Image by Editor | Midjourney & Canva
Large Language Models are advanced types of artificial intelligence designed to understand and generate human-like text. They are built using machine learning techniques, specifically deep learning. Essentially, LLMs are trained on vast amounts of text data from the Internet, books, articles, and other sources to learn the patterns and structures of human language.
The history of Large Language Models (LLMs) began with early neural network models. Still, a significant milestone was the introduction of the Transformer architecture by Vaswani et al. in 2017, detailed in the paper "Attention Is All You Need."

The Transformer — model architecture | Source: Attention Is All You Need
This architecture improved the efficiency and performance of language models. In 2018, OpenAI released GPT (Generative Pre-trained Transformer), which marked the beginning of highly capable LLMs. The subsequent release of GPT-2 in 2019, with 1.5 billion parameters, demonstrated unprecedented text generation abilities and raised ethical concerns due to its potential misuse. GPT-3, launched in June 2020, with 175 billion parameters, further showcased the power of LLMs, enabling a wide range of applications from creative writing to programming assistance. More recently, OpenAI's GPT-4, released in 2023, continued this trend, offering even greater capabilities, although specific details about its size and data remain proprietary.
Key components of LLMs
LLMs are complex systems with several critical components that enable them to understand and generate human language. The key elements are neural networks, deep learning, and transformers.
Neural Networks
LLMs are built on neural network architectures, computing systems inspired by the human brain. These networks consist of layers of interconnected nodes (neurons). Neural networks process and learn from data by adjusting the connections (weights) between neurons based on the input they receive. This adjustment process is called training.
Deep Learning
Deep learning is a subset of machine learning that uses neural networks with multiple layers, hence the term "deep." It allows LLMs to learn complex patterns and representations in large datasets, making them capable of understanding nuanced language contexts and generating coherent text.
Transformers
The Transformer architecture, introduced in the 2017 paper "Attention Is All You Need" by Vaswani et al., revolutionized natural language processing (NLP). Transformers use an attention mechanism that enables the model to focus on different parts of the input text, understanding context better than previous models. Transformers consist of encoder and decoder layers. The encoder processes the input text, and the decoder generates the output text.
How Do LLMs Work?
LLMs operate by harnessing deep learning techniques and extensive textual datasets. These models typically employ transformer architectures, such as the Generative Pre-trained Transformer (GPT), which excels in handling sequential data like text inputs.

This image illustrates how LLMs are trained and how they generate responses.
Throughout the training process, LLMs can forecast the next word in a sentence by considering the context that precedes it. This involves assigning probability scores to tokenized words, broken into more minor character sequences, and transforming them into embeddings, numerical representations of context. LLMs are trained on massive text corpora to ensure accuracy, enabling them to grasp grammar, semantics, and conceptual relationships through zero-shot and self-supervised learning.
Once trained, LLMs autonomously generate text by predicting the next word based on received input and drawing from their acquired patterns and knowledge. This results in coherent and contextually relevant language generation that is useful for various Natural Language Understanding (NLU) and content generation tasks.
Moreover, enhancing model performance involves tactics like prompt engineering, fine-tuning, and reinforcement learning with human feedback (RLHF) to mitigate biases, hateful speech, and factually incorrect responses termed "hallucinations" that may arise from training on vast unstructured data. This aspect is crucial in ensuring the readiness of enterprise-grade LLMs for safe and effective use, safeguarding organizations from potential liabilities and reputational harm.
LLM use cases
LLMs have various applications across various industries due to their ability to understand and generate human-like language. Here are some everyday use cases, along with a real-world example as a case study:
- Text generation: LLMs can generate coherent and contextually relevant text, making them useful for tasks such as content creation, storytelling, and dialogue generation.
- Translation: LLMs can accurately translate text from one language to another, enabling seamless communication across language barriers.
- Sentiment analysis: LLMs can analyze text to determine the sentiment expressed, helping businesses understand customer feedback, social media reactions, and market trends.
- Chatbots and virtual assistants: LLMs can power conversational agents that interact with users in natural language, providing customer support, information retrieval, and personalized recommendations.
- Content summarization: LLMs can condense large amounts of text into concise summaries, making it easier to extract critical information from documents, articles, and reports.
Case Study:ChatGPT
OpenAI's GPT-3 (Generative Pre-trained Transformer 3) is one of the most significant and potent LLMs developed. It has 175 billion parameters and can perform various natural language processing tasks. ChatGPT is an example of a chatbot powered by GPT-3. It can hold conversations on multiple topics, from casual chit-chat to more complex discussions.
ChatGPT can provide information on various subjects, offer advice, tell jokes, and even engage in role-playing scenarios. It learns from each interaction, improving its responses over time.
ChatGPT has been integrated into messaging platforms, customer support systems, and productivity tools. It can assist users with tasks, answer frequently asked questions, and provide personalized recommendations.
Using ChatGPT, companies can automate customer support, streamline communication, and enhance user experiences. It provides a scalable solution for handling large volumes of inquiries while maintaining high customer satisfaction.
Developing AI-Driven Solutions with LLMs
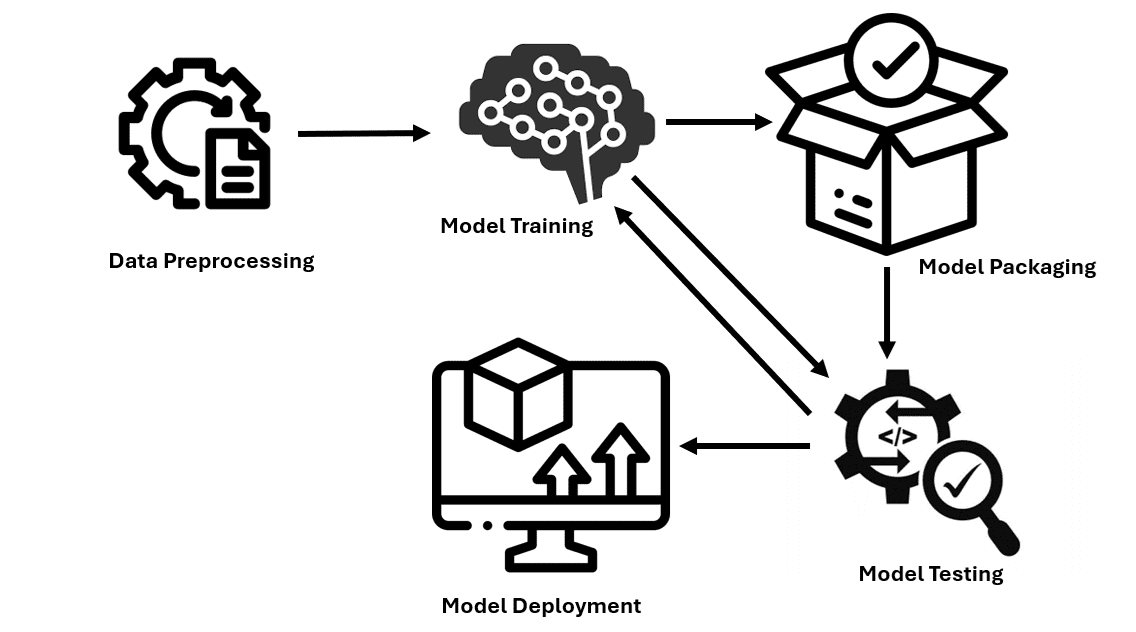
Developing AI-driven solutions with LLMs involves several key steps, from identifying the problem to deploying the solution. Let's break down the process into simple terms:

This image illustrates how to develop AI-driven solutions with LLMs | Source: Image by author.
Identify the Problem and Requirements
Clearly articulate the problem you want to solve or the task you wish the LLM to perform. For example, create a chatbot for customer support or a content generation tool. Gather insights from stakeholders and end-users to understand their requirements and preferences. This helps ensure that the AI-driven solution meets their needs effectively.
Design the Solution
Choose an LLM that aligns with the requirements of your project. Consider factors such as model size, computational resources, and task-specific capabilities. Tailor the LLM to your specific use case by fine-tuning its parameters and training it on relevant datasets. This helps optimize the model's performance for your application.
If applicable, integrate the LLM with other software or systems in your organization to ensure seamless operation and data flow.
Implementation and Deployment
Train the LLM using appropriate training data and evaluation metrics to assess its performance. Testing helps identify and address any issues or limitations before deployment. Ensure that the AI-driven solution can scale to handle increasing volumes of data and users while maintaining performance levels. This may involve optimizing algorithms and infrastructure.
Establish mechanisms to monitor the LLM's performance in real time and implement regular maintenance procedures to address any issues.
Monitoring and Maintenance
Continuously monitor the performance of the deployed solution to ensure it meets the defined success metrics. Collect feedback from users and stakeholders to identify areas for improvement and iteratively refine the solution. Regularly update and maintain the LLM to adapt to evolving requirements, technological advancements, and user feedback.
Challenges of LLMs
While LLMs offer tremendous potential for various applications, they also have several challenges and considerations. Some of these include:
Ethical and Societal Impacts:
LLMs may inherit biases present in the training data, leading to unfair or discriminatory outcomes. They can potentially generate sensitive or private information, raising concerns about data privacy and security. If not properly trained or monitored, LLMs can inadvertently propagate misinformation.
Technical Challenges
Understanding how LLMs arrive at their decisions can be challenging, making it difficult to trust and debug these models. Training and deploying LLMs require significant computational resources, limiting accessibility to smaller organizations or individuals. Scaling LLMs to handle larger datasets and more complex tasks can be technically challenging and costly.
Legal and Regulatory Compliance
Generating text using LLMs raises questions about the ownership and copyright of the generated content. LLM applications need to adhere to legal and regulatory frameworks, such as GDPR in Europe, regarding data usage and privacy.
Environmental Impact
Training LLMs is highly energy-intensive, contributing to a significant carbon footprint and raising environmental concerns. Developing more energy-efficient models and training methods is crucial to mitigate the environmental impact of widespread LLM deployment. Addressing sustainability in AI development is essential for balancing technological advancements with ecological responsibility.
Model Robustness
Model robustness refers to the consistency and accuracy of LLMs across diverse inputs and scenarios. Ensuring that LLMs provide reliable and trustworthy outputs, even with slight variations in input, is a significant challenge. Teams are addressing this by incorporating Retrieval-Augmented Generation (RAG), a technique that combines LLMs with external data sources to enhance performance. By integrating their data into the LLM through RAG, organizations can improve the model's relevance and accuracy for specific tasks, leading to more dependable and contextually appropriate responses.
Future of LLMs
LLMs' achievements in recent years have been nothing short of impressive. They have surpassed previous benchmarks in tasks such as text generation, translation, sentiment analysis, and question answering. These models have been integrated into various products and services, enabling advancements in customer support, content creation, and language understanding.
Looking to the future, LLMs hold tremendous potential for further advancement and innovation. Researchers are actively enhancing LLMs' capabilities to address existing limitations and push the boundaries of what is possible. This includes improving model interpretability, mitigating biases, enhancing multilingual support, and enabling more efficient and scalable training methods.
Conclusion
In conclusion, understanding LLMs is pivotal in unlocking the full potential of AI-driven solutions across various domains. From natural language processing tasks to advanced applications like chatbots and content generation, LLMs have demonstrated remarkable capabilities in understanding and generating human-like language.
As we navigate the process of building AI-driven solutions, it is essential to approach the development and deployment of LLMs with a focus on responsible AI practices. This involves adhering to ethical guidelines, ensuring transparency and accountability, and actively engaging with stakeholders to address concerns and promote trust.
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.
More On This Topic
- Top Open Source Large Language Models
- More Free Courses on Large Language Models
- Learn About Large Language Models
- Introducing Healthcare-Specific Large Language Models from John Snow Labs
- What are Large Language Models and How Do They Work?
- AI: Large Language & Visual Models