Image by Author Introduction
Have you heard of the term Artificial General Intelligence (AGI)? If not, let me clarify. AGI can be thought of as an AI system that can understand, process, and respond the intellectual tasks just like humans do. It's a challenging task that requires an in-depth understanding of how the human brain works so we can replicate it. However, the advent of ChatGPT has drawn immense interest from the research community to develop such systems. Microsoft has released one such key AI-powered system called HuggingGPT (Microsoft Jarvis). It is one of the most mind-blowing things that I have come across.
Before I dive into the details of what is new in HuggingGPT and how it works, let us first understand the issue with ChatGPT and why it struggles to solve complex AI tasks. Large Language models like ChatGPT excel at interpreting textual data and handling general tasks. However, they often struggle with specific tasks and may generate absurd responses. You might have encountered bogus replies from ChatGPT while solving complex mathematical problems. On the other side, we have expert AI models like Stable Diffusion, and DALL-E that have a deeper understanding of their subject area but struggle with the broader tasks. We cannot fully harness the potential of LLMs to solve challenging AI tasks unless we develop a connection between them and the Specialized AI models. This is what HuggingGPT did. It combined the strengths of both to create more efficient, accurate, and versatile AI systems.
What is HuggingGPT?
According to a recent paper published by Microsoft, HuggingGPT leverages the power of LLMs by using it as a controller to connect them to various AI models in Machine Learning communities (HuggingFace). Rather than training the ChatGPT for various tasks, we enable it to use external tools for greater efficiency. HuggingFace is a website that provides numerous tools and resources for developers and researchers. It also has a wide variety of specialized and high-accuracy models. HuggingGPT uses these models for sophisticated AI tasks in different domains and modalities thereby achieving impressive results. It has similar multimodal capabilities to OPenAI GPT-4 when it comes to text and images. But, it also connected you to the Internet and you can provide an external web link to ask questions about it.
Suppose you want the model to generate an audio reading of the text written on an image. HuggingGPT will perform this task serially using the best-suited models. Firstly, it will generate the image from text and use its result for audio generation. You can check the response details in the image below. Simply Amazing!

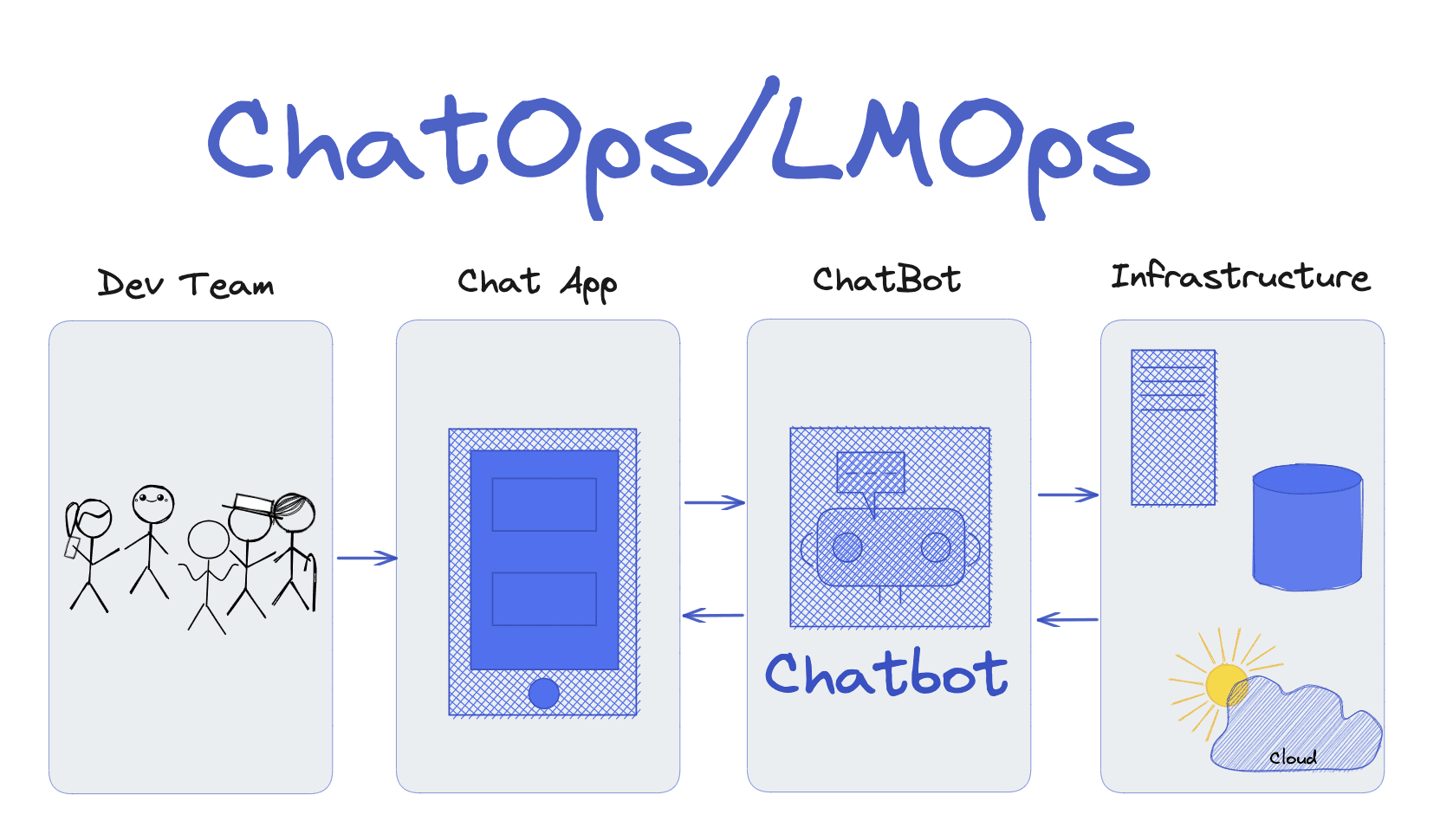
Qualitative analysis of multi-model cooperation on video and audio modalities (Source) How Does HuggingGPT Work? 
Image by Author
HuggingGPT is a collaborative system that uses LLMs as an interface to send user requests to expert models. The complete process starting from the user prompt to the model till receiving the response can be broken down into the following discrete steps:
1. Task Planning
In this stage, HuggingGPT makes use of ChatGPT to understand the user prompt and then breaks down the query into small actionable tasks. It also determines the dependencies of these tasks and defines their execution sequence. HuggingGPT has four slots for task parsing i.e. task type, task ID, task dependencies, and task arguments. Chat logs between the HuggingGPT and the user are recorded and displayed on the screen that shows the history of the resources.
2. Model Selection
Based on the user context and the available models, HuggingGPT uses an in-context task-model assignment mechanism to select the most appropriate model for a particular task. According to this mechanism, the selection of a model is considered a single-choice problem and it initially filters out the model based on the type of the task. After that, the models are ranked based on the number of downloads as it is considered a reliable measure that reflects the quality of the model. “Top-K” models are selected based on this ranking. Here K is just a constant that reflects the number of models, for example, if it is set to 3 then it will select 3 models with the highest number of downloads.
3. Task Execution
Here the task is assigned to a specific model, it performs the inference on it and returns the result. To enhance the efficiency of this process, HuggingGPT can run different models at the same time as long as they don’t need the same resources. For example, if I give a prompt to generate pictures of cats and dogs then separate models can run in parallel to execute this task. However, sometimes models may need the same resources which is why HuggingGPT maintains an <resource> attribute to keep the track of the resources. It ensures that the resources are being used effectively.
4. Response Generation
The final step involves generating the response to the user. Firstly, it integrates all the information from the previous stages and the inference results. The information is presented in a structured format. For example, if the prompt was to detect the number of lions in an image, it will draw the appropriate bounding boxes with detection probabilities. The LLM (ChatGPT) then uses this format and presents it in human-friendly language.
Setting Up HuggingGPT
HuggingGPT is built on top of Hugging Face's state-of-the-art GPT-3.5 architecture, which is a deep neural network model that can generate natural language text. Here is how you can set it up on your local computer:
System Requirements
The default configuration requires Ubuntu 16.04 LTS, VRAM of at least 24GB, RAM of at least 12GB (minimal), 16GB (standard), or 80GB (full), and disk space of at least 284 GB. Additionally, you'll need 42GB of space for damo-vilab/text-to-video-ms-1.7b, 126GB for ControlNet, 66GB for stable-diffusion-v1-5, and 50GB for other resources. For the "lite" configuration, you'll only need Ubuntu 16.04 LTS.
Steps to Get Started
First, replace the OpenAI Key and the Hugging Face Token in the server/configs/config.default.yaml file with your keys. Alternatively, you can put them in the environment variables OPENAI_API_KEY and HUGGINGFACE_ACCESS_TOKEN, respectively
Run the following commands:
For Server:
- Set up the Python environment and install the required dependencies.
# setup env cd server conda create -n jarvis python=3.8 conda activate jarvis conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia pip install -r requirements.txt- Download the required models.
# download models. Make sure that `git-lfs` is installed. cd models bash download.sh # required when `inference_mode` is `local` or `hybrid`.- Run the server
# run server cd .. python models_server.py --config configs/config.default.yaml # required when `inference_mode` is `local` or `hybrid` python awesome_chat.py --config configs/config.default.yaml --mode server # for text-davinci-003Now you can access Jarvis' services by sending HTTP requests to the Web API endpoints. Send a request to :
- /hugginggpt endpoint using the POST method to access the full service.
- /tasks endpoint using the POST method to access intermediate results for Stage #1
- /results endpoint using the POST method to access intermediate results for Stages #1-3.
The requests should be in JSON format and should include a list of messages that represent the user's inputs.
For Web:
- Install node js and npm on your machine after starting your application awesome_chat.py in server mode.
- Navigate to the web directory and install the following dependencies
cd web npm install npm run dev- Set http://{LAN_IP_of_the_server}:{port}/ to HUGGINGGPT_BASE_URL of web/src/config/index.ts, in case you are running the web client on another machine.
- If you want to use the video generation feature, compile ffmpeg manually with H.264.
# Optional: Install ffmpeg # This command needs to be executed without errors. LD_LIBRARY_PATH=/usr/local/lib /usr/local/bin/ffmpeg -i input.mp4 -vcodec libx264 output.mp4- Double-click on the setting icon to switch back to ChatGPT.
For CLI:
Setting up Jarvis using CLI is quite simple. Just run the command mentioned below:
cd server python awesome_chat.py --config configs/config.default.yaml --mode cliFor Gradio:
Gradio demo is also being hosted on Hugging Face Space. You can experiment with it after entering the OPENAI_API_KEY and HUGGINGFACE_ACCESS_TOKEN.
To run it locally:
- Install the required dependencies, clone the project repository from the Hugging Face Space, and navigate to the project directory
- Start the model server followed by the Gradio demo using:
python models_server.py --config configs/config.gradio.yaml python run_gradio_demo.py --config configs/config.gradio.yaml- Access the demo in your browser at http://localhost:7860 and test by entering various inputs
- Optionally, you can also run the demo as a Docker image by running the following command:
docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.pyNote: In case of any issue please refer to the official Github Repo.
Final Thoughts
HuggingGPT also has certain limitations that I want to highlight here. For instance, the efficiency of the system is a major bottleneck and during all the stages mentioned earlier, HuggingGPT requires multiple interactions with LLMs. These interactions can lead to degraded user experience and increased latency. Similarly, the maximum context length is also limited by the number of allowed tokens. Another problem is the System's reliability, as the LLMs may misinterpret the prompt and generate a wrong sequence of tasks which in turn affects the whole process. Nonetheless, it has significant potential to solve complex AI tasks and is an excellent advancement toward AGI. Let's see in which direction this research leads us too. That’s a wrap, feel free to express your views in the comment section below.
Kanwal Mehreen is an aspiring software developer with a keen interest in data science and applications of AI in medicine. Kanwal was selected as the Google Generation Scholar 2022 for the APAC region. Kanwal loves to share technical knowledge by writing articles on trending topics, and is passionate about improving the representation of women in tech industry.
- The secret to analysing large, complex datasets quickly and productively?
- 5 Tasks To Automate With Python
- Data Representation for Natural Language Processing Tasks
- How to Manage Your Complex IT Landscape with AIOps
- Scaling human oversight of AI systems for difficult tasks — OpenAI approach
- Python String Matching Without Complex RegEx Syntax