

Earlier this year, Google released Gemma, a family of lightweight open-source language models developed by Google DeepMind and other teams across Google. Soon after its launch, many Indian developers experimented with it and built Indic LLMs like Tamil Gemma, Telugu Gemma, Hindi Gemma and many more.
“Gemma probably does a better job in Indic tokenisation than GPT-4 and Llama 3,” said Vivek Raghavan, co-founder of Sarvam AI, in an exclusive interview with AIM.
However, he added that Llama 3 has its own advantages. “I think Llama 3 looks quite good. There are many open models and we have a strategy where we leverage all of them,” he said.
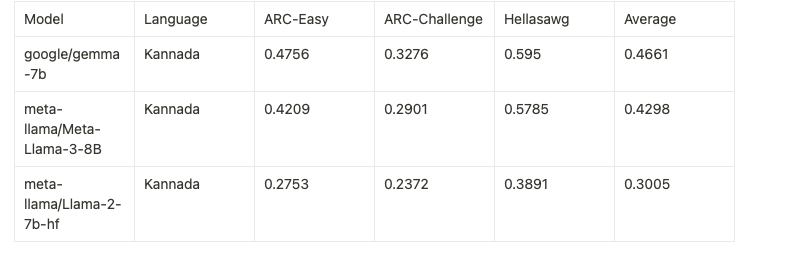
The thought was echoed by Adithya S Kolavi, founder of Cognitive Lab, who recently built a leaderboard for Indic LLMs. According to his leaderboard, Meta’s latest release, Llama 3, performs significantly better than Llama 2 on most benchmarks. However, compared to Gemma, it falls a little short. Gemma’s tokenization for Devanagari is efficient when compared to Llama 2.
Average eval scores for hindi
gemma-7b -> 0.550
llama3-8b -> 0.498
llama2-7b -> 0.309 https://t.co/cQCuB1W9od pic.twitter.com/Cfcf3Kzggm— Adithya S K (@adithya_s_k) April 20, 2024
“Models using Llama 2 extended its tokenizer by 20 to 30k tokens, reaching a vocabulary size of 50-60k. Continuous pre-training is crucial for understanding these new tokens. In contrast, Gemma’s tokenizer initially handles Indic languages well, requiring minimal fine-tuning for specific tasks,” said Kolavi.
Recently, Telugu LLM Labs also experimented with Gemma and released Telugu Gemma. “On a higher level, the Gemma tokenizer includes tokens for most Indian languages, providing strong representations for these tokens. In contrast, the Llama3 tokenizer supports only a few languages, and its quality of support is not as robust,” said Ravi Theja, founder of Telugu LLM Labs.
“Gemma features an exhaustive 256K tokenizer. A quick test of its tokenizing capabilities revealed that the models are exceptionally proficient in handling the Telugu language,” he added.
Similarly, OdiaGenAI released Hindi-Gemma-2B-instruct, a 2 billion SFT with 187k large instruction sets in Hindi. The company said the Gemma-2B was chosen as a base model due to 2B versions for CPU and on-device applications and efficient tokenisers on Indic languages compared to other LLMs.
“In comparative tests conducted by the OdiaGenAI team, the Gemma 7B model demonstrates superior performance over the Gemma 2B LLM model for Indic languages such as Odia,” shared Shantipriya Parida, the creator of Odia Llama.
Gemma Holds Advantage Over Llama 3
Llama 3 is pre-trained on over 15 trillion tokens collected from publicly available sources. Only 5% of the Llama 3 pre-training dataset consists of high-quality non-English data, covering over 30 languages, which amounts to 750 billion tokens.
“750 billion tokens are spread across 30 languages, and considering an equal distribution over all 30 languages, it comes out to be 25 billion tokens per non-English language. A language like Hindi is very rich, so I feel it’s grossly underrepresented in Llama 3,” said Adarsh Shirawalmath, founder of Tensoic and creator of Kannada Llama.
Llama 3 is a bit difficult when it comes to Indic LLMs “It’s going to be hard to adapt Llama 3 for Indic languages, in my opinion,” said Kolavi. Even though initial tests show better performance with Devanagari compared to Llama 2, it struggles with other languages like Kannada, Malayalam, and Tamil. More testing is needed to fully assess Llama 3’s performance with these languages.
He explained in his blog that Llama 3 uses a TikToken-based tokenizer, which struggles to efficiently tokenize Indic languages, even with a vocabulary size of 121k. Moreover, when it comes to vocabulary expansion, unlike models using sentence-piece tokenization as Gemma does, Llama 3 may face difficulties in expanding its vocabulary to better handle the wide variety of Indic languages.
Not all is Lost for Llama 3
“The environment around Llama 3 is really buzzing and a lot of experiments are being done whereas the same has plateaued for Gemma. While Gemma is better for Indic languages since it has a lot of Indic tokens in its 256k vocab size, it does not mean that it’s easier to work with. In fact, Gemma is really hard and unstable to work with,” said Shirawalmath.
He said that given the size of the embedding layer due to its huge vocab size, it’s really hard to train/finetune. Llama 3 on the other hand hits the sweet spot of 128k vocab size using the Tiktoken tokenizer but really lacks Indic tokens.
“There are some challenges, but they are all solvable depending upon what you do,” said Raghavan about Llama 3, where he and his team are currently experimenting to build an Indic voice LLM, which is expected to be launched in the coming months.
The post Why Google Gemma is Better than Meta’s Llama 3 for Indic LLMs appeared first on Analytics India Magazine.