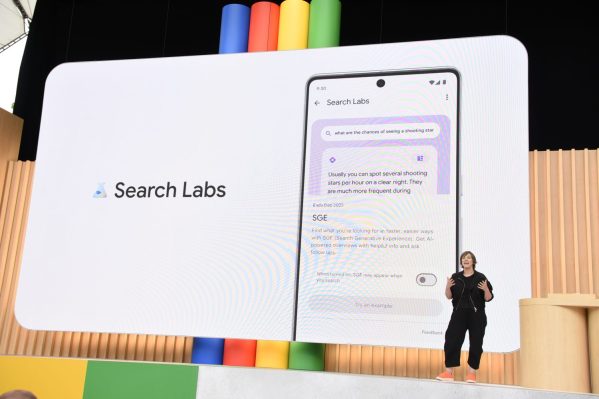
For all the cloud that perception creates, numbers always tell the real story. According to the 8th annual ‘State of Smart Manufacturing Report’ by Rockwell Automation released in March this year, India has the largest number of manufacturing firms investing in technology. The survey was conducted across 1,350 manufacturers in 13 of the major manufacturing countries including India, China, US, Germany, Japan and the UK. The report stated that Indian manufacturers were spending 35% of their operating budgets in technology, far more than the global mean of 23% investment.
India leads investment in manufacturing
But the money hasn’t just translated into tangible results as of yet. India is still lagging behind in digital maturity. A report by Lenovo released just last week found that 48% of Indian businesses are still clung to the first stage of digital maturity. While 87% of businesses believe digital infrastructure is critical for them to make money, only 33% of Indian companies are adequately prepared. For companies to reach stage 3 or 4 of digital maturity, their IT teams must have moved to the hybrid cloud.
And yet falls behind in digital transformation?
But it would seem as though Indian companies have long existed in this state of limbo. Arun Bajaj, Director of smart TV manufacturer Videotex spoke that a big chunk of the companies were still plagued by age-old issues. “Lack of digital infrastructure, knowledge and expertise are significant obstacles preventing Indian businesses from being digitally mature. Progress is also hampered by out-of-date hardware and software and cybersecurity risks,” he said.
He admitted that money was being spent in the right direction, there were still gaps. “Although ongoing spending is crucial, it is not the only factor influencing digital maturity. We believe that manufacturers should invest in digital skills training, infrastructure improvements and increased awareness of the advantages of digital transformation in order to assist more Indian firms in reaching higher levels of digital maturity and competing in the global economy. Collaboration between businesses, governmental organisations and educational institutions is needed to get past these obstacles,” he stated.
But from what Bajaj described, cloud transformation was still a distant reality for most companies here. “Adopting cloud-based technologies and software solutions first will increase operational agility and efficiency. Businesses should also think about partnering with knowledgeable technology providers who can create solutions specifically for them. They should also continuously evaluate their progress towards achieving their objectives for digital transformation and develop a clear digital strategy that is in line with their business goals,” he noted.
Aniruddha Banerjee, co-founder of AI services startup SwitchOn explained that the issues had more to do with mindset of company leaders and could be divided cleanly into three parts. “Firstly, most company leaders face the issue of short-term thinking. Most of the objectives are driven with short-term outlook and rarely lead to organisational wide changes due to obstacles with scale. Companies should instead focus on the long term business outcomes rather than just trying to ‘just do something.
“Secondly, there’s a constant reliability on global products. Products that succeed globally rarely succeed in India due to a lack of Indian context. This is almost never understood well. Companies need to trust products that have worked in the Indian context and have been built in India. They know Indian users the best.
“And thirdly, Indian companies have an unnecessary focus on minor details rather than overall strategy when digitising. This leads to huge adoption time and a lack of interest or focus. Companies should look at the big picture and minor issues will resolve themselves automatically,” he explained.
Baby steps in Smart Manufacturing
But even as India is in the throes of these middling changes, the concept of smart manufacturing has walked in through the doors. Smart manufacturing is a full realisation of the digital dream in manufacturing. Smart factories have advanced sensors, embedded software (like IoT, cloud computing, analytics) and robotics for optimising better decision-making.
The goal of smart manufacturing is to push automation, have predictive maintenance and address customer concerns in real-time. The making of India’s first smart factory, backed by Boeing, is still in progress at the Indian Institute of Science’s (IISc) at Bangalore’s Product Design and Manufacturing (CPDM) Center.
Despite the massive push in India, there are many lessons still to be learned from countries like Japan and South Korea which are far ahead on their journey of modernising manufacturing. “We need to learn from Japan. This country literally transformed the way of working of the industries and the way of doing business. The Academia- institution- industry collaboration in Japan helped in achieving this. It’s time India too went for such collaborative efforts, which will help us grow fast,” Shyam Singh, Tata Motors Plant Head said at his inaugural speech for a week-long Faculty Development Program on smart manufacturing at the DY Patil International University, Pune.
Raghav Gupta, co-founder and CEO of Futurense Technologies reiterated this in a panel discussion at the DES conference held this year. For smart manufacturing to become a solid reality, India too would have to start young. “The challenge is that the number of those people are firstly very low. And secondly, when it comes to re-training the people from the industry, the challenge is un-learning and then learning. There has to be an understanding that education needs to move towards domain-specific courses from a very young age,” Gupta stated.
The post Indian Manufacturers Trail in Digital Transformation Despite Investment appeared first on Analytics India Magazine.