Tencent has introduced VoCo-LLaMA, a new approach that can efficiently compress hundreds of vision tokens into just a single token while minimising loss of visual information. The method introduces special “Vision Compression” (VoCo) tokens between visual and text tokens in large language models, allowing the model itself to compress and distil the vision tokens.
Click here to check out the paper.
With VoCo-LLaMA, a compression ratio of 576x can be achieved while retaining 83.7% of performance on common visual understanding benchmarks like GQA, MMBench, and VQAv2. The compressed tokens also enable major efficiency gains – up to 99.8% reduction in cache storage, 94.8% fewer FLOPs, and 69.6% faster inference time.
By leveraging attention distillation, VoCo-LLaMA distils how large language models understand uncompressed vision tokens into their processing of the compact VoCo tokens. This facilitates effective compression without specialised cross-modal modules.
The approach can be easily implemented by modifying the attention mask during standard visual instruction tuning, without additional training phases. On video benchmarks like MSVD-QA and MSRVTT-QA, VoCo-LLaMA outperforms previous compression methods by capturing temporal correlations among compressed video frame tokens.
While promising, VoCo-LLaMA has limitations – it diminishes the model’s ability to understand uncompressed tokens and struggles with diverse fine-grained compression levels. But it offers a path to overcome the context window bottleneck in vision-language models for more scalable multi-modal applications.
Last year, Apple published a paper titled “LLM in a Flash: Efficient Large Language Model Inference with Limited Memory,” which outlines how to run large language models on devices with limited DRAM. It appears that Apple is optimising large language models for edge use cases.
The post Tencent Introduces VoCo-LLaMA for Compressing Visual Information with LLMs appeared first on AIM.
It is unlikely that AI safety for superintelligence and artificial general intelligence could be achieved directly without a track from current risks. Already, there are minute fractions of predicted existential threats of AGI that provide a map towards preparing for the unknowns, ahead.
AI is a dynamic non-living thing. Its dynamism applies to tasks, positive or otherwise, but it does not have a core aspect of what comes with the dynamism of organisms—the ability for some control, resulting in misuses like deepfakes and misinformation.
If it were possible to collect certain input and output vectors of large language models, it could become a near-term AI safety mechanism against present problems of deepfakes and misinformation.
Currently, what are the available technical options to fight deepfakes? Mostly guardrails, digital hashing, watermarks, authentication, encryption, identity verification, and others. While they hold potency in many aspects, they may not be thorough enough for the safety needs against several voice cloning or impersonation techniques, as well as deepfake images, videos, and misinformation reaches.
Though, without guardrails, these problems would have been much worse, guardrails appear to bear individual capability more than general capability, where safety may matter more.
How can deepfake audio be tracked at the source? How is it possible to collect this across AI tools that are indexed on search engines? How can this apply to deepfake videos and images, as well as misinformation?
A research area for AI safety, for now, could be web crawling and scraping of AI tools, for their embeddings. This could be possible by a different kind of robot.txt and data API. The research would explore how to do this, in intervals, for certain keywords, to monitor what is processed, to provide information, to sources where they might be used, to foil their impact on arrival.
In a recent report by Reuters, Exclusive: Multiple AI companies bypassing web standard to scrape publisher sites, licensing firm says, it is stated that “Multiple artificial intelligence companies are circumventing a common web standard used by publishers to block the scraping of their content for use in generative AI systems, content licensing startup TollBit has told publishers. TollBit said its analytics indicate “numerous” AI agents are bypassing the protocol, a standard tool used by publishers to indicate which parts of its site can be crawled. The robots.txt protocol was created in the mid-1990s as a way to avoid overloading websites with web crawlers. More recently, robots.txt has become a key tool publishers have used to block tech companies from ingesting their content free-of-charge for use in generative AI systems that can mimic human creativity and instantly summarize articles.”
Since AI models gather data on web scraping, it should be possible to allow some of their inputs and outputs to be scrapped as well, in a technical adventure that can be done within the province of the US AI Safety Institute and the UK’s.
These embeddings from several sources, around certain keywords or events timing, could become fresh sets of data to explore intent, using extensive dot products, predicting for major risks of AGI.
The compute requirement may be tapered by having the scraped embeddings in blocks, for reporting and tracking, aside from experimenting for future risks. This approach may also provide an extra option among ongoing efforts against hallucinations.
There is a new paper in Nature, Detecting hallucinations in large language models using semantic entropy, where the authors wrote, “Here we develop new methods grounded in statistics, proposing entropy-based uncertainty estimators for LLMs to detect a subset of hallucinations—confabulations—which are arbitrary and incorrect generations. Our method addresses the fact that one idea can be expressed in many ways by computing uncertainty at the level of meaning rather than specific sequences of words. Our method works across datasets and tasks without a priori knowledge of the task, requires no task-specific data and robustly generalizes to new tasks not seen before.”
What would it mean for AGI to be safe? A question is intent—good intent, as well as little to no goal direction, while it can be free enough to do good stuff. Efforts on these could begin now, with current misuses, which may prospect a general standard as well, where, long before AGI, AI outputs and inputs can be generally tracked, then monitored, in a way to gather use ranges, and place safety, against allowing open risks maturation.
Recently, Tesla chief Elon Musk reposted the picture of a giant GPU cooler in Texas with a caption that read, “We are nothing without our fans.” He revealed that the facility will use around 130 MW of power and cooling this year, increasing to over 500 MW in the next 18 months.
This underscores the fact that despite the increasing relevance of liquid cooling, traditional air coolers with heatsinks and fans remain the most common cooling solution.
He also shared that Tesla’s next-generation self-driving computer, now called AI5 instead of Hardware 5 (HW5), will consume about four times the energy of the current HW3 and HW4 computers when it launches in vehicles in the second half of 2025.
As computing performance continues to advance, effective thermal management is becoming a key engineering challenge. This is especially true for top-tier GPUs, as traditional air cooling becomes inadequate for rack densities of 20 kW or more.
Challenges Facing Liquid Cooling Adoption
However, there’s resistance to the shift to liquid cooling in data centres due to significant challenges that operators navigate today—despite this infrastructure being able to handle the heavy workload that comes with heavier racks for GPUs.
One of the primary obstacles is the high initial cost of implementing liquid cooling systems. A study projects that the global data centre liquid cooling market will grow from $2.6 billion in 2023 to $7.8 billion by 2028, with a compound annual growth rate (CAGR) of 24.4%.
This rapid growth underscores the substantial investments being made in this technology but also highlights the significant upfront costs that organisations must consider.
Infrastructure modifications present another major hurdle. Many existing data centres require extensive retrofitting to accommodate liquid cooling systems.
This challenge is reflected in a survey by Uptime Institute, which found that fewer than 10% of data centre operators have adopted liquid cooling at a significant scale. The complexity of these modifications often deters widespread adoption, particularly in older facilities.
This concern is not merely theoretical but grounded in reality with indicators like Data Center Physical Infrastructure (DCPI) revenue growth slowing down in the first quarter of 2024.
This slowdown is attributed to design shifts aimed at supporting accelerated computing infrastructure of AI workloads that need more time to materialise.
Liquid cooling systems also introduce new operational challenges. They are generally more complex to maintain than traditional air cooling systems, requiring regular inspections for leaks, fluid quality checks, and specialised maintenance procedures.
The risk of leaks is particularly concerning, as even small amounts of liquid can cause significant damage to sensitive electronic equipment. Additionally, not all IT equipment is designed for liquid cooling, which may necessitate investments in new, compatible hardware or the implementation of hybrid cooling solutions.
But, Liquid Cooling is Gaining Ground
Despite these challenges, liquid cooling is steadily gaining adoption. For instance, India-based Ctrls is using advanced cooling technologies including liquid cooling for its 13MW DC3 data centre.
A study by Persistence Market Research projects that the global data centre liquid cooling market will reach approximately $31.07 billion by 2032, growing at a CAGR of 25.8% from 2021 to 2032.
The shift towards liquid cooling is driven by its superior efficacy, with liquid cooling being up to 3,000 times more effective at heat transfer than air. Liquid cooling also offers superior efficiency, consuming about 10% less energy than air cooling and reducing carbon emissions proportionally.
Due to these reasons, approximately 22% of data centres now utilise some form of liquid cooling, according to IDC analyst Sean Graham.
This remarkable growth is fueled by several key factors. Increasing rack densities, which now frequently exceed 20-30 kW per rack, are pushing the limits of traditional air-cooling efficiency.
Additionally, the rise of AI, machine learning, and high-performance computing workloads is creating the need for more robust cooling solutions. Sustainability goals and energy efficiency requirements also play a crucial role in driving the adoption of liquid cooling technologies.
Best of Both Worlds
In response to these changing needs, many data centres are adopting hybrid approaches that combine air and liquid cooling. This strategy allows for a gradual transition to more advanced cooling methods without the need to overhaul existing infrastructure completely.
Such hybrid solutions provide a bridge between traditional air cooling systems and the more efficient liquid cooling technologies of the future.
As data centre demands evolve, cooling strategies are likely to become more diverse, with air cooling remaining a significant part of the mix alongside various liquid cooling technologies in the near future.
Conclusively, while liquid cooling is gaining significant traction in the data centre industry, air cooling remains the dominant cooling method in 2024. The industry is in a state of transition, with hybrid solutions bridging the gap between traditional and advanced cooling technologies.
The post Elon Musk is Nothing Without His Fans appeared first on AIM.
Yet another generative AI venture has raised a bundle of money. And, like the others before it, it’s promising the moon.
Emergence, whose co-founders include Satya Nitta, the former head of global AI solutions at IBM’s research division, on Monday emerged from stealth with $97.2 million in funding from Learn Capital plus credit lines totaling more than $100 million. Emergence claims to be building an “agent-based” system that can perform many of the tasks typically handled by knowledge workers, in part by routing these tasks to first- and third-party generative AI models like OpenAI’s GPT-4o.
“At Emergence, we are working on multiple aspects of the evolving field of generative AI agents,” Nitta, Emergence’s CEO, told TechCrunch. “In our R&D labs, we are advancing the science of agentic systems and tackling this from a ‘first principles’ perspective. This includes critical AI tasks such as planning and reasoning as well as self-improvement in agents.”
Nitta says that the idea for Emergence came shortly after he co-founded Merlyn Mind, which builds education-oriented virtual assistants. He realized that some of the same technologies developed at Merlyn could be applied to automate workstation software and web apps.
So Nitta recruited fellow ex-IBMers Ravi Koku and Sharad Sundararajan to launch Emergence, with the goal of “advancing the science and development of AI agents,” in Nitta’s words.
“Current generative AI models, while powerful in language understanding, still lag in advanced planning and reasoning capabilities necessary for more complex automation tasks which are the provenance of agents,” Nitta said. “This is what Emergence specializes in.”
Emergence has a very aspirational roadmap that includes a project called Agent E, which seeks to automate tasks like filling out forms, searching for products across online marketplaces and navigating streaming services like Netflix. An early form of Agent E is already available, trained on a mix of synthetic and human-annotated data. But Emergence’s first finished product is what Nitta describes as an “orchestrator” agent.
This orchestrator, open-sourced Monday, doesn’t perform any tasks itself. Rather, it functions as a kind of automatic model switcher for workflow automations. Factoring in things like the capabilities of and the cost to use a model (if it’s third-party), the orchestrator considers the task to be performed — e.g. writing an email — then chooses a model from a developer-curated list to complete that task.
An early version of Emergence’s Agent E project.Image Credits: Emergence
“Developers can add appropriate guardrails, use multiple models for their workflows and applications, and seamlessly switch to the latest open-source or generalist model on demand without having to worry about issues such as cost, prompt migration or availability,” Nitta said.
Emergence’s orchestrator seems quite similar in concept to AI startup Martian’s model router, which takes in a prompt intended for an AI model and automatically routes it to different models depending on things like uptime and features. Another startup, Credal, provides a more basic model-routing solution driven by hard-coded rules.
Nitta doesn’t deny the similarities. But he not-so-subtly suggests that Emergence’s model-routing tech is more reliable than others; he also notes that it offers additional configuration features like a manual model selector, API management and a cost overview dashboard.
“Our orchestrator agent is built with a deep understanding of scalability, robustness and availability that enterprise systems need and is backed by decades of experience that our team possesses in building some of the most scaled AI deployments in the world,” he said.
Emergence intends to monetize the orchestrator with a hosted, available-through-an-API premium version in the coming weeks. But that’s only a slice of the company’s grand plan to build a platform that, among other things, processes claims and documents, manages IT systems, and integrates with customer relationship management systems like Salesforce and Zendesk to triage customer inquiries.
Toward this end, Emergence says it’s formed strategic partnerships with Samsung and touch display company Newline Interactive — both of which are existing Merlyn Mind customers, in what seems unlikely to be a coincidence — to integrate Emergence’s tech into future products.
Another screenshot of Emergence’s Agent E in action.Image Credits: Emergence
Which specific products and when can we expect to see them? Samsung’s WAD interactive displays and Newline’s Q and Q Pro series displays, Nitta said, but he didn’t have an answer to the second question, implying that it’s very early days.
There’s no denying that AI agents are buzzy right now. Generative AI powerhouses OpenAI and Anthropic are developing task-performing agentic products, as are big tech companies including Google and Amazon.
But it’s not obvious where Emergence’s differentiation lies, besides the sizeable amount of cash out of the starting gate.
TechCrunch recently covered another AI agent startup, Orby, with a similar sales pitch: AI agents trained to work across a range of desktop software. Adept, too, was developing tech along these lines, but despite raising more than $415 million reportedly now finds itself on the brink of a bailout from either Microsoft or Meta.
Emergence is positioning itself as more R&D-heavy than most: the “OpenAI of agents,” if you will, with a research lab dedicated to investigating how agents might plan, reason and self-improve. And it’s drawing from an impressive talent pool; many of its researchers and software engineers hail from Google, Meta, Microsoft, Amazon and the Allen Institute for AI.
Nitta says that Emergence’s guiding light will be prioritizing openly available work while building paid services on top of its research, a playbook borrowed from the software-as-a-service sector. Tens of thousands of people are already using early versions of Emergence’s services, he claims.
“Our conviction is that our work becomes foundational to how multiple enterprise workflows get automated in the future,” Nitta said.
Color me skeptical, but I’m not convinced that Emergence’s 50-person team can outgun the rest of the players in the generative AI space — nor that it’ll solve the overarching technical challenges plaguing generative AI, like hallucinations and the mammoth cost of developing models. Cognition Labs’ Devin, one of the best-performing agents for building and deploying software, only manages to get around a 14% success rate on a benchmark test measuring the ability to resolve issues on GitHub. There’s clearly a lot of work to be done to reach the point where agents can juggle complex processes without oversight.
Emergence has the capital to try — for now. But it might not in the future as VCs — and businesses — express increased skepticism in generative AI tech’s path to ROI.
Nitta, projecting the confidence of someone whose startup just raised $100 million, asserted that Emergence is well-positioned for success.
“Emergence is resilient due to its focus on solving fundamental AI infrastructure problems that have a clear and immediate ROI for enterprises,” he said. “Our open-core business model, combined with premium services, ensures a steady revenue stream while fostering a growing community of developers and early adopters.”
Meta has announced the launch of its AI assistant, Meta AI, across WhatsApp, Facebook, Instagram and Messenger in India. The AI-powered tool, built on Meta’s Llama 3, aims to help users with tasks like planning, learning, creating content and connecting with others.
One of the key advantages of Meta AI is its seamless integration into Meta’s popular apps, making it easily accessible to users on both Android and iOS devices as well as the web, according to Ryan Cairns, VP of Engineering at Meta.
“Our apps provide both the biggest distribution and the most availability to the end user,” Cairns said, contrasting Meta AI with competitors like Google Assistant and Siri which are more platform-specific.
Meta AI can assist with a wide range of use cases that users in India have already experienced during the pilot, such as gathering information, learning, coding help, generating social media content like captions and Instagram threads, and even creating stylised brand logos.
The AI’s “imagine” feature also enables users to generate and share unique images from text prompts and modify or animate them.
Addressing concerns about data privacy and potential misuse, Cairns stated that while using public information to train AI models is an industry-wide practice, building AI responsibly with a focus on safety is a top priority for Meta.
He noted that Meta AI’s images are stylised rather than photorealistic to prevent deepfakes, and that the models are updated every two weeks based on user feedback to improve accuracy and prevent misinformation.
Meta AI is currently available in English in India, with no other language options at this time. The company has expressed excitement about introducing this next-generation AI assistant to a wider audience and its potential positive impact on people’s daily lives.
The post Meta Launches AI Assistant in India Across WhatsApp, Facebook, Instagram appeared first on AIM.
Full-stack development is the most highly sought tech skill among freelance talent, according to Upwork’s March list of the most in-demand skills for freelance professionals in 2024. Among Upwork’s list of most in-demand skills for independent talent, the fastest-growing skills in data science and analytics were generative AI modeling, machine learning and data analytics. Generative AI modeling in particular saw a 70% year-over-year increase in the fourth quarter of 2023.
Below, we list the most in-demand skills for freelance professionals based on what businesses are looking for in tech, marketing, customer service, accounting and consulting, and design and creative categories.
SEE: Hiring kit: Data scientist (TechRepublic Premium)
Top 10 most in-demand data science and analytics skills for 2024
Data analytics.
Machine learning.
Data visualization.
Data extraction.
Data engineering.
Data processing.
Data mining.
Experimentation and testing.
Deep learning.
Generative AI modeling.
Top 10 most in-demand coding and web development skills for 2024
Full-stack development.
Front-end development.
Web design.
Mobile app development.
Back-end development.
E-commerce website development.
UX/UI design.
Scripting and automation.
CMS development.
Manual testing.
Top 10 most in-demand marketing skills for 2024
Social media marketing.
SEO.
Sales and business development.
Lead generation.
Telemarketing.
Search engine marketing.
Marketing automation.
Email marketing.
Marketing strategy.
Campaign management.
Top 10 most in-demand customer service and admin support skills for 2024
General virtual assistance.
Data entry.
Digital project management.
General research services.
Dropshipping and order processing.
Market research.
Executive virtual assistance.
Manual transcription.
Development and IT project marketing.
Medical virtual assistance.
Top 10 most in-demand accounting and consulting skills for 2024
Accounting.
Bookkeeping.
Recruiting and talent sourcing.
Financial analysis and modeling.
Management consulting.
Instructional design.
HR administration.
Business analysis and strategy.
Tax preparation.
Financial management/CFO.
Top 10 most in-demand design and creative skills for 2024
Graphic design.
Video editing.
Presentation design.
Illustration.
Image editing.
3D animation.
Video production.
Product and industrial design.
Cartoon and comic illustration.
Logo design.
Why is freelance work so popular now?
Even during economic uncertainty and with many professionals reevaluating their work priorities, companies continue to face a persistent talent shortage. Recent Upwork data indicates 64 million Americans performed freelance work in the 12 months before the polling dates of October 24, 2023 and November 9, 2023. That represents 39% of the U.S. workforce, an all-time high.
When asked their reasons for freelancing, respondents often cited, “to have flexibility in my schedule,” “to be in control of my own financial future,” and “to work from the location of my choosing.” Of freelancers, 60% work remotely, compared to 32% of the non-freelance professionals polled.
“In 2024, emergent technologies like generative AI are having a major impact on the skills-based economy,” wrote Kelly Monahan, managing director of the Upwork Research Institute, in the 2024 report on in-demand skills. “Of course business demand for these types of skills is increasing, but we’re also seeing a complementary impact, whereby AI technology is driving greater demand for all types of work across our marketplace.”
Methodology of the Upwork survey
Skills data was sourced from the Upwork database and is based on U.S. freelancer earnings from January 1, 2023 to December 31, 2023, Upwork said. Each skill had a minimum of 250 projects with active work during the period. Year-over-year growth was estimated by comparing the freelancer earnings in 2023 to freelancer earnings in the same period in 2022.
Note: This article was updated from the original version, which covered the same report from last year.
In an era where data is worth more than gold, data scientists are on the cutting edge of business development. But now, a new player has joined the data science game, and its name is Artificial Intelligence (AI). Many in this field wonder how AI will influence their industries, roles, and day-to-day operations.
So, for today’s article, let’s explore eight ways AI has already been incorporated into data science. Some you might know, while others you might not expect! Will your job as a data scientist be affected? Dive in to find out.
8 unexpected ways that AI is influencing data science
Automated data preparation (ADP)
Data science has never been an easy job — you try gathering, cleaning, and processing enormous datasets every day! In fact, 76% of data scientists dread this part of their job. Thanks to the wonders of AI, this time-consuming task has been automated.
Once fed the raw dataset, your AI of choice will return your data in a usable format. This way, data scientists can focus on their most important tasks. ADP also reduces the chances of human error.
Find patterns in huge datasets
AI-powered neural networks are a powerhouse when it comes to anomaly and pattern detection in complex datasets. These algorithms can spot relationships between data that otherwise would have been missed.
Data scientists often know exactly what they’re looking for and might not realize the more subtle connections between data. These patterns, after all, are the insights data scientists are searching for.
The new age of predictive analytics
With this powerful ability to find even the faintest relationships between data, predictive analytics have also evolved. Arguably the most important role of data scientists, predictions are what give businesses a leg-up on their competition.
Anomaly and pattern detection help to forecast future trends.
Datasets can be fed to AI chatbots for automated predictions.
AI can assess historical data before making predictions.
Customer intent, market trends, and financial forecasts can be automated.
Chatbots can assist in data exploration
In the end, it’s rarely data scientists that make the big business decisions based on their findings. Shareholders and executives will likely want to understand your findings, too — here’s where AI can be a tour guide of sorts:
Chatbots can answer Q&As regarding the dataset;
Automatically simplify or advance technical language used;
Any staff member can be walked through the dataset and findings, regardless of technical knowledge.
Fraud prevention safeguards data scientists
AI has allowed the cybersecurity industry to advance data protection in various ways. One of the greatest improvements caused by AI is the strides taken in fraud prevention technology.
Data scientists are no strangers to cyber attacks, being the gatekeepers of confidential business data. All data scientists should have next-gen firewalls, high-end encryption (e.g.: Surfshark VPN), and flawless cyber hygiene.
Recruitment is precise and automated
Depending on the industry, data scientists have varied roles within their companies. However, an uncommon role for a data scientist is in the recruitment process. Yet, with AI at their side, data scientists are being tasked with streamlining this process.
AI can filter through thousands of CVs and resumes;
All suitable candidates are compiled according to the desired skills;
Everything from work history to personality can be automatically assessed.
Menials tasks are turbocharged with AI
Forming the bulk of a data scientist’s job are various menial tasks that often consume entire work days. AI can help data scientists to instantaneously produce:
Boiler-plate or unique code;
Email responses;
Data summaries and reports;
Visual components like graphs, diagrams, etc.
AI not only performs these menial tasks as accurately as humans but also in a fraction of the time.
Transparency has never been easier
Many open-source AI models allow companies, their customers, and data scientists to gain deep insights into the AI clockwork. This enables businesses to comprehend the data science process and share this transparency with their shareholders. This added transparency enables companies to:
Explore and understand the technical side of their AI helpers;
Ensure a high ethical standard with no bias detected in the AI;
Understand complex relationships and patterns in datasets.
Conclusion
AI’s impact on the world of data science is inevitable. Data scientists have welcomed the advances of AI as a tool to reach deeper insights and make precise market predictions. From preventing cyber attacks to offering transparency, the effects of AI on data science have only begun. So, what impact do you think AI will have on data science next?
OpenAI has acquired a startup called Multi to build the ChatGPT desktop app. Alexander Embiricos, the founder of Multi, will be joining OpenAI. Effective today, Multi will be shut down. “We’ve closed new team signups, and currently active teams will be able to use the app until July 24, 2024, after which we’ll delete all user data,” the company said in a blog post.
“We’ve been increasingly asking ourselves how we should work with computers. Not on or using computers, but truly with computers. With AI. We believe it’s one of the most important product questions of our time,” added the company in its blog post.
“So much to say, but what matters most? Talking to users and shipping. With that in mind… I couldn’t be more excited to have joined the ChatGPT desktop team. Send me your feedback and bug reports. DMs open!,” posted Embiricos on X.
So much to say, but what matters most? Talking to users and shipping. With that in mind… I couldn’t be more excited to have joined the ChatGPT desktop team. Send me your feedback and bug reports. DMs open! https://t.co/Nrn94w46ex
— Alexander Embiricos (@embirico) June 24, 2024
Multi, previously known as Remotion, is a collaboration platform co-founded by Embiricos in 2021 during the significant shift to remote work. The company aimed to replicate the spontaneous collaboration of in-person work environments through a remote communication platform. The goal was to facilitate impromptu video calls and presence-based interactions.
Multi allows users to share applications across workspaces. Teams can code, edit, and work together as if they were side by side, regardless of their physical location. The platform supports native apps to provide the best user experience, emphasising clear screen sharing and audio quality.
The company raised $13 million in funding to date from investors including Greylock Partners and First Round.
This is OpenAI’s second acquisition in a week, following its purchase of Rockset, a data analytics company co-founded in 2016 by former Meta engineers Dhruba Borthakur and Venkat Venkataramani, for $105 million (INR 905 crore). This acquisition aims to leverage Rockset’s advanced analytics to enhance OpenAI’s retrieval infrastructure.
The post OpenAI Acquires Startup Multi to Develop ChatGPT Desktop App appeared first on AIM.
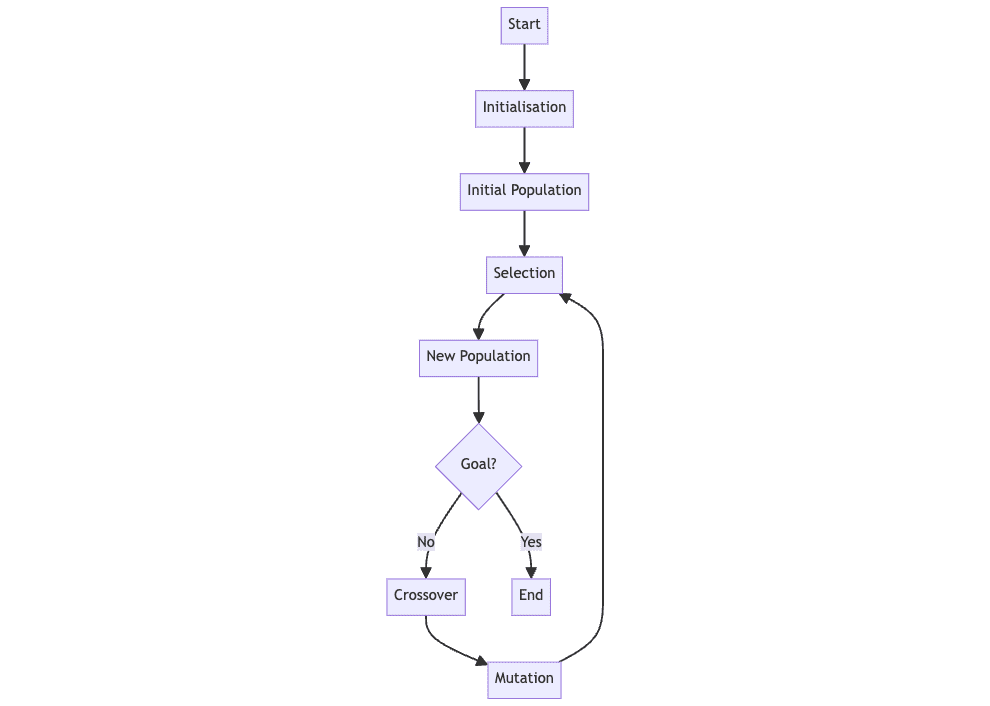
Genetic algorithms are techniques based on natural selection used to solve complex problems. They are used to arrive at reasonable solutions to the problem rather than other methods because the problems are complicated. In this article, we will cover the basics of genetic algorithms and how they can be implemented in Python.
Genetic Components
Fitness Function
The fitness function gauges the proximity of a considered solution to the best possible solution to the problem. It provides a fitness level for each person in the population, which describes the quality or efficiency of the current generation. This score defines the choice while the higher fitness value suggests an improved solution. For instance, suppose we are involved in the process of dealing with an actual function, f(x) in which x is a set of parameters. The optimal value to find is x so that f(x) assumes the largest value.
Selection
This is a process that defines which individuals within the present generation are to be favored and thus reproduce and contribute to the next generation. It is possible to identify many selection methods, and each of them has its own features and suitable contexts.
Roulette Wheel Selection: Depending on the fitness level of the individual, the probability of choosing the individual is also maximal.
Tournament Selection: A group is randomly selected and the best of them is taken.
Rank-Based Selection: People are sorted according to fitness and selection chances are proportionally allocated according to the fitness scores.
Crossover
Crossover is a basic concept of genetic algorithm that aims at the exchange of genetic information of two parent individuals to form one or more progeny. This process is closely similar to the crossover and recombination of the biology happening in nature. Applying the basic principles of heredity, crossover attempts to produce offspring that will embody desirable characteristics of the parents and, thus, possess better adaptation in the next generations. Crossover is a relatively broad concept which can be divided into several types each of which has their peculiarities and the sphere where they can be applied effectively.
Single-Point Crossover: A crossover point is chosen on the parent chromosomes and only one crossover actually happens. Prior to this position all genes are taken from the first parent, and all genes since this position are taken from the second parent.
Two-Point Crossover: Two breakpoints are selected and the part between them is swapped between the two parent chromosomes. It also favors interchanging of genetic information as opposed to single point crossover.
Mutation
In Genetic Algorithms, mutation is of paramount significance because it provides diversity which is a crucial factor when avoiding convergence directly towards the area of the optimum solutions. Therefore, getting random changes in the string of an individual mutation allows the algorithm to go into other regions of the solution space that it cannot reach by means of crossover operations alone. This stochastic process ensures that no matter what, the population will evolve or shift its position in the areas of the search space which have been identified as optimal by the genetic algorithm.
Steps To Implement A Genetic Algorithm
Let’s try to implement the genetic algorithm in Python.
Problem Definition
Problem: Compute on the specific function; f(x) = x^2f(x) = x^2; only integer values of x. Fitness Function: For the case of a chromosome that is binary being x, an example of the fitness function could be f(x)= x^2.
def fitness(chromosome): x = int(''.join(map(str, chromosome)), 2) return x ** 2
Population Initialization
Generate a random chromosome of a given length.
def generate_chromosome(length): return [random.randint(0, 1) for _ in range(length)] def generate_population(size, chromosome_length): return [generate_chromosome(chromosome_length) for _ in range(size)] population_size = 10 chromosome_length = 5 population = generate_population(population_size, chromosome_length)
Fitness Evaluation
Evaluate the fitness of each chromosome in the population.
fitnesses = [fitness(chromosome) for chromosome in population]
Selection
Use roulette wheel selection to select parent chromosomes based on their fitness.
def select_pair(population, fitnesses): total_fitness = sum(fitnesses) selection_probs = [f / total_fitness for f in fitnesses] parent1 = population[random.choices(range(len(population)), selection_probs)[0]] parent2 = population[random.choices(range(len(population)), selection_probs)[0]] return parent1, parent2
Crossover
Use single-point crossover by choosing a random cross-over position in a parents’ string and swapping all the gene values after this location between the two strings.
Implement mutation by flipping bits with a certain probability.
def mutate(chromosome, mutation_rate): return [gene if random.random() > mutation_rate else 1 - gene for gene in chromosome] mutation_rate = 0.01
Wrapping Up
To sum up, genetic algorithms are consistent and efficient for solving optimization problems that cannot be solved directly as they mimic the evolution of species. Thus, once you grasp the essentials of GAs and understand how to put them into practice in Python, the solution to complex tasks will be much easier. Selection, crossover, and mutation keys enable you to make modifications in solutions and get the best or nearly best answers constantly. Having read this article, you are prepared to apply the genetic algorithms to your own tasks and thereby improve in different tasks and problem solving.
Jayita Gulati is a machine learning enthusiast and technical writer driven by her passion for building machine learning models. She holds a Master's degree in Computer Science from the University of Liverpool.
More On This Topic
Understanding by Implementing: Decision Tree
Understanding Machine Learning Algorithms: An In-Depth Overview
Genetic Programming in Python: The Knapsack Problem
Implementing DBSCAN in Python
KDnuggets News, August 24: Implementing DBSCAN in Python • How to…
Atena Reyhani is Chief Product Officer at ContractPodAi
With the deployment of generative artificial intelligence (GenAI) happening at a rapid pace, organizations of all sizes are tasked with navigating the challenges around implementation, especially regarding ethics and accuracy.
What is important for corporate leaders is establishing clear guidelines and guardrails for GenAI that encourage responsible AI usage and avoid unintended consequences. Product teams and business leaders, meanwhile, should secure a path for their organization’s digital transformation journey, safely building and employing AI solutions across the enterprise in an ethical and transparent function.
With that in mind, here are four suggestions on areas companies can focus on to make sure ethics and safety are at the forefront of their GenAI implementation:
Leveraging Specialized LLMs
Public, one-size fits all domains only goes so far when ensuring security for verticalized use cases. This is why organizations deploying GenAI should focus on specialized enterprise large language models (LLMs) and vertical solutions. Vertical solutions add industry-relevant frameworks, customer specific rules and information to enhance precision regarding business' needs.
By using specialized models and vertical solutions, leaders can not only make sure certain AI outputs are relevant to the business and its objectives and specific to the industry but also put in place guardrails for essential accuracy, privacy, and security.
Specialized LLMs can play a vital role in GenAI rollout
Having a guardrails-first mindset and strong governance mechanisms for the responsible use of AI helps protect companies against AI misuse and misleading content on one hand and breaches and cyber threats on the other.
Furthermore, if you’re leveraging a vendor’s GenAI solution, their values and practices must align with your organization’s values. For example, asking the vendor questions about how their data is being trained, what sort of guardrails they have in place, and how they go about ensuring security and ethical usage, will help you narrow down the right GenAI vendor to work with.
Raising AI Awareness with Training Initiatives
When GenAI is adopted and implemented in a company, leaders should implement employee training initiatives to help employees keep up with the technology, support them in understanding how the technology is, and is not, to be used, and to reinforce training on the human-in-the-loop approach when it comes to vetting the GenAI outputs.
This is all in an effort to make them comfortable with the introduction of GenAI and its application to other processes. It is a way to help them understand this technology’s possibilities as much as its limitations and creates a means to foster more literacy, promote engagement, and trust around the technology throughout the company. Also, by continuing to educate people on GenAI usage and offering ongoing training, leaders can build on that awareness and trust, increasing comfortability with AI technology and decreasing chances of its misuse.
Furthermore, not only is it important for the people to be trained, but the output of the GenAI is only as accurate as the data within. Organizations must ensure the data is being trained, and cleansed, that’s feeding into the GenAI.
Ensuring Strict Data Privacy Enterprise-Wide
In large industries—like legal, banking, and healthcare—inputting vast amounts of personal information into publicly accessible AI systems represents a substantial security risk to individuals.
If an organization is leveraging a vendor’s GenAI solution, they can check to see if their vendor fully controls the data that their LLMs are trained on and ensure the customer data isn’t used for model training. The data will be processed by AI, but it’s important that the AI does not learn or retain the customer data for privacy purposes.
Data privacy is of the utmost importance in GenAI deployment
To mitigate privacy risk, then, leaders must implement added safety measures and robust data governance practices—across the enterprise—around how this data is collected and retained.
This involves factoring in privacy considerations during AI design to limit unnecessary data exposure later on; putting strict limits on how long data is stored to prevent the storage of personal information over long periods and reducing the chances of it being exposed to breaches; and anonymizing and aggregating data—or removing identifiable information from datasets and combining individual data points into larger datasets—to shield people’s identities and personal details.
Take a “Human in The Loop” Approach
As mentioned above, AI systems can sometimes generate inaccurate or unexpected outputs—or what are known as “hallucinations.” These occurrences give rise to the need for leaders to supervise and evaluate the quality of AI responses with increasing regularity.
Companies can start by dedicating resources to monitor AI systems to improve their quality and, therefore, their trustworthiness. Think of overseeing the technology as watching over a child’s behavioral development: the quality of the oversight the AI or child is exposed to directly impacts their output and behavior respectively.
This means fostering fair and balanced AI outputs by constantly exposing AI models to diverse, unbiased, and wholly accurate data.
The Future of Generative AI
At the end of the day, the increasing advancement and regulation of GenAI calls for corporate leaders to establish accurate, secure, and trusted forms of the technology. It takes time to increase AI awareness with internal training initiatives, adopt and implement specific large language models, guarantee strict data privacy across the enterprise, and watch over and adjust the very latest AI systems.
But by embracing the unique opportunity to take the above measures—and many others—corporate leaders can advance corporate innovation that is not only ethically sound and socially responsible but also operationally advantageous for their business.
Atena Reyhani is Chief Product Officer at ContractPodAi. Her responsibilities include leading the product vision, product strategy, and roadmap. She leads the product team and works in close collaboration with the rest of the leadership team across the organization to formulate and execute the product vision. Prior to joining ContractPodAi, Atena led various cross-functional teams to develop products in Higher Education, Lottery & Gaming industries. Her educational background is a blend of computer science and business, and her areas of focus include brain-computer interfaces and AI-based business transformation.