

Stability AI Releases Stable Diffusion 3.5 Text-to-Image AI Model
Snippet: The Stable Diffusion 3.5 allows users to easily fine-tune the model for specific creative projects or build custom workflows
Stability AI has introduced Stable Diffusion 3.5 which includes multiple model variants. These models are capable of running on consumer-grade hardware and are available for both commercial and non-commercial use under the flexible Stability AI Community License.
Developers now can customise and integrate the models without worrying about restrictive licensing, making them ideal for a wide range of applications.

The Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo is available for download on Hugging Face, and the inference can be accessed on GitHub.
What’s New?
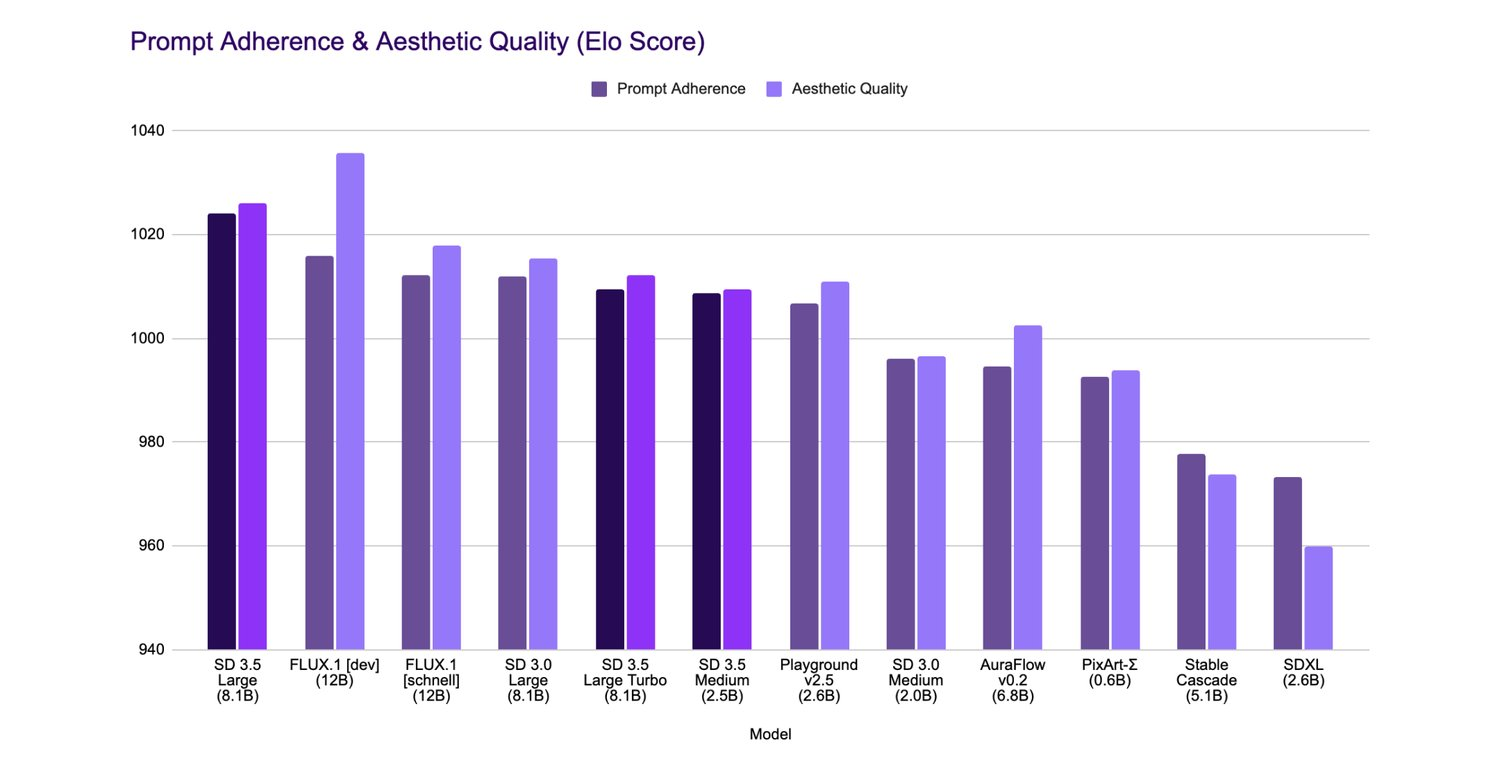
Stable Diffusion 3.5 offers a range of models catering to different users, including researchers, startups, and enterprises.
The Stable Diffusion 3.5 Large model, with 8 billion parameters, delivers superior image quality and prompt adherence, making it apt for professional use at a 1-megapixel resolution. The Large Turbo version is a faster alternative, generating high-quality images in just 4 steps.
The company says the model is also optimised for efficient performance on standard consumer hardware, particularly in the Medium and Large Turbo versions.
Besides, it generates inclusive and diverse images, accurately representing various skin tones and features without needing extensive prompts.
The models are trained on the subset of the LAION-5b dataset—which was created by the DeepFloyd team—to further filter adult content using the dataset’s NSFW filter.
The model is available at no cost for non-commercial purposes, including academic research. Startups, small to medium businesses, and creators can use the model commercially for free, provided their annual revenue is under $1M.
Users maintain full ownership of the generated content, with no restrictive licensing.
Google Pauses Gemini Image Generation
Meanwhile, Google announced it is pausing its Gemini artificial intelligence image generation feature after saying it offers “inaccuracies” in historical pictures.
Gemini-generated pictures went viral on social media recently, leading to widespread ridicule and anger. Some users criticized Google, claiming that the company is overly concerned with being socially aware, even if it means sacrificing truth and accuracy.
“We recently made the decision to pause Gemini’s image generation of people while we work on improving the accuracy of its responses,” said Google.
Social media users have been complaining that the AI tool generates images of historical figures—like the U.S. Founding Fathers—as people of colour, calling this inaccurate.
The post Stability AI Releases Stable Diffusion 3.5 Text-to-Image AI Model appeared first on AIM.