Google has released the latest version of its popular open-source software library, TensorFlow 2.13. The launch comes four months after the introduction of TensorFlow 2.12. In 2022, the team had released three versions – 2.8, 2.9, 2.10 and 2.11. For 2023, we already have the second update with the earlier one being released in March.
Check out the GitHub repository to learn more about the update.
In the updated version, the LMDB kernels have been changed to return an error. This is in preparation for completely removing them from TensorFlow. The LMDB dependency that these kernels are bringing to TensorFlow has been dropped, thus making the build slightly faster and more secure.
Other major improvements have been made to TF lite; the team has added 16-bit and 64-bit float type support for built-in op cast. Also, the Python TF Lite Interpreter bindings now have an option experimental_disable_delegate_clustering to turn-off delegate clustering.
Furthermore, the tf.data.Dataset.zip now supports Python-style zipping, i.e. Dataset.zip(a, b, c). Now ‘tf.data.Dataset.shuffle’ supports ‘tf.data.UNKNOWN_CARDINALITY’ when doing a “full shuffle” using dataset = dataset.shuffle(dataset.cardinality()). But a “full shuffle” will load the full dataset into memory so that it can be shuffled, so users are recommended to only use this while working with small datasets or datasets of small objects.
Similar to the last update, some considerable additions have been made to Keras as well. The team has removed the Keras scikit-learn API wrappers (KerasClassifier and KerasRegressor), which was deprecated in August 2021. Instead, the team recommended using SciKeras. They also added a utility to run a timed thread every x seconds. The feature can be used to run a threaded function alongside model training or any other snippet of code.
Other features like F-score metrics, activation function, experimental KPI for metrics and so on have been added. Though no update regarding the security of the software has been released.
The post What’s New in the Latest TensorFlow 2.13 appeared first on Analytics India Magazine.
In the dynamic world of the Internet of Things (IoT), data integration plays a crucial role in harnessing the full potential of connected devices. By seamlessly combining data from diverse sources, data integration enables organizations to unlock valuable insights, optimize operations, and make informed decisions. This blog will explore the significance of data integration in IoT environments, its, techniques, benefits, and future trends.
Understanding data integration in IoT
Data integration in the context of IoT refers to the process of gathering, consolidating, and transforming data from various IoT devices, sensors, and systems into a unified format for meaningful analysis. Data integration presents a holistic view of scattered data in a singular space, improving accessibility and decision-making speed.
Techniques and Technologies for Data Integration:
Let’s look at some of the fundamental techniques and technologies used in data integration across IoT systems:
Message queuing and publish/subscribe systems
Message queuing systems, such as Apache Kafka and RabbitMQ, and publish/subscribe systems, like MQTT, are widely used in IoT data integration. These systems facilitate efficient and reliable data transmission between IoT devices and systems. Messages are published by senders and received by subscribers, enabling real-time communication and data flow between different components of the IoT ecosystem.
For example, in a smart home scenario, a temperature sensor publishes data on room temperature changes, and an HVAC system subscribes to this data to adjust the heating or cooling accordingly.
Application programming interfaces (APIs)
APIs provide standardized interfaces and protocols for integrating data from various sources in IoT systems. They enable data exchange and seamless communication between devices, platforms, and systems. APIs define the rules and formats for requesting and exchanging data, making it easier to integrate diverse data sources.
For instance, a weather API may allow an IoT weather station to retrieve real-time weather data and integrate it into a smart irrigation system. This integration enables the irrigation system to adjust watering schedules based on weather conditions.
Data integration platforms
Data integration platforms offer comprehensive solutions for managing and orchestrating data integration workflows in IoT environments. These platforms provide ETL functionality to extract, transform, and load data from multiple sources.
They often include visual interfaces and zero code, drag-and-drop capabilities for designing integration workflows, allowing users to define data mapping, transformation rules, and data quality controls. These platforms help organizations simplify the complexities of data integration in IoT and ensure consistency and reliability in the integrated data.
These techniques and technologies for data integration in IoT provide the necessary infrastructure and tools to handle the complexities of integrating diverse data sources, ensuring reliable data transmission, standardized data formats, and efficient data management. By leveraging these techniques, organizations can harness the full potential of IoT data and derive valuable insights for enhanced decision-making and improved operational efficiency.
Advantages of data integration in IoT environments
Data integration plays a vital role in maximizing the benefits obtained from IoT environments.
Enhanced decision-making: By integrating data from diverse IoT sources, organizations comprehensively understand their operations. This integrated data provides valuable insights for making well-informed decisions. Analyzing patterns and trends across multiple data streams allows organizations to make accurate predictions, identify optimization opportunities, and manage risks effectively.
Improved operational efficiency: Data integration optimizes operations and enhances efficiency. Organizations can identify bottlenecks, inefficiencies, and redundancies by consolidating data from various devices, sensors, and systems. For example, in a factory, integrating data from sensors embedded in production lines, supply chain systems, and quality control processes helps identify areas of inefficiency and streamline workflows.
Seamless connectivity and interoperability: Data integration enables smooth connectivity and interoperability in IoT environments, allowing effective communication and collaboration among diverse devices, protocols, and platforms. For instance, in the healthcare sector, data integration facilitates seamless sharing of patient data between medical devices, electronic health records (EHR) systems, and healthcare providers.
Real-time monitoring: Data integration enables real-time monitoring of IoT systems, providing immediate visibility into the status, performance, and health of assets. It allows data teams to detect anomalies, deviations, or potential failures in real-time, enabling proactive maintenance and predictive analytics.
Future trends
The field of IoT continues to evolve rapidly, and with it, the use of data integration techniques in IoT systems is expected to witness several future trends. Some of the promising ones are:
Edge computing and fog computing: Fog and Edge computing involve processing and analyzing data closer to the source rather than relying solely on centralized cloud infrastructure. Edge computing allows for local data processing and integration at the device level, enabling faster insights and more efficient utilization of network resources. Fog computing extends this concept by distributing data processing across multiple layers, combining edge devices and gateway nodes for increased scalability and responsiveness.
Artificial intelligence (AI) and machine learning (ML) integration: Integrating AI and ML technologies with data integration in IoT systems will continue to expand. AI and ML algorithms can automate tasks and make smart predictions. For example, in industries such as manufacturing and transportation, ML algorithms can be integrated into IoT systems to monitor and analyze data from sensors embedded in machinery and predict potential failures or maintenance needs.
Blockchain for secure and trustworthy data integration: Blockchain technology can enhance the security and trustworthiness of data integration. By providing a decentralized and immutable ledger, blockchain can ensure the integrity and authenticity of data during the integration process.
Federated data integration: Federated data integration involves integrating data from multiple IoT systems that belong to different organizations or domains. It allows organizations to collaborate and share data securely while preserving data ownership and privacy.
By embracing these trends, organizations can leverage data integration to unlock the full potential of IoT systems, drive innovation, and achieve new levels of efficiency and insights.
The future is bright
Data integration is a critical aspect of IoT environments, enabling organizations to harness the potential of connected devices. Data integration empowers organizations to gain actionable insights, optimize operations, and achieve seamless connectivity by overcoming challenges and leveraging key components, techniques, and technologies. As IoT continues to evolve, embracing data integration strategies will drive innovation and success in this interconnected world.
OpenAI is forming a new team to bring ‘superintelligent’ AI under control Kyle Wiggers 7 hours
OpenAI is forming a new team led by Ilya Sutskever, its chief scientist and one of the company’s co-founders, to develop ways to steer and control “superintelligent” AI systems.
In a blog post published today, Sutskever and Jan Leike, a lead on the alignment team at OpenAI, predict that AI with intelligence exceeding that of humans could arrive within the decade. This AI — assuming it does, indeed, arrive eventually — won’t necessarily be benevolent, necessitating research into ways to control and restrict it, Sutskever and Leike say.
“Currently, we don’t have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue,” they write. “Our current techniques for aligning AI, such as reinforcement learning from human feedback, rely on humans’ ability to supervise AI. But humans won’t be able to reliably supervise AI systems much smarter than us.”
To move the needle forward in the area of “superintelligence alignment,” OpenAI is creating a new Superalignment team, led by both Sutskever and Leike, which will have access to 20% of the compute the company has secured to date. Joined by scientists and engineers from OpenAI’s previous alignment division as well as researchers from other orgs across the company, the team will aim to solve the core technical challenges of controlling superintelligent AI over the next four years.
How? By building what Sutskever and Leike describe as a “human-level automated alignment researcher.” The high-level goal is to train AI systems using human feedback, train AI to assist in evaluating other AI systems and ultimately to build AI that can do alignment research. (Here, “alignment research” refers to ensuring AI systems achieve desired outcomes or don’t go off the rails.)
It’s OpenAI’s hypothesis that AI can make faster and better alignment research progress than humans can.
“As we make progress on this, our AI systems can take over more and more of our alignment work and ultimately conceive, implement, study and develop better alignment techniques than we have now,” Leike and colleagues John Schulman and Jeffrey Wu postulated in a previous blog post. “They’ll work together with humans to ensure that their own successors are more aligned with humans. Human researchers will focus more and more of their effort on reviewing alignment research done by AI systems instead of generating this research by themselves.”
Of course, no method is foolproof — and Leike, Schulman and Wu acknowledge the many limitations of OpenAI’s in their post. Using AI for evaluation has the potential to scale up inconsistencies, biases or vulnerabilities in that AI, they say. And it might turn out that the the hardest parts of the alignment problem might not be related to engineering at all.
But Sutskever and Leike think it’s worth a go.
“Superintelligence alignment is fundamentally a machine learning problem, and we think great machine learning experts — even if they’re not already working on alignment — will be critical to solving it,” they write. “We plan to share the fruits of this effort broadly and view contributing to alignment and safety of non-OpenAI models as an important part of our work.”
Andrew Ng, touted to be one of the Godfathers of AI is back again with a short, free new course, ‘LangChain: Chat With Your Data!’ which will cover Retrieval Augmented Generation (RAG) and building advanced chatbots.
Harrison Chase, cofounder and CEO of LangChain will take you through the course by the end of which, you’ll have the expertise to create practical applications that leverage LangChain and LLMs.
RAG involves using external datasets to retrieve contextual documents, while the chatbot guide emphasises responding to queries based on document content rather than training data.
The key focus areas of the course:
Document Loading: Understand the basics of data loading and explore over 80 unique loaders available in LangChain. These loaders allow you to access diverse data sources, including audio and video.
Document Splitting: Learn the recommended practices and considerations for splitting data effectively.
Vector Stores and Embeddings: Delve into the concept of embeddings and explore how LangChain integrates with vector stores, enabling seamless integration of vector-based data.
Retrieval: Master advanced techniques for accessing and indexing data within the vector store. This knowledge empowers you to retrieve the most relevant information beyond simple semantic queries.
Question Answering: Develop a comprehensive question-answering solution that operates in a single pass.
Chat: Acquire the skills to track and select pertinent information from conversations and data sources. Using LangChain, you’ll build your own chatbot capable of engaging with users effectively.
This course is ideal for Python developers with a passion for harnessing the potential of these cutting-edge technologies.
Previously as well, Ng collaborated with Chase for another course – ‘LangChain for LLM Application Development’ that focused on how to apply LLMs to your data, and build personalised assistants and chatbots.
The post Andrew Ng Introduces Free Course with LangChain appeared first on Analytics India Magazine.
This is the first in a series of articles based on interviews with the technical leaders and hands-on architects at Intel who are working behind the scenes to advance and democratize accelerated AI and its application — remarkably in a vendor-agnostic, open ecosystem, community-driven manner. These technologists have the AI knowledge and a mandate to leverage their knowledge, design capability, and deep reach into the datacenter to advance the state-of-the-art in AI computation. The follow-on articles will focus on individual technologies, their impact, and contributions by these Intel groups.
The 5th epoch
The current transition to AI and accelerated computing is considered the 5th epoch of distributed computing,[1] an epoch where we must challenge conventional wisdom so that programming models and network stacks can (and must) evolve to meet the productivity and efficiency goals of coming distributed systems. While some may think Moore’s Law is hitting the wall of performance per core, Intel’s Pat Gelsinger noted that “Even Gordon Moore, when he wrote his original paper on Moore’s law, saw this day of reckoning where we’ll need to build larger systems out of smaller functions, combining heterogeneous and customized solutions.” [2]
This 5th epoch is focused on machine learning where computational accelerators like GPUs are needed to provide arithmetic scalability (to an exaflop/s and beyond) to address workload requirements and interactive response for data-centric human-machine interactions. GPUs and alternative computational acceleration are only part of the story. Data is the foundation of machine learning. Performance, security, and power efficiency require that smart hardware accelerators be tasked with managing and protecting on-node data as well as moving data to computation and computation to data within a distributed data center. There is a high demand for high memory bandwidth to keep these accelerated platforms fed with data. The current technology implementation uses HBM2e on GPUs and CPUs (See CPU speedups below). With advanced packaging that can place heterogenous dies in a single processor packaging along with GPU technology, data providers can continue their transition to securely deliver planet-scale software services and exascale simulation capabilities. Thus, we enter the 5th epoch with a burgeoning hardware ecosystem that provides ubiquitous heterogeneous accelerated computing.
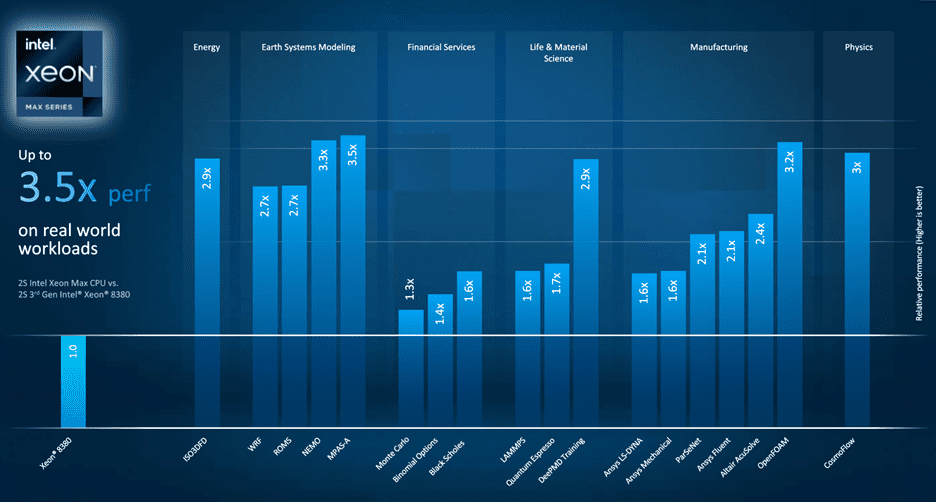
Figure 1. Real-world Intel Xeon CPU Max Series performance reported by Intel.[3] The current technology implementation uses HBM2e which helps keep acceleration platforms fed with data
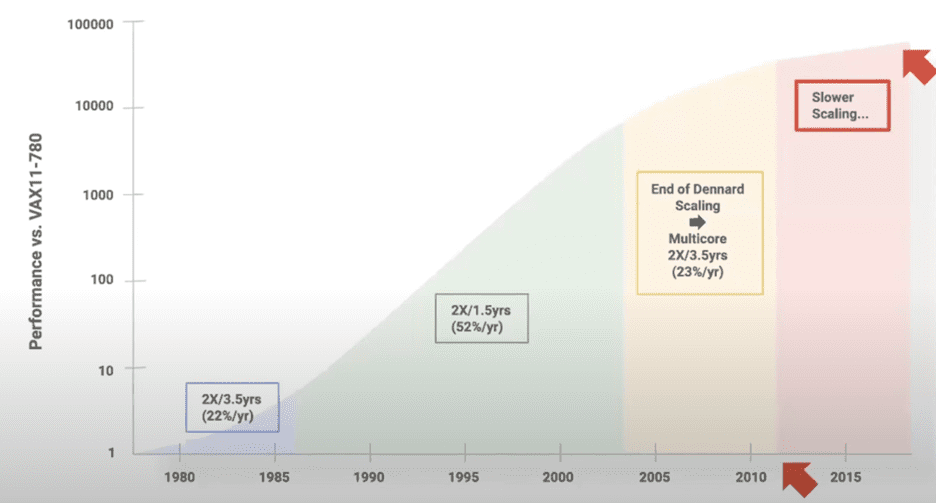
This rapid evolution and widespread deployment of accelerators powering the 5th epoch transition requires the creation of a software-defined infrastructure that fundamentally redefines how we build distributed systems. Industry trends demonstrate that accelerators are our friends (and path to the future) because a single general-purpose server architecture cannot generalize to all application needs (Figure 2). Domain- and application-specific accelerators will proliferate because they can deliver significant efficiency improvements beyond what is possible with general-purpose hardware. [4]
Figure 2. Forty years of processor performance relative to the baseline of a VAX11-780 illustrate the need for accelerators. (Source)
Joe Curley (vice president and general manager – Intel Software Products and Ecosystem), put the Intel efforts in perspective: “In facing workloads like HPC and AI,” he noted, “some hardware devices are more optimal than others. What I love about HPC and AI is that we have melded brick-and-mortar testing with software and moved it to the computer. Simulations now give us insights that were not previously obtainable in weather simulation, high energy physics, and computer manufacturing, plus addressing an exponential societal infrastructure demand [5] and numerous other datacenter workloads that have tremendous societal and commercial impacts. With hardware accelerators, we can optimize critical path operations to get answers faster while consuming less power, two very desirable outcomes, but accelerators require an appropriate software ecosystem. Creating this ecosystem requires a community effort given the portability needs of our customers combined with the breadth and rapid adoption of AI.”
“With hardware accelerators, we can optimize critical path operations to get answers faster while consuming less power, two very desirable outcomes, but accelerators require an appropriate software ecosystem. Creating this ecosystem requires a community effort given the portability needs of our customers combined with the breadth and rapid adoption of AI.” — Joe Curley
Even greater speedups using AI-enabled HPC
The HPC community is currently experiencing a surge in the adoption of machine learning in scientific computing. The forthcoming 2+ exaflop/s (performing double-precision arithmetic) Aurora supercomputer, for example, is being built in collaboration with Intel and Hewlett Packard Enterprise using Intel Xeon CPU Max Series and Intel Data Center GPU Max Series. One of Aurora’s distinguishing features will be its ability to seamlessly integrate the important scientific tools of data analysis, modeling and simulation, and artificial intelligence.[6]
AI-accelerated HPC was the theme of the special presentation at ISC’23 by Jeff McVeigh, Intel GM of the Super Compute Group. He presented data on Max Series GPU performance on AI-accelerated HPC applications and Intel efforts to address the “boom” in AI and scientific computing (Figure 3). Ansys CTO Prith Banerjee also shared a real-world example of the Max Series GPU at ISC’23 running over 50% faster than the competition on both the inference and training components of CoMLSim, a code that uses AI to accelerate fluid dynamics problems. [7]
Figure 3: The many areas being affected by scientific AI according to Jeff McVeigh. (Source)
Language processing AI models illustrate the power of an accelerator hierarchy
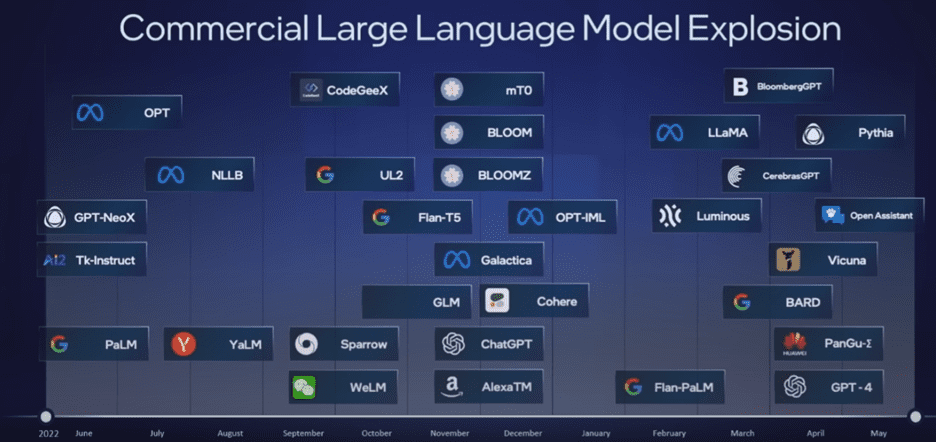
ChatGPT is currently one of the most popularly recognizable generative AI models, but it is just the tip of the iceberg in a remarkable explosion in language-processing AI models. These models are capable of generating human-like prose, programs, and more. These language models are huge, with parameter counts in the trillions.[8]
Figure 4. Some of the many commercial large language models. (Source)
Emphasizing this trend, Argonne National Laboratory announced plans at ISC’23 to create generative AI models for the scientific research community, in collaboration with Intel and HPE.
“The project aims to leverage the Aurora supercomputer to produce a resource that can be used for downstream science at the Department of Energy labs and in collaboration with others,” said Rick Stevens, Argonne associate laboratory director.
These generative AI models for science will be trained on general text, code, scientific texts and structured scientific data from biology, chemistry, materials science, physics, medicine and other sources.
The resulting models (which are huge and can contain trillions of parameters) will be used in a variety of scientific applications, from the design of molecules and materials to the synthesis of knowledge across millions of sources to suggest new and interesting experiments in systems biology, polymer chemistry and energy materials, climate science and cosmology. The model will also be used to accelerate the identification of biological processes related to cancer and other diseases and suggest targets for drug design.
Argonne is one member in an international collaboration to advance the generative AI project, including Intel, HPE; Department of Energy laboratories, U.S. and international universities, nonprofits, and international partners, such as RIKEN.
A hierarchy of accelerators
Argonne is, of course, a premier institution for working with such models on the latest hardware including the Aurora exascale supercomputer. Democratizing AI requires enabling a mass audience with accelerated computing devices at a variety of price/performance tiers. Hence the need for an accelerator hierarchy.
For dedicated accelerated training of AI models containing enormous numbers of parameters, Sree Ganesan (product management head of software at Habana), noted that huge amounts of memory are needed. He noted that with 96GB of HBM2e memory, the new GAUDI2 processor is designed for many aspects of enabling deep learning on such massive models. The GAUDI deep learning training and inference processors provide an alternative to GPUs for dedicated deep-learning workloads.
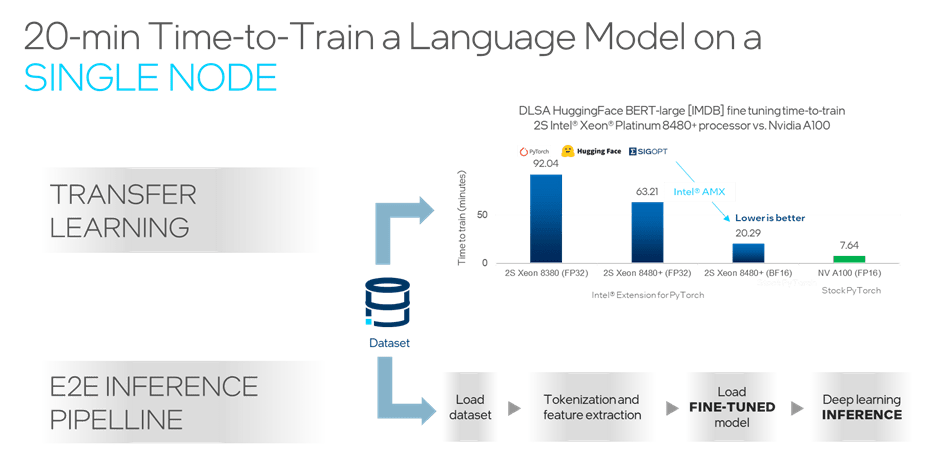
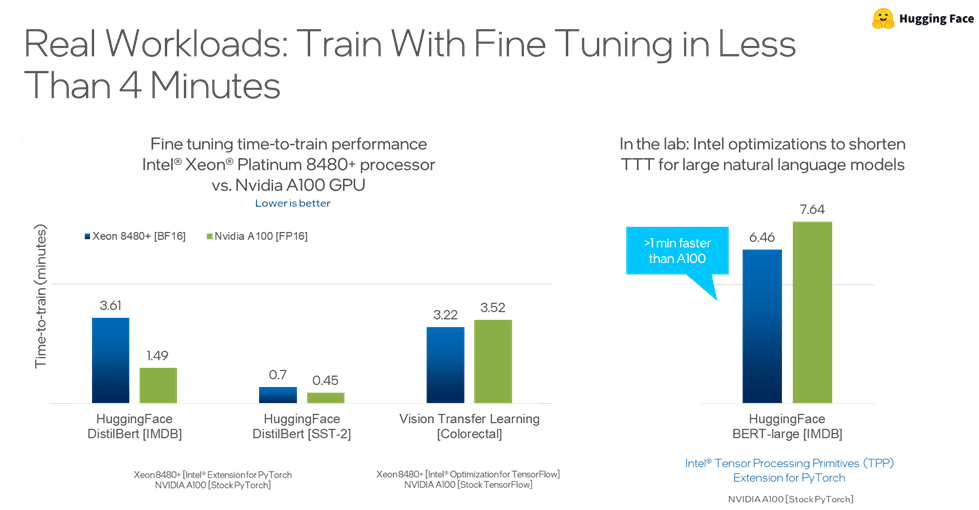
General-purpose CPUs and GPUs can also support the training and inference of even such large AI models. Bundling all this under the umbrella of “universal AI”, Pradeep Dubey (Senior Fellow and Parallel Computing Lab Director at Intel) believes the latest 4th Gen Intel Xeon processors can support the workflow for many AI users without leaving the CPU.. This “fast enough to stay on the CPU” claim is backed up by benchmarks such as training a Bidirectional Encoder Representations from Transformers (BERT) language model (Figure 5) on a single Intel® Xeon® Platinum 8480+ 2S node in 20 minutes.
Figure 5: Training can occur quickly on the CPU.
Fine tuning a natural language model took less than four minutes (Figure 6).
Figure 6: Fast CPU-based fine tuning.
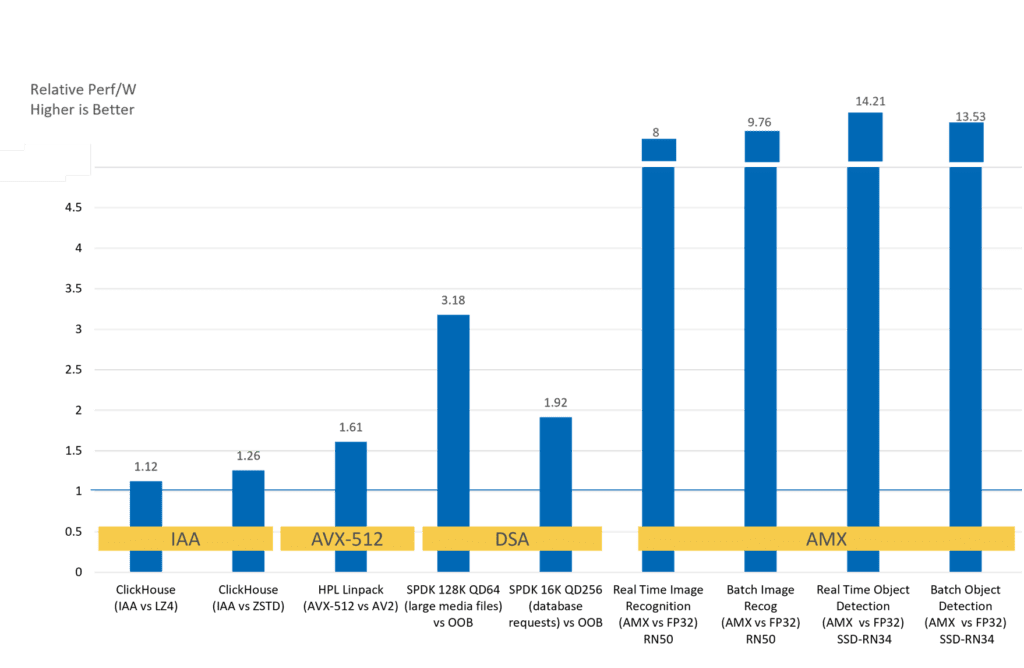
This performance leveraged the accelerators in the 4th Gen Intel Xeon processors such as the Intel® Advanced Matrix Extensions (Intel® AMX) and the Intel® Data Streaming Accelerator (Intel® DSA).
Intel AMX: Intel AMX delivers 3× to 10× higher inference and training performance versus the previous generation on AI workloads that use bint8 and bfloat16 matrix operations. [9] [10]
Intel DSA: Benchmarks for Intel DSA vary according to workload and operation performed. Speedups include faster AI training by having the DSA zero memory in the kernel, increased IOP/s/core by offloading CRC generation during storage operations, and of course, MPI speedups that include higher throughput for shmem data copies. For example, Intel quotes a 1.7× increase in IOP/s rate for large sequential packet reads when using DSA compared to using the Intel® Intelligent Storage Acceleration Library without DSA.[11]
Along with increased application performance, acceleration can also deliver dramatic power benefits. Maximizing performance for every watt of power consumed is a major concern at HPC and cloud data centers around the world. Comparing the relative performance per watt on a 4th Gen Intel Xeon processor running accelerated vs. nonaccelerated software shows a significant performance per watt benefit — especially for Intel AMX accelerated workloads.
Figure 7. Accelerator performance per watt benchmarks [12].
From big AI models to small, accelerators make the difference
Stephen Gillich (director AI and technical computing Intel) summarized the breadth of the Intel acceleration efforts “From big problems to small, Intel has optimized architectures for a full range of AI and HPC applications. HPC has high-precision requirements while AI is able to use lower-precision numerical representations such as bfloat16. Thus, different architectures and numerical resolution apply to a hierarchy of problems: Dedicated deep learning workloads can run on the Habana devices, while general-purpose GPUs and CPUs with accelerators speed general-purpose AI and HPC workloads.”
Summary
Advanced packaging and accelerators now empower hardware designers in ways that simply were not previously possible. These optimized designs are bringing about the 5th epoch in computing along with AI-enabled planet scale software services and a revolution in exascale-capable HPC simulation capabilities. They have also created a combinatorial software support problem. Programmers cannot anticipate — nor can they test and verify across — all heterogenous and accelerated computing environments in which their codes will run. The only solution out of this conundrum is to create a vendor-agnostic, free-to-all, flexible, open source, community software defined infrastructure such as the Intel oneAPI software ecosystem and the efforts to democratize AI.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology.
[1] Tim Mattson, senior principal engineer at Intel believes the sixth generation will start around 2025 with software defined ‘everything’ and be limited by the speed of light: https://www.youtube.com/watch?v=SdJ-d7m0z1I.
Intel® Xeon® 8380: Test by Intel as of 10/11/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:on; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=high;
Intel® Xeon® 8480+: Test by Intel as of 9/29/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Total Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:off; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=high;
Intel® Xeon® Max 9480: Test by Intel as of 9/29/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:off; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=high;
DeePMD (Multi-Instance Training)
Intel® Xeon® 8380: Test by Intel as of 10/20/2022. 1-node, 2x Intel® Xeon® 8380 processor, Total Memory 256 GB, kernel 4.18.0-372.26.1.eI8_6.crt1.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
3.9
Intel® Xeon® 8480+: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, Total Memory 512 GB, kernel 4.18.0-365.eI8_3x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
Intel® Xeon® Max 9480: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, Total Memory 128 GB (HBM2e at 3200 MHz), kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-13), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
Quantum Espresso (AUSURF112, Water_EXX)
Intel® Xeon® 8380: Test by Intel as of 9/30/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, Quantum Espresso 7.0, AUSURF112, Water_EXX
Intel® Xeon® 8480+: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), ucode revision= 0x90000c0, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, Quantum Espresso 7.0, AUSURF112, Water_EXX
Intel® Xeon® Max 9480: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Total Memory 128 GB (8x16GB HBM2 3200MT/s), ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, Quantum Espresso 7.0, AUSURF112, Water_EXX
ParSeNet (SplineNet)
Intel® Xeon® 8380: Test by Intel as of 10/18/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.6, Linux version 4.18.0-372.19.1.el8_6.crt1.x86_64, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
Intel® Xeon® 8480+: Test by Intel as of 10/18/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode revision=0xaa0000a0, CentOS Stream 8, Linux version 4.18.0-365.el8.x86_64, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
Intel® Xeon® Max 9480: Test by Intel as of 09/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Total Memory 128 GB (8x16GB HBM2 3200MT/s), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
CosmoFlow (training on 8192 image batches)
3rd Gen Intel® Xeon® Scalable Processor 8380 : Test by Intel as of 06/07/2022. 1-node, 2x Intel® Xeon® Scalable Processor 8380, 40 cores, HT On, Turbo On, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Red Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, Tensorflow 2.9.0, horovod 0.23.0, keras 2.6.0, oneCCL-2021.4, oneAPI MPI 2021.4.0, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® 8480+ (AVX-512 FP32): Test by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Xeon 8480+, HT On, Turbo On, Total Memory 512 GB (16 slots/ 32 GB/ 4800 MHz, DDR5), BIOS EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel 4.18.0-365.el8.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, Tensorflow 2.6.0, horovod 0.23, keras 2.6.0, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® Processor Max Series HBM (AVX-512 FP32): Test by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, Total Memory 128 HBM and 512 GB DDR (16 slots/ 32 GB/ 4800 MHz), BIOS SE5C7411.86B.8424.D03.2208100444, ucode 0x2c000020, CentOS Stream 8, kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, TensorFlow 2.6.0, horovod 0.23.0, keras 2.6.0, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® 8480+ (AMX BF16): Test by Intel as of 10/18/2022. 1node, 2x Intel® Xeon® Platinum 8480+, HT On, Turbo On, Total Memory 512 GB (16 slots/ 32 GB/ 4800 MHz, DDR5), BIOS EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel 4.18.0-365.el8.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AMX, BF16, Tensorflow 2.9.1, horovod 0.24.3, keras 2.9.0.dev2022021708, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
Intel® Xeon® Max 9480 (AMX BF16): Test by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, Total Memory 128 HBM and 512 GB DDR (16 slots/ 32 GB/ 4800 MHz), BIOS SE5C7411.86B.8424.D03.2208100444, ucode 0x2c000020, CentOS Stream 8, kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AMX, BF16, TensorFlow 2.9.1, horovod 0.24.0, keras 2.9.0.dev2022021708, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.9
DeepCAM
Intel® Xeon® Scalable Processor 8380: Test by Intel as of 04/07/2022. 1-node, 2x Intel® Xeon® 8380 processor, HT On, Turbo Off, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Red Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-4), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
Intel® Xeon® Max 9480 (Cache Mode) AVX-512: Test by Intel as of 05/25/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On,Turbo Off, Total Memory 128GB HBM and 1TB (16 slots/ 64 GB/ 4800 MHz, DDR5), Cluster Mode: SNC4, BIOS EGSDCRB1.86B.0080.D05.2205081330, ucode 0x8f000320, OS CentOS Stream 8, kernel 5.18.0-0523.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10, https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, AVX-512, FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
Intel® Xeon® Max 9480 (Cache Mode) BF16/AMX: Test by Intel as of 05/25/2022. 1-node, 2x Intel® Xeon® Max 9480 , HT On, Turbo Off, Total Memory 128GB HBM and 1TB (16 slots/ 64 GB/ 4800 MHz, DDR5), Cluster Mode: SNC4, BIOS EGSDCRB1.86B.0080.D05.2205081330, ucode 0x8f000320, OS CentOS Stream 8, kernel 5.18.0-0523.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, AVX-512 FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512, AMX, BFloat16 Enabled), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
Intel® Xeon® 8480+s Mulit-Node cluster: Test by Intel as of 04/09/2022. 16-nodes Cluster, 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 256 GB (16 slots/ 16 GB/ 4800 MHz, DDR5), BIOS Intel SE5C6301.86B.6712.D23.2111241351, ucode 0x8d000360, OS Red Hat Enterprise Linux 8.4 (Ootpa), kernel 4.18.0-305.el8.x86_64, compiler gcc (GCC) 8.4.1 20200928 (Red Hat 8.4.1-1), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98 AVX-512, FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=4, LBS=16, ~1024GB data, 16 epochs, Python3.8
WRF4.4 – CONUS-2.5km
Intel Xeon 8360Y: Test by Intel as of 2/9/23, 2x Intel Xeon 8360Y, HT On, Turbo On, NUMA configuration SNC2, 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, WRF v4.4 built with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags ”-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Fabric
Intel Xeon 8480+: Test by Intel as of 2/9/23, 2x Intel Xeon 8480+, HT On, Turbo On, NUMA configuration SNC4, 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, WRF v4.4 built with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Fabric
Intel Xeon Max 9480: Test by Intel as of 2/9/23, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, 128 GB HBM2e at 3200 MHz and 512 GB DDR5-4800, BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, WRF v4.4 built with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Fabric
Intel® Xeon® 8380: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, ROMS V4 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=high -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
Intel® Xeon® 8480+: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, NUMA configuration SNC4, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, ROMS V4 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=high -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
Intel® Xeon® Max 9480: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, ROMS V4 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=high -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
NEMO (GYRE_PISCES_25, BENCH ORCA-1)
Intel® Xeon® 8380: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, NEMO v4.2 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags ”-i4 -r8 -O3 -fno-alias -march=core-avx2 -fp-model fast=2 -no-prec-div -no-prec-sqrt -align array64byte -fimf-use-svml=true”
Intel® Xeon® Max 9480: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, NEMO v4.2 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-i4 -r8 -O3 -fno-alias -march=core-avx2 -fp-model fast=2 -no-prec-div -no-prec-sqrt -align array64byte -fimf-use-svml=true”.
Ansys Fluent
Intel Xeon 8380: Test by Intel as of 08/24/2022, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Hemisphere, 256 GB DDR4-3200, BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode 0xd000375, Rocky Linux 8.7, kernel version 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1 . HDR Fabric
Intel Xeon 8480+: Test by Intel as of 2/11/2023, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4 Mode, 512 GB DDR5-4800, BIOS Version SE5C7411.86B.8901.D03.2210131232, ucode 0x2b0000a1, Rocky Linux 8.7, kernel version 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1. HDR Fabric
Intel Xeon Max 9480: Test by Intel as of 02/15/2023, 2x Intel Xeon Max 9480, HT ON, Turbo ON, SNC4, SNC4 and Fake Numa for Cache Mode runs, 128 GB HBM2e at 3200 MHz and 512 GB DDR5-4800, BIOS Version SE5C7411.86B.9409.D04.2212261349, ucode 0xac000100, Rocky Linux 8.7, kernel version 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1. HDR Fabric
Ansys LS-DYNA (ODB-10M)
Intel® Xeon® 8380: Test by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s DDR4), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LS-DYNA R11
Intel® Xeon® 8480+: Test by Intel as of ww41’22. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Total Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, LS-DYNA R11
Intel® Xeon® Max 9480: Test by Intel as of ww36’22. 1-node, 2x Intel® Xeon® Max 9480, HT
Intel® Xeon® 8380: Test by Intel as of 08/24/2022. 1-node, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Quad, Total Memory 256 GB, BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Mechanical 2022 R2
AMD EPYC 7763: Test by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7763, HT On, Turbo On, NPS2,Total Memory 512 GB, BIOS ver. Ver 2.1 Rev 5.22, ucode 0xa001144, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Mechanical 2022 R2
AMD EPYC 7773X: Test by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7773X, HT On, Turbo On, NPS4,Total Memory 512 GB, BIOS ver. M10, ucode 0xa001229, CentOS Stream 8, kernel version 4.18.0-383.el8.x86_6, Ansys Mechanical 2022 R2
Intel® Xeon® 8480+: Test by Intel as of 09/02/2022. 1-node, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4, Total Memory 512 GB DDR5 4800 MT/s, BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel version 4.18.0-365.el8.x86_64, Ansys Mechanical 2022 R2
Intel® Xeon® Max 9480: Test by Intel as of 08/31/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo ON, SNC4, Total Memory 512 GB DDR5 4800 MT/s, 128 GB HBM in Cache Mode (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode 2c000020, CentOS Stream 8, kernel version 5.19.0-rc6.0712.intel_next.1.x86_64+server, Ansys Mechanical 2022 R2
Altair AcuSolve (HQ Model)
Intel® Xeon® 8380: Test by Intel as of 09/28/2022. 1-node, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Quad, Total Memory 256 GB, BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Altair AcuSolve 2021R2
Intel® Xeon® 6346: Test by Intel as of 10/08/2022. 4-nodes connected via HDR-200, 2x Intel® Xeon® 6346, 16 cores, HT ON, Turbo ON, Quad, Total Memory 256 GB, BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Altair AcuSolve 2021R2
Intel® Xeon® 8480+: Test by Intel as of 09/28/2022. 1-node, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4, Total Memory 512 GB, BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel version 4.18.0-365.el8.x86_64, Altair AcuSove 2021R2
Intel® Xeon® Max 9480: Test by Intel as of 10/03/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode 2c000020, CentOS Stream 8, kernel version 5.19.0-rc6.0712.intel_next.1.x86_64+server, Altair AcuSolve 2021R2
OpenFOAM (Geomean of Motorbike 20M, Motorbike 42M)
Intel® Xeon® 8380: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.6, Linux version 4.18.0-372.19.1.el8_6.crt1.x86_64, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
Intel® Xeon® 8480+: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode revision=0xaa0000a0, CentOS Stream 8, Linux version 4.18.0-365.el8.x86_64, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
Intel® Xeon® Max 9480: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Total Memory 128 GB (8x16GB HBM2 3200MT/s), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
MPAS-A (MPAS-A V7.3 60-km dynamical core)
Intel® Xeon® 8380: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, MPAS-A V7.3 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
Intel® Xeon® 8480+: Test by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, NUMA configuration SNC4, Total Memory 512 GB (16x32GB 4800MT/s, Dual-Rank), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, MPAS-A V7.3 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
Intel® Xeon® Max 9480: Test by Intel as of 10/12/22. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, MPAS-A V7.3 build with Intel® Fortran Compiler Classic and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
Intel® Xeon® 8380: Test by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, Converge GROMACS v2021.4_SP
Intel® Xeon® 8480+: Test by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Total Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Version SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux version 4.18.0-372.26.1.el8_6.crt1.x86_64, GROMACS v2021.4_SP
Intel® Xeon® Max 9480: Test by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux version 5.19.0-rc6.0712.intel_next.1.x86_64+server, GROMACS v2021.4_SP
[4] SIGCOMM keynote, Amin Vadhat, 5th Epoch of Distributed Computing.
[5] SIGCOMM keynote, Amin Vadhat, 5th Epoch of Distributed Computing.
Cloud technology has garnered the attention of organizations globally. Due to the ease of scalability, flexibility, global footprint, and cost efficiency, more organizations are increasingly turning to hybrid and multi-cloud to expand their operations. Moreover, it is not just the systems and resources that are increasing beyond borders but also the data these systems and applications generate. In fact, data itself generates more data.
In the age where cyber threats are rampant, it’s more crucial than ever for businesses to address the security concerns present in the cloud environment. The critical need to protect the cloud infrastructure and the data has led organizations to consider two security solutions: Cloud Security Posture Management (CSPM) & Data Security Posture Management (DSPM). This blog will discuss the primary differences between these two solutions highlighting their distinct approach to cloud security.
What is CSPM & how does it work?
Cloud Security Posture Management is also known as CSPM in the cloud security community. Gartner defines CSPM as “Cloud Security Posture Management (CSPM) consists of offerings that continuously manage IaaS and PaaS security posture through prevention, detection, and response to cloud infrastructure risks.”
To understand the concept of CSPM better, let’s take the example of an autonomous vehicle. An autonomous vehicle has many integrated features to ensure safe driving. For instance, the vehicle may have radar, an integrated GPS, Light Detection and Ranging, and multiple cameras. All these components enable the self-driving vehicle to assess road conditions, the weather, passersby, and other objects. This ensures that the car remains on track, it doesn’t collide with any object, and the brakes trigger near the red light to prevent a crash.
Similarly, CSPM is a solution that scans a cloud infrastructure, including but not limited to compute instances, workloads, datastores, and networks for misconfigurations, such as open ports, publicly accessible datastores, etc. The solution looks for misconfigurations based on a set of industry-standard security policies, such as NIST, CIS, PCI DSS, etc. Upon the identification of misconfigurations across cloud infrastructure, it helps cloud security teams resolve these issues either manually or via automation. All in all, CSPM protects the infrastructure against security threats like unauthorized access, etc.
What are the key capabilities of CSPM?
CSPM solutions are based on various capabilities that enable teams to identify and resolve vulnerabilities in the cloud. However, there are some capabilities that remain the same across different solutions or offerings, such as:
CSPM solutions leverage various native connectors or APIs to integrate with a wide range of cloud systems and resources to discover misconfigurations.
Another important component of a CSPM solution is configuration settings that are aligned to industry best practices and standards, including but not limited to the NIST framework, CIS, PCI DSS standard, GDPR, etc. These standards help security teams identify and resolve any security risks, non-compliant settings, and other misconfigurations.
CSPM solutions enable continuous monitoring of the cloud infrastructure. With real-time monitoring, CSPM delivers prompt alerts if a misconfiguration is detected and offers immediate remediation.
It is also important to note that CSPM treats all data systems equally since it lacks intelligence or insights into sensitive data. Hence, it increases the chances of false positive alerts, which ultimately leads to alert fatigue.
What is DSPM & how does it work?
Data Security Posture Management is usually referred to as DSPM, and it is a relatively new term. Gartner defines DSPM as “Data security posture management (DSPM) provides visibility as to where sensitive data is, who has access to that data, how it has been used, and what the security posture of the data stored or application is.”
Let’s take the example of a castle to understand more about DSPM. A castle may have large towers, strong gates, and other infrastructure protection mechanisms. However, if it has no protective mechanisms around the treasure inside the castle, then once a breach occurs from any vulnerable place like an unguarded secret tunnel, the invading army will most likely seize the treasure. Hence, it is important to place protective measures like hidden traps, iron bars, and well-concealed places to hide and safeguard the treasure.
Here, the castle’s outer protective measures resemble CSPM, while the measures around the treasure resemble DSPM. In other words, DSPM is a data-oriented approach to cloud security. DSPM gathers various insights around data to better protect it, such as its existing security controls, potential security gaps or risks, compliance requirements, and access controls policy. These potential data insights help organizations optimize data protection policies and implement effective controls.
What are the key capabilities of DSPM?
DSPM solutions may offer wide-ranging features and functionalities, but every solution’s core capabilities remain the same. Here are some of the core capabilities of DSPM:
DSPM solution’s first core capability is detecting and cataloging data assets. It can discover data assets across numerous systems and different types of assets, including shadow and cloud-native data assets.
DSPM solutions also offer highly efficient and accurate data discovery and classification capabilities. It can classify and categorize data down to its granular attributes, context, and metadata.
DSPM also offers data lineage capabilities, providing insights into data transformation across its lifecycle. This ultimately helps with improving data governance strategies.
DSPM also provides comprehensive visibility of sensitive data access. This helps access governance teams optimize access controls’ policies.
DSPM also helps map data to various compliance requirements, such as GDPR, CPRA, etc.
What are the most common differences between DSPM and CSPM?
From the above explanations of DSPM and CSPM, we can conclude that the technologies have the following differences.
CSPM mainly focuses on protecting cloud infrastructure, while DSPM focuses on protecting data.
CSPM identifies and resolves cloud misconfiguration settings like open ports, publicly exposed data stores, etc. Whereas, DSPM identifies and resolves security risks, such as unauthorized access, non-compliance, and data privacy risks.
CSPM can identify misconfiguration across IaaS and PaaS, while DSPM can discover data and associated risks across public clouds only.
CSPM focuses on the security of multi-cloud infrastructure, such as identity and access management, network security, & configuration management. On the other end, DSPM uses context-aware strategies to provide visibility and security to the data hosted on the cloud.
Final thoughts
Cloud security posture management and data security posture management are two distinct yet crucial components of cloud security. However, as data security professionals, we cannot ditch one for the other. In fact, it is important to leverage CSPM in tandem with DSPM for a holistic cloud security approach.
As Web3 evolves and transforms into a more decentralized and user-centric ecosystem, the role of artificial intelligence or AI cannot be understated. By leveraging its capabilities, AI is contributing to various aspects of the Web3 landscape, such as managing data, executing contracts, generating insights, securing identities, curating content, governing organizations, and enhancing user experiences. An in-depth analysis of the key areas in which AI’s integration empowers Web3, including intelligent automation, personalization, data-driven insight, and distributed decision-making, is presented in this article. Through the use of artificial intelligence, Web3 seeks to create a more inclusive, transparent, and user-controlled Internet, revolutionizing the way people engage and interact with one another online. Let’s learn how AI in Web3 ensures effective content moderation for dating websites.
Web3 is what it sounds like.
A web ecosystem based on decentralization and user-centricity is referred to as Web3. Although Web2 is characterized by centralized platforms, Web3 aims to empower individuals, groups, companies, and organizations by providing them with greater control over their data, content moderation, identity and online interactions. Through the implementation of decentralized technologies such as blockchain, smart contracts, and peer-to-peer networking, it seeks to create a more transparent, open, and peer-to-peer internet. Thus, creating a safe environment with seamless content moderation for dating websites.
A number of key concepts and technologies are introduced in Web3:
Decentralization: A major goal of Web3 is to eliminate dependence upon central authorities by utilizing decentralized technologies, such as blockchain. A network of computers stores and controls data instead of a single entity, enhancing transparency and reducing the likelihood of censorship.
Self-sovereign identity: As a result of Web3, users will be able to establish their own self-sovereign identities. By doing so, individuals are able to control and own their personal information, sharing it selectively with trustworthy third parties without relying on centralized identity providers.
Smart contracts: A smart contract is a self-executing agreement that follows predefined rules and conditions. Web3 utilizes smart contracts to achieve this. It is possible to deploy smart contracts on decentralized platforms such as Ethereum and eliminate the need for intermediaries in trustless and automated transactions.
Cryptocurrencies and tokens: The use of cryptocurrencies and tokens in Web3 facilitates value exchange and motivates the participation of participants in decentralized networks. There are many types of assets within the Web3 ecosystem, including ownership rights, utility, and governance assets.
Decentralized applications (dApps): As part of Web3, decentralized applications (dApps) are encouraged to be developed which operate on distributed networks. Smart contracts are often leveraged by these dApps in order to provide services and utilities that are more transparent, resistant to censorship, and provide users with greater control.
Interoperability: Among the primary features of Web3 is its emphasis on interoperability between different decentralized systems and protocols. The decentralized web is enabled by seamless interaction between different platforms and the sharing of data between them, thus creating a richer experience for users.
As part of Web3, we envision a world in which the empowerment of users, content moderation, data ownership, privacy, and security are prioritized. As part of this initiative, centralized models are disrupted, innovation is encouraged, and individuals are given greater control over their online experiences. Making content moderation for dating website’s all the more efficient.
In Web3, AI contributes to the following areas:
Decentralized data marketplaces:
Using AI, decentralized data marketplaces can be created, providing individuals with greater control over their data. As a result of using artificial intelligence algorithms, users are able to selectively share and monetize their data while maintaining privacy and security. It is possible to analyze and categorize data with the help of artificial intelligence, optimize data matching between buyers and sellers, and facilitate efficient and trusted data transactions with the help of AI.
Autonomous agents and smart contracts:
By providing autonomous agents with real-time data and predefined rules, artificial intelligence enhances the capabilities of smart contracts in Web3 platforms. These intelligent agents are capable of negotiating, executing transactions, optimizing resource allocation, and providing personalized services. By automating complex processes, reducing intermediaries, and fostering trust and transparency, AI-powered smart contracts improve Web3 ecosystems.
Analytics and insights based on predictive models:
The use of artificial intelligence techniques, such as machine learning and natural language processing, is capable of processing and analyzing vast amounts of data generated within Web3 networks. With AI, Web3 users can gain access to predictive analytics, market trends, and market trends by analyzing market trends, determining sentiments, and providing personalized recommendations. Data-driven insights enable users to gain a deeper understanding of the decentralized landscape and navigate it more effectively.
System for identifying and reputating individuals:
Providing decentralized and self-governing identity solutions is one of the objectives of Web3. Through the analysis of user behavior, the verification of credentials, and the assessment of trustworthiness, artificial intelligence plays a pivotal role in building robust identity and reputation systems. In order to ensure secure interactions and foster a sense of trust among participants, the Web3 ecosystem is equipped with artificial intelligence algorithms.
Curating and personalizing content:
Using artificial intelligence, decentralized content platforms can filter, curate, and recommend relevant content to users according to their preferences, behavior, and network interactions. The AI-driven content curation process will enhance the user experience, increase engagement, and facilitate the discovery of valuable content within the vast and decentralized Web3 network.
Organizations with autonomous governance:
Within Web3, AI plays an important role in the development of autonomous organizations (DAOs). Using AI algorithms, DAOs are able to make decisions, allocate resources, and manage governance processes. AI-powered DAOs improve Web3 governance models’ efficiency, transparency, and inclusivity by automating voting mechanisms, managing funds, and optimizing operations.
User experience enhancements:
Web3 applications leverage technologies such as natural language processing, computer vision, and voice recognition to enhance the user experience. By using chatbots, virtual assistants, and AI-driven interfaces, complex processes can be simplified, and Web3 technologies are being adopted more widely by users.
As a result of the Web3 ecosystem being powered by AI, a decentralized and user-centric internet is being envisioned. Through the integration of these two technologies, automated processes can be carried out intelligently, data-driven insights can be gained, and personalized experiences can be provided as a result of its integration. By combining artificial intelligence with decentralized technology, it is anticipated that the digital landscape will become more inclusive, transparent, and user-controlled, enabling people to interact and collaborate with one another more easily and efficiently. This technology will continue to contribute to the development of a more inclusive, transparent, and user-controlled digital landscape. Thus making dating websites safer with effective and continuous content moderation.
Within the context of Web3, artificial intelligence plays a fundamental role in content moderation of dating websites. Using AI in this context can improve content moderation as follows:
Detection and filtering by automated systems:
As a result of AI-driven algorithms, user-generated content, such as profile descriptions, images, and messages, can be filtered and detected to avoid inappropriate or abusive content from being published. It is possible to use machine learning models in order to identify patterns, keywords, or explicit content on the web, so as to flag or remove the material from the web before other users have the opportunity to view it.
Identifying and analyzing images and videos:
Users can upload images and videos and AI algorithms can analyze them. In this way, explicit or inappropriate visual content can be detected and prevented from being shared. As well, artificial intelligence is capable of detecting fake or manipulated images in order to prevent catfishing and misrepresenting profiles.
Sentiment analysis and language processing:
Text in user profiles and messages can be analyzed using natural language processing (NLP) algorithms in order to determine whether the language is offensive, harassing, or inappropriate. As well as providing insight into a message’s tone and intent, sentiment analysis techniques can also be utilized to flag messages that may violate community guidelines or harm other users.
Analyzing the behavior of users:
The use of artificial intelligence can be used to identify suspicious or malicious activity by analyzing user behavior patterns. As an example, the system can flag or limit the access of users who engage in spamming behavior or consistently exhibit negative interactions.
Chat sessions are moderated in real-time by the following moderators:
Using artificial intelligence in a chatbot or a system that moderates real-time conversations is an effective method of monitoring and analyzing ongoing discussions between users. When potentially harmful or inappropriate content is detected, these systems are capable of detecting and intervening in real-time to provide immediate feedback or warnings to users involved.
Providing feedback and reporting to the community:
Users can report inappropriate or offensive behavior using AI to facilitate community-driven content moderation. In order to prioritize and review flagged content more efficiently, AI algorithms can be used to process these reports.
Learning and adapting on a continuous basis:
Incorporating user feedback, interactions, and community moderation efforts into AI models can continuously improve their accuracy over time. In order to improve the effectiveness of content moderation, user feedback and human oversight can be used to refine the AI system’s algorithms and guidelines.
Final thoughts
The use of artificial intelligence in content moderation for dating websites can contribute greatly. In order to ensure the smooth moderation of content on dating sites, artificial intelligence (AI) must be integrated into the Web3 ecosystem. The use of artificial intelligence algorithms and techniques for content moderation includes automatically detecting abusive or inappropriate content, identifying and analyzing images, videos, sentiment analysis, behavior analysis, facilitating chat sessions, analyzing feedback, and adapting constantly.
It is possible to analyze user-generated content, identify explicit or inappropriate visual content, and assess sentiment and intent for text content. The AI algorithm also assists in community-driven content moderation by detecting suspicious or malicious user behavior and providing advice and warnings in real-time. AI learns and adapts through user feedback.
AI content moderation is integrated into Web3’s ecosystem to provide more secure dating websites. Decentralized technology combined with AI-driven content moderation provides a more transparent, more trustworthy, and more enjoyable internet.
In the movie the Lord of the Rings – the wizard Sauron says that “The hour is later than you think”
I was reminded of this phrase when I read a report from McKinsey The economic potential of generative A
There are some key findings on the future of AI which shows you how fast the world is changing
Current generative AI and other technologies have the potential to automate work activities that absorb 60 to 70 percent of employees’ time today. In contrast, we previously estimated that technology has the potential to automate half of the time employees spend working
The acceleration in the potential for technical automation is largely due to generative AI’s increased ability to understand natural language, which is required for work activities that account for 25 percent of total work time. Thus, generative AI has more impact on knowledge work associated with occupations that have higher wages and educational requirements than on other types of work.
The pace of workforce transformation is likely to accelerate, given increases in the potential for technical automation Our updated adoption scenarios, including technology development, economic feasibility, and diffusion timelines, lead to estimates that half of today’s work activities could be automated between 2030 and 2060, with a midpoint in 2045, or roughly a decade earlier than in our previous estimates.
This shift will have a major impact on economies.
Generative AI could add the equivalent of $2.6 trillion to $4.4 trillion annually based on the use cases the study considered. In comparison, the United Kingdom’s entire GDP in 2021 was $3.1 trillion.This is like adding an entire UK to the overall global economy.
About 75 percent of the value that generative AI use cases could deliver falls across four areas: Customer operations, marketing and sales, software engineering, and R&D.
Examples of AI impact would include generative AI’s ability to support interactions with customers, generate creative content for marketing and sales, and write code.
Generative AI will have a significant impact across all industry sectors. Banking, high tech, and life sciences are among the industries that could see the biggest impact as a percentage of their revenues from generative AI. Across the banking industry,
Generative AI has the potential to change the anatomy of work, augmenting the capabilities of individual workers by automating some of their individual activities.
So, if the pace of change is accelerated in the sense that
Current generative AI and other technologies have the potential to automate work activities that absorb 60 to 70 percent of employees’ time today.
Half of today’s work activities could be automated between 2030 and 2060, with a midpoint in 2045
That’s what we mean by the hour is later than you think!
But what does it mean for you?
Here are some implications:
Redefining Work: Collaboration between humans and AGI can reshape work dynamics. Humans can focus on tasks that require creativity, empathy, complex decision-making, and interpersonal skills, while AGI handles more routine and repetitive tasks. This collaboration can lead to the augmentation of human capabilities and the emergence of new job roles that combine human expertise with AGI support.
How could humans and AI collaborate in the world of artificial general intelligence? Here are some ideas: Human-in-the-Loop Systems, Decision Support and Augmentation by AGI, Enhanced creativity for humans through AGI, Training and Learning for both humans and AGI and Ethical and Value Alignment
But the most important skill could be problem formulation. Problem formulation is the process of clearly defining and understanding a problem or challenge in a way that allows for effective problem-solving. It involves breaking down a complex issue into its constituent parts, identifying the key factors, and clarifying the objectives and constraints. Problem formulation includes Critical thinking, metacognition and other skills. Problem formulation is a critical step that sets the foundation for finding appropriate solutions. Here are the key aspects of problem formulation:
Problem Definition
Objectives and Constraints
Scope and Boundaries
Stakeholder Analysis
Data and Information Gathering
Problem Decomposition
Problem Framing:
Effective problem formulation is essential because it guides the subsequent steps of problem-solving, such as generating solutions, evaluating alternatives, and implementing interventions. It helps ensure that the efforts and resources are directed towards addressing the root causes and achieving the desired outcomes.
I believe that this skill will be important because AI will need to know what problem to solve.
In any case, this future is closer than we all think!
Just a week after the ChatGPT Browse feature went live on the iOS app, OpenAI had to deactivate it due to displaying content "in ways we don't want," according to a tweet from the company that created the AI chatbot.
The feature enabled users to bypass paywalls to access subscription-based content without subscriptions. "If a user specifically asks for a URL's full text, it may inadvertently fulfill this request. We are disabling Browse while we fix this — want to do right by content owners," the company's tweet continued.
Also: Will AI take programming jobs or turn programmers into AI managers?
While Browse was enabled, users needed to be ChatGPT Plus members to become beta users, as it was only available under the GPT-4 model, and select the web browsing model, a Bing-based search engine.
Users quickly discovered the workaround mentioned above to bypass paywalls, where users gave ChatGPT links to different news sites and asked the AI chatbot to reply with only the text found in the URL.
Also: Harvard is using ChatGPT to teach computer science
ChatGPT, obedient as ever, returned with the text from the news article each time, even if it was behind a paywall.
OpenAI's tweet said the company wants to "do right by content owners," so it turned off browsing altogether.
Though it is unclear when the Bing-powered browsing feature will be back online, OpenAI's president and co-founder Greg Brockman tweeted that the team is working to bring back the browsing feature soon.
It's surprising that customer service is not a leader in the adoption of AI given the scale, volume, and deterministic nature of service transactions.
Artificial intelligence can play a crucial role in assisting leaders and their teams in making strategic, as well as immediate, data-driven decisions and taking effective action. AI has the potential to automate 40% of the average workday, but are companies ready to implement and operationalize the use of generative AI? More than 50% of sales and service teams don't know how to get the most value out of generative AI, according to a survey of more than 2,000 sales and service professionals. Salesforce research identified these key findings:
Also: 73% of consumers trust what generative AI wants us to see
Sales and service professionals identify customer experience as a clear benefit of generative AI.
61% of salespeople believe generative AI will help them better serve their customers.
63% of service professionals say the technology will help them serve their customers faster.
61% of salespeople believe generative AI will help them sell efficiently.
84% of salespeople using generative AI say it helps increase sales at their organization by enhancing and speeding up customer interactions.
Of service professionals currently using generative AI, 90% report it helps them serve their customers faster.
Customer-facing roles with the highest use of generative AI include basic content generation (82%), followed by analyzing market data (74%), automating sales communications (71%), and better automation of customer service communications (67%).
When asked about how generative AI can transform customer-facing roles, the respondents said the following:
Generate sales reporting (51%)
Basic content creation (48%)
Analyze market data (47%),
Improve customer self-service options (48%)
Sales and service adoption of generative AI solutions is low
Only 41% of employees are currently using or planning to use generative AI. Marketing is leading the adoption of generative AI with 51% either using or planning, followed by Sales at 35% and Service at 24%. It is surprising that customer service is not a leader in the adoption of AI given the scale, volume, and deterministic nature of service transactions. I anticipate that service adoption of generative AI will soar in the next two years.
Also: Ahead of AI, this other technology wave is sweeping in fast
"Generative AI will completely reshape the field of customer service, said Clara Shih, CEO of Salesforce AI. "We'll have the ability to automatically generate personalized responses for agents to quickly email or message to customers, freeing human agents to spend more time deeply engaging on complex issues and building long-term customer relationships."
Clara Shih, newly named CEO of Salesforce AI
The biggest impediment to the adoption of generative AI is the skills gap and fear of automation.
The survey found that most sales and service professionals do not know how to get the most value out of generative AI at work (Sales at 53% and Service at 60%). Adding to this skills gap is the fear of job losses with 48% of service and 39% of sales professionals worrying that they will lose their jobs if they don't learn how to use generative AI at work.
Customer-facing professionals do not trust generative AI
The lack of training is certainly one effective way to reduce the trust gap that exists with use of generative AI. The survey found that 63% of employees expect generative AI learning opportunities from their employers. And 67% say their employer does not provide generative AI training. Both sales and service professionals agree that a trust gap exists in business with respect to the adoption of generative AI.
Also: The best AI chatbots: ChatGPT and other noteworthy alternatives
56% say human oversight is critical in successfully using generative AI in their role.
55% say enhanced security measures are critical in successfully using generative AI in their role.
The most important benefit of generative AI is the opportunity for sales, service, marketing, and commerce professionals to transform their companies to become customer companies. Businesses must invest in training their employees on the use and benefits of generative AI. With trusted customer data, pre-built, custom, or public AI models that can power automation and smart workflows, a single platform with security and governance built-in to enable both innovations and increased customer trust, and proper staff training, generative AI can empower organizations to deliver powerful customer experiences while driving efficiency.
Also: These are my 5 favorite AI tools for work
From marketing and sales to customer service and digital commerce, generative AI will transform the customer experience at every touchpoint.