With the rise of generative AI over the last year and a half, its impact on company revenues has become increasingly evident. As per a forthcoming AIM Research report, the total market for generative AI is expected to grow at a compound annual growth rate (CAGR) of 40.22% by 2033 as compared to 2023.
Furthermore, companies in the service sector are anticipated to experience a slightly higher CAGR of 45%, indicating a faster GenAI expansion compared to the overall market.
GenAI Revenues Galore
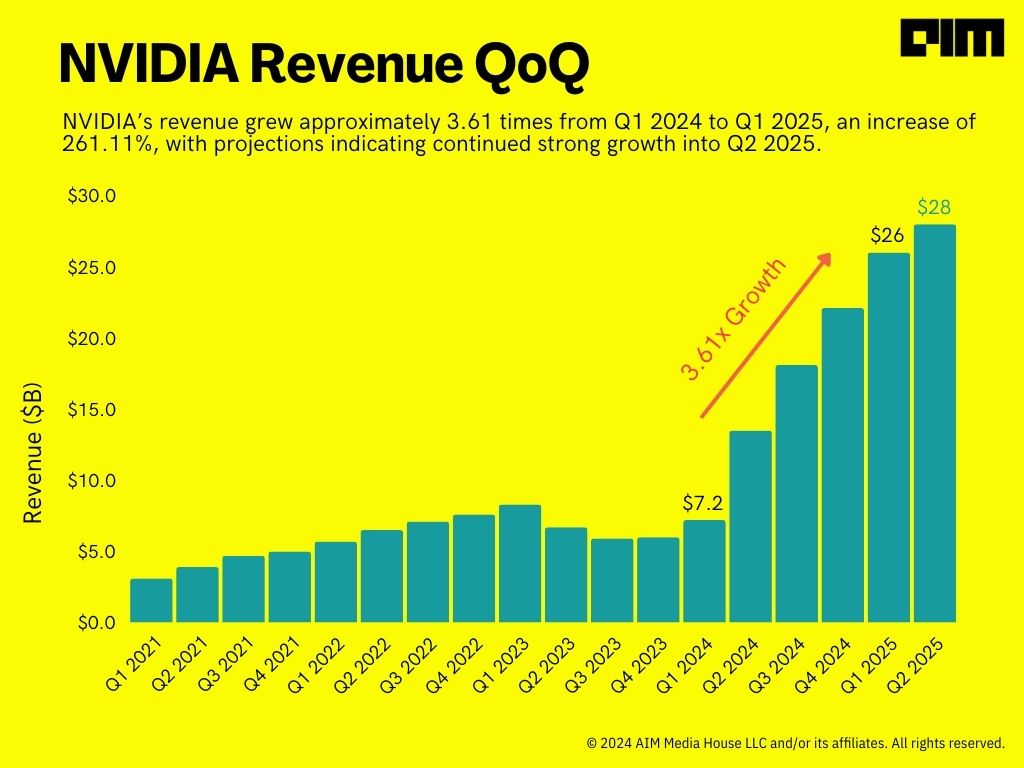
Most recently, NVIDIA reported a revenue of $26.04 billion in Q1 2025, fuelled by the generative AI boom. In contrast, during the first quarter of 2024, NVIDIA’s revenue was $7.19 billion.
NVIDIA is followed by AMD in the data centre market, with AMD holding a 3% share. Total spending in this market reached $49 billion in 2023, a significant increase from $17 billion in 2022, according to AIM Research.
While Google, Microsoft, AWS, Apple, and Meta, alongside Intel and AMD, are investing heavily in developing custom chips to run AI workloads, experts believe they will never be able to catch up with NVIDIA, as it controls a whopping 95% of the AI chip market.
Cloud companies are at the forefront of benefitting from generative AI. Microsoft Azure has shown steady growth in the cloud sector, increasing its market share.
In the recent quarter, Azure’s cloud revenue was $26.7 billion, up 23% year-on-year (YoY). Google Cloud reported revenue of $9.6 billion, up 28.43% YoY. On the other hand, AWS reported revenue of $25.04 billion in Q1 2025, up 13% from the fourth quarter of the previous year.
IT Companies
Generative AI has contributed to the revenue growth of Indian IT companies by creating new business opportunities and enhancing productivity. For instance, TCS reported GenAI deals worth $900 million in Q4 FY24.
Meanwhile, Tech Mahindra achieved a 27% increase in revenue per advertiser for a large retail e-commerce client in the SMB segment. The company implemented generative AI in revenue operations (RevOps) to optimise ad campaigns and enhance customer satisfaction.
Wipro is also feeling confident about its generative AI solutions. In the latest quarter, the company launched the Wipro Enterprise Artificial Intelligence Ready platform in partnership with IBM, expanding on a substantial investment in AI.
Infosys revealed in its Q4 FY24 quarterly reports that the IT giant is seeing excellent traction with its clients for generative AI work. The company generated over 3 million lines of code using generative AI and large language models available in the public domain.
Global IT firm Accenture secured multiple GenAI projects worth $600 million in the last quarter, building upon the $450 million in projects secured in the preceding quarter. The company’s planned investment of $3 billion aims to enhance its capabilities and cement its position as a top service provider.
Genpact, on the other hand, reported a 4% increase in Q1 2024 revenues to $1.13 billion, with significant execution improvements in data, generative AI, and digital operations.
Data and Analytics
Snowflake recently announced that their quarterly revenue was $790 million, up 34% year-over-year. The company has announced that its product revenue is projected to be between $805 million and $810 million for the current quarter ending in July, also up 34% year-over-year. In contrast, the total revenue in Q1 2021 was $228.9 million.
Since Sridhar Ramaswamy assumed the CEO position, Snowflake has transformed from a data cloud company to a data and AI-driven entity with a strong emphasis on generative AI.
“I think it’s a huge opportunity in the world of data applications and AI. It will keep me busy for many years to come,” said Ramaswamy in a recent interview after taking the helm at Snowflake.
On the other hand, in 2024, Databricks reached a revenue run rate of $1.9 billion, with a year-over-year growth rate of 26.67%. The company reported $1.6 billion in revenue for the fiscal year ending January 31, 2024, representing over 50% year-over-year growth.
Databricks’ India arm has recorded an 80% annualised growth over the past two fiscal years, from February 1, 2022, to January 31, 2024. The company attributes this surge to the rising demand for data and AI capabilities among Indian enterprises.
Indian enterprises, including Air India, Aditya Birla Fashion and Retail, CommerceIQ, Freshworks, InMobi, Meesho, Myntra, Parle, and UPL, use Databrick’s platform.
BFSI Sector
Banks that move quickly to scale generative AI across their organisations could increase their revenues by up to 600 basis points (bps) in three years, according to Accenture research. The analysis found that banks that effectively adopt and scale generative AI could increase employee productivity by up to 30%, streamlining numerous language-related tasks.
One notable example of generative AI increasing a bank’s revenue is Wells Fargo’s implementation of its generative AI virtual assistant, named Fargo. Launched in March 2023, Fargo has handled 20 million interactions and is projected to reach 100 million interactions annually.
Fargo is built on Google’s PaLM 2 and can answer everyday banking queries, provide insights into spending patterns, check credit scores, pay bills, and offer transaction details.
Pharma
Moderna reported a revenue of $167 million in Q1 2024, down significantly from the $2.8 billion earned in the previous quarter due to a drop in sales of its COVID-19 vaccine, Spikevax. Following that, the pharma giant partnered with OpenAI to use ChatGPT Enterprise for mRNA medicine development, aiming to launch up to 15 new products in the next five years, including a vaccine for respiratory syncytial virus and personalised cancer treatments.
Of all the AI startups, OpenAI is leading the way. It reached the $2 billion revenue milestone in December, according to a report by the Financial Times. The report indicated that OpenAI expects to more than double this figure by 2025, driven by a strong interest from business customers looking to implement generative AI tools in the workplace.
Chinese investor and entrepreneur Kai-Fu Lee is bullish about OpenAI becoming a trillion-dollar company in the next two to three years. “OpenAI will likely be a trillion-dollar company in the not-too-distant future,” said Lee at a recent event with Fortune.
The post GenAI Service Market to Grow at 45% CAGR by 2033 appeared first on AIM.