Meta, formerly known as Facebook, is set to release a commercial version of LLaMA, its open-source large language model (LLM) that uses artificial intelligence (AI) to generate text, images, and code.
LLaMA, which stands for Large Language Model Meta AI, was publicly announced in February as a small foundational model, and made available to researchers and academics.
Also: Want to build your own AI chatbot? Say hello to open-source HuggingChat
Now, the Financial Times is reporting that Meta is prepared to release the commercial version of the model, which would enable developers and businesses to build applications using the foundational model.
Since it's an open-source AI technology, commercial access to LLaMA gives businesses of all sizes the opportunity to adapt and improve the AI, accelerating technological innovation across various sectors and potentially leading to more robust models.
Meta's LLaMA is available in 7, 13, 33, and 65 billion parameters, compared to ChatGPT's LLM, GPT-3.5, which has been confirmed to have 175 billion parameters. OpenAI hasn't said how many parameters GPT-4 has, but it's estimated to have over 1 trillion parameters — the more parameters, the better the model can understand input and generate appropriate output.
Also: Google Bard is stepping up its AI game with these new features
Currently, OpenAI leads the AI race, with ChatGPT as its sprinter, an AI chatbot that unleashed a generative AI revolution with its release in November. Microsoft has made hefty investments into OpenAI. The tech giant uses GPT-4 technology in the revamped, AI-powered Bing, and to power its Image Creator. Google has its own AI chatbot, Bard, and proprietary LLMs. None of these systems are open source.
Though open-source AI models already exist, launching Meta's LLaMA commercially is still a significant step, due to it being larger than many of the available open-source LLMs on the market, and the fact that it is from one of the biggest tech companies in the world.
Also:ChatGPT vs Bing vs Google Bard: Which is the best AI chatbot?
The launch means Meta is directly competing with Microsoft-backed OpenAI and Google, and that competition could mean significant advancements in the AI field. Closed or proprietary software, like that used in OpenAI's ChatGPT, has drawn criticism over transparency and security.
Today, it is challenging to come across a company that does not want to utilise generative AI. Prominent leaders in every organisation are eager to discuss their endeavours in leveraging generative AI capabilities. However, as the adoption of this technology expands, there arises a parallel need to exercise responsible usage, balancing between harnessing the benefits of AI and preserving the value of human jobs.
A recent incident in the Indian startup landscape has highlighted the importance of responsible use of AI. Dukaan, a DIY platform that enables merchants with zero programming skills to set up their e-commerce business, recently laid off 90% of support staff and replaced them with an AI chatbot named Lina.
“We had to lay off 90% of our support team because of this AI chatbot. Tough? Yes. Necessary? Absolutely,” Suumit Shah, founder & chief executive at Dukaan, said in a tweet. He received immense backlash with many calling him insensitive, lacking empathy and even heartless.
Shah claims leveraging AI reduced Dukaan’s customer support costs by 85%. At the same time, he also mentioned that the time required for the initial response had reduced from 1 minute and 44 seconds to an instant. Further, the resolution time had slashed from an average of 2 hours and 13 minutes to 3 minutes and 12 seconds.
However, how a company handles layoffs tells a lot about the company and its leadership. In today’s growing competitive landscape, companies prioritise shareholder value creation above everything else. The ‘humane’ aspect of running a company somewhere gets lost. Often things like employee welfare, sustainability, or even consumer protection are in the bottom half of their priority list, or in some cases, not a part of it at all.
Lessons from Zerodha
What Dukaan did was not extraordinary. They implemented an AI-powered chatbot that now answers customer’s queries instead of humans. AI-bots are not new either, and the thing is, it is something that has been contemplated by others as well, in the Indian startup ecosystem.
“It took us 30 mins to integrate commoditised ChatGPT, see tangible benefits, and realise that more than 20% ( 200 approx) of jobs could be automated. Now, imagine what more intelligent tools could lead to?,” Nithin Kamath, founder & CEO at Zerodha said, earlier this year.
Through a blog post, Zerodha revealed that they are not going to be using AI just for ‘the sake of using it.’ The stock broker company said they will only use AI when they find the right use case.
What’s commendable is Zerodha will not fire anyone on the team just because it has implemented a new piece of technology that makes an earlier job redundant. Moreover, the startup has formulated an internal AI policy to provide clarity to its team members, addressing concerns and alleviating anxiety related to AI and potential job losses.
Unlike Shah, Kamath was showered with praises by the internet. However, how many companies are willing to take a similar approach is the question? In the global landscape, another commendable example is Swedish multinational conglomerate brand IKEA. The furniture giant also introduced an AI-powered chatbot called Billie to support customer support.
But, rather than resorting to employee layoffs, the company is taking a proactive approach by retraining its call centre employees to transition into roles as interior design advisors. Here, it is important to note that various factors such as market condition, financial condition, and profitability of a company also play crucial roles in such decisions. Let’s take Zerodha for example, which is a profitable company. In FY 2023, the company could make INR2500 crores in profit, reports said.
“Businesses with financial freedom should, if nothing else, give their teams that helped build the business time to adapt,” Kamath said. Hence, for Zerodha, or even IKEA, it might appear easy to retain their employees compared to Dukaan. However, Shah, in March 2023, did reveal that Dukaan is also growing its revenues at a healthy pace, after it decided to shift its focus on larger brands from small kiranas.
Blame it on AI
Today, we are in the age of generative AI, and it does bring significant advantages to businesses. Many businesses are in fact, looking at leveraging the power of Large Language Models (LLM) to improve their contact centres and customer support team. In fact, it was envisaged that customer support is the first segment that will be impacted by generative AI.
However, industry leaders AIM has spoken to think otherwise. They feel that generative AI will only make customer support agents more efficient and add to productivity of the organisation. AI is still not at a stage to completely take care of customer support of a company.
“Generative AI enables human agents to focus on more complex and value-added activities that require critical thinking, problem-solving, and creativity,” Gaurav Singh, founder, and chief executive at Verloop, told AIM.
Even though Shah claims his chatbot has improved his customer support, experts are of the opinion that AI is still not a stage to handle complex customer support queries at this stage.
“Many companies will likely let go of employees and blame it on AI. In the process, companies will earn more and make their shareholders wealthier, worsening wealth inequality,” Kamath predicted earlier this year. Hence, going forward, another company laying off its employees and blaming it on AI might not be surprising.
The post What Can Dukaan Learn from Zerodha? appeared first on Analytics India Magazine.
Feature learning is a vital component of machine learning but is often little talked about, with many guides and blog posts focusing on the latter stages of the ML lifecycle. This supporting step can make machine learning models more accurate and efficient, turning raw data into something more tangible and ready to use. Without it, building a fully-optimized model is impossible.
In this article, we will talk about how feature learning works in machine learning and how it can be implemented in simple, practical steps. In addition, we will also discuss some of the drawbacks of ML, giving a comprehensive overview of this essential process.
What Is Feature Engineering?
Feature engineering is an important machine learning (ML) technique that processes datasets and turns them into a usable set of figures that are relevant to specific tasks.
Source
Features are the data elements that are analyzed, appearing as columns within a dataset. By correcting, sorting, and normalizing these data elements, models can be optimized for better performance. Feature learning modifies these data elements to make them relevant, thus making models more accurate and with quicker response times thanks to fewer variables being used.
The feature engineering process can be broken down as follows:
Analysis is performed to correct any issues found in the data, such as incomplete fields, inconsistencies, and other anomalies.
Any variables that do not have any relevance to the model behavior are deleted.
Duplicate data is dismissed.
The records are correlated and normalized.
Why Is Feature Engineering So Important In Machine Learning?
Without feature engineering, it would not be possible to design predictive models that are capable of performing their function accurately. Feature learning also reduces the time and computation resources needed, making models more efficient.
The features of the data dictate how the predictive model will work, helping to train each model to achieve the desired results. This means that even data that is not fully applicable to a specific function can be modified to achieve a suitable outcome. Feature learning also significantly reduces the time that is spent conducting data analysis later on.
Feature Engineering: Benefits and Drawbacks
Although feature learning is essential, it does have some limitations, as well as the obvious benefits, which are listed below.
Feature Engineering: Benefits
Models with engineered features benefit from faster data processing.
Models are simplified and, therefore, easier to maintain.
Predictions and estimations are more accurate.
Feature Engineering: Drawbacks
Feature engineering can be a time-consuming process.
Deep analysis is required to build an effective feature list. This includes a thorough understanding of the datasets, the model’s processing behaviors, and the business context.
A Practical Approach To Feature Engineering In Machine Learning: Six Steps
Now we have a better understanding of what feature learning can do, as well as its drawbacks, let’s consider a practical approach to the process in 6 key steps.
#1 Data Preparation
The first step in the feature engineering process is to convert the raw data that has been collated from a range of sources into a usable format. Usable ML formats include; .csc; .tfrecords; .json; .xml; and .avro. To prepare the data, it must go through a range of processes such as cleansing, fusion, ingestion, and loading.
#2 Data Analysis
The analysis stage, sometimes referred to as the exploratory stage, is when insights and descriptive statistics are taken from the datasets, which are then presented in visualizations to better understand the data. This is then followed by identifying correlated variables and their properties so they can be cleaned.
#3 Improvement
Once the data has been analyzed and cleansed, it is time to improve it by adding any missing values, normalizing, transforming, and scaling. Data can also be further modified by adding dummy values which are qualitative/ discrete variables that represent categorical data.
#4 Construction
Features can be constructed both manually and automatically using algorithms (tSNE or Principal Component Analysis (PCA), for example). There are an almost inexhaustible number of options when it comes to feature construction. However, the solution will always depend on the problem.
#5 Selection
Feature/ variable/ attribute selection reduces the number of input variables (feature columns) by only choosing the ones that are most relevant to the variable that the model is built to predict. This helps to deliver better processing speeds and reduce computational resource usage.
Feature selection techniques include:
Filters to remove any irrelevant features.
Wrappers to train ML models to use several features
Hybrid models which combine filters and wrappers
Filter-based techniques, for example, rely on statistical tests to determine whether the feature correlates sufficiently with the target variable.
#6 Evaluation and Verification
The evaluation process determines the accuracy of the model in terms of training data using the features selected. If the level of accuracy meets the required standard, then the model can be verified. If not, then the feature selection stage will need to be repeated.
Feature Engineering Use Cases
Now let’s take a look at three common use cases for feature engineering in machine learning.
Additional Insights From The Same Dataset
Many datasets contain arbitrary values, such as date, age, etc., that could be modified into different formats that provide specific information regarding a query. For example, date and duration details can be cross-referenced to determine user behaviors, such as how frequently they visit a website and how much time they spend on there.
Predictive Models
Selecting the correct features can help to build predictive models for a range of industries, one industry that can benefit from such a model is public transport, helping to gauge how many passengers may use a service on a specific day.
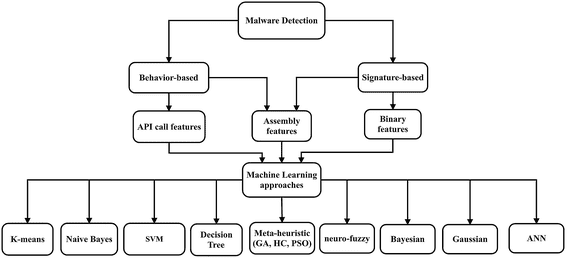
Malware Detection
Manual malware detection is extremely difficult, and most neural networks also have issues in this regard. However, feature engineering can combine manual techniques and neural networks to highlight unusual behaviors.
Source
Feature Engineering In Machine Learning: Conclusion
Feature engineering is an important stage when building machine learning models, and getting this stage right can ensure ML models are more accurate, use less computational resources, and process at higher speeds.
The feature engineering process can be broken down into six stages, from the initial data preparation to verification, choosing only the most relevant data elements for a specific task. Nahla Davies is a software developer and tech writer. Before devoting her work full time to technical writing, she managed — among other intriguing things — to serve as a lead programmer at an Inc. 5,000 experiential branding organization whose clients include Samsung, Time Warner, Netflix, and Sony.
More On This Topic
Feature Engineering of DateTime Variables for Data Science, Machine…
Feature Store Summit 2022: A free conference on Feature Engineering
A (Much) Better Approach to Evaluate Your Machine Learning Model
Date Processing and Feature Engineering in Python
Using RAPIDS cuDF to Leverage GPU in Feature Engineering
A Structured Approach To Building a Machine Learning Model
The AI compute market is seeing somewhat of a renaissance with the boom in generative AI. At the same time, research into alternative methods of accelerating AI workloads have also been in full swing. Researchers from the University of Washington, in conjunction with a researcher from Microsoft, have found a way to serve LLM workloads in a more efficient way.
They published their findings in a paper termed ‘Chiplet Cloud’, detailing their plan to build an AI supercomputer based on the chiplet manufacturing process. Compared to general-purpose GPUs, this computing model achieves a whopping 94x improvement. Even when pitted against Google’s built-for-AI TPUv4, the new architecture sees a 15x improvement.
As covered by AIM previously, the industry as a whole is moving towards specialised chip design. Following in the footsteps of companies like Cerebras, Samba Nova, and GraphCore, the chiplet cloud might just represent the future of AI compute in the enterprise.
Chiplet cloud explained
The paper describes an architecture wherein purpose-built ASIC (application specific integrated circuit) chips make up the bulk of computing power. These chips are the pinnacle of specialised chips, as seen by their adoption by Intel (Meteor Lake) and AMD (Zen). While these chipmakers use ASICs as a smaller part of their general-purpose chips, the paper proposes the whole architecture be constructed of ASICs.
By creating an ASIC optimised for maths matrix calculations, which make up the bulk of AI compute workloads, the researchers showed a huge performance increase and cost savings over GPUs. In terms of total cost of ownership per generated tokens, the chiplet cloud saw a 94x improvement over a cloud of NVIDIA’s last-gen A100 GPUs.
This cost savings mainly stems from the silicon-level optimisations that come with creating customised chips. In addition to the optimisations for maths matrix calculations, the chip also has huge amounts of memory in the form of SRAM (static random access memory). This is one of the most important parts of any system for LLM workloads, as it allows for the model to be stored in fast memory.
This has long been an issue with GPUs, as even the fastest memory today cannot keep up with LLMs’ requirement. This leads to a phenomenon known as bottlenecking, wherein the GPU is not used to its fullest potential due to memory bandwidth constraints. The chiplet cloud does not fall prey to this issue, as it has extremely low-latency memory placed right next to the processing chips.
These chips are then connected together using a 2D torus structure, which the researchers say is flexible enough for different kinds of AI workloads. These features are only half the story, as the main benefit of introducing a chiplet cloud comes in the cost reduction.
Future of AI compute
As mentioned previously, cloud service providers are reaching into their deep pockets to fund research into specialised AI chips. AWS has Graviton and Inferentia, and Google has TPUs, but Microsoft had fallen behind, until now. This research holds the potential to change the way the enterprises approach cloud compute for AI.
To begin with, even manufacturing the nodes required for the chiplet cloud would be a drop in the ocean compared to competitors. Researchers estimated the cost of building a comparable GPU cluster at $40 billion, notwithstanding the operating expenses that come with such powerful machines.
On the other hand, the chiplet cloud cost was estimated to be around $35 million, which makes it highly competitive especially when considering their huge efficiency gains. Moreover, breaking down the silicon chip into chiplets improves manufacturing yield, further driving down the cost of ownership.
In addition to this, these ASICs will also be utilised at their full capacity due to the 2D torus architecture, as opposed to 40% utilisation on TPUs and 50% on GPUs for LLM workloads. These chips can also be deployed as per the software and hardware requirements of the companies, making it even more suited for cloud deployment.
The chiplet cloud compute type and memory capacity can be changed depending on the type of model being deployed on it. This alone will have AI-first companies queuing up for the product, as the custom-sized clouds can help them save costs while optimising for narrow use-cases. Moreover, the cloud can also be configured for either latency or TCO per token, meaning that companies can either opt to have their models fast or accurate.
The possibilities are endless with the chiplet cloud architecture, which might also be why Microsoft is conducting research into this field. If this undertaking makes its way into Azure, Microsoft would not only have a unique bargaining chip against AWS and GCP, but can also supercharge OpenAI’s APIs and its own Azure OpenAI service. While it is still in the research phase, the chiplet cloud’s various benefits might make it the go-to cloud compute for AI.
The post Chiplet Cloud will be the Future Of Enterprise AI Compute appeared first on Analytics India Magazine.
Organizations that want to harness generative artificial intelligence (AI) more effectively should use their own data to train AI systems, using foundation models as a starting point.
Doing so can provide more relevant context and allay concerns about the potential risks, such as inaccuracy and intellectual property infringements.
Also: How to use ChatGPT: Everything you need to know
Accuracy, in particular, is a top priority for a company such as Jiva. The agritech vendor uses AI to power its mobile app, Crop Doctor, which identifies crop diseases via image processing and computer vision, and recommends treatments. It also taps AI to determine the credit worthiness of farmers who ask for cash advancements prior to a harvest and returns the loans when their harvest pays out.
It uses various AI and machine-learning tools, including Pinecorn, OpenAI, and scikit-learn, as well as Google's TensorFlow and Vertex AI. Jiva has operations in Singapore, Indonesia, and India.
It trains its AI models on thousands of annotated images for each disease, according to Jiva's CTO Tejas Dinkar. The agritech company has collected hundreds of thousands of images from the ground through its field teams and farmers who are part of Jiva's network and use its app AgriCentral, which is available in India.
Also: How to use Bing Image Creator (and why it's better than DALL-E 2)
Its field experts are involved in the initial collection and annotation of images, before these are passed on to agronomy experts who further annotate the images. These then are added to the training model used to identify plant disease.
For new crops or crops that its team of experts are less familiar with, Jiva brings in other platforms, such as Plantix, which have extensive datasets to power image recognition and diagnosis information.
Delivering accurate information is vital because the data can improve farmers' harvests and livelihoods, Dinkar said in an interview with ZDNET. To further ensure data veracity, generative AI and large language models (LLMs) use only datasets Jiva itself had sourced and vetted.
The chatbot is further asked, through prompt engineering, to ignore any pretrained data about farming that might be in the LLMs, he said.
Also: This new AI system can read minds accurately about half the time
If there's no data to draw from, the chatbot returns a response to say it is unable to identify the crop disease. "You want to ensure there's enough data. We don't want to provide a vague answer," he said.
Jiva also uses its image library to build on top of platforms, such as Plantix. These models provide a good baseline but, as they are developed by global companies, they may not necessarily be adequately trained on data specific to a region or market, Dinkar said.
This issue meant Jiva had to create training models for crops that were more common in Indonesia and India, such as corn, he said. These have been performing better than Plantix or other off-the-shelf products, he added, noting the importance of localization in AI models.
Finetune base models to get better results
Using foundation data models out of the box is one way to get started quickly with generative AI. However, a common challenge with that approach is the data may not be relevant to the industry within which the business operates, according to Olivier Klein, Amazon Web Services' (AWS) Asia-Pacific chief technologist.
To be successful in their generative AI deployments, organizations should finetune the AI model with their own data, Klein said. Companies that take the effort to do this properly will move faster forward with their implementation.
Also: These experts are racing to protect AI from hackers
Using generative AI on its own will prove more compelling if it is embedded within an organization's data strategy and platform, he added.
Depending on the use case, a common challenge companies face is whether they have enough data of their own to train the AI model, he said. He noted, however, that data quantity did not necessarily equate data quality.
Data annotation is also important, as is applying context to AI training models so the system churns out responses that are more specific to the industry the business is in, he said.
With data annotation, individual components of the training data are labeled to enable AI machines to understand what the data contains and what components are important.
Klein pointed to a common misconception that all AI systems are the same, which is not the case. He reiterated the need for organizations to ensure they tweak AI models based on the use case as well as their vertical.
LLMs have driven many conversations among enterprise customers about the use of generative AI in call centers, in particular, he said. There is interest in how the technology can enhance the experience for call agents, who can access better responses on-the-fly and incorporate these to improve customer service.
Call center operators can train the AI model using their own knowledge base, which can comprise chatbot and customer interactions, he noted.
Adding domain-specific content to an existing LLM already trained on general knowledge and language-based interaction typically requires significantly less data, according to a report by Business Harvard Review. This finetuning approach involves adjusting some parameters of a base model and uses just hundreds or thousands of documents, rather than millions or billions. Less compute time is also needed, compared to building a new foundational model from ground zero.
Also: Generative AI can make some workers a lot more productive, according to this study
There are some limitations, though. The report noted that this approach still can be expensive and requires data science expertise. Furthermore, not all providers of LLMs, such as OpenAi's ChatGPT-4, permit users to finetune on top of theirs.
Tapping their own data also addresses a common concern customers have amid the heightened interest in generative AI, where businesses want to retain control of the data used to train AI models and have the data remain within their environments, Klein said.
This approach ensures there is no "blackbox" and the organization knows exactly what data is used to feed the AI model, he noted. It also assures transparency and helps establish responsible AI adoption.
There also are ongoing efforts in identifying policies needed to avoid the blackbox effect, he said, adding that AWS works with regulators and policy makers to ensure its own AI products remain compliant. The company also help customers do likewise with their own implementations.
Also: People are turning to ChatGPT to troubleshoot their tech problems now
Amazon Bedrock, for instance, can detect bias and filter content that breaches AI ethical guidelines, he said. Bedrock is a suite of foundation models that encompass proprietary as well as industry models, such as Amazon Titan, AI21 Labs' Jurassic-2, Anthropic's Claude, and Stability AI.
Klein anticipates that more foundation data models will emerge in future, including vertical-specific base models, to provide organizations with further options on which to train.
Key issues to resolve with generative AI
Where there is a lack of robust AI models, humans can step back in.
For rare or highly specific crop issues, Dinkar noted that Jiva's team of agronomy experts can work with local researchers and field teams to resolve them.
The company's credit assessment team also overlays data generated by the AI systems with other information, he said. For example, the team may make an on-site visit and realize a crop is just recently ready for harvest, which the AI-powered system may not have taken into consideration when it generated the credit assessment.
"The objective is not to remove humans entirely, but to move them to areas they can amplify and [apply] adaptive thoughts, which machines aren't yet up to," Dinkar said.
Asked about challenges Jiva encountered with its generative AI adoption, he pointed to the lack of a standard prompt methodology across difference software versions and providers.
"True omni-lingualism" also is missing in LLMs, he said, while hallucination remains a key issue.
"Various large language models all have their own quirks [and] the same prompt techniques do not work across these," he explained. For instance, through refined prompt engineering, Jiva has been able to instruct its agronomy bot to clarify if it is unable to infer, from context, the crop that the farmer is referencing.
Also: How I tricked ChatGPT into telling me lies
However, while this particular prompt performed well on GPT-3.5, it did not do as well on GPT-4, he said. It also does not work on a different LLM.
"The inability to reuse prompts across versions and platforms necessitates the creation of bespoke sets of prompt techniques for each one," Dinkar said. "As tooling improves and best practices emerge for prompting various large language models, we hope cross-platform prompts will become a reality."
Improvements are also needed in cross-language support, he said, pointing to strange responses that its chatbot sometimes generates that are out of context.
GitHub has joined the likes of Google, Apple, and Microsoft in adding passkey support to its platform. Through this new standard, users can sign in securely, replacing passwords which GitHub claims are the root cause of 80% of data breaches.
The FIDO Alliance’s passkey standard is slowly gaining more steam as more companies jump on the passkey bandwagon. Touted as the beginning of the end for passcodes, this new standard aims to replace traditional sign in methods.
The support for passkeys also comes alongside GitHub’s larger push for more secure log-on options. As part of this push, the software repo platform also added 2 factor authentication across the platform last year.
GitHub users need to opt-in to use the new features, and once they do, they can navigate to GitHub settings to convert their existing security keys into passkeys. The company says that most up-to-date devices support passkeys out of the box, thus allowing users to log in using biometric authentication like FaceID or fingerprints.
This system will also work with browsers’ autofill systems to suggest that users sign in with passkeys. Just like other passkeys, GitHub’s passkeys can also be used across devices. Developers can use this feature to simply scan a QR using their phone and login to GitHub quickly, easily, and securely. These passkeys can also be synced across devices, so as to ensure that users will never be locked out due to a lack of a key.
Other companies like Google, Apple, and password managers like 1Password and LastPass have already adopted passkeys. This new standard, proposed by the FIDO alliance, has some big names on board, and could be the alternative to passwords companies have been searching for.
However, as reported by AIM in a deeper dive into the passkey standard, it might be sacrificing decentralisation for ease of use. With the standard being adopted among various platforms, the Internet is slowly moving towards centralisation through passkeys.
The post GitHub Adds Supports For Passkeys appeared first on Analytics India Magazine.
Sam Altman is not just your typical ChatGPT man. The farsightedness of this investor and tech magnate is probably bringing Midas’s Golden touch into whatever he sets his eyes on. Investing in domains that have far-fetched futuristic goals, Altman has a diversified portfolio of investments, betting big on cryptocurrency, longevity research, and the biggest bet of all – “Energy.”
“I think the two most important inputs to a great future are abundant intelligence and abundant energy. I have long been interested in the potential that nuclear energy offers to provide clean, reliable, and affordable energy at great scale.” – Sam Altman.
Speaking about a future of “abundant intelligence,” Altman’s plans are beyond AI. Let’s just say, achieving AGI and superintelligence is in the near future map. Last week, OpenAI announced its plans to achieve superintelligence alignment within the next four years for which they have allocated 20% of its computing resources.
A month ago, OpenAI announced their new process supervision training model which is said to reduce hallucinations and probably help inch closer to AGI. To achieve a fully established AGI, energy computation will be unfathomable. However, Altman’s focus on building that energy will be the beacon that will aid its progress.
Altman has been laying hints on his interests for clean energy and has been investing in the field for a while now. From being in the Board of Directors for a nuclear fission startup to being an investor funding such companies, Altman has a significant stake in energy. Surprisingly, Altman owns zero stake in OpenAI.
While Altman’s nuclear energy investments may sound as any investor’s route to profitability, there is another path unwinding for the entrepreneur. It’s almost as if Altman is charting a path where his investments in nuclear energy will address any or all of the computation and energy drain that is associated with training and running large language models.
Not once has he spoken about OpenAI’s sustainability goals, where his company produces massive carbon footprints for training their GPT models.
Only talks
On his recent trip to Israel, Sam Altman spoke in Tel Aviv University about how you can achieve a lot of things if one can figure “how to make a lot of clean energy cheaply, efficiently capture carbon, and build a factory at a planetary scale to do this.” Even in his India visit, when asked about Helion and energy consumption, his desire to focus on nuclear energy was apparent. He believes that if fusion can work, the cost can become less than 1/10 of current energy and “can be manufactured for the whole planet and for ten years.”
In a 2021 tweet, Sam Altman predicted that costs of intelligence and energy are headed to a path towards near-zero and that AI revolution along with renewable and nuclear energy will help achieve that. Setting a preface to Altman’s vested interests in nuclear energy, major developments have taken place ever since.
In exactly two months of that tweet, OpenAI invested $375 million in a nuclear fusion startup Helion Energy, which was considered Altman’s largest investment in a startup till date. Altman’s vision of Helion has been well-defined : generate electricity that is affordable and accessible, and address the climate crisis. Helion wishes to deliver electricity for 1 cent per kilowatt-hour.
However, this is not the only nuclear company Sam has laid his eyes on.
abundant energy is important to a great future and there are only a few technologies that can deliver it safely, cost-effectively, at scale, and without burning carbon. as ceo of altc, i am excited to be combining with @oklo, a unique company positioned to lead in fission.
— Sam Altman (@sama) July 11, 2023
Mapping the Intelligence-Energy Synergy
Oklo Inc. that designs and deploys advanced fission power plants, led by chairman Sam Altman, announced the company’s plan to go public through a merger with special-purpose acquisition company (SPAC) AltC Acquisition Corporation where he serves as CEO and Director. The company is said to raise $500 million. In a video talking about Oklo, Altman reiterated on how intelligence and energy will go hand-in-hand for a bright future.
Interestingly, at the start of last year, the Nuclear Regulatory Commission denied application from Oklo for building and operating an advanced nuclear reactor Aurora in Idaho citing significant gaps in describing potential accidents and classification of safety systems and components.
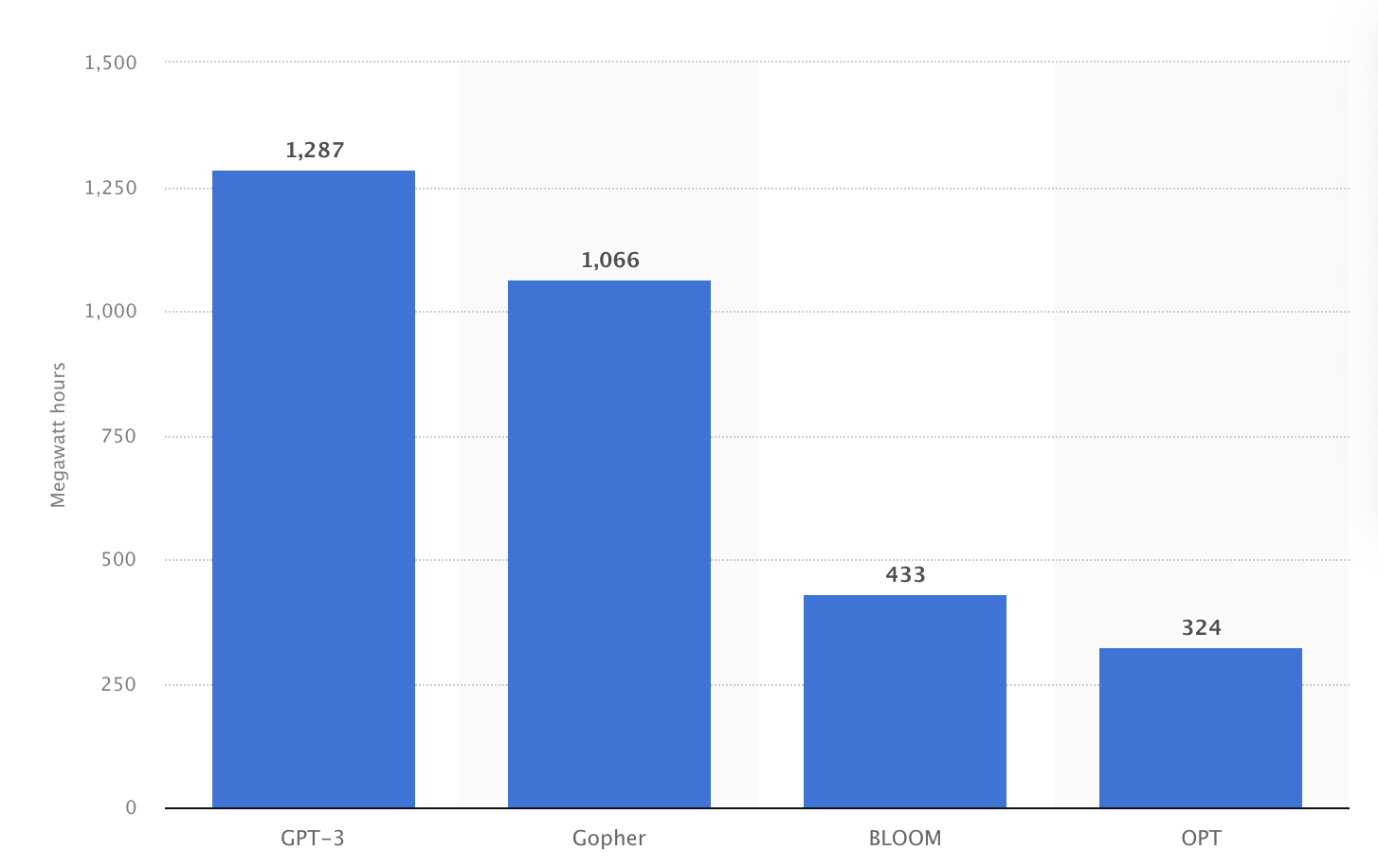
The environmental impact of LLM has been on the rise with the uptick of generative AI models. Training the GPT-3 model just once consumes 1287 MWh, which is equivalent to supplying an average US household for 120 years.
Power Consumption (MWh) for training LLM
Source: Statista
The carbon footprints left by training large large language models run into hundreds of tonnes. In 2022, the carbon dioxide-equivalent emissions produced by GPT-3 was at 502 tonnes.
Okla, a nuclear fission microreactor company is working towards commercialising nuclear fission that is required for powering nuclear power plants which employ smaller reactors.
Helion, on the other hand, is a company that is working towards commercialising nuclear fusion. By having control over both kinds of nuclear energy generation modes, Altman has got sustainability covered under his kitty.
In an interview with CNBC, Altman expressed his disagreement with the idea of limited energy availability. He emphasised that advocating for reduced production and consumption of energy usage as means to protect natural resources was undesirable.
He believes that nuclear energy is necessary to meet the rising demand as the shift in movement from burning fossil fuels that causes global warming keeps rising. “I don’t see a way for us to get there without nuclear.”
Towards Clean Energy
With climate conscious goals of working towards reducing carbon footprints and creating sustainable energy sources, several big tech companies are investing in renewable energy startups, especially nuclear energy. Probably, in a bid to address the energy crisis and have a stake in the rising industry, tech players such as Jeff Bezos, Bill Gates and others have invested in the field.
Jeff Bezos’ has invested in a Canadian company General Fusion which will build a nuclear fusion facility in the UK by 2025. TerraPower, which was founded by Bill Gates in 2008 is opening a nuclear power plant in Wyoming. Microsoft on the other hand has agreed to purchase electricity from Helion by 2028.
With companies chasing nuclear energy, Altman has been way ahead by creating two paths that will work on symbiosis: AI and energy. By focusing on clean and renewable energy, he is also building a sustainable ecosystem for powering AI models. Who knows? Altman might be the first one to crack the AGI code.
The post Sam is Not Into AI Anymore appeared first on Analytics India Magazine.
Twitter today announced the launch of its ‘Creator Ads Revenue Sharing Program’ for creators subscribed to Twitter Blue or Verified Organizations. Twitter said that content creators will now have the opportunity to earn a share of the revenue generated from ads displayed within their replies.
To be eligible for this program, creators must be verified users and have garnered at least 5 million impressions in the last three months. Once Twitter approves a creator’s eligibility, they will be required to have a Stripe account to facilitate payment processing, the company added.
In February Musk had announced that Twitter will start sharing revenue from reply-thread ads with creators who are subscribed to Twitter Blue Verified. In April, Twitter rolled down its legacy Verification Program which led to previous verified accounts on the basis of previous criteria (active, notable and authentic) to lose their blue checkmark.
In a recent announcement, Musk also introduced a limit on the number of posts a user can read per day on a platform. The rationale behind implementing this restriction, as explained by Musk, was to tackle the issue of excessive data scraping and manipulation of the system.
Now Who is Copying Who?
With this, Twitter is trying to draw more content creators into its ecosystem. This comes shortly after the introduction of Threads, which is being promoted as a potential ‘Twitter Killer’ application by Zuckerberg. Notably, Threads achieved a significant milestone by surpassing 100 million sign-ups within just five days, surpassing even the rapid growth observed with OpenAI’s ChatGPT.
It would be interesting to see if Threads will also start “Creator Ads Revenue Sharing Programme,” as it previously seems to have inspired everything that Elon’s Twitter has been doing to make the platform better, including the Piad blue tick, and to an extent, the entire platform as well.
However, Meta previously had introduced something similar to Twitter ad revenue sharing on Instagram reels for select creators, where they could earn money by posting reels.
The post Twitter Now Pays “Blue Verified” Creators, Will Threads Follow Suit? appeared first on Analytics India Magazine.
Meta launched Threads on July 5, and became the fastest growing app in history. Mark Zuckerberg, founder of Meta, was counting every milestone as it passed 2 million sign ups in the first two hours, 5 million in the first four hours, 10 million in seven hours and 30 million in 24 hours. Threads has got 100 million sign ups in a week.
This is an unprecedented growth for any platform in the history of the Internet, but there’s no guarantee that this rapid success will sustain.
According to experts, social media without a clear purpose or a proper target audience or seamless tech or even any one of these has failed miserably in the past. Even Facebook, a platform that found Mark Zuckerberg incredible success is losing users everyday.
Here is a list of 6 platforms that lost out in the last decade.
Vine
Vine, founded in 2012 by Dom Hofmann, Rus Yusupov, and Colin Kroll, quickly gained popularity as a unique platform for creating and viewing content. It was acquired by Twitter for $30 million in the same year and released on Android, iOS, and Windows in 2013. However, Vine’s success was short-lived.
Its initial dominance in the market was due to the lack of competition. Top creators like King Bach, Nash Grier, Amanda Cerny, and Rudy Mancuso amassed millions of followers and billions of Vine “loops.” Unfortunately, Vine’s downfall was just as swift as its ascent.
The main reason behind Vine’s failure was its failure to establish a monetization program to reward its creators. Despite earning millions in ad revenue from user-generated content, Vine’s creators struggled to turn their creativity into a sustainable career. Top creators attempted to negotiate official deals with Vine management, but their requests were rejected. Consequently, these creators migrated to YouTube, where they could compile their Vines into videos and earn a living. Vine’s refusal to compensate creators for their work contrasted with the approach of TikTok, a platform that understood the importance of supporting and rewarding creators.
Clubhouse
Launched in April 2020, Clubhouse, a social audio app, initially attracted users through its invite-only feature and notable personalities like Elon Musk and Mark Zuckerberg. However, there was no moat in the business. A few months later, Twitter announced a new feature called “Spaces” in the microblogging platform, which made Clubhouse obsolete.
Besides, as pandemic restrictions eased, daily active users decreased significantly, especially after celebrities and their followers left the platform. Clubhouse’s management failed to establish a business model, lacked user and analytics data, and couldn’t curate conversations effectively.
In April, this year the company announced they were laying off more than half of their employees. The founders said they need to “reset” the company in the aftermath of COVID-19.
Musical.ly
Musical.ly was a short-form video social media platform that gained over 200 million users during its active years which began in April 2014. It allowed users to create and share short videos with soundtracks, focusing on lip-syncing content. The app was headquartered in Shanghai and became particularly popular with pre-teen and teenage girls, especially in the US. In 2017, it was acquired by ByteDance, the parent company of TikTok, for around $800 million.
However, ByteDance eventually decided to merge Musical.ly into TikTok, resulting in the shutdown of the Musical.ly app. The merger allowed TikTok to consolidate users and features from Musical.ly into its platform. The decision to shut down Musical.ly and merge it with TikTok was driven by ByteDance’s desire to leverage the user base and technology of both platforms, streamline resources, and compete more effectively in the global video-sharing market.
Yik Yak
Yik Yak was an anonymous social media app that allowed users to make posts visible to others within a 5-mile radius launched in November 2013. It gained popularity, particularly on school and college campuses in the US, with 1.8 million downloads by September 2014. The app’s founders, Tyler Droll and Brooks Buffington, secured funding and raised the company’s value to around $400 million at its peak.
The app struggled with site performance, leading to slow loading times and an inability to handle high traffic. One significant factor in Yik Yak’s decline was its issue with cyberbullying. The app’s anonymity and hyper-localization made it a breeding ground for bullying. Instances of threats, violence, and harassment were reported, leading to media outcry, school bans, and negative user experiences. Yik Yak attempted to address the problem by implementing geo-fencing, disabling app usage in schools. However, this decision severely impacted its user base, as schools and colleges were its primary market.
Kik
Kik Messenger was a free mobile messaging app that allowed users to send audio, text, images, GIFs, and videos which began its services in 2010. It differentiated itself by not requiring phone number sign-up and offering anonymity and chatbot integration.
Kik faced challenges due to changing strategic directions, ownership changes, and content moderation issues. In 2019, the app was sold to MediaLab after unsuccessful attempts at reinventing the company. MediaLab continued to maintain the platform without significant innovation.
Its decline can be attributed to its constant shifts in focus, lack of effective monetization, distraction with ICOs, and inability to effectively moderate content. The ownership of Kik currently rests with MediaLab, a Los Angeles-based holding company with experience in running digital assets. The exact acquisition price remains undisclosed.
Google+
Google+ had seamless technology and a large number of users who had already signed up for gmail. The company also sent many private invitations and hyped up the platform so much that it had 10 million users within 2 weeks of launch in 2011. After a year, it only had 90 million users.
Even with superior technology, Google failed to understand customers’ wants and needs. Facebook already existed as a platform connecting people, and Google wanted users to share everything, including emails,tweets, photos, videos. Which users found unnecessary. It failed to connect people outside of its own ecosystem. The concept of ‘circles’ was interesting but was confusing to use and sharing posts and images was complicated. Google+ also lacked a strong mobile experience.
It tried to be everything and ended up being nothing that users needed.
Things changed further when its founder Vic Gundotra left in 2014. Its collaboration with Photos and Hangouts was abandoned and it came out as an independent social networking site. It further detached Youtube and GooglePlay and was left confused on what the purpose of the platform was. Strong competition and no vision finally led to its demise.
The post 6 Popular Social Media Platforms that Tanked in The Last Decade appeared first on Analytics India Magazine.
Google has embraced AI and hit the ground running. This is evident with Google's rapid launch of its own chatbot, Google Bard. Now, the tech giant is expanding its AI offerings with the launch of its 'AI-first notebook'.
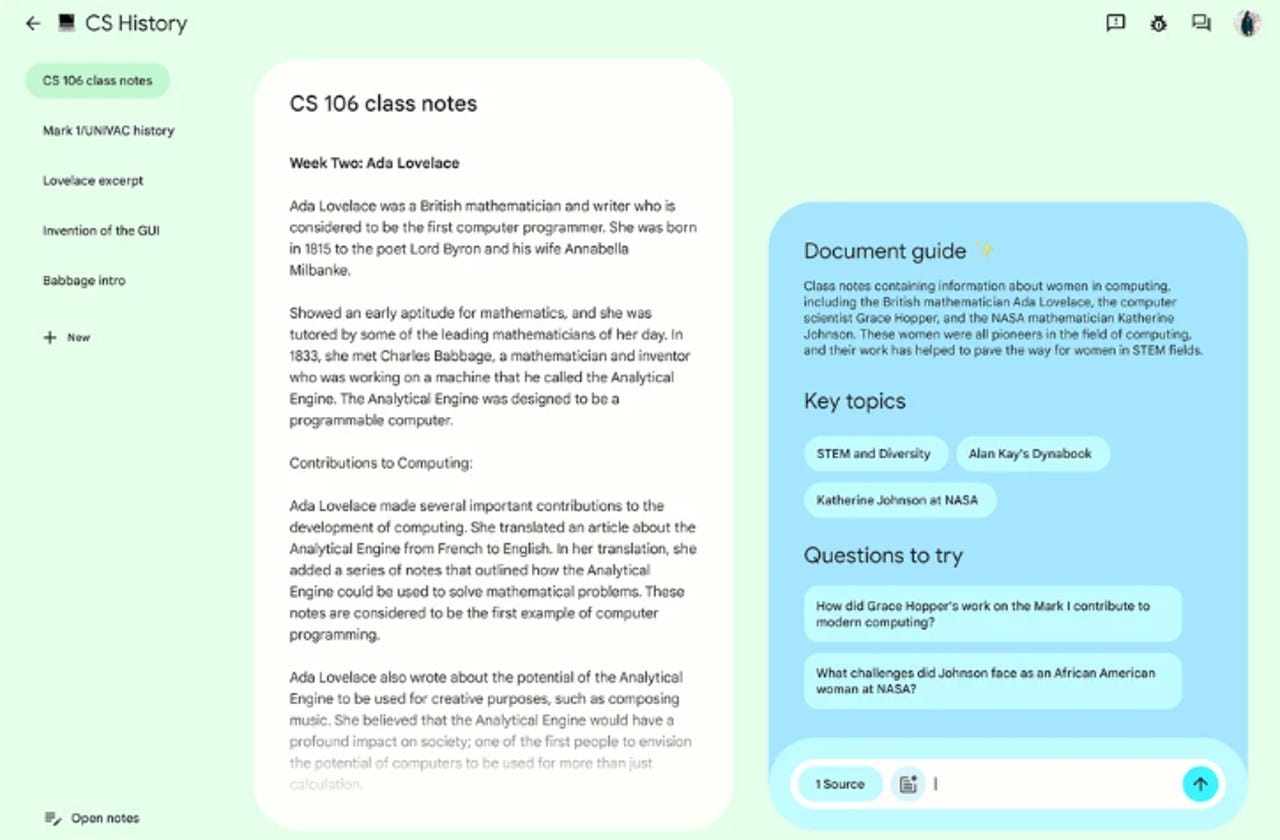
NotebookLM is Google's take on notetaking software that keeps a language model at its core. Instead of a typical chatbot, this software works with the content you already have and uses AI to further deepen your understanding of the content.
Also: Google Bard is stepping up its AI game with these new features
"A key difference between NotebookLM and traditional AI chatbots is that NotebookLM lets you 'ground' the language model in your notes and sources," says Google.
For example, when you drop a Google Doc into NotebookLM, it will automatically generate a summary of the document and provide you with key topics and questions you can ask to better understand the material.
You can also ask NotebookLM questions about the uploaded documents, prompting it to generate a glossary of key terms for you, a summary of specific aspects of the document, and more.
If you upload a pitch deck, you can also ask it to generate potential questions for investors. Or, if you are a content creator, you can share video ideas and ask it to create a script for your video, according to the release.
Also: Google tests its new AI medical chatbot at Mayo Clinic
NotebookLM is an experimental product built by a small team at Google Labs. The team has the intention of testing it and learning from people about how to refine the technology before rolling it out further. Currently, NotebookLM is being tested with a small group of users in the US. If you're interested, you can join the waitlist.
This technology was initially announced at Google I/O under the name Project Tailwind as part of Google's many AI announcements. Today, Google launched some Google Bard features that were also announced at Google I/O, such as using images in Google Bard prompts.