This data science project has been used as a take-home assignment in the recruitment process at Meta (Facebook). In this take-home assignment, we will discover how Rotten Tomatoes is making labeling as ‘Rotten’, ‘Fresh’ or ‘Certified Fresh’.
Link to this data science project: https://platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
To do that, we will develop two different approaches.
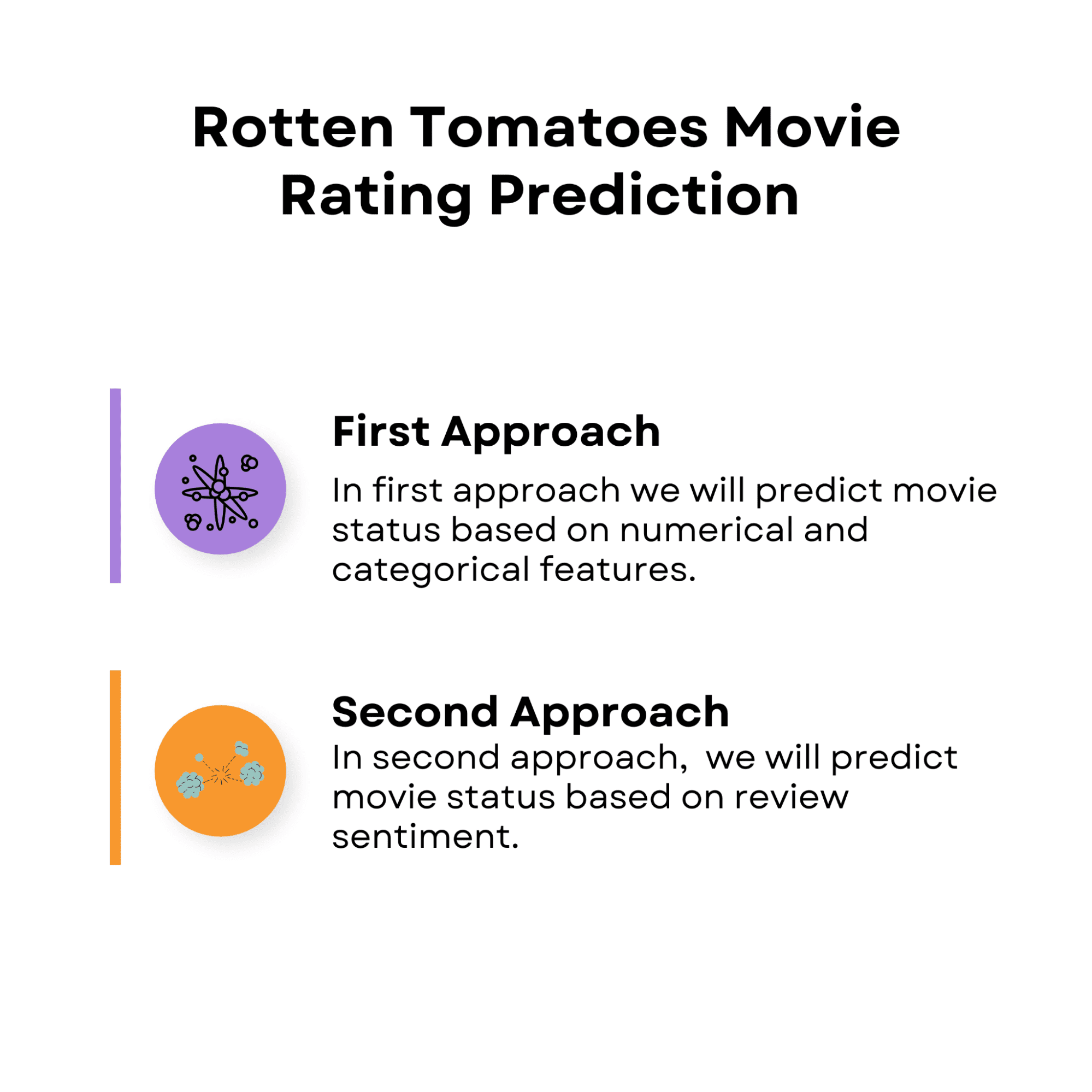
Image by Author
Throughout our exploration, we will discuss data preprocessing, various classifiers, and potential improvements to enhance the performance of our models.
By the end of this post, you will have gained an understanding of how machine learning can be employed to predict movie success and how this knowledge can be applied in the entertainment industry.
But before going deeper, let’s discover the data we will work on.
Second Approach: Predicting Movie Status Based on Review Sentiment
In the second approach, we plan to predict the movie's success by assessing the sentiment of its reviews. We will specifically apply sentiment analysis to evaluate the overall sentiment of the review and classify the film as 'Fresh' or 'Rotten' based on this sentiment.
Yet, before we start the sentiment analysis, we must first prepare our dataset. In contrast to the preceding strategy, this one entails dealing with text data (reviews) rather of numerical and categorical variables. For this challenge, we will continue to employ the Random Forest model. Let's take a closer look at our data before we go on.
First, let’s read the data.
Here's the code.
df_critics = pd.read_csv('rotten_tomatoes_critic_reviews_50k.csv') df_critics.head()
Here is the output.

Image by Author
Great, let’s start with the Data Preprocessing.
Data Preprocessing
In this dataset, we do not have the movie names and corresponding statuses. For this dataset, we have review_content and review_type variables.
That’s why we will merge this dataset with our previous one, on rotten_tomatoes_link, and select the necessary features with index bracketing as follows.
Here's the code:
df_merged = df_critics.merge(df_movie, how='inner', on=['rotten_tomatoes_link']) df_merged = df_merged[['rotten_tomatoes_link', 'movie_title', 'review_content', 'review_type', 'tomatometer_status']] df_merged.head()
Here is the output.

In this approach, we will use only the review_content column as the input feature and review_type as the ground truth label.
To ensure that the data is usable, we need to filter out any missing values in the review_content column since empty reviews cannot be used in the sentiment analysis.
df_merged = df_merged.dropna(subset=['review_content'])
After filtering out missing values, we will visualize the distribution of review_type to gain a better understanding of the distribution of data.
# Plot distribution of the review ax = df_merged.review_type.value_counts().plot(kind='bar', figsize=(12,9)) ax.bar_label(ax.containers[0])
This visualization will help us determine whether there are any class imbalances in the data and will guide us in selecting an appropriate evaluation metric for our model.
Here's the whole code:
df_merged = df_merged.dropna(subset=['review_content']) # Plot distribution of the review ax = df_merged.review_type.value_counts().plot(kind='bar', figsize=(12,9)) ax.bar_label(ax.containers[0])
Here is the output.
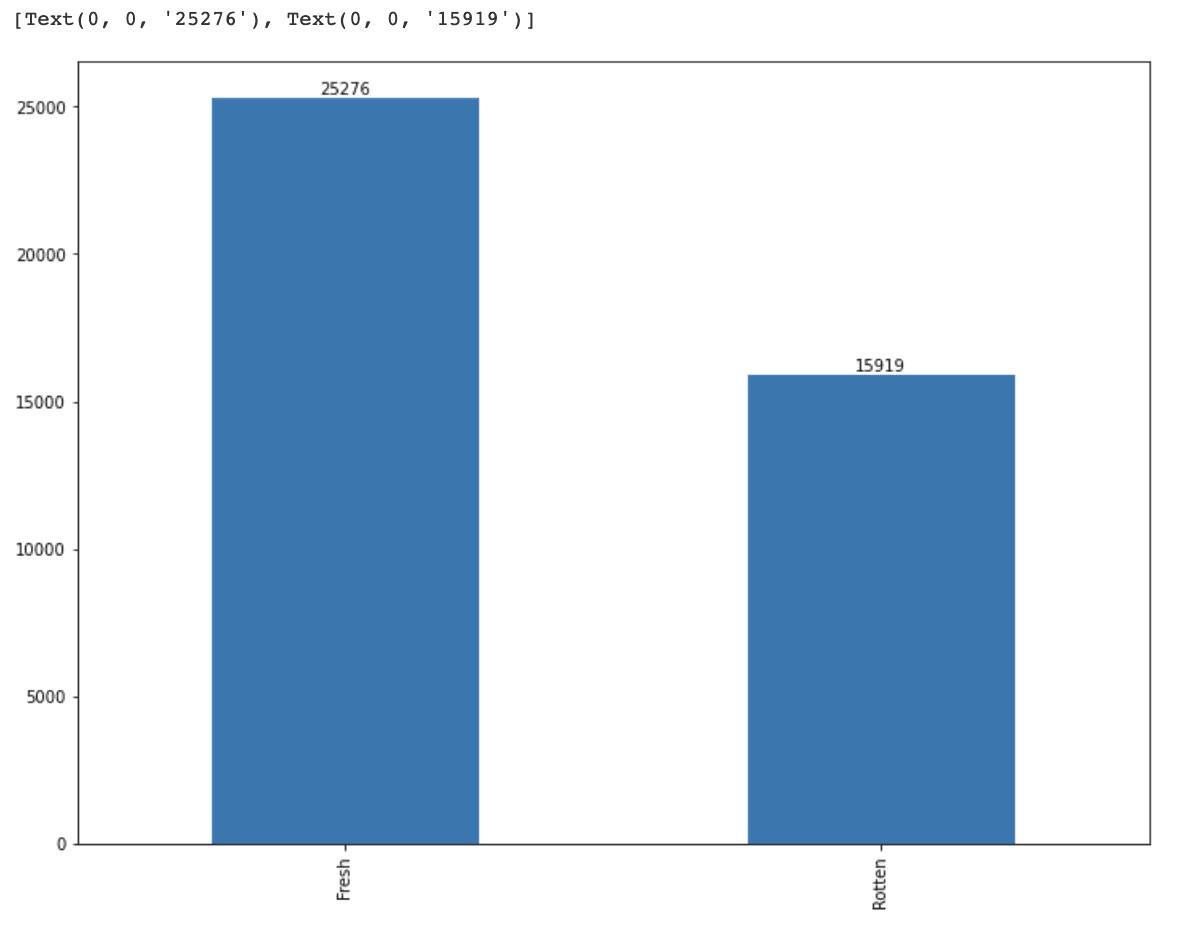
It looks like we have an imbalance problem between our features.
And also, we have too many data points, which might decrease our speed.
So, we will pick 5000 entries from the original dataset first.
df_sub = df_merged[0:5000]
Then we will do the ordinal encoding.
review_type = pd.DataFrame(df_sub.review_type.replace(['Rotten','Fresh'],[0,1]))
Finally, we will create a data frame, that contains the encoded labels with review content by using the concat() method in Python and view the first 5 rows by using the head() method.
df_feature_critics = pd.concat([df_sub[['review_content']] ,review_type], axis=1).dropna() df_feature_critics.head()
Here's the whole code.
# Pick only 5000 entries from the original dataset df_sub = df_merged[0:5000] # Encode the label review_type = pd.DataFrame(df_sub.review_type.replace(['Rotten','Fresh'],[0,1])) # Build final DataFrame df_feature_critics = pd.concat([df_sub[['review_content']] ,review_type], axis=1).dropna() df_feature_critics.head()
Here is the output.

Great, now as a final step for this section, let’s split our dataset into trainset and test set.
X_train, X_test, y_train, y_test = train_test_split( df_feature_critics['review_content'], df_feature_critics['review_type'], test_size=0.2, random_state=42)
Default Random Forest
To use the text reviews in our DataFrame for machine learning methods, we must transform them into a format that can be processed. In Natural Language Processing, this is known as tokenization, where we translate text or words into n-dimensional vectors and then use these vector representations as training data for our machine learning algorithm.
To do this, we are going to use scikit-learn's CountVectorizer class to turn the text reviews into a matrix of token counts. We begin by creating a dictionary of unique terms from the input text.
For example, based on the two reviews "This movie is good" and "The movie is bad," the algorithm would create a dictionary of unique phrases such as ;
Then, based on the input text, we calculate the number of times of each word in the dictionary.
["this", "movie", "is", "a", "good", "the", "bad"].
For instance, the input "This movie is a good movie" would result in a vector of [1, 2, 1, 1, 1, 0, 0]
Finally, we input the generated vector into our Random Forest model.
We can predict the sentiment of the reviews and classify the movie as 'Fresh' or 'Rotten' by training our Random Forest classifier on the vectorized text data.
The following code instantiates a CountVectorizer class that transforms text data into numerical vectors, and specifies that a word must appear in at least one document to be included in the vocabulary.
# Instantiate vectorizer class vectorizer = CountVectorizer(min_df=1)
Next, we are going to transform the training data into vectors using the instantiated CountVectorizer object.
# Transform our text data into vector X_train_vec = vectorizer.fit_transform(X_train).toarray()
Then, we instantiate a RandomForestClassifier object with a specified random state and fit the random forest model using the training data.
# Initialize random forest and train it rf = RandomForestClassifier(random_state=2) rf.fit(X_train_vec, y_train)
Now it is time to predict by using the trained model and transformed test data.
Then we will print out the classification report that contains evaluation metrics such as precision, recall, and f1-score.
# Predict and output classification report y_predicted = rf.predict(vectorizer.transform(X_test).toarray()) print(classification_report(y_test, y_predicted))
Finally, let’s create a new figure with a specified size for the confusion matrix plot and plot the confusion matrix.
fig, ax = plt.subplots(figsize=(12, 9)) plot_confusion_matrix(rf, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax
Here is the whole code.
# Instantiate vectorizer class vectorizer = CountVectorizer(min_df=1) # Transform our text data into vector X_train_vec = vectorizer.fit_transform(X_train).toarray() # Initialize random forest and train it rf = RandomForestClassifier(random_state=2) rf.fit(X_train_vec, y_train) # Predict and output classification report y_predicted = rf.predict(vectorizer.transform(X_test).toarray()) print(classification_report(y_test, y_predicted)) fig, ax = plt.subplots(figsize=(12, 9)) plot_confusion_matrix(rf, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax
Here is the output.

Weighted Random Forest
As we can see from our latest confusion matrix, the performance of our model is not good enough.
Yet, this might be expected due to working with a limited number of data points.(5000 instead of 100000).
Let’s see if we can increase the performance by solving the imbalance issue with class weights.
Here's the code.
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature_critics.review_type), y = df_feature_critics.review_type.values) class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist())) class_weight_dict
Here is the output.
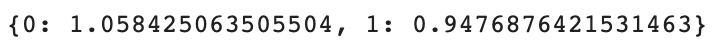
We now train our Random Forest classifier on the vectorized text input, but this time including the class weight information to increase the evaluation metrics.
We first create the CountVectorizer class and, like previously, turn our text input into vectors.
And transform our text data into a vector.
vectorizer = CountVectorizer(min_df=1) X_train_vec = vectorizer.fit_transform(X_train).toarray()
Then we will define a random forest with calculated class weight and train it.
# Initialize random forest and train it rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict) rf_weighted.fit(X_train_vec, y_train)
Now it is time to make a prediction by using test data and printing out the classification report.
# Predict and output classification report y_predicted = rf_weighted.predict(vectorizer.transform(X_test).toarray()) print(classification_report(y_test, y_predicted))
In final step, we set the figure size and plot the confusion matrix.
fig, ax = plt.subplots(figsize=(12, 9)) plot_confusion_matrix(rf_weighted, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax)
Here is the whole code.
# Instantiate vectorizer class vectorizer = CountVectorizer(min_df=1) # Transform our text data into vector X_train_vec = vectorizer.fit_transform(X_train).toarray() # Initialize random forest and train it rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict) rf_weighted.fit(X_train_vec, y_train) # Predict and output classification report y_predicted = rf_weighted.predict(vectorizer.transform(X_test).toarray()) print(classification_report(y_test, y_predicted)) fig, ax = plt.subplots(figsize=(12, 9)) plot_confusion_matrix(rf_weighted, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax)
Here is the output.
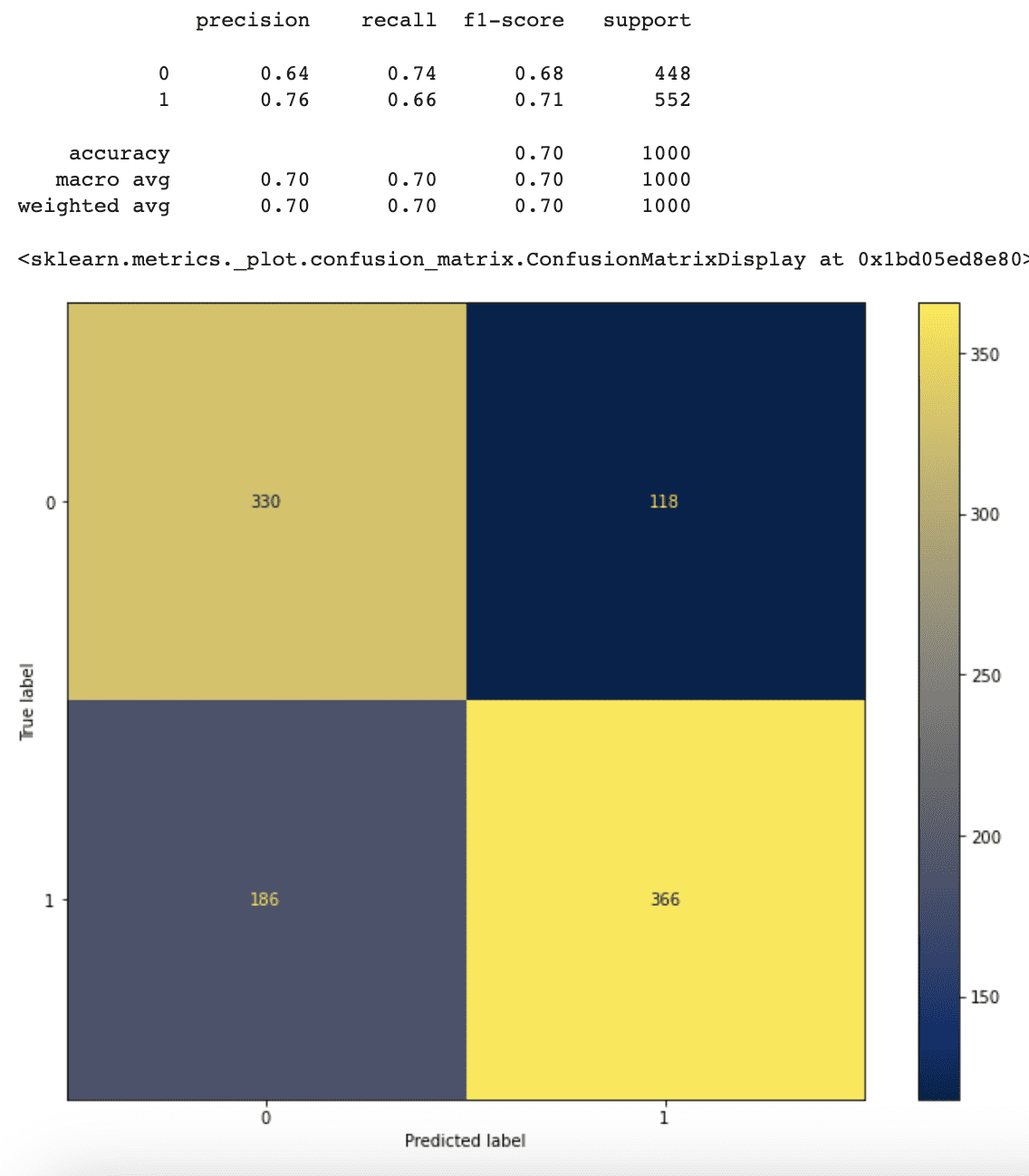
Now our model’s accuracy is slightly better than the one without class weights.
Furthermore, because the weight of class 0 ('Rotten') is greater than the weight of class 1 ('Fresh,' the model now performs better in predicting 'Rotten' movie reviews but worse in predicting 'Fresh' movie reviews.
This is because the model pays more attention to the data classed as 'Rotten'.
Movie Status Prediction
Let's use our Random Forest model to predict movie status now that we've trained it to predict the sentiment of a movie review. We'll go through the following stages to determine a movie's status:
- Collect all of the reviews for a certain film.
- Make use of our Random Forest model to estimate the state of each review (for example, 'Fresh' or 'Rotten').
- To classify the final status of a movie based on the total review status, use the rule-based approach given on the Rotten Tomatoes website.
Here in the following code, we first create a function name predict_movie_statust, which take a prediction as an argument.
Then, depending on the positive_percentage value, we identify the movie status, assigning either 'Fresh' or 'Rotten' to the prediction variable.
Finally, it will output the positive review percentage with the movie status.
Here is the code.
def predict_movie_status(prediction): """Assign label (Fresh/Rotten) based on prediction""" positive_percentage = (prediction == 1).sum()/len(prediction)*100 prediction = 'Fresh' if positive_percentage >= 60 else 'Rotten' print(f'Positive review:{positive_percentage:.2f}%') print(f'Movie status: {prediction}')
In this example, we'll predict the status of three films: Body of Lies, Angel Heart, and The Duchess. Let us begin with Body of Lies.
'Body of Lies' Prediction
Now as it stated above, first let’s collect all of the reviews of Body of Lies movie.
Here is the code.
# Gather all of the reviews of Body of Lies movie df_bol = df_merged.loc[df_merged['movie_title'] == 'Body of Lies'] df_bol.head()
Here is the output.

Great, at this stage let’s apply a weighted random forest algorithm to predict status. Then we use this in the custom function we defined earlier, which takes a prediction as an argument.
Here is the code.
y_predicted_bol = rf_weighted.predict(vectorizer.transform(df_bol['review_content']).toarray()) predict_movie_status(y_predicted_bol)
Here is the output.

And here is our result, let’s check our result whether it is valid or not by comparing it with ground_truth status.
Here is the code.
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'Body of Lies'].unique()
Here is the output.

It looks like our prediction is pretty valid because the status of this movie is Rotten as we predict.
'Angel Heart' Prediction
Here we will repeat all steps.
- Gather all of the reviews
- Make prediction
- Comparing
Let’s first gather all of the reviews for Anna Karenina's movie.
Here is the code.
df_ah = df_merged.loc[df_merged['movie_title'] == 'Angel Heart'] df_ah.head()
Here is the output.

Now it is time to make a prediction by using random forest and our custom function.
Here is the code.
y_predicted_ah = rf_weighted.predict(vectorizer.transform(df_ah['review_content']).toarray()) predict_movie_status(y_predicted_ah)
Here is the output.

Let’s make a comparison.
Here is the code.
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'Angel Heart'].unique()
Here is the output.
Our model predicts correct again.
Now let’s try one more time.
'The Duchess' Prediction
First let’s collect all reviews.
Here is the code.
df_duchess = df_merged.loc[df_merged['movie_title'] == 'The Duchess'] df_duchess.head()
Here is the output.

Then now it is time to make a prediction.
Here is the code.
y_predicted_duchess = rf_weighted.predict(vectorizer.transform(df_duchess['review_content']).toarray()) predict_movie_status(y_predicted_duchess)
Here is the output.

Let’s compare our prediction with the ground truth.
Here is the code.
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'The Duchess'].unique()
Here is the output.

And the movie's ground-truth label is 'Fresh,' indicating that our model's forecast is incorrect.
Yet, it can be noticed that our model's predicted is very close to the 60% threshold, indicating that a minor tweak to the model might alter its prediction from 'Rotten' to 'Fresh'.
Obviously, the Random Forest model that we trained above is not the best model, since there is still potential for improvement. In the next part, we will provide many suggestions for improving the performance of our model.
Suggestions for Performance Improvement
- Increase the amount of data you have.
- Set different hyperparameters of the random forest model.
- Apply different machine learning models to find the best.
- Adjust the method used to represent the text data.
Conclusion
In this article, we explored two different approaches to predict movie status based on numerical and categorical features.
We first performed data preprocessing and then applied a decision tree classifier and random forest classifier to train our model.
We also experimented with feature selection and a weighted random forest classifier.
In the second approach, we used the default random forest and weighted random forest to predict the movie status of three different films.
We provided suggestions for improving the performance of our models. We hope this article has been informative and helpful.
If you want some beginner level projects, check out our post “Data Science Project Ideas for Beginners”.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.
More On This Topic
- Data Science Project of Rotten Tomatoes Movie Rating Prediction: First…
- KDnuggets™ News 20:n44, Nov 18: How to Acquire the Most Wanted Data…
- How to Future-Proof Your Data Science Project
- Data Science Project Infrastructure: How To Create It
- 19 Data Science Project Ideas for Beginners
- 4 Steps for Managing a Data Science Project