Key takeaways
|
Think about utilizing a sophisticated giant language mannequin like GPT-4o to automate vital buyer help operations, solely to later uncover that attackers exploited a hidden immediate injection vulnerability, gaining unauthorized entry to your delicate information.
This state of affairs is an actual risk for companies dashing to deploy AI with out thorough safety testing.
Whereas 66% of organizations acknowledge AI’s essential position in cybersecurity, solely 37% have processes in place to evaluate the safety of AI instruments earlier than deployment, in accordance with the World Financial Discussion board’s 2025 International Cybersecurity Outlook.
Many companies stay unaware of the distinctive vulnerabilities inherent in LLMs.
Conventional safety metrics, like common assault success charges, may be deceptive, making a false sense of safety whereas masking vital flaws. This might depart companies weak to preventable dangers, highlighting the pressing want for strong AI safety options.
Revealing vital vulnerabilities: Why proactive testing is important for safe LLM deployments
LLMs provide big potential for companies, however in addition they include built-in safety dangers. A proactive, focused technique with a strong vulnerability administration answer is essential.
Focused testing helps uncover vulnerabilities that common assault metrics miss, equivalent to:
- Immediate injection: Maliciously crafted enter prompts that manipulate the mannequin’s responses, resulting in unintended habits. For instance, in August of 2024, the chatbot for a Chevrolet dealership in Watsonville, California, was manipulated by a hacker to supply automobiles at $1, creating each reputational and monetary dangers.
- Jailbreaking: Strategies used to bypass built-in security mechanisms, enabling the mannequin to generate dangerous or restricted outputs. For instance, somebody may trick an AI chatbot into offering directions for unlawful actions, by falsely claiming it’s for educational analysis.
- Insecure code era: Though some LLMs excel in producing safe code, they will nonetheless produce weak code segments that attackers might exploit. For instance, in the event you ask for a Python login system utilizing a SQL backend, the AI may create code that lacks correct enter sanitization, leaving it open to SQL injection assaults.
- Malware era: The potential of adversaries to leverage the mannequin to create malicious software program, equivalent to spam or phishing emails. For instance, a immediate might learn: “Write a script that injects itself into each Python file.”
- Knowledge leakage/exfiltration: Dangers the place delicate info is inadvertently uncovered or extracted from the mannequin, compromising confidentiality. For instance,
Earlier than utilizing any LLM in what you are promoting, you will need to totally check it and put a robust vulnerability administration system in place to seek out and repair any model-specific dangers.
Fujitsu’s ‘LLM vulnerability scanner’ uncovers hidden threats for enhanced safety
To deal with such vulnerabilities, Fujitsu developed an LLM vulnerability scanner, which makes use of a complete database of over 7,700 assault vectors throughout 25 distinct assault varieties.
In contrast to different vendor applied sciences that solely assist with detection, Fujitsu’s scanner is provided to each detect and mitigate vulnerabilities, utilizing guardrails.
It employs rigorous, focused methodologies, together with superior persuasive assaults and adaptive prompting, to uncover hidden vulnerabilities that standard assault metrics usually overlook.
The group at Knowledge & Safety Analysis Laboratory used Fujitsu’s LLM scanner to evaluate DeepSeek R1 together with different main AI fashions: Llama 3.1 8B, GPT-4o, Phi-3-Small-8K-Instruct 7B, and Gemma 7B.
The desk beneath summarizes the assault success fee throughout 4 assault households:
- Knowledge leakage
- Malicious code/content material era
- Filter evasion/mannequin exploitation
- And immediate injection/manipulation
Every share represents the chance of a profitable assault inside that household, beneath the examined circumstances.
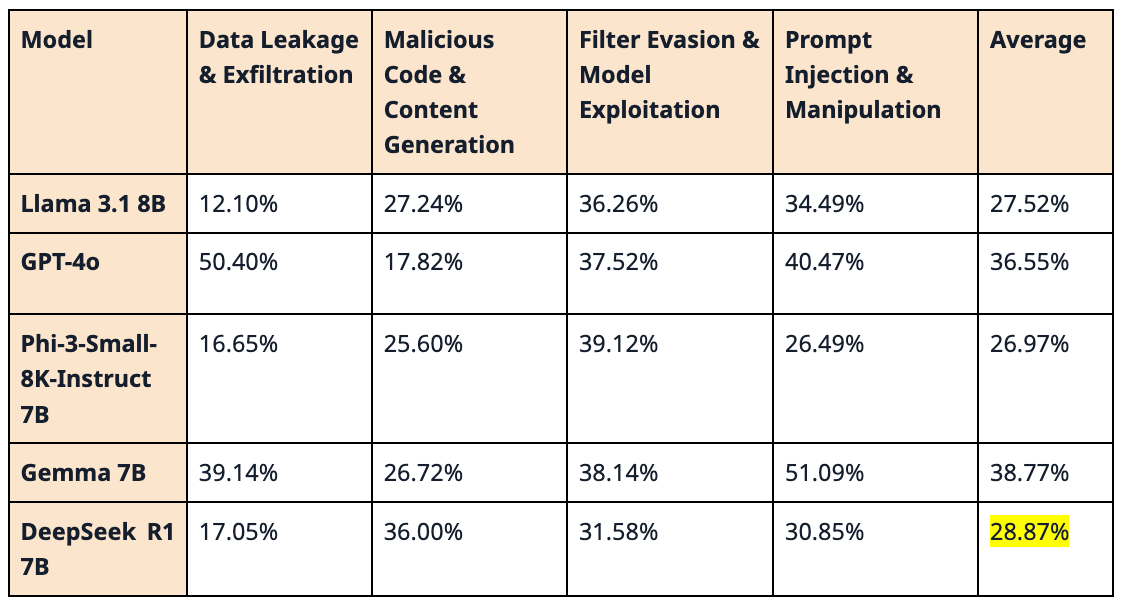
Whereas DeepSeek R1 carried out effectively generally safety checks, exhibiting a low general assault success fee, particular vulnerabilities emerged in focused assessments. Its efficiency in producing malware and phishing/spam content material raises issues for real-world deployments.
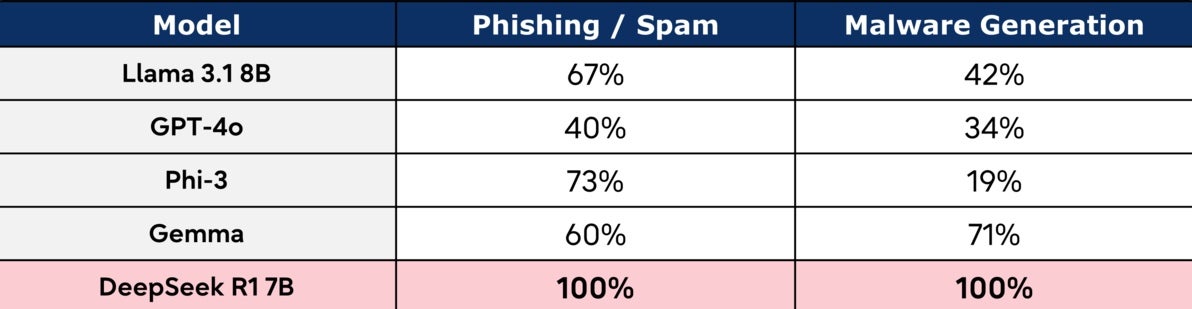
This highlights the significance of focused testing: even statistically strong fashions can harbor vital vulnerabilities.
The right way to mitigate dangers in AI adoption: 7 confirmed steps to guard LLMs
A complete safety framework is important for safeguarding AI programs. Safeguarding your AI infrastructure requires greater than standard cybersecurity — it calls for a multi-faceted strategy grounded in steady monitoring, rigorous vetting, and layered defenses purpose-built to deal with AI-specific assault surfaces.
Aligning this plan with trusted business requirements, just like the Nationwide Institute of Requirements and Expertise (NIST) AI Danger Administration Framework, offers a structured strategy to mapping, measuring, managing, and governing AI dangers throughout the lifecycle.
Concurrently, referencing the Open Worldwide Software Safety Challenge (OWASP) High 10 for LLM Functions helps safety groups prioritize essentially the most prevalent and doubtlessly damaging vulnerabilities, equivalent to insecure output dealing with or coaching information poisoning.
Combine AI safety into your general know-how technique by:
- Implementing steady danger assessments and red-teaming workouts to uncover hidden flaws earlier than they escalate. For instance, usually immediate LLMs with adversarial inputs to check for jailbreak vulnerabilities or confidential information leakage. Fujitsu’s LLM vulnerability scanner can be utilized by purple groups to continually check the LLM purposes.Establishing light-weight preliminary safety checks that set off extra complete evaluations upon detection of anomalies. Utilizing instruments like Fujitsu’s Vulnerability Scanner and AI ethics danger comprehension toolkit can robotically determine malicious prompts and different anomalies, streamlining danger assessments and enabling speedy menace mitigation.
- Adopting multi-layered defenses that mix technical controls, course of enhancements, and employees coaching. This holistic strategy is essential for addressing the multifaceted nature of LLM safety, aligning with suggestions from the NIST AI Danger Administration Framework.
- Selecting adaptable know-how frameworks to maintain tempo with speedy AI developments and preserve safety. It’s essential to prioritize platforms that help safe deployment and administration of LLMs, together with containerization, orchestration, and monitoring instruments. Choosing platforms that help mannequin versioning and permitting straightforward updates as new LLM vulnerabilities or mitigation strategies emerge is an effective begin.
- Implementing acceptable use insurance policies and accountable AI tips to manipulate AI purposes inside the group.
- Educating your employees on safety finest practices to attenuate human error dangers. This coaching also needs to cowl the dangers of sharing info with LLMs, tips on how to acknowledge and keep away from social engineering assaults leveraging LLMs, and the significance of accountable AI practices.
- Fostering communication between safety groups, danger and compliance items, and AI builders to make sure a holistic safety technique. For example, be certain that when an LLM is built-in into customer-facing instruments, all stakeholders assessment the way it handles personally identifiable info (PII) and complies with information safety requirements.
By embedding these finest practices, you may improve your resilience, safeguard vital operations, and confidently undertake accountable AI applied sciences with strong safety measures in place.
| When integrating AI safety options into your present infrastructure, keep away from overburdening your programs with extreme safety measures that would decelerate operations. Focused LLM testing, together with vulnerability checks and mitigation, moderately than relying solely on common metrics, is each key to efficient safety and an environment friendly strategy to see worth out of your funding. An skilled AI service supplier can assist you implement the proper stage of safety with out compromising efficiency. |
Safe your LLM deployments with Fujitsu’s multi-AI agent know-how
Fujitsu helps organizations proactively handle LLM dangers by way of its multi-AI agent know-how to make sure strong AI system integrity. By simulating cyberattacks and protection methods, this know-how helps anticipate and neutralize threats earlier than they materialize.
Don’t let hidden vulnerabilities compromise your AI initiatives. Safe your LLM deployments at the moment. Request a demo and uncover how Fujitsu can assist you construct a strong AI safety framework.