Large Language Models and Generative AI have demonstrated unprecedented success on a wide array of Natural Language Processing tasks. After conquering the NLP field, the next challenge for GenAI and LLM researchers is to explore how large language models can act autonomously in the real world with an extended generation gap from text to action, thus representing a significant paradigm in the pursuit of Artificial General Intelligence. Online games are considered to be a suitable test foundation to develop large language model embodied agents that interact with the visual environment in a way that a human would do.
For example, in a popular online simulation game Minecraft, decision making agents can be employed to assist the players in exploring the world along with developing skills for making tools and solving tasks. Another example of LLM agents interacting with the visual environment can be experienced in another online game, The Sims where agents have demonstrated remarkable success in social interactions and exhibit behavior that resembles humans. However, compared to existing games, tactical battle games might prove to be a better choice to benchmark the ability of large language models to play virtual games. The primary reason why tactical games make a better benchmark is because the win rate can be measured directly, and consistent opponents including human players and AI are always available.
Building on the same, POKELLMON, aims to be the world’s first embodied agent that achieves human-level performance on tactical games, similar to the one witnessed in Pokemon battles. At its core, the POKELLMON framework incorporates three main strategies.
- In-context reinforcement learning that consumes text-based feedback derived from battles instantaneously to refine the policy iteratively.
- Knowledge-augmented generation that retrieves external knowledge to counter hallucinations, enabling the agent to act properly and when it's needed.
- Consistent action generation to minimize the panic switching situation when the agent comes across a strong player, and wants to avoid facing them.
This article aims to cover the POKELLMON framework in depth, and we explore the mechanism, the methodology, the architecture of the framework along with its comparison with state of the art frameworks. We will also talk about how the POKELLMON framework demonstrates remarkable human-like battle strategies, and in-time decision making abilities, achieving a respectable win rate of almost 50%. So let’s get started.
POKELLMON: A Human Parity Agent with LLM for Pokemon Battles
The growth in the capabilities, and efficiency of Large Language Models, and Generative AI frameworks in the past few years has been nothing but marvelous, especially on NLP tasks. Recently, developers and AI researchers have been working on ways to make Generative AI and LLMs more prominent in real-world scenarios with the ability to act autonomously in the physical world. To achieve this autonomous performance in physical and real world situations, researchers and developers consider games to be a suitable test bed to develop LLM-embodied agents with the ability to interact with the virtual environment in a manner that resembles human behavior.
Previously, developers have tried to develop LLM-embodied agents on virtual simulation games like Minecraft and Sims, although it is believed that tactical games like Pokemon might be a better choice to develop these agents. Pokemon battles enables the developers to evaluate a trainer’s ability to battle in well-known Pokemon games, and offers several advantages over other tactical games. Since the action and state spaces are discrete, it can be translated into text without any loss. The following figure illustrates a typical Pokemon battle where the player is asked to generate an action to perform at each turn given the current state of the Pokemon from each side. The users have the option to choose from five different Pokemons and there are a total of four moves in the action space. Furthermore, the game helps in alleviating the stress on the inference time and inference costs for LLMs since the turn-based format eliminates the requirement for an intensive gameplay. As a result, the performance is dependent primarily on the reasoning ability of the large language model. Finally, although the Pokemon battle games appear to be simple, things are a bit more complex in reality and highly strategic. An experienced player does not randomly select a Pokemon for the battle, but takes various factors into consideration including type, stats, abilities, species, items, moves of the Pokemons, both on and off the battlefield. Furthermore, in a random battle, the Pokemons are selected randomly from a pool of over a thousand characters, each with their own set of distinct characters with reasoning ability and Pokemon knowledge.

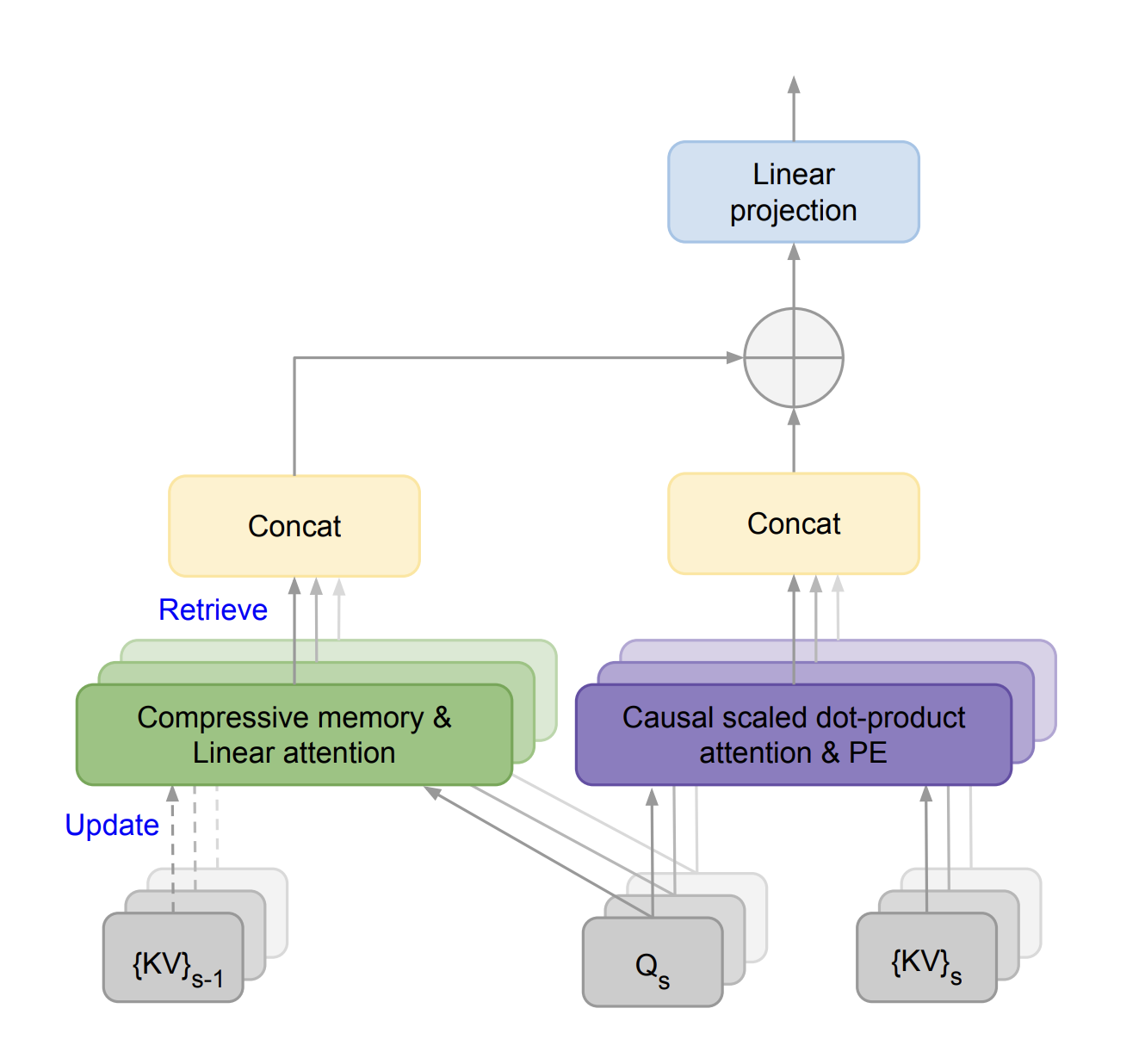
POKELLMON : Methodology and Architecture
The overall framework and architecture of the POKELLMON framework is illustrated in the following image.

During each turn, the POKELLMON framework uses previous actions, and its corresponding text-based feedback to refine the policy iteratively along with augmenting the current state information with external knowledge like ability/move effects or advantage/weakness relationship. For information given as input, the POKELLMON framework generates multiple actions independently, and then selects the most consistent ones as the final output.
In-Context Reinforcement Learning
Human players and athletes often make decisions not only on the basis of the current state, but they also reflect on the feedback from previous actions as well the experiences of other players. It would be safe to say that positive feedback is what helps a player learn from their mistakes, and refrains them from making the same mistake over and over again. Without proper feedback, the POKELLMON agents might stick to the same error action, as demonstrated in the following figure.

As it can be observed, the in-game agent uses a water-based move against a Pokemon character that has the “Dry Skin” ability, allowing it to nullify the damage against water-based attacks. The game tries to alert the user by flashing the message “Immune” on the screen that might prompt a human player to reconsider their actions, and change them, even without knowing about “Dry Skin”. However, it is not included in the state description for the agent, resulting in the agent making the same mistake again.
To ensure that the POKELLMON agent learns from its prior mistakes, the framework implements the In-Context Reinforcement Learning approach. Reinforcement learning is a popular approach in machine learning, and it helps developers with the refining policy since it requires numeric rewards to evaluate actions. Since large language models have the ability to interpret and understand language, text-based descriptions have emerged as a new form of reward for the LLMs. By including text-based feedback from the previous actions, the POKELLMON agent is able to iteratively and instantly refine its policy, namely the In-Context Reinforcement Learning. The POKELLMON framework develops four types of feedback,
- The actual damage caused by an attack move on the basis of the difference in HP over two consecutive turns.
- The effectiveness of attack moves. The feedback indicates the effectiveness of the attack in terms of having no effect or immune, ineffective, or super-effective due to ability/move effects, or type advantage.
- The priority order for executing a move. Since the precise stats for the opposing Pokemon character is not available, the priority order feedback provides a rough estimate of speed.
- The actual effect of the moves executed on the opponent. Both attack moves, and status might result in outcomes like recover HP, stat boost or debuffs, inflict conditions like freezing, burns or poison.

Furthermore, the use of the In-Context Reinforcement Learning approach results in significant boost in performance as demonstrated in the following figure.

When put against the original performance on GPT-4, the win rate shoots up by nearly 10% along with nearly 13% boost in the battle score. Furthermore, as demonstrated in the following figure, the agent begins to analyze and change its action if the moves executed in the previous moves were not able to match the expectations.

Knowledge-Augmented Generation or KAG
Although implementing In-Context Reinforcement Learning does help with hallucinations to an extent, it can still result in fatal consequences before the agent receives the feedback. For example, if the agent decides to battle against a fire-type Pokemon with a grass-type Pokemon, the former is likely to win in probably a single turn. To reduce hallucinations further, and improve the decision making ability of the agent, the POKELLMON framework implements the Knowledge-Augmented Generation or the KAG approach, a technique that employs external knowledge to augment generation.
Now, when the model generates the 4 types of feedback discussed above, it annotates the Pokemon moves and information allowing the agent to infer the type advantage relationship on its own. In an attempt to reduce the hallucination contained in reasoning further, the POKELLMON framework explicitly annotates the type advantage, and weakness of the opposing Pokemon, and the agent’s Pokemon with adequate descriptions. Furthermore, it is challenging to memorize the moves and abilities with distinct effects of Pokemons especially since there are a lot of them. The following table demonstrates the results of knowledge augmented generation. It is worth noting that by implementing the Knowledge Augmented Generation approach, the POKELLMON framework is able to increase the win rate by about 20% from existing 36% to 55%.

Furthermore, developers observed that when the agent was provided with external knowledge of Pokemons, it started to use special moves at the right time, as demonstrated in the following image.

Consistent Action Generation
Existing models demonstrate that implementing prompting and reasoning approaches can enhance the LLMs ability on solving complex tasks. Instead of generating a one-shot action, the POKELLMON framework evaluates existing prompting strategies including CoT or Chain of Thought, ToT or Tree of Thought, and Self Consistency. For Chain of Thought, the agent initially generates a thought that analyzes the current battle scenario, and outputs an action conditioned on the thought. For Self Consistency, the agent generates three times the actions, and selects the output that has received the maximum number of votes. Finally, for the Tree of Thought approach, the framework generates three actions just like in the self consistency approach, but picks the one it considers the best after evaluating them all by itself. The following table summarizes the performance of the prompting approaches.

There is only a single action for each turn, which implies that even if the agent decides to switch, and the opponent decides to attack, the switch-in Pokémon would take the damage. Normally the agent decides to switch because it wants to type-advantage switch an off-the-battle Pokémon, and thus the switching-in Pokémon can sustain the damage, since it was type-resistant to the opposing Pokémon’s moves . However, as above, for the agent with CoT reasoning, even if the powerful opposing Pokémon forces various rotates, it acts inconsistently with the mission, because it might not want to switch-in to the Pokemon but several Pokémon and back, which we term panic switching. Panic switching eliminates the chances to take moves, and thus defeats.
POKELLMON : Results and Experiments
Before we discuss the results, it is essential for us to understand the battle environment. At the beginning of a turn, the environment receives an action-request message from the server and will respond to this message at the end, which also contains the execution result from the last turn.
- First parses the message and updates local state variables, 2. then translates the state variables into text. The text description has mainly four parts: 1. Own team information, which contains the attributes of Pokémon in-the-field and off-the-field (unused).
- Opponent team information, which contains the attributes of opponent Pokémon in-the-field and off-the-field (some information is unknown).
- Battlefield information, which includes the weather, entry hazards, and terrain.
- Historical turn log information, which contains previous actions of both Pokémon and is stored in a log queue. LLMs take the translated state as input and output actions for the next step. The action is then sent to the server and executed at the same time as the action done by the human.
Battle Against Human Players
The following table illustrates the performance of the POKELLMON agent against human players.

As it can be observed, the POKELLMON agent delivers performance comparable to ladder players who have a higher win rate when compared to an invited player along with having extensive battle experience.
Battle Skill Analysis
The POKELLMON framework rarely makes a mistake at choosing the effective move, and switches to another suitable Pokemon owing to the Knowledge Augmented Generation strategy.

As shown in the above example, the agent uses only one Pokemon to defeat the entire opponent team since it is able to choose different attack moves, the ones that are most effective for the opponent in that situation. Furthermore, the POKELLMON framework also exhibits human-like attrition strategy. Some Pokemons have a “Toxic” move that can inflict additional damage at each turn, while the “Recover” move allows it to recover its HP. Taking advantage of the same, the agent first poisons the opposing Pokemon, and uses the Recover move to prevent itself from fainting.

Final Thoughts
In this article, we have talked about POKELLMON, an approach that enables large language models to play Pokemon battles against humans autonomously. POKELLMON, aims to be the world’s first embodied agent that achieves human-level performance on tactical games, similar to the one witnessed in Pokemon battles. The POKELLMON framework introduces three key strategies: In-Context Reinforcement Learning which consumes the text-based feedback as “reward” to iteratively refine the action generation policy without training, Knowledge-Augmented Generation that retrieves external knowledge to combat hallucination and ensures the agent act timely and properly, and Consistent Action Generation that prevents the panic switching issue when encountering powerful opponents.