Andrew Ng’s DeepLearning.AI has announced a free short course on Prompt Engineering for Vision Models, offered in collaboration with Comet ML. This course is intended to give a comprehensive introduction to the concept of prompt engineering, specifically tailored for vision models.
It is one one-hour course under instruction by Abby Morgan (ML Engineer), Jacques Verré (Head of Product) and Caleb Kaiser (ML Engineer). To get the most out of this course, it is recommended to have a Python experience.
To stay relevant on the bleeding edge, you will promote different vision models, such as Meta’s Segment Anything Model (SAM), a universal image segmentation model, OWL-ViT, a zero-shot object detection model, and Stable Diffusion 2.0.
Participants will gain knowledge of how they can generate images efficiently using hyperparameters like strength, guidance scale, and number of inference steps.
Furthermore, you can select specific parts of an image by providing coordinates or drawing a box around the area you want to isolate and by combining all of these, you will be able to replace objects within an image with generated content.
The best part is you can generate custom images based on pictures of people or places that you provide using a fine-tuning technique called DreamBooth.
This course will utilise Comet, a library to track experiments and optimise visual prompt engineering workflows.
Previously, Andrew Ng had partnered with Google Cloud for the LLMOps to equip learners with the practical skills and knowledge needed to work with LLMs and build LLMOps pipelines in real-world applications.
The post Andrew Ng, Comet Partner for New Course on Prompt Engineering for Vision Models appeared first on Analytics India Magazine.
Digitisation has paved the way for data science to swiftly become a highly sought-after career path. Businesses worldwide are eager to harness the power of data professionals to maximise their data’s potential and improve business performance.
As AI and data science become crucial across all types of organisations, pursuing a career in this field has become easier. To meet this rising demand, esteemed institutions such as the IITs and IIMs have begun integrating departments focused on data science and AI, offering courses at different proficiency levels.
We have carefully curated a list of institutions in India that teach data science and artificial intelligence.
Wadhwani School of Data Science and Artificial Intelligence, IIT Madras
Just a few months ago, Sunil Wadhwani, a distinguished alumnus of IIT Madras and co-founder of iGATE and Mastech Digital, donated ₹110 crore to establish the Wadhwani School of Data Science. It endeavours to impart knowledge not only on the intricacies of AI algorithms, but also the underlying systems driving AI, along with proficiency in data gathering and management.
The curriculum is structured into four main components: Foundational sciences, modelling techniques, training and deploying models, and ultimately, integrating these insights into real-world applications.
The school offers a diverse range of courses, including BTech and MTech programs in data science and AI, an interdisciplinary dual degree program in data science, MS and PhD programs, a joint MSc in data science and AI with the University of Birmingham, and a web-enabled MTech program in industrial AI.
Recently, Balraman Ravindran shared a post unveiling his journey at Wadhwani School.
Centre for Machine Intelligence and Data Science, IIT Mumbai
The Centre for Machine Intelligence and Data Science (C-MInDS) is at the forefront of AI and ML exploration. Through groundbreaking research, academic programs, and strong industry collaborations, C-MInDS is expanding the horizons of these technologies and exploring their real-world uses.
Their academic offerings span a wide spectrum, catering to students at various stages of their educational journey. From foundational courses in AI for undergraduates to advanced postgraduate and doctoral studies, they provide a comprehensive range of programs.
Yardi School of Artificial Intelligence, IIT Delhi
The Yardi School of Artificial Intelligence (Yardi ScAI) was established in September 2020 at IIT Delhi with a mission to advance education and research in artificial intelligence, machine learning, and data science, along with their diverse applications in fields such as healthcare, materials science, robotics, industry 4.0, weather prediction, and transportation.
This interdisciplinary school boasts support from over 40 faculty members across various departments, reflecting its broad focus on applications. Yardi ScAI offers a range of programs, their MINDS program caters to industry needs, while the MS(R) program is tailored for those inclined towards research.
Machine Intelligence and Robotics COE (MINRO), IIIT Bangalore
The MINRO Center has a broad mandate: to conduct top-tier research in machine intelligence and robotics, with the aim of producing groundbreaking innovations that benefit both Karnataka and the nation.
The centre is dedicated to multidisciplinary research and development across key areas such as machine intelligence, artificial intelligence systems, data analysis, data science, pattern recognition, human-machine interface, and industrial products related to robotics and automation.
Mehta Family School of Data Science and Artificial Intelligence, IIT Guwahati
Established in 2021 at IIT Guwahati and supported by the Mehta Family Foundation, the school aims to become a leading institution dedicated to generating knowledge through the analysis of diverse datasets and the development of intelligence engineering methodologies.
Since its inception, the school has introduced BTech and PhD programs in Data Science & Artificial Intelligence. Building on this foundation, in 2023, Mehta Family expanded their offerings to include an MTech program in Data Science, offered jointly with the departments of mathematics and electrical engineering.
The Centre of Excellence in Artificial Intelligence (CoEAI), IIT Kharagpur
Established in 2018, the AI and ML Innovations Centre at IIT Kharagpur, leverages the drive to transform change across industries and society through the power of AI. The efforts are concentrated in four pivotal domains: pioneering research, advanced education, collaborative industry endeavours, and vibrant entrepreneurship.
The academic offerings include PhD, MTech, Dual Degree (MTech), and micro-specialisation programs, providing a comprehensive educational landscape for aspiring AI and ML enthusiasts.
NV AI Centre and KRIYA, IIT Hyderabad
The AI department at IIT Hyderabad has gained acclaim for its groundbreaking work in AI and research. This recognition extends to its comprehensive educational programs spanning BTech, MTech, and PhD studies in AI.
A Center for Research and Innovation in AI (क्रिया) has been entrenched to bolster the department’s research activities. This AI क्रिया Center not only provides spaces for collaboration such as seating areas, classrooms, and conference rooms but also hosts a mini-data centre.
Featuring a range of GPU servers, including the advanced NVIDIA DGX1 and DGX2 deep learning supercomputers, the data centre delivers a staggering 250 TFlops of GPU computing power. Such capabilities empower faculty, research personnel, and students to conduct state-of-the-art AI research on-site.
The post 7 Leading Data Science and AI Institutes in India appeared first on Analytics India Magazine.
In a bid to expand its data science team, Indian e-commerce brand Myntra is hiring a data scientist to work on cutting-edge AI and ML-based solutions.
As a data scientist at Myntra, you’ll be responsible for the design, development, and deployment of ML models and algorithms to tackle complex business challenges across various domains such as RecSys, search, vision, SCM, pricing, forecasting, trend and virality prediction, and generative AI. Furthermore, you’ll play a crucial role in ensuring the reliability and robustness of software solutions for model deployment while supporting ML pipelines, including tasks such as data cleaning, feature extraction, and basic model training.
The basic qualifications for this role include a Master’s or PhD in computer science, mathematics, statistics, or related fields, or alternatively, over one year of relevant industry experience coupled with a bachelor’s degree. Proficiency in Python or an equivalent high-level programming language is essential, alongside a theoretical understanding of statistical models and machine learning algorithms. Strong written and verbal communication skills are also recommended.
Alongside, the preferred qualifications encompass prior experience with ML frameworks such as TensorFlow, PyTorch, or scikit-learn, as well as basic familiarity with statistical methods as they pertain to machine learning. Additionally, proficiency in SQL and/or NoSQL databases is advantageous, along with any experience with ML orchestration tools or exposure to GenAI models.
Inside Myntra’s Data Science Team
Myntra’s expansive data science team, known for being one of the largest in the nation, is the driving force behind the company’s multifaceted operations and business success, with a major portion of its solutions subject to AB testing for efficacy. The company recently came up with MyFashionGPT – an LLM-based chatbot that responds to user queries and not only understands the natural language but also offers tailored recommendations based on customer queries.
The team also delivers a plethora of data-driven solutions, strategically deployed across diverse customer touchpoints on a quarterly basis, resulting in substantial impacts on revenue generation and enhancing customer experiences.
These solutions consist of real-time, near-real-time, and offline functionalities, each tailored to meet specific latency requirements.
If you think you are fit for the role, apply here.
Read more: Data Science Hiring Process At Myntra
The post Myntra is Hiring Data Scientists appeared first on Analytics India Magazine.
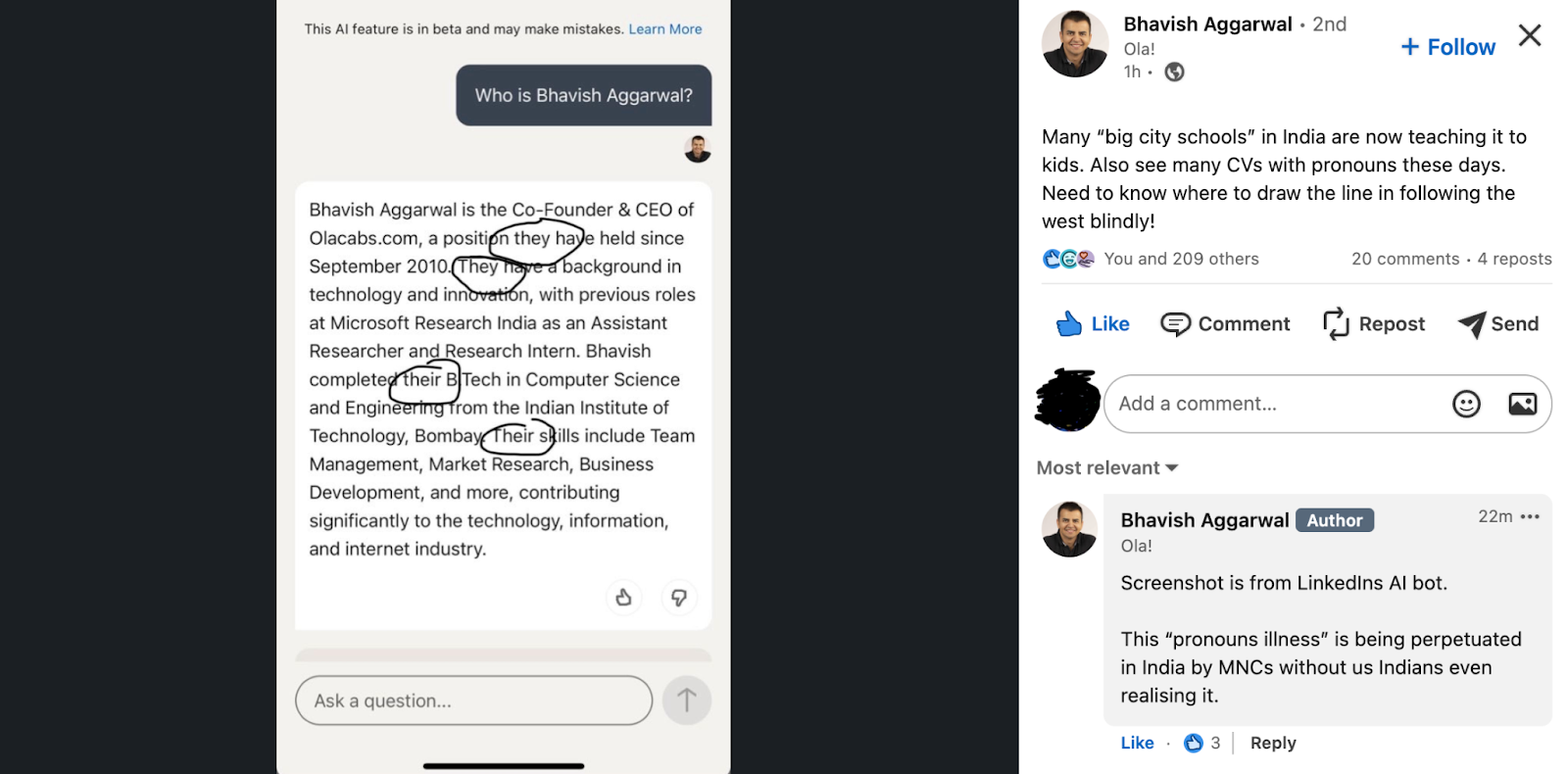
In a shocking new revelation, Ola Krutrum’s chief Bhavish Aggarwal shared a screenshot of a chat from a LinkedIn AI bot, in which he highlighted by circling the ‘pronouns’ and said he doesn’t want the trend of using specific pronouns, which he refers to as ‘pronoun illness,’ to become widespread in India.
Further, he said that many ‘big city schools’ in India are now introducing this practice, which is increasingly visible in CVs. “Need to know where to draw the line in following the West blindly!” he added, sharing his concerns about how Western culture influences most LLM-based chatbots.
“This ‘pronouns illness’ is being perpetuated in India by MNCs without us Indians even realising it,” shared Aggarwal, worryingly.
However, Aggarwal’s sentiment has created quite a stir, as it questions Ola’s diversity and inclusion practices. Medical student Vani Malhotra said she did not know this was an ‘Illness.’
“It costs us nothing to be inclusive. If it can help someone with their identity without causing anyone harm, what’s the problem? Don’t get it,” she added, saying that addressing an error by AI and creating shame around something as an influential person are two very different things!
This development follows Ola Krutrim’s recent release of the Android version of its chatbot, alongside AI Cloud Platform and developer tools.
At the launch, the team said that they were building these things for the Indian ecosystem, ensuring the preservation of Indian culture and tradition.
“We need to understand what makes an Indian language model and how it works with our languages and culture,” said Gautam Bhargava, the vice president and head of AI Engineering at Ola Krutrim, the former CTO of Rippling and the vice president of Visual Search and augmented Reality at Amazon.
The post Ola Krutrim’s Chief Bhavish Aggarwal Doesn’t Want ‘Pronoun Illness’ to Reach India appeared first on Analytics India Magazine.
Women in AI: Catherine Breslin helps companies develop AI strategies Dominic-Madori Davis 9 hours
To give AI-focused women academics and others their well-deserved — and overdue — time in the spotlight, TechCrunch has been publishing a series of interviews focused on remarkable women who’ve contributed to the AI revolution. We’re publishing these pieces throughout the year as the AI boom continues, highlighting key work that often goes unrecognized. Read more profiles here.
Catherine Breslin is the founder and director of Kingfisher Labs, where she helps companies develop AI strategies. She has spent more than two decades as an AI scientist and has worked for Cambridge University, Toshiba Research, and even Amazon Alexa. She was previously an adviser to the VC fund Deeptech Labs and was the Solutions Architect Director at Cobalt Speech & Language.
She attended Oxford University for undergrad before receiving her master’s and PhD at the University of Cambridge.
Briefly, how did you get your start in AI? What attracted you to the field?
I always loved maths and physics at school and I chose to study engineering at university. That’s where I first learned about AI, though it wasn’t called AI at the time. I got intrigued by the idea of using computers to do the speech and language processing that we humans find easy. From there, I ended up studying for a PhD in voice technology and working as a researcher. We’re at a point in time where there’ve been huge steps forward for AI recently, and I feel like there’s a huge opportunity to build technology that improves people’s lives.
What work are you most proud of in the AI field?
In 2020, in the early days of the pandemic, I founded my own consulting company with the mission to bring real-world AI expertise and leadership to organizations. I’m proud of the work I’ve done with my clients across different and interesting projects and also that I’ve been able to do this in a truly flexible way around my family.
How do you navigate the challenges of the male-dominated tech industry and, by extension, the male-dominated AI industry?
It’s hard to measure exactly, but something like 20% of the AI field is women. My perception is also that the percentage gets lower as you get more senior. For me, one of the best ways to navigate this is by building a supportive network. Of course, support can come from people of any gender. Sometimes, though, it’s reassuring to talk to women who are facing similar situations or who’ve seen the same problems, and it’s great not to feel alone.
The other thing for me is to think carefully about where to spend my energy. I believe that we’ll only see lasting change when more women get into senior and leadership positions, and that won’t happen if women spend all their energy on fixing the system rather than advancing their careers. There’s a pragmatic balance to be had between pushing for change and focusing on my own daily work.
What advice would you give to women seeking to enter the AI field?
AI is a huge and exciting field with a lot going on. There’s also a huge amount of noise with what can seem like a constant stream of papers, products, and models being released. It’s impossible to keep up with everything. Further, not every paper or research result is going to be significant in the long run, no matter how flashy the press release. My advice is to find a niche that you’re really interested in making progress in, learn everything you can about that niche, and tackle the problems that you’re motivated to solve. That’ll give you the solid foundation that you need.
What are some of the most pressing issues facing AI as it evolves?
Progress in the past 15 years has been fast, and we’ve seen AI move out of the lab and into products without really having stepped back to properly assess the situation and anticipate the consequences. One example that comes to mind is how much of our voice and language technology performs better in English than other languages. That’s not to say that researchers have ignored other languages. Significant effort has been put into non-English language technology. Yet, the unintended consequence of better English language technology means that we’re building and rolling out technology that doesn’t serve everyone equally.
What are some issues AI users should be aware of?
I think people should be aware that AI isn’t a silver bullet that’ll solve all problems in the next few years. It can be quick to build an impressive demo but takes a lot of dedicated effort to build an AI system that consistently works well. We shouldn’t lose sight of the fact that AI is designed and built by humans, for humans.
What is the best way to responsibly build AI?
Responsibly building AI means including diverse views from the outset, including from your customers and anyone impacted by your product. Thoroughly testing your systems is important to be sure you know how well they work across a variety of scenarios. Testing gets the reputation of being boring work compared to the excitement of dreaming up new algorithms. Yet, it’s critical to know if your product really works. Then there’s the need to be honest with yourself and your customers about both the capability and limitations of what you’re building so that your system doesn’t get misused.
How can investors better push for responsible AI?
Startups are building many new applications of AI, and investors have a responsibility to be thoughtful about what they’re choosing to fund. I’d love to see more investors be vocal about their vision for the future that we’re building and how responsible AI fits in.
Alternative clouds are booming as companies seek cheaper access to GPUs Kyle Wiggers 7 hours
The appetite for alternative clouds has never been bigger.
Case in point: CoreWeave, the GPU infrastructure provider that began life as a cryptocurrency mining operation, this week raised $1.1 billion in new funding from investors including Coatue, Fidelity and Altimeter Capital. The round brings its valuation to $19 billion post-money, and its total raised to $5 billion in debt and equity — a remarkable figure for a company that’s less than ten years old.
It’s not just CoreWeave.
Lambda Labs, which also offers an array of cloud-hosted GPU instances, in early April secured a “special purpose financing vehicle” of up to $500 million, months after closing a $320 million Series C round. The nonprofit Voltage Park, backed by crypto billionaire Jed McCaleb, last October announced that it’s investing $500 million in GPU-backed data centers. And Together AI, a cloud GPU host that also conducts generative AI research, in March landed $106 million in a Salesforce-led round.
So why all the enthusiasm for — and cash pouring into — the alternative cloud space?
The answer, as you might expect, is generative AI.
As the generative AI boom times continue, so does the demand for the hardware to run and train generative AI models at scale. GPUs, architecturally, are the logical choice for training, fine-tuning and running models because they contain thousands of cores that can work in parallel to perform the linear algebra equations that make up generative models.
But installing GPUs is expensive. So most devs and organizations turn to the cloud instead.
Incumbents in the cloud computing space — Amazon Web Services (AWS), Google Cloud and Microsoft Azure — offer no shortage of GPU and specialty hardware instances optimized for generative AI workloads. But for at least some models and projects, alternative clouds can end up being cheaper — and delivering better availability.
On CoreWeave, renting an Nvidia A100 40GB — one popular choice for model training and inferencing — costs $2.39 per hour, which works out to $1,200 per month. On Azure, the same GPU costs $3.40 per hour, or $2,482 per month; on Google Cloud, it’s $3.67 per hour, or $2,682 per month.
Given generative AI workloads are usually performed on clusters of GPUs, the cost deltas quickly grow.
“Companies like CoreWeave participate in a market we call specialty ‘GPU as a service’ cloud providers,” Sid Nag, VP of cloud services and technologies at Gartner, told TechCrunch. “Given the high demand for GPUs, they offers an alternate to the hyperscalers, where they’ve taken Nvidia GPUs and provided another route to market and access to those GPUs.”
Nag points out that even some big tech firms have begun to lean on alternative cloud providers as they run up against compute capacity challenges.
Last June, CNBC reported that Microsoft had signed a multi-billion-dollar deal with CoreWeave to ensure that OpenAI, the maker of ChatGPT and a close Microsoft partner, would have adequate compute power to train its generative AI models. Nvidia, the furnisher of the bulk of CoreWeave’s chips, sees this as a desirable trend, perhaps for leverage reasons; it’s said to have given some alternative cloud providers preferential access to its GPUs.
Lee Sustar, principal analyst at Forrester, sees cloud vendors like CoreWeave succeeding in part because they don’t have the infrastructure “baggage” that incumbent providers have to deal with.
“Given hyperscaler dominance of the overall public cloud market, which demands vast investments in infrastructure and range of services that make little or no revenue, challengers like CoreWeave have an opportunity to succeed with a focus on premium AI services without the burden of hypercaler-level investments overall,” he said.
But is this growth sustainable?
Sustar has his doubts. He believes that alternative cloud providers’ expansion will be conditioned by whether they can continue to bring GPUs online in high volume, and offer them at competitively low prices.
Competing on pricing might become challenging down the line as incumbents like Google, Microsoft and AWS ramp up investments in custom hardware to run and train models. Google offers its TPUs; Microsoft recently unveiled two custom chips, Azure Maia and Azure Cobalt; and AWS has Trainium, Inferentia and Graviton.
“Hypercalers will leverage their custom silicon to mitigate their dependencies on Nvidia, while Nvidia will look to CoreWeave and other GPU-centric AI clouds,” Sustar said.
Then there’s the fact that, while many generative AI workloads run best on GPUs, not all workloads need them — particularly if they’re aren’t time-sensitive. CPUs can run the necessary calculations, but typically slower than GPUs and custom hardware.
More existentially, there’s a threat that the generative AI bubble will burst, which would leave providers with mounds of GPUs and not nearly enough customers demanding them. But the future looks rosy in the short term, say Sustar and Nag, both of whom are expecting a steady stream of upstart clouds.
“GPU-oriented cloud startups will give [incumbents] plenty of competition, especially among customers who are already multi-cloud and can handle the complexity of management, security, risk and compliance across multiple clouds,” Sustar said. “Those sorts of cloud customers are comfortable trying out a new AI cloud if it has credible leadership, solid financial backing and GPUs with no wait times.”
While everyone has been breaking a sweat over AI taking away their job, the technology has apparently zeroed-in on an unlikely target – the commanders. Surprisingly, the threat may have shifted to middle and upper management, instead of the foot soldiers of an organisation.
In the latest episode of the Ben and Marc Show, a16z co-founders Marc Andreessen and Ben Horowitz‘s podcast, the duo spoke about how AI was more likely to affect managerial roles over workers themselves.
While there’s a lot of hubbub on AI taking over call centres, Andreessen said, “Maybe it’s actually easier to automate the manager’s job than the worker’s job.”
They spoke about the specifics of actually automating managerial roles, potentially allowing for better training and communication with workers.
“Everyone has an idealised version of what a great manager is. Most people have had bad experiences with mediocre or bad managers,” Andreessen said.
AI Managers vs Human Managers
Horowitz gave the example of Cresta AI, which is purpose-built for training call centre workers in real-time. Of course, there’s also the added bonus of not getting frustrated, tired, or potentially error-prone like a regular human manager.
Cresta isn’t the only startup that uses AI to train workers though. Several others, like Observe.AI and Gong, have begun offering services to train call centre workers and sales agents using AI.
Now, this is a step far from actually taking over jobs. AI could be good at training workers, constant mentorship, answering questions, and providing real-time input, which are the core duties of a manager.
“[Imagine] if you had an AI bot that was super sympathetic and super supportive and always happy to mentor you and teach you… never get frustrated. They’re [available] 24/7, if you’re trying to figure something out at 2 am on the night shift… they’re happy to talk to you about it,” Andreessen suggested.
Funnily enough, he also pointed out that AI probably wouldn’t have the same problems as a regular manager in terms of a lack of personal life or other potential interpersonal issues that could affect their work.
Meanwhile, the use of AI as customer service representatives and call centre workers has not been as successful.
Limitations
While people can make use of chatbots, actually using them in customer-facing roles to interact with potentially agitated customers seems like a recipe for disaster.
“Who knows what the person on the other side of the phone is going to say? Could be something completely unanticipated and it turns out that humans are very good at adapting, whereas machines can go a little haywire,” Horowitz said.
Already, cases like these have been reported, even without a voice-enabled AI customer service representative. Last year, Air Canada faced a similar problem, wherein their AI chatbot had misinformed a customer on their policy for bereavement rates, leading to the customer paying full price for a ticket.
Following a legal battle where the Canadian airline had alleged that the chatbot acted on its own accord and should be considered a separate legal entity, the court ruled in the customer’s favour.
Similarly, to actually replace workers with AI could be way more costly, as seen by Amazon’s recent Just Walk Out debacle. While the company lauded its use of AI to help customers bypass regular checkouts, reports alleged that the tech was actually powered by around a thousand workers based out of India.
So, will AI actually replace workers? Probably not. But whether they will replace middle management is yet to be seen, as more companies make use of AI’s training services.
The post AI More Likely to Replace Your Toxic Manager than Workers appeared first on Analytics India Magazine.
This Week in AI: Generative AI and the problem of compensating creators Kyle Wiggers Devin Coldewey 12 hours
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
By the way — TechCrunch plans to launch an AI newsletter soon. Stay tuned.
This week in AI, eight prominent U.S. newspapers owned by investment giant Alden Global Capital, including the New York Daily News, Chicago Tribune and Orlando Sentinel, sued OpenAI and Microsoft for copyright infringement relating to the companies’ use of generative AI tech. They, like The New York Times in its ongoing lawsuit against OpenAI, accuse OpenAI and Microsoft of scraping their IP without permission or compensation to build and commercialize generative models such as GPT-4.
“We’ve spent billions of dollars gathering information and reporting news at our publications, and we can’t allow OpenAI and Microsoft to expand the big tech playbook of stealing our work to build their own businesses at our expense,” Frank Pine, the executive editor overseeing Alden’s newspapers, said in a statement.
The suit seems likely to end in a settlement and licensing deal, given OpenAI’s existing partnerships with publishers and its reluctance to hinge the whole of its business model on the fair use argument. But what about the rest of the content creators whose works are being swept up in model training without payment?
It seems OpenAI’s thinking about that.
A recently published research paper co-authored by Boaz Barak, a scientist on OpenAI’s Superalignment team, proposes a framework to compensate copyright owners “proportionally to their contributions to the creation of AI-generated content.” How? Through cooperative game theory.
The framework evaluates to what extent content in a training data set — e.g. text, images or some other data — influences what a model generates, employing a game theory concept known as the Shapley value. Then, based on that evaluation, it determines the content owners’ “rightful share” (i.e. compensation).
Let’s say you have an image-generating model trained using artwork from four artists: John, Jacob, Jack and Jebediah. You ask it to draw a flower in Jack’s style. With the framework, you can determine the influence each artists’ works had on the art the model generates and, thus, the compensation that each should receive.
There is a downside to the framework, however — it’s computationally expensive. The researchers’ workarounds rely on estimates of compensation rather than exact calculations. Would that satisfy content creators? I’m not so sure. If OpenAI someday puts it into practice, we’ll certainly find out.
Here are some other AI stories of note from the past few days:
Microsoft reaffirms facial recognition ban: Language added to the terms of service for Azure OpenAI Service, Microsoft’s fully managed wrapper around OpenAI tech, more clearly prohibits integrations from being used “by or for” police departments for facial recognition in the U.S.
The nature of AI-native startups: AI startups face a different set of challenges from your typical software-as-a-service company. That was the message from Rudina Seseri, founder and managing partner at Glasswing Ventures, last week at the TechCrunch Early Stage event in Boston; Ron has the full story.
Anthropic launches a business plan: AI startup Anthropic is launching a new paid plan aimed at enterprises as well as a new iOS app. Team — the enterprise plan — gives customers higher-priority access to Anthropic’s Claude 3 family of generative AI models plus additional admin and user management controls.
CodeWhisperer no more: Amazon CodeWhisperer is now Q Developer, a part of Amazon’s Q family of business-oriented generative AI chatbots. Available through AWS, Q Developer helps with some of the tasks developers do in the course of their daily work, like debugging and upgrading apps — much like CodeWhisperer did.
Just walk out of Sam’s Club: Walmart-owned Sam’s Club says it’s turning to AI to help speed up its “exit technology.” Instead of requiring store staff to check members’ purchases against their receipts when leaving a store, Sam’s Club customers who pay either at a register or through the Scan & Go mobile app can now walk out of certain store locations without having their purchases double-checked.
Fish harvesting, automated: Harvesting fish is an inherently messy business. Shinkei is working to improve it with an automated system that more humanely and reliably dispatches the fish, resulting in what could be a totally different seafood economy, Devin reports.
Yelp’s AI assistant: Yelp announced this week a new AI-powered chatbot for consumers — powered by OpenAI models, the company says — that helps them connect with relevant businesses for their tasks (like installing lighting fixtures, upgrading outdoor spaces and so on). The company is rolling out the AI assistant on its iOS app under the “Projects” tab, with plans to expand to Android later this year.
More machine learnings
Image Credits: US Dept of Energy
Sounds like there was quite a party at Argonne National Lab this winter when they brought in a hundred AI and energy sector experts to talk about how the rapidly evolving tech could be helpful to the country’s infrastructure and R&D in that area. The resulting report is more or less what you’d expect from that crowd: a lot of pie in the sky, but informative nonetheless.
Looking at nuclear power, the grid, carbon management, energy storage, and materials, the themes that emerged from this get-together were, first, that researchers need access to high-powered compute tools and resources; second, learning to spot the weak points of the simulations and predictions (including those enabled by the first thing); third, the need for AI tools that can integrate and make accessible data from multiple sources and in many formats. We’ve seen all these things happening across the industry in various ways, so it’s no big surprise, but nothing gets done at the federal level without a few boffins putting out a paper, so it’s good to have it on the record.
Georgia Tech and Meta are working on part of that with a big new database called OpenDAC, a pile of reactions, materials, and calculations intended to help scientists designing carbon capture processes to do so more easily. It focuses on metal-organic frameworks, a promising and popular material type for carbon capture, but one with thousands of variations, which haven’t been exhaustively tested.
The Georgia Tech team got together with Oak Ridge National Lab and Meta’s FAIR to simulate quantum chemistry interactions on these materials, using some 400 million compute hours — way more than a university can easily muster. Hopefully it’s helpful to the climate researchers working in this field. It’s all documented here.
We hear a lot about AI applications in the medical field, though most are in what you might call an advisory role, helping experts notice things they might not otherwise have seen, or spotting patterns that would have taken hours for a tech to find. That’s partly because these machine learning models just find connections between statistics without understanding what caused or led to what. Cambridge and Ludwig-Maximilians-Universität München researchers are working on that, since moving past basic correlative relationships could be hugely helpful in creating treatment plans.
The work, led by Professor Stefan Feuerriegel from LMU, aims to make models that can identify causal mechanisms, not just correlations: “We give the machine rules for recognizing the causal structure and correctly formalizing the problem. Then the machine has to learn to recognize the effects of interventions and understand, so to speak, how real-life consequences are mirrored in the data that has been fed into the computers,” he said. It’s still early days for them, and they’re aware of that, but they believe their work is part of an important decade-scale development period.
Over at University of Pennsylvania, grad student Ro Encarnación is working on a new angle in the “algorithmic justice” field we’ve seen pioneered (primarily by women and people of color) in the last seven or eight years. Her work is more focused on the users than the platforms, documenting what she calls “emergent auditing.”
When Tiktok or Instagram puts out a filter that’s kinda racist, or an image generator that does something eye-popping, what do users do? Complain, sure, but they also continue to use it, and learn how to circumvent or even exacerbate the problems encoded in it. It may not be a “solution” the way we think of it, but it demonstrates the diversity and resilience of the user side of the equation — they’re not as fragile or passive as you might think.
Women in AI: Tara Chklovski is teaching the next generation of AI innovators Dominic-Madori Davis 7 hours
To give AI-focused women academics and others their well-deserved — and overdue — time in the spotlight, TechCrunch has been publishing a series of interviews focused on remarkable women who’ve contributed to the AI revolution. We’re publishing these pieces throughout the year as the AI boom continues, highlighting key work that often goes unrecognized. Read more profiles here.
Tara Chklovski is the CEO and founder of Technovation, a nonprofit that helps teach young girls about technology and entrepreneurship. She has led the company for the past 17 years, finding ways to help young women use technology to solve some of the world’s most pressing issues. She attended St. Stephen’s College in Delhi, before receiving a master’s at Boston University and a PhD at the University of Southern California in Aerospace Engineering.
Briefly, how did you get your start in AI? What attracted you to the field?
I started learning about AI in 2016 when we were invited to the AAAI (Association for the Advancement of Artificial Intelligence) Conference taking place in San Francisco, and we had a chance to interview a range of AI researchers using AI to tackle interesting problems ranging from space to stocks. Technovation is a nonprofit organization and our mission is to bring the most powerful, cutting-edge tools and technologies to the most underserved communities. AI felt powerful and right. So I decided to learn a lot about it!
We conducted a national survey of parents in 2017, asking them about their thoughts and concerns around AI, and we were blown away by how African American mothers were very interested in bringing AI literacy to their children, more so than any other demographic. We then launched the first global AI education program — the AI Family Challenge, supported by Google and Nvidia.
We continued to learn and iterate since then, and now we are the only global, project-based AI education program with a research-based curriculum that is translated into 12 languages.
What work are you most proud of in the AI field?
The fact that we are the only org that has a peer-reviewed research article on the impact of our project-based AI curriculum and that we have been able to bring it to tens of thousands of girls around the world.
How do you navigate the challenges of the male-dominated tech industry and, by extension, the male-dominated AI industry?
It is hard. We have many allies, but typically, power and influence lie with the CEOs, and they are usually male and do not fully empathize with the barriers that women face at every step. You become the CEO of a trillion-dollar company based on certain characteristics, and these characteristics may not be the same that enable you to empathize with others.
As far as solutions, society is becoming more educated, and both genders are becoming more sophisticated in empathy, mental health, psychological development, etc. My advice to those who support women in tech would be to be more bold in their investments so we can make more progress. We have enough research and data to know what works. We need more champions and advocates.
What advice would you give to women seeking to enter the AI field?
Start today. It is so easy to start messing around online with free and world-class lectures and courses. Find a problem that is interesting to you, and start learning and building. The Technovation curriculum is one great starting point as well, as it requires no prior technical background and by the end you would have created an AI-based startup.
What are some of the most pressing issues facing AI as it evolves?
[Society views] underserved groups as a monolithic group with no voice, agency, or talent — just waiting to be exploited. In fact, we have found that teenage girls are some of the earliest adopters of technology and have the coolest ideas. A Technovation team of girls created a ride-sharing and taxi-hailing app in December 2010. Another Technovation team created a mindfulness and focus app in March 2012. Today, Technovation teams are creating AI-based apps, building new datasets focused on groups in India, Africa, and Latin America — groups that are not being included in the apps coming out of Silicon Valley.
Instead of viewing these countries as just markets, consumers, and recipients, we need to view these groups as powerful collaborators who can help ensure that we are building truly innovative solutions to the complex problems facing humanity.
What are some issues AI users should be aware of?
These technologies are fast-moving. Be curious and peek under the hood as much as possible by learning how these models are working. This will help you become a curious and hopefully informed user.
What is the best way to responsibility build AI?
By training groups that are not normally part of the design and engineering teams, and then building better technologies with them as co-designers and builders. It doesn’t take that much more time, and the end product will be much more robust and innovative for the process.
How can investors better push for responsible AI?
Push for collaborations with global nonprofits that have access to diverse talent pools so that your engineers are talking to a broad set of users and incorporating their perspectives.
Hallucinations — the lies generative AI models tell, basically — are a big problem for businesses looking to integrate the technology into their operations.
Because models have no real intelligence and are simply predicting words, images, speech, music and other data according to a private schema, they sometimes get it wrong. Very wrong. In a recent piece in The Wall Street Journal, a source recounts an instance where Microsoft’s generative AI invented meeting attendees and implied that conference calls were about subjects that weren’t actually discussed on the call.
As I wrote a while ago, hallucinations may be an unsolvable problem with today’s transformer-based model architectures. But a number of generative AI vendors suggest that they can be done away with, more or less, through a technical approach called retrieval augmented generation, or RAG.
Here’s how one vendor, Squirro, pitches it:
At the core of the offering is the concept of Retrieval Augmented LLMs or Retrieval Augmented Generation (RAG) embedded in the solution … [our generative AI] is unique in its promise of zero hallucinations. Every piece of information it generates is traceable to a source, ensuring credibility.
Here’s a similar pitch from SiftHub:
Using RAG technology and fine-tuned large language models with industry-specific knowledge training, SiftHub allows companies to generate personalized responses with zero hallucinations. This guarantees increased transparency and reduced risk and inspires absolute trust to use AI for all their needs.
RAG was pioneered by data scientist Patrick Lewis, researcher at Meta and University College London, and lead author of the 2020 paper that coined the term. Applied to a model, RAG retrieves documents possibly relevant to a question — for example, a Wikipedia page about the Super Bowl — using what’s essentially a keyword search and then asks the model to generate answers given this additional context.
“When you’re interacting with a generative AI model like ChatGPT or Llama and you ask a question, the default is for the model to answer from its ‘parametric memory’ — i.e., from the knowledge that’s stored in its parameters as a result of training on massive data from the web,” David Wadden, a research scientist at AI2, the AI-focused research division of the nonprofit Allen Institute, explained. “But, just like you’re likely to give more accurate answers if you have a reference [like a book or a file] in front of you, the same is true in some cases for models.”
RAG is undeniably useful — it allows one to attribute things a model generates to retrieved documents to verify their factuality (and, as an added benefit, avoid potentially copyright-infringing regurgitation). RAG also lets enterprises that don’t want their documents used to train a model — say, companies in highly regulated industries like healthcare and law — to allow models to draw on those documents in a more secure and temporary way.
But RAG certainly can’t stop a model from hallucinating. And it has limitations that many vendors gloss over.
Wadden says that RAG is most effective in “knowledge-intensive” scenarios where a user wants to use a model to address an “information need” — for example, to find out who won the Super Bowl last year. In these scenarios, the document that answers the question is likely to contain many of the same keywords as the question (e.g., “Super Bowl,” “last year”), making it relatively easy to find via keyword search.
Things get trickier with “reasoning-intensive” tasks such as coding and math, where it’s harder to specify in a keyword-based search query the concepts needed to answer a request — much less identify which documents might be relevant.
Even with basic questions, models can get “distracted” by irrelevant content in documents, particularly in long documents where the answer isn’t obvious. Or they can — for reasons as yet unknown — simply ignore the contents of retrieved documents, opting instead to rely on their parametric memory.
RAG is also expensive in terms of the hardware needed to apply it at scale.
That’s because retrieved documents, whether from the web, an internal database or somewhere else, have to be stored in memory — at least temporarily — so that the model can refer back to them. Another expenditure is compute for the increased context a model has to process before generating its response. For a technology already notorious for the amount of compute and electricity it requires even for basic operations, this amounts to a serious consideration.
That’s not to suggest RAG can’t be improved. Wadden noted many ongoing efforts to train models to make better use of RAG-retrieved documents.
Some of these efforts involve models that can “decide” when to make use of the documents, or models that can choose not to perform retrieval in the first place if they deem it unnecessary. Others focus on ways to more efficiently index massive datasets of documents, and on improving search through better representations of documents — representations that go beyond keywords.
“We’re pretty good at retrieving documents based on keywords, but not so good at retrieving documents based on more abstract concepts, like a proof technique needed to solve a math problem,” Wadden said. “Research is needed to build document representations and search techniques that can identify relevant documents for more abstract generation tasks. I think this is mostly an open question at this point.”
So RAG can help reduce a model’s hallucinations — but it’s not the answer to all of AI’s hallucinatory problems. Beware of any vendor that tries to claim otherwise.