Image by Author
When building applications in Python, JSON is one of the common data formats you’ll work with. And if you’ve ever worked with APIs, you're probably already familiar with parsing JSON responses from APIs.
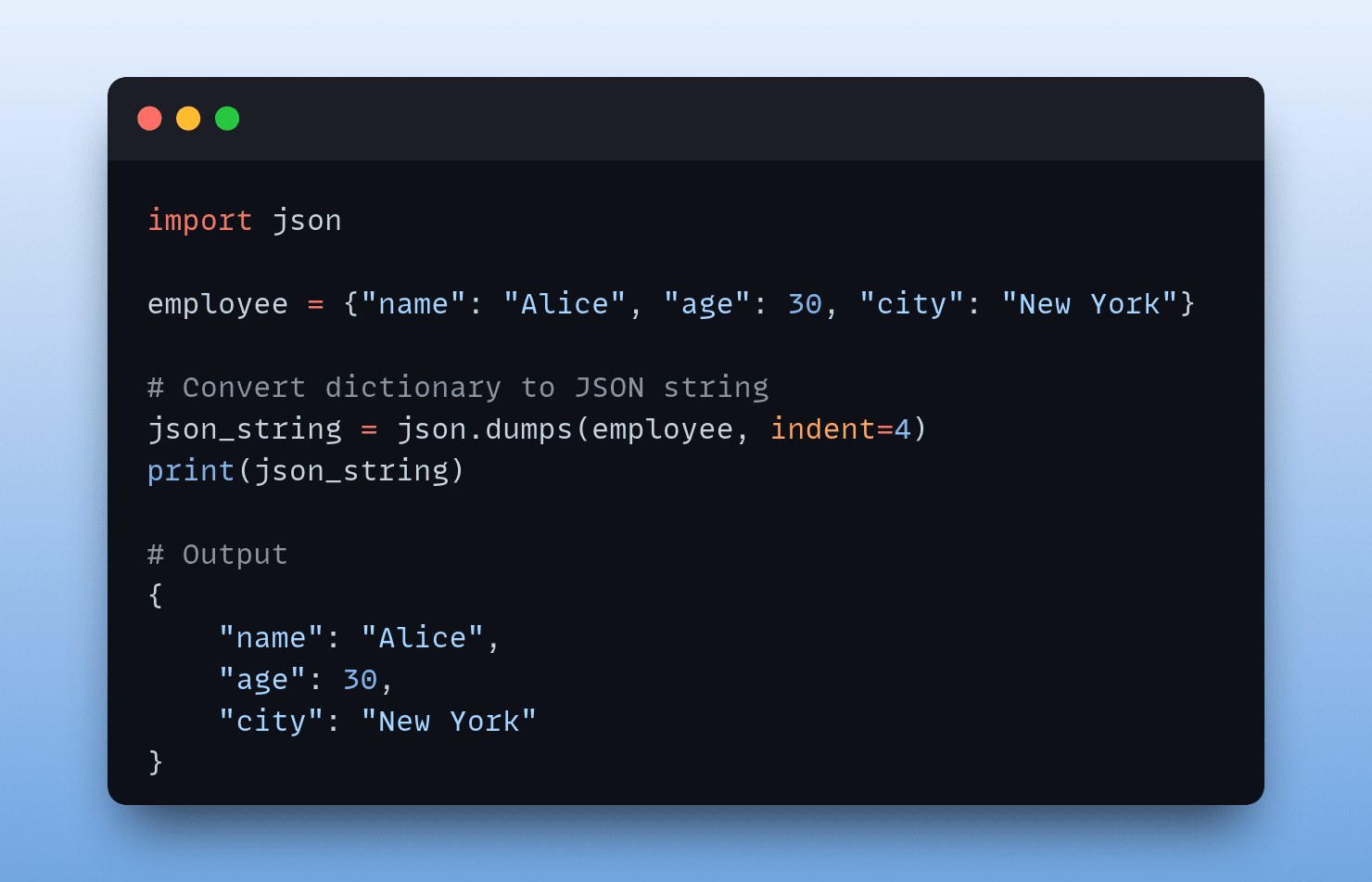
As you know, JSON is a text-based format for data interchange, which stores data in key-value pairs and is human readable. And Python dictionaries store data in key-value pairs. Which makes it intuitive to load JSON strings into dictionaries for processing and also dump data from dictionaries into the JSON strings.
In this tutorial, we’ll learn how to convert a Python dictionary to JSON using the built-in json module. So let's start coding!
Converting a Python Dictionary to a JSON String
To convert a Python dictionary to JSON string, you can use the dumps() function from the json module. The dumps() function takes in a Python object and returns the JSON string representation. In practice, however, you’ll need to convert not a single dictionary but a collection such as a list of dictionaries.
So let’s choose such an example. Say we have books, a list of dictionaries, where each dictionary holds information on a book. So each book record is in a Python dictionary with the following keys: title, author, publication_year, and genre.
When calling json.dumps(), we set the optional indent parameter—the indentation in the JSON string as it helps improve readability (yes, pretty printing json we are ??):
import json books = [ { "title": "The Great Gatsby", "author": "F. Scott Fitzgerald", "publication_year": 1925, "genre": "Fiction" }, { "title": "To Kill a Mockingbird", "author": "Harper Lee", "publication_year": 1960, "genre": "Fiction" }, { "title": "1984", "author": "George Orwell", "publication_year": 1949, "genre": "Fiction" } ] # Convert dictionary to JSON string json_string = json.dumps(books, indent=4) print(json_string)
When you run the above code, you should get a similar output:
Output >>> [ { "title": "The Great Gatsby", "author": "F. Scott Fitzgerald", "publication_year": 1925, "genre": "Fiction" }, { "title": "To Kill a Mockingbird", "author": "Harper Lee", "publication_year": 1960, "genre": "Fiction" }, { "title": "1984", "author": "George Orwell", "publication_year": 1949, "genre": "Fiction" } ]
Converting a Nested Python Dictionary to a JSON String
Next, let’s take a list of nested Python dictionaries and obtain the JSON representation of it. Let’s extend the books dictionary by adding a “reviews” key. Whose value is a list of dictionaries with each dictionary containing information on a review, namely, “user”, “rating”, and “comment”.
So we modify the books dictionary like so:
import json books = [ { "title": "The Great Gatsby", "author": "F. Scott Fitzgerald", "publication_year": 1925, "genre": "Fiction", "reviews": [ {"user": "Alice", "rating": 4, "comment": "Captivating story"}, {"user": "Bob", "rating": 5, "comment": "Enjoyed it!"} ] }, { "title": "To Kill a Mockingbird", "author": "Harper Lee", "publication_year": 1960, "genre": "Fiction", "reviews": [ {"user": "Charlie", "rating": 5, "comment": "A great read!"}, {"user": "David", "rating": 4, "comment": "Engaging narrative"} ] }, { "title": "1984", "author": "George Orwell", "publication_year": 1949, "genre": "Fiction", "reviews": [ {"user": "Emma", "rating": 5, "comment": "Orwell pulls it off well!"}, {"user": "Frank", "rating": 4, "comment": "Dystopian masterpiece"} ] } ] # Convert dictionary to JSON string json_string = json.dumps(books, indent=4) print(json_string)
Note that we use the same indent value of 4, and running the script gives the following output:
Output >>> [ { "title": "The Great Gatsby", "author": "F. Scott Fitzgerald", "publication_year": 1925, "genre": "Fiction", "reviews": [ { "user": "Alice", "rating": 4, "comment": "Captivating story" }, { "user": "Bob", "rating": 5, "comment": "Enjoyed it!" } ] }, { "title": "To Kill a Mockingbird", "author": "Harper Lee", "publication_year": 1960, "genre": "Fiction", "reviews": [ { "user": "Charlie", "rating": 5, "comment": "A great read!" }, { "user": "David", "rating": 4, "comment": "Engaging narrative" } ] }, { "title": "1984", "author": "George Orwell", "publication_year": 1949, "genre": "Fiction", "reviews": [ { "user": "Emma", "rating": 5, "comment": "Orwell pulls it off well!" }, { "user": "Frank", "rating": 4, "comment": "Dystopian masterpiece" } ] } ]
Sorting Keys When Converting a Python Dictionary to JSON
The dumps function has several optional parameters. We’ve already used one such optional parameter indent. Another useful parameter is sort_keys. This is especially helpful when you need to sort the keys of the Python dictionary when converting it to JSON
Because sort_keys is set to False by default, so you can set it to True if you need to sort the keys when converting to JSON.
Here’s a simple person dictionary:
import json person = { "name": "John Doe", "age": 30, "email": "john@example.com", "address": { "city": "New York", "zipcode": "10001", "street": "123 Main Street" } } # Convert dictionary to a JSON string with sorted keys json_string = json.dumps(person, sort_keys=True, indent=4) print(json_string)
As seen, the keys are sorted in alphabetical order:
Output >>> { "address": { "city": "New York", "street": "123 Main Street", "zipcode": "10001" }, "age": 30, "email": "john@example.com", "name": "John Doe" }
Handling Non-Serializable Data
In the examples we’ve coded so far, the keys and values of the dictionary are all JSON serializable. The values were all strings or integers to be specific. But this may not always be the case. Some common non-serializable data types include datetime, Decimal, and set.
No worries, though. You can handle such non-serializable data types by defining custom serialization functions for those data types. And then setting the default parameter of json.dumps() to the custom functions you define.
These custom serialization functions should convert the non-serializable data into a JSON-serializable format (who would’ve guessed!).
Here’s a simple data dictionary:
import json from datetime import datetime data = { "event": "Meeting", "date": datetime.now() } # Try converting dictionary to JSON json_string = json.dumps(data, indent=2) print(json_string)
We’ve used json.dumps() as before, so we’ll run into the following TypeError exception:
Traceback (most recent call last): File "/home/balapriya/djson/main.py", line 10, in json_string = json.dumps(data, indent=2) ^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/usr/lib/python3.11/json/__init__.py", line 238, in dumps **kw).encode(obj) ^^^^^^^^^^^ ... File "/usr/lib/python3.11/json/encoder.py", line 180, in default raise TypeError(f'Object of type {o.__class__.__name__} ' TypeError: Object of type datetime is not JSON serializable
The relevant part of the error is: Object of type datetime is not JSON serializable. Okay, now let’s do the following:
- Define a
serialize_datetime function that converts datetime objects to ISO 8601 format using the isoformat() method.
- When calling
json.dumps(), we set the default parameter to the serialize_datetime function.
So the code looks as follows:
import json from datetime import datetime # Define a custom serialization function for datetime objects def serialize_datetime(obj): if isinstance(obj, datetime): return obj.isoformat() data = { "event": "Meeting", "date": datetime.now() } # Convert dictionary to JSON # with custom serialization for datetime json_string = json.dumps(data, default=serialize_datetime, indent=2) print(json_string)
And here’s the output:
Output >>> { "event": "Meeting", "date": "2024-03-19T08:34:18.805971" }
Conclusion
And there you have it!
To recap: we went over converting a Python dictionary to JSON, and using the indent and sort_keys parameters as needed. We also learned how to handle JSON serialization errors.
You can find the code examples on GitHub. I’ll see you all in another tutorial. Until then, keep coding!
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.
More On This Topic
- How To Write Efficient Python Code: A Tutorial for Beginners
- How to Convert an RGB Image to Grayscale
- How to Use ChatGPT to Convert Text into a PowerPoint Presentation
- Convert Text Documents to a TF-IDF Matrix with tfidfvectorizer
- Text Summarization Development: A Python Tutorial with GPT-3.5
- Pydantic Tutorial: Data Validation in Python Made Simple