Audio journalism app Curio can now create personalized episodes using AI Sarah Perez @sarahintampa / 10 hours 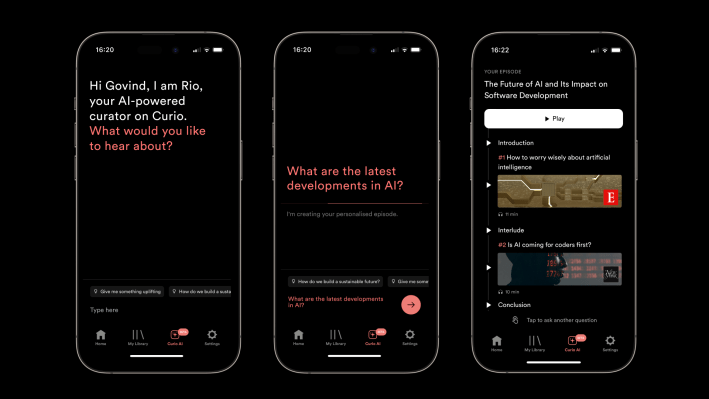
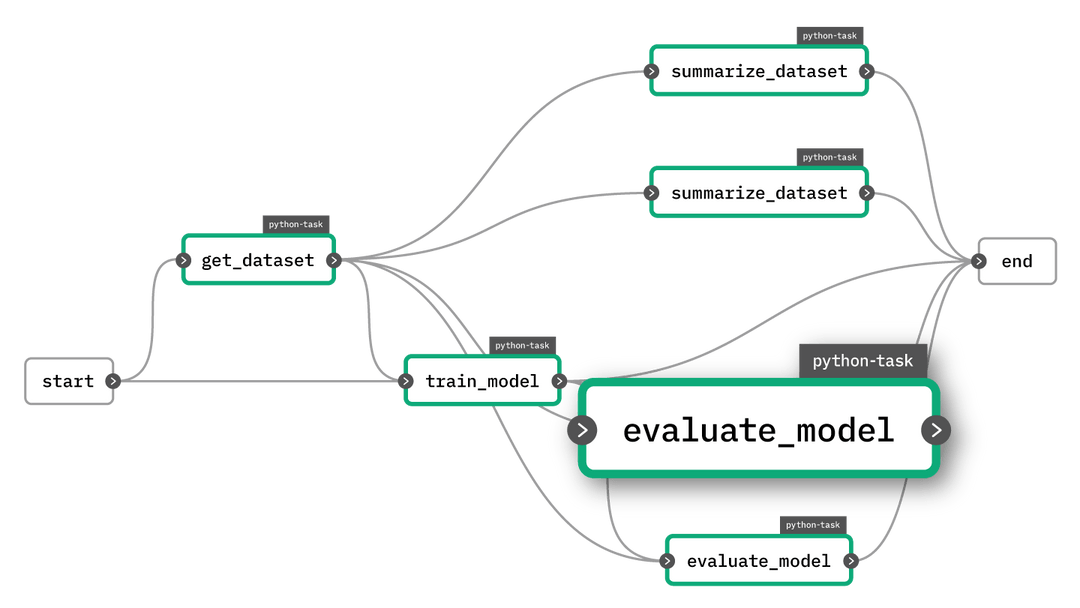
Curio, a startup building a platform that turns expert journalism into professionally narrated content, is embracing AI technology to create customized audio episodes, based on your prompts. The company today already has a large catalog of high-quality journalism licensed from partners like The Wall St. Journal, The Guardian, The Atlantic, The Washington Post, Bloomberg, New York Magainze, and others, which it leveraged to train its AI model, powered by OpenAI technologies. This allows Curio users to now ask its new AI helper, “Rio,” a question they want to learn more about, then have it return a bespoke audio episode that includes only fact-checked content — not AI “hallucinations.”
The company is also today announcing an additional strategic investment from the head of TED, Chris Anderson, a prior investor in Curio’s Series A round. Ahead of this, Curio had raised over $15 million from investors including Earlybird, Draper Esprit, Cherry Ventures, Horizons Ventures, 500 Startups, and others.
Anderson’s new contribution amount is not being disclosed, but Curio says he’s a “significant investor.”
Here's an amazing new use of AI: to create a custom audio episode of the most interesting recent magazine and newspaper articles. It comes from Curio, a startup I'm proud to be an investor in. https://t.co/gsBMRL1yLL
— Chris Anderson (@TEDchris) May 17, 2023
Founded in 2016 by ex-BBC strategist Govind Balakrishnan and London lawyer Srikant Chakravarti, Curio’s original concept was to offer a subscription-based service that provides access to a curated library of journalism translated into audio. To do so, the company partnered with dozens of media organizations to license their content, which is then narrated by voice actors and added to the Curio app. The experience is an improvement over the news audio offerings provided by services like Pocket, where users save articles to listen to later, as Curio’s content is read by real people, not robotic-sounding AI voices.
With the addition of its AI feature, Curio is now able to curate custom audio as well, on top of its hand-picked selection of audio journalism. The company believes this could become a powerful use case for AI at a time when there are legitimate concerns about AI chatbots providing false information or making up facts when they don’t know how to generate the right answer — something that’s called a “hallucination.” Already, we’ve seen falsehoods provided by AI chatbots when both Google and Microsoft demonstrated their new AI search tools, for instance.
Curio’s AI, on the other hand, won’t return anything it “makes” up, as it’s combining audio clips from across its catalog in response to users’ queries, effectively creating mini podcast episodes that allow you to explore a topic through quality, fact-checked journalism.
The company suggests you could use the AI feature via prompts like, “tell me about the possibility of peace in Ukraine,” “what is the future of food?,” “tell me about the U.S. debt ceiling,” “tell me why Vermeer is so great,” or “I have 40 minutes, update me on AI,” for example.
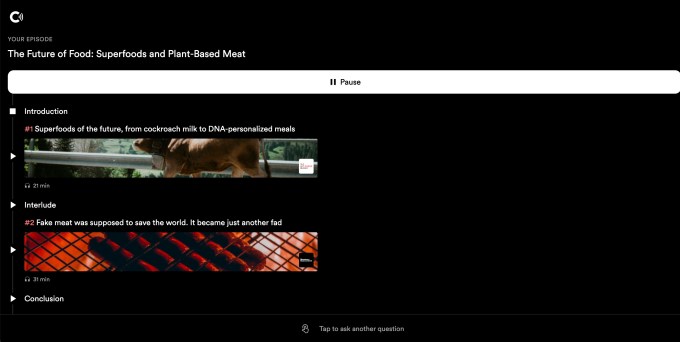
Image Credits: Curio screenshot on web
However, the AI can’t return information on breaking news, as it takes time for it to translate news articles into narrated audio. But could be used to explore various topics in more detail.
“We are trying to create from, a technical perspective, an AI that doesn’t hallucinate,” explains Curio’s Chief Marketing Officer, Gastón Tourn. “And the second thing that is interesting is this idea of unlocking knowledge from journalism — from news — because when you ask questions, it actually also proposes articles from, maybe from a few years ago, but they’re still super relevant to what’s going on right now.”
In addition to the media brands mentioned above, Curio also has relationships with The Economist, FT, WIRED, Vox, Vulture, Scientific American, Fast Company, Salon, Aeon, Bloomberg Businessweek, Foreign Policy, The Cut, and others — in total, over 30 publications are supported. (The New York Times, we should note, is not one of them. And the company launched its own audio journalism app today, as it turns out.)
To get started with the new Curio AI, you’ll type your question or prompt into the box provided, as if you were interacting with an AI chatbot, like ChatGPT. (Curio relies on OpenAI’s GPT 3.5 model, we understand.) This feature is available both on the web and in Curio’s mobile apps.
To create the personalized audio episode for you, Curio crunches through over 5,000 hours of audio, but this all takes just a few moments of processing from the user’s perspective. This results in a custom audio episode that includes an introduction along with two articles from Curio’s publications.
Curio itself is a premium subscription service priced at $24.99 per month (or $14.99/mo if paying for a year upfront). However, the AI feature is free to use, for the time being. The company says that’s because it wants to get “Rio” into the hands of as many people as possible, so it can learn. For instance, it’s looking to understand what length users prefer for these personalized episodes, though right now it’s leaning toward shorter articles.
Later, Curio may add more features — like the ability to share your episodes with others or get suggestions based on what other users are asking about.
“We don’t see AI as a curation tool,” notes Tourn. “We see it more as a discovery tool. We think what AI does is unearth content that is super interesting and finds ways to relate to it, but the curation is still human and the voices are still human.”
The company today has a customer base of thousands of subscribers, and a million-plus app downloads, but the AI addition may prompt the app to gain more traction as users explore this unique use case for AI. The company is forecasting a reach of 100K paid subscribers by year-end.
Curio, the curated audio platform for journalism, has closed $9M Series A funding
Updated, 5/17/23, 12:57 PM ET to include forecast