This is the first in a series of articles based on interviews with the technical leaders and hands-on architects at Intel who are working behind the scenes to advance and democratize accelerated AI and its application — remarkably in a vendor-agnostic, open ecosystem, community-driven manner. These technologists have the AI knowledge and a mandate to leverage their knowledge, design capability, and deep reach into the datacenter to advance the state-of-the-art in AI computation. The follow-on articles will focus on individual technologies, their impact, and contributions by these Intel groups.
The 5th epoch
The current transition to AI and accelerated computing is considered the 5th epoch of distributed computing,[1] an epoch where we must challenge conventional wisdom so that programming models and network stacks can (and must) evolve to meet the productivity and efficiency goals of coming distributed systems. While some may think Moore’s Law is hitting the wall of performance per core, Intel’s Pat Gelsinger noted that “Even Gordon Moore, when he wrote his original paper on Moore’s law, saw this day of reckoning where we’ll need to build larger systems out of smaller functions, combining heterogeneous and customized solutions.” [2]
This 5th epoch is focused on machine learning where computational accelerators like GPUs are needed to provide arithmetic scalability (to an exaflop/s and beyond) to address workload requirements and interactive response for data-centric human-machine interactions. GPUs and alternative computational acceleration are only part of the story. Data is the foundation of machine learning. Performance, security, and power efficiency require that smart hardware accelerators be tasked with managing and protecting on-node data as well as moving data to computation and computation to data within a distributed data center. There is a high demand for high memory bandwidth to keep these accelerated platforms fed with data. The current technology implementation uses HBM2e on GPUs and CPUs (See CPU speedups below). With advanced packaging that can place heterogenous dies in a single processor packaging along with GPU technology, data providers can continue their transition to securely deliver planet-scale software services and exascale simulation capabilities. Thus, we enter the 5th epoch with a burgeoning hardware ecosystem that provides ubiquitous heterogeneous accelerated computing.
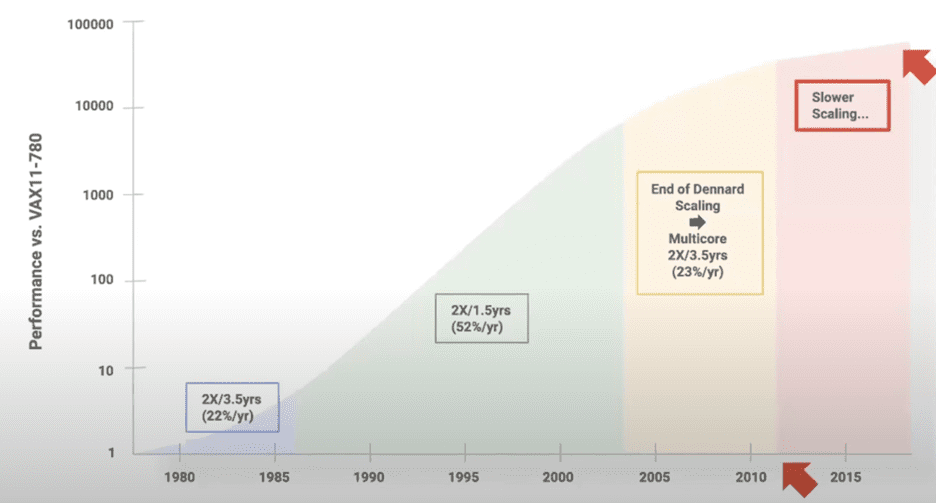
This rapid evolution and widespread deployment of accelerators powering the 5th epoch transition requires the creation of a software-defined infrastructure that fundamentally redefines how we build distributed systems. Industry trends demonstrate that accelerators are our friends (and path to the future) because a single general-purpose server architecture cannot generalize to all application needs (Figure 2). Domain- and application-specific accelerators will proliferate because they can deliver significant efficiency improvements beyond what is possible with general-purpose hardware. [4]
Joe Curley (vice president and general manager – Intel Software Products and Ecosystem), put the Intel efforts in perspective: “In facing workloads like HPC and AI,” he noted, “some hardware devices are more optimal than others. What I love about HPC and AI is that we have melded brick-and-mortar testing with software and moved it to the computer. Simulations now give us insights that were not previously obtainable in weather simulation, high energy physics, and computer manufacturing, plus addressing an exponential societal infrastructure demand [5] and numerous other datacenter workloads that have tremendous societal and commercial impacts. With hardware accelerators, we can optimize critical path operations to get answers faster while consuming less power, two very desirable outcomes, but accelerators require an appropriate software ecosystem. Creating this ecosystem requires a community effort given the portability needs of our customers combined with the breadth and rapid adoption of AI.”
“With hardware accelerators, we can optimize critical path operations to get answers faster while consuming less power, two very desirable outcomes, but accelerators require an appropriate software ecosystem. Creating this ecosystem requires a community effort given the portability needs of our customers combined with the breadth and rapid adoption of AI.” — Joe Curley
Even greater speedups using AI-enabled HPC
The HPC community is currently experiencing a surge in the adoption of machine learning in scientific computing. The forthcoming 2+ exaflop/s (performing double-precision arithmetic) Aurora supercomputer, for example, is being built in collaboration with Intel and Hewlett Packard Enterprise using Intel Xeon CPU Max Series and Intel Data Center GPU Max Series. One of Aurora’s distinguishing features will be its ability to seamlessly integrate the important scientific tools of data analysis, modeling and simulation, and artificial intelligence.[6]
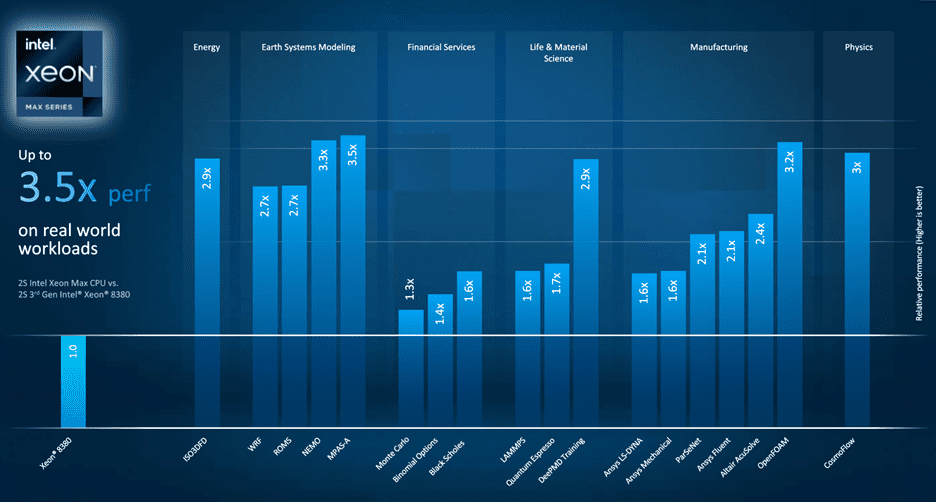
AI-accelerated HPC was the theme of the special presentation at ISC’23 by Jeff McVeigh, Intel GM of the Super Compute Group. He presented data on Max Series GPU performance on AI-accelerated HPC applications and Intel efforts to address the “boom” in AI and scientific computing (Figure 3). Ansys CTO Prith Banerjee also shared a real-world example of the Max Series GPU at ISC’23 running over 50% faster than the competition on both the inference and training components of CoMLSim, a code that uses AI to accelerate fluid dynamics problems. [7]

Language processing AI models illustrate the power of an accelerator hierarchy
ChatGPT is currently one of the most popularly recognizable generative AI models, but it is just the tip of the iceberg in a remarkable explosion in language-processing AI models. These models are capable of generating human-like prose, programs, and more. These language models are huge, with parameter counts in the trillions.[8]
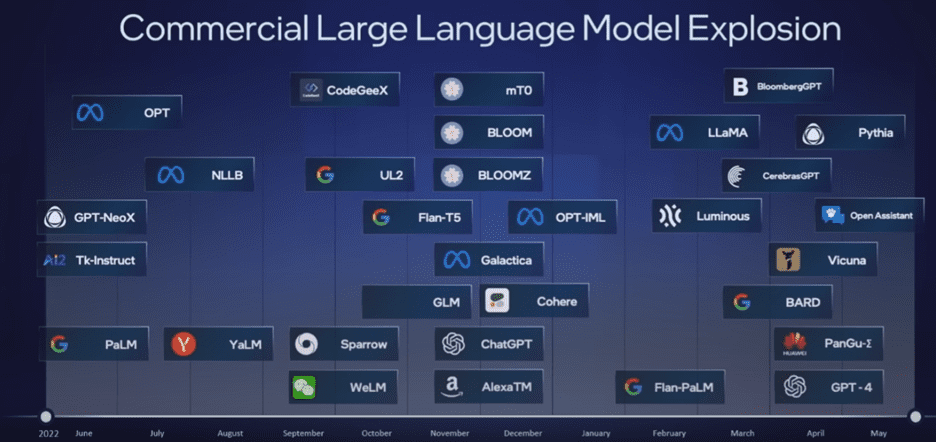
Emphasizing this trend, Argonne National Laboratory announced plans at ISC’23 to create generative AI models for the scientific research community, in collaboration with Intel and HPE.
“The project aims to leverage the Aurora supercomputer to produce a resource that can be used for downstream science at the Department of Energy labs and in collaboration with others,” said Rick Stevens, Argonne associate laboratory director.
These generative AI models for science will be trained on general text, code, scientific texts and structured scientific data from biology, chemistry, materials science, physics, medicine and other sources.
The resulting models (which are huge and can contain trillions of parameters) will be used in a variety of scientific applications, from the design of molecules and materials to the synthesis of knowledge across millions of sources to suggest new and interesting experiments in systems biology, polymer chemistry and energy materials, climate science and cosmology. The model will also be used to accelerate the identification of biological processes related to cancer and other diseases and suggest targets for drug design.
Argonne is one member in an international collaboration to advance the generative AI project, including Intel, HPE; Department of Energy laboratories, U.S. and international universities, nonprofits, and international partners, such as RIKEN.
A hierarchy of accelerators
Argonne is, of course, a premier institution for working with such models on the latest hardware including the Aurora exascale supercomputer. Democratizing AI requires enabling a mass audience with accelerated computing devices at a variety of price/performance tiers. Hence the need for an accelerator hierarchy.
For dedicated accelerated training of AI models containing enormous numbers of parameters, Sree Ganesan (product management head of software at Habana), noted that huge amounts of memory are needed. He noted that with 96GB of HBM2e memory, the new GAUDI2 processor is designed for many aspects of enabling deep learning on such massive models. The GAUDI deep learning training and inference processors provide an alternative to GPUs for dedicated deep-learning workloads.
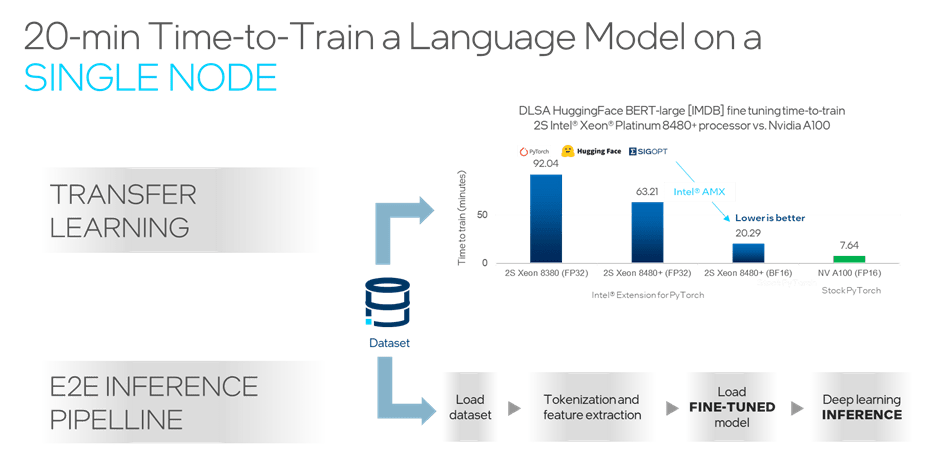
General-purpose CPUs and GPUs can also support the training and inference of even such large AI models. Bundling all this under the umbrella of “universal AI”, Pradeep Dubey (Senior Fellow and Parallel Computing Lab Director at Intel) believes the latest 4th Gen Intel Xeon processors can support the workflow for many AI users without leaving the CPU.. This “fast enough to stay on the CPU” claim is backed up by benchmarks such as training a Bidirectional Encoder Representations from Transformers (BERT) language model (Figure 5) on a single Intel® Xeon® Platinum 8480+ 2S node in 20 minutes.
Fine tuning a natural language model took less than four minutes (Figure 6).
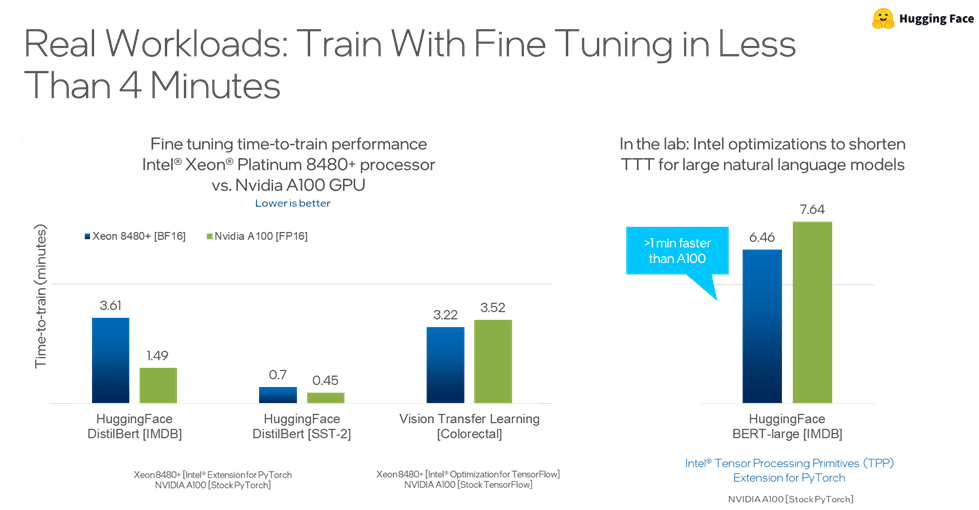
This performance leveraged the accelerators in the 4th Gen Intel Xeon processors such as the Intel® Advanced Matrix Extensions (Intel® AMX) and the Intel® Data Streaming Accelerator (Intel® DSA).
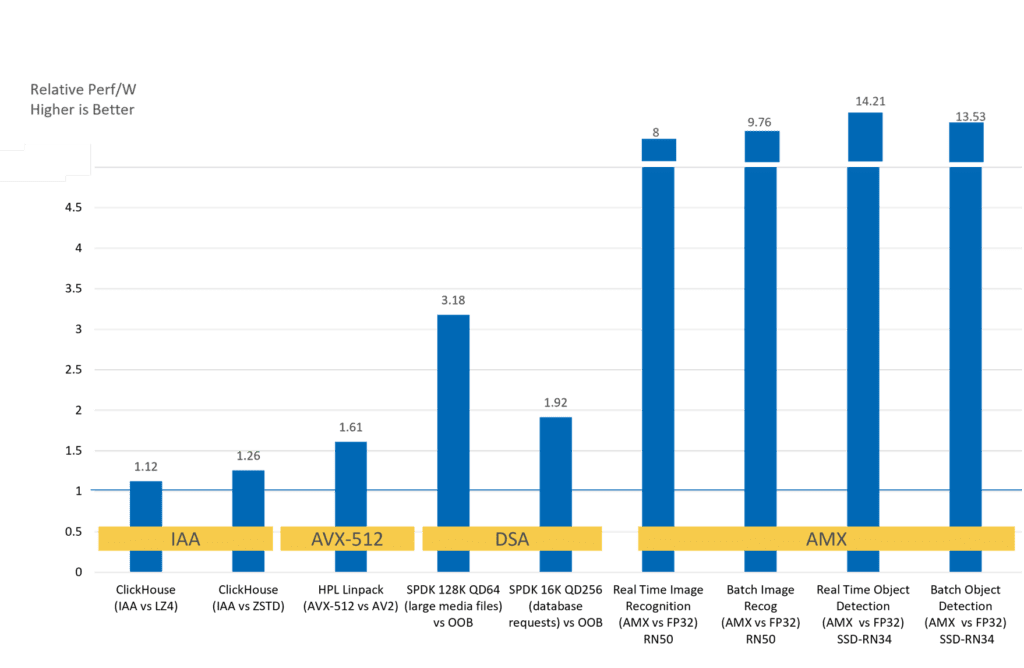
- Intel AMX: Intel AMX delivers 3× to 10× higher inference and training performance versus the previous generation on AI workloads that use bint8 and bfloat16 matrix operations. [9] [10]
- Intel DSA: Benchmarks for Intel DSA vary according to workload and operation performed. Speedups include faster AI training by having the DSA zero memory in the kernel, increased IOP/s/core by offloading CRC generation during storage operations, and of course, MPI speedups that include higher throughput for shmem data copies. For example, Intel quotes a 1.7× increase in IOP/s rate for large sequential packet reads when using DSA compared to using the Intel® Intelligent Storage Acceleration Library without DSA.[11]
Along with increased application performance, acceleration can also deliver dramatic power benefits. Maximizing performance for every watt of power consumed is a major concern at HPC and cloud data centers around the world. Comparing the relative performance per watt on a 4th Gen Intel Xeon processor running accelerated vs. nonaccelerated software shows a significant performance per watt benefit — especially for Intel AMX accelerated workloads.
From big AI models to small, accelerators make the difference
Stephen Gillich (director AI and technical computing Intel) summarized the breadth of the Intel acceleration efforts “From big problems to small, Intel has optimized architectures for a full range of AI and HPC applications. HPC has high-precision requirements while AI is able to use lower-precision numerical representations such as bfloat16. Thus, different architectures and numerical resolution apply to a hierarchy of problems: Dedicated deep learning workloads can run on the Habana devices, while general-purpose GPUs and CPUs with accelerators speed general-purpose AI and HPC workloads.”
Summary
Advanced packaging and accelerators now empower hardware designers in ways that simply were not previously possible. These optimized designs are bringing about the 5th epoch in computing along with AI-enabled planet scale software services and a revolution in exascale-capable HPC simulation capabilities. They have also created a combinatorial software support problem. Programmers cannot anticipate — nor can they test and verify across — all heterogenous and accelerated computing environments in which their codes will run. The only solution out of this conundrum is to create a vendor-agnostic, free-to-all, flexible, open source, community software defined infrastructure such as the Intel oneAPI software ecosystem and the efforts to democratize AI.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology.
[1] Tim Mattson, senior principal engineer at Intel believes the sixth generation will start around 2025 with software defined ‘everything’ and be limited by the speed of light: https://www.youtube.com/watch?v=SdJ-d7m0z1I.
[2] https://www.theregister.com/2022/09/28/intel_chiplets_advanced_packaging/
[3] LAMMPS (Atomic Fluid, Copper, DPD, Liquid_crystal, Polyethylene, Protein, Stillinger-Weber, Tersoff, Water)
Intel® Xeon® 8380: Test by Intel as of 10/11/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:on; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=high;
Intel® Xeon® 8480+: Test by Intel as of 9/29/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Total Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:off; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=high;
Intel® Xeon® Max 9480: Test by Intel as of 9/29/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:off; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=high;
DeePMD (Multi-Instance Training)
Intel® Xeon® 8380: Test by Intel as of 10/20/2022. 1-node, 2x Intel® Xeon® 8380 processor, Total Memory 256 GB, kernel 4.18.0-372.26.1.eI8_6.crt1.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
3.9
Intel® Xeon® 8480+: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, Total Memory 512 GB, kernel 4.18.0-365.eI8_3x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
Intel® Xeon® Max 9480: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, Total Memory 128 GB (HBM2e at 3200 MHz), kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-13), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
Quantum Espresso (AUSURF112, Water_EXX)
Intel® Xeon® 8380: Test by Intel as of 9/30/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, Quantum Espresso 7.0, AUSURF112, Water_EXX
Intel® Xeon® 8480+: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), ucode revision= 0x90000c0, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, Quantum Espresso 7.0, AUSURF112, Water_EXX
Intel® Xeon® Max 9480: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Total Memory 128 GB (8x16GB HBM2 3200MT/s), ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, Quantum Espresso 7.0, AUSURF112, Water_EXX
ParSeNet (SplineNet)
Intel® Xeon® 8380: Test by Intel as of 10/18/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.6, Linux version 4.18.0-372.19.1.el8_6.crt1.x86_64, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
Intel® Xeon® 8480+: Test by Intel as of 10/18/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode revision=0xaa0000a0, CentOS Stream 8, Linux version 4.18.0-365.el8.x86_64, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
Intel® Xeon® Max 9480: Test by Intel as of 09/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Total Memory 128 GB (8x16GB HBM2 3200MT/s), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
CosmoFlow (training on 8192 image batches)
3rd Gen Intel® Xeon® Scalable Processor 8380 : Test by Intel as of 06/07/2022. 1-node, 2x Intel® Xeon® Scalable Processor 8380, 40 cores, HT On, Turbo On, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Red Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, Tensorflow 2.9.0, horovod 0.23.0, keras 2.6.0, oneCCL-2021.4, oneAPI MPI 2021.4.0, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® 8480+ (AVX-512 FP32): Test by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Xeon 8480+, HT On, Turbo On, Total Memory 512 GB (16 slots/ 32 GB/ 4800 MHz, DDR5), BIOS EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel 4.18.0-365.el8.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, Tensorflow 2.6.0, horovod 0.23, keras 2.6.0, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® Processor Max Series HBM (AVX-512 FP32): Test by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, Total Memory 128 HBM and 512 GB DDR (16 slots/ 32 GB/ 4800 MHz), BIOS SE5C7411.86B.8424.D03.2208100444, ucode 0x2c000020, CentOS Stream 8, kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, TensorFlow 2.6.0, horovod 0.23.0, keras 2.6.0, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® 8480+ (AMX BF16): Test by Intel as of 10/18/2022. 1node, 2x Intel® Xeon® Platinum 8480+, HT On, Turbo On, Total Memory 512 GB (16 slots/ 32 GB/ 4800 MHz, DDR5), BIOS EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel 4.18.0-365.el8.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AMX, BF16, Tensorflow 2.9.1, horovod 0.24.3, keras 2.9.0.dev2022021708, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® Max 9480 (AMX BF16): Test by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, Total Memory 128 HBM and 512 GB DDR (16 slots/ 32 GB/ 4800 MHz), BIOS SE5C7411.86B.8424.D03.2208100444, ucode 0x2c000020, CentOS Stream 8, kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AMX, BF16, TensorFlow 2.9.1, horovod 0.24.0, keras 2.9.0.dev2022021708, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.9
DeepCAM
Intel® Xeon® Scalable Processor 8380: Test by Intel as of 04/07/2022. 1-node, 2x Intel® Xeon® 8380 processor, HT On, Turbo Off, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Red Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-4), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
Intel® Xeon® Max 9480 (Cache Mode) AVX-512: Test by Intel as of 05/25/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On,Turbo Off, Total Memory 128GB HBM and 1TB (16 slots/ 64 GB/ 4800 MHz, DDR5), Cluster Mode: SNC4, BIOS EGSDCRB1.86B.0080.D05.2205081330, ucode 0x8f000320, OS CentOS Stream 8, kernel 5.18.0-0523.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10, https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, AVX-512, FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
Intel® Xeon® Max 9480 (Cache Mode) BF16/AMX: Test by Intel as of 05/25/2022. 1-node, 2x Intel® Xeon® Max 9480 , HT On, Turbo Off, Total Memory 128GB HBM and 1TB (16 slots/ 64 GB/ 4800 MHz, DDR5), Cluster Mode: SNC4, BIOS EGSDCRB1.86B.0080.D05.2205081330, ucode 0x8f000320, OS CentOS Stream 8, kernel 5.18.0-0523.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, AVX-512 FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512, AMX, BFloat16 Enabled), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
Intel® Xeon® 8480+s Mulit-Node cluster: Test by Intel as of 04/09/2022. 16-nodes Cluster, 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 256 GB (16 slots/ 16 GB/ 4800 MHz, DDR5), BIOS Intel SE5C6301.86B.6712.D23.2111241351, ucode 0x8d000360, OS Red Hat Enterprise Linux 8.4 (Ootpa), kernel 4.18.0-305.el8.x86_64, compiler gcc (GCC) 8.4.1 20200928 (Red Hat 8.4.1-1), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98 AVX-512, FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=4, LBS=16, ~1024GB data, 16 epochs, Python3.8
WRF4.4 – CONUS-2.5km
Intel Xeon 8360Y: Test by Intel as of 2/9/23, 2x Intel Xeon 8360Y, HT On, Turbo On, NUMA configuration SNC2, 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, WRF v4.4 built with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags ”-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Fabric
Intel Xeon 8480+: Test by Intel as of 2/9/23, 2x Intel Xeon 8480+, HT On, Turbo On, NUMA configuration SNC4, 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, WRF v4.4 built with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Fabric
Intel Xeon Max 9480: Test by Intel as of 2/9/23, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, 128 GB HBM2e at 3200 MHz and 512 GB DDR5-4800, BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, WRF v4.4 built with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Fabric
ROMS (benchmark3 (2048x256x30), benchmark3 (8192x256x30))
Intel® Xeon® 8380: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, ROMS V4 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=high -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
Intel® Xeon® 8480+: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, NUMA configuration SNC4, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, ROMS V4 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=high -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
Intel® Xeon® Max 9480: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, ROMS V4 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=high -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
NEMO (GYRE_PISCES_25, BENCH ORCA-1)
Intel® Xeon® 8380: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, NEMO v4.2 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags ”-i4 -r8 -O3 -fno-alias -march=core-avx2 -fp-model fast=2 -no-prec-div -no-prec-sqrt -align array64byte -fimf-use-svml=true”
Intel® Xeon® Max 9480: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, NEMO v4.2 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-i4 -r8 -O3 -fno-alias -march=core-avx2 -fp-model fast=2 -no-prec-div -no-prec-sqrt -align array64byte -fimf-use-svml=true”.
Ansys Fluent
Intel Xeon 8380: Test by Intel as of 08/24/2022, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Hemisphere, 256 GB DDR4-3200, BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode 0xd000375, Rocky Linux 8.7, kernel version 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1 . HDR Fabric
Intel Xeon 8480+: Test by Intel as of 2/11/2023, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4 Mode, 512 GB DDR5-4800, BIOS Version SE5C7411.86B.8901.D03.2210131232, ucode 0x2b0000a1, Rocky Linux 8.7, kernel version 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1. HDR Fabric
Intel Xeon Max 9480: Test by Intel as of 02/15/2023, 2x Intel Xeon Max 9480, HT ON, Turbo ON, SNC4, SNC4 and Fake Numa for Cache Mode runs, 128 GB HBM2e at 3200 MHz and 512 GB DDR5-4800, BIOS Version SE5C7411.86B.9409.D04.2212261349, ucode 0xac000100, Rocky Linux 8.7, kernel version 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1. HDR Fabric
Ansys LS-DYNA (ODB-10M)
Intel® Xeon® 8380: Test by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s DDR4), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LS-DYNA R11
Intel® Xeon® 8480+: Test by Intel as of ww41’22. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Total Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LS-DYNA R11
Intel® Xeon® Max 9480: Test by Intel as of ww36’22. 1-node, 2x Intel® Xeon® Max 9480, HT
Ansys Mechanical (V22iter-1, V22iter-2, V22iter-3, V22iter-4, V22direct-1, V22direct-2, V22direct-3)
Intel® Xeon® 8380: Test by Intel as of 08/24/2022. 1-node, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Quad, Total Memory 256 GB, BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Mechanical 2022 R2
AMD EPYC 7763: Test by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7763, HT On, Turbo On, NPS2,Total Memory 512 GB, BIOS ver. Ver 2.1 Rev 5.22, ucode 0xa001144, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Mechanical 2022 R2
AMD EPYC 7773X: Test by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7773X, HT On, Turbo On, NPS4,Total Memory 512 GB, BIOS ver. M10, ucode 0xa001229, CentOS Stream 8, kernel version 4.18.0-383.el8.x86_6, Ansys Mechanical 2022 R2
Intel® Xeon® 8480+: Test by Intel as of 09/02/2022. 1-node, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4, Total Memory 512 GB DDR5 4800 MT/s, BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel version 4.18.0-365.el8.x86_64, Ansys Mechanical 2022 R2
Intel® Xeon® Max 9480: Test by Intel as of 08/31/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo ON, SNC4, Total Memory 512 GB DDR5 4800 MT/s, 128 GB HBM in Cache Mode (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode 2c000020, CentOS Stream 8, kernel version 5.19.0-rc6.0712.intel_next.1.x86_64+server, Ansys Mechanical 2022 R2
Altair AcuSolve (HQ Model)
Intel® Xeon® 8380: Test by Intel as of 09/28/2022. 1-node, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Quad, Total Memory 256 GB, BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Altair AcuSolve 2021R2
Intel® Xeon® 6346: Test by Intel as of 10/08/2022. 4-nodes connected via HDR-200, 2x Intel® Xeon® 6346, 16 cores, HT ON, Turbo ON, Quad, Total Memory 256 GB, BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Altair AcuSolve 2021R2
Intel® Xeon® 8480+: Test by Intel as of 09/28/2022. 1-node, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4, Total Memory 512 GB, BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel version 4.18.0-365.el8.x86_64, Altair AcuSove 2021R2
Intel® Xeon® Max 9480: Test by Intel as of 10/03/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode 2c000020, CentOS Stream 8, kernel version 5.19.0-rc6.0712.intel_next.1.x86_64+server, Altair AcuSolve 2021R2
OpenFOAM (Geomean of Motorbike 20M, Motorbike 42M)
Intel® Xeon® 8380: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.6, Linux version 4.18.0-372.19.1.el8_6.crt1.x86_64, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
Intel® Xeon® 8480+: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode revision=0xaa0000a0, CentOS Stream 8, Linux version 4.18.0-365.el8.x86_64, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
Intel® Xeon® Max 9480: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Total Memory 128 GB (8x16GB HBM2 3200MT/s), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
MPAS-A (MPAS-A V7.3 60-km dynamical core)
Intel® Xeon® 8380: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, MPAS-A V7.3 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
Intel® Xeon® 8480+: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, NUMA configuration SNC4, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, MPAS-A V7.3 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
Intel® Xeon® Max 9480: Test by Intel as of 10/12/22. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, MPAS-A V7.3 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
GROMACS (benchMEM, benchPEP, benchPEP-h, benchRIB, hecbiosim-3m, hecbiosim-465k, hecbiosim-61k, ion_channel_pme_large, lignocellulose_rf_large, rnase_cubic, stmv, water1.5M_pme_large, water1.5M_rf_large)
Intel® Xeon® 8380: Test by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, Converge GROMACS v2021.4_SP
Intel® Xeon® 8480+: Test by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Total Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, GROMACS v2021.4_SP
Intel® Xeon® Max 9480: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, GROMACS v2021.4_SP
[4] SIGCOMM keynote, Amin Vadhat, 5th Epoch of Distributed Computing.
[5] SIGCOMM keynote, Amin Vadhat, 5th Epoch of Distributed Computing.
[6] https://www.anl.gov/aurora
[7] https://youtu.be/XVcKLetqf3U?t=1402
[8] https://www.forbes.com/sites/bernardmarr/2023/02/24/gpt-4-is-coming–what-we-know-so-far/?sh=783365516c2d
[9] https://www.nextplatform.com/2023/01/16/application-acceleration-for-the-masses/.
[10] https://www.intel.com/content/www/us/en/newsroom/news/4th-gen-xeon-scalable-processors-max-series-cpus-gpus.html .
[11] See [N18] at http://intel.com/processorclaims : 4th Gen Intel® Xeon® Scalable processors. Results may vary.
[12]See slide 8 in https://www.colfax-intl.com/downloads/Public-Accelerators-Deep-Dive-Presentation-Intel-DSA.pdf.
{kind=link}