Photo by Arian Darvishi on Unsplash
MLOps, or Machine Learning Operations, is a collection of techniques and tools for model deployment in a production environment. In the past years, the success of DevOps in minimising the time between software releases and minimising gaps has been integral in any company's lifetime.
With the successful history, developers came to the machine learning field to apply the DevOps principle, which created the MLOps. By combining the CI/CD principle with the machine learning model, the data world can integrate and deliver models in time mannerly within production. MLOps introduce new principles of Continous Training (CT) and Continous Monitoring, making the production environment even further suitable for any machine learning model.
With so much progress in the MLOps, we should follow a few best practices to achieve the best workflow. What are the practices? Let’s get into it.
MLOps Best Practices
Before continuing, this article would assume the reader already has the basic knowledge of MLOps, machine learning, and programming. With that in mind, let’s continue with the best practices.
1. Establishing a Clear Project Structure
MLOps is easier to assess with a clear structure for your company's use cases. There are no exact MLOps pipeline and tools for every single point, so we need a clear structure for our project. A well-organized project structure makes navigating, maintaining, and scaling our future projects more manageable.
Project structure means that we need to understand from end-to-end, from the business problem until the production and monitoring need to be precise. Some tips to improve our project structure include:
— Organize our code and data based on the environment and function. Also, keeps the code and data name convention neat to avoid mishap,
— Use version control such as GIT or DVC to track the changes,
— Having documentation with a consistent style,
— Communicate with the teams on whatever you do and change.
Establishing a clear project structure is a hassle, but it would certainly help our project in the long run.
2. Know Your Tools Stack
MLOps is not only about the concept, but it’s also about the tools. There are many tools to choose from for every activity in your MLOps. However, the choices depend on your project and company requirements.
For example, if your company's compliance requires that the data analysis be done in the tools created by the home company, we must follow it. That is why knowing the tools stack you want to use in your MLOps pipeline when we develop the capability is essential.
To help you understand the necessary tools for your project, here is the MLOps Stack Template by Valohai that you can refer to.
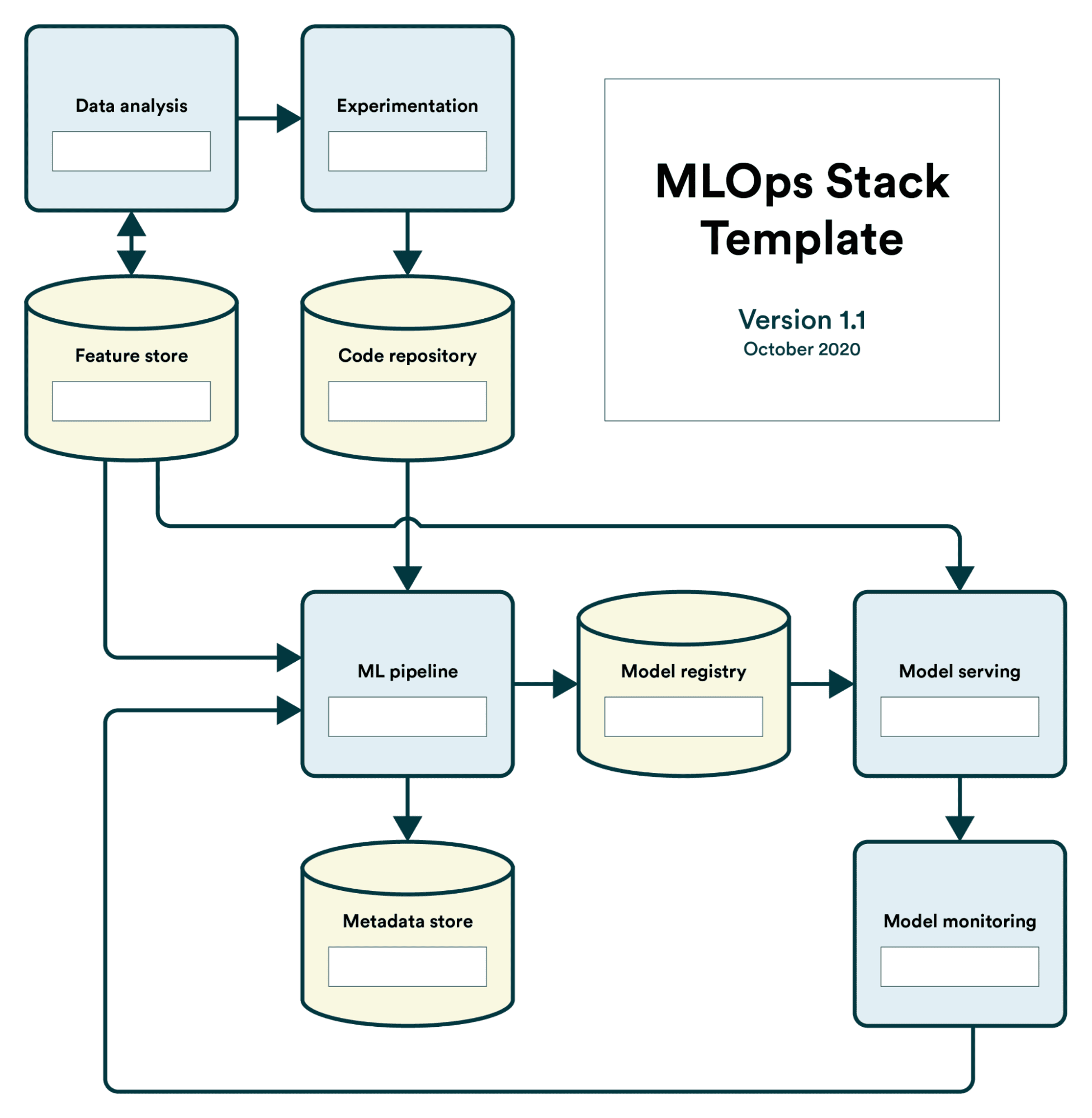
Image by Valohai
Also, try to limit the tools to around three to five. The more tools you use, the more complicated it will become.
3. Track Your Expenses
The aim of using MLOps in our pipeline is to minimise technical debt. It’s a great aim, as we don’t want technical debt to complicate our project. However, don’t let the monetary expenses to become high just because we want to minimise our technical debt.
Many of the tools used for MLOps were subscription-based or pay-per-use based, depending on the tools themselves. Rather than develop it from scratch or using an open-source based, many paying tools offer a service that allows users to integrate MLOps with a better experience.
But, sometimes, we need to remember that the services require us to pay money, and we use them sparsely, which happens to me as well in my early time adopting MLOps. Remember to track our expenses well, as we don’t want the value provided by MLOps to be diminished by money.
Using cloud services such as AWS, a calculator, and an alarm would remind you of your expenses. If not, try to track them using various tools. Even simple Excel already works.
4. Having a Standard for Everything
We not only have a straightforward structure project, but we also need a standard for every part of our MLOps pipeline. Minimising technical debt means we want everything to work correctly, and often the fault is because there needs to be a standard in the team.
Imagine that the naming of the tools, variables, scripts, data, etc., were random, and there was no coherence between one teammate and the other. The process would become even longer as the developer needs to understand what happens, and it would incur technical debt.
Standardise applied not only to the naming conventions but could also apply to everything that related to the MLOps pipeline. The data analysis process, the environment used, the pipeline structure, the deployment process, and more. Have all the standards in place, and the MLOps would work well.
5. Assess Your MLOps Maturity Periodically
How far is our MLOps readiness already is a question that we need to ask often. We want to get the full benefit of the MLOps, which could only be present if the maturity level is already there. Sadly, it’s not something you can achieve in a day or even a month.
It would take some time, but that is why don’t wait for a perfect pipeline when you start implementing MLOps. Instead, start with a thing that we can process first and keep assessing the readiness of our MLOps.
As a reference, I love to use the MLOps maturity pyramid by Microsoft Azure to assess readiness. There are five levels, and each level provides value to our ecosystem.
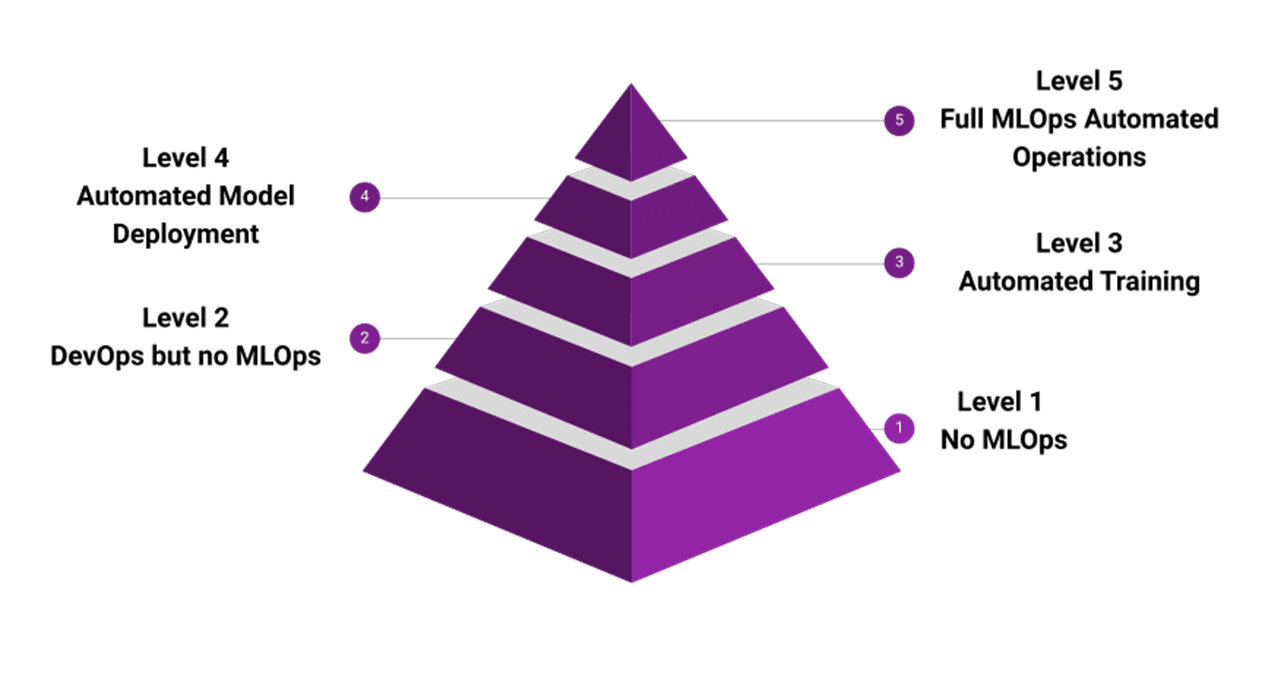
Image by Microsoft Azure Conclusion
MLOps or Machine Learning Operations becomes essential to the company life cycle. That is why there are some best practices you could follow:
- Establishing a Clear Structure Project
- Know Your Tools Stack
- Track Your Expenses
- Having a Standard for Everything
- Assess Your MLOps Maturity Periodically
I hope it helps.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.
- MLOps Best Practices
- MLOps: The Best Practices and How To Apply Them
- Data Warehousing and ETL Best Practices
- 7 Data Security Best Practices for 2021
- MLOps – "Why is it required?" and "What it is"?
- Overview of MLOps