Meituan buys founder’s months-old ‘OpenAI for China’ for $234M Rita Liao 7 hours
One of China’s most highly anticipated artificial intelligence startups is undergoing a significant change of direction.
Light Year, which was founded merely four months ago by Wang Huiwen, a co-founder of Meituan, with the ambition of becoming the “OpenAI for China”, is getting bought out. In a filing released on Thursday, Meituan announced that it will be fully acquiring Light Year for $233.7 million in cash.
The deal also includes $50.66 million worth of debt and paying the AI startup’s investors, Qimai, which is controlled by Meituan’s current CEO Wang Xing, $5 million, as well as HongShan, which was called Sequoia China before the recent restructuring of the fund, $28 million.
The acquisition came shortly after Meituan announced Wang Huiwen was resigning from all his corporate roles at the food delivery giant due to health reasons. A widely circulated blog post claiming knowledge of the matter said Wang had been diagnosed with depression, sparking discussion on entrepreneurs’ mental health issues in China’s tech community.
Light Year had had net cash of around $285 million as of June 29, the filing says.
A year-old AI startup Inflection AI, led by CEO Mustafa Suleyman, has secured $1.3 billion in their latest round of funding. This comes less than two months after the launch of their personal chatbot Pi.
Playing with big bucks from the start, the company is the product of tech giants Microsoft and NVIDIA. Apart from the two companies, this round of funding comes from influential figures like Reid Hoffman, Bill Gates, and Eric Schmidt. Inflection’s latest funding round values the company at $4 billion, according to a source familiar with the transaction.
It’s the fourth biggest raise for an AI startup ever, excluding multiple rounds raised by the same companies. With this funding, Inflection has raised a total of $1. 5. The company looks to use this fund to enhance technology capabilities, bringing in more personalised conversational experience to end users and more.
Suleyman revealed that the additional investment came after receiving numerous offers following the successful launch of Pi, which is a conversational chatbot introduced in May this year. He expressed confidence in the future potential of chatbots, stating that “conversation is the new interface.”
While specific details of the deal with Microsoft and NVIDIA were not disclosed, Suleyman clarified that the majority of the $1.3 billion raised was in cash, ensuring that Inflection has sufficient funds to operate. The equity stake held by Microsoft and Nvidia in Inflection remains undisclosed, but Suleyman emphasised that the companies do not have control over the business or any preferential rights. He reassured that the funding round followed a traditional structure, with no intellectual property transfers, and Inflection retained its independence and freedom to pursue commercial partnerships.
Inflection Pi
Pi which stands for ‘Personal Intelligence’ is engineered to be a kind and supportive companion offering conversations, friendly advice, and concise information in a natural, flowing style, like the friendliest person. Launched only in May this year, the AI chatbot has mostly received positive feedback.
The primary objective of Inflection AI is to develop a universal AI-powered digital assistant. This type of assistant is seen by many technologists, including Bill Gates, as the future of human-computer interaction. “Whoever wins the personal agent, that’s the big thing, because you will never go to a search site again, you will never go to a productivity site, you’ll never go to Amazon again,” Gates said at an event recently.
Generative AI Startups on Funding Spree
Investors have poured billions of dollars into AI startups this year, mostly on companies specialising in generative AI. Earlier today, RunwayML also announced $141 million in funding from investors including Google, NVIDIA, and Salesforce. This funding is an extension of a $50 million Series C round led by Felicis Ventures. With this funding, Runway has now raised a total of $237 million.
The New York-based startup is focused on AI film and editing tools and aims to explore the potential of generative AI for video content. The latest funding round values Runway at $1.5 billion. CEO Cris Valenzuela stated that the funds will be used for further research in video and image generation AI models. A few weeks ago, a month-old AI startup Mistral AI also announced a $113M seed round at a $260M valuation.
The post A Year-old Startup Inflection AI Raises $1.3 Bn from Microsoft, NVIDIA, Bill Gates and Others appeared first on Analytics India Magazine.
Image generated using Stable Diffusion Introduction
The world of AI has shifted dramatically towards generative modeling over the past years, both in Computer Vision and Natural Language Processing. Dalle-2 and Midjourney have caught people's attention, leading them to recognize the exceptional work being accomplished in the field of Generative AI.
Most of the AI-generated images currently produced rely on Diffusion Models as their foundation. The objective of this article is to clarify some of the concepts surrounding Stable Diffusion and offer a fundamental understanding of the methodology employed.
Simplified Architecture
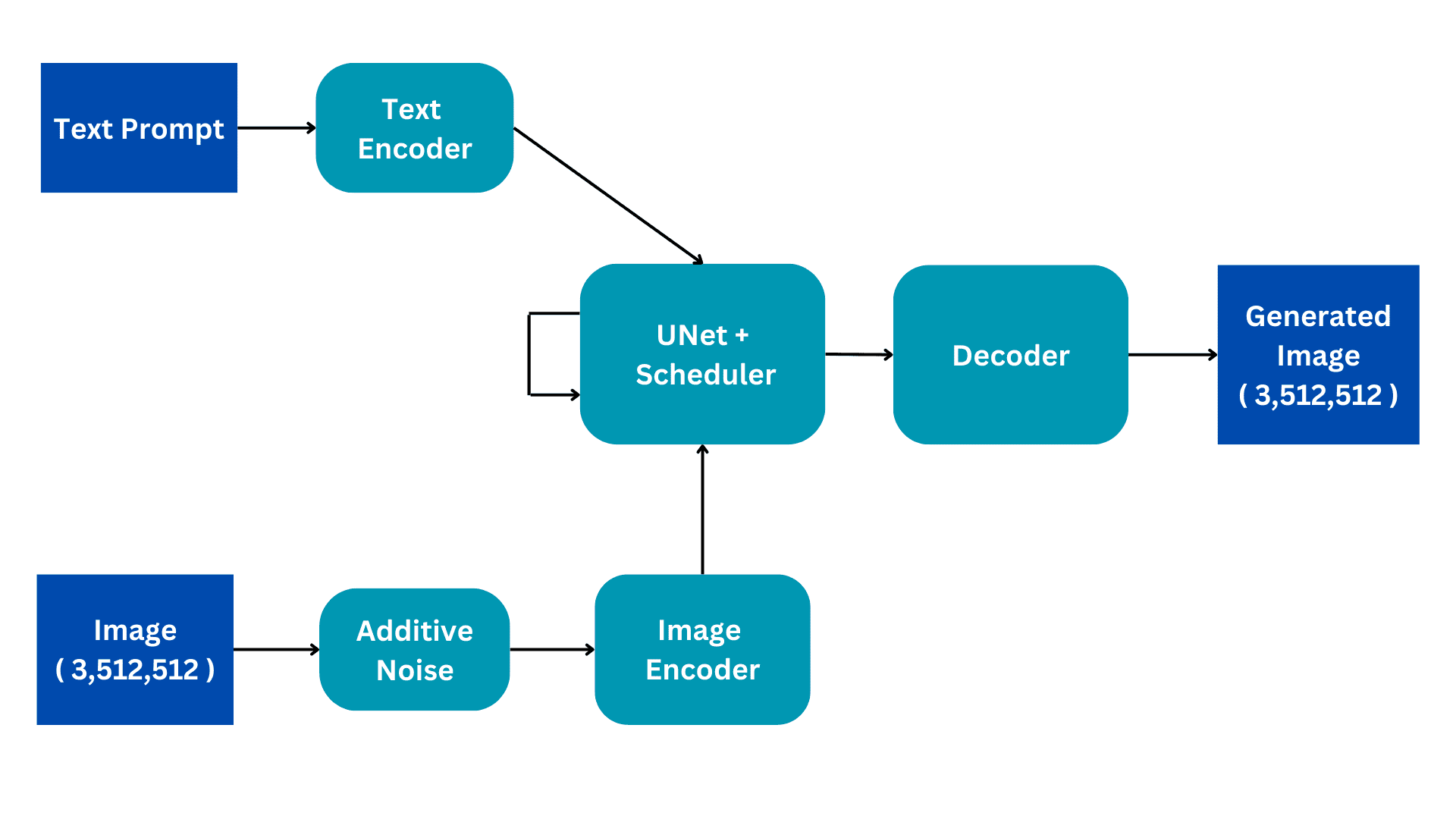
This flowchart shows the simplified version of a Stable Diffusion architecture. We will go through it piece by piece to build a better understanding of the internal workings. We will elaborate on the training process for better understanding, with the inference having only a few subtle changes.
Image by Author
Inputs
The Stable Diffusion models are trained on Image Captioning datasets where each image has an associated caption or prompt that describes the image. There are therefore two inputs to the model; a textual prompt in natural language and an image of size (3,512,512) having 3 color channels and dimensions of size 512.
Additive Noise
The image is converted to complete noise by adding Gaussian noise to the original image. This is done in consequent steps, for example, a small amount is noise is added to the image for 50 consecutive steps until the image is completely noisy. The diffusion process will aim to remove this noise and reproduce the original image. How this is done will be explained further.
Image Encoder
The Image encoder functions as a component of a Variational AutoEncoder, converting the image into a 'latent space' and resizing it to smaller dimensions, such as (4, 64, 64), while also including an additional batch dimension. This process reduces computational requirements and enhances performance. Unlike the original diffusion models, Stable Diffusion incorporates the encoding step into the latent dimension, resulting in reduced computation, as well as decreased training and inference time.
Text Encoder
The natural language prompt is transformed into a vectorized embedding by the text encoder. This process employs a Transformer Language model, such as BERT or GPT-based CLIP Text models. Enhanced text encoder models significantly enhance the quality of the generated images. The resulting output of the text encoder consists of an array of 768-dimensional embedding vectors for each word. In order to control the prompt length, a maximum limit of 77 is set. As a result, the text encoder produces a tensor with dimensions of (77, 768).
UNet
This is the most computationally expensive part of the architecture and main diffusion processing occurs here. It receives text encoding and noisy latent image as input. This module aims to reproduce the original image from the noisy image it receives. It does this through several inference steps which can be set as a hyperparameter. Normally 50 inference steps are sufficient.
Consider a simple scenario where an input image undergoes a transformation into noise by gradually introducing small amounts of noise in 50 consecutive steps. This cumulative addition of noise eventually transforms the original image into complete noise. The objective of the UNet is to reverse this process by predicting the noise added at the previous timestep. During the denoising process, the UNet begins by predicting the noise added at the 50th timestep for the initial timestep. It then subtracts this predicted noise from the input image and repeats the process. In each subsequent timestep, the UNet predicts the noise added at the previous timestep, gradually restoring the original input image from complete noise. Throughout this process, the UNet internally relies on the textual embedding vector as a conditioning factor.
The UNet outputs a tensor of size (4, 64, 64) that is passed to the decoder part of the Variational AutoEncoder.
Decoder
The decoder reverses the latent representation conversion done by the encoder. It takes a latent representation and converts it back to image space. Therefore, it outputs a (3,512,512) image, the same size as the original input space. During training, we aim to minimize the loss between the original image and generated image. Given that, given a textual prompt, we can generate an image related to the prompt from a completely noisy image.
Bringing It All Together
During inference, we have no input image. We work only in text-to-image mode. We remove the Additive Noise part and instead use a randomly generated tensor of the required size. The rest of the architecture remains the same.
The UNet has undergone training to generate an image from complete noise, leveraging text prompt embedding. This specific input is used during the inference stage, enabling us to successfully generate synthetic images from the noise. This general concept serves as the fundamental intuition behind all generative computer vision models. Muhammad Arham is a Deep Learning Engineer working in Computer Vision and Natural Language Processing. He has worked on the deployment and optimizations of several generative AI applications that reached the global top charts at Vyro.AI. He is interested in building and optimizing machine learning models for intelligent systems and believes in continual improvement.
More On This Topic
Become an AI Artist Using Phraser and Stable Diffusion
Top 7 Diffusion-Based Applications with Demos
ChatGPT, GPT-4, and More Generative AI News
Using Generative Models for Creativity
Pandas AI: The Generative AI Python Library
Are Data Scientists Still Needed in the Age of Generative AI?
Predicting the Financial Market with Large Language Models June 29, 2023 by Mariana Iriarte
Large Language Models (LLMs) are made of artificial neural networks associated with millions or billions of parameters and trained on massive amounts of data — whether it’s self-supervised learning or semi-supervised learning techniques — to understand and reiterate information. The financial industry has started to leverage these tools for a variety of reasons, including predicting the stock market, financial education, economic advisory, trading strategies, sentiment analysis, and risk management. With the technological advances brought on by ChatGPT, BloombergGPT and FinGPT were developed specifically for the finance sector. All three LLMs have the potential to make an impact on the financial sector.
ChatGPT
Two University of Florida professors from the Department of Finance argue that using advanced LLMs in the financial industry can predict more accurate results n the stock market and would only benefit trading strategies. In this study, the authors used ChatGPT to “predict stock market returns using sentiment analysis of news headlines.” They found that ChatGPT — as compared to models such as BERT, GPT-1, and GPT-2 — performed the best and only more advanced models like ChatGPT can analyze large amounts of data to successfully predict the stock market.
ChatGPT is an LLM based on generative pre-trained transformer architecture that was first introduced in November of 2022 by OpenAI, an AI research and deployment company. According to the authors, “the GPT architecture uses a multi-layer neural network to model the structure and patterns of natural language. Using unsupervised learning methods, it is pre-trained on a large corpus of text data, such as Wikipedia articles or web pages.” For this study, the authors used a dataset pulled from the Center for Research in Security Prices daily returns, news headlines, and RavenPack.
The end results of their study only highlight the potential of ChatGPT as a tool for the financial industry in predicting the stock market based on sentiment analysis, the authors said. They also note that more studies are needed.
BloombergGPT
In March of this year, Bloomberg released its own LLM dubbed BloombergGPT, a 50-billion parameter LLM specifically developed for the financial industry. The propriety BloombergGPT is made up of a 363 billion token dataset pulled from Bloomberg’s data sources, and the dataset also includes 345 billion tokens from general-purpose datasets, according to a research paper published by Bloomberg.
Table 1. How BloombergGPT performs across two broad categories of NLP tasks: finance-specific and general-purpose. Photo: Bloomberg
Researchers validated BloombergGPT on finance-specific natural language processing (NLP) benchmarks. The LLM was also validated through Bloomberg’s own suite of internal benchmarks. They found that BloombergGPT compared to LLMs such as GPT-NeoX, OPT66B, BLOOM176B, and GPT-3, BloombergGPT performed the best. Table 1 shows BloombergGPT performance scores across two broad categories of NLP tasks: finance-specific and general-purpose.
“The quality of machine learning and NLP models comes down to the data you put into them,” said Gideon Mann, Head of Bloomberg’s ML Product and Research team. “Thanks to the collection of financial documents Bloomberg has curated over four decades, we were able to carefully create a large and clean, domain-specific dataset to train an LLM that is best suited for financial use cases. We’re excited to use BloombergGPT to improve existing NLP workflows, while also imagining new ways to put this model to work to delight our customers.”
FinGPT
Unlike BloombergGPT, which is based on proprietary knowledge, FinGPT is an open source LLM that was also developed specifically for the financial industry. FinGPT is described as an AI-powered financial consultant released in March of 2023 by Finblox, a crypto trading app backed by Dragonfly and Sequoia. The group’s goal is to democratize LLMs in the finance sector.
"Our mission is to empower users with the knowledge and tools to take control of their financial future," said Peter Hoang, chief executive officer of Finblox. "We are dedicated to making financial literacy and inclusion accessible to everyone. With its user-friendly interface and personalized recommendations, FinGPT represents a significant step towards creating a more inclusive and engaging financial ecosystem."
A team of researchers from Columbia University and New York University (Shanghai) argues that FinGPT can provide access to the resources that researchers and users need to develop LLMs for the financial industry. FinGPT’s dataset is pulled from financial news, social media, filings, trends, and academic setups. FinGPT takes a data-centric approach and embraces a full-stack framework. Two associated codes are publicly available on GitHub here and here.
The Eufy Clean X9 Pro CleanerBot, a new 2-in-1 robot vacuum, boasts a deep cleaning, hands-free mopping experience, coupled with 5,500pa of suction power. It also uses some AI navigation features to maneuver throughout your house.
Also: Best robot vacuum deals: Get a Roomba or Shark on sale now
Initially, I was less than enthusiastic about trying out yet another robot mop vacuum (I'd tested a similar one recently), but once I watched the Eufy X9 Pro work its way across my home floors, my mind was changed.
ZDNET RECOMMENDS
Eufy Clean X9 Pro CleanerBot
This is the perfect robot vacuum and mop for homes with hard floors, even if there are carpets and rugs in between.
View at Us.eufy
The CleanerBot truly lives up to the name, outperforming my old Roborock and the Yeedi MopStation Pro in vacuum and mop functions. The suction power, 5,500pa at maximum capacity, is outstanding. And the main brush is bristle-less, made of silicone wedges instead that are just as effective at cleaning floors.
In my limited experience (as I've only tested this model for about a week), the primary silicone brush makes it less likely for the X9 Pro to get tangled, as it's easier to scoop debris up than sweep it.
The mopping function on the Eufy X9 Pro CleanerBot is one of the two features that impressed me the most. The X9 Pro has two rotating mop pads — which I love in a robot vac/mop combo — which put 2.2 lbs of downward pressure to break down tough stains, a particularly useful feat for my home of children and pets.
Review: Roborock S8 Pro Ultra: This 2-in-1 vacuum can do just about everything
The other outstanding feature, and probably my favorite, is the use of AI for navigation, obstacle avoidance, and mapping. The CleanerBot has time-of-flight sensors and an AI camera system, called AI See, that helps detect and avoid objects so the vacuum doesn't suck up your kids' socks or stuffed animals.
It also uses iPath Laser Navigation to create maps of your home, which separates the rooms by color in the Eufy Clean app and even shows you the obstacles that the robot has found in each room. When you review the map after cleaning, you'll find things like power cords, shoes, and trash cans marked on the map.
Eufy isn't the first to use this technology for obstacle avoidance and mapping, but it is a great feature. I hate having to pick up every last bit of paper my kids dropped before I can start cleaning — only to have the robot vacuum get stuck anyway on a power cord somewhere.
Also: This robot vacuum has a brilliant self-cleaning feature I didn't know I needed
The Eufy Clean app lets you customize settings for charging, cleaning intensity, voice, and more. And it also enables you to choose from the rooms that the robot automatically created on the map so you can send it to clean just that area, like a muddy entryway. You can choose to clean zones as small as 1.6 ft by 1.6 ft on the map in case of spills.
The Eufy Clean X9 Pro CleanerBot easily adjusts to uneven surfaces to cross up to 2 cm barriers.
Beyond the AI See camera set, the CleanerBot has a sensor to detect floor types in case you're running the X9 Pro in vacuum and mopping mode and it reaches a carpet or a rug. Once the robot detects a rug or carpet, it raises the mop pads to keep them off the mat and only vacuums on the soft surface.
Also: Best robot vacuums you can buy right now
Here's another thing I was glad to see: The X9 returns dutifully to its station to wash the mop pads rather than wait until they're overdue for a cleaning. I don't want to see my robot mop dragging dry, dirty mopping pads minutes after it should've returned for a refresh, but I haven't found this to be a problem with the X9.
The Eufy Clean X9 Pro CleanerBot is available for sale at $900 and is the perfect option for someone looking for a robot vacuum and mop combination for a home with a lot of hard floors, whether that's tile or hardwood, with some carpet or rugs mixed in.
It doesn't have a self-emptying dustbin, and the dustbin itself has to be emptied after each cleaning as it's pretty tiny. Still, the mopping feature and the suction power are impressive, especially as the mop can pick up stains and dirt that my Yeedi MopStation Pro left behind.
Still lacking key traits needed to decipher information, artificial intelligence (AI) should not be left on its own to decide what content people should read.
Human oversight and guardrails are critical to ensure the right content is pushed to users, said Arjun Narayan, head of trust, safety, and customer experience at SmartNews.
Also:Six skills you need to become an AI prompt engineer
The news aggregator platform curates articles from 3,000 news sources worldwide, where its users spend an average of 23 minutes a day on its app. Available on Android and iOS, the app has clocked more than 50 million downloads. Headquartered in Tokyo, SmartNews has teams in Japan and the US, comprising linguists, analysts, and policymakers.
The company's stated mission, amid the vast amount of information now available online, is to push news that is reliable and relevant to its users. "News should be trustworthy. Our algorithms evaluate millions of articles, signals, and human interactions to deliver the top 0.01% of stories that matter most, right now," SmartNews pitches on its website.
The platform uses machine learning and natural language processing technologies to identify and prioritize news that users want. It has metrics to assess the trustworthiness and accuracy of news sources.
Also:Mass adoption of generative AI tools is derailing one very important factor, says MIT
This is critical as information increasingly is consumed through social media where veracity can be questionable, Narayan said.
Its proprietary AI engine powers a news feed that is tailored based on users' personal preferences, such as topics they follow. It also uses various machine learning systems to analyze and evaluate articles that have been indexed to determine if the content is compliant with the company's policies. Non-compliant sources are filtered out, he said.
Because customer support reports to his team, he added that user feedback can be quickly reviewed and incorporated where relevant.
Like many others, the company currently is looking at generative AI and assessing how best to use the emerging technology to further enhance content discovery and search. Narayan declined to provide details on what these new features might be.
He did stress, though, the importance of retaining human oversight amid the use of AI, which still was lacking in some areas.
Also:If you use AI-generated code, what's your liability exposure?
Large language models, for instance, are not efficient in processing breaking or topical news but run at higher accuracy and reliability when used to analyze evergreen content, such as DYI or how-to articles.
These AI models also do well in summarizing large chunks of content and supporting some functions, such as augmenting content distribution, he noted. His team is evaluating the effectiveness of using large language models to determine if certain pieces of content meet the company's editorial policies. "It's still nascent and early days," he said. "What we've learnt is [the level of] accuracy or precision of AI models is as good as the data you feed it and train it."
Models today largely are not "conscious" and lack contextual comprehension, Narayan said. These issues can be resolved over time as more datasets and kinds of data are fed into the model, he said.
Equal effort should be invested to ensure training data is "treated" and free of bias or normalized for inconsistencies. This is especially important for generative AI, where open datasets commonly are used to train the AI model, he noted. He described this as the "shady" part of the industry, which will lead to issues related to copyright and intellectual property infringements.
Also:A thorny question: Who owns code, images, and narratives generated by AI?
"Right now, there isn't much public disclosure about what kind of data is going into the AI model," he said. "This needs to change. There should be transparency around how they're trained and the decision logic, because these AI models will shape our world views."
He expressed concerns about "hallucinations," where the AI is capable of generating false information so realistic people are convinced to be true.
Such problems further emphasize the need for some form of governance that involves humans overseeing the content that is pushed to users, he said.
Organizations also need to audit what comes out of their AI models and implement the necessary guardrails. For instance, there should be safety nets in place when the AI system is asked to provide instructions on building a bomb or writing an article that plagiarizes.
"AI, right now, is not at a stage where you can let it run on its own," Narayan said, adding that there should always be investment in human capabilities and oversight. "You need guardrails. You don't want content that isn't proofread or fact-checked."
And amid the hype, it is important to be mindful of the limitations of generative AI, which models still are not trained to handle breaking news and do not run well on real-time data.
Also:Who owns the code? If ChatGPT helps you write your app, does it belong to you?
Where AI has worked better is in powering its recommendation engine, which SmartNews uses to prioritize articles deemed to be of higher interest based on certain background signals, such as the user's reading patterns. These AI systems have been in use over the past decade, where rules and algorithms have been continuously finetuned, he explained.
While he was unwilling to divulge details about how generative AI could be incorporated, he pointed to its potential in easing human interaction with machines.
Anyone, including those without a technical background, will be able to get the responses they need as long as they know how to ask the right questions. They then can repurpose the answers for use in their daily activities, he said.
Some areas of generative AI, though, remain gray.
According to Narayan, there are ongoing discussions with publishers on its news platform about how articles written completely by AI, as well as those written by humans but augmented with AI, should be managed. And should rules be established for such articles, how then would these be enforced?
In addition, there are questions about the level of disclosure that should apply to the different variations, so readers know when and how AI is used.
Regardless of how these eventually will be addressed, what remains a mandate is editorial oversight. Again stressing the importance of transparency, Narayan said every piece of content still will have to meet SmartNews' editorial policies on accuracy and trustworthiness.
He expressed alarm over tech layoffs that saw the removal of AI ethics and trust teams. "I will tell you now, it's so important to continue to have [human] oversight and investment in safety guardrails. If the diligence is missing, we're going to create a monster," he said. "Automation is great [and allows] you to scale systems, but nothing comes close to human ingenuity."
Inflection lands $1.3B investment to build more ‘personal’ AI Kyle Wiggers 8 hours
There’s still plenty of cash to go around in the generative AI space, apparently.
As first reported by Forbes, Inflection AI, an AI startup aiming to create “personal AI for everyone,” has closed a $1.3 billion funding round led by Microsoft, Reid Hoffman, Bill Gates, Eric Schmidt and new investor Nvidia. A source familiar with the matter tells TechCrunch the tranche, which brings the company’s total raised to $1.525 million, values Inflection at $4 billion.
CEO Mustafa Suleyman, who previously co-founded the Google-owned AI lab DeepMind, says that the new capital will support Inflection’s work to build and design its first product, an AI-powered assistant called Pi.
“Personal AI is going to be the most transformational tool of our lifetimes. This is truly an inflection point,” Suleyman said in a canned statement. “We’re excited to collaborate with Nvidia, Microsoft, and CoreWeave as well as Eric, Bill and many others to bring this vision to life.”
Palo Alto, California-based Inflection, which has a small team of around 35 employees, has kept a relatively low profile to date, granting few interviews to the media. But in May, Inflection launched the aforementioned Pi, which is designed to provide knowledge based on a person’s interests and needs. Available to test via a messaging app or online, Pi’s intended to be a “kind” and “supportive” companion, Inflection says — offering “friendly” advice and info in a “natural, flowing” style.
Inflection’s personal AI assistant, which offers “friendly” advice.
Inflection recently peeled back the curtains on Inflection-1, the AI model powering Pi, asserting that it’s competitive or superior with other models in its tier — namely OpenAI’s GPT-3.5 and Google’s PaLM-540B. According to results the company, Inflection-1 indeed performs well on various measures, like middle- and high school-level exam tasks and “common sense” benchmarks. But it falls behind on coding, where GPT-3.5 beats it handily and, for comparison, OpenAI’s GPT-4 smokes the competition.
In pursuit of larger and more capable models, Inflection says it’s working with Nvidia and CoreWeave, a GPU cloud provider, to build what it claims is one of the largest AI training clusters in the world, comprising 22,000 Nvidia H100 GPUs.
It has the cash to do so now, one would presume. With the closing of the latest tranche, Inflection sits behind OpenAI (which has raised $11.3 billion to date) as the second-best-funded generative AI startup — edging out Anthropic ($1.5 billion). Well behind it are Cohere ($445 million), Adept ($415 million), Runway ($195.5 million), Character.ai ($150 million) and Stability AI (~$100 million).
Despite the difficult macroeconomic environment, money’s still pouring into generative AI startups, indeed. According to Pitchbook, roughly $1.7 billion was generated across 46 deals in Q1 2023, with an additional $10.68 billion worth of deals announced sometime in the quarter but not yet completed.
Vedanta Resources Ltd., led by billionaire Anil Agarwal, is making a significant push into the electronics sector with the announcement of a $4 billion display factory in western India. The newly appointed CEO of Vedanta’s display business, YJ Chen, has revealed plans to hire global talent from countries like South Korea, Taiwan, and Japan to build and operate a liquid crystal display (LCD) panel fabrication unit in India. The factory is expected to create approximately 3,500 direct jobs.
Vedanta’s expansion into the electronics sector comes as India strives to establish itself as a prominent technology manufacturing hub. The display business is distinct from Vedanta’s struggling chip venture, but it is expected to have a smoother path to success as it is considered a less technically demanding endeavor.
To support its display business, Vedanta has partnered with Innolux Corp., an affiliate of Foxconn Group. The company intends to manufacture glass and assemble LCD panels at its new factory. However, the project’s progress and commencement of production by the end of 2025 depend on crucial funding from the Indian government, which has pledged $10 billion to attract chip and display manufacturers to the country. Prime Minister Narendra Modi’s administration has promised to bear half the cost of establishing semiconductor and display fabrication sites.
While Vedanta’s chip plans are still awaiting government backing, the display business is poised to benefit from existing partnerships with leading technology companies, making it more likely to secure state incentives. Vedanta also owns AvanStrate, a Japan-based company that produces layers used in LCD panels, further bolstering its capabilities in the display industry.
It is worth noting that major display companies worldwide are gradually phasing out LCD technology in favour of sharper and more advanced OLED displays. South Korea’s Samsung Display Co., the leader in display technology, has already ceased LCD production and is investing heavily in next-generation displays. Similarly, LG Display Co., another South Korean company, is scaling down its LCD manufacturing operations.
Vedanta aims to capitalise on India’s growing display market, which is projected to reach an annual value of $30 billion over the next seven years. However, the company faces challenges such as competition from inexpensive Chinese LCDs. To ensure long-term success, Vedanta plans to build its own supply chain within India, focus on developing new designs to lower costs, and compete effectively with Chinese manufacturers.
The post Vedanta Expands Technological Footprint in India with $4 Billion Investment appeared first on Analytics India Magazine.
Before the hype around large language models (LLMs), NLP was building but was progressing in the lurk. Now it has become revolutionized since the release of LLMs such as ChatGPT. LLMs have been shown to understand as well as generate human-like text. Models such as ChatGPT, Google Bard, and more have been trained on high volumes of text data within a deep neural network architecture.
But how do these models understand humans exactly, as well as output human-like reponses? NLP. A subfield of artificial intelligence that helps models process, understand and output the human language. They are typically trained on tasks such as next word prediction which allow them to build contextual dependencies and then be able to generate relevant outputs. The NLP field has advanced applications such as chatbots, text summarization, and more.
There are some ethical concerns around LLMs and their bias in text generation, sparking further research into NLP and its use in LLM applications. Although these concerns and challenges are currently being addressed, with the impact LLM models such as ChatGPT have had on the world — it looks like they’re here to stay and understanding NLP will be essential.
If you want to understand more about LLMs, you need to learn about NLP. In this article, I will go through 5 FREE books which you need to read in 2023 to get a better grasp of NLP.
1. Speech and Language Processing
Authors: Dan Jurafsky and James H. Martin
Link: Speech and Language Processing
Written by two university professors, this Speech and Language Processing book provides you with a comprehensive introduction to the world of NLP. It is broken down into 3 sections: Fundamental Algorithms for NLP, NLP Applications, and Annotating Linguistic Structure. The first section is essential to beginners to get a better understanding of what NLP is, the foundations of it with examples breaking it down. You will come across a range of topics such as semantics, syntax, and more.
If the field of NLP is new to you or you want to transition into the field, I truly believe this book will be very beneficial to an individual's learning. As it was written by professors, the practical examples help readers understand the concepts much better than a purely theoretical book.
2. Foundations of Statistical Natural Language Processing
Authors: Christopher D. Manning and Hinrich Schütze
Link: Foundations of Statistical Natural Language Processing
If you are a data professional, or in the world of artificial intelligence — you will know how important statistics is to the field. Some believe that you do not require a high understanding of the sector, however I believe it is important as it will make your data professional journey much smoother.
When you have a good foundation about the NLP field, you might think the next step is to learn about the algorithms. Before that, you will want to learn more about the mathematical foundations of language. This book not only starts with the basics of NLP, it dives into the mathematical aspects such as probability spaces, bayes’ theorem, variance, and more.
3. Pattern Recognition and Machine Learning
Author: Christopher M. Bishop
Link: Pattern Recognition and Machine Learning
The best way to understand the performance of models is by understanding how the model works, its train of thought, pattern recognition and why it outputs what it does. Pattern recognition is the process of distinguishing data based on a set criteria performed by special algorithms.It enables learning and allows for room for improvement, which makes it very important to machine learning algorithms and their performance.
Every chapter has an exercise at the end which has been chosen to better explain each concept to the reader. The author kept the mathematical content at a minimum to help the reader grasp a better understanding, however it is noted that it will be beneficial to have a good grasp of calculus, linear algebra, and probability theory to understand pattern recognition and machine learning techniques.
4. Neural Network Methods in Natural Language Processing
Author: Yoav Goldberg
Link: Neural Network Methods in NLP
When looking into the growth of NLP, we can say that neural networks have played a big part. Neural networks have provided NLP models with a better understanding of the human language, allowing them to predict words and compartmentalize different topics that were not previewed to them during their learning face.
This book does not dive into the ins and outs of neural networks straight away. It starts off with learning the basics such as linear models, perceptrons, feed-forward, neural network training and more. The author has used a mathematical approach to explain these fundamental elements along with practical examples.
5. Practical Natural Language Processing
Authors: Sowmya Vajjala, Bodhisattwa Majumder, Anuj Gupta, and Harshit Surana
Link: Practical Natural Language Processing
So you’ve understood speech and language, you’ve covered statistical NLP, then looked at pattern recognition and neural networks in NLP. The last thing you need to learn about is the practical use of NLP.
This book goes through how NLP is used in the real world, the pipeline of NLP models, and more about text data and use cases, such as Chatbots like ChatGPT. In this book you will learn how NLP can be used in a variety of sectors such as retail, healthcare, finance, and more. With the different sectors, you will be able to gauge how the NLP pipeline works for each, and be able to figure out how to use it for yourself.
Wrapping it up
The aim and flow of this article was to provide you with 5 free books which I believe are essential and will benefit your NLP career or study. Although I did it in a structure format, I hope each book bounces off the other taking your studying to the next level.
If there are any other FREE NLP books which you believe others would benefit from, please drop them in the comments! Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.
More On This Topic
5 Free Data Science Books You Must Read in 2023
3 More Free Top Notch Natural Language Processing Courses
N-gram Language Modeling in Natural Language Processing
Natural Language Processing with spaCy
Natural Language Processing Key Terms, Explained
How to Start Using Natural Language Processing With PyTorch
With generative AI being the hype these days, leading companies like Google, AWS, Microsoft and Infosys do not want the world to be left behind to use it. These companies realised that generative AI being completely new to most of the workers around the world, took responsibility to come up with the content that will help the general public to upgrade themselves so that they can apply that knowledge at their workplace.
Moreover, according to the World Economic Forum, AI skills represent the third-highest priority for companies’ training strategies, right alongside analytical and creative thinking. It is pretty much true that ‘AI might not replace you, but a person who uses AI could.’ Every firm or institution wants the work to happen at a faster pace, and if AI is able to assist with them then people shouldn’t shy away from it.
Given that the field of AI can be bewildering for many individuals, these companies aim to address this knowledge gap by introducing new courses and tools. Here is the list of courses launched by various leading companies to upskill their workers:
Microsoft
Recently, Microsoft launched a new AI Skills Initiative to help people and communities around the world learn how to harness the power of AI.
Microsoft’s AI Skills Initiative comprises several new offerings aimed at making AI education more accessible. These include free courses developed in collaboration with LinkedIn, including the first-ever Professional Certificate on Generative AI.
Additionally, Microsoft even launched Generative AISkills Grant Challenge, an open global grant challenge organised in partnership with data.org to explore innovative approaches for training individuals in generative AI. Microsoft is also providing increased access to free digital learning events and resources, allowing anyone to enhance their understanding and proficiency in AI.
Here is the course under ‘Learn Skills for in Demand Jobs’ on Generative AI by Microsoft on Linkedin.
Career Essentials in Generative AI by Microsoft and LinkedIn
Google
Google has recently unveiled its latest generative AI learning path, which encompasses a selection of ten courses. The primary objective of these courses is to enhance the average person’s comprehension of AI and machine learning principles.
Here are few handpicked basic courses that one must go through
Introduction to Generative AI
Introduction to Responsible AI
Introduction to Image Generation
Introduction to Large Language Models
AWS
Andrew Ng’s DeepLearning.AI, in partnership with Amazon Web Services (AWS) announced an exciting new course on Coursera called “Generative AI with Large Language Models” to address the growing demand for expertise in this field.
Participants who choose to enrol in this course will acquire an extensive knowledge of the generative AI lifecycle, which relies on LLMs (Language Models) and the transformative architecture that drives them.
The course will enable them to understand the intricacies of LLMs and how they can be effectively utilised for different tasks. Additionally, participants will gain the ability to select the most appropriate model for specific purposes and employ suitable training techniques to maximise their effectiveness.
Click here to check out the course
Infosys
Infosys collaborated with Skillsoft to provide learners, free of cost, access to a rich repository of Skillsoft learning content designed to build technology, leadership and business, and behavioural skills through Infosys Springboard.
The content ranges from Skillsoft’s basic to advanced level courses covering topics such as digital transformation, AI and ML, data science, cloud, cybersecurity, and effective communication and presentation.
The content will be augmented with commentaries in multiple Indian regional languages, including Hindi, Marathi, Gujarati, Tamil and in some international languages.
Earlier this month, Infosys launched a comprehensive and free AI certification training programme through Infosys Springboard to empower individuals with the necessary skills to succeed in the future job market.
Click here to access Springboard
The post Upskill Yourself With These Free Generative AI Courses Offered by Big Techs & IT Firms appeared first on Analytics India Magazine.