Image by Author
Introducing Llama 3
Meta recently released Llama 3, one of the most powerful “open” AI models to date.
Llama 3 is available in 2 sizes: Llama 3 8B, which has 8 billion parameters, and Llama 3 70 B, with 70 billion parameters.
These are relatively small models that barely exceed the size of their predecessor, Llama 2. However, it seems like Llama 3’s focus is on quality rather than size, as the model was trained on over 15 trillion tokens of data.
Due to the increase in the quantity of training data and advancements in training techniques, Llama 3 performs significantly better than Llama 2 although they are the same size.
This will make it easier to run Llama 3 on local machines.
How Does Llama 3 Perform Among Other Open Models?
Here is a table showcasing the performance of Llama 3 against other language models on various benchmarks:
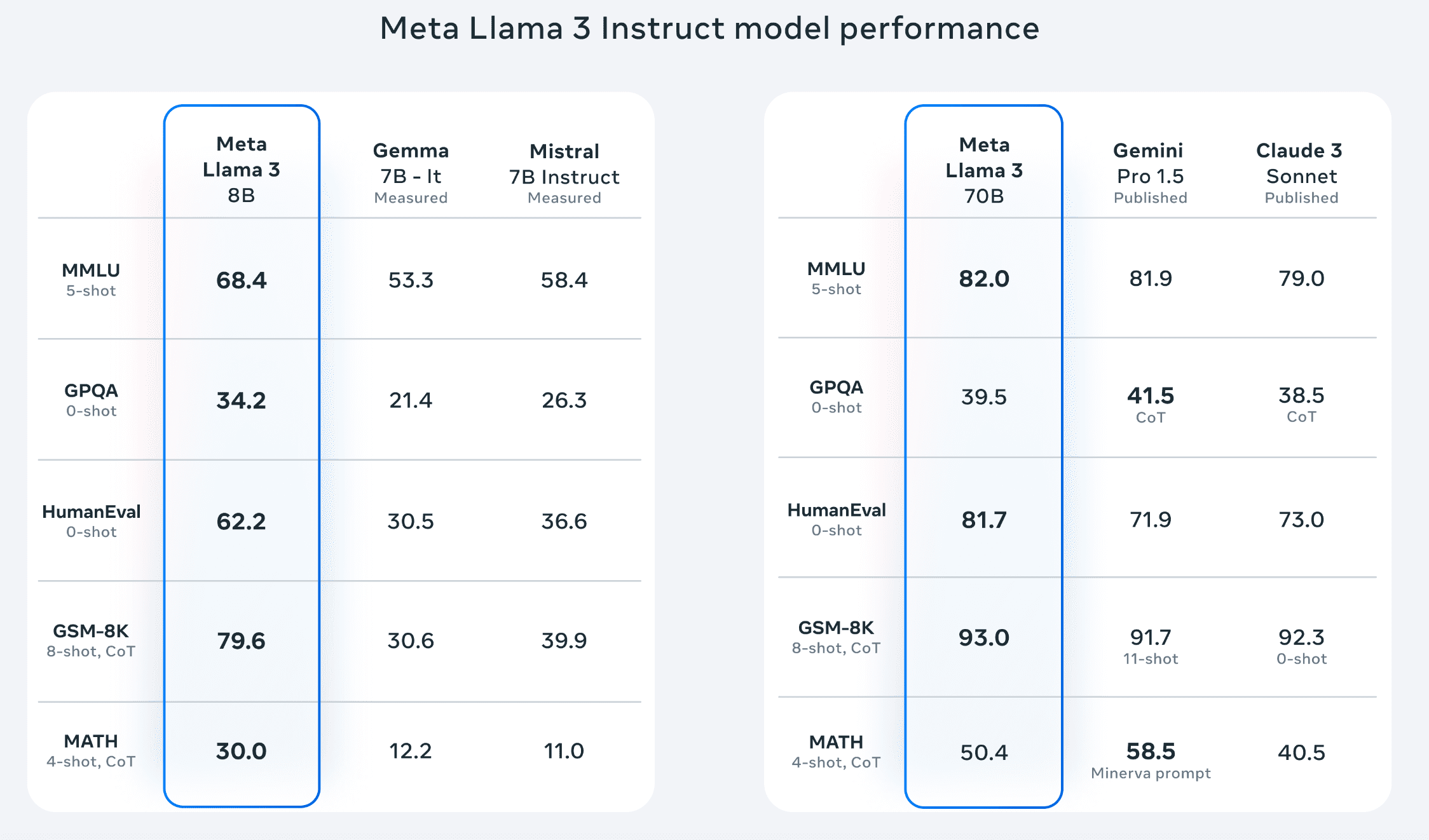
Source: Meta
Here’s what these benchmarks mean:
- MMLU (Massive Multitask Language Understanding): A benchmark designed to understand how well a language model can multitask. The model’s performance is assessed across a range of subjects, such as math, computer science, and law.
- GPQA (Graduate-Level Google-Proof Q&A): Assesses a model’s ability to answer questions that are challenging for search engines to solve directly. This benchmark evaluates whether the AI can handle questions that usually require human-level research skills.
- HumanEval: Assesses how well the model can write code by asking it to perform programming tasks.
- GSM-8K: Evaluates the model’s ability to solve math word problems.
- MATH: Tests the model’s ability to solve middle school and high school math problems.
On the left, we see a performance comparison between the smaller model, Llama 3 8B, against Gemma 7B It and Mistral 7B Instruct, two similarly sized open-source models.
Llama 3 8B outperforms comparably sized language models on every benchmark on the list.
Llama 3 70B was benchmarked against Gemini Pro 1.5 and Claude 3 Sonnet. These are two state-of-the-art AI models released by Google and Anthropic and are not open source.
Interestingly, Gemini Pro 1.5 is Google’s flagship model. It is said to perform better than its current most capable model, Gemini Ultra.
As the only openly available model on the list, it is impressive to see that Llama 3 70B beats Gemini Pro 1.5 and Claude 3 Sonnet on 3 out of 5 performance benchmarks.
Meet MetaAI: The Most Intelligent, Freely Available AI Assistant
Llama 3 also powers Meta AI, an AI assistant that is capable of complex reasoning, following instructions, and visualizing ideas.
It has a chat interface that allows you to interact with Llama 3. You can ask it questions, perform research, and even have it generate images.
Unlike existing LLM chatbots like ChatGPT, Gemini, and Claude, Meta AI is completely free to use. Its most advanced model is not hidden behind a paywall, making it a powerful free alternative to existing AI assistants.
Meta AI is integrated into Meta’s suite of apps, like Facebook, Instagram, WhatsApp, and Messenger. You can use it to perform advanced searches on these platforms.
According to Mark Zuckerberg, Meta AI is now the most intelligent, freely available AI assistant.
Unfortunately, Meta AI is currently only available in select countries and will be rolled out to users worldwide in the near future.
If it isn’t available in your country yet, don’t worry! I will show you two other ways to access Llama 3 for free.
Getting Started: How to Access Llama 3
Here are two other ways to access Llama 3 for free:
Accessing Llama 3 with Hugging Face
Hugging Face is a community that helps developers build and train machine learning models. The organization is focused on democratizing access to AI and allows you to access cutting-edge machine-learning models for free.
To access Llama 3 in Hugging Face, you first need to create an account with Hugging Face by signing up.
Then, navigate to HuggingChat; Hugging Face’s platform that makes the best AI models from the community available to the public.
You should see a screen that looks like this:
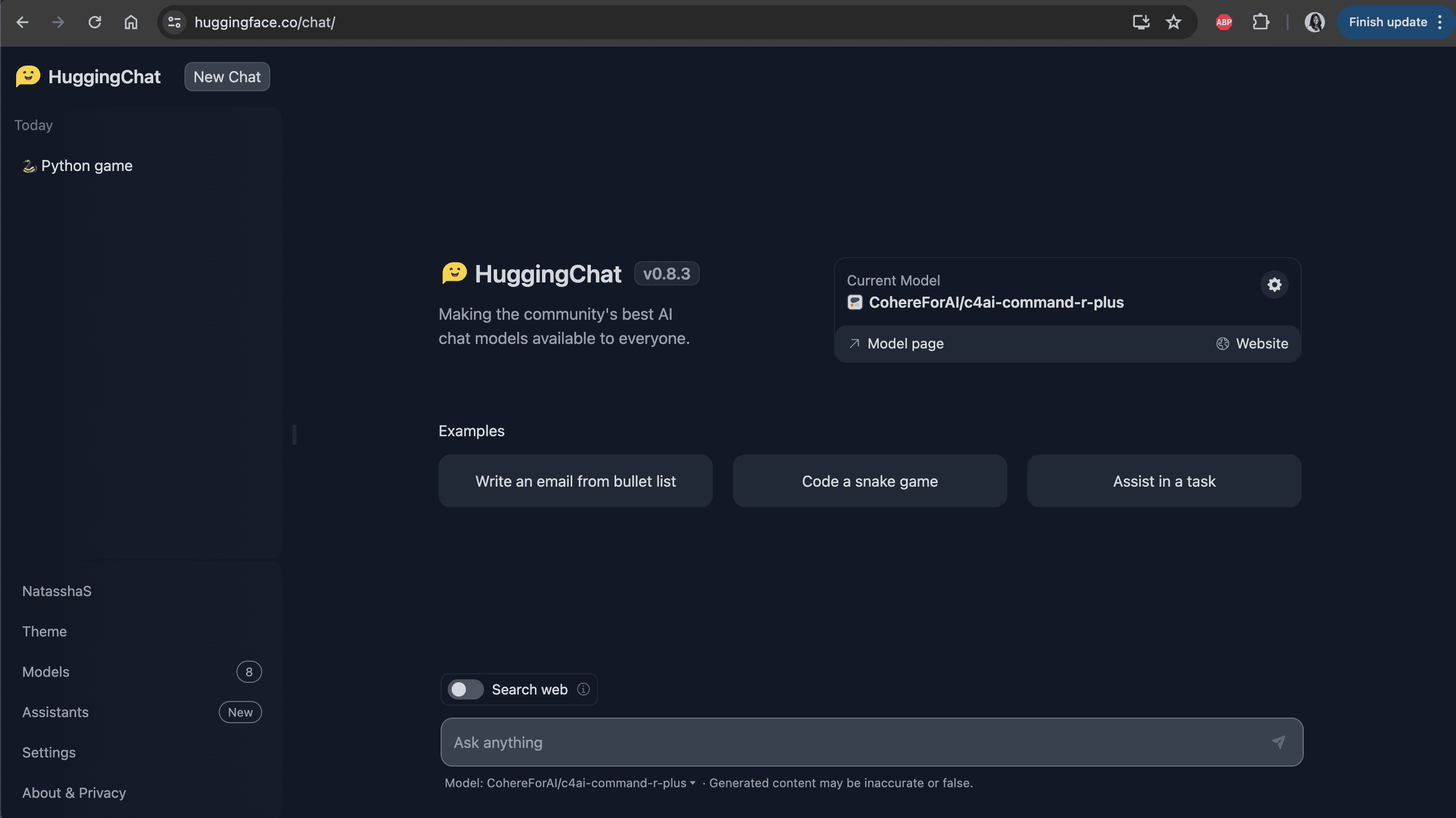
Source: HuggingChat
Simply select the wheel icon and change your current model to Meta Llama 3 as shown below:
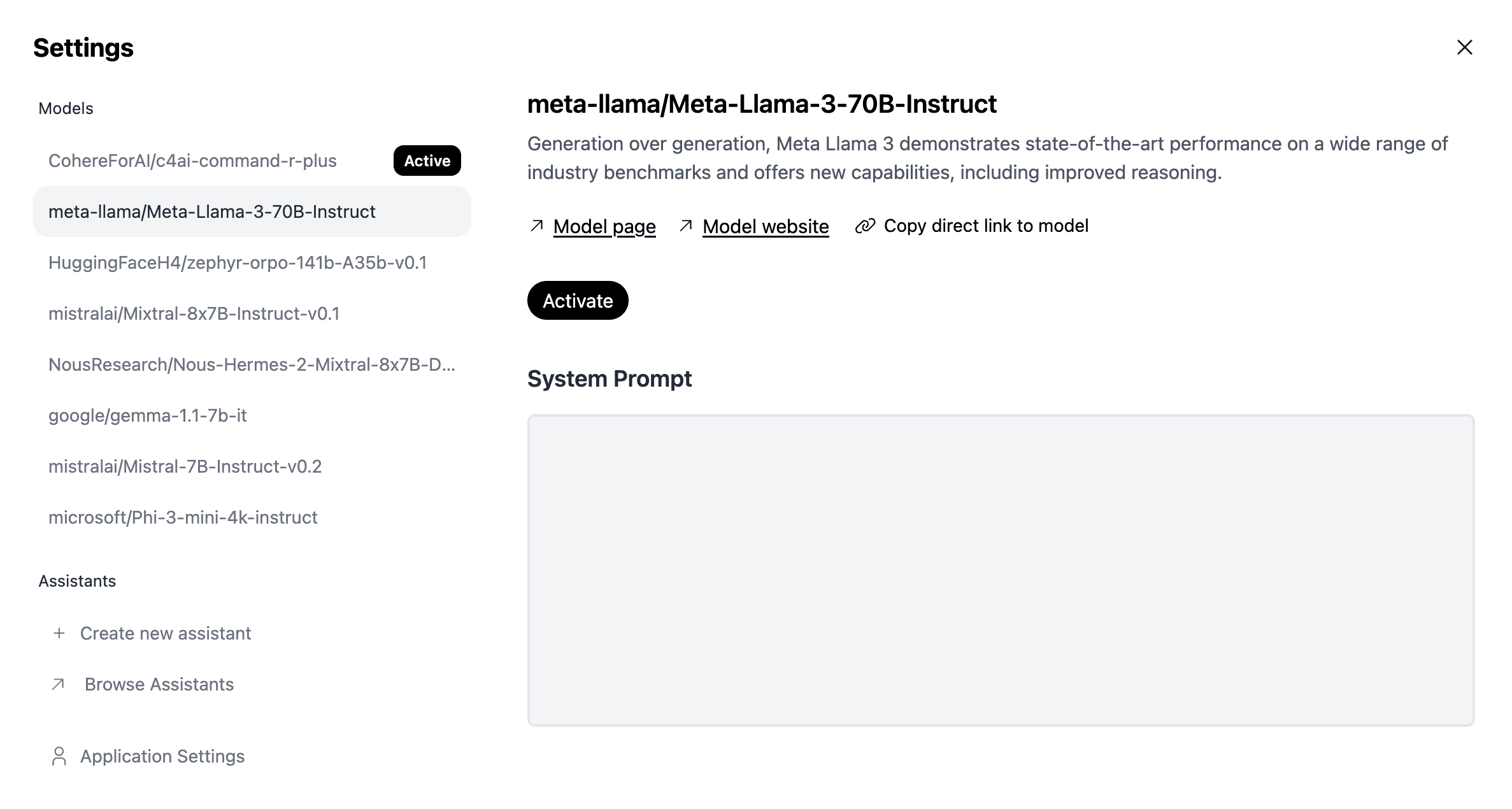
Source: HuggingChat
Then, select “Activate,” and you can start interacting with the model!
Accessing Lllama 3 with Ollama
Ollama is a tool that lets you run language models on your local machine. With Ollama, you can easily interact with open-source models like Llama, Mistral, and Gemma in just a few steps.
To access Llama 3 with Ollama, simply navigate to the Ollama website and download the tool. Follow the installation instructions you see on the screen.
Then, navigate to your command line interface and type the following command: ollama run llama3:70b.
The model should take a few minutes to download. Once this is done, you can type your prompts into the terminal and interact with Llama 3, as shown in the screenshot below:
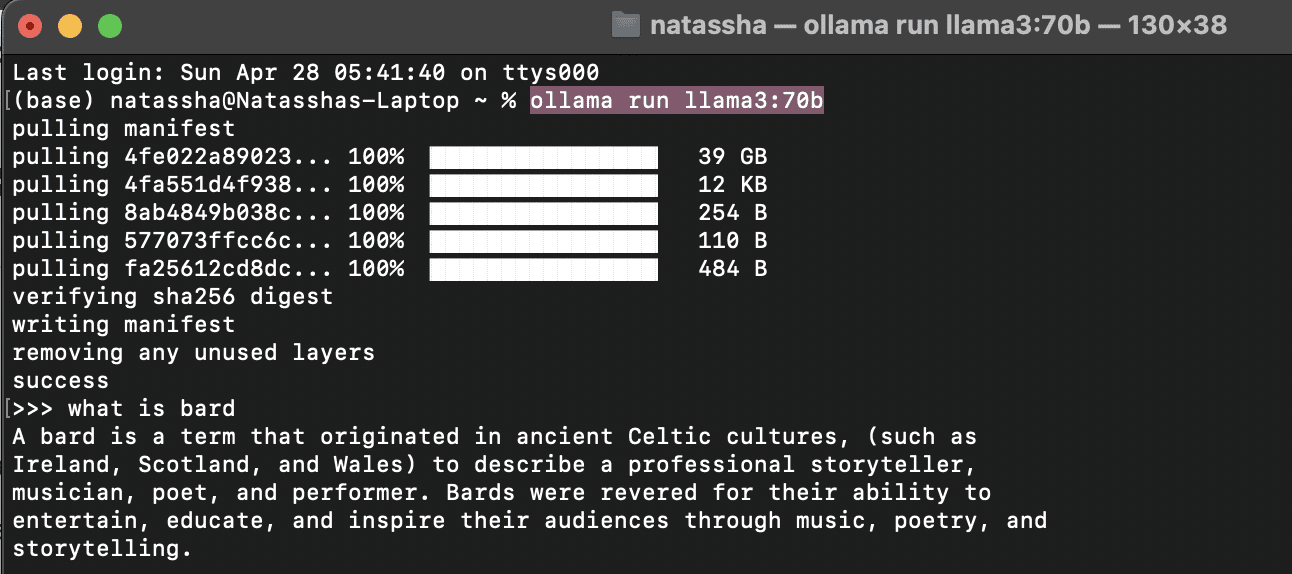
Image by Author
Summary
Llama 3 is Meta’s latest openly available model. This LLM outperforms similarly sized models released by Google and Anthropic and currently powers Meta AI, an AI assistant built into Meta’s suite of products.
To access Llama 3, you can use the Meta AI chat interface, interact with the model through HuggingChat, or run it locally using Ollama.
Natassha Selvaraj is a self-taught data scientist with a passion for writing. Natassha writes on everything data science-related, a true master of all data topics. You can connect with her on LinkedIn or check out her YouTube channel.
- Unveiling the Power of Meta's Llama 2: A Leap Forward in Generative AI?
- Closed Source VS Open Source Image Annotation
- Baize: An Open-Source Chat Model (But Different?)
- The Ultimate Open-Source Large Language Model Ecosystem
- Generative AI Playground: LLMs with Camel-5b and Open LLaMA 3B on…
- How to build a model to find the most impactful paths in user journeys