Voice changing software is a type of AI application that allows users to modify their voice in real-time or alter pre-recorded audio. These software solutions provide different effects, such as changing the pitch or speed of the voice, or transforming the user's voice to sound like someone or something else, such as a famous celebrity, cartoon character, robot, or different genders and ages.
These tools are widely used in different industries and applications, such as video gaming (where players may wish to mask their identity or role-play different characters), multimedia production, telecommunication, podcasts, and many other areas where voice manipulation can enhance the user experience or support creative processes.
There are many voice changing software available on the market, each offering a unique set of features and capabilities.
1. Hitpaw Voice Changer
This easy to use AI tool is considered to be one of the best applications for Gamers, Streamers, YouTubers, and Meetings. Gamers enjoy it because it enables you to easily sound like a favorite character in a video game, entrepreneurs enjoy it because it can make them sound authoritative.
Unleash your creativity, change voices with endless possibilities. Be a robot, demon, chipmunk, woman, man, ghostface, or anime actor, HitPaw Voice Changer offers a huge number of voice-changing effects to meet your needs and give you more options to act like the character you want.
- Change your voice with various voice-changing effect in real-time
- Integrate perfectly with all popular games and programs
- Perfect voice modifier for gameplay, content creator, Vtuber, or live streamer
- Remove noise and echo while changing voices
- Change voice effortlessly with high quality
2. Murf
One of the most popular and impressive AI voice changers on the market is Murf, which enables anyone to convert text to speech, voice-overs, and dictation. It is especially useful for product developers, podcasters, educators, and those in the business world.
Murf creates natural voices in a very short amount of time and with minimal effort needed. They can then be used in nearly any sector. With a library consisting of over 110 voices in 15 different languages, Murf has a wide range of uses.
Here are some of the main features of Murf:
- Large library of voices and languages
- Expressive emotional speaking styles
- Pitch and fine-tune voice tones
- Audio and text input support
3. Synthesys
Synthesis is one of the most popular and powerful AI voice changers and generators, it enables anyone to produce a professional AI voiceover or AI video in a few clicks.
This platform is on the leading edge of developing algorithms for text to voiceover and videos for commercial use. Imagine being able to enhance your website explainer videos or product tutorials in a matter of minutes with the aid of a natural human voice. Synthesys Text-to-Speech (TTS) and Synthesys Text-to-Video (TTV) technology transform your script into vibrant and dynamic media presentations.
A myriad of features is offered including:
- Choose from a large library of professional voices: 34 Female, 35 Male
- Create and sell unlimited voiceovers for any purpose
- Extremely lifelike voices unlike competing platforms
- The choice of emphasizing specific words to be able to express a range of emotions like happiness, excitement, sadness, etc.
- Add pauses when the user wants to give the voiceovers an even more human feel.
- Preview mode to see results quickly and apply changes without losing time rendering.
- Use for sales videos, letters, animations, explainers, social media, TV commercials, podcasts, and more.
4. Voice Over by Speechify
Speechify can turn text in any format into natural-sounding speech. Based on the web, the platform can take PDFs, emails, docs, or articles and turn it into audio that can be listened to instead of read. The tool also enables you to adjust the reading speed, and it has over 200 natural-sounding voices to select from.
The software is intelligent and can identify more than 15 different languages when processing text, and it can seamlessly convert scanned printed text into clearly audible audio.
Here are some of the top features of Speechify:
- Web-based with Chrome and Safari extensions
- Over 200+ high-quality voices voices to select from
- 20+ languages & accents
- Granular controls on the pitch, tone and speed
- Commercial usage rights
- Custom soundtracks
30% discount code: SPEECHIFYPARTNER30
5. Altered
Altered Studio is a next-generation audio editor that integrates multiple voice AI technologies into a single user friendly application. It runs online as well as locally on Windows and Mac using local computing resources.
The Voice AI tools can help you with your dubbing workflow. Transcribe, voice over, text-to-speech and Translations.
Altered Studio provides a unique speech-to-speech, performance-to-performance Speech Synthesis technology that pushes the boundaries of what can be done.
One option of the unique technology allows you to modify your voice to a custom voice. You can also transcribe, add voice-over with text-to-Speech and translate audio files.
Main features include:
- Create a specific voice. It might be the voice of a famous actor, a captivating voice-talent, a friend or a grandparent.
- Use life-like Text-To-Speech to add Voice-Over to your content in 70+ languages.
- From personal audio notes to long meetings conversations, quick and accurate transcription is just one click away.
- Google Drive integration, easily work from anywhere and easily share files.
- Voice Editor can record directly from the browser through the microphone or any other recording device.
- Import and export your files in many different formats, lossless and raw.
- Spectrogram and spectrum visualisation are one click away, for detailed frequency analysis.
6. Lovo.ai
Lovo.ai is an award-winning AI-based voice generator and text-to-speech platform that also be used as a voice changer. It is one of the most robust and easiest platform to use that produces voices that resemble the real human voice.
Lovo.ai has provided a wide range of voices, servicing several industries, including entertainment, banking, education, gaming, documentary, news, etc., by continuously refining its voice synthesis models. Because of this, Lovo.ai has garnered a lot of interest from esteemed organizations on a global scale, making them stand out as innovators in the voice synthesis sector.
LOVO has recently launched Genny, a next-gen AI voice generator equipped with text-to-speech and video editing capabilities. It can produce human-like voices with stunning quality and content creators can simultaneously edit their video.
Genny lets you choose from over 500 AI voices in 20+ emotions and 150+ languages. Voices are professional grade voices that sound human-like and realistic. You can use the pronunciation editor, emphasis, speed and pitch control to perfect your speech and customize how you want it to sound.
Features:
- World's largest library of voices of over 500+ AI voices
- Granular control for professional producers using pronunciation editor, emphasis, and pitch control.
- Video editing capabilities that allow you to edit videos simultaneously while generating voiceovers.
- Resource database of non-verbal interjections, sound effects, royalty free music, stock photos and videos
With 150+ languages available, content can be localized with the click of a button.
7. Listnr
Another top listing for voice changers, is Listnr, an AI text-to-speech voice generator tool that converts text-to-speech in various formats, such as genre selection, pauses, accent selection, and more. One of the best features of Listnr is that it enables you to get your own customizable audio player embed, which can be embedded into your blog as an audio version.
Listnr is personalized to each individual listener's routine and preferences. It is also a great tool for creating, managing, and publishing podcasts. Whether you are a commercial or freelance podcaster, Listnr can help you monetize your content through advertising. You can use the AI voice generator tool to distribute and convert audio with commercial broadcasting rights on the world's biggest platforms like Spotify, Apple, and Google Podcasts. When it comes to podcasting, Listnr supports more than 17 languages, and the AI technology can convert blog posts into several different languages and dialects.
Listnr also helps you improve conversation rates by enabling the option to read-listen and watch-listen for users.
Here are some of the main features of Listnr:
- Embed customizable audio player
- Personalized to each listener
- Improves conversion rates
- AI voice-overs for YouTube, blog posts, and audiobooks
- Audio analytics
8. Play.ht
A powerful AI text-to-speech generator, Play.ht relies on AI to generate audio and voices from IBM, Microsoft, Amazon, and Google. The tool is especially useful for converting text into natural voices, and it allows you to download the voice-over as MP3 and WAV files.
With Play.ht, you can choose a voice type and either import and type text, which the tool will instantly convert into a natural human voice. The audio can then be enhanced with SSML tags, speech styles, and pronunciations.
Play.ht is used by major brands like Verizon and Comcast.
Here are some of the main features of Play.ht:
- Convert blog posts to audio
- Integrate real-time voice synthesis
- Over 570 accents and voices
- Realistic voice-overs for podcasts, videos, e-learning, and more
9. Deepbrain AI
The Deepbrain AI tool offers the ability to easily create AI-generated videos using basic text instantly quickly and easily. Simply prepare your script and use the Text-to-Speech feature to receive your first AI video in 5 minutes or less.
There are 3 quick steps to get started they are as following:
- First, create a new project. You can start with your own PPT template or choose one of the starter templates.
- You can manually type in or copy and paste your script. Contents of your uploaded PPT will be entered in automatically.
- Once you select the appropriate language and AI model and finish editing, you can export the synthesized video.
This tool offers the following benefits:
- Easy find a custom-made AI avatar that best fits your brand.
- The Intuitive tool is designed to be super easy to use for beginners.
- Offers significant time savings in video preparation, filming, and editing.
- Cost-saving in the entire video production process.
10. Sonantic
Sonantic has risen in popularity since it was used to help actor Val Kilmer reclaim his voice with a synthetic voice replica. The easy-to-use AI tool is popular in the entertainment industry since it enables lively voice expressions.
The tool allows you to change the tone of the speech generated, with tones like happy, sad, or angry. You can also customize the level of emotion through adjustments, and it works by simply copying and pasting a written text into the editor before waiting for it to be converted to audio.
These reasons are why Sonantic has been used for animations, films, and games.
Here are some of the top features of Sonantic:
- Human-like voice generator
- Emotion adjustments
- Voice parameters
- Voice projects like Shouts or Fear



 Anthropic has also increased the length of Claude’s input and output. Users can now input up to 100,000 tokens in each prompt, which adds up to hundreds of pages, the company claims. Claude can now write longer responses up to a few thousand tokens, as well.
Anthropic has also increased the length of Claude’s input and output. Users can now input up to 100,000 tokens in each prompt, which adds up to hundreds of pages, the company claims. Claude can now write longer responses up to a few thousand tokens, as well. Whether or not GPT-4 is actually “dumber,” OpenAI is also in the news this week due to a new investigation opened by the Federal Trade Commission.
Whether or not GPT-4 is actually “dumber,” OpenAI is also in the news this week due to a new investigation opened by the Federal Trade Commission.






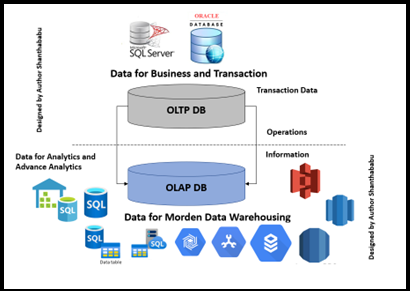
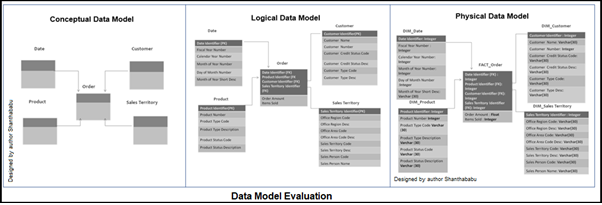
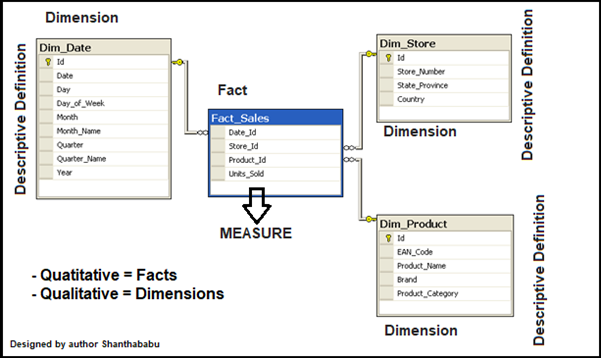

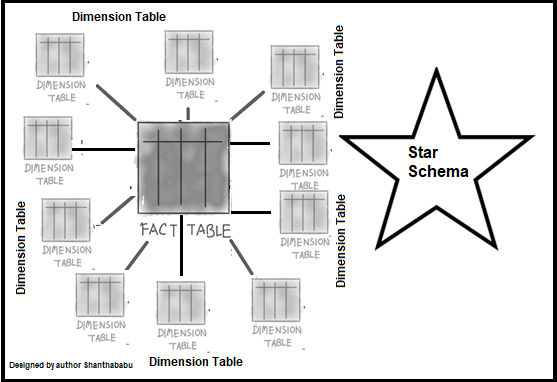
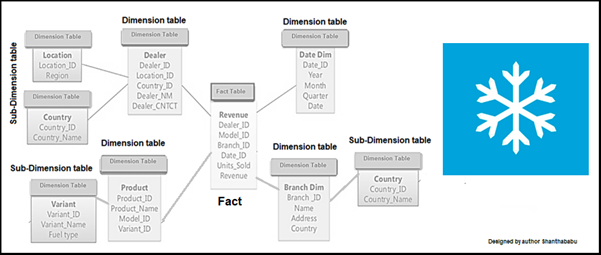
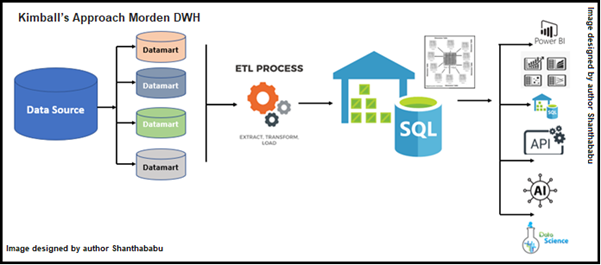
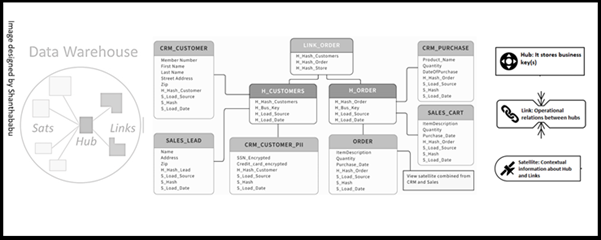





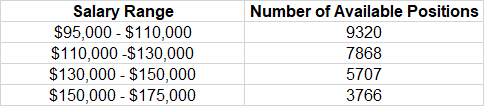
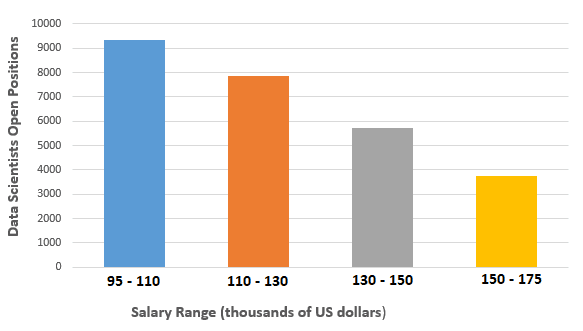
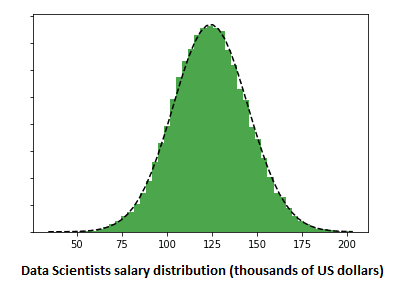



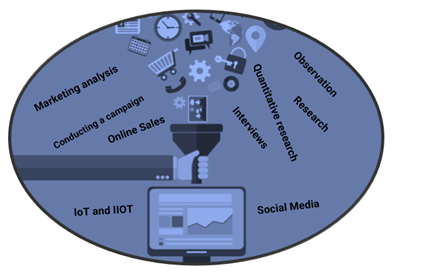
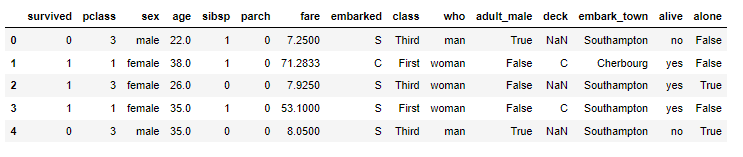
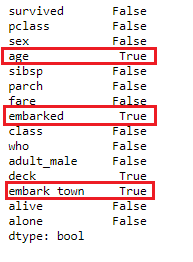
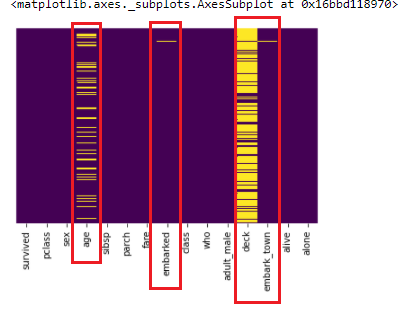
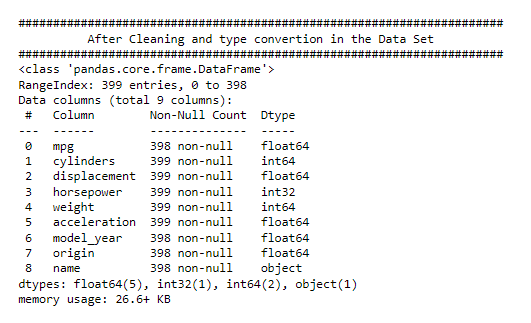
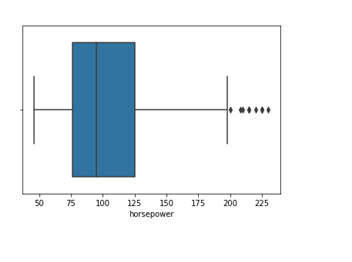
.png)