

In the past week, we saw several ‘Mixture of Experts’ models coming in, like Databricks DBRX, AI21 Labs’ Jamba, xAI’s Grok-1, and Alibaba’s Qwen 1.5, with Mixtral 8X 7B already in the mix, making MoE popular.
Welcome to MOE's, which model would you like to use today from our new and updated menu?
XXL @DbrxMosaicAI
XL @MistralAI
Medium @AI21Labs
Small @Alibaba_Qwen
cc @code_star @JustinLin610 @tombengal_ pic.twitter.com/Ms7PCXiULv— Alex Volkov (Thursd/AI) (@altryne) March 28, 2024
Decoding Mixture of Experts
A Mixture of Experts (MoE) model is a type of neural network architecture that combines the strengths of multiple smaller models, known as ‘experts’, to make predictions or generate outputs. An MoE model is like a team of hospital specialists. Each specialist is an expert in a specific medical field, such as cardiology, neurology, or orthopaedics.
With respect to Transformer models, MoE has two key elements – Sparse MoE Layers and a Gate Network.
Sparse MoE layers represent different ‘experts’ within the model, each capable of handling specific tasks. The gate network functions like a manager, determining which words or tokens are assigned to each expert.
MoEs replace the feed-forward layers with Sparse MoE layers. These layers contain a certain number of experts (e.g. 8), each being a neural network (usually an FFN).
Breaking Down Popular MoEs
Databricks DBRX uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters, of which 36B are active on any input. It stands out among other open MoE models, such as Mixtral and Grok-1, because it employs a fine-grained approach.
A fine-grained mixture of expert models further breaks down the ‘experts’ to perform extremely specific subtasks, splitting the FFNs into smaller components. This can result in many small experts (even hundreds of experts), and then you can control how many experts you want to be activated.
The idea of fine-grained experts was introduced by DeepSeek-MoE.
Specifically, DBRX has 16 experts and selects four of them, whereas Mixtral and Grok-1 each have eight experts and choose two. According to Databricks, this provides 65x more possible combinations of experts.
xAI recently open-sourced Grok 1, which is a 314B parameter Mixture-of-Experts model with 25% of the weights active on a given token, which means at a time it uses 78 billion parameters.
Whereas, AI21 Labs’ Jamba is a hybrid decoder architecture that combines Transformer layers with Mamba layers, a recent state-space model (SSM), along with a mixture-of-experts (MoE) module. The company refers to this combination of three elements as a Jamba block.
Jamba applies MoE at every other layer, with 16 experts and uses the top-2 experts at each token. “The more the MoE layers, and the more the experts in each MoE layer, the larger the total number of model parameters,” wrote AI21 Labs in Jamba’s research paper.
Jamba uses MoE layers to only use 12 billion out of its total 52 billion parameters during inference, making it more efficient than a Transformer-only model of the same size.
“Jamba looks very impressive! It’s technically smaller than Mixtral yet shows similar performance on benchmarks and has a 256k context window,” shared a user on X.
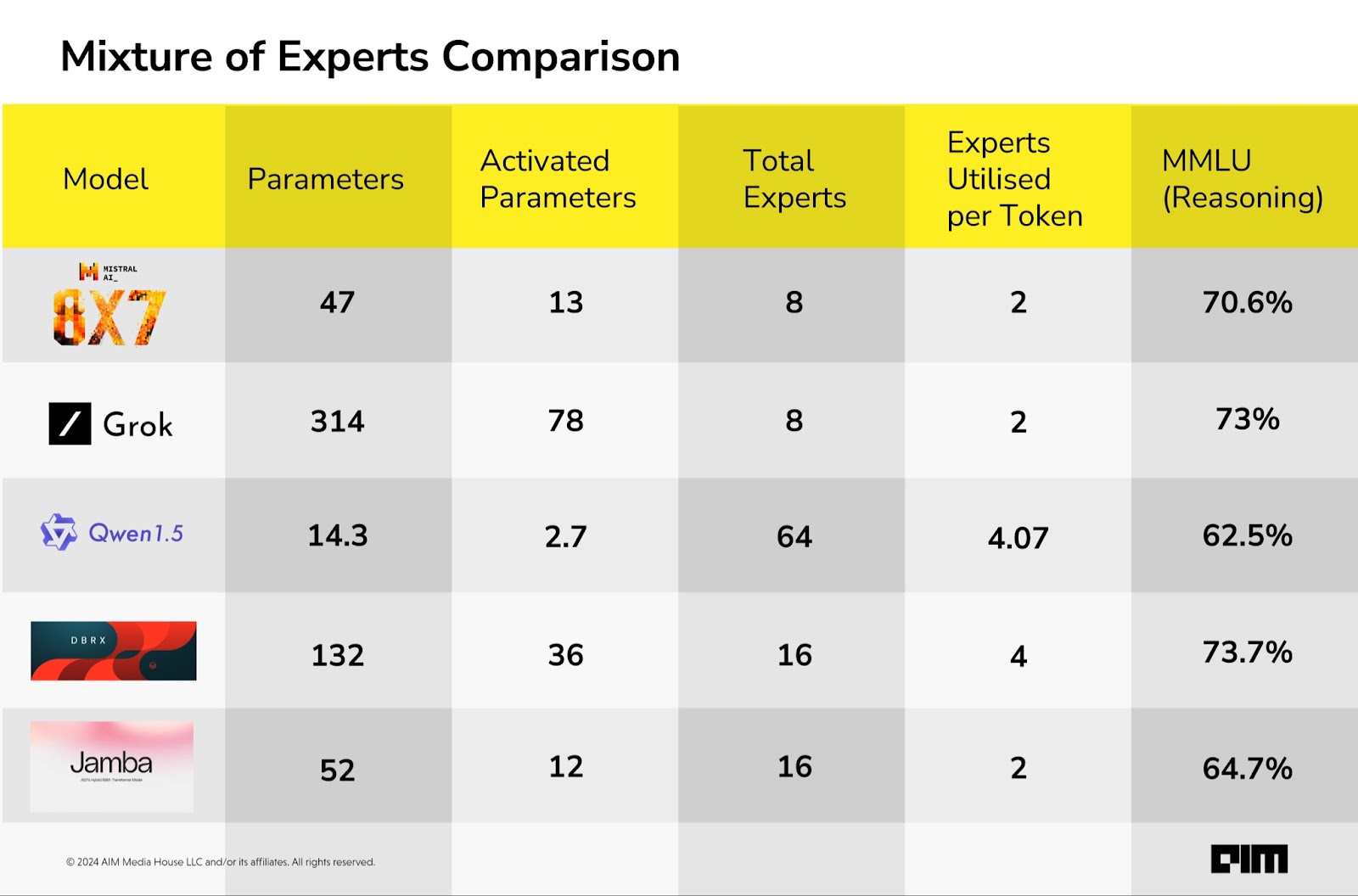
Alibaba recently released Qwen1.5-MoE which is a 14B MoE model with only 2.7 billion activated parameters. It comes with a total of 64 experts, representing an 8-time increase compared to the conventional MoE setup of eight experts.
Similar to DBRX, it also employs a fine-grained MoE architecture where Alibaba has partitioned a single FFN into several segments, each serving as an individual expert.
“DBRX is good for enterprise applications, but the Qwen MoE is a cool and great toy to play with,” wrote a user on X.
Mixtral 8X7B is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block selects from eight distinct parameter groups. At each layer, for every token, a router network chooses two of these groups (the ‘experts’) to process the token. It has 47B parameters but uses only 13B active parameters during inference
Why Choose MoE?
“Mixture-of-Experts will be Oxford’s 2024 Word of the Year,” quipped a user on X. However, jokes aside the reason today MoE models are getting popularity is that they enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model.
In an MoE model, not all parameters are active or used during inference, even though the model might have many parameters. This selective activation makes inference much faster compared to a dense model that uses all parameters for every computation. However, there’s a trade-off in terms of memory requirements because all parameters must be loaded into RAM, which can be high.
As the need for larger and more capable language models increases, the adoption of MoE techniques is expected to gain momentum in the future.
The post The Rise of Mixture of Experts (MoE) Models appeared first on Analytics India Magazine.