Pune based consumer lending startup Fibe is exploring generative AI applications in customer service and risk assessment. It recently released a chatbot supported by LLMs via Amazon Bedrock, which has improved its customer support efficiency by30%.
At AWS Fintech Forum held in Bengaluru earlier this month, AIM caught up with Anil Sinha, chief technology officer of Fibe. He said that the team finds Anthropic’s Claude 3, hosted on Bedrock, most useful for their work. The company also employs Amazon Comprehend for natural language processing, which is used to analyse sentiment and quality in customer calls.
Amazon Bedrock provides the choice of top-notch models from both Amazon’s own first-party offerings (like Amazon Titan)and various third-party models. This includes families of foundational models from AI-focused companies like Meta, AI21 Labs, Anthropic, Cohere, AI21, Mistral, Stability AI, and more. Last year, Amazon invested $4 billion in Anthropic.
“The investments made with Anthropic and others is kind of helping us to bring this choice to customers, but then customers can also use open source models with Hugging Face set up on SageMaker,” Pandurang Nayak, head of startup solutions architects AWS India, told AIM at the event.
Fibe’s Growth Story
“We have been using AWS for the past seven to eight years now which went from a single-product offering to a diverse portfolio that now includes personal loans, embedded finance, and more,” Sinha told AIM. He said that this expansion was facilitated by AWS’ robust infrastructure, which provided the scalability and security necessary to manage increased demand and complexity.
Fibe primarily caters to young salaried professionals and has been able to disburse more than six million loans worth ₹30,000 crore in near real-time since its inception. The startup leverages AWS ML services to streamline KYC processing, employing features such as optical character recognition, face match, and selfie deduplication.
Along similar lines, it has developed FibeShield, a proprietary algorithm-based product, crafted with AWS tools such as Amazon Neptune, AWS Lambda, and Amazon S3. FibeShield uses graph ML, device fingerprinting, and geo-fencing to effectively identify fraud by revealing hidden connections and duplications among users.
“AWS credits and the Activate program have been helpful in providing us with resources to experiment freely from the time we started out. The support from AWS, including technical advice and regulatory guidance, has enabled us to focus more on innovation rather than infrastructure management,” added Sinha.
Since its inception in 2013, AWS Activate has provided $6 billion in credits to startups around the globe to help them build solutions in the cloud.
Why Enterprises Choose AWS
Besides Fibe, Nayak highlighted several success stories demonstrating the scalability AWS offers. “One such success story is with EaseBuzz, a Pune-based company that grew fourfold in two years using AWS Spot Instances, optimising their infrastructure costs while scaling their operations massively,” he added.
Another example is fintech startup Ring, whose data science team has been using its tools like Amazon Rekognition and Amazon Textract to process customer data rapidly, reducing its NPS by 45% and improving overall collection efficiency by 30%. Its loan application processing times have also halved.
“We’ve always worked backwards from what our customer needs are. In fact, 90% of the features in our products are developed from customer feedback, while the remaining 10% come from developments like AWS Lambda. We maintain this approach as part of our culture, continuously adapting to what customers need and offering them the flexibility to use technology in various ways,” added Nayak.
Other startups include Yubi, inVOID, TrapyZ, PayU, Fibe, and so on.
AWS has been instrumental in shaping early-stage startups through programs like the AWS Activate Program, Startup Architecture Challenge, AccelerateHer Program, Public Sector Startup Ramp, and more.
Looking ahead, AWS is committed to continuing its support for startups by enhancing its service offerings and reducing the “undifferentiated heavy lifting” that often slows down innovation. The goal is to allow startups to focus more on their core products and customer experiences rather than on managing infrastructure.
The post Fibe Leverages Amazon Bedrock to Increase Customer Support Efficiency by 30% appeared first on Analytics India Magazine.
AWS has announced the general availability of Meta’s recently released new generation of LLM, Llama 3, in Amazon Bedrock. The 7B model outperforms Gemma and Mistral on all benchmarks, and the 70B model outperforms Gemini Pro 1.5 and Claude 3 Sonnet.
The Llama 3 models are tailored for diverse AI applications and are presented in two main configurations: the Llama 3 8B and Llama 3 70B. These variants are specially designed for tasks ranging from text summarisation to complex language translation. Meta is also developing even more powerful models, potentially exceeding 400 billion parameters, that will support features like multimodal inputs and multilingual capabilities, greatly expanding the use cases of these models.
Expanded Capabilities of Amazon Bedrock
Additionally, Amazon Bedrock is now equipped with new features for customers exploring generative AI.
Custom Model Import: This new functionality allows users to integrate their unique models into the Bedrock environment. This integration supports a wide range of AI applications by simplifying the development process and reducing operational overhead.
Model Evaluation: This tool is now generally available and accelerates the model selection process. It enables organisations to assess and compare the effectiveness of different models on Amazon Bedrock, thus optimising their AI strategies based on performance, accuracy, and suitability for specific tasks.
Guardrails: Designed to be responsible for the deployment of AI applications, this feature helps users implement essential safety measures. It effectively filters out undesirable content, aligning with organisational policies and ethical AI practices.
Amazon Bedrock is leveraged by various enterprises for its scalability and versatility. For example, airline Ryanair enhances crew operations by using Bedrock to access vital regulatory information and procedural guidelines quickly. In the healthcare sector, Netsmart is making significant strides in improving the efficiency of clinical documentation, which facilitates better patient care and faster service delivery. On the other hand, New York Stock Exchange (NYSE): The NYSE employs Bedrock to decode and simplify vast amounts of regulatory documentation, making critical information more accessible and understandable for stakeholders.
The post AWS Brings Meta’s Llama 3 Models on Amazon Bedrock appeared first on Analytics India Magazine.
Despite the scepticism about producing quality data using synthetic data, Anthropic chief Dario Amodei recently believes that creating an infinite data generation engine that can help build better AI systems is possible.
“If you do it right, with just a little bit of additional information, I think it may be possible to get an infinite data generation engine,” said Amodei in an interview with CNBC while discussing the challenges and potential of using synthetic data to train AI models.
“We are working on several methods for developing synthetic data. These are ideas where you can take real data present in the model and have the model interact with real data in some way to produce additional or different data,” explained Amodei.
Citing AlphaGo, he said, it is actually possible to inject very small amounts of new information to get more than you started with.
“If you go back to systems eight years ago, so if you remember AlphaGo, note that the model there just trains against itself with nothing other than the rules of Go to adjudicate,” he added, saying that those little rules of Go, the little additional piece of information, is enough to take the model from “no ability at all to smarter than the best human at Go.”
Amodei believes that if we do it right, with just a little bit of additional information, we can create an infinite data generation engine. For those unaware, AlphaGo systems were trained by reinforcement learning, where the neural networks were initially bootstrapped from human gameplay expertise.
Meta’s AI chief, Yann LeCun, a self-supervised-learning proponent, has slightly different views, criticising reinforcement learning for being inefficient and impractical for real-world applications when used on its own.
“A lot of the success of machine learning at least until fairly recently was mostly with supervised learning. Reinforcement learning gave some people a lot of hope, but turned out to be so inefficient as to be almost impractical in the real world, at least in isolation, unless you rely much more on something called self-supervised learning, which is really what has brought about the big revolution that we’ve seen in AI over the last few years,” said LeCun.
Self-supervised learning is a technique used where the model autonomously discovers patterns and structures in data without explicit labels.
Other techniques
Besides reinforcement learning and self-supervised learning, LeCun also discussed other techniques for data generation and training AI systems. This includes generative models such as GANs and VAEs, which generate new data by learning the distribution of existing data. “There are systems of this type that have been trained to produce images and they use other techniques like diffusion models,” he added.
Predictive learning modelsare also another interesting method, which forecasts future states or missing parts of data to aid in learning representations and dynamics. “A particular way of doing it is you take a piece of data… and then you train some gigantic neural net to predict the words that are missing,” said LeCun.
Then, there are energy-based models, which score data configurations based on their probability of supporting various tasks, including generation and classification. “Energy-based models learn a scalar energy for each configuration of the variables of interest,” explained LeCun.
Joint embedding predictive architectures (JEPA) is another technique for training AI systems. It uses embeddings to predict parts of data from others, facilitating the learning of complex data relationships. “Instead of reconstructing y from x, you run both x and y through encoders… you do the prediction in representation space,” he explained.
Latent variable models also help in data generation. These models integrate hidden variables that explain inherent data variability, which is essential for complex generative tasks. “Latent variable models consist in models that have a latent variable z that is not given to you during training or during tests that you have to infer the value of,” mentioned LeCun.
Lastly, there is hierarchical planning. This technique is crucial for enabling AI systems to operate in complex, real-world environments where decisions need to be made at both strategic and tactical levels. Here, LeCun gave an example of planning a trip to Paris through high-level tasks (like getting to the airport) and detailed steps (like navigating to the departure gate), touching upon the reasoning aspect.
Join us at the Data Engineering Summit 2024 on May 30-31 at the Hotel Radisson Blu in Bengaluru, India, organised by AIM for two days of cutting-edge discussions on data engineering innovation featuring top engineers and innovators from leading tech companies.
The post ‘We May be Able to Create an Infinite Data Generation Engine with Synthetic Data,’ says Anthropic CEO appeared first on Analytics India Magazine.
Brazilian surgeons recently used the Apple Vision Pro headset to enhance shoulder arthroscopy, projecting high-resolution images and real-time data during surgery.
“Shoulder arthroscopy surgery uses a camera inside the joint, and surgeons perform it by looking directly at a screen. With this device, I was able to see the image on a display the size of a movie screen with high resolution. Besides, I was able to see the patient’s exams and 3D models in real-time,” Dr Bruno Gobbato told MacMagazine, after using Apple Vision Pro for the first time while performing a surgery recently.
APPLE VISON PRO ADOPTED BY BRAZILIAN SURGEON For the first time in Brazil, a surgeon successfully used an Apple Vision Pro headset to optimize a surgical procedure. Surgeon, Bruno Gobbato: "Shoulder arthroscopy surgery uses a camera inside the joint and surgeons perform it… pic.twitter.com/cgwS8jmN3g
— Mario Nawfal (@MarioNawfal) April 21, 2024
That’s a first for Brazil that a surgeon has used an Apple Vision Pro headset to optimise a surgical procedure. The orthopaedic doctor used the device to operate on a patient with a rotator cuff tear. He posted a video on YouTube demonstrating how easily he could view his notes, patient X-rays, and a live camera feed at the same time using the headset.
Gobbato also praised the dynamic range of the cameras in the device emphasising that while regular cameras struggle to capture footage due to the glare from bright surgical lights, this was not a problem with the Apple headset.
However, this is not the first time that the device made its way into an OT. Earlier, the headset helped surgeons in a spine operation in the UK. Used alongside an app developed by eXeX, Vision Pro facilitated real-time data streaming, surgical preparation, and instrument selection, potentially eliminating human errors and boosting surgical confidence.
Apple Takes Healthcare Seriously
“If you zoom out into the future and look back and you ask the question – what was Apple’s greatest contribution to mankind? It will be about health,” CEO Tim Cook had once said. It seems that his vision is finally turning into reality. Apple is building the healthcare OS, where AI will play a big role.
With iPads and iPhones assisting nurses in responding more promptly to alerts and enhancing medication administration, the healthcare community has effectively driven meaningful change with Apple products at their fingertips.
Then there are Apple Smartwatches, health data trackers, and health-kit-enabled apps on iPhone all trying to fix the healthcare industry. The company plans to release watches that will be able to detect hypertension and sleep apnea.
What’s more? It’s also working on bringing hearing-aid capabilities to its AirPods and on an AI-powered health coaching service to track emotions.
However, when it comes to healthcare innovation, Apple Vision Pro seems to be a stellar new addition. With its ultra-high-resolution screens for each eye and multiple cameras for hand and eye tracking, the headset heralds a new era of innovation in healthcare.
By blending digital content with the physical world, it unlocks powerful spatial experiences, transforming areas such as clinical education, surgical planning, training, medical imaging, behavioral health, and more.
Revolutionising Healthcare
Developers across the healthcare community are using the technical capabilities of visionOS to create and bring new apps to Apple Vision Pro that are igniting new possibilities for physicians, frontline workers, and even students.
For instance, Stryker’s myMako app extends a surgeon’s experience in and beyond the operation theatre with Apple Vision Pro. It’s a 3D program that allows surgeons to create models of what they would be doing in the surgery beforehand, and have access to those surgical plan details and insights during the actual procedure in a 3D immersive visual experience.
The myMako app was also employed during the latest surgery use case of Apple Vision Pro by the Brazilian doctor.
Vision Pro has the potential to revolutionise medical education and training. Through immersive VR experiences, aspiring healthcare professionals can gain hands-on experience in simulated settings, refining their skills and improving their learning outcomes.
Furthermore, VR-enabled live streaming of surgical procedures provides extensive access to surgical education, bridging the gap between theory and practice.
i mean it when i say that the Apple Vision Pro will be a game changer for education here’s how I studied the heart 5 years ago vs how I can study it today, credit to the visionOS app Insight Heart the contrast in experience and comprehension can’t be denied pic.twitter.com/a2Yx60iPsD
— Justin Ryan ᯅ (@justinryanio) March 23, 2024
Apple’s Vision Pro headset is emerging as a healthcare game-changer, using VR and AR to enhance treatment and monitoring. It enables healthcare professionals to view a patient’s medical history and vitals in a way that was previously unimaginable.
The headset’s display capabilities fill a doctor’s field of view with anything from a patient’s blood pressure graphs to their latest chest X-ray, ensuring that crucial information is always at the forefront. It facilitates more accurate and informed decision-making and diagnoses.
One of the most notable benefits of Vision Pro is its potential to enhance telemedicine experiences. By offering immersive virtual consultations, it enables patients to access healthcare services from anywhere, thereby breaking down barriers of distance and accessibility.
It is especially beneficial for those managing conditions like Parkinson’s or Alzheimer’s as home monitoring can be crucial for them.
Recently, Sharp HealthCare’s Spatial Computing Centre of Excellence in San Diego bought 30 Vision Pro units to give them to healthcare workers for exploring the use of the tech in healthcare settings.
What’s Next?
There is no doubt that Apple Vision Pro has made VR headsets cool again. When compared to other headsets like Meta’s Quest 3, Vision Pro has a lot of advanced features to offer.
The Vision Pro headset has two micro-OLED displays packing 4k screens for each eye. It comes with 12 cameras in various positions all over the headset, five sensors to track other details, which include a LiDAR Scanner, and two TrueDepth sensors.
These sensors work with two infrared flood illuminators to paint a 3D image of the surroundings. To process all of this data quickly and on the device, Apple even created the R1 chip, which reduces the latency to around 12 ms.
However, it’s only for those who can afford the price. As, clearly the $3,500 price tag doesn’t sit well with a lot of users who think it’s too much for a headset, even with all these features.
And, reportedly Apple is also cutting down on Vision Pro production due to low demand.
Source: X
Transforming its features into healthcare solutions, Vision Pro shows that the future of healthcare is bright, innovative, and it is digital – and Apple can lead the way in making such a future possible.
However, the company may want to look into further improving the headset’s features and going bearish on the product’s pricing strategy.
Source: X
Currently, Apple Vision Pro is only available for sale in the US, with other countries, including India, which houses the largest developer ecosystem, waiting patiently for its release. But with the reports of production cuts coming in, it seems like the waiting period is going to be a little longer.
The post Doctors Use Apple Vision Pro to Enhance Shoulder Arthroscopy Surgery appeared first on Analytics India Magazine.
Since data varies from industry to industry, its impact on digitalization efforts differs widely — a utilization strategy that works in one may be ineffective in another. How does the variety and availability of information impact the digital transformation process in various fields?
The connection between data and digitalization
Data is the core transformative tool organizations rely on during digitalization. Without it, their decisions would be uncoordinated, their strategies would be redundant and their investments would be immaterial.
Digitalization extends far beyond transitioning from paper-based systems to computers. It is supposed to shape business strategies, drive innovation, and uncover insights. Realistically, without data on customer behavior, returns, or pain points, organizations can only guess where digital transformation will be most impactful.
With data, organizations can establish benchmarks to inform their digitalization strategies. Being able to identify baseline key performance indicators (KPIs) enables them to accurately track their progress and see how impactful digital transformation is.
Of course, data also helps organizations secure buy-in from the board and stakeholders. If they can show metrics and statistics to validate their claims and support their strategies, they have a higher likelihood of receiving funds and getting the green light.
The benefits of data-driven digitalization
Although data is foundational to digitalization, there are varying degrees to which companies can leverage it successfully. If they validate, clean, transform, and categorize the information they collect, they will likely see greater success during their digital transformation.
While most organizations are aware of the potential benefits of such a strategy, few implement it. According to one survey, respondents estimated that 43% of their data goes unutilized. This kind of barrier can artificially lengthen and complicate digitalization efforts.
However, organizations can see substantial gains if they strategically utilize data since it can help them streamline operations and extract meaningful insights. For instance, four in 10 executives agree operational efficiency is among the top benefits of digitalization.
How data impacts digitalization in various industries
Every industry must leverage data differently during its digitalization process.
Manufacturing
In the manufacturing industry, digitalization is heavily influenced by equipment and operational data — the primary variety of information facilities collect. They use it to inform their investment decisions, often utilizing tools like robotic process automation or artificial intelligence.
Without data, manufacturers will not know what technologies to invest in during digitalization. According to one survey, 95% of them agree digital transformation is essential to their future success, highlighting the importance of strategic collection and utilization.
Retail
Businesses in the retail industry depend on customer data during digitalization. It impacts how they anticipate and respond to dynamic market conditions. Additionally, it influences how they interpret customer demand. During a digital transformation, they need a massive database of purchase histories, shopping trends and demographic details to inform their strategies.
Pharmaceutical
In the pharmaceutical industry, patient data impacts digitalization. When companies know how individuals schedule appointments, react to drugs and make payments, they can accelerate their products’ time to market and automate digital tools like their coding and billing systems.
Consumer electronics
In the consumer electronics industry, data on market conditions and customer demand impacts digitalization efforts. For example, based on the data point that the technology sector is responsible for 2%-3% of global greenhouse gas emissions, they may consider shifting toward sustainable practices. These insights can drive innovation in an oversaturated field.
Finance
Economic and customer data influence digitalization in the finance industry. Financial institutions and services rely on it to optimize cost-reduction efforts, decide where to invest and streamline operational processes during their digital transformation.
In one case, a bank developed a database of tens of millions of households to digitalize loan pre-approval. Within two years of its launch, they shortened the approval process from 28 days to seven, resulting in a 35% increase in loan originations and a 20% origination cost reduction.
The transformative power of data
Data variety and availability have a tremendous impact on the digitalization strategies various industries leverage. Even though they share the same end goal — to digitize their manual systems and procedures — their courses of action must differ.
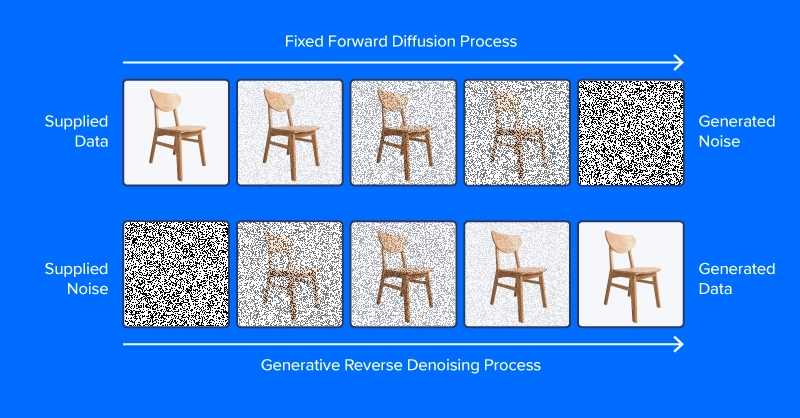
Denoising diffusion models are trained to pull patterns out of noise, to generate a desirable image. The training process involves showing model examples of images (or other data) with varying levels of noise determined according to a noise scheduling algorithm, intending to predict what parts of the data are noise. If successful, the noise prediction model will be able to gradually build up a realistic-looking image from pure noise, subtracting increments of noise from the image at each time step.
Unlike the image at the top of this section, modern diffusion models don’t predict noise from an image with added noise, at least not directly. Instead, they predict noise in a latent space representation of the image. Latent space represents images in a compressed set of numerical features, the output of an encoding module from a variational autoencoder, or VAE. This trick put the “latent” in latent diffusion, and greatly reduced the time and computational requirements for generating images. As reported by the paper authors, latent diffusion speeds up inference by at least ~2.7X over direct diffusion and trains about three times faster.
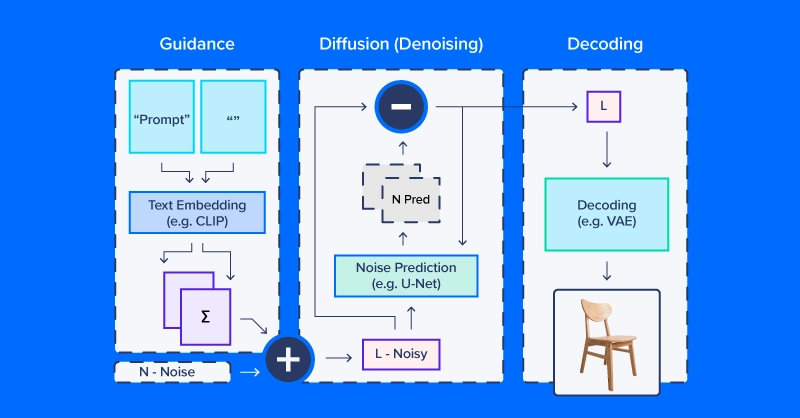
People working with latent diffusion often talk of using a “diffusion model,” but in fact, the diffusion process employs several modules. As in the diagram above, a diffusion pipeline for text-to-image workflows typically includes a text embedding model (and its tokenizer), a denoise prediction/diffusion model, and an image decoder. Another important part of latent diffusion is the scheduler, which determines how the noise is scaled and updated over a series of “time steps” (a series of iterative updates that gradually remove noise from latent space).
Latent diffusion code example
We’ll use CompVis/latent-diffusion-v1-4 for most of our examples. Text embedding is handled by a CLIPTextModel and CLIPTokenizer. Noise prediction uses a ‘U-Net,’ a type of image-to-image model that originally gained traction as a model for applications in biomedical images (especially segmentation). To generate images from denoised latent arrays, the pipeline uses a variational autoencoder (VAE) for image decoding, turning those arrays into images.
We’ll start by building our version of this pipeline from HuggingFace components.
Make sure to check pytorch.org to ensure the right version for your system if you’re working locally. Our imports are relatively straightforward, and the code snippet below suffices for all the following demos.
import os import numpy as np import torch from diffusers import StableDiffusionPipeline, AutoPipelineForImage2Image from diffusers.pipelines.pipeline_utils import numpy_to_pil from transformers import CLIPTokenizer, CLIPTextModel from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler, LMSDiscreteScheduler
from PIL import Image import matplotlib.pyplot as plt
Now for the details. Start by defining image and diffusion parameters and a prompt.
Encoding the text prompt as an embedding requires first tokenizing the string input. Tokenization replaces characters with integer codes corresponding to a vocabulary of semantic units, e.g. via byte pair encoding (BPE). Our pipeline embeds a null prompt (no text) alongside the textual prompt for our image. This balances the diffusion process between the provided description and natural-appearing images in general. We’ll see how to change the relative weighting of these components later in this article.
Everything is ready to go, and we can dive into the diffusion loop itself. We can keep track of images by sampling periodically throughout so we can see how noise is gradually decreased.
# diffusion loop for step_idx, timestep in enumerate(scheduler.timesteps): with torch.no_grad(): # concatenate latents, to run null/text prompt in parallel. model_in = torch.cat([latents] * 2) model_in = scheduler.scale_model_input(model_in, timestep).to(my_device) predicted_noise = unet(model_in, timestep, encoder_hidden_states=text_embeddings).sample # pnu – empty prompt unconditioned noise prediction # pnc – text prompt conditioned noise prediction pnu, pnc = predicted_noise.chunk(2) # weight noise predictions according to guidance scale predicted_noise = pnu + guidance_scale * (pnc – pnu) # update the latents latents = scheduler.step(predicted_noise, timestep, latents).prev_sample # Periodically log images and print progress during diffusion if step_idx % display_every == 0 or step_idx + 1 == len(scheduler.timesteps): image = vae.decode(latents / 0.18215).sample[0] image = ((image / 2.) + 0.5).cpu().permute(1,2,0).numpy() image = np.clip(image, 0, 1.0) images.extend(numpy_to_pil(image)) print(f”step {step_idx}/{number_inference_steps}: {timestep:.4f}”)
At the end of the diffusion process, we have a decent rendering of what you wanted to generate. Next, we’ll go over additional techniques for greater control. As we’ve already made our diffusion pipeline, we can use the streamlined diffusion pipeline from HuggingFace for the rest of our examples.
Controlling the diffusion pipeline
We’ll use a set of helper functions in this section:
We’ll start with the most well-known and straightforward application of diffusion models: image generation from textual prompts, known as text-to-image generation. The model we’ll use was released into the wild (of the Hugging Face Hub) by the academic lab that published the latent diffusion paper. Hugging Face coordinates workflows like latent diffusion via the convenient pipeline API. We want to define what device and what floating point to calculate based on if we have or do not have a GPU.
If you use a very unusual text prompt (very unlike those in the dataset), it’s possible to end up in a less-traveled part of latent space. The null prompt embedding provides a balance and combining the two according to guidance_scale allows you to trade off the specificity of your prompt against common image characteristics.
guidance_images = [] for guidance in [0.25, 0.5, 1.0, 2.0, 4.0, 6.0, 8.0, 10.0, 20.0]: seed_all(my_seed) my_output = pipe(my_prompt, num_inference_steps=50, num_images_per_prompt=1, guidance_scale=guidance) guidance_images.append(my_output.images[0]) for ii, img in enumerate(my_output.images): img.save(f”prompt_{my_seed}_g{int(guidance*2)}_{ii}.jpg”)
Since we generated the prompt using the 9 guidance coefficients, you can plot the prompt and view how the diffusion developed. The default guidance coefficient is 0.75 so on the 7th image would be the default image output.
Negative prompts
Sometimes latent diffusion really “wants” to produce an image that doesn’t match your intentions. In these scenarios, you can use a negative prompt to push the diffusion process away from undesirable outputs. For example, we could use a negative prompt to make our Martian astronaut diffusion outputs a little less human.
You should receive outputs that follow your prompt while avoiding outputting the things described in your negative prompt.
Image variation
Text-to-image generation from scratch is not the only application for diffusion pipelines. Actually, diffusion is well-suited for image modification, starting from an initial image. We’ll use a slightly different pipeline and pre-trained model tuned for image-to-image diffusion.
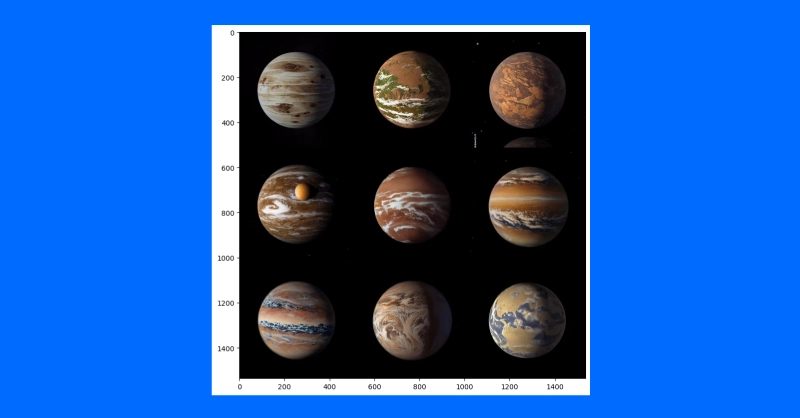
One application of this approach is to generate variations on a theme. A concept artist might use this technique to quickly iterate different ideas for illustrating an exoplanet based on the latest research.
We’ll first download a public domain artist’s concept of planet 1e in the TRAPPIST system (credit: NASA/JPL-Caltech). Then, after downscaling to remove details, we’ll use a diffusion pipeline to make several different versions of the exoplanet TRAPPIST-1e.
url = “https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/TRAPPIST-1e_artist_impression_2018.png/600px-TRAPPIST-1e_artist_impression_2018.png” img_path = url.split(“/”)[-1] if not (os.path.exists(“600px-TRAPPIST-1e_artist_impression_2018.png”)): os.system(f”wget ‘{url}'”) init_image = Image.open(img_path)
seed_all(my_seed)
trappist_prompt = “Artist’s impression of TRAPPIST-1e” “large Earth-like water-world exoplanet with oceans,” “NASA, artist concept, realistic, detailed, intricate”
By feeding the model an example initial image, we can generate similar images. You can also use a text-guided image-to-image pipeline to change the style of an image by increasing the guidance, adding negative prompts and more such as “non-realistic” or “watercolor” or “paper sketch.” Your mile may vary and adjusting your prompts will be the easiest way to find the right image you want to create.
Conclusions
Despite the discourse behind diffusion systems and imitating human generated art, diffusion models have other more impactful purposes. It has been applied to protein folding prediction for protein design and drug development. Text-to-video is also an active area of research and is offered by several companies (e.g. Stability AI, Google). Diffusion is also an emerging approach for text-to-speech applications.
It’s clear that the diffusion process is taking a central role in the evolution of AI and the interaction of technology with the global human environment. While the intricacies of copyright, other intellectual property laws, and the impact on human art and science are evident in both positive and negative ways. But what is truly a positive is the unprecedented capability AI has to understand language and generate images. It was AlexNet that had computers analyze an image and output text, and only now computers can analyze textual prompts and output coherent images.
The incredible abilities of LLMs are powered by their vast neural networks which are made up of billions of parameters. These parameters are the result of training on extensive text corpora and are fine-tuned to make the models as accurate and versatile as possible. This level of complexity requires significant computational power for processing and storage.
The accompanying bar graph delineates the number of parameters across different scales of language models. As we move from smaller to larger models, we witness a significant increase in the number of parameters with ‘Small’ language models at the modest millions of parameters and ‘Large’ models with tens of billions of parameters.
However, it is the GPT-4 LLM model with 175 billion parameters that dwarfs other models’ parameter size. Not only is GPT-4 using the most parameters out of the graphs, but it also powers the most recognizable generative AI model, ChatGPT. This towering presence on the graph is representative of other LLMs of its class, displaying the requirements needed to power the future’s AI chatbots, as well as the processing power required to support such advanced AI systems.
The cost of running LLMs and quantization
Deploying and operating complex models can get costly due to their need for either cloud computing on specialized hardware, such as high-end GPUs, AI accelerators, and continuous energy consumption. Reducing the cost by choosing an on-premises solution can save a great deal of money and increase flexibility in hardware choices and freedom to utilize the system wherever with a trade-off in maintenance and employing a skilled professional. High costs can make it challenging for small business deployments to train and power an advanced AI. Here is where quantization comes in handy.
What is quantization?
Quantization is a technique that reduces the numerical precision of each parameter in a model, thereby decreasing its memory footprint. This is akin to compressing a high-resolution image to a lower resolution while retaining the essence and most important aspects but at a reduced data size. This approach enables the deployment of LLMs on with less hardware without substantial performance loss.
ChatGPT was trained and is deployed using thousands of NVIDIA DGX systems, millions of dollars of hardware, and tens of thousands more for infrastructure. Quantization can enable good proof-of-concept, or even fully fledged deployments with less spectacular (but still high performance) hardware.
In the sections to follow, we will dissect the concept of quantization, its methodologies, and its significance in bridging the gap between the highly resource-intensive nature of LLMs and the practicalities of everyday technology use. The transformative power of LLMs can become a staple in smaller-scale applications, offering vast benefits to a broader audience.
Basics of quantization
Quantizing a large language model refers to the process of reducing the precision of numerical values used in the model. In the context of neural networks and deep learning models, including large language models, numerical values are typically represented as floating-point numbers with high precision (e.g., 32-bit or 16-bit floating-point format). Read more about Floating Point Precision here.
Quantization addresses this by converting these high-precision floating-point numbers into lower-precision representations, such as 16- or 8-bit integers to make the model more memory-efficient and faster during both training and inference by sacrificing precision. As a result, the training and inferencing of the model requires less storage, consumes less memory, and can be executed more quickly on hardware that supports lower-precision computations.
Types of quantization
To add depth and complexity to the topic, it is critical to understand that quantization can be applied at various stages in the lifecycle of a model’s development and deployment. Each method has its distinct advantages and trade-offs and is selected based on the specific requirements and constraints of the use case.
1. Static quantization
Static quantization is a technique applied during the training phase of an AI model, where the weights and activations are quantized to a lower bit precision and applied to all layers. The weights and activations are quantized ahead of time and remain fixed throughout. Static quantization is great for known memory requirements of the system the model is planning to be deployed to.
Pros of Static Quantization
Simplifies deployment planning as the quantization parameters are fixed.
Reduces model size, making it more suitable for edge devices and real-time applications.
Cons of Static Quantization
Performance drops are predictable; so certain quantized parts may suffer more due to a broad static approach.
Limited adaptability for static quantization for varying input patterns and less robust update to weights.
2. Dynamic quantization
Dynamic Quantization involves quantizing weights statically, but activations are quantized on the fly during model inference. The weights are quantized ahead of time, while the activations are quantized dynamically as data passes through the network. This means that quantization of certain parts of the model are executed on different precisions as opposed to defaulting to a fixed quantization.
Pros of Dynamic Quantization
Balances model compression and runtime efficiency without significant drop in accuracy.
Useful for models where activation precision is more critical than weight precision.
Cons of Dynamic Quantization
Performance improvements aren’t predictable compared to static methods (but this isn’t necessarily a bad thing).
Dynamic calculation means more computational overhead and longer train and inference times than the other methods, while still being lighter weight than without quantization
3. Post-training quantization (PTQ)
In this technique, quantization is incorporated into the training process itself. It involves analyzing the distribution of weights and activations and then mapping these values to a lower bit depth. PTQ is deployed on resource-constrained devices like edge devices and mobile phones. PTQ can be either static or dynamic.
Pros of PTQ
Can be applied directly to a pre-trained model without the need for retraining.
Reduces the model size and decreases memory requirements.
Improved inference speeds enabling faster computations during and after deployment.
Cons of PTQ
Potential loss in model accuracy due to the approximation of weights.
Requires careful calibration and fine tuning to mitigate quantization errors.
May not be optimal for all types of models, particularly those sensitive to weight precision.
4. Quantization aware training (QAT)
During training, the model is aware of the quantization operations that will be applied during inference and the parameters are adjusted accordingly. This allows the model to learn to handle quantization induced errors.
Pros of QAT
Tends to preserve model accuracy compared to PTQ since the model training accounts for quantization errors during training.
More robust for models sensitive to precision and is better at inferencing even on lower precisions.
Cons of QAT
Requires retraining the model resulting in longer training times.
More computationally intensive since it incorporates quantization error checking.
5. Binary ternary quantization
These methods quantize the weights to either two values (binary) or three values (ternary), representing the most extreme form of quantization. Weights are constrained to +1, -1 for binary, or +1, 0, -1 for ternary quantization during or after training. This would drastically reduce the number of possible quantization weight values while still being somewhat dynamic.
Pros of Binary Ternary Quantization
Maximizes model compression and inferencing speed and has minimal memory requirements.
Fast inferencing and quantization calculations enables usefulness on underpowered hardware.
Cons of Binary Ternary Quantization
High compression and reduced precision results in a significant drop in accuracy.
Not suitable for all types of tasks or datasets and struggles with complex tasks.
The benefits & challenges of quantization
The quantization of Large Language Models brings forth multiple operational benefits. Primarily, it achieves a significant reduction in the memory requirements of these models. Our goal for post-quantization models is for the memory footprint to be notably smaller. Higher efficiency permits the deployment of these models on platforms with more modest memory capabilities and decreasing the processing power needed to run the models once quantized translates directly into heightened inference speeds and quicker response times that enhance user experience.
On the other hand, quantization can also introduce some loss in model accuracy since it involves approximating real numbers. The challenge is to quantize the model without significantly affecting its performance. This can be done with testing the model’s precision and time of completion before and after quantization with your models to gauge effectiveness, efficiency, and accuracy.
By optimizing the balance between performance and resource consumption, quantization not only broadens the accessibility of LLMs but also contributes to more sustainable computing practices.
In this third part of the solution, we discuss how to implement a GraphRAG. This implementation needs an understanding of Langchain which we shall also discuss. As we have discussed, the combination of Knowledge Graphs and vector databases brings the ability to manage both structured and unstructured information. To implement the end to end solution, we use Langchain.
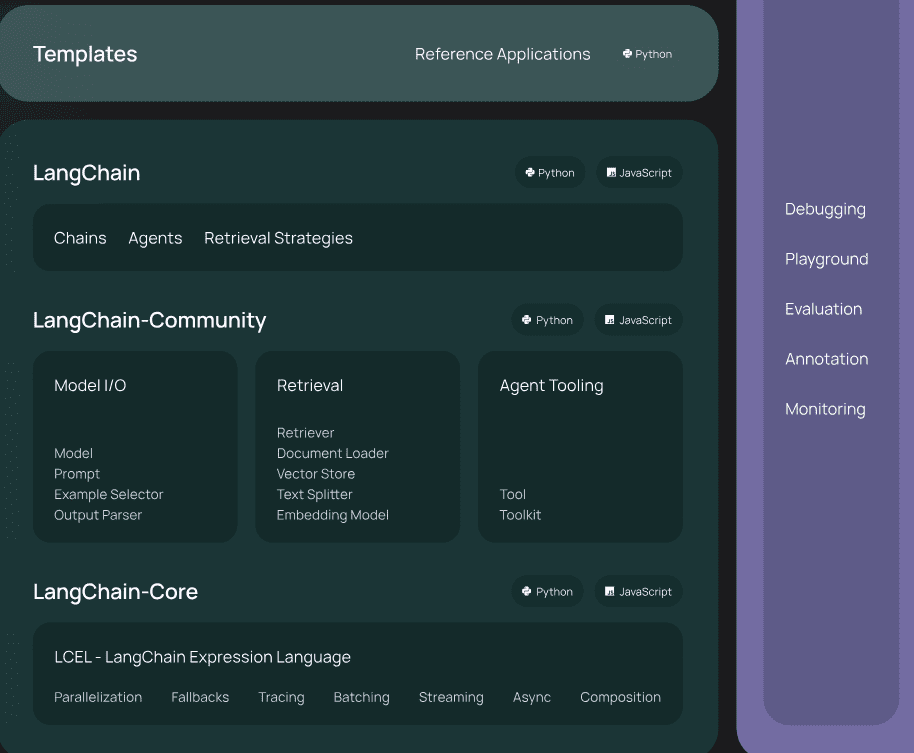
The LangChain framework consists of several components designed to streamline the development of applications using large language models (LLMs).
Model I/O: These components are responsible for formatting and managing inputs and outputs for language models. This includes handling prompts and managing different model interfaces like chat models and text completion models.
Sample Model I/O components include:
Prompts: They format user input into structured queries that guide the generation process of LLMs.
Chat Models: Designed for conversation-based interactions, these models handle input as a sequence of chat messages and return responses in a similar format.
LLMs: Traditional language models that take plain text as input and return text as output, suitable for straightforward query-response setups
Retrieval: This part of the framework handles the interfacing with application-specific data. It includes components like document loaders which fetch data, text splitters to adapt documents for specific uses, embedding models to generate text vector representations for natural language search, and retrievers that find documents based on unstructured queries
Sample Retrieval components include
Document Loaders: These components load data from various sources to be used by the application, organizing it into usable formats.
Text Splitters: They split documents into smaller segments, making them more manageable for processing by LLMs.
Embedding Models: Generate vector representations of text, facilitating the search and retrieval of information based on semantic similarities.
Retrievers: Fetch relevant documents or data in response to unstructured queries, using the embeddings created by the models
Composition: These are higher-level components that combine different systems or LangChain primitives. This includes tools which allow an LLM to interact with external systems, agents which select tools based on directives, and chains, which are compositions of other components to perform specific tasks
Sample Composition components include
Tools: Interfaces that allow LLMs to interact with external systems or databases, enhancing their functionality.
Agents: Decision-making components that select and manage the use of various tools based on the application’s needs.
Chains: Configurable sequences of operations that link different tools and models to perform complex tasks
Additional Components: LangChain also includes elements for managing application memory to persist state across sessions, and callbacks for logging and streaming the steps in a process.
Each component is designed to be modular, allowing developers to use them in isolation or integrate them into larger systems. This flexibility makes LangChain a versatile tool for building sophisticated applications powered by advanced language models.
To build an end-to-end application using large language models (LLMs) with the LangChain framework, developers typically follow a structured process that leverages various components of LangChain to handle different aspects of the application. Here’s a generalized step-by-step guide:
Defining the Use Case and Requirements: Identify what you need the LLM application to do, including the types of interactions and the expected outputs.
Model Selection and Integration: Choose the appropriate LLM (like GPT or a domain-specific model) based on your needs.
Input/Output Management: Utilize LangChain’s Model I/O components to format and manage the inputs and outputs of your LLM.
Data Retrieval and Management: Use document loaders to fetch data, embedding models to create searchable text vectors, and retrievers to find relevant information based on queries.
Composition of Components: Combine different LangChain components like tools, agents, and chains to build more complex interactions. For instance, you might use an agent to decide dynamically which tools to use based on the user’s input or the context provided by previous interactions
By following these steps, developers can leverage the powerful components of LangChain to build robust, scalable, and effective LLM applications tailored to specific needs. This approach allows for flexibility in integrating various data sources, LLM providers, and external systems, ensuring that the final application is well-suited to the intended tasks and user expectations.
With this understanding, lets now explore how the GraphRAG solution can be implemented using neo4j
In the data ingestion phase, we use the langchain loaders to fetch and split the documents
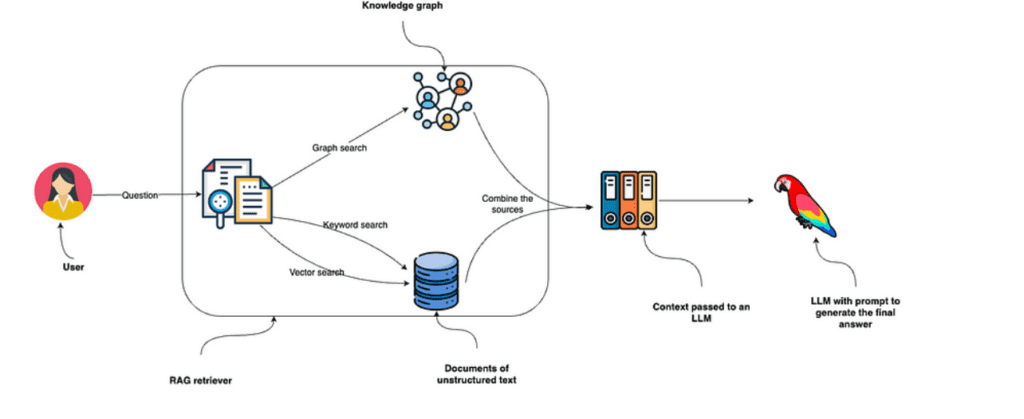
The user’s question is directed at RAG retriever. This retriever employs keyword and vector searches to search through unstructured text data and combines it with the information it collects from the knowledge graph.
The collected data from these sources is fed into an LLM to generate and deliver the final answer.
You could also implement a Graph only search
Image source: Enhancing the Accuracy of RAG Applications With Knowledge Graphs
The code is available on GitHub.
References:
Tomaz Bratanic
Enhancing the Accuracy of RAG Applications With Knowledge Graphs
AI makes workers more productive, but we are still lacking in regulations, according to new research. The 2024 AI Index Report, published by the Stanford University Human-Centered Artificial Intelligence institute, has uncovered the top eight AI trends for businesses, including how the technology still does not best the human brain on every task.
TechRepublic digs into the business implications of these takeaways, with insight from report co-authors Robi Rahman and Anka Reuel.
SEE: Top 5 AI Trends to Watch in 2024
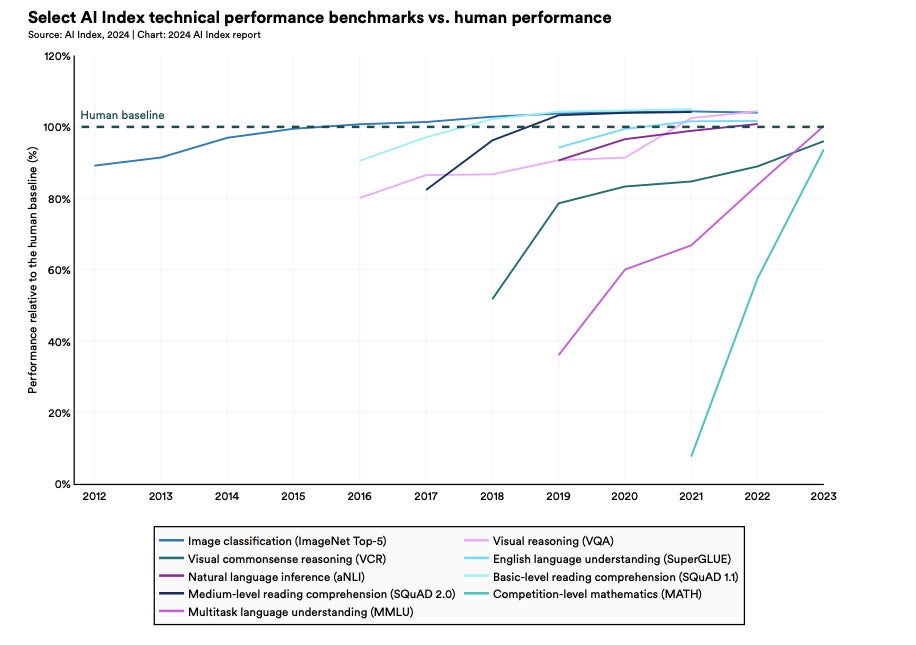
1. Humans still outperform AI on many tasks
According to the research, AI is still not as good as humans at the complex tasks of advanced-level mathematical problem solving, visual commonsense reasoning and planning (Figure A). To draw this conclusion, models were compared to human benchmarks in many different business functions, including coding, agent-based behaviour, reasoning and reinforcement learning.
Figure A
Performance of AI models in different tasks relative to humans. Image: AI Index Report 2024/Stanford University HAI
While AI did surpass human capabilities in image classification, visual reasoning and English understanding, the result shows there is potential for businesses to utilise AI for tasks where human staff would actually perform better. Many businesses are already concerned about the consequences of over-reliance on AI products.
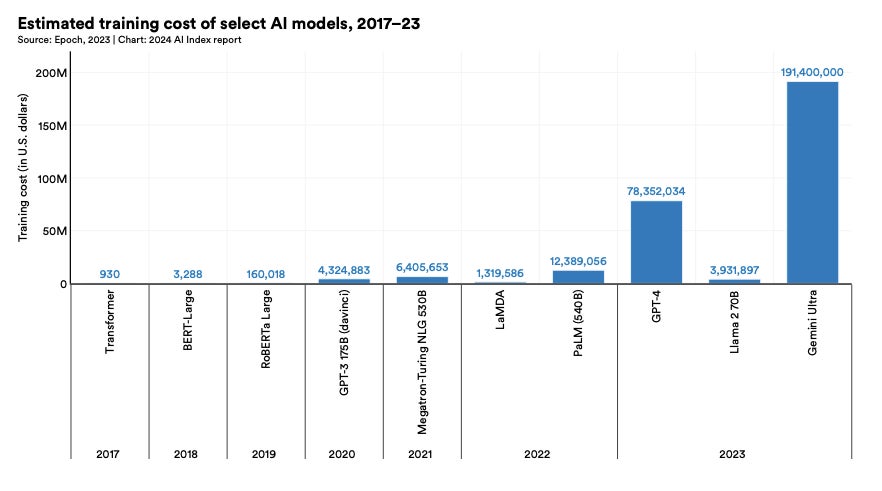
2. State-of-the-art AI models are getting more expensive
The AI Index reports that OpenAI’s GPT-4 and Google’s Gemini Ultra cost approximately $78 million and $191 million to train in 2023, respectively (Figure B). Data scientist Rahman told TechRepublic in an email: “At current growth rates, frontier AI models will cost around $5 billion to $10 billion in 2026, at which point very few companies will be able to afford these training runs.”
Figure B
Training costs of AI models, 2017 to 2023. Image: AI Index Report 2024/Stanford University HAI/Epoch, 2023
In October 2023, the Wall Street Journal published that Google, Microsoft and other big tech players were struggling to monetize their generative AI products due to the massive costs associated with running them. There is a risk that, if the best technologies become so expensive that they are solely accessible to large corporations, their advantage over SMBs could increase disproportionately. This was flagged by the World Economic Forum back in 2018.
However, Rahman highlighted that many of the best AI models are open source and thus available to businesses of all budgets, so the technology should not widen any gap. He told TechRepublic: “Open-source and closed-source AI models are growing at the same rate. One of the largest tech companies, Meta, is open-sourcing all of their models, so people who cannot afford to train the largest models themselves can just download theirs.”
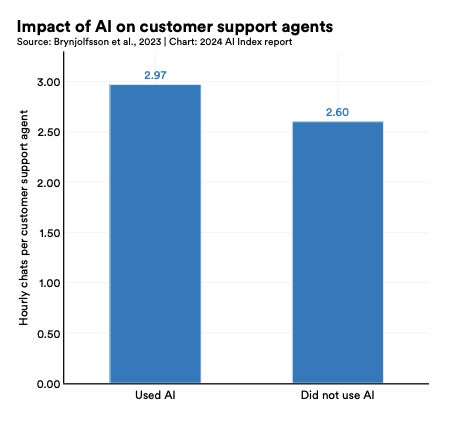
3. AI increases productivity and work quality
Through evaluating a number of existing studies, the Stanford researchers concluded that AI enables workers to complete tasks more quickly and improves the quality of their output. Professions this was observed for include computer programmers, where 32.8% reported a productivity boost, consultants, support agents (Figure C) and recruiters.
Figure C
Impact of AI on customer support agent productivity. Image: AI Index Report 2024/Stanford University HAI/Brynjolfsson et al., 2023
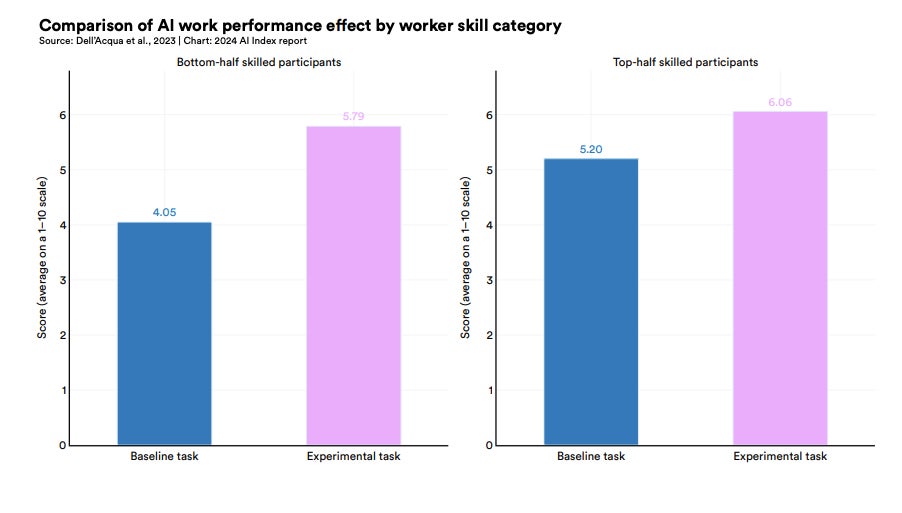
In the case of consultants, the use of GPT-4 bridged the gap between low-skilled and high-skilled professionals, with the low-skilled group experiencing more of a performance boost (Figure D). Other research has also indicated how generative AI in particular could act as an equaliser, as the less experienced, lower skilled workers get more out of it.
Figure D
Improvement of work performance on low- and high-skilled consultants when using AI. Image: AI Index Report 2024/Stanford University HAI
However, other studies did suggest that “using AI without proper oversight can lead to diminished performance,” the researchers wrote. For example, there are widespread reports that hallucinations are prevalent in large language models that perform legal tasks. Other research has found that we may not reach the full potential of AI-enabled productivity gains for another decade, as unsatisfactory outputs, complicated guidelines and lack of proficiency continue to hold workers back.
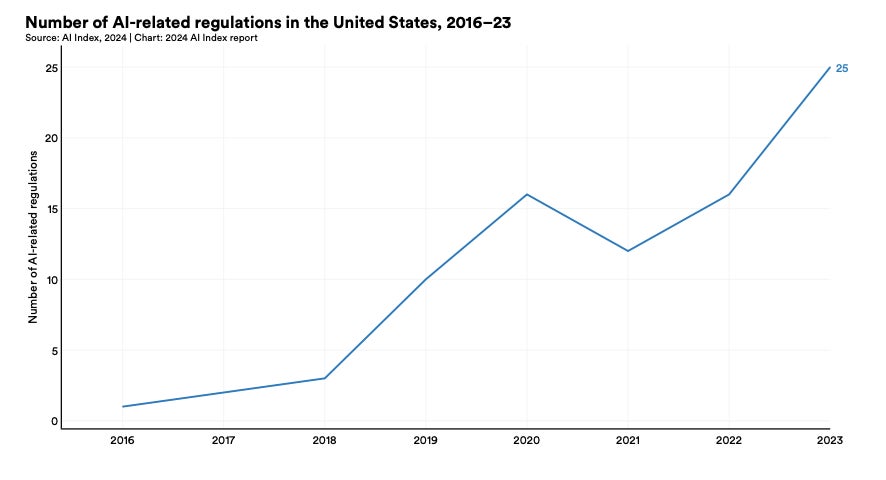
4. AI regulations in the U.S. are on the rise
The AI Index Report found that, in 2023, there were 25 AI-related regulations active in the U.S., while in 2016 there was only one (Figure E). This hasn’t been a steady incline, though, as the total number of AI-related regulations grew by 56.3% from 2022 to 2023 alone. Over time, these regulations have also shifted from being expansive regarding AI progress to restrictive, and the most prevalent subject they touch on is foreign trade and international finance.
Figure E
Number of AI-related regulations active in the U.S. between 2016 and 2023. Image: AI Index Report 2024/Stanford University HAI
AI-related legislation is also increasing in the EU, with 46, 22 and 32 new regulations being passed in 2021, 2022 and 2023, respectively. In this region, regulations tend to take a more expansive approach and most often cover science, technology and communications.
SEE: NIST Establishes AI Safety Consortium
It is essential for businesses interested in AI to stay updated on the regulations that impact them, or they put themselves at risk of heavy non-compliance penalties and reputational damage. Research published in March 2024 found that only 2% of large companies in the U.K. and EU were aware of the incoming EU AI Act.
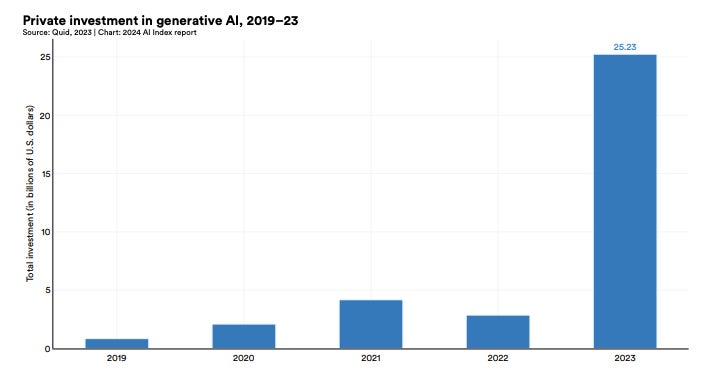
5. Investment in generative AI is increasing
Funding for generative AI products that generate content in response to a prompt nearly octupled from 2022 to 2023, reaching $25.2 billion (Figure F). OpenAI, Anthropic, Hugging Face and Inflection, amongst others, all received substantial fundraising rounds.
Figure F
Total global private investment in generative AI from 2019 to 2023. Image: AI Index Report 2024/Stanford University HAI/Quid, 2023
The buildout of generative AI capabilities is likely to meet demand from businesses looking to adopt it into their processes. In 2023, generative AI was cited in 19.7% of all earnings calls of Fortune 500 companies, and a McKinsey report revealed that 55% of organisations now use AI, including generative AI, in at least one business unit or function.
Awareness of generative AI boomed after the launch of ChatGPT on November 30, 2022, and since then, organisations have been racing to incorporate its capabilities into their products or services. A recent survey of 300 global businesses conducted by MIT Technology Review Insights, in partnership with Telstra International, found that respondents expect their number of functions deploying generative AI to more than double in 2024.
SEE: Generative AI Defined: How it Works, Benefits and Dangers
However, there is some evidence that the boom in generative AI “could come to a fairly swift end”, according to leading AI voice Gary Marcus, and businesses should be wary. This is primarily due to limitations in current technologies, such as potential for bias, copyright issues and inaccuracies. According to the Stanford report, the finite amount of online data available to train models could exacerbate existing issues, placing a ceiling on improvements and scalability. It states that AI firms could run out of high-quality language data by 2026, low-quality language data in two decades and image data by the late 2030s to mid-2040s.
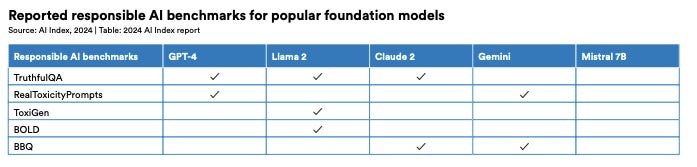
6. Benchmarks for LLM responsibility vary widely
There is significant variation in the benchmarks that tech companies evaluate their LLMs against when it comes to trustworthiness or responsibility, according to the report (Figure G). The researchers wrote that this “complicates efforts to systematically compare the risks and limitations of top AI models.” These risks include biassed outputs and leaking private information from training datasets and conversation histories.
Figure G
The responsible AI benchmarks used in the development of popular AI models. Image: AI Index Report 2024/Stanford University HAI
Reuel, a PhD student in the Stanford Intelligent Systems Laboratory, told TechRepublic in an email: “There are currently no reporting requirements, nor do we have robust evaluations that would allow us to confidently say that a model is safe if it passes those evaluations in the first place.”
Without standardisation in this area, the risk that some untrustworthy AI models may slip through the cracks and be integrated by businesses increases. “Developers might selectively report benchmarks that positively highlight their model’s performance,” the report added.
Reuel told TechRepublic: “There are multiple reasons why a harmful model can slip through the cracks. Firstly, no standardised or required evaluations making it hard to compare models and their (relative) risks, and secondly, no robust evaluations, specifically of foundation models, that allow for a solid, comprehensive understanding of the absolute risk of a model.”
7. Employees are nervous and concerned about AI
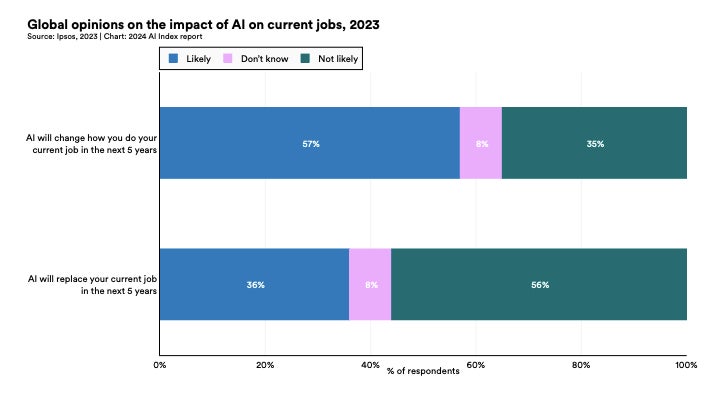
The report also tracked how attitudes towards AI are changing as awareness increases. One survey found that 52% express nervousness towards AI products and services, and that this figure had risen by 13% over 18 months. It also found that only 54% of adults agree that products and services using AI have more benefits than drawbacks, while 36% are fearful it may take their job within the next five years (Figure H).
Figure H
Global opinions on the impact AI will have on current jobs in 2023. Image: AI Index Report 2024/Stanford University HAI/Ipsos, 2023
Other surveys referenced in the AI Index Report found that 53% of Americans currently feel more concerned about AI than excited, and that the joint most common concern they have is its impact on jobs. Such worries could have a particular impact on employee mental health when AI technologies start to be integrated into an organisation, which business leaders should monitor.
SEE: The 10 Best AI Courses in 2024
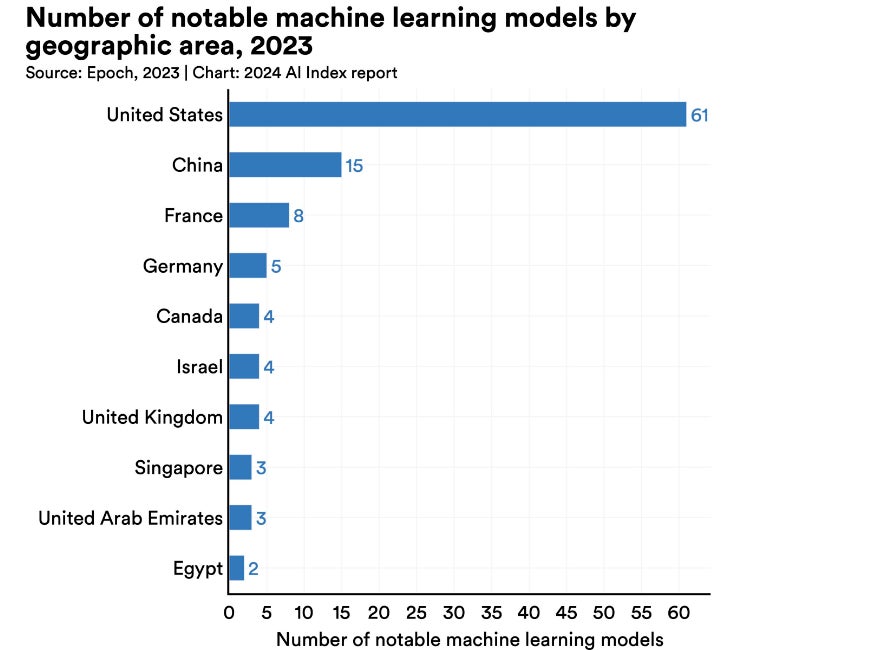
8. US and China are creating most of today’s popular LLMs
TechRepublic’s Ben Abbott covered this trend from the Stanford report in his article about building AI foundation models in the APAC region. He wrote, in part:
“The dominance of the U.S. in AI continued throughout 2023. Stanford’s AI Index Report released in 2024 found 61 notable models had been released in the U.S. in 2023; this was ahead of China’s 15 new models and France, the biggest contributor from Europe with eight models (Figure I). The U.K. and European Union as a region produced 25 notable models — beating China for the first time since 2019 — while Singapore, with three models, was the only other producer of notable large language models in APAC.”
Figure I
The U.S. is outpacing China and other countries in the development of AI models. Image: Epoch
Properly managing data is more essential than ever. Organizations now operate among a complicated web of business applications, ushering in extensive amounts of analytical information that can quickly become unwieldy. Without the right oversight, companies miss out on the chance to make the most of this data to drive smarter decision making, strategic planning and even reduce costs. The growing use of generative AI, machine learning and other emerging technologies are posed to transform data management but how can businesses best leverage these platforms to glean the most business value and risk assessment? In the upcoming Data Management: Navigating Opportunities for Success summit, leading experts in the field will discuss the latest data management strategies as well as what’s next in data analytics and architecture.
The adoption of zero trust has surged in recent years, driven by two main factors: 1). A wave of high-profile data breaches that highlighted the need for enhanced cybersecurity strategies and 2). The COVID-19 pandemic created the need for remote access technologies beyond VPN. While the zero trust model can be highly beneficial, it does have some challenges. That’s why making zero trust cybersecurity as effective as possible starts by understanding its challenges. In the upcoming The Zero Trust Journey: From Concept to Implementation summit, industry leaders, experts and practitioners provide resources and recommendations to help you build a zero trust framework.
Top Stories
Implementing AI in K-12 education April 22, 2024 by Dan Wilson In the latest episode of the AI Think Tank Podcast, we ventured into the rapidly evolving intersection of artificial intelligence and K-12 education. I was fortunate to host a discussion that not only explored the transformative potentials of AI in educational settings but also tackled the complexities and ethical concerns that come with such technological integration. Joining me were friends Rebecca Bultsma and Ahmad Jawad, two notable experts who brought a wealth of knowledge and insight to our conversation.
Understanding GraphRAG – 3 Implementing a GraphRAG solution April 22, 2024 by Ajit Jaokar In this third part of the solution, we discuss how to implement a GraphRAG. This implementation needs an understanding of Langchain which we shall also discuss. As we have discussed, the combination of Knowledge Graphs and vector databases brings the ability to manage both structured and unstructured information.
Quantization and LLMs – Condensing models to manageable sizes April 19, 2024 by Kevin Vu The scale and complexity of LLMs The incredible abilities of LLMs are powered by their vast neural networks which are made up of billions of parameters. These parameters are the result of training on extensive text corpora and are fine-tuned to make the models as accurate and versatile as possible.
In-Depth
How to implement big data for your company April 23, 2024 by Yana Ihnatchyck Big data analytics empowers organizations to get valuable insights from vast and intricate data sets, offering a pathway to improved decision-making, excellent performance, and competitive advantage. As the volume of global data surges, exemplified by the expected 167 exabytes of monthly mobile traffic by 2024, the rise of analytics offers immense potential.
Understanding GraphRAG – 2 addressing the limitations of RAG April 22, 2024 by Ajit Jaokar Background We follow on from the last post and explore the limitations of RAG and how you can overcome these limitations using the idea of a GRAPHRAG. The GRAPHRAG combines a knowledge graph with a RAG. Thus, the primary construct of the GRAPHRAG is a knowledge graph.
How predictive analytics improves payment fraud detection April 22, 2024 by Zachary Amos Payment fraud is a significant issue for banks, customers, government agencies and others. However, advanced predictive analytics tools can reduce or eliminate it. Minimizing false alarms Many people have had the embarrassing experience of trying to pay for something and having the transaction flagged.
Diffusion and denoising – Explaining text-to-image generative AI April 19, 2024 by Kevin Vu The concept of diffusion Denoising diffusion models are trained to pull patterns out of noise, to generate a desirable image. The training process involves showing model examples of images (or other data) with varying levels of noise determined according to a noise scheduling algorithm, intending to predict what parts of the data are noise.
How data impacts the digitalization of industries April 18, 2024 by Jane Marsh Since data varies from industry to industry, its impact on digitalization efforts differs widely — a utilization strategy that works in one may be ineffective in another. How does the variety and availability of information impact the digital transformation process in various fields?
DSC Weekly 16 April 2024 April 16, 2024 by Scott Thompson Read more of the top articles from the Data Science Central community.








 APPLE VISON PRO ADOPTED BY BRAZILIAN SURGEON
APPLE VISON PRO ADOPTED BY BRAZILIAN SURGEON