Hands on with Google’s AI-powered music generator Kyle Wiggers 13 hours 
Can AI work backward from a text description to generate a coherent song? That’s the premise of MusicLM, the AI-powered music creation tool Google released yesterday during the kickoff of its I/O conference.
MusicLM, which was trained on hundreds of thousands of hours of audio to learn to create new music in a range of styles, is available in preview via Google’s AI Test Kitchen app. I’ve been playing around with it for the past day or so, as have a few of my colleagues.
The verdict? Let’s just say MusicLM isn’t coming for musicians’ jobs anytime soon.
Using MusicLM in Test Kitchen is pretty straightforward. Once you’re approved for access, you’re greeted with a text box where you can enter a song description — as detailed as you like — and have the system generate two versions of the song. Both can be downloaded for offline listening, but Google encourages you to “thumbs up” one of the tracks to help improve the AI’s performance.
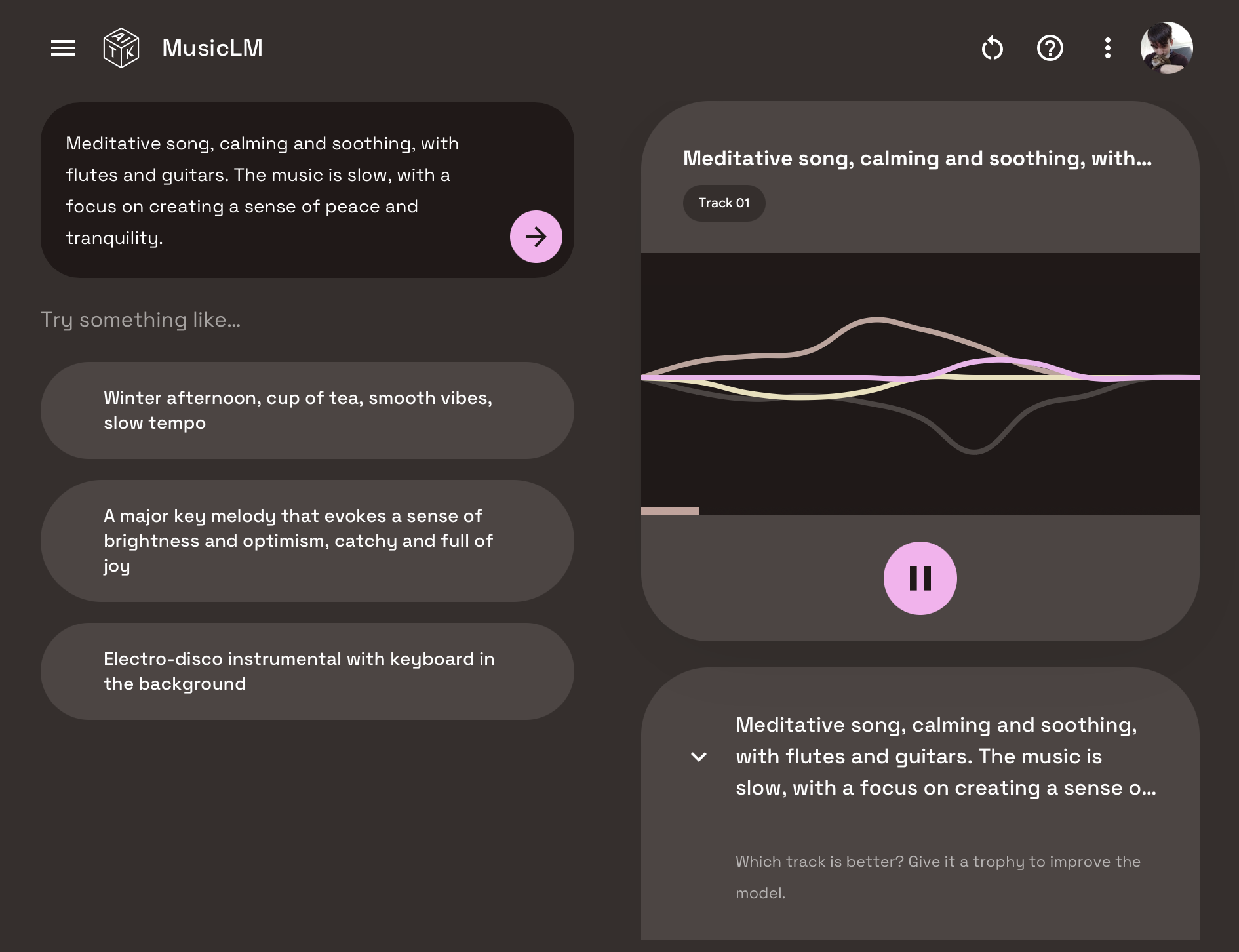
Image Credits: Google
When I first covered MusicLM in January, before it was released, I wrote that the system’s songs sounded something like a human artist might compose — albeit not necessarily as musically inventive or cohesive. Now I can’t say I entirely stand by those words, as it seems clear that there was some serious cherry-picking going on with samples from earlier in the year.
Most songs I’ve generated with MusicLM sound passable at best — and at worst like a four-year-old let loose on a DAW. I’ve mostly stuck to EDM, trying to yield something with structure and a discernible (plus pleasant, ideally) melody. But no matter how decent — even good! — the beginning of MusicLM’s songs sounds, there comes a moment when they break down in a very obvious, musically unpleasing way.
For example, take this sample, generated using the prompt “EDM song in a light, upbeat and airy style, good for dancing.” It starts off promising, with head-bobbing baseline and elements of a classic Daft Punk single. But toward the middle of the track, it veers wayyyyy off course — practically another genre.
Here’s a piano solo from a simpler prompt — “romantic and emotional piano music.” Parts, you’ll notice, sound well and fine — exceptional even, at least in terms of the finger work. But then it’s as if the pianist becomes possessed by mania. A jumble of notes later, and the song takes on a radically different direction, as if from new sheet music — albeit along the lines of the original.
I tried MusicLM’s hand at chiptunes for the heck of it, figuring the AI might have an easier time with songs of a more basic construction. No dice. The result (below), while catchy in parts, ended just as randomly as the other samples.
On the plus side, MusicLM, on the whole, does a much better job than Jukebox, OpenAI’s attempt several years ago at creating an AI music generator. In contrast to MusicLM, given a genre, artist and a snippet of lyrics, Jukebox could generate relatively coherent music complete with vocals, but the songs Jukebox produced lacked typical musical elements like choruses that repeat and often contained nonsense lyrics. MusicLM-produced songs contain fewer artifacts, as well, and generally feel like a step up where it concerns fidelity.
MusicLM’s usefulness is a bit limited besides, thanks to artificial limitations on the prompting side. It won’t generate music featuring artists or vocals, not even in the style of particular musicians. Try typing a prompt like “along the lines of Barry Manilow” and you’ll get nothing but an error message.

Image Credits: Google
The reason’s likely legal. Deepfaked music stands on murky legal ground, after all, with some in the music industry arguing that AI music generators like MusicLM violate music copyright. It might not be long before there’s some clarity on the matter — several lawsuits making their way through the courts will likely have a bearing on music-generating AI, including one pertaining to the rights of artists whose work is used to train AI systems without their knowledge or consent. Time will tell.
For now, though, I’d argue that artists don’t have much reason to worry. MusicLM, like the other AI music generators that’ve been released recently, serves more than anything as an illustration of just how far the tech has to go.