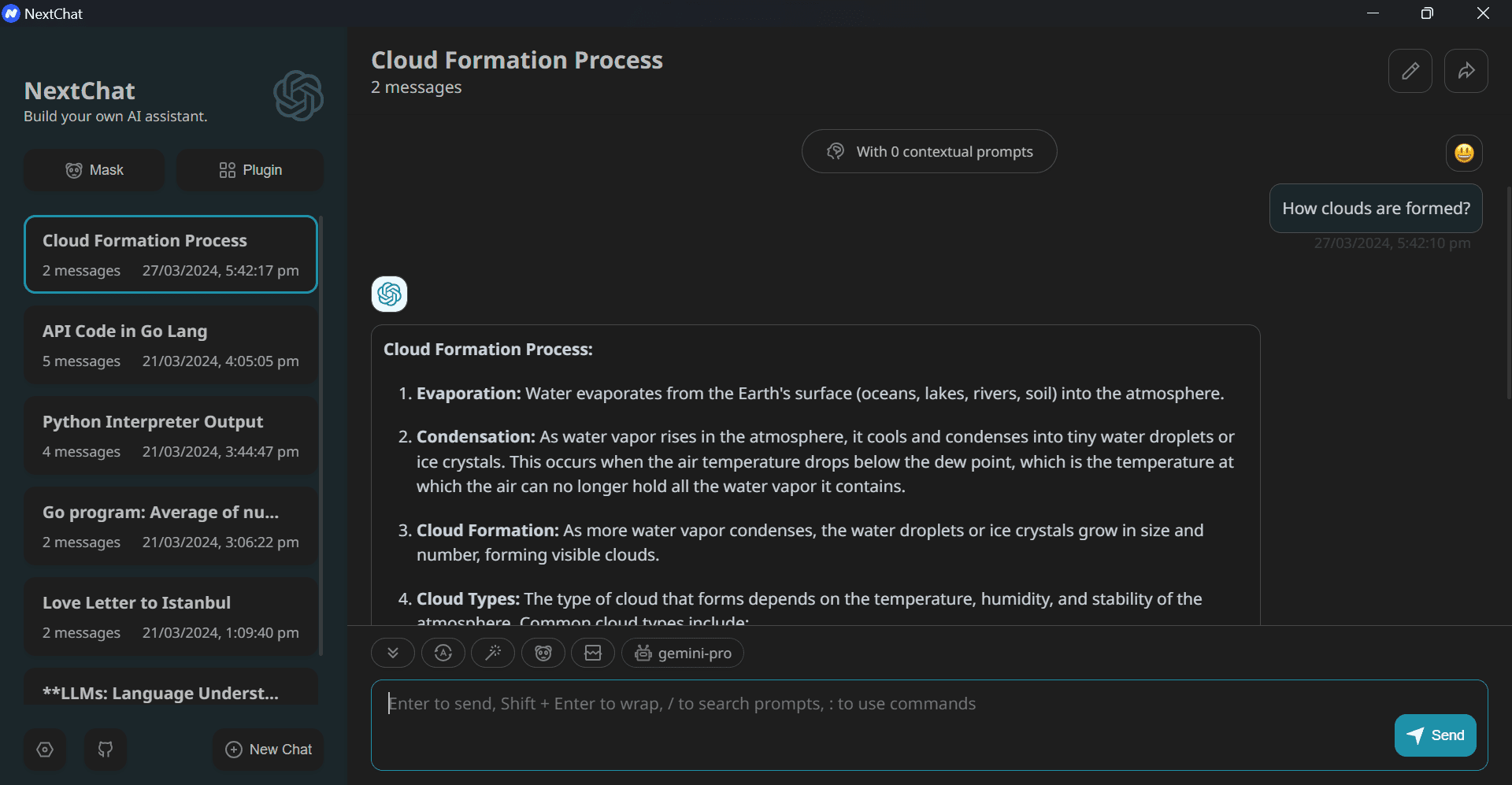
Click on the robot (🤖) above the message box and select the “gemini-pro” model.
Type the prompt in the message box, and within seconds, it will start generating the response. It is fast and fun to use.
3. Local Windows Application
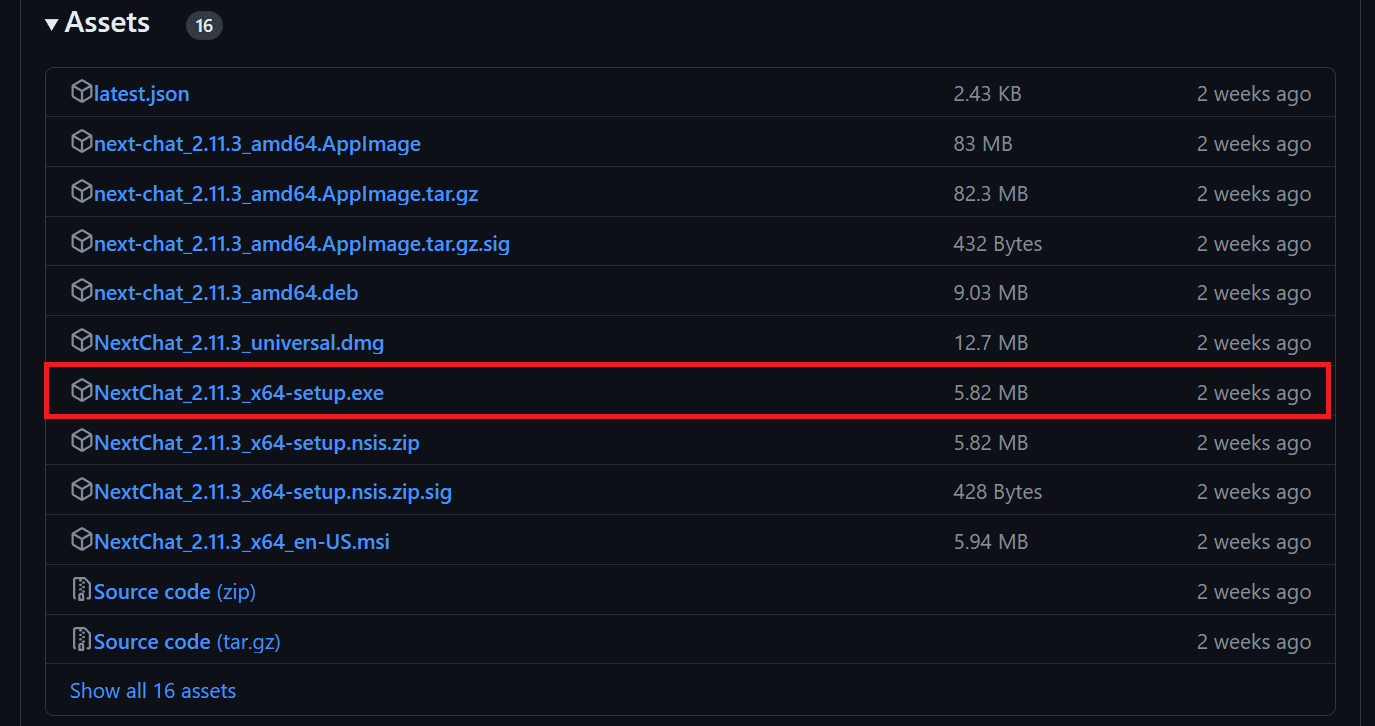
Let's proceed with the installation of ChatGPT Next Web on your laptop. This application is compatible with Linux, Windows, and MacOS.
In our case, we will visit the following link: https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web/releases and click on the `.exe` file. This will download the application setup file. Once downloaded, install the application with default settings and launch it.
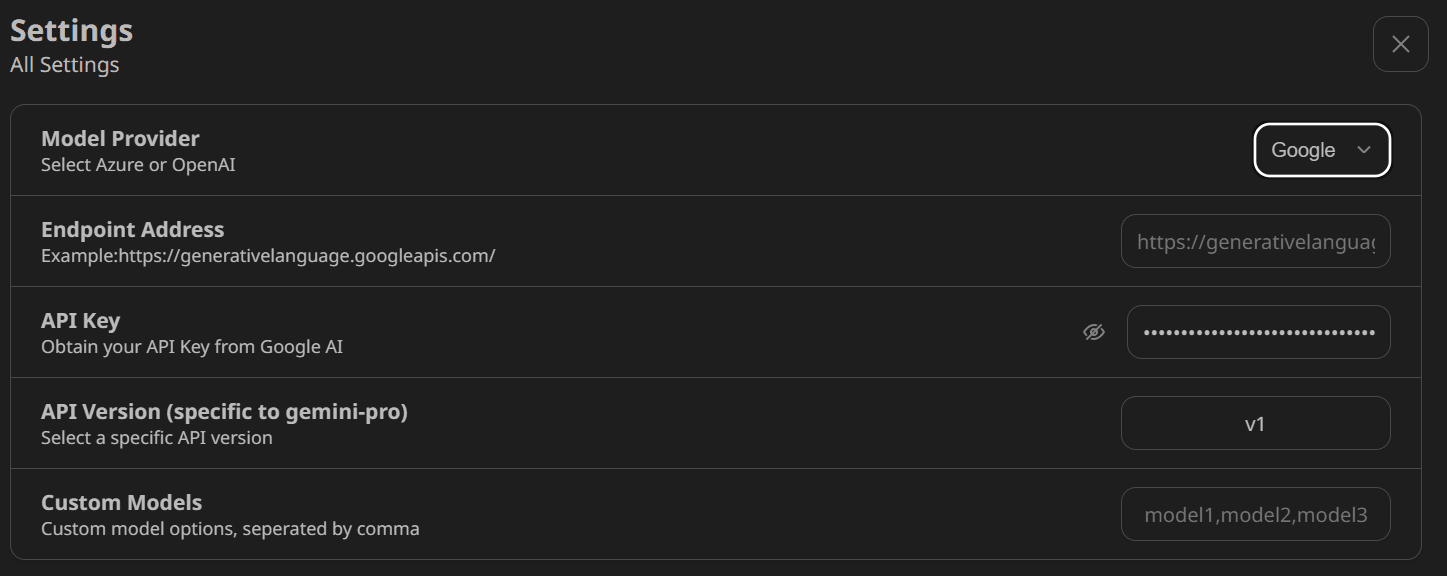
The Windows application does not have an authentication page. Therefore, to set up the Google AI API, we need to navigate to the settings and scroll down to locate the "Model Provider" section. From there, we should select the correct model provider and provide the API key, as demonstrated below.
After that, select the “gemini-pro” model and start using the application.
4. Deploy your Web Application with One Click
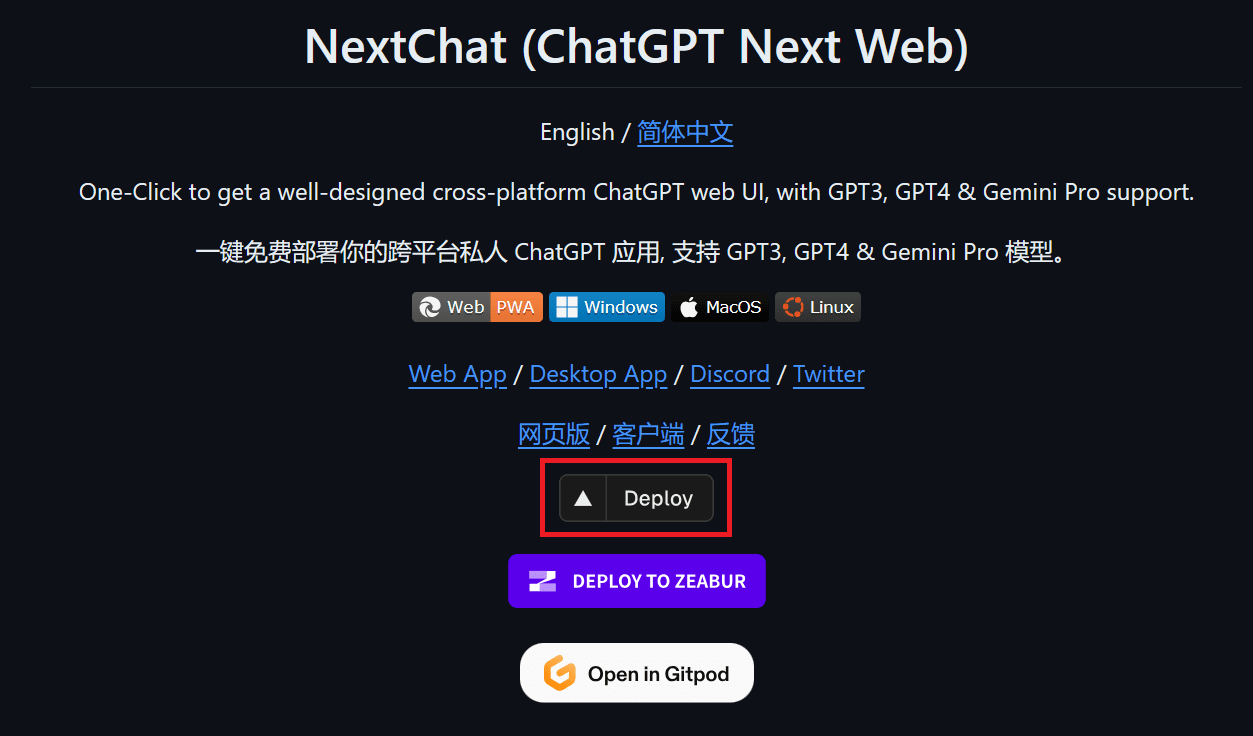
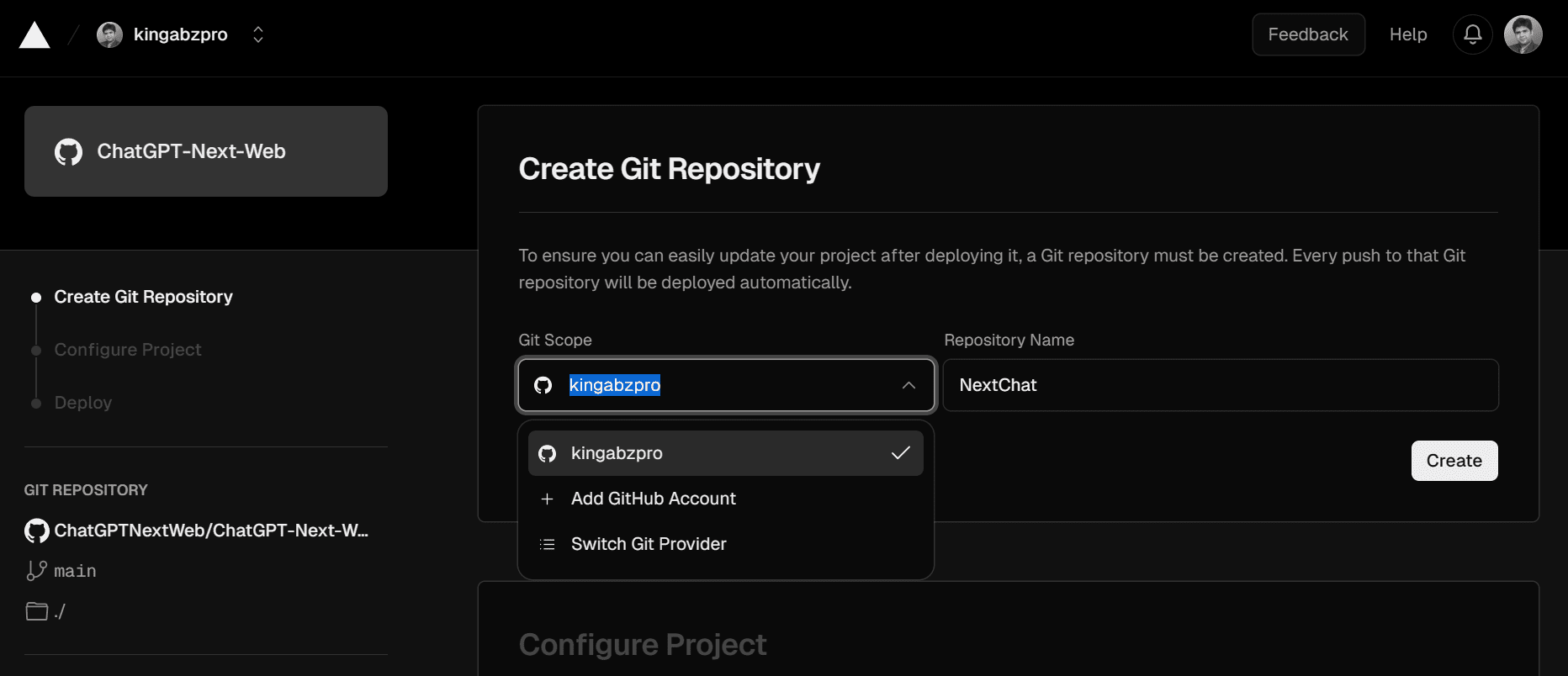
In the last section, we will learn to deploy our own web application on Vercel. To do so, we have to go to the official GitHub repository, ChatGPTNextWeb/ChatGPT-Next-Web, and click on the “Deploy” button.
After clicking the link, you will be directed to a new tab. Here you need to sign up for Vercel and log in to your GitHub account to create a new repository. Follow the simple instructions, press the deploy button, and wait for the process to complete.
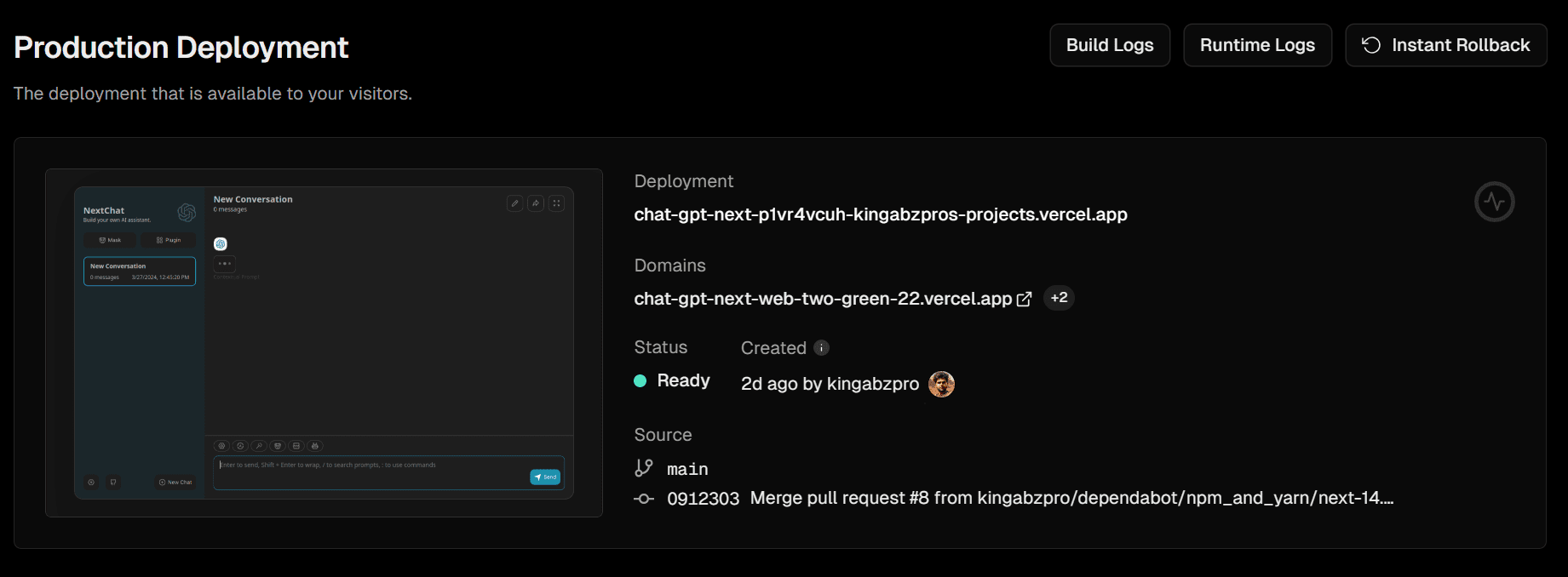
After a few minutes, the deployment will finish, and you will receive the URL for your web application.
To access the Vercel-deployed web application, visit https://chat-gpt-next-web-two-green-22.vercel.app/. I find NextChat to be smoother than Bard or ChatGPT.
Final Thoughts
I've been using ChatGPT Next Web for a while now, with an OpenAI API key. Even though it's a paid API, my monthly usage only costs around $0.3. Instead of paying $20 for ChatGPT Pro, I can access top-of-the-line models at a fraction of the cost, with a better user interface. If you're using Gemini Pro, it is even better because it's free for everyone.
If you're still unsure about using this application, follow my guide and use it for a week to explore its various features. I'm confident you'll change your mind, just like I did.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in technology management and a bachelor's degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
More On This Topic
Learning How to Use ChatGPT to Learn Python (or anything else)
Free ChatGPT Course: Use The OpenAI API to Code 5 Projects
Meet MetaGPT: The ChatGPT-Powered AI Assistant That Turns Text Into…
Top Free Resources To Learn ChatGPT
6 ChatGPT mind-blowing extensions to use anywhere
How to Use ChatGPT to Convert Text into a PowerPoint Presentation
Here’s something that can potentially ease, if not annihilate, Bengaluru’s traffic woes. Google’s Project Green Light is helping the city notorious for its jams and bottlenecks, improve traffic flow at intersections and reduce stop-and-go emissions.
This stems from an idea that Dotan Emanuel, researcher at Google, conceptualised over a dinner chat with his wife. Started in 2021, Google’s Project Green Light looks to optimise traffic lights in urban areas to reduce vehicle emissions, thereby contributing to the global effort to combat climate change and enhance urban mobility.
With AI and insights from Google Maps driving trends, Green Light demonstrates a deep understanding of global road networks. This enables it to model traffic patterns and build intelligent recommendations for city traffic engineers to optimise traffic flow.
“Project Green Light is now live in 13 global cities, like Rio, Hamburg, Bengaluru, and my hometown – Seattle,” said Juliet Rothenberg, product team lead of Climate AI at Google, in a recent interview with CBS News, demonstrating its workings. “Every red light is an opportunity for us,” she added.
Further, she said the early numbers indicate a potential for up to 30% reduction in stops and up to 10% cut in emissions at intersections. At the 70 intersections where Green Light is already live, this can save fuel and lower emissions for up to 30 million car rides monthly.”
Currently, Project Green Light operates at 70 intersections in 12 cities, including Bengaluru, Hyderabad, and Kolkata.
“Green Light has become an essential ally for the Kolkata Traffic Police. It contributes to safer, more efficient, and organised traffic flow and has helped us reduce gridlock at busy intersections,” said Vineet Kumar Goyal, the commissioner of police in Kolkata, reflecting on the initiative’s integration into the city.
He said that since November 2022, they have implemented suggestions at 13 intersections. “The outcome is excellent as per the feedback from commuters and traffic personnel,” he added.
Next Up: Solving ‘Ghost Traffic’
Project Green Light initiative has also addressed the concerns revolving around what you may call ‘ghost or phantom traffic‘, when congestion occurs seemingly without a clear cause.
A patented technology, Ghost Traffic Detection and Avoidance, outlines this approach to addressing ghost traffic. This technique mitigates traffic congestion by identifying road segments with high traffic volumes and providing speed recommendations to vehicles approaching those segments.
It works by gathering sensor data from vehicles and infrastructure, detecting areas of congestion, and then calculating a target speed for vehicles to maintain a safe distance from the cars in front and behind them.
This target speed is communicated to the drivers through a client device or vehicle interface. By ensuring consistent spacing between vehicles, the system aims to smoothen out traffic flow and reduce the stop-and-start patterns that often exacerbate congestion.
This is important because it addresses ‘ghost traffic jams’, where the traffic slows down without an apparent cause like accidents or roadwork. By managing vehicle speeds in response to real-time traffic conditions, it can significantly reduce unnecessary congestion and improve the overall traffic flow.
In other words, Google Maps provides real-time feedback to drivers, indicating the optimal speed to maintain in relation to the vehicle’s speed ahead. This is reflected through numerical or colour-coded indicators: green to speed up, yellow to slow down, and blue to maintain the same speed.
Recently, Google collaborated with the Bengaluru Traffic Police to reduce congestion. Features like Street View were introduced to offer real-time updates and alternative routes for faster commutes. Last year, the tech giant partnered with BMTC to optimise routes and schedules available to commuters using mobile phones.
Google’s Project Green Light certainly looks promising for curbing traffic congestion, not only in Bengaluru but also in other cities.
However, the tech giant is not alone in this initiative. Recently, a traffic control experiment was conducted in Nashville to understand if AI can solve phantom traffic.
Over 100 Nissan Rogue, Toyota RAV4, and Cadillac XT5 vehicles equipped with AI-powered control systems were designed to turn the cars into robot traffic managers. The researchers now aim to implement the same on a larger scale.
The space does look more exciting than ever.
The post Google Cracks Bengaluru’s Traffic appeared first on Analytics India Magazine.
SaaS entrepreneur Raisinghani’s new AI venture nabs $5.5M to boost sales efficiency Jagmeet Singh 8 hours
SiftHub, an AI startup founded by the former CTO and co-founder of LogiNext, Manisha Raisinghani, has raised $5.5 million in seed funding to build out its AI assistant, which is aimed at helping sales and presales teams focus more on building relationships and less on grunt work.
The company’s generative AI assistant is targeting the bulk of non-sales activity that sales personnel have to deal with, like entering data into CRM systems, filing requests for proposals (RFPs), researching customer info and building presentation decks. SiftHub integrates with sources of information like Google Drive, Slack, Zendesk, HubSpot and Salesforce, and sales and presales teams can simply talk to its AI assistant to complete infosec questionnaires, vendor assessment forms, and file RFPs and request for information (RFI) forms. The assistant is available through Slack and Microsoft Teams as a bot, as a Microsoft add-in, a Chrome plugin, and a web app, and has support for 10 languages, including Spanish and German.
“When salespeople are selling to businesses, they should be spending more time building relationships, which has a direct impact on the top line,” Raisinghani told TechCrunch. “When you don’t have to hire so many presales people to do the deep technical work for you, you’re saving time and that impacts your bottom line,” she told TechCrunch.
SiftHub’s AI assistant is built on open-source large language models (LLMs), and is supported by retrieval augmented generation (RAG) technology, which uses additional data sources to fine-tune the quality of content generated by AI. Using RAG on top of LLMs helps SiftHub limit hallucinations — a common issue with generative AI, where the system generates incorrect or misleading results. The startup also uses cross-encoders to prevent its platform from picking the wrong information from a given knowledge base. Cross-encoders analyze two queries simultaneously, instead of looking at each separately, to deliver more accurate answers.
“We would rather not give an answer rather than give the wrong answer,” Raisinghani said. The founder added that SiftHub’s system might give 5% fewer answers, but she is confident that at least 75% of the AI’s responses will be correct.
SiftHub also uses a “smart search algorithm” that considers the recency of documents or knowledge sources to surface relevant recent information, Raisinghani said.
After spending over 10 years at LogiNext, Raisinghani saw the need for a solution like SiftHub when she was advising blockchain startup Polygon Labs in 2022 on its enterprise go-to-market strategy. She realized that finding information about Polygon was an arduous task because data was not available through a single channel, as it was stored across multiple platforms. Sales and presales people need a lot of info about their company and its business operations when they reach out to their potential customers. Finding that info through different sources, including the company’s Slack channels and other unorganized documentation, is a cumbersome task that can take a lot of time.
She then spoke with about 200 users to understand the problem statement better and categorize their responses into different use cases. All that eventually brought her focus to sales and presales teams.
“Sales teams have a shadow team — a presales team or solutions engineers — and they are usually the unsung heroes of the organization. They do a lot of the technical work, right from filing RFPs (request for proposals) to finding answers to customers’ questions,” she explained. “If you’re saving time for both sales and presales, salespeople will automatically be able to spend more time on relationship building.”
The market for AI startups focusing on sales and presales operations has gained traction in the past year since generative AI took off. Companies across the spectrum, from giants like Salesforce, Zoom and Google to startups like Quilt, People.ai, and Darwin AI have built GenAI-powered tools to let salespeople simplify a wide array of tasks like filing routine forms, generating drafts for emails, filling up CRMs with publicly available information on customers, generate copy, get suggestions on which prospective customer is likely to buy or churn, and much more.
However, Raisinghani believes that SiftHub has a distinctive edge, as it sits deeper in customers’ business workflows and can solve the entire sales response problem — unlike a “wrapper around OpenAI or any other LLM.”
The startup is also banking on Raisinghani’s own experience in scaling startups and its team of 15, which includes some ex-entrepreneurs. “When you’re going to give at least 10 years of your life to something, you want to make sure that you are going to be excited and you truly believe in it for the next decade,” she said. The company is headquartered in the U.S., and has an R&D team in Mumbai, India.
The funding will be used to hire more people in product R&D, enhance the product, and help the company go to market. The seed round was co-led by Matrix Venture Partners and Blume Ventures, with participation from Neon Fund as well as executives and founders from Superhuman, Cloudflare, DevRev, RazorPay and SuperOps.
SiftHub is initially targeting B2B companies selling to mid-market and enterprise customers with revenues between $50 million and $500 million. The AI assistant is currently available to a small group of users for early feedback, and the startup is planning a “full-blown launch” later this year.
“Buyers have become smarter and engage sales later in the buying journey, with more advanced questions. As a result, the expectation from sales teams has changed — they need to know advanced product, technical, and legal information to get the win. Sales and presales teams lack the necessary tooling to handle this new selling environment. We are excited by SiftHub’s vision to use AI to manage product knowledge so that sales can focus on relationships,” said Pranay Desai, a partner at Matrix Partners India, in a prepared statement.
“SiftHub is Manisha’s second venture in the SaaS space. Armed with over a decade of entrepreneurial experience and an impressive track record, Manisha and her team are building a game-changing AI platform to transform the entire sales and presales process. We are excited to back the SiftHub team and be a part of their ambitious journey,” said Sanjay Nath, a partner at Blume Ventures.
Amid the buzz surrounding Apple’s unveiling of the new MM1 model last month, the tech giant has now introduced another contender poised to beat OpenAI’s GPT-4 with its latest AI model, ReALM (Reference Resolution As Language Modeling).
This new model comprehends various contexts and delivers accurate information. Users can pose queries, which are visible on the screen or running in the background, and receive precise answers seamlessly.
Apple says its latest AI model ReALM is even “better than OpenAI’s GPT4”. It likely is as GPT4 has regressed because of “alignment”. The ReALM war begins at WWDC 2024. Paper: https://t.co/3emVSjgRvK pic.twitter.com/tOPMVaVI9V
— Brian Roemmele (@BrianRoemmele) April 1, 2024
Apple believes its latest AI model surpasses OpenAI’s GPT-4.
“We also benchmark against GPT-3.5 and GPT-4, with our smallest model achieving performance comparable to that of GPT-4, and our larger models substantially outperforming it,” said the researchers in the paper titled ReALM: Reference Resolution As Language Modeling.
The researchers include Joel Ruben Antony Moniz, Soundarya Krishnan, Melis Ozyildirim, Prathamesh Saraf, Halim Cagri Ates, Yuan Zhang, Hong Yu, and Nidhi Rajshree.
GPT-4 vs ReALM
Apple researchers said the difference between GPT-3.5 and GPT-4 is how they process information. They said that GPT-3.5 can only understand text, so we only give it text prompts. On the other hand, GPT-4 can also understand images. This combination of text and image helps GPT-4 perform much better.
ReALM, on the other hand, uses both text and images (like screenshots) to understand and respond to prompts more effectively.
The researchers, however, said that there are even more ways to enhance results, like using similar phrases until you reach a certain length of the prompt. “This more complex approach deserves further, dedicated exploration, and we leave this to future work,”
Further, they said that the ReALM model will be tested across three distinct entity types associated with diverse tasks: on-screen entities, conversational entities, and background entities.
Decoding Reference Resolution
Apple researchers further said that understanding references like ‘they’ or ‘that’ in human speech is intuitive for our brains and helps us effortlessly understand contextual cues. However, deciphering such references poses a challenge for an LLM-based chatbot as it struggles to understand the intended context.
This challenge is known as reference resolution, where the aim is to comprehend the specific entity or concept to which an expression refers.
The researchers believe that the low-power nature and latency constraints of such systems require the use of a ‘single LLM’ with extensive prompts to achieve seamless experiences.
For instance, a user asks about nearby pharmacies, which can be done by Siri, leading to a list being presented. Later, the user asks to call the bottom listed number (present on-screen). Siri would not perform this particular task. However, with ReALM, the language model can comprehend the context by analysing on-device data and fulfilling the query. This also hints that at WWDC 2024, scheduled for June 10-14, 2024, Siri will most likely get a generative AI upgrade, setting the stage and heralding the arrival of the ReALM. “It’s going to be Absolutely Incredible!” said Apple SVP of marketing Greg Joswiak, in his recent post, hinting at the AI innovations that are going to be unveiled at the developers’ conference.
The post Apple’s ReALM Challenges OpenAI’s GPT-4 appeared first on Analytics India Magazine.
I got my first data analytics internship back in 2020.
Ever since then, I’ve transitioned into a senior-level full-time role, landed multiple freelance data analytics gigs, and consulted for companies in different parts of the world.
During this time, I have reviewed resumes for data analyst positions and even shortlisted candidates for jobs.
And I noticed one thing that separated the most prominent applicants from everyone else.
Projects.
Even if you have zero experience in the data industry and no technical background, you can stand out from everyone else and get hired solely based on the projects you display on your resume.
In this article, I’m going to show you how to create projects that help you stand out from the competition and land your first data analyst job.
Data Analytics Projects That Will KILL Your Resume
If you’re reading this article, you probably already know that it is important to display projects on your resume.
You might even have built a few projects of your own after taking an online course or boot camp.
However, many data analytics projects do more harm to your portfolio than good. These projects can actually lower your chances of getting a job and must be avoided at all costs.
For example, if you’ve taken the popular Google Data Analytics Certificate on Coursera, you’ve probably done the capstone project that comes with this certification.
Image from Coursera
However, over 2 million other people have enrolled in the same course, and have potentially completed the same capstone project.
Chances are, recruiters have seen these projects on the resume of hundreds of applicants, and will not be impressed by it.
A similar logic applies to any other project that has been created many times.
Creating a project using the Titanic, Iris, or Boston Housing dataset on Kaggle can be a valuable learning experience, but should not be displayed on your portfolio.
If you want a competitive edge over other people, you need to stand out.
Here’s how.
5 Data Analytics Projects to Get You a Job
A project that stands out must be unique.
Pick a project that:
Solves a real-world problem.
Cannot be easily replicated by other people.
Is interesting and tells a story.
Much of the advice on data analytics projects on the Internet is inaccurate and unhelpful.
You will be told to create generic projects like an analysis of the Titanic dataset—projects that add no real value to your resume.
Unfortunately, the people telling you to do these things aren’t even working in the data industry, so you must be discerning when taking this advice.
In this article, I will be showing you examples of real people who have landed jobs in data analytics because of their portfolio projects.
You will learn about the types of projects that actually get people hired in this field so that you can potentially build something similar.
1. Job Trends Monitoring Dashboard
The first project is a dashboard displaying job trends in the data industry.
I found this project in a video created by Luke Barousse, a former lead data analyst who also specializes in content creation.
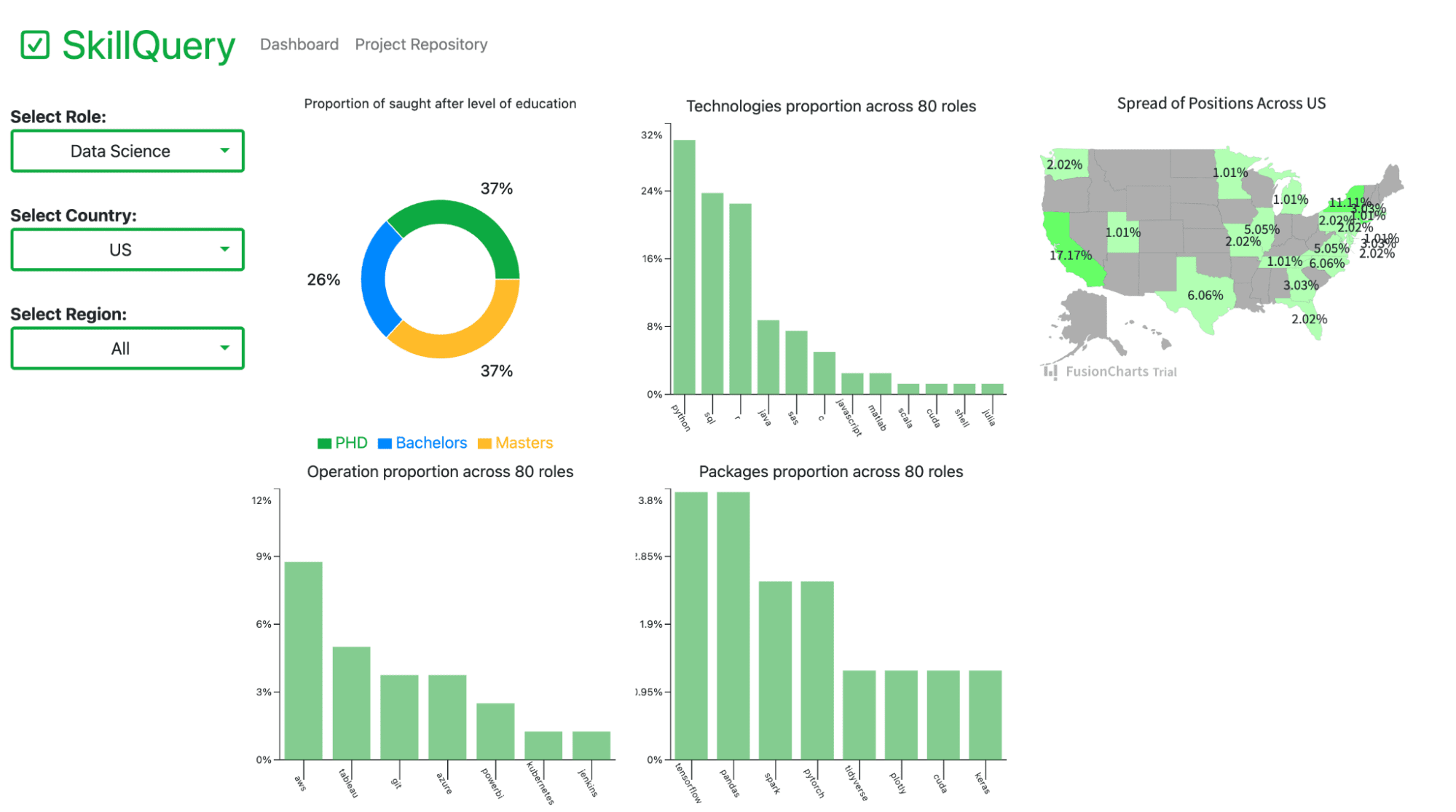
Here is a screenshot of this dashboard:
Image from SkillQuery
The above dashboard is called SkillQuery, and it displays the top technologies and skills that employers are looking for in the data industry.
For instance, we can tell by looking at the dashboard that the top language that employers are looking for in data scientists is Python, followed by SQL and R.
The reason this project is so valuable is because it solves an actual problem.
Every job-seeker wants to know the top skills that employers are looking for in their field so they can prepare accordingly.
SkillQuery helps you do exactly this, in the form of an interactive dashboard that you can play around with.
The creator of this project has displayed crucial data analytics skills such as Python, web scraping, and data visualization.
You can find a link to this project’s GitHub repository here.
2. Credit Card Approval
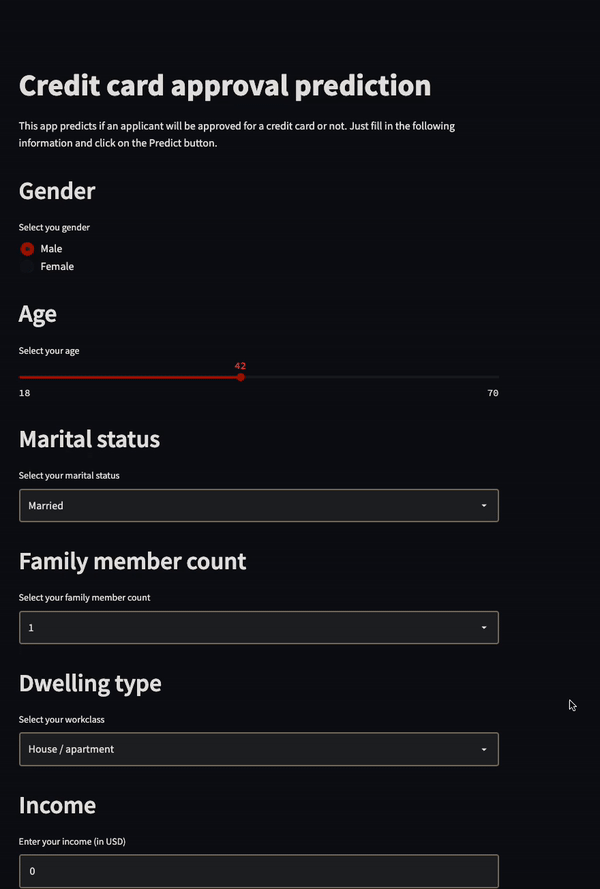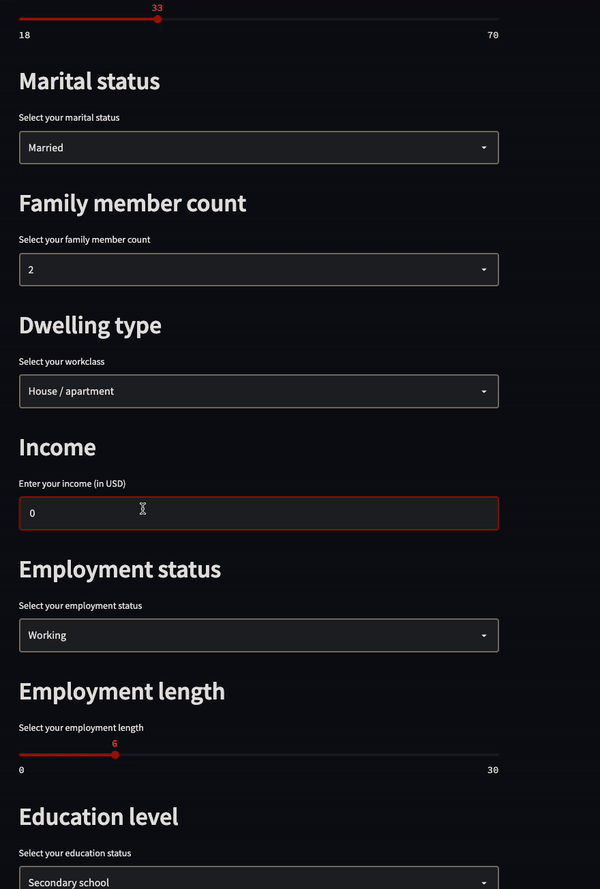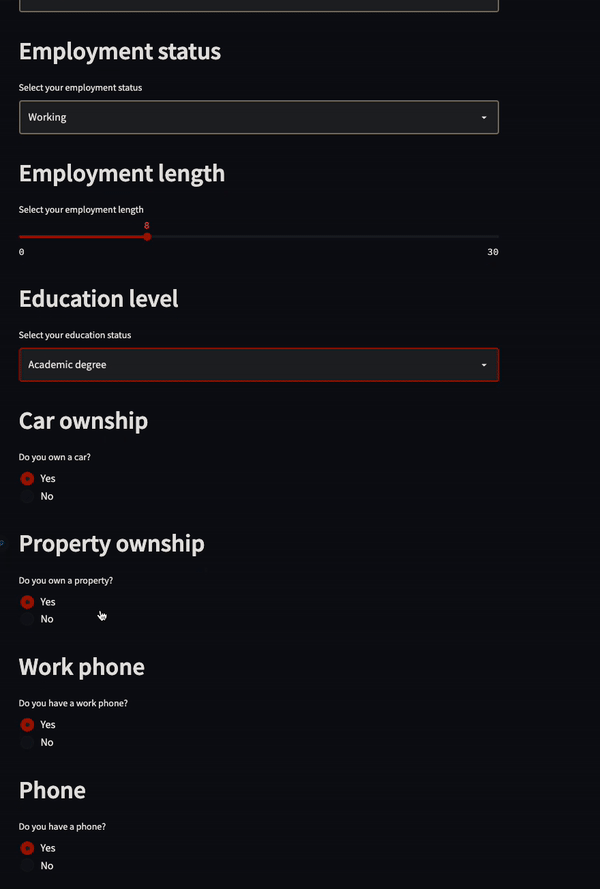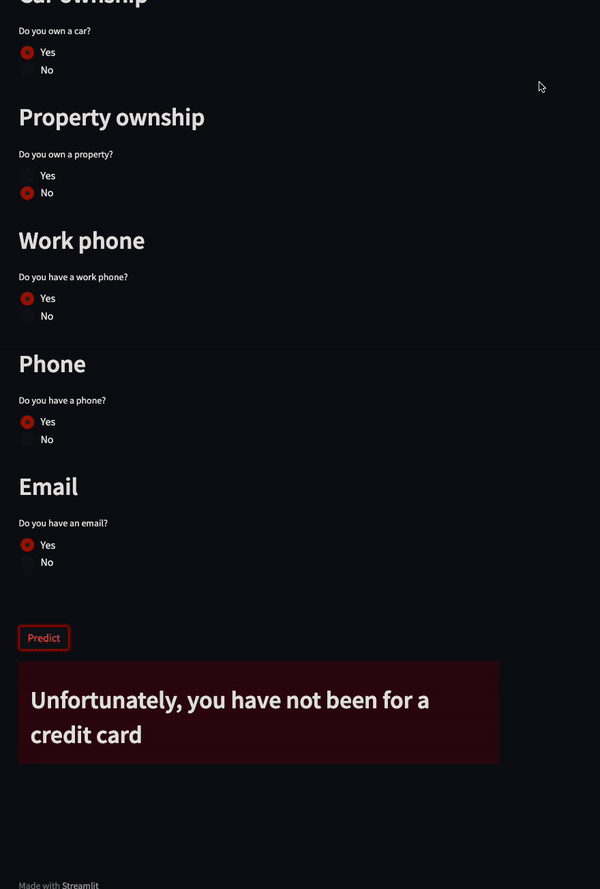
This project was created to predict whether a person will be approved for a credit card or not.
I found it in the same video created by Luke Barousse, and the creator of this project ended up getting a full-time role as a data analyst.
The credit card approval model was deployed as a Streamlit application:
Image from Semasuka’s GitHub Project
You simply need to answer the questions displayed on this dashboard, and the app will tell you whether or not you have been approved for a credit card.
Again, this is a creative project that solves a real-world problem with a user-friendly dashboard, which is why it stood out to employers.
The skills displayed in this project include Python, data visualization, and cloud storage.
3. Social Media Sentiment Analysis
This project, which I created a few years ago, involves conducting sentiment analysis on content from YouTube and Twitter.
I’ve always enjoyed watching YouTube videos and was particularly fascinated by channels that created makeup tutorials on the platform.
At that time, a huge scandal surfaced on YouTube involving two of my favorite beauty influencers—James Charles and Tati Westbrook.
I decided to analyze this scandal by scraping data on YouTube and Twitter.
I built a sentiment analysis model to gauge public sentiment of the feud and even created visualizations to understand what people were saying about these influencers.
Although this project had no direct business application, it was interesting since I analyzed a topic I was passionate about.
I also wrote a blog post outlining my findings, which you can find here.
The skills demonstrated in this project include web scraping, API usage, Python, data visualization, and machine learning.
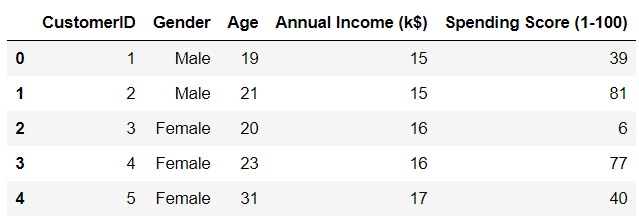
4. Customer Segmentation with Python
This is another project that was created by me.
In this project, I built a K-Means clustering model with Python using a dataset on Kaggle.
I used variables such as gender, age, and income to create various segments of mall customers:
Image from Kaggle
Since the dataset used for this project is popular, I tried to differentiate my analysis from the rest.
After developing the segmentation model, I went a step further by creating consumer profiles for each segment and devising targeted marketing strategies.
Because of these additional steps I took, my project was tailored to the domain of marketing and customer analytics, increasing my chances of getting hired in the field.
I have also created a tutorial on this project, providing a step-by-step guide for building your own customer segmentation model in Python.
The skills demonstrated in this project include Python, unsupervised machine learning, and data analysis.
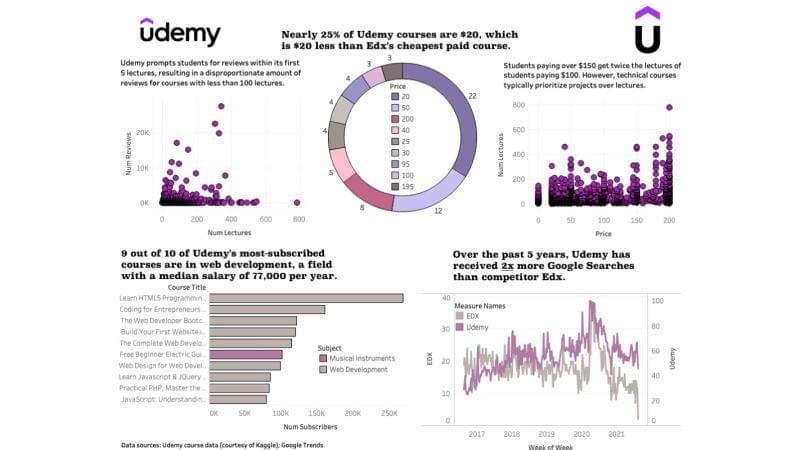
5. Udemy Course Data Analysis Dashboard
The final project on this list is a dashboard displaying insights on Udemy courses:
Image from Medium
I found this project in a Medium article written by Zach Quinn, who currently is a senior data engineer at Forbes.
Back when he was just starting out, Zach says that this dashboard landed him a data analyst job offer from a reputable company.
And it’s easy to see why.
Zach went beyond simply using SQL and Python to process and analyze data.
He has incorporated data communication best practices into this dashboard, making it engaging and visually appealing.
Just by looking at the dashboard, you can gain key insights about Udemy’s courses, its student’s interests, and its competitors.
The dashboard also demonstrates metrics that are vital to businesses, such as customer engagement and market trends.
Among all the projects listed in this article, I like this one the most since it goes beyond technical skills and displays the analyst’s adeptness in data storytelling and presentation.
Here is a link to Zach’s article where he provides the code and steps taken to create this project.
Data Analytics Projects to Land You a Job—Next Steps
I hope that the projects described in this article have inspired you to create one of your own.
If you don’t have any project ideas or face obstacles when developing your own, I recommend utilizing generative AI models for assistance.
ChatGPT, for example, can provide a wealth of project ideas and even generate fake datasets, allowing you to hone your analytical skills.
Engaging with ChatGPT for data analysis will allow you to learn new technologies faster and become more efficient, helping you stand out from the competition.
If you’d like to learn more about using ChatGPT and generative AI for data analysis, you can watch my video tutorial on the topic.
Natassha Selvaraj is a self-taught data scientist with a passion for writing. Natassha writes on everything data science-related, a true master of all data topics. You can connect with her on LinkedIn or check out her YouTube channel.
More On This Topic
Data Science Projects That Will Land You The Job in 2022
3 Data Science Projects Guaranteed to Land You That Job
KDnuggets News, June 1: The Complete Collection of Data Science…
KDnuggets™ News 22:n05, Feb 2: 7 Steps to Mastering Machine…
A Data Science Portfolio That Will Land You The Job in 2022
GitHub has introduced several new updates for GitHub Actions to further support enterprise customers, bringing stronger security and even more power to GitHub-hosted runners.
The updates include Azure private networking for GitHub-hosted runners, GPU-hosted runners for machine learning, and additional runner SKUs.
Azure private networking for GitHub-hosted runners is generally available
Azure private networking for GitHub-hosted runners is now generally available. This feature allows developers to run Actions workflows on GitHub-hosted runners that are connected to their Azure virtual network, without compromising on security or performance.
GitHub-hosted runners provide powerful compute in the cloud for running CI/CD and automation workflows that are fully managed, eliminating the overhead of managing and maintaining infrastructure. However, enterprises having strict networking and security requirements, prevents them from using GitHub-hosted runners to their full potential, specifically:
Secure access to private resources within their on-prem or cloud-based locations, such as databases, artifactory, storage accounts, or APIs.
Enforce network security policies and outbound access rules on the runners to reduce data exfiltration risks.
Isolate their build traffic from the public internet and route it through their existing private network connections (ex. VPN or ExpressRoute).
Monitor network traffic for any malicious or unusual behaviour as workflows run.
With Azure private networking, organizations can easily create GitHub-hosted runners that are provisioned within their Azure virtual network and subnet of choice.
Thereafter, Actions workflows can securely access Azure services like storage accounts, databases and on-premises data sources such as an Artifactory through existing, pre-configured connections like VPN gateways and ExpressRoutes.
Additionally, security is front and centre with this update. Any existing or new networking policies, such as Network Security Group (NSG) or firewall rules, will automatically apply to GitHub-hosted runners giving platform administrators comprehensive control over network security, all managed within a single place.
GitHub has also introduced the latest additions to the GitHub-hosted runner fleet, 2 vCPU Linux and 4 vCPU Windows runners, supporting auto-scaling and private networking features.
Previously, GitHub’s supported SKUs ranged from 4 vCPU (Linux only) to 64 vCPU, prompting substantial feedback requesting smaller SKUs with the same auto-scaling and private networking capabilities.
These newly introduced smaller machines are geared to specifically support scenarios where smaller machine sizes suffice yet the demand for heightened security and performance persists. Additionally, Apple silicon (M1) hosted runners, specifically macOS L (12-core Intel) and macOS XL (M1 w/GPU hardware acceleration) which were previously in public beta, are now generally available.
GPU hosted runners available in public beta
Additionally, GitHub has announced GPU-hosted runners in public beta. This new runner empowers teams working with machine learning models such as large language models (LLMs) or those requiring GPU graphic cards for game development to run these more efficiently as part of their automation or CI/CD process, empowering teams to do complete application testing, including the ML components, with GitHub Actions.
Moreover, the GPU SKU comes equipped with auto-scaling and private networking features. GitHub is initially rolling out support for a 4-core SKU with 1 T4 GPU, and has more SKUs planned for later this year.
The post GitHub is Bringing Enterprise-level Security to GitHub Hosted Runners appeared first on Analytics India Magazine.