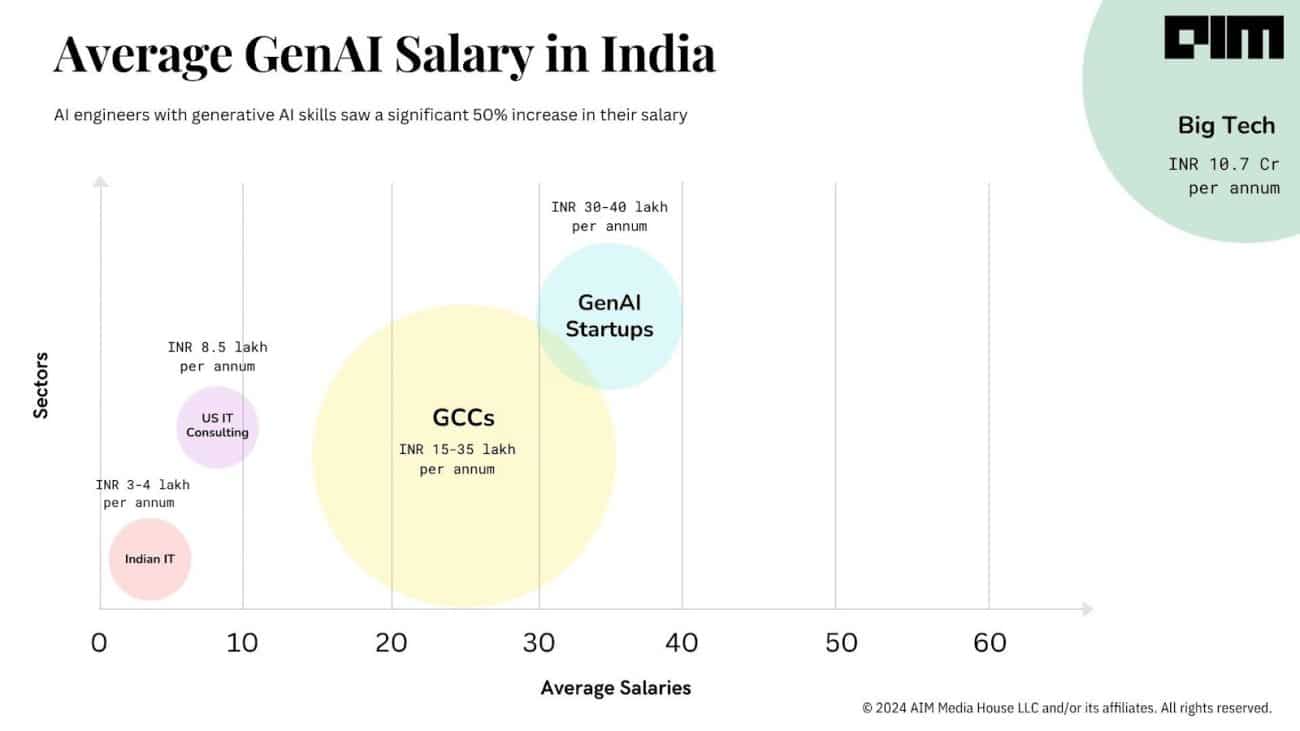
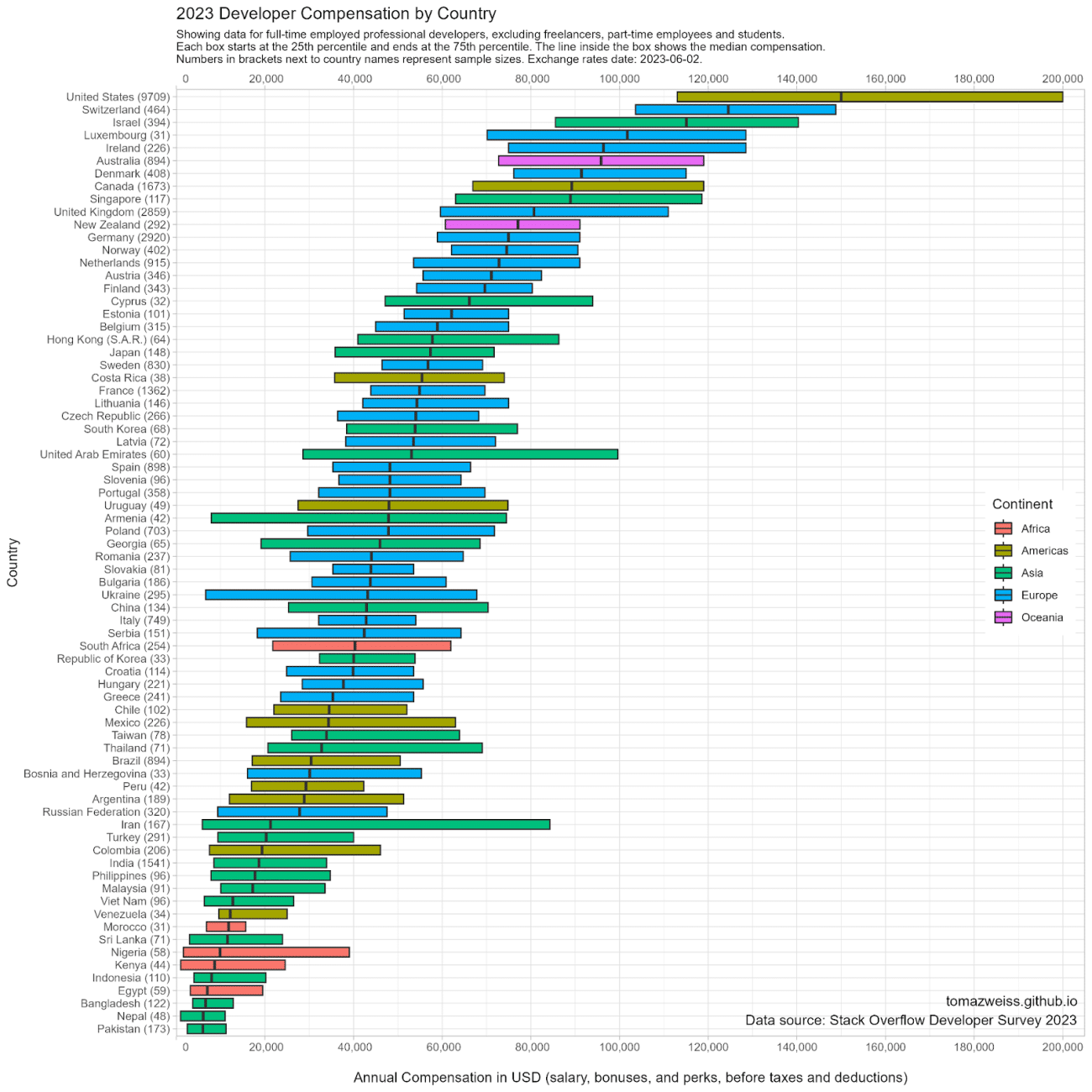
For over a decade, a popular belief has been that a computer science degree is all you need to tread the path to wealth, especially in a country like India.
If you looked around then, everyone and their neighbour pursued engineering college degrees to land software engineer jobs. Cut to 2024, things are slowly changing.
“Winter is coming for software engineering,” said Deedy Das from Menlo Ventures, sharing a graph (see below) about how by 2024, software engineering roles will almost become a distant memory.
The graph clearly shows that there was a boom in hiring tech talent back in 2021, which has now dropped to 40% of it in 2024. Added to this are the layoffs in big tech, such as the recent one where Google decided to lay off its Python programmers for outsourcing to cheaper options.
Even startups, one of the biggest providers of jobs to developers, are now preferring to hire tenured people with expertise. “Startups often dislike hiring new grads because the cost to train them and get them up to speed is quite high,” explained Das in the post, adding that freshers with knowledge about new technologies such as AI are preferred.
It seems like AI is stealing jobs indeed. There are a lot of CS majors who are no longer able to find jobs as now everyone wants to be a programmer. With AI tools in the market, it has become easier to become a programmer, and the barrier to entry has reduced significantly, making everyone want to do something with software.
What about more jobs?
Das said that people would migrate from software for a little bit and then come back during the next boom cycle, just like AI. Isaac Hasson suggested developers to stop studying pure computer science and get skilled in other disciplines such as biology and chemistry, which he said are all going to transform pretty soon as well.
This is what Yann LeCun, the chief of AI at Meta, posted on X about a year back. It takes at least 15-20 years to have an effect on productivity. The delay is determined by how fast people learn and adapt to it. “So no, AI is not going to cause instant mass unemployment,” LeCun concluded. “It is only going to displace jobs over time and make people more productive,” just like any other technological revolution.
On the other hand, several predictions suggest that there will be many more jobs in the future. According to Francois Chollet, the creator of Keras, “There will be more software engineers (the kind that write code, e.g., Python, C or JavaScript code) in five years than there are today.” He adds that the estimated number of professional software engineers today is 26 million, which would jump to 30-35 million in five years.
For context, he said that many are currently claiming that people shouldn’t get into computer science because, in the future, most of the software engineering will be done by AI, the likes of Devin, Devika, and the recent GitHub Workspace update. In the latest podcast with Lex Fridman, when asked how much programming people would do in the next 5-10 years, OpenAI CEO Sam Altman said, “A lot, but I think it’ll be in a very different shape.”
Similarly, a user Bjoern said, “ I see AI as the fracking tech of software engineering that allows us to extract enormous amounts of previously inaccessible oil,” which he said are the long tail of software use cases that were not available before. “We will need more software engineers to decide what to build, how to scale things, and how to maintain that long tail of complexity.”
Computer science is not all you need
The number of CS majors in universities have increased exponentially over the last decade and the trend seems to increase even more. But the problem is that people are applying for software engineering roles while relying completely on AI and Copilot tools, which are not enough to get jobs in the market.
An entire generation is studying for jobs that won’t exist. Mark Cuban last year predicted that the highest-paying college major in the world, computer science, will hold very little value for employers in the future. “Twenty years from now, if you are a coder, you might be out of a job,” he said in a podcast.
One of the most important things that Altman and LeCun agree upon is that humans should be trained with AI and use them as copilots. Well, the most-celebrated phrase across 2023 has been, “AI won’t take your job, it’s somebody using AI that will take your job.” And, “you will be 10x more valuable in the coming years”, as Logan Kilpatrick said on X.
“The best practitioners of the craft will use multiple tools and they’ll do some work in natural language,” he added. Altman explained that people would be able to focus on the higher level of abstractions, and the puzzle-solving skill set of programming, which Fridman agreed, was the harder part.
Furthermore, implying that a lot of software engineering jobs would be redundant is dangerous as many students would not know if they should attend college at all.
The post Software Engineering Jobs are Dying appeared first on Analytics India Magazine.