

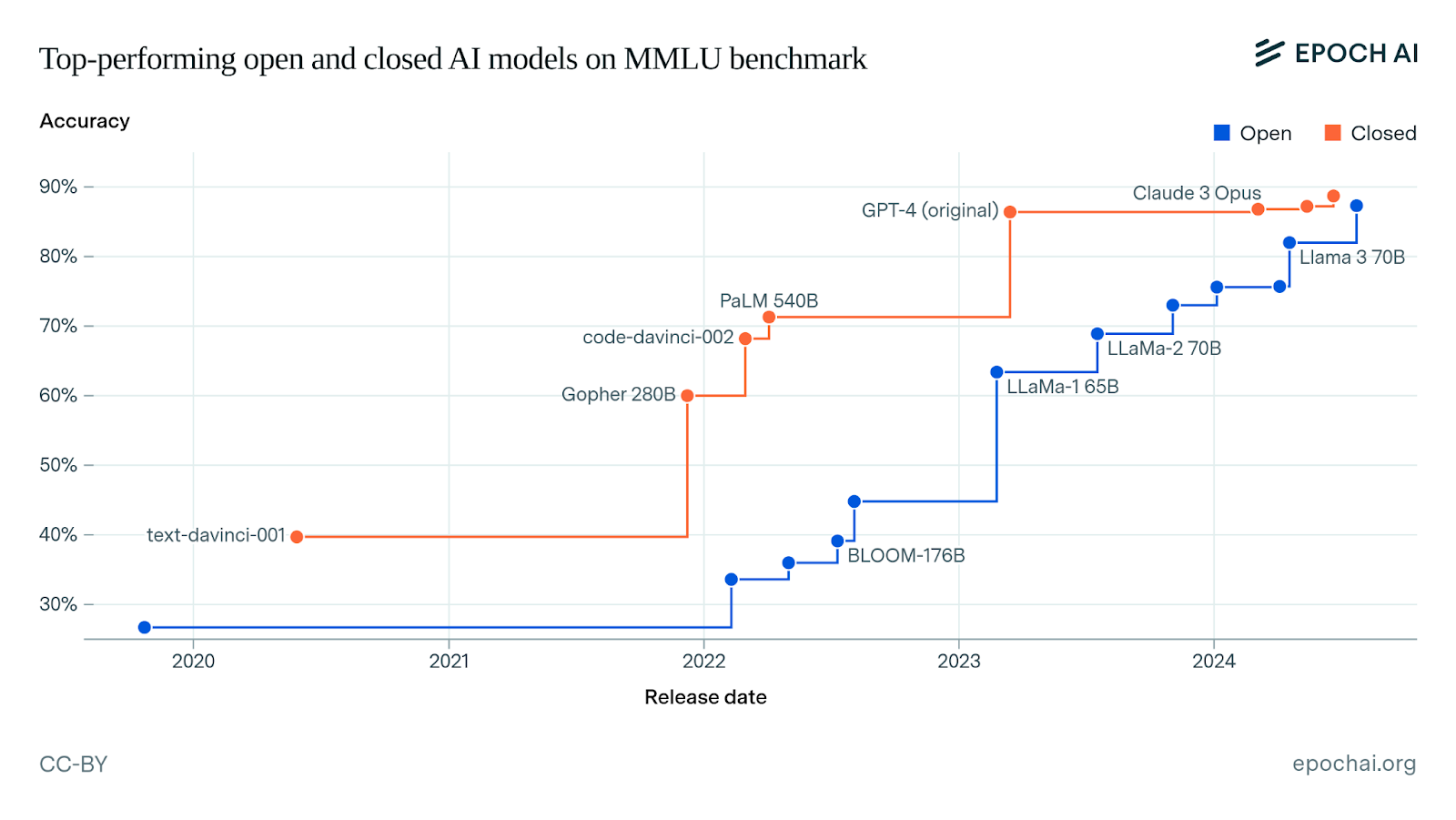
The gap between open and closed-source models is blurring. According to a recent study published by research group Epoch AI—‘How Far Behind Are Open Models?’—the best open-source large language models (LLMs) have lagged behind the best closed-source LLMs by five to 22 months in terms of benchmark performance.
“Meta’s Llama 3.1 405B is the most recent open model to close the gap across multiple benchmarks. The results are similar when we exclude Meta’s Llama models,” the report states.
Meanwhile, Meta’s chief AI scientist Yann LeCun said on LinkedIn, “In the future, our entire information diet is going to be mediated by [AI] systems. They will constitute basically the repository of all human knowledge. And you cannot have this kind of dependency on a proprietary, closed system.”
It is evident that the AI chatbot market is highly competitive. For instance, ChatGPT, which operates using closed models has around 350 million monthly users, while Meta’s AI assistant, utilising open models, has close to 500 million monthly users.
The report presents ample evidence for comparing the capabilities of open and closed AI models over time. It has systematically collected data on the availability of model weights and training codes for hundreds of AI models released since 2018, which are now available in the Notable AI Models database.
Soon, Llama will Surpass
Meta’s Llama models are pushing towards autonomous machine intelligence with advancements in real-time reasoning and adaptability.
As Manohar Paluri, VP of AI at Meta, told AIM, future Llama versions aim to “know that they’re on the right track and backtrack if needed”, enhancing complex problem-solving by combining perception, reasoning, and planning.
Leveraging self-supervised learning (SSL) for broad knowledge acquisition and reinforcement learning with human feedback (RLHF) for task-specific alignment, Llama also excels in synthetic data generation for underserved languages, making it ideal for multilingual applications.
Earlier this year, after Llama 3.1 was leaked, Meta officially released Llama 3.1 405B, a new frontier-level open-source AI model, alongside its 70B and 8B versions. Meta is offering developers free access to its weights and codes, and enabling fine-tuning, distillation, and deployment.
Our Llama 3.1 405B is now openly available! After a year of dedicated effort, from project planning to launch reviews, we are thrilled to open-source the Llama 3 herd of models and share our findings through the paper:
Llama 3.1 405B, continuously trained with a 128K context… pic.twitter.com/RwhedAluSM
— Aston Zhang (@astonzhangAZ) July 23, 2024
The Llama 3.1 405B model performs on par with the best closed-source models. It supports a context length of 128k and eight languages and offers robust capabilities in code generation, complex reasoning, and tool use.
“Meta AI is on track to reach our goal of becoming the most used AI assistant in the world by the end of the year,” said Meta chief Mark Zuckerberg.
“Today, several tech companies are developing leading closed models. But open source is quickly closing the gap. Last year, Llama 2 was only comparable to an older generation of models behind the frontier. This year, Llama 3 is competitive with the most advanced models and leading in some areas,” he further said.
Zuckerberg has predicted that, starting next year, future Llama models will become the most advanced in the industry.
Furthermore, the launch of Llama 3.2 also enhanced edge AI and vision tasks, offering both small and medium vision LLMs (11B and 90B) and lightweight models (1B and 3B) optimised for on-device use, with robust support for Qualcomm and MediaTek hardware.
“Llama 3.2 models bring SOTA capabilities to developers without the need for extensive resources, enabling innovation and breakthroughs directly on edge and mobile devices,” Zuckerberg added.

Interestingly, Llama 3.2 claimed to beat all closed-source models on vision, including Claude 3 Haiku and GPT-4o-mini.
What are the Findings?
“In terms of training compute, the largest open models have lagged behind the largest closed models by about 15 months,” the report has found.
It further highlighted that the release of Llama 3.1 405B relative to GPT-4 is consistent with this lag, at 16 months.
According to benchmarks, Llama 3.1 outperforms OpenAI’s GPT-4o in categories such as general knowledge, reasoning, reading comprehension, code generation, and multilingual capabilities. “Open-source is about to be SOTA (state-of-the-art) — even the 70B is > GPT-4o, and this is before instruct tuning, which should make it even better,” wrote an X user.
However, the report mentioned that closed models are outperforming not only in accuracy benchmarks but also in user preference rankings.
“In leaderboards based on human preferences between models, such as LMSYS Chatbot Arena and SEAL Coding, closed models such as OpenAI’s o1 and Google DeepMind’s Gemini 1.5 Pro outrank open models such as Llama 3.1 405B and DeepSeek-V2.5,” it added.
The analysis of benchmark performance and training compute shows that on the GPQA benchmark, open models lag by about five months, shorter than the 16-25 month lag seen on MMLU.
“The lag on MMLU, GSM1k and BBH is also shorter at higher levels of accuracy, which were achieved more recently. This weakly suggests that the lag of open models has shortened in the past year,” the findings revealed.
However, Meta aims for Llama 4 to be the “most advanced model in the industry next year”, requiring nearly 10 times more compute than Llama 3.
With Llama 3.1, Meta has made it clear that their focus spans the entire LLM market, regardless of size.
Rumours suggest Meta has already begun training Llama 4, which is expected to be multimodal with audio features, integrated into the Meta Ray-Ban glasses.
Llama is Not Alone
Small language models have gained popularity over the past few months, and they can greatly help with several applications that do not demand high output accuracy.
With further research and development focusing on improving the performance of SLMs and optimising LLMs, will we reach a point where standard large parameter models seem redundant for most applications?
Meta’s quantised models, Microsoft’s Phi, HuggingFace’s SmolLM and OpenAI’s GPT Mini indicate strong efforts to build efficient, and small-sized models. The Indian AI ecosystem was quick to turn towards SLMs as well. Recently, Infosys and Saravam AI collaborated to develop small language models for banking and IT applications.
Soon, we’ll certainly see a rising interest in techniques and frameworks that optimise LLMs.
The study stated that in terms of training compute, the top-1 open models have scaled at a similar pace to the top-1 closed models, at 4.6x/year for the past five years. This suggests that the lag of open models will remain stable rather than shorten.
Meanwhile, looking at a broader set of models—the top-10—open models have scaled at 3.6x/year, slower than closed models at 5.0x/year. This suggests a growing lag for this broader set of open models.
Expectations
However, Ilya Sutskever, co-founder and chief scientist (former) at OpenAI once stated that the gap between open-source and private AI models may continue to increase.
“This is because:
• Small teams develop open-source models less frequently
• Advanced neural networks need more engineering.”
The report however, highlights the trend in Meta’s open Llama models and states that they “expect the lag between the best open and closed models to shorten next year”.
“On historical trends alone, the evidence for how the lag will change is mixed,” the report further added.
The report attributed the prevalence of notable open models to the significant growth in the overall number of open models. The model hosting platform HuggingFace, founded in 2016, currently hosts over 1 million open models.
Additionally, CodeGPT mentioned on X, “Since launching in March of last year, @codegptAI has been downloaded over 1.4M times with users in 180+ countries. It’s one of the top players in the AI for developers space and Llama models have been a big part of that.”
As a matter of fact,in the 2023 earnings call, NVIDIA chief Jensen Huang noted that everyone would be able to code, “you just have to say something to the computer”. Without learning how to code, even kids can do it with the help of low-code or no-code platforms.
For example, many of the current Indian language models such as Kannada Llama, or MalayaLLM, or Telugu Llama, have been created by college students, still in the second-year of their degree course. Without undermining their achievements, it is essential to note that the barrier to entry for training these models has become increasingly low.
The post The Gap Between Open and Closed AI Models Is Closing Faster Than Expected appeared first on Analytics India Magazine.