Go beyond business analytics with Bay Path University's MS in Applied Data Science. Data Science teams need general industry experts who understand data science and technical specialists who can make it happen. Bay Path University will provide you with a career path in data science, regardless of your background and experience. We were one of the first institutions to develop two tracks to complete the Master of Science (MS) in Applied Data Science degree, which is right for you?
Generalist Track — This track prepares students to be well-rounded, collaborative, and skilled data scientists and analysts regardless of their background or area of expertise. Coursework in this track provides the foundation needed for breaking into the fast-growing field of data science.
Specialist Track — This track prepares students to take on more technical roles on data science teams, such as data modeler, data mining engineer, or data warehouse architect.
Our MS in Applied Data Science Degree Program Provides:
Small class settings, led by an extraordinary team of faculty who teach and mentor students throughout the program
Hands-on application using essential programming languages such as Python, SAS, R, and SQL
A project-based curriculum teaching students to solve real-world business challenges, using both "small" and "big" data and cutting-edge practices in statistical modeling, machine learning, and data mining
A project-oriented capstone that will harness the skills gained throughout the program
Flexibility for working professionals with convenient one and two-year schedules
LEARN MORE
More On This Topic
Online Master’s in Data Science from Northwestern
Northwestern Online Master's in Data Science
Read This Before You Apply to a Business Analytics Master's Program
Join UC's Information Session for the Master's in Business Analytics…
Maximize Your Productivity as a Data Scientist by Organizing
We live in an era of tremendous innovation, where groundbreaking advancements in open-source AI models are being unveiled almost every week. These remarkable developments offer a glimpse into the future, showcasing the potential of artificial intelligence. However, while some of these models are accompanied by interactive demos, the majority of projects just share a dataset and model weights. Consequently, it becomes challenging for non-technical individuals to experience and explore these new technologies firsthand.
In this article, we aim to bridge this gap by introducing eight user-friendly platforms that enable anyone to test and compare open-source AI models for free. Furthermore, they provide a diverse range of updated models, ensuring that you stay up to date with the latest advancements.
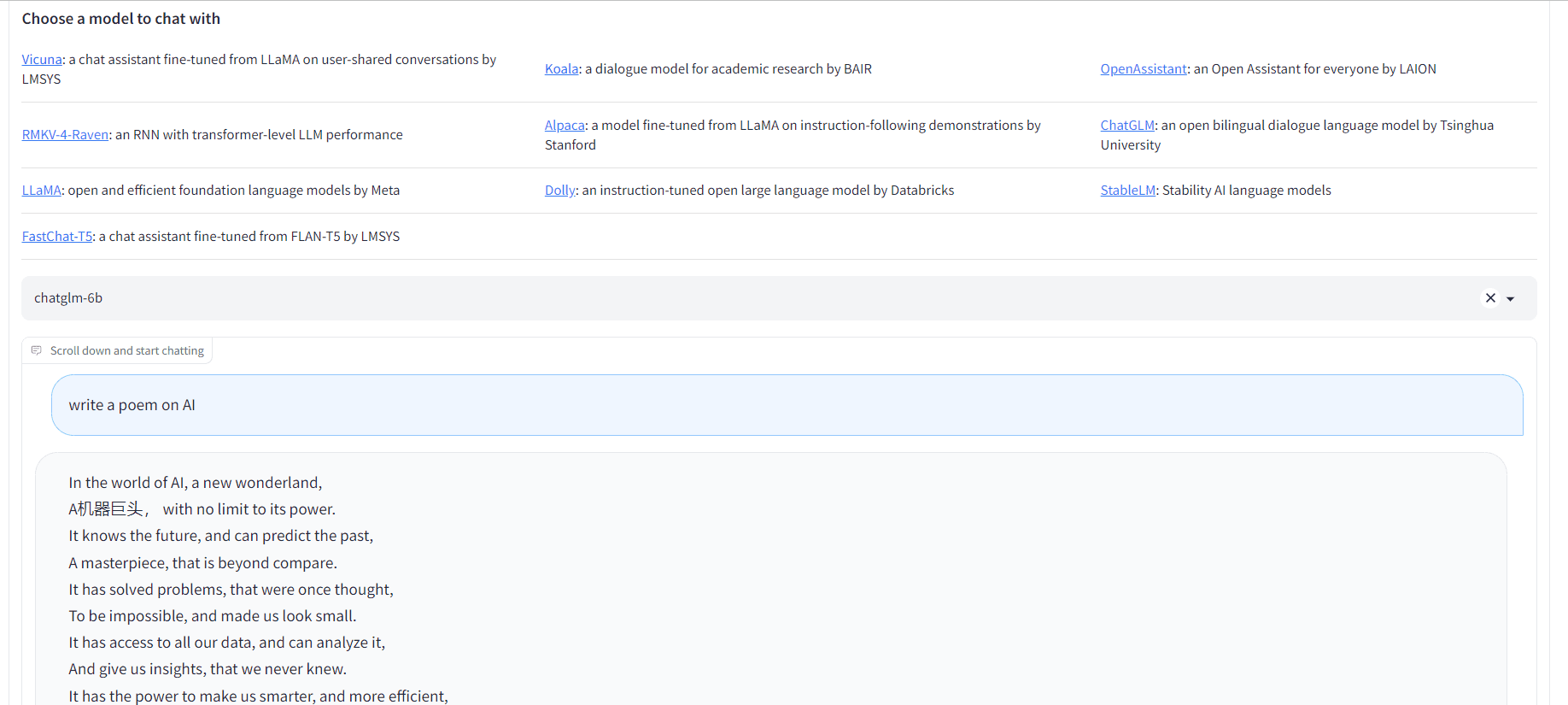
1. Chatbot Arena
Chatbot Arena lets you experience a wide variety of models like Vicuna, Koala, RMKV-4-Raven, Alpaca, ChatGLM, LLaMA, Dolly, StableLM, and FastChat-T5. Moreover, you can compare the model performance, and according to the leaderboard Vicuna 13b is winning with an 1169 elo rating.
Image from Chatbot Arena 2. Vercel AI Playground
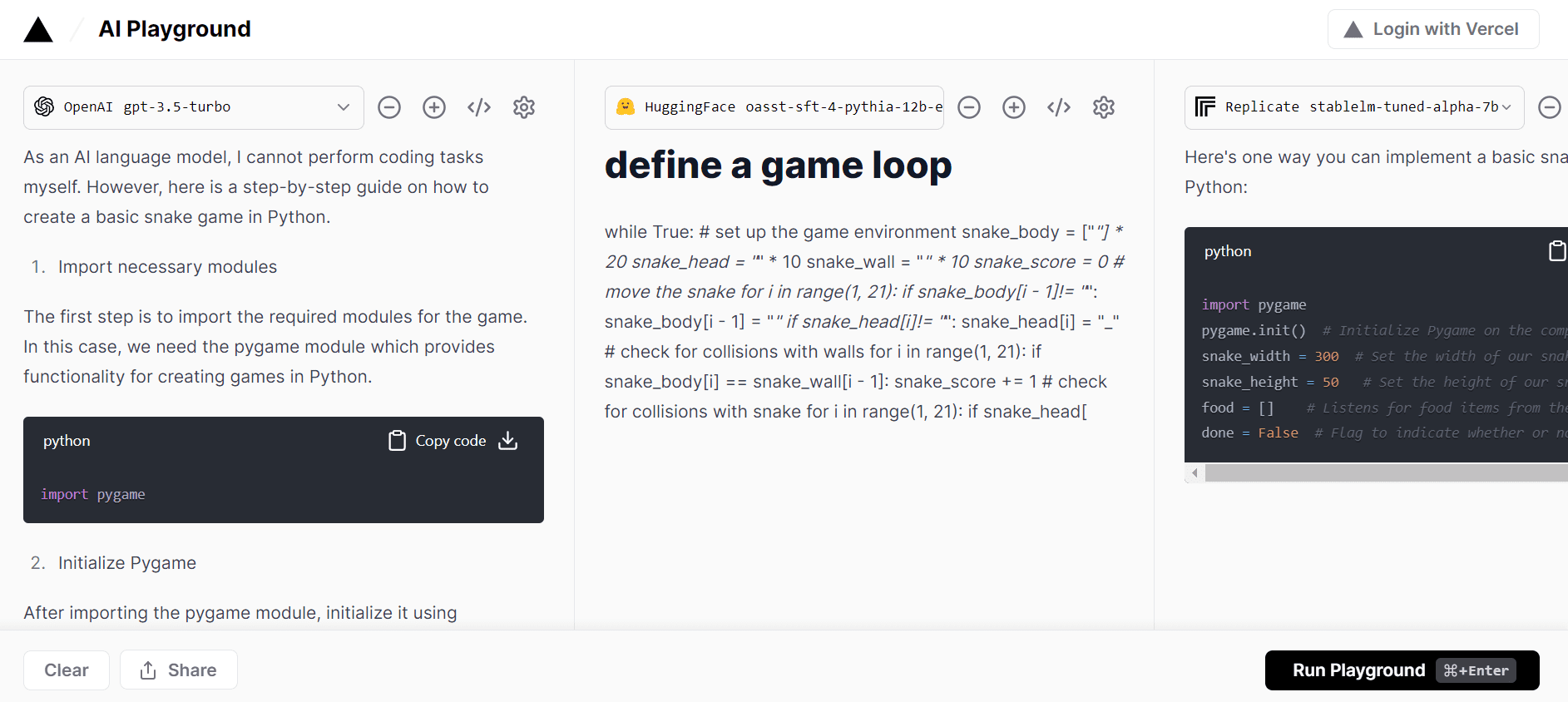
Vercel AI Playground lets you test a single model or compare multiple models for free. You don’t even have to enter your OpenAI API key to test GPT-3.5 turbo model. The platform offers models inference from Hugging Face, OpenAI, cohere, Replicate, and Anthropic. It is fast and requires no signup.
Image from Vercel AI Playground 3. GPT4ALL
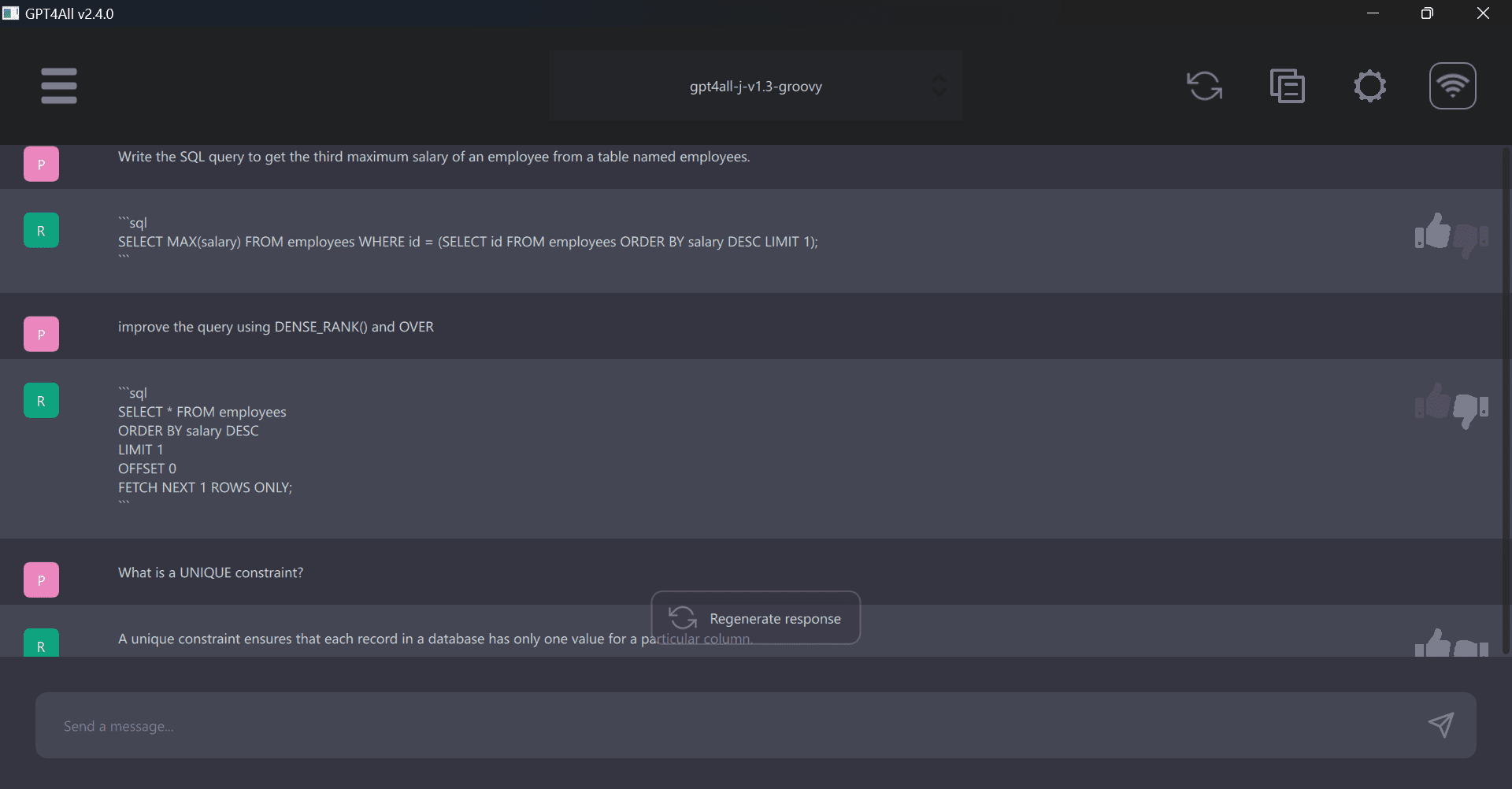
GPT4ALL is top on my list as it provides an online demo, webUI, LangchainAPI, and desktop application for you to experience the state of the model on our laptop. It is simple and requires two steps to run the model on your machine.
GPT4ALL offers various versions of gpt4all-j, vicuna, stable-vicuna, and wizardLM. It also provides us with a CPU quantized GPT4All model checkpoint that can be run on any machine.
Image from GPT4ALL 4. Quora Poe
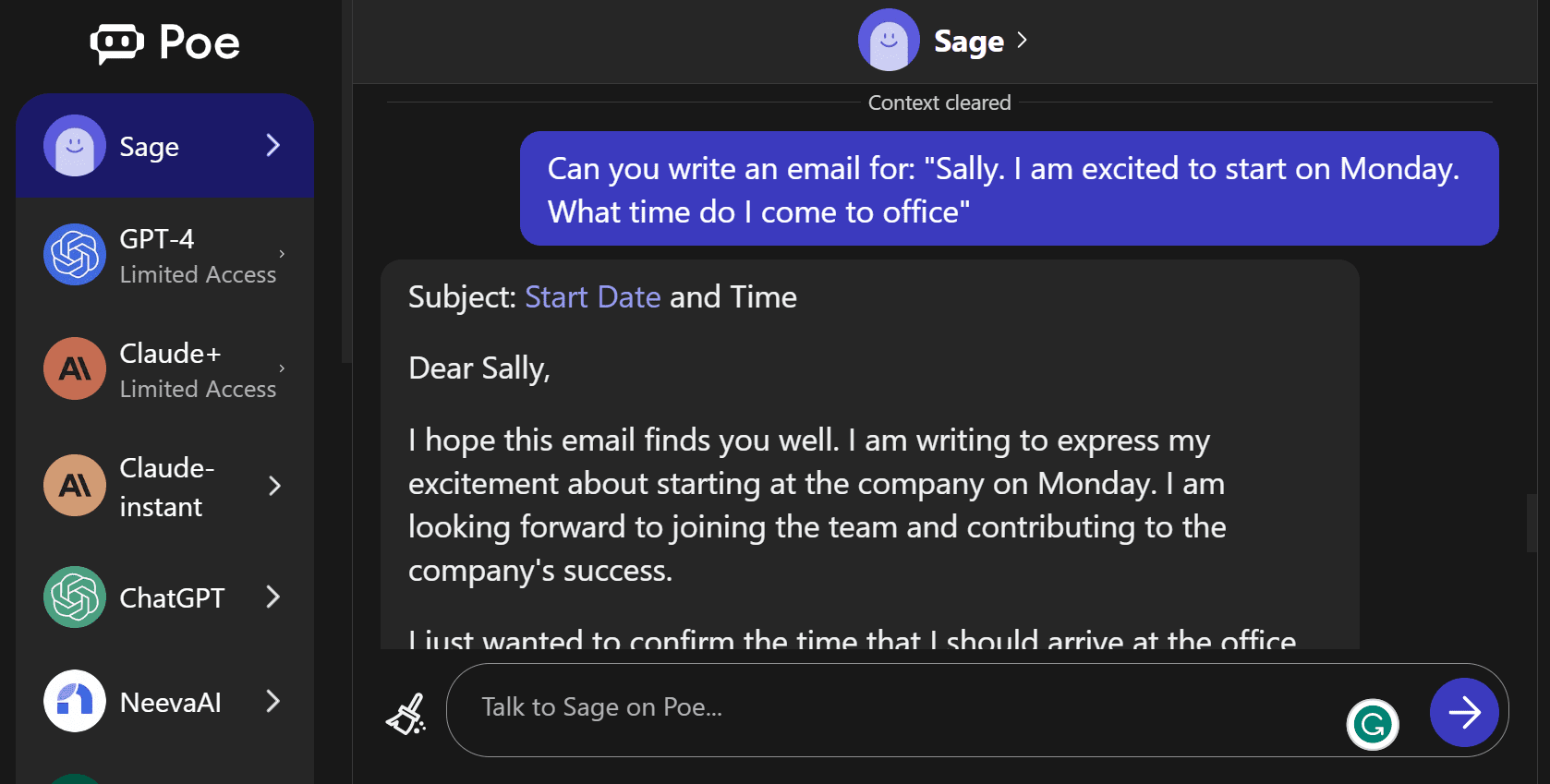
Quora Poe platform provides a unique opportunity to experiment with cutting-edge chatbots and even create your own. With access to industry-leading AI models such as GPT-4, ChatGPT, Claude, Sage, NeevaAI, and Dragonfly, the possibilities are endless. It requires simple signup, and you get to use the AI models for free.
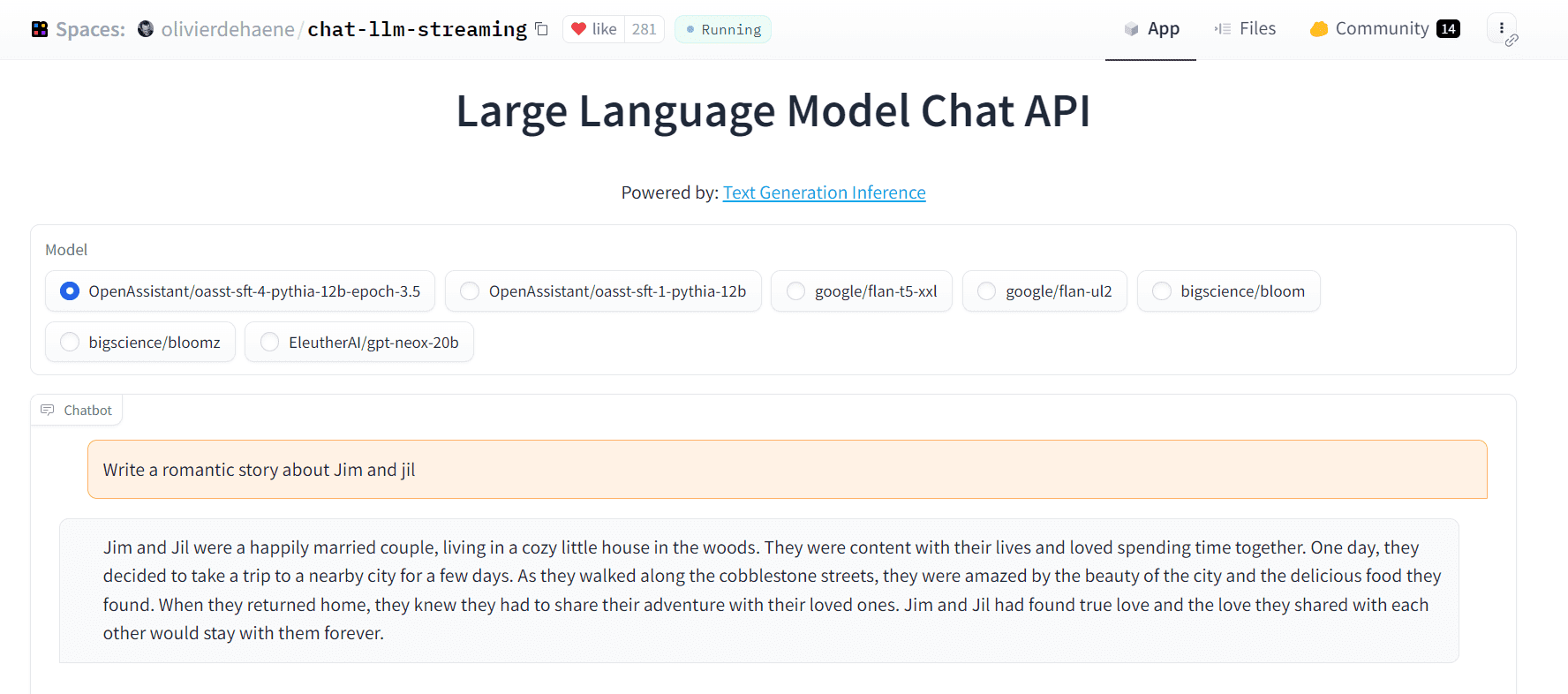
Image from Poe 5. Chat LLM Hugging Face
Chat LLM Hugging Face is a chatbot Gradio app hosted on Hugging Face Spaces. It lets you test Open assistant Pythia models, Google Flan, Big Science bloom and Bloomz, and EleutherAI GPT-NEOx. It is fast and simple and requires no setup or signup. You can even access it through the embed link.
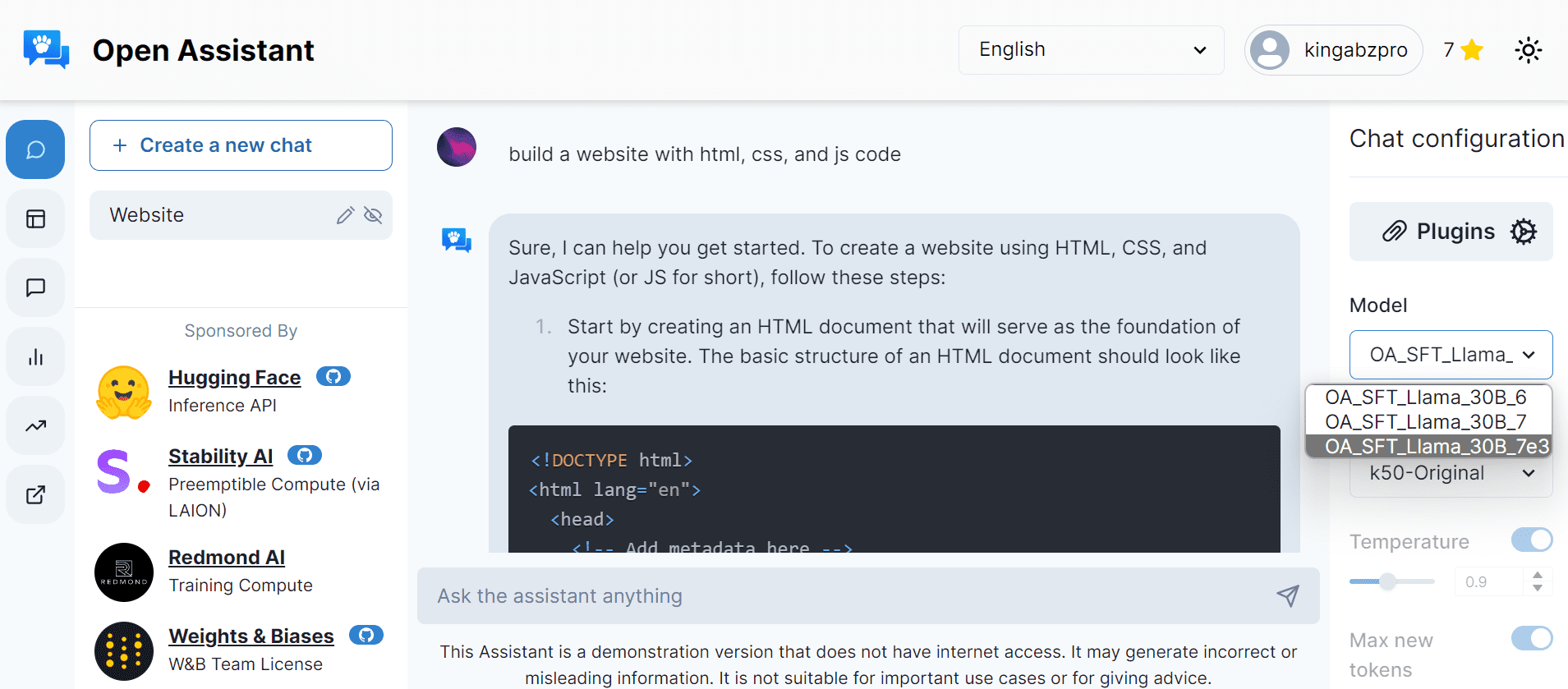
Image from Hugging Face 6. Open Assistant
Open Assistant is an open-source project led by the community, allowing users to test a range of cutting-edge models. The platform encourages contributions from anyone interested in improving the dataset and enhancing prompts by signing up for our service. Presently, we offer different versions of LLaMA models; however, we plan to introduce advanced editions of StableLM and Pythia that can be utilized for commercial purposes.
Image from Open Assistant 7. Open Playground
Open Playground lets you use all of your favorite LLMs models on your laptop using a Python package. The application either downloads the model from Hugging Face or lets you use the model directly using API. It offers models from OpenAI, Anthropic, Cohere, Forefront, HuggingFace, Aleph Alpha, and llama.cpp.
Follow a guide from Cornellius Yudha Wijaya to step up APIs and use multiple models.
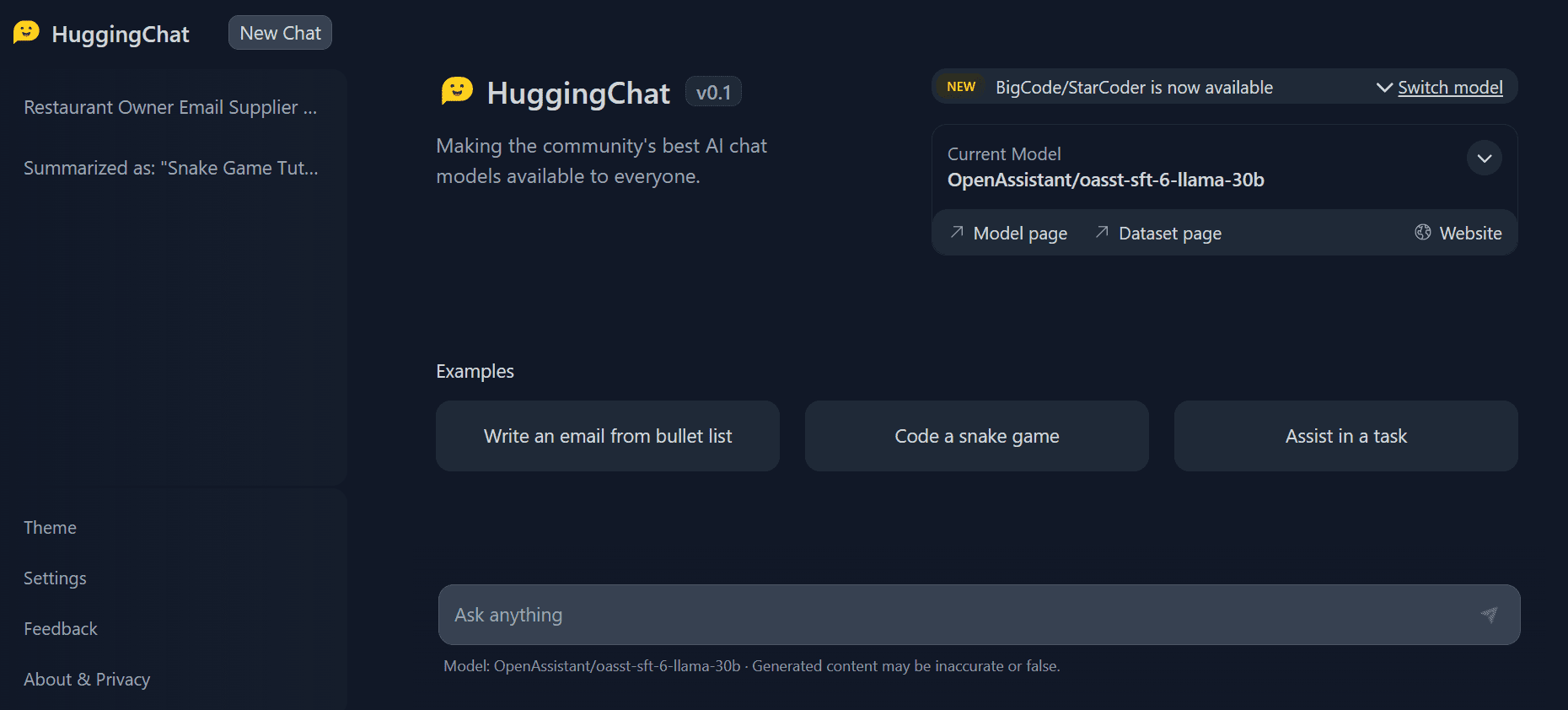
Image by Cornellius Yudha Wijaya 8. HuggingChat
HuggingChat is currently my favorite platform. It is fast, free, requires no signup, and provides the best-performing models for coding and general use. HuggingChat has a similar UI as ChatGPT, and you can use it for coding, math, research, and creative writing.
Recently, they have introduced the BigCode-StarCoder model for code generation in 86 programming languages.
Image from HuggingChat
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
More On This Topic
How Watermarking Can Help Mitigate The Potential Risks Of LLMs?
Explore LLMs Easily on Your Laptop with openplayground
The debate happening inside of every VC firm Natasha Mascarenhas @nmasc_ / 8 hours
Precursor’s Charles Hudson wants to be cautious but not too cautious. The venture capitalist was at an AI confab last month, but he has not yet made a new AI investment during the current hype cycle.
He’s one of many investors who have seen an inflection point take over a sector before, bringing in boatloads of capital, new founders and, at times, speedy and FOMO-driven deals. Historically, Hudson hasn’t minded sitting out. “With crypto, for example, I was OK being at almost zero,” he said. “I don’t think I’m OK with zero as the answer for AI. The question is where and how.”
While the “ChatGPT for X” companies are certainly interesting, Hudson says that he’s out on them for now because they are just “wrapper” companies stitching together different preexisting companies. “I might regret that, but I think I would just say, my imagination didn’t provide the answer.” He said a founder recently pitched him an exciting product, but when asked how long it would take someone else to build the same tool, the entrepreneur said “two weeks.”
Hudson’s interest in crypto reflects what’s happening inside of every generalist firm right now: Are VCs backing net new startups, or are they letting their existing portfolios lead them to AI, either through seemingly magical pivots or via a shared love and validation for low-flying AI companies in the space?
For example, Jason Lemkin says he hasn’t yet invested in a pure-play AI startup. “I’m not sure there is a rush, but I could be wrong,” he said. Most of the investor’s portfolio companies are adding an AI component to their businesses. Then there is Sapphire’s Cathy Guo, who invests in late-stage startups, allowing her to take time to make her investment decisions. During a recent conversation, she described the “arms race” between big companies launching massive products and startups integrating AI to differentiate.
Big tech companies are throwing generative AI at just about everything. Recently, Meta introduced the AI Sandbox, a testing playground for early versions of new tools and features, including generative AI-powered ad tools. The team is currently developing tools such as text variation, background generation, and image cropping.
Text variation generates multiple versions of text to emphasise important messages, while background generation creates custom images from text inputs, allowing for a greater variety of creative assets. With image cropping, advertisers can easily adjust their assets to fit different surfaces, saving time and resources.
Meta is currently working with a small group of advertisers to gather feedback and plans to gradually expand access to more advertisers starting in July, with plans to add some of these features to its products later this year.
Meta has also released new Meta Advantage features, such as the ability to switch manual campaigns to Advantage+ shopping in one click, using video creative in catalog ads, rolling out performance comparisons, and allowing Advantage+ audience users to use audience inputs as suggestions to guide who sees an ad. The company is investing billions of dollars in infrastructure, with an increasing portion dedicated to building AI capacity for ads. Building products with generative AI capabilities also means investing more in computing capability.
As part of its ongoing efforts to advance AI modelling, Meta has implemented larger, more complex models in its ads system. This has led to improved performance and measurement, even when access to granular data is limited.
For instance, previously on Instagram, optimising clicks on Story ads required a separate model from optimising conversions or sales for ads on Reels. However, with the development of more advanced AI modelling that optimises across all surfaces (Feed, Story, Explore, and Reels), Meta can transfer learnings across multiple surfaces simultaneously, helping improve advertiser conversions and enhance the quality of ads that people see.
The post Meta Unveils AI Sandbox to Empower Advertisers appeared first on Analytics India Magazine.
In most recent news, the Japan-based mobile unit of SoftBank Corporation has set up a new AI-focused entity, with a specific focus on building generative AI products similar to OpenAI’s ChatGPT. CEO Junichi Miyakawa addressed the team during an earnings briefing, choosing about 1,000 people for building a Japanese version of ChatGPT similar technology.
“We are dead positive on ChatGPT,” said Miyakawa, as he mentioned that most of the meetings talk about building such technology. He said that the founder of SoftBank, Masayoshi Son, has been gathering engineers to hop onto this “revolutionary technology”. This move has also raised the stocks of Japanese AI companies.
Son has been one of the biggest proponents of AI, even before OpenAI or Google were, for the past six years. He had said in 2019 that, “AI will completely change the way humans live within 30 years.” Looks like we are closer than ever to that reality.
But the firm had been relatively silent for the last year when every single company was investing in AI and AI startups. SoftBank Vision Fund invested $3.1 billion in 2022, which is miniscule compared to $44 billion in 2021. Softbank Vision Fund was started in 2017 with a total of $100 billion in the bank.
Unfortunately, the Softbank Vision Fund has reported a loss of $32 billion in the year ended in March 2023. Over the past year, SoftBank has been exiting from a lot of investments to raise cash, which includes pulling out of AliBaba, the China-based big-tech firm, which is also building generative AI capabilities.
“Total defence” to “cautious offence”
Interestingly, the company is now switching gears and has decided to increase investments in AI startups again even after reporting a total loss of $32 billion through their SoftBank Vision Fund. One of the major losses includes the investment in an AI startup named SenseTime, through which the firm was hoping to develop generative AI capabilities.
One of the firm’s own robotics arm, SoftBank Robotics, has been one of the industry leaders when it comes to service robots, and is increasingly expanding. Last month, the company announced its new Robot integrator strategy to develop better robots. The month before that, the parent company SoftBank group had also announced plans to acquire the remaining portion of the already invested AI and robotics company Berkshire Grey, to integrate more AI into their own robots.
But on the flip side, the company had failed in the robotics field before. Pepper, one of the first humanoid robots developed by SoftBank was stopped from production in 2021 as it never caught up as a commercial product. Maybe this time the company would make a better one.
To get the new firepower to invest in startups, SoftBank has decided to cash out almost the entirety of its stake in Alibaba. This means over 23 years, AliBaba has returned the investment of $54 million into $72 billion. Seems like the loss through the vision fund is now recovered and the company can start afresh.
At the same time, SoftBank had also been funding its AI chatbot dream through AliBaba. To that note, AliBaba had also planned to launch its own AI chatbot, Tongyi Qianwen to rival ChatGPT. Seems like the firm now is steering away from investing in Chinese companies, to invest in Japan, while also building its own language model technology.
Now, “We are getting ready to go on the offensive with the AI revolution on the horizon,” said SoftBank Chief Financial Officer Yoshimitsu Goto. “The time for AI has come.”
Is There Competition?
Luckily, Prime Minister Fumio Kishida initiated discussions in the Japanese government’s strategy council for the first time to build frameworks for the development of generative AI starting next month. “AI has the potential to change our economic society positively, but it also has risks, so it’s important to deal with both appropriately,” said Prime Minister Kishida.
In the same meeting, one of the participants said that it is important for Japanese companies to build their own language models to not fall behind in business. This is because amid the hype around generative AI, a lot of Japanese companies would have to forcefully adopt language models from U.S. companies and use them for businesses.
Here is where OpenAI stepped in. Exactly a month ago, Sam Altman had made a visit to Japan to speak to the Prime Minister Fumio Kishida about expanding OpenAI’s office in Japan while also discussing the merits and the risks of such models. To this, Hirozkazu Matsuno, the chief cabinet secretary, has said that the country is evaluating the possibilities of introducing OpenAI’s technology in the country.
Similar to Softbank’s vision of a Japanese version of ChatGPT, Altman told reporters that he, “hopes to build something great for Japanese people, make the models better for Japanese language and culture.” Taro Kono, responsible for Japan’s digital transformation in the cabinet, also expressed optimism about AI technologies in the government while also talking about the potential downfalls it may entail.
SoftBank investing in AI startups is like rising from the ashes. But apart from the investments, its bid to develop language models for Japanese language with the government’s push towards it as well, would be the perfect combination for the company.
While everyone was hopping onto the race, SoftBank remained quiet. It is one of the only big investors in the world that stayed away from OpenAI. Looks like they had it all planned out, but hopefully they are not too late.
It is quite possible that this rush by the firm, and the Japanese government as well, was triggered by Altman’s expansionist vision in Japan. But who knows, instead of a competition, this might be a first step towards a partnership that will only help SoftBank in the end.
The post SoftBank’s Pursuit of AI-ness appeared first on Analytics India Magazine.
Just when we thought things couldn’t shake up the tech industry anymore, welcome the new programming language that has been designed as a superset of the Python programming language.
Python still ranks high as one of the most popular programming languages due to its ability to create complex applications using simple and readable syntax. However, if you use Python, you know its biggest challenge is speed. Speed is an important element of programming, therefore does Python's great ability to produce complex applications with easy syntax dismiss its lack of speed? Unfortunately no.
There are other programming languages such as C or C++, which have incredible speed, and higher performance in comparison to Python. Although Python is the most widely used programming language for AI, if speed is what you’re looking for, the majority of people stick with C, Rust, or C++.
But that may all change, with the new programming language Mojo Lang.
What is Mojo Lang?
The creator of Mojo Lang, Chris Latner, the creator of the Swift programming language and the LLVM Compiler Infrastructure has taken the usability of Python and merged it with the performance of the C programming language. This has unlocked a new level of programming for all AI developers with unparalleled programmability of AI hardware and the extensibility of AI models.
In comparison to Python, PyPy is ??22x, Scalar C++ is 5000x, and Mojo Lang is 35000x faster.
Mojo Lang is a language that has been designed to program on AI hardware, such as GPUs running CUDA. It is able to achieve this by using Multi-Level Intermediate Representation (MLIR) to scale hardware types, without complexity.
Mojo Lang is a superset of Python, which means that it does not require you to learn a new programming language. Handy, right? The base language is fully compatible with Python and allows you to interact with the Python ecosystem and make use of libraries such as NumPy.
Other features of Mojo Lang include:
Leverage types for better performance and error checking.
Taking control of storage by inline-allocating values into structures, with zero cost abstractions.
Ownership and borrower checker by taking advantage of memory safety without the rough edges.
Auto-tuning, allows you to automatically find the best values for your parameters.
Differences between Mojo Lang and Python
Mojo Lang and Python are so similar, but there must be some differences, right?
Well yes, we’ve stated that the most significant difference between the two is speed. But there are a few more.
Adding Types
Mojo Lang has a built-in struct keyword similar to a Python class. The difference is that struct is static, whereas class is dynamic.
Inside struct, Mojo Lang has keywords such as var, which is mutable and let which is immutable. def as we know in Python defines a function, in Mojo lang, def is replaced with fn which is a stricter function.
It can also include SIMD, single instruction multiple data which is a built-in type that represents a vector where a single instruction can be executed across multiple elements, all in parallel on the underlying hardware.
Using struct as a type and using it in the Python implementation can improve your performance by 500x.
Parallel Computing
Mojo Lang has a built-in parallelize function, which can make your code multi-threaded, which can increase your speed by 2000x. Parallel processing is not available in Python and can be very complex to do.
Tiling Optimization
Mojo has a built-in tiling optimization tool, which allows you to cache and reuse your data more effectively. You can use memory that is close to each other at a time, and reuse it.
Autotune
Mojo Lang allows you to autotune your code to help you automatically find the optimum parameters for your target hardware.
There are some more features to the Mojo Lang, to see how it works, watch this Mojo demo with Jeremy Howard:
Can I Use Mojo Lang Now?
Unfortunately, Mojo Lang is not available to the public as it is in early development. It will be open-sourced in the future, however, you can join the waitlist to try Mojo Lang when available.
Wrapping it up
You’ve had an insight into the new Mojo Lang programming language and its features. Is Mojo Lang just Python++ or will it completely convert all Python users? Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.
More On This Topic
Why You Need To Learn More Than One Programming Language!
Python: The programming language of machine learning
GitHub Copilot and the Rise of AI Language Models in Programming Automation
DataLang: A New Programming Language for Data Scientists… Created by…
What Makes Python An Ideal Programming Language For Startups
N-gram Language Modeling in Natural Language Processing
Data lakes have become an indispensable part of any modern data infrastructure due to their varied benefits. Owing to their ability to store large amounts of raw and unstructured data while providing democratic and secure access has made it a favourite of enterprises.
Estimates put the CAGR of the data lakes market at about 24.9%, with a predicted market size of $17.6 billion by 2026. With the bombastic growth that this market is seeing, it is no surprise that enterprises are finding new use cases for data lakes —— moving away from monolithic data lakes to domain-specific data lakes.
Why monolithic data lakes are bad
Data lakes undoubtedly offer benefits over the previous, more traditional approach of handling data, like ERP and CRM softwares. While the previous approach is more like small, self-owned, self-operated stores, data lakes can be compared to Walmart, where all the data can be found in a single place.
However, as the technology matures, enterprises are finding that this approach also comes with its set of drawbacks. Without proper management, large data lakes can quickly become data swamps — unmanageable pools of dirty data. In fact, there are 3 paradigms in which data lakes can fall apart, namely complexity, data quality, and security.
Flexibility is one of the biggest pros of maintaining a data lake, as they are large dumps of raw data in their native format. This data is also not stored in a hierarchical structure, instead using a flat architecture to store data.
However, with this flexibility also comes with added complexity, meaning that talented data scientists and engineers need to trawl through this data to derive value out of it. This cannot be done without specialised talent to maintain and operate it.
This leads into our next issue — data quality. Operating and sifting through a data lake consumes lots of time and resources, requiring constant data governance. If this is ignored, the data lake will become a data swamp, with lots of new data not being properly labelled or identified. Metadata is the key to a good data lake, and this requires constant governance.
Due to the centralised nature of data lakes, security becomes a concern with the number of teams that are accessing them. Access control is one of the most important facets of maintaining a data lake, as well as providing the right set of data to the right teams. If this is not done properly, sensitive data might become prone to leaks.
Even as data lakes have these drawbacks, their positive impact is undeniable. Their scalability, cost savings, and functionality are their biggest selling points. However, there is a way to get the best of both worlds — moving away from a monolithic data lake to various smaller, distributed data lakes.
A data monolith vs. a data mesh
As data lakes scale up, these issues have become more prominent, prompting companies to move to smaller, domain-specific data lakes. Termed as a data mesh, this is more of an organisational approach leveraging the benefits of data lakes with few of their drawbacks.
In a typical data lake, all of the organisation’s data is ingested into one platform, and then cleaned and transformed. This represents a move away from domain oriented data ownership to one that is more agnostic to the domains, creating a centralised monolith. Creating a data mesh bypasses these limitations, going back to domain oriented data ownership while maintaining the benefits of data lakes.
Instead of providing a centralised repository that various teams will access through access control, teams can take ownership of the data created in their domains. This approach not only reduces the amount of maintenance required for the overall data lake, but also gives democratised access to specific domains, allowing them to take charge of their data.
Data mesh bypasses the issues posed by monolithic data lakes. Data security becomes less of an issue when compared to a monolithic structure, as teams only access the data they need to, as opposed to controlled access to all the data. Complexity is also reduced, making it easier for data concierges to handle and manage the data.
Managing data quality also becomes easier, as the smaller the data lake is, the lesser the likelihood of it becoming a data swamp. However, even as smaller data lakes exist, it is important for them to be built upon an existing big data architecture to allow for cross-domain data access.
Even with the benefits data mesh offers, it is important to note that these benefits will only be seen as the data needs of a company scale up. At smaller scales, the benefits offered by data mesh will be outweighed by the benefits offered by a centralised data lake. As with any data architecture, companies must test what works for their specific use-cases.
The post Is the Big Data Lake Era Fading? appeared first on Analytics India Magazine.
Of the many AI things that were unveiled and discussed at the Google I/O event, RCS or ‘Rich Communication Service’ was in focus. RCS, a supposed replacement for SMS, was first launched by Google in 2019. Four years after the rollout, the company announced RCS has 800m monthly active users, and is expected to cross over a billion at the end of the year. But, what’s so special about RCS, and is this Google’s way of pushing their messaging service?
Rich Communication Service is a messaging protocol that is similar to an SMS (short messaging service). RCS uses the internet to transmit messages, whereas a cellular network is required for SMS services. It allows group chats, video, audio, images, real-time viewing, and other features of messaging apps such as Apple’s iMessage.
At the event, Sameer Samat, VP of Product Management at Google, emphasised on how a messaging platform should entail the basics of “sending high quality images and video, getting typing notifications and end-to-end encryption,” which is Google’s RCS.
RCS Message UI. Source: Jibe Google
In the Google I/O event, further updates were announced to the messaging service. Google Messages that supports both SMS and RCS will have an AI added feature called ‘Magic Compose’ that will help in defining how the message should sound. The company claims that the conversations can be made “expressive, fun and playful.”
Source: Youtube
All Too Similar
While the RCS features sound impressive, they all ring a familiar bell. Doesn’t a platform that does all of this already exist? With over 2 billion monthly active users, Whatsapp is the world’s leading messenger app. With end-to-end encryption, whatsapp also works on the same format. The biggest difference is that Whatsapp works as a separate platform which needs to be downloaded, whereas anyone with an Android can communicate over RCS.
Whatsapp has added security features such as disappearing messages, blocking messages, group chat privacy settings, and others which are not available in messaging protocol RCS. In fact, when RCS started off, the encryption used to happen in transit and not from end-to-end, which meant that Google or the carrier could read your messages. Though it’s fully encrypted now, with the latest AI update that will feature on Google’s messaging service, the question of security again rises.
Apple Will Not Budge
With Google increasingly pushing their RCS across different operators, one player has remained impervious to the change. Feud between Google and Apple regarding the latter’s non-adoption of RCS has been happening for a while now. Google did not miss a chance to take a jab at Apple in the recent Google I/O event too. Samat said that if every mobile operating system adopts RCS, “we can all hang out in group chats” irrespective of the “device” people use.
Last year, Hiroshi Lockheimer, SVP for Platforms and Ecosystems at Google tweeted about how by not having RCS, Apple is holding back the industry and user experience for Android and Apple users.
It did not stop with tweets and Google blogs by Google executives, there were even campaigns targeted at Apple which was run by Android, calling it Apple #GetTheMessage.
Apple has been adamant in not adopting RCS, and Tim Cook has been clear in his stance. In a conference last year, when a user explained how he is not able to send certain videos over SMS to his mother who uses an Android, Cook responded with “buy your mom an iPhone.”Apple has always been particular in building and maintaining their user ecosystem. With iMessage being automatically available on all Apple devices, there is no separate need to download the application, and their user base naturally grows, which obviously means that there is no room for RCS.
In June 2022, Google disabled RCS service in India for businesses as they were violating their anti-spam policy and sending unsolicited messages to people. As RCS offers richer message content as opposed to normal plain text via SMS, businesses were exploiting the functionality which led to its disablement.
Interestingly, the company has not mentioned anything about security measures to combat spam messages or similar problems this time.
Going by how there are other players in the market such as Whatsapp, Facebook Messenger, and also considering how companies like Apple will continue shielding their user base, Google’s forecast of RCS users touching 1 billion per month, seems a bit far-fetched.
The post Google’s Ambition to Replace SMS with RCS. Will it Succeed? appeared first on Analytics India Magazine.
In February this year, when we first experimented with the AI-chatbot ChatGPT attempting UPSC, which is widely regarded as one of the toughest exams in the world, it failed miserably – out of 100 questions (Paper 1), the chatbot could answer only 54 questions correctly. ChatGPT’s inability to pass the UPSC prelims became a source of pride for many aspirants.
But, since we did that story, a lot of new updates and developments have happened in the world of AI. Most notably, OpenAI released GPT-4, which is the most advanced Large Language Model (LLM) to date.
The previous version of ChatGPT was powered by GPT3.5, and a few months back OpenAI made GPT-4 accessible through ChatGPT Plus.
Now, the Indian Civil Services prelims examination is also just around the corner. In this spirit, we thought, can GPT-4 clear UPSC?
GPT-4 takes UPSC (Attempt 2)
We conducted the same experiment again, but this time, we asked the same 100 questions to GPT-4, and this time, it got 86 questions right.
Here, it’s important to note that Prelims consists of two papers-General Studies Paper-I and General Studies Paper-II, we stuck to Paper-I only in both cases (attempt 1 & 2).
While the cut off for previous year (2021) was 87.54 marks, considering only paper 1, GPT-4 scored 162.76 marks, which would mean ChatGPT Plus (powered by GPT-4) cleared UPSC.
In the previous experiment, ChatGPT gave 46 answers wrong, and in that terms, we have seen a huge improvement with GPT-4 as it got only 14 answers wrong. Having said that, this was not something completely unexpected either.
When OpenAI released the technical paper of GPT-4, it did not mention any information about the architecture (including model size), hardware, training compute, dataset construction, training method etc, resulting in a furore among researchers.
But interestingly, OpenAI did reveal that they tested GPT-4 on a diverse set of benchmarks, including simulating exams that were originally designed for humans.
(Source: GPT-4 technical paper)
In the technical paper, OpenAI also notes that GPT-4 outperforms GPT-3.5 ( ChatGPT) on most exams tested. Hence, it’s not surprising that GPT-4 scored better in UPSC than ChatGPT.
Some interesting observations
One of the reasons why ChatGPT got so many answers wrong was that it hallucinates. However, according to OpenAI, GPT-4 is more creative and less likely to make up facts than its predecessor. This has played an important role in GPT-4’s improved performance in the UPSC exam.
When we made ChatGPT take the civil services exam the first time, we found that in certain cases, ChatGPT created its own alternatives.
(ChatGPT response)
But unlike its predecessor, we did not observe any similar occurrences with GPT-4. Nonetheless, GPT-4 does exhibit some level of hallucination, albeit to a much lesser degree.
Additionally, many argued that one of the plausible reasons for ChatGPT’s failure to clear UPSC could be attributed to its training data. ChatGPT, along with GPT-4, has been trained on data only up to September 2021, thereby lacking knowledge about events that occurred after 2021. Hence, despite the limitation, GPT-4 did fairly well unlike its predecessor.
Surprisingly, both models answered history-related questions incorrectly, despite it being an area where they are expected to perform well.
( GPT-4 response)
Besides, it is important to note that it was just a fun experiment and no concrete judgments should be made based on these results.
While GPT-4 cleared exams such as GRE and LSAT, it failed in English literature. Similarly, ChatGPT, despite having all the knowledge in the world, failed in an exam designed for a sixth grader.
On an ending note, it’s also important to note that by altering the inquiry, we could prompt GPT-4 to arrive at accurate responses. This implies that in some instances, rephrasing the same question could lead GPT-4 to provide correct answers, and vice versa. However, in the experiment, only the bot’s initial responses were considered.
The post ChatGPT Reattempts UPSC appeared first on Analytics India Magazine.
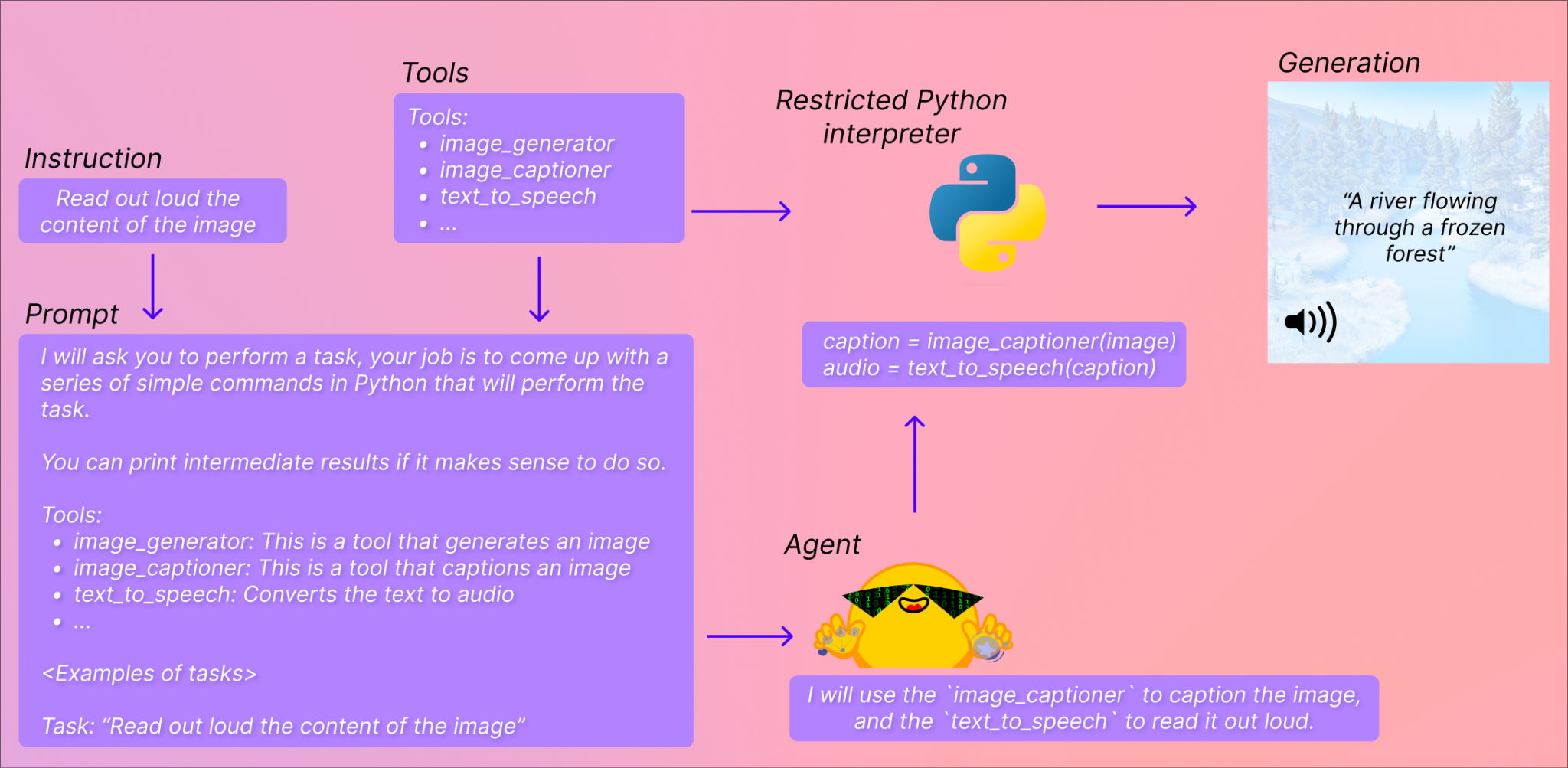
It has been an eventful week for Hugging Face as it has been raining AI innovations. It has just released Transformers Agent which allows users to manage over 100,000 HF models by conversing with the Transformers and Diffusers interface. The new API of tools and agents can generate other HF models to address complex, multimodal challenges.
Transformers Agent provides a natural language API on top of transformers, with a set of curated tools and an agent designed to interpret natural language and utilise these tools. The system is intentionally extensible, with the ability to easily integrate any relevant tools developed by the community. Before using the agent.run functionality, users must instantiate an agent, which is an LLM. The system supports both OpenAI modes as well as open source alternatives from BigCode and OpenAssistant. Hugging Face offers free access to endpoints for BigCode and OpenAssistant models.
The tools consist of a single function with a designated name and description which are then employed to prompt an agent to perform a given task. The agent is taught how to use these tools by means of a prompt that demonstrates how the tools can be leveraged to accomplish the requested query. While pipelines frequently combine multiple tasks into a single operation, tools are designed to concentrate on one specific, uncomplicated task.
There are two APIs available:
Single execution (run): The user has access to the single execution method which involves using the agent’s run() method. This method automatically selects the necessary tool or tools required for the task at hand and runs them accordingly. The run() method is capable of executing one or multiple tasks in the same instruction, although the complexity of the instruction may increase the likelihood of the agent failing. Each run() operation is independent, allowing the user to run it multiple times with different tasks consecutively.
Chat-based Execution (chat): The agent’s chat-based approach is characterised by its use of the chat() method. This method is particularly useful when there is a need to maintain the state across different instructions. While it is ideal for experimentation, it is not particularly well-suited for complex instructions, which the run() method is better equipped to handle. The chat() method can also accept arguments, allowing for the passage of non-textual types or specific prompts as required.
The code is then executed using a small Python interpreter along with a set of inputs provided by the user’s tools. Despite concerns about arbitrary code execution, the only functions that can be called are those provided by Hugging Face and the print function, which limits what can be executed. Additionally, attribute lookups and imports are not allowed, further reducing the risk of attacks.
Curated Tools
Document-based question answering: Using Donut, agents can answer questions based on a document, even if it is in image format, like a PDF (Donut).
Text-based question answering: With Flan-T5, agents can answer questions based on long texts by identifying the most relevant information (Flan-T5).
Unconditional image captioning: Agents can add captions to images using BLIP (BLIP).
Image question answering: VILT enables agents to answer questions about an image by identifying the most relevant features. (VILT)
Image segmentation: With CLIPSeg, agents can output segmentation masks based on image prompts, which can be useful for tasks like object detection (CLIPSeg).
Speech to text: Agents can transcribe spoken words into text using Whisper, which is particularly useful for processing audio recordings (Whisper).
Text to speech: SpeechT5 enables agents to convert text into speech (SpeechT5).
Zero-shot text classification: BART helps agents to classify text into predefined labels without needing prior training data (BART).
Text summarisation: With BART, agents can summarise long texts into concise sentences or paragraphs (BART).
Translation: NLLB allows agents to translate text from one language to another, which can be useful for communication across different cultures and languages (NLLB).
Custom tools
Text downloader: This tool enables you to download text from a web URL.
Text to image: With this tool, you can create an image based on a prompt, using stable diffusion.
Image transformation: Using instruct pix2pix stable diffusion, this tool enables you to modify an image based on an initial image and a prompt.
Text to video: This tool generates a brief video according to a prompt, utilizing damo-vilab.
Read more: The Peaks and Pits of Open-Source with Hugging Face
Last week, Hugging Face partnered with ServiceNow to develop a new open-source language model for codes called StarCoder. The model created as a part of the BigCode initiative is an improved version of the StarCoderBase model trained on 35 billion Python tokens. Researchers stated StarCoder’s capabilities have been tested on a range of benchmarks, including the HumanEval benchmark for Python. The model has outperformed larger models like PaLM, LaMDA, and LLaMA, and has proven to be on par with or even better than closed models like OpenAI’s code-Cushman-001 (the original Codex model that powered early versions of GitHub Copilot).
The post Hugging Face Releases Groundbreaking Transformers Agent appeared first on Analytics India Magazine.