CVPR 2024 (Conference on Computer Vision and Pattern Recognition) saw some of the most outstanding research papers on computer vision. As a preeminent event for new research in support of AI, ML, deep learning, and much more, it continues to lead the field.
This year, CVPR saw 11,532 papers submitted with 2,719 approvals, which is a considerable increase compared to last year that saw 9,155 papers and 2,359 accepted.
CVPR, a leading-edge expo, also provides a platform for networking opportunities with tutorials and workshops, with the event annually attracting over 10,000 scientists and engineers. It featured research papers presented by major tech companies, including Meta, Google, and others, which followed suit from last year.
Here are some of the top papers presented by Meta.
PlatoNeRF: 3D Reconstruction in Plato’s Cave via Single-View Two-Bounce Lidar
PlatoNeRF is an innovative method for reconstructing 3D scenes from a single view using two-bounce lidar data. By combining neural radiance fields (NeRF) with time-of-flight data from a single-photon lidar system, it reconstructs both visible and occluded geometry with enhanced robustness to ambient light and low albedo backgrounds.
This method outperforms existing single-view 3D reconstruction techniques by utilising pulsed laser measurements to train NeRF, ensuring accurate reconstructions without hallucination. As single-photon lidars become more common, PlatoNeRF offers a promising, physically accurate alternative for 3D reconstruction, especially for occluded areas.
Read the full paper here.
Relightable Gaussian Codec Avatars
Meta researchers developed Relightable Gaussian Codec Avatars, which create high-fidelity, relightable head avatars capable of generating novel expressions.
The method uses a 3D Gaussian geometry model to capture fine details and a learnable radiance transfer appearance model for diverse materials, enabling realistic real-time relighting even under complex lighting.
This approach outperforms existing methods, demonstrated on a consumer VR headset. By combining advanced geometry and appearance models, it achieves exceptional visual quality and realism suitable for real-time applications like virtual reality, though further research is needed to address scalability, accessibility, and ethical considerations.
Read the full paper here.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
The Nymeria dataset, the world’s largest of its kind, contains 300 hours of human motion data from 264 participants across 50 locations, captured using multimodal egocentric devices.
It includes 1200 recordings, 260 million body poses, 201.2 million images, 11.7 billion IMU samples, and 10.8 million gaze points, all synchronised into a single metric system.
The dataset features comprehensive language descriptions of human motion, totaling 310.5K sentences and 8.64 million words. It supports research tasks like motion tracking, synthesis, and understanding, with baseline results for models such as MotionGPT and TM2T.
Collected under strict privacy guidelines, the Nymeria dataset significantly advances egocentric motion understanding and supports breakthroughs in related research areas.
Read the full paper here.
URHand: Universal Relightable Hands
URHand is a universal relightable hand model using multi-view images of hands captured in a light stage with hundreds of identities.
Its key innovation is a spatially varying linear lighting model that preserves light transport linearity, enabling efficient single-stage training and adaptation to continuous illuminations without costly processes.
Combining physically-based rendering with data-driven modelling, URHand generalises across various conditions and can be quickly personalised using a phone scan. It outperforms existing methods in quality producing realistic renderings with detailed geometry and accurate shading.
URHand is suitable for applications in gaming, social telepresence, and augmenting training data for hand pose estimation tasks, representing a significant advancement in scalable, high-fidelity hand modelling.
Read the full paper here.
HybridNeRF: Efficient Neural Rendering via Adaptive Volumetric Surfaces
HybridNeRF enhances the speed of neural radiance fields (NeRFs) by blending surface and volumetric rendering methods. While traditional NeRFs are slow due to intensive per-ray sampling in volume rendering, HybridNeRF optimises by predominantly rendering objects as surfaces.
It requires fewer samples, and reserves volumetric modelling for complex areas like semi-opaque or thin structures.
Adaptive “surfaceness” parameters dictate this hybrid approach, which improves error rates by 15-30% compared to current benchmarks and achieves real-time frame rates of over 36 FPS at 2K x 2K resolution.
Evaluated on datasets including Eyeful Tower and ScanNet++, HybridNeRF delivers state-of-the-art quality and real-time performance through innovations like spatially adaptive surfaceness, distance-adjusted Eikonal loss, and hardware acceleration techniques, advancing neural rendering for immersive applications.
Read the full paper here.
Robust Human motion reconstruction via diffusion
The paper ‘RoHM: Robust Human Motion Reconstruction via Diffusion’ introduces a method for reconstructing 3D human motion from monocular RGB(-D) videos, focusing on noise and occlusion challenges.
RoHM uses diffusion models to denoise and fill motion data iteratively, improving upon traditional methods like direct neural network regression or data-driven priors with optimisation.
It divides the task into global trajectory reconstruction and local motion prediction, managed separately with a novel conditioning module and iterative inference scheme.
RoHM outperforms existing methods in accuracy and realism across various tasks, with faster test-time performance. Future work aims to enhance real-time capability and incorporate facial expressions and hand poses.
Read the full paper here.
Learning to Localise Objects Improves Spatial Reasoning in Visual-LLMs
LocVLM is a novel approach to enhance spatial reasoning and localisation awareness in visual language models (V-LLMs) such as BLIP-2 and LLaVA. The method utilises image-space coordinate-based instruction fine-tuning objectives to inject spatial awareness, treating location and language as a single modality.
This approach improves VQA performance across image and video domains, reduces object hallucination, enhances contextual object descriptions, and boosts spatial reasoning abilities.
The researchers evaluate their model on 14 datasets across five vision-language tasks, introducing three new localisation-based instruction fine-tuning objectives and developing pseudo-data generation techniques.
Overall, LocVLM presents a unified framework for improving spatial awareness in V-LLMs, leading to enhanced performance in various vision-language tasks.
Read the full paper here.
The post Top 7 Papers Presented by Meta at CVPR 2024 appeared first on AIM.
AI startups are not easy to build. The costs of computing alone are astronomical, with a majority of seed funding going towards training models and research. But what if you didn’t need to worry about renting GPUs?
Allen Institute of AI’s commonsense AI senior research director Yejin Choi posed this possibility at Databricks’ Data + AI Summit this year when discussing the possibilities of working with small language models (SLMs).
“Right now, the recipe is, ‘Let’s just make the models super big – the bigger, the better,’ but humans – you and I – can’t really remember all that context, you know?” she said.
In posing several ‘mission impossibles’ in building SLMs, one of the constraints she gave was in building a model without a GPU.
Choi’s Mission Impossibles for SLMs
The first “mission impossible” scenario that Choi went into was being able to summarise sentences without the use of reinforcement learning from human feedback (RLHF), extreme scale pre-training and supervised datasets at scale.
Taking it a step further, her second “mission impossible” was to do the same, but summarising documents this time instead of sentences, with the additional constraint of not relying on human-supervised critics.
Choi reduced the capabilities that her team were working with in the third “mission impossible”, stating that they tried to make older statistical n-gram language models relevant to neural language models.
In doing so, she said that they made an equivalent to infinity, it had to compute over trillions of tokens with an almost instantaneous response time, and finally, all of this had to be done without the use of GPUs.
This is done because SLMs do not require the massive amounts of compute that LLMs require, thereby foregoing the need for GPUs. Choi highlighted this by taking the example of Infini.gram, an engine built by researchers from Washington University and the Allen Institute for AI, which can be run with basic compute from CPUs.
In doing so, Choi demonstrated that it was possible to compete with larger models even under previously thought impossible constraints and with limited resources.
Her biggest contention was that AI would be as good as the data it was trained on, hence she speculated that synthesised data would be the way to go in the future.
“Please do not overgeneralise to conclude that all SLMs are completely out of the league. There are numerous other counterexamples that demonstrate that task-specific symbolic knowledge distillation can work across many different tasks and domains,” she said, highlighting that SLMs were still plenty effective if certain criteria were fulfilled.
High-Quality SLMs
Choi said that the commonly held belief at the moment is that we aren’t able to efficiently build the human-like ability to abstract information into AI models.
“You just abstract away everything I told you instantaneously but you still remember what I said so far. That’s really amazing human intelligence that we don’t yet know how to build efficiently through AI models. I believe that it’s possible, we’re just not trying hard enough because we’re blinded by just the magic of a scale,” she said.
This means that, in order to build an efficient SLM, the focus would need to be on perfecting abstraction within the model, rather than increasing the amount of training data that the model relies on.
Synthesised Data
Additionally, Choi focused on synthesised data, rather than what was already available, because, in her words, “We have to synthesise data because if it already exists somewhere on the internet, OpenAI has already crawled it.”
She said that while certain concerns exist about the use of synthetic data, including the quality of the data, as well as potential bias, the actual synthesis of data needs to be done carefully and in a way that is innovative.
Further, she said this was already occurring, highlighting a research paper on annotating synthesised data by Meta AI called the Segment Anything Model (or SAM). Another paper she highlighted was Microsoft’s ‘Textbooks Are All You Need’.
“When you have really high-quality data, or textbook quality data, synthesised, you can actually compete against larger counterparts across many different tasks,” she said.
Relying on synthesised data, SLMs can lower the cost of acquiring data and satisfy the need to use novel data while still training the model itself on high-quality data, as demonstrated by the ‘Textbooks Are All You Need’ research paper.
With synthesised data and perfecting abstraction, Choi believes that building SLMs can substitute the need for LLMs, especially thanks to the respite it allows in terms of compute.
The post Achieving Mission Impossible in AI with Yejin Choi appeared first on AIM.
Vertiv and Ballard Power Systems a PEM fuel cells provider, have announced a strategic technology partnership focused on developing hydrogen fuel cell backup power solutions for data centers and critical infrastructure. The scalable systems will range from 200kW to multiple megawatts.
The companies have successfully demonstrated a proof of concept at Vertiv’s facility in Ohio, integrating Ballard fuel cell power modules with a Vertiv Liebert EXL S1 uninterruptible power system (UPS).
Initial validations and tests showed the zero-emission backup power system operating successfully as part of an uninterruptible power architecture.
“As the soaring increase in data usage is driving up power demand and expansion of data centre capacity globally, the need to effectively manage electricity consumption and the carbon footprint of this energy-intensive sector is critical to achieve net-zero targets,” said Nicolas Pocard, vice president of marketing and strategic partnerships at Ballard.
The demonstrated system, called Vertiv Power Module H2, integrates two Ballard PowerGen 200kW fuel cell cabinets along with cooling, power conditioning, and hydrogen storage infrastructure. It is part of a 1 MW microgrid solution at Vertiv’s Customer Experience Center that also includes solar PV and battery energy storage.
Viktor Petik, vice president of Vertiv infrastructure solutions, said the adoption of AI and high-performance computing is driving demand for eco-friendly power solutions focused on zero-carbon and low-carbon alternatives.
“The successful fuel cell proof-of-concept with Ballard provides a viable option for customers strengthening their data center sustainability strategy, and those moving to a future-ready Bring Your Own Power model,” he stated.
The Vertiv Power Module H2 solution provides a rapidly deployable and scalable power infrastructure for new and existing data centers. It offers advantages such as zero greenhouse gas emissions, low noise, rapid power response, low maintenance, extended backup duration, optimized footprint, and multi-megawatt scalability.
The partnership aligns with Vertiv’s “One Vertiv, One World” sustainability strategy. The companies plan to demonstrate the fuel cell powered backup systems at the Smarter E Europe 2024 energy industry exhibition in June
The post Vertiv and Ballard Partner on Hydrogen Fuel Cells for Data Center Backup Power appeared first on AIM.
Founded in 2021 by Lawrance Amburose, Sekhar Reddy, William Rathinasamy, and Anuj Kumar Sen, Bengaluru-based Diggibyte Technologies focuses on providing data and platform engineering, data science AI, and consulting services to a variety of industries. The founders bring a wealth of experience and expertise in leveraging big data and analytics to drive business innovation and efficiency.
AIM got in touch with Anuj Kumar Sen, the chief technology officer of Diggibyte, to learn more about the company’s AI and data science operations, expansion plans, interview process, and work culture.
The company is currently hiring for five data science positions in Bengaluru with at least two years of experience in the field.
Inside Diggibyte’s Data Science Team
Diggibyte’s data science team has tackled numerous issues across various domains. “We have solved multiple problems using data science across the domain, which include customer insights and personalisation (home appliance),” Sen told AIM.
By collecting and analysing data from multiple channels, the 50-member data science team provided insights into customer purchasing behaviour, preferences, and needs to tailor marketing efforts and customer satisfaction.
When it comes to logistics, the team has addressed the problem of inaccurate demand predictions, an issue that can potentially lead to mismanagement of fleet drivers and resources. By analysing historical sales data, market trends, and seasonal variations, the team claims to have developed accurate demand forecasts.
An improved predictive capability helps clients optimise and plan their fleets and drivers, ensuring resources meet customer demand without impacting delivery efficiency or profitability.
Another notable project is the development of an AI-driven headline generator for Norwegian language articles. Using NLP models, this solution scans article content and claims to generate compelling headlines that capture the story’s essence.
Besides, the company also employs generative AI for multiple clients in construction, media, and retail. “Our team is currently working on a latent diffusion image-to-image in-painting model that can automate the process of lifestyle product photography and commercial photography for sports accessories,” he added.
Tech Stack
The team leverages both Transformer architecture models and GPT models depending on the task requirements. They have developed solutions using the Transformer library for an RAG system. Additionally, they created a chatbot for customer support utilising GPT-3.5 Turbo in Azure ML Studio.
In potential candidates, the company looks for proficiency in Python, SQL, Pandas, NumPy, and machine learning. They should also be adept in using frameworks like Keras or TensorFlow and have experience with Databricks.
In addition to these core competencies, data scientists are encouraged to have competitive programming skills, be fast learners, and stay updated with the latest developments in generative AI, preferably with hands-on experience.
Interview Process
The interview round at the company is followed by a thorough and structured process to assess both technical and interpersonal skills. It begins with two technical assessment rounds where candidates are evaluated on their fundamental data science skills and adaptability to the latest trends in data science and AI.
These are followed by an HR round focusing on the candidate’s interpersonal skills, career goals, collaborative abilities, and employment history.
The company sources its best fit by relying on a multi-channel approach to find the top talent in data science. This includes leveraging its internal careers page (set to be deployed in 20 days), online career portals, and trusted vendors.
Work Culture
Once employed, new hires can expect to work on cutting-edge AI projects. It also provides training to bridge gaps, if any, in both technical and interpersonal skills, supported by the leadership team.
“Since we have a separate team for analytics, engineering, visualisation, and machine learning, we expect candidates to have specialisation in one skill rather than general knowledge in multiple skills,” Sen explained.
Employees can pursue certifications from reputable sources such as Azure and Databricks. The company covers the exam costs. It offers a flexible work-life balance, accommodating four days’ of work-from-office and work-from-home arrangements, along with a supportive leave policy.
The company also has policies in effect to make job options accessible, inclusive and diverse for all. Efforts around healthcare and a positive office atmosphere promote employee well-being.
Diggibyte Technologies was certified as the Best Firm For Data Engineers and was awarded during DES 2024.
The post Data Science Hiring Process at Diggibyte appeared first on AIM.
Samsung on Tuesday said it built a Compute Express Link (CXL) infrastructure certified by open-source software provider Red Hat.
According to the South Korean tech giant, having the data center infrastructure in-house, an industry first, will allow Samsung to directly verify CXL-related products, software, and others that configure servers at Samsung Memory Research Center, its memory chip research arm, at Hwaseong, South Korea.
CXL products that are verified by Samsung can afterward immediately be requested for product registration to Red Hat, enabling faster product development for both the South Korean tech giant and customers.
Samsung said it has verified its CXL memory module DRAM (CMM-D) through the infrastructure this month. Going forward, it will provide tailored solutions to customers by optimizing products at earlier development stages, the company added.
CXL is a unified interface standard that connects various processors and memory devices through a PCIe interface at lower latency and higher bandwidth than existing standards. This allows existing data centers to improve speed, latency, and scalability at low cost.
The AI boom has put additional impetus on such a move to alter server architecture fundamentally as data centers face new challenges in operations from the massive explosion of data.
In December, Samsung, in collaboration with Red Hat, said it verified the use of CXL memory operation in a real user environment. Samsung became the first in the industry to offer CXL module, open-source software, and CXL DRAM supporting CXL 2, a culmination of the pair's partnership that started in May 2022.
Meanwhile, since then, Samsung's data center solid-state drive (SSD) products has also been certified, the South Korean tech giant said, allowing customers used Red Hat-certified products to build systems receiving Linux support based on them.
Last month, Samsung showed off its CMM-D1, embedded in Red Hat Enterprise Linux 9.3, which can enhance the performance of deep learning recommendation models or DLRM. In the demo, Samsung also showcased its scalable memory development kit's memory interleaving software.
LLMs are the talk of the town – maybe a little too much. Yann LeCun from Meta AI had recently shared similar sentiments. “If you are a student interested in building the next generation of AI systems, don’t work on LLMs. This is in the hands of large companies, there’s nothing you can bring to the table,” said LeCun at the VivaTech conference in Paris.
“The only way you could possibly contribute is by analysing existing LLMs and showing their power and limitations,” said LeCun, about what the researchers should focus on. When it comes to India, the thoughts are quite similar.
Though LeCun had praised the creation of Kannada Llama created by Adarsh Shirawalmath, he seems to be advocating the use of Llama in products more than creating any more LLMs.
Similarly, Raj Dabre, a researcher at NICT in Kyoto and adjunct faculty at IIT Madras, said the same thing. “If you’re a student or an academic dreaming of making LLMs for Indian languages, stop wasting your time. You’re not going to make it,” he said.
If you're not going to listen to me then atleast listen to the master. If you're a student or an academic dreaming of making LLMs for Indian Languages, stop wasting your time. You're not going to make it. Instead focus on more fundamental and focused problems like: 1. How to get… https://t.co/PHLzyfxZbU
— Raj Dabre (@prajdabre1) June 23, 2024
Solving Niche Problems is the Answer
Naveen Rao, the VP of generative AI at Databricks, told AIM that a vast majority of foundational model companies will fail.
“You’ve got to do something better than they [OpenAI] do. And, if you don’t, and it’s cheap enough to move, then why would you use somebody else’s model? So it doesn’t make sense to me just to try to be ahead unless you can beat them,” he added.
Francois Chollet, the creator of Keras, also recently shared similar thoughts about this. “OpenAI has set back the progress towards AGI by 5-10 years because frontier research is no longer being published and LLMs are an offramp on the path to AGI,” he said in an interview.
The LLM boom and then the advent of Indic Llama models has been particularly crucial for the misdirected efforts in the Indian AI landscape. Dabre argues that aspiring to develop LLMs for Indian languages is a misguided ambition. According to him, without substantial computational resources and exceptional talent, these efforts are doomed to fall short.
Instead, he suggests that researchers concentrate on more niche, yet fundamental, challenges in AI. Dabre pointed out the importance of honing LLMs to perform specific tasks, tackling the data challenges inherent in LLMs, and improving transfer learning from English to other languages.
He also emphasised the critical need for efficiency and the integration of external knowledge into LLMs.
This is something similar to what Pranav Mistry, the founder of TWO.AI also argued recently about researching on 1-bit LLMs, instead of building on top of the existing ones, and barely expanding the vocabulary.
Similarly, Dabre’s critique is also rooted in the current inefficacies of Indian language models. He noted that significant resources are being wasted on developing models with limited improvements over existing ones.
“Wasting all that time and compute to get a 7B LLM to the same few shot classification performance as a 200M parameter Bert, but with terrible performance for actual generative tasks only proves that you don’t know what you are doing,” said Dabre.
However, the trend in India has been criticised for a lack of originality. Much of the work involves tweaking existing models like Llama 2 and rebranding them as new products. This approach has led to a proliferation of models such as Tamil Llama, Telugu Llama, and Kannada Llama, which are essentially built on top of open-source English language models.
This strategy has been seen as a missed opportunity for genuine innovation. AI experts lament that India’s AI research landscape is overly reliant on Western models, resulting in a dearth of groundbreaking research.
Not Just LLM Alternatives
It might be too soon to write off LLMs completely, but the discussion on alternatives to LLM-based models has been gaining traction. Mufeed VH, the creator of Devika, advocates for moving away from Transformer models and exploring different architectures like RMKV, an RNN-based model.
Mufeed highlighted the potential of such architectures to offer unlimited context windows and improved inference capabilities. He believes that by focusing on these alternatives, researchers can develop models that rival the capabilities of current leading models like GPT-4.
LeCun’s advocacy for new architectures aligns with his broader vision of democratising AI technology. He warns against the concentration of AI development in the hands of a few large entities, as this could stifle diversity of thought and innovation. LeCun emphasised the importance of open-source platforms to ensure that AI development is inclusive and widely accessible.
The consensus among leading AI researchers is clear: Indian researchers need to move away from developing redundant LLMs and focus on solving fundamental problems in AI. For now, even though one can say that these fine-tuned models cannot be classified as products, they are ideal for research for students in universities.
The post Indian Researchers Need to Stop Making Useless LLMs appeared first on AIM.
Python continues to reign supreme as the world’s most popular programming language, according to the TIOBE Index. This versatile and user-friendly language, named after beloved British comedy troupe Monty Python, has become an essential tool for developers, data scientists and tech enthusiasts alike.
Python’s simplicity and readability make the programming language an ideal choice for beginners, while its robust libraries and frameworks support advanced applications in web development, machine learning and data analysis. TechRepublic takes a look at the top 10 Python courses available in 2024 for developers with different experiences and goals.
When assessing online courses, we examined the reliability and popularity of the provider, the depth and variety of topics offered, the practicality of the information, the cost and the duration. The courses and certification programs vary considerably, so be sure to choose the option that is right for your goals and learning style.
Best for beginners on a budget: Python Programming MOOC 2024 — University of Helsinki
Best for aspiring data analysts: Python for Everybody Specialization — University of Michigan — Coursera
Best for beginners who want daily lessons: 100 Days of Code — The Complete Python Pro Bootcamp — Udemy
Best for beginners who want a crash course: The Complete Python Bootcamp From Zero to Hero in Python — Udemy
Best for learning on the go: futurecoder
Best for automating real-life tasks: Automate the Boring Stuff with Python Programming — Udemy
Best for in-depth computer science: MITx Introduction to Computer Science and Programming Using Python — edX
Best for machine learning and data science for beginners: Professional Certificate in Learning Python for Data Science — Harvard University — edX
Best for advanced data analysts: Google Advanced Data Analytics Professional Certificate — Coursera
Best for well-known certification: PCAP- Programming Essentials in Python — Cisco Networking Academy
SEE: Udemy Report: Which IT Skills Are Most in Demand in Q1 2024?
Free course material, exams cost $59 and $295 per sitting.
75 hours
Beginner and Intermediate
Python Programming MOOC 2024 — University of Helsinki: Best for beginners on a budget
Live University of Helsinki lectures will be broadcast via Zoom in Fall 2024. Currently, you will find the recordings of the 2023 lectures. Image: University of Helsinki/Screenshot by TechRepublic
Python Programming MOOC 2024 is a highly-regarded Python course suitable for complete beginners and run by the University of Helsinki. MOOC stands for Massive Online Open Course, so there are no limitations on the number of students who can use the resources throughout the year.
Course content is split into 14 sections of notes, each of which come with about 30 exercises to complete in-browser. This is a self-paced course, though there are exams put on by the University of Helsinki at set dates and times. It is free, but to do the exercises, you need to sign up for a MOOC account.
Price
Free.
Duration
12 hour-long lectures with written notes and exercises. Those who have completed the course say it takes about two months overall.
Pros
It’s free.
Beginner friendly.
There’s an active Discord channel where course participants discuss their progress.
Cons
Must be self-motivated to complete, as it is self-paced.
Less intensive and in-depth than other listed courses.
Pre-requisites
None.
Visit Python Programming MOOC 2024
Python for Everybody Specialization — University of Michigan — Coursera: Best for aspiring data analysts
Dr Chuck teaches the basics of programming and how to pull and store data in databases in this course. Image: Coursera/Screenshot by TechRepublic
Charles Russell Severance, a Clinical Professor at the University of Michigan School of Information — AKA “Dr Chuck” — is the instructor for Python for Everybody Specialization on Coursera. It covers basic programming principles, but in the Python language, setting up participants to be able to move onto other languages. It covers all the fundamentals as well as data structures, web scraping, databases and more. It ends with a Capstone project where participants can build a program that retrieves, processes and visualises data from the web with a JavaScript library.
Price
$59 a month after a 7-day free trial.
Duration
10 hours a week for two months, but it can take up to eight months.
Pre-requisites
None.
Pros
Experienced instructor.
Beginner friendly.
Teaches practical uses of Python for entry-level data analysis role.
Cons
Course fees.
Requires significant time dedication.
Career certificate itself is not well-respected.
Visit Coursera
100 Days of Code — The Complete Python Pro Bootcamp — Udemy: Best for beginners who want daily lessons
Get to grips with Python by building 100 projects in 100 days with Dr Angela Yu. Image: Udemy/Screenshot by TechRepublic
Dr Angela Yu’s 100 Days of Code: The Complete Python Pro Bootcamp is designed to turn beginners into proficient Python programmers over a manageable timespan. Dr. Yu is a leading bootcamp instructor and has been invited by companies such as Twitter, Facebook and Google to teach their employees. Her course helps its students to actually understand the code rather than just churn out simple exercises by providing a challenge with every new concept. Topics covered include automation, game, app and web development, data science and machine learning. Reviewers praise the pacing, Dr. Yu’s teaching and the diverse projects.
Price
$109.99
Duration
100 days at one hour a day, however, course content is available on-demand.
Pre-requisites
None.
Pros
Experienced instructor.
Beginner friendly.
Encourages you to code every day.
Cons
Course fee.
Some outdated content based on reviewers comments.
There are self-guided projects towards the end of the course that some learners may find tricky without an instructor.
Visit Udemy
The Complete Python Bootcamp From Zero to Hero in Python — Udemy: Best for beginners who want a crash course
This course sees learners create mini games like Tic Tac Toe and Blackjack with Python. Image: Udemy/Screenshot by TechRepublic
Engineering graduate and professional instructor Jose Portilla leads The Complete Python Bootcamp From Zero to Hero in Python, another top-rated Udemy course. Through a series of 100 lectures, the course starts by guiding learners through installing Python on their operating system before getting into the basics and using the language to manipulate emails, PDFs, Excel files, images and more. Along with lectures, learners have access to tests, exercises and three larger projects.
Price
Full price is $189.99, though Udemy has weekly sales that see this reduced significantly.
Duration
22 hours of on-demand video lectures plus articles and exercises.
Pre-requisites
None. It does contain modules about advanced Python features that are suitable for programmers with basic experience.
Pros
Experienced instructor.
Good explanations of the basics.
Cons
Limited content on more advanced topics and using Python for real-life tasks.
Course fee.
Visit Udemy
futurecoder: Best for learning on the go
futurecoder does not have any video lectures; learners simply progress through exercises that gradually increase in complexity. Image: futurecoder/Screenshot by TechRepublic
If you’re not into video lectures and want to learn Python at your own pace through step-by-step exercises, then futurecoder may be the course for you. This has the fewest barriers to entry of all the courses, as no account is required to get started (but you can get one if you want to save your progress), and the whole thing takes place in-browser.
Standout features include the very gradual guidance provided with each exercise, rather than large hints or complete solutions. Answers are automatically graded, error messages are easily understandable and it provides debugging tools for extra understanding of what went wrong. futurecoder is 100% free and has no ads, and feels more like Duolingo for coding than a university-style course.
Price
Free.
Duration
60 exercises, each of which take between 10-30 minutes to complete.
Pre-requisites
None.
Pros
Free with no ads.
Slick interface.
Cons
No video tutorials, but this may be a pro depending on your learning style.
It’s quite short, not taking the learner to a very advanced level.
Visit futurecoder
Automate the Boring Stuff with Python Programming — Udemy: Best for automating real-life tasks
This course teaches how to automate tasks so they can be done in minutes by a computer rather than take hours manually. Image: Udemy/Screenshot by TechRepublic
Automate the Boring Stuff, taught by software engineer and tech book author Al Sweigart, is best for learners who want to dive right into real-world applications of Python. It is perfect for office and administrative workers looking to improve their productivity by programmatically updating spreadsheets, parsing documents, sending email alerts and more.
While there are a few quizzes, the majority of the course is screen recordings with Sweigart’s voiceover and some downloadable scripts, so those looking for something more interactive may want to choose a different course.
Price
Full price is $119.99; however, Udemy has weekly sales that see this reduced significantly.
Duration
9.5 hours.
Pre-requisites
None.
Pros
Focuses on practical uses of Python from the get-go.
Based on a well-reviewed book of the same name.
Book of theory can be downloaded for free.
Cons
There is not a lot about computer science theory, so this is not ideal for those looking to go into a career as a developer.
Certification is not well-regarded.
Course fee.
Some reviewers have found the exercises difficult without prior Python knowledge.
Visit Udemy
MITx Introduction to Computer Science and Programming Using Python — edX: Best for in-depth computer science
This MITx course is designed to help people learn to think computationally and write Python programs to tackle problems. Image: edX/Screenshot by TechRepublic
Introduction to Computer Science and Programming Using Python is the first course on this list to require a basic knowledge of mathematics and programming. Run by MITx, the online learning arm of the Massachusetts Institute of Technology, the lecture series intends to teach students how to think computationally to prepare them for a career in software engineering. It includes lecture videos, exercises and problem sets using Python 3.5 and covers lots of different areas, like algorithms, testing and debugging and data structures.
Price
$149 for full access to course materials and certification upon completion. However, limited access to course materials is provided for free, but you cannot take graded assignments or exams.
Duration
9 weeks, 14 – 16 hours a week.
Pre-requisites
High school algebra and a reasonable aptitude for mathematics are required. Students without a prior programming background will find there is a steep learning curve.
Pros
Expert tutoring from MIT professors.
Course material is free.
Cons
Course fee.
Not many real-world applications are taught that are based on the computer science theory.
Reviewers say it is easier with the accompanying textbook, which comes at an additional cost.
Complicated mathematics involved in the latter part of course.
Visit edX
Professional Certificate in Learning Python for Data Science — Harvard University — edX: Best for machine learning and data science for beginners
This course provides access to teaching from the world-class educational institute Harvard University. Image: edX/Screenshot by TechRepublic
If you’re looking to initiate a career in data science, then an education from Harvard University is a great place to start. The Professional Certificate in Learning Python for Data Science, offered via edEx, consists of video lectures, programming exercises and quizzes.
Learners have access to the Python portion of the famous CS50: Introduction to Computer Science module, as well as others covering probability, data science and machine learning. While the material becomes in-depth like the other courses on this list, it does begin with teaching how to read and write Python code. It also includes applications of Python specific to data science, utilising libraries like numPy, matplotlip and Pandas.
Price
$747.
Duration
6 months, three to six hours a week.
Pre-requisites
None.
Pros
Taught by Harvard University experts.
Specific to data science.
Cons
Course fee.
Course duration is long.
Visit edX
Google Advanced Data Analytics Professional Certificate — Coursera: Best for advanced data analysts
Google’s Advanced Data Analytics Professional certificate is best for those with some experience in analytics and statistics who want to become proficient in Python. Image: Coursera Academy/Screenshot by TechRepublic
Google’s Advanced Data Analytics Professional Certificate expects some proficiency with data analytics prior to starting the course, though Python fundamentals are covered as appropriate for beginners. The series of five courses takes learners from language and data analysis basics into more advanced regression analysis and machine learning.
Specifically, it covers the manipulation of large data sets, using machine learning to find patterns in data, data visualisation, analytics tools — like Jupyter Notebook, Tableau and more. Projects are distributed throughout the course that can add to the learner’s portfolio of work, and there is a capstone at the end that combines all the lessons.
Price
$59 a month after a 7-day free trial.
Duration
Six months at 10 hours a week.
Pre-requisites
Prior knowledge of foundational analytical principles, skills and tools. Some programming knowledge is also useful.
Pros
Goes beyond the theoretical to teach how to apply data analytics to real-world scenarios.
Includes information about the data analyst job market and how to prepare for applications.
Cons
Course fee.
Requires experience. Beginners should try the entry-level version.
Substantial time commitment required.
Visit Coursera
PCAP- Programming Essentials in Python — Cisco Networking Academy: Best for well-known certification
The free course PCAP: Programming Essentials in Python prepares learners for the PCEP and PCAP exams. Image: Cisco Networking Academy/Screenshot by TechRepublic
While certifications are somewhat controversial amongst developers, with some believing that experience is more valuable, pursuing a well-regarded accreditation is often a good way of ensuring you have comprehensive knowledge in an area. The Python Institute offers the most well-known set of Python certifications, which are aimed at four progressive levels: entry-level, associate, professional 1 and professional 2.
This free course from Cisco Networking Academy guides learners through the content of the first two levels and prepares them for the Certified Entry-Level Python Programmer Certification and Certified Associate Python Programmer Certification exams. Content is delivered through practice labs, interactive activities, videos and assessments.
Price
Free, though there are fees associated with the exams that lead to formal certification. Currently, it costs $59 to take the PCEP exam once and $295 for the PCAP.
Duration
75 hours.
Pre-requisites
None.
Pros
Beginner friendly.
Course content is free.
Cons
The exams are not free.
Visit Cisco Networking Academy
Is it worth paying for a Python course?
The short answer is it depends on your budget and what motivates you.
There is a wealth of free resources available through some of the courses listed here as well as in library books, on YouTube and elsewhere online that will enable a motivated student to get to grips with Python. Many developers insist it is possible to master programming without paying a penny by working on small projects like those on GitHub and learning on the go, which could be a good option for those on a budget. Alternatively, check out the free courses Python Programming MOOC 2024 and futurecoder.
However, the key to learning any new skill is to be persistent, and it can be difficult to remain motivated without a defined learning programme to follow, coursemates to connect with or a course fee at risk of going to waste. For individuals with a tendency to start projects but not finish them, an initial investment in a structured course may provide the motivation they need. Many paid courses also give direct access to qualified instructors who can provide tailored help that would otherwise not be available. Therefore, a paid course like 100 Days of Code may be worth it in the long run, as the fee provides motivation to continue progressing.
Is Python the best programming language to learn?
Python is widely regarded as one of the best programming languages for beginners for a number of reasons.
It is easy to understand, as its syntax is intuitive and closely resembles natural language.
It is versatile, used in various relevant domains such as web development, data science, automation, AI and scientific computing.
It has extensive libraries and frameworks, like NumPy, Pandas and TensorFlow, enabling developers to build larger programs without starting from scratch.
It integrates well with other commonly-used languages like C++ and Java, technologies like Terraform and REST APIs, and platforms like Amazon Web Services and Raspberry Pi.
It is used by many major tech companies, including Google, Netflix and Meta.
It has a large and active community of users who update tutorials, documents and open-source projects to support learning.
SEE: Top Python AI and Machine Learning Libraries
Do employers look at Python certifications?
Every employer is different, and while some may be looking for specific skills that are proven by well-regarded certifications, others may be more interested in project work, collaboration and other experiences. Before embarking on a Python course to obtain a certificate, look at the requirements of vacancies that interest you.
Certifications are somewhat controversial in the developer community for a number of reasons. Many believe that the availability of free resources for learning means that paid certifications are financially exploitative. Programming languages and technologies also evolve quickly, so certifications can become outdated but remain advertised as worthwhile. Some courses focus more on teaching theoretical knowledge rather than how to solve real-world problems, and therefore the certification is not representative of programming ability.
On the other hand, the job market for junior developers is tight, with many career-changers looking for an entry-level role in tech, and AI tools taking on tasks normally given to less experienced employees. Therefore, it is important to differentiate your CV from others, and certifications in specific areas of software development can be a good way of doing so. A certificate can also provide motivation to push through to the end of a lengthy course of study.
Google AI Overviews is a feature within Google Search that provides AI-generated summaries and insights at the top of search results. It is powered by Google’s custom artificial intelligence model, Gemini, and is designed to help users quickly find detailed and contextually relevant information from a variety of online sources.
The following guide is designed to help you understand Google AI Overviews, how it works and how it aligns with Google’s Search Generative Experience initiative.
Understanding Google AI Overviews
Google AI Overviews was previously part of SGE, a feature within Google Search that allowed users to tap into Google’s generative AI technology for text and image-based searches. This has since evolved into a broader experiment that expands Google’s generative AI capabilities to more parts of the search experience.
Google AI Overviews leans on the software giant’s custom large language model, Google Gemini, to provide snapshot-type answers to users’ search queries (hence “overviews”). Because Gemini is integrated into Google’s core web ranking system, AI Overviews can search and pull relevant information from Google’s own index.
The system is designed to make it easier for users to find the information they need quickly without having to scour through multiple sources. For example, if you’re looking for information on climate change, AI Overviews can provide a summarized response with key facts and statistics, along with links for further reading. In doing so, AI Overviews reduces the effort users need to put into searching for information by doing all the legwork for them — or so the theory goes.
Key features of Google AI Overviews
Multi-step reasoning
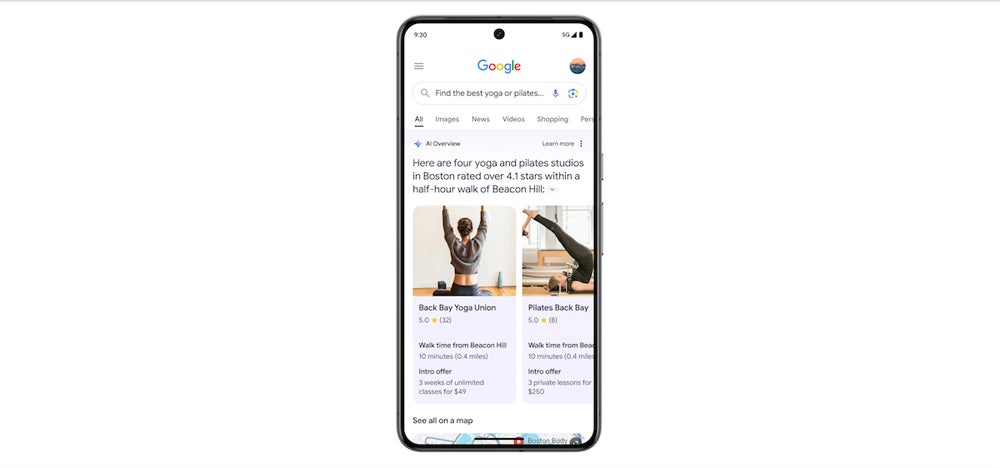
AI Overviews can handle complex, multi-part user queries by linking together related information and provide more nuanced responses as a result. For example, you could search “Show me the best gyms within 30 minutes’ drive with no joining fees,” and AI Overviews will show you nearby gyms, their distance from you and any relevant sign-up offers (Figure A).
Likewise, asking the prompt “What are good options for a day out in Dallas with the kids? Recommend some ice cream shops near each option” might see AI Overviews respond with a list of family-friendly ideas, each accompanied by nearby ice cream shops and a map showing their locations.
Figure A: AI Overviews can serve up more contextually relevant information than traditional Google searches. Image: Google
Planning and brainstorming aids
Beyond answering questions, AI Overviews can help users plan activities or gather ideas for projects by aggregating relevant information and resources. For example, you could search “Create a five-day high protein meal plan that’s easy to prepare,” and AI Overviews will aggregate recipes from across the web to give you a jumping-off point. From there, you can customize responses, such as asking for vegetarian alternatives, and add the necessary ingredients to your shopping list.
Starting this summer, users will also be able to use AI Overviews for trip planning. This was shown off by Sissie Hsiao, vice president at Google and general manager for Gemini experiences, during Google I/O.
During a demo, Hsiao gave the example prompt: “My family and I are going to Miami for Labor Day. My son loves art, and my husband really wants fresh seafood. Can you pull my flight and hotel information from Gmail and help me plan the weekend?” Gemini will then pull together information from Maps, Search and Gmail to provide a customized itinerary, factoring in things like flight schedules and the distance of the hotel from suitable nearby dinner spots.
Google plans to add more customization options capabilities later in the year, including more comprehensive recommendations for less specific prompts. For instance, “Anniversary celebration dinner places Dallas” might highlight venues with more romantic ambience or — weather-permitting — spots with rooftop dining.
SEE: Artificial Intelligence: Cheat Sheet
Video-based search
In the future, AI Overviews will be capable of understanding and responding to queries uploaded in video form; this means users will be able to shoot a video of something, ask a question about it and have AI Overviews help them out. Google says this will make it easier to find answers to problems without the need to type out detailed text descriptions (Figure B).
Figure B: Shoot a video and ask a question; AI Overviews will soon be able to respond. Image: Google
AI Overviews vs Google SGE
Google introduced generative AI to its search platform on October 12, 2023 as part of SGE. It was an experiment by Google Search Labs that initially allowed users to generate AI-powered images and text directly from the search bar. Its aim was to provide more creative answers to questions that traditional search results might not fully address.
SGE has since become AI Overviews, which began rolling out to users in the U.S. on May 14 following the Google I/O 2024 conference. The feature will be expanded to users worldwide throughout the remainder of the year. Google’s aim is to make AI Overviews available to more than a billion people by the end of 2024.
How to access, customize or disable AI Overviews
To access AI Overviews, just perform a regular search on Google. The AI-generated overview will show up at the top of the search results if it’s relevant to your query, much like a knowledge panel.
There’s currently no default option to disable AI Overviews entirely. A Google support page notes, “AI Overviews are part of Google Search like other features, such as knowledge panels, and can’t be turned off.” In which case, the best you can do is ignore them and focus on the traditional search results instead. If you prefer the usual list of links, you can switch to the Web tab at the top of the Google Search results page. Alternatively, you can go down the custom web extension route, in which case we advise caution.
Regarding customization, Google plans to introduce options allowing users to adjust the complexity of the language used in AI Overviews or to expand on the results it provides. Users will be able to enter a prompt and select between the original answer, a simplified version or the option to break it down into more detail. This should make AI Overviews more useful for a wider range of users, from novices to experts.
AI Overviews challenges and user response
The rollout of Google AI Overviews hasn’t been smooth sailing. In late May, Google was prompted to revisit the feature after it threw out some questionable results. Google attributed the issues to its AI model misunderstanding queries or nuances in language, as well as gaps in available quality information such as advice on how many rocks one should each per day. (Note: TechRepublic strongly advises against eating rocks.)
In response, Liz Reid, head of Google Search, said the company would “keep improving when and how we show AI Overviews and strengthening our protections, including for edge cases.” Among the improvements include refining AI Overviews to better interpret satirical content and nonsensical queries and adding restrictions to prevent the AI from triggering in situations where it can’t provide useful information.
The worlds of technology and entertainment are not as disparate as they may seem. Taking their careers to pivot, some individuals have made a slick transition from being tech-savvy professionals to captivating actors.
One notable example is that of techie-turned-actor Ashton Kutcher. Before his acting career took off, he worked as a biochemical engineer. However, Kutcher continued to remain deeply involved in the tech world as a successful venture capitalist and co-founder of investment firm Sound Ventures.
Here are a few Indians who have not only challenged career trajectories but also redefined the stereotypes associated with tech professionals.
Premgi Amaren
Prem Kumar Gangai Amaren is an Indian singer, composer, songwriter, actor, and comedian. His stage name, Premgi, was originally a spelling error, as it was intended to be ‘Prem G’, with the G representing Gangai.
Before entering the entertainment industry, this music director turned actor worked at HCL Technologies.
Santhanam
An actor and comedian, primarily active in Tamil cinema, started his professional journey working at Wipro before transitioning into acting. He initiated his career as a television comedian, gaining popularity through his well-received performances and box office success.
By the early 2010s, the film industry had quickly recognized him as the “Comedy Superstar”.
Rahul Ravindran
This artist is a multi-talented actor, director, and screenwriter, recognized primarily for his roles in Telugu films. Prior to his acting career, he worked at Infosys. In 2018, he made his directorial debut with the Telugu film Chi La Sow, for which he received the National Award for Best Original Screenplay.
Jitendra Kumar
Best known for his portrayal of Jeetu in TVF Pitchers, Jeetu Bhaiya in the series Kota Factory, and themuch-loved Sachiv Ji in Amazon Prime’s series Panchayat, Kumar studied civil engineering at the Indian Institute of Technology (IIT) Kharagpur.
After completing his education, he worked briefly in a corporate job before pursuing a career in acting.
Nivin Pauly
Nivin Pauly is an actor and producer, primarily active in the Malayalam film industry. Prior to his acting career, he worked as a software engineer at Infosys in Bangalore, a position he secured through campus placements.
Nivin was employed from 2006 to 2008 before deciding to resign and pursue acting full-time. He has since received numerous accolades, including two Kerala State Film Awards, two Kerala Film Critics Association Awards, and many more.
Karthik Kumar
Karthik Kumar, an actor and stand-up comedian, had a stint at Google before venturing into acting. He has an impressive record of performing over 1000 shows across various countries including India, USA, UK, Singapore, Malaysia, and Hong Kong.
In November 2016, Karthik expressed his frustration about being typecast in certain roles, leading him to announce his retirement from the film industry. However, he made a comeback with a role in the movie Rocketry: The Nambi Effect in 2022.
Sumukhi Suresh
Sumukhi Suresh is an actor, stand-up comic, writer, and director. She worked at Mindtree before pursuing comedy and has been compared to Tina Fey by Hindustan Times. Sumukhi also launched a content platform called ‘Motormouth‘ for writers to pitch stories for movies and web shows.
R Madhavan
Prior to his successful career as an actor, writer, director, and producer, predominantly in Tamil and Hindi films, R Madhavan had a background in technology. He spent a brief period working as a software programmer in Canada before returning to India to pursue his acting career.
Throughout his career, he has received numerous awards, including one National Film Award and two Tamil Nadu State Film Awards, among others. Currently, he holds the position of the president at the Film and Television Institute of India (FTII) in Pune.
Siddharth
Siddharth is a well-known actor who has worked in Tamil, Telugu, and Hindi cinema. In addition to acting, he has also contributed to films as a screenwriter, producer, and playback singer.
Before entering the film industry, he began his career in the tech field, at IBM. However, he later decided to pursue acting. In 2014, he had a highly successful year, winning critical acclaim and achieving box office success.
The post Meet the Indian Techies who Turned into Actors appeared first on AIM.
Summer may have just begun, but back-to-school season will be here in the blink of an eye. To help students be better prepared for the upcoming school year, Google updated Gemini to let more young scholars take advantage of its assistance.
On Monday, Google announced that it will make Gemini available to teen students using their Google Workspace for Education accounts in English in over 100 counties in the coming months, free of charge for all educational institutions.
Also: How to use ChatGPT to analyze PDFs for free
Previously, Gemini was only accessible to students 18 or older. With the update, teens ages 13 and up can access Gemini in the US, allowing younger students to partake of the same benefits. In other countries, Google's minimum age requirement for each country would apply.
According to Google, the decision to expand access to younger minds was not made lightly. Google shared that it worked with child safety and development experts to include several additional protections and limitations prioritizing safety.
These include extra data protection for all education users, ensuring that Google will not use chat data to improve its AI models. Also, Google will identify content that may be inappropriate for teen users, and provide trigger guardrails that prevent inappropriate responses — such as illegal substances — from appearing.
Learning resources customized for teens will also be available, including a new teen-friendly onboarding experience featuring an AI literacy video endorsed by ConnectSafely and FOSI — two organizations dedicated to promoting online safety — as well as resources and training to help students, educators, and parents use generative AI tools responsibly and effectively, as seen in the video below.
Students and educators will have access to some education tools, including Learning Coach, a custom version of Gemini to help students build knowledge; OpenStax and Data Commons extensions; Google's collaborative video-creating platform, Google Vids; new lesson planning and grading tools; and Read Along in Google Classroom.