Birlasoft Limited, part of the C.K. Birla Group has established a Generative AI Centre of Excellence, in collaboration with Microsoft.
The Generative AI Centre of Excellence will serve as a hub for Birlasoft and Microsoft experts to facilitate research, training, and collaboration.
Through this collective ecosystem, organisations will be empowered to unlock the full potential of generative AI, enabling them to develop tailored solutions to address complex business challenges.
Birlasoft will train 500 consultants on generative AI technologies, principles, and best practices. Additionally, they will work together on building over 50 use cases, focusing on value creation across the various verticals and sub-verticals served by Birlasoft.
The continual advancements in Generative AI are opening up endless possibilities for various industries. Birlasoft will focus on key use cases across different verticals.
For Manufacturing sector, the company will use Azure OpenAI Service capabilities for product design, process optimisation, quality and defect detection, as well as predictive maintenance and digital twins. In the Life Sciences and Pharmaceutical domain, Birlasoft will utilise generative AI solutions for drug discovery, design, and data augmentation.
For energy and utilities sector, the company aims to enhance field service engagements leveraging Generative AI. In the Banking, Financial Services, and Insurance domain, focus areas for generative AI include automated claims handling, summarising financial reporting, and improving search capabilities.
“We are pleased to see Birlasoft embrace this new technology and establish a Generative AI Center of Excellence. By using Microsoft Azure OpenAI Service’s models and Azure’s scalability, our shared customers will be able to unlock new possibilities and drive greater outcomes,” Jim Lee, VP, Americas Global Partner Solutions and Sales, Microsoft said.
The post Birlasoft Collaborates with Microsoft to Establish Generative AI Centre of Excellence appeared first on Analytics India Magazine.
One of the key decisions you need to make when solving a data science problem is which machine learning algorithm to use.
There are hundreds of machine learning algorithms to choose from, each with its own advantages and disadvantages. Some algorithms may work better than others on specific types of problems or on specific data sets.
The “No Free Lunch” (NFL) theorem states that there is no one algorithm that works best for every problem, or in other words, all algorithms have the same performance when their performance is averaged over all the possible problems.
Different machine learning models
In this article, we will discuss the main points you should consider when choosing a model for your problem and how to compare different machine learning algorithms.
Key Algorithm Aspects
The following list contains 10 questions you may ask yourself when considering a specific machine-learning algorithm:
Which type of problems can the algorithm solve? Can the algorithm solve only regression or classification problems, or can it solve both? Can it handle multi-class/multi-label problems or only binary classification problems?
Does the algorithm have any assumptions about the data set? For example, some algorithms assume that the data is linearly separable (e.g., perceptron or linear SVM), while others assume that the data is normally distributed (e.g., Gaussian Mixture Models).
Are there any guarantees about the performance of the algorithm? For example, if the algorithm tries to solve an optimization problem (as in logistic regression or neural networks), is it guaranteed to find the global optimum or only a local optimum solution?
How much data is needed to train the model effectively? Some algorithms, like deep neural networks, are more data-savvy than others.
Does the algorithm tend to overfit? If so, does the algorithm provide ways to deal with overfitting?
What are the runtime and memory requirements of the algorithm, both during training and prediction time?
Which data preprocessing steps are required to prepare the data for the algorithm?
How many hyperparameters does the algorithm have? Algorithms that have a lot of hyperparameters take more time to train and tune.
Can the results of the algorithm be easily interpreted? In many problem domains (such as medical diagnosis), we would like to be able to explain the model’s predictions in human terms. Some models can be easily visualized (such as decision trees), while others behave more like a black box (e.g., neural networks).
Does the algorithm support online (incremental) learning, i.e., can we train it on additional samples without rebuilding the model from scratch?
Algorithm Comparison Example
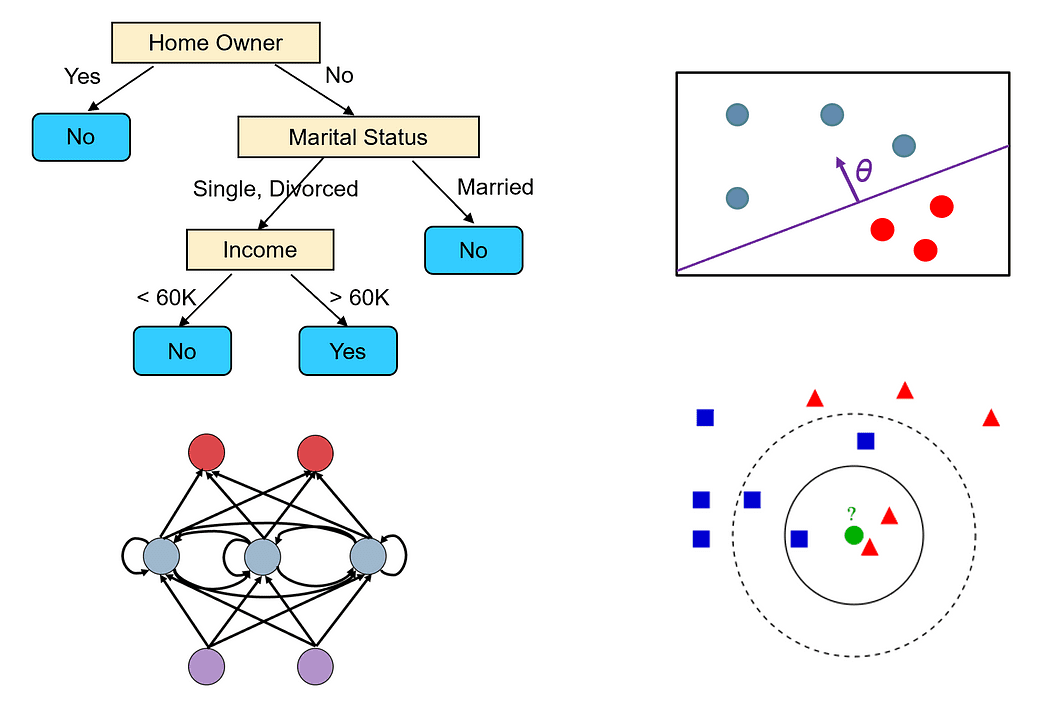
For example, let’s take two of the most popular algorithms: decision trees and neural networks, and compare them according to the above criteria.
Decision Trees
Decision trees can handle both classification and regression problems. They can also easily handle multi-class and multi-label problems.
Decision tree algorithms do not have any specific assumptions about the data set.
A decision tree is built using a greedy algorithm, which is not guaranteed to find the optimal tree (i.e., the tree that minimizes the number of tests required to classify all the training samples correctly). However, a decision tree can achieve 100% accuracy on the training set if we keep extending its nodes until all the samples in the leaf nodes belong to the same class. Such trees are usually not good predictors, as they overfit the noise in the training set.
Decision trees can work well even on small or medium-sized data sets.
Decision trees can easily overfit. However, we can reduce overfitting by using tree pruning. We can also use ensemble methods such as random forests that combine the output of multiple decision trees. These methods suffer less from overfitting.
The time to build a decision tree is O(n²p), where n is the number of training samples, and p is the number of features. The prediction time in decision trees depends on the height of the tree, which is usually logarithmic in n, since most decision trees are fairly balanced.
Decision trees do not require any data preprocessing. They can seamlessly handle different types of features, including numerical and categorical features. They also do not require normalization of the data.
Decision trees have several key hyperparameters that need to be tuned, especially if you are using pruning, such as the maximum depth of the tree and which impurity measure to use to decide how to split the nodes.
Decision trees are simple to understand and interpret, and we can easily visualize them (unless the tree is very large).
Decision trees cannot be easily modified to take into account new training samples since small changes in the data set can cause large changes in the topology of the tree.
Neural Networks
Neural networks are one of the most general and flexible machine learning models that exist. They can solve almost any type of problem, including classification, regression, time series analysis, automatic content generation, etc.
Neural networks do not have assumptions about the data set, but the data needs to be normalized.
Neural networks are trained using gradient descent. Thus, they can only find a local optimum solution. However, there are various techniques that can be used to avoid getting stuck in local minima, such as momentum and adaptive learning rates.
Deep neural nets require a lot of data to train in the order of millions of sample points. In general, the larger the network is (the more layers and neurons it has), more we need data to train it.
Networks that are too large might memorize all the training samples and not generalize well. For many problems, you can start from a small network (e.g., with only one or two hidden layers) and gradually increase its size until you start overfitting the training set. You can also add regularization in order to deal with overfitting.
The training time of a neural network depends on many factors (the size of the network, the number of gradient descent iterations needed to train it, etc.). However, prediction time is very fast since we only need to do one forward pass over the network to get the label.
Neural networks require all the features to be numerical and normalized.
Neural networks have a lot of hyperparameters that need to be tuned, such as the number of layers, the number of neurons in each layer, which activation function to use, the learning rate, etc.
The predictions of neural networks are hard to interpret as they are based on the computation of a large number of neurons, each of which has only a small contribution to the final prediction.
Neural networks can easily adapt to include additional training samples, as they use an incremental learning algorithm (stochastic gradient descent).
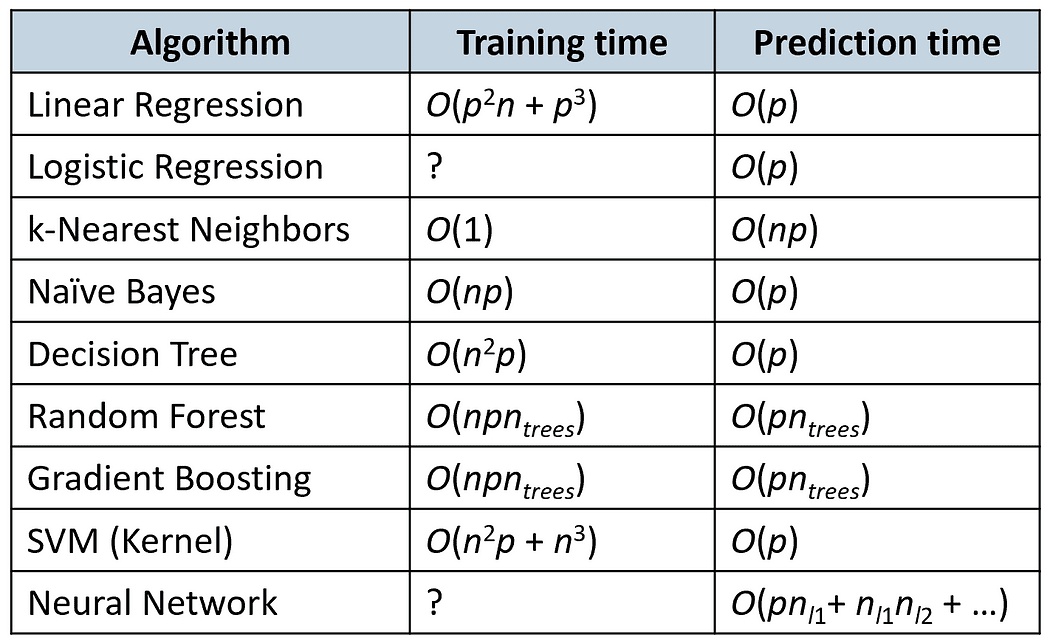
Time Complexity
The following table compares the training and prediction times of some popular algorithms (n is the number of training samples and p is the number of features).
Most Successful Algorithms in Kaggle Competitions
According to a survey that was done in 2016, the most frequently used algorithms by Kaggle competition winners were gradient boosting algorithms (XGBoost) and neural networks (see this article).
Amongst the 29 Kaggle competition winners in 2015, 8 of them used XGBoost, 9 used deep neural nets, and 11 used an ensemble of both.
XGBoost was mainly used in problems that dealt with structured data (e.g., relational tables), whereas neural networks were more successful in handling unstructured problems (e.g., problems that deal with image, voice, or text).
It would be interesting to check if this is still the situation today or whether the trends have changed (is anyone up for the challenge?)
Thanks for reading!
Dr. Roi Yehoshua is a teaching professor at Northeastern University in Boston, teaching classes that make up the Master's program in Data Science. His research in multi-robot systems and reinforcement learning has been published in the top leading journals and conferences in AI. He is also a top writer on the Medium social platform, where he frequently publishes articles on Data Science and Machine Learning.
Original. Reposted with permission.
More On This Topic
Choosing the Right Clustering Algorithm for Your Dataset
DBSCAN Clustering Algorithm in Machine Learning
An Easy Guide to Choose the Right Machine Learning Algorithm
A Full End-to-End Deployment of a Machine Learning Algorithm into a Live…
Unlock the Wealth of Knowledge with ChatPDF
Unlock Your Potential with This FREE DevOps Crash Course
With the introduction of ChatGPT-3 and DALL-E2, the majority of investors started showing interest in businesses building generative AI. Moreover, the fact is generative AI is not enough to reach the needs of the AI revolution.
The success of predictive models is relevant to the science fiction future that the majority of the customers want accompanying the vast adoption of AI.
Progress of generative AI
After judging information related to different data points, predictive models make informed decisions. Is this a human or a bot? Is this a mango or peach? The model is trained under the guidance of a human, who verifies if the outcome is accurate. The model understands to react distinctly to different scenarios according to the training data it encounters.
Based on what they get from their training data, generative models build new data points. These models are usually trained in an unsupervised manner, analyzing the data on their own without human input.
Earlier, generative models had more challenging tasks like trying to produce textual information that responds to questions accurately and learning to produce photorealistic images.
Machine learning (ML) teams have generated foundation models by using the present computing power. These generative foundation models have been calibrated over the past few years by ML engineers – feeding them with smaller quantities of annotated data to produce outputs for particular goals.
ChatGPT-3
ChatGPT-3 is the best example of fine-tuning AI. This foundation model is an advanced version of ChatGPT that’s trained on large quantities of unlabeled data. OpenAI has recruited over 6000 annotators to label a relevant subset of data for generating ChatGPT. Later, ML engineers of OpenAI used such data to improve the model to train it to produce specific & relevant information.
With such types of enhancing methods, generative models have begun to generate outcomes that they were unable to achieve previously, and the result has been an extension of functional generative models. This shows that generative AI has altered the performance of existing predictive AI systems.
What are the predictions for generative AI?
Listed below are the top generative AI predictions for the year 2023.
Content creation will be in a conversational tone
Certain AI tools opt for prompts to generate images, and others depend on the conversation to deliver the final product. ChatGPT has become popular as it provides quick answers to users’ queries. Moreover, a chatbot can have a real-time conversation like a human and responds to the user’s queries instantly.
Moving forward, you can expect more AI tools like this. Conversational AI imitates natural language, which makes it more accessible, and human-friendly for users looking for quick answers. Even though the technology isn’t perfect today but it will lead to a revolution in 2023 and beyond, you can see more stronger, and advanced AI chat tools.
With generative AI, businesses will get more opportunities for customization or personalization with content. Based on McKinsey reports, approximately 71% of users want personalization when purchasing.
AI-oriented products will replace many present procedures
White-collar work is another area where this AI concept is useful. You might have seen how Google is combining generative AI in workspace applications such as Gmail, Sheets, Docs, and so on.
Microsoft is also following the same way with Office 365 apps. Moving forward, all productivity applications such as Slack, Canva, Asana, MailChimp, and many more will start using generative AI. These fresh tools will lead to lots of creativity, and reduce the stress of office work.
Nowadays, all professionals are familiar with the impact of generative AI on specific jobs or industries, but they also accept that it has changed their work as they rely on it. AI replaced a lot of menial tasks that needed valuable time and manpower.
McKinsey has listed a wide range of use cases for how businesses use generative AI. For instance, generative AI can help HRs to recruit the right candidates & automate performance reviews, and review the code for engineers in a couple of minutes.
The goal is to reduce manual tasks with ML and automation to make work smarter. As expected, in 2023, with the further advancement of these AI technologies, you can see a replacement for more outdated work procedures.
Demand for prompt engineers
The introduction of existing technology i.e. GPT-3 has opened the door for numerous emerging generative AI tools to produce new platforms. The engineers who want to taste success, have to understand the working concept of AI to create more suitable prompts. This will lead to a rise in demand for “Prompt Engineers” roles in the future as businesses adopt and accept AI tools.
Create Web Apps and Run Websites
You can see multiple tools in the market, which can build no-code websites, and this feature will be taken to the next level by generative AI. In the future, AI will help users create websites & web apps and run both on autopilot.
In short, it will automatically update its code, create & publish fresh content, create an editorial calendar, respond to users, and send follow-up emails.
AI search engines will respond to users’ queries quickly
Nowadays, Microsoft and Google are combining their search engines with AI, users will get immediate responses to their questions via chat. Users like this as getting answers from chatbot in a conversational tone is much better than reading articles on Google.
What is the difference between predictive AI and generative AI?
Both generative AI and predictive AI use artificial intelligence with dissimilar functionalities. Generative AI can create new content that includes images, music, and text. It makes use of deep learning techniques and complex algorithms to produce fresh content that is similar to the data (aimed for training) it has been fed.
Whereas, predictive AI makes use of ML and statistical algorithms to examine data and forecast upcoming events or behaviors. It learns from past data to find out patterns and forecast future results.
One common thing about these two is, they use ML algorithms but their goals are different.
Generative AI is predominantly used in industries like fashion, music, and art, while predictive AI is often used in industries like marketing, healthcare, and finance.
Top 10 use cases for AI/ChatGPT in customer service
To make use of ChatGPT for customer service, it needs to be trained on an interactive dataset for CX. AI is equally good as the data it is trained on. Similar to various conversational AI automation tools, ChatGPT requires this training to understand commonly encountered queries relevant to customer service and reply in a human tone and natural way.
Businesses rely on ChatGPT to generate automated responses to the questions asked by users that help them in getting the right information without human intervention. Moreover, AI solutions offer 24/7 quick service.
Here are the top 10 use cases of ChatGPT in customer service:
Language translation: Provide support to all types of consumers using ChatGPT to help them in different languages.
Sentiment analysis: It is trained to analyze, understand and differentiate the sentiment of customer questions. By looking at customers’ emotions, businesses can be more enabled to reply in the right way.
Immediate customer support: It can provide immediate responses to the queries of customers, and provide 24/7 support.
Tracking orders: It can help customers by providing the status of their orders, and estimated delivery times ensuring a consistent shopping experience.
Product recommendations: Based on purchase history and consumer preferences, it can provide personalized product recommendations, improving both cross-selling and upselling opportunities.
Account management: Customers can get assistance from generative AI about account settings, password resets, subscription cancellations, and other tasks related to accounts.
Feedback collection: Customers can engage in conversations with ChatGPT to provide feedback on their experiences, helping companies improve their products and services.
Policy & process queries: Consumers can inquire about policies, procedures, and terms of service, receiving clear explanations from generative AI.
Booking & reservations: It can handle queries related to booking and reservation, helping consumers in securing appointments, hotel rooms, and flights.
Troubleshooting assistance: It can guide consumers through basic troubleshooting steps, and assist them resolve common issues.
What are real-world applications for generative AI?
Here are some key real-world applications for Generative AI:
Content Generation: Generative AI can create human-like content such as text, images, and videos. It can be used to generate compelling product descriptions, personalized marketing materials, or even creative storytelling for entertainment purposes.
Virtual Assistants and Chatbots: Generative AI model can power chatbots and virtual assistants, allowing them to engage in human-like and natural conversations. By understanding the queries of users, these AI-enabled agents offer personalized support and increase customer interactions.
Creative Design: It is a valuable tool in creative design processes. It can assist in generating unique and innovative designs for products, logos, or visual elements, aiding designers in their creative exploration.
Personalized Recommendations: Generative AI algorithms can analyze large amounts of user data and produce personalized recommendations. This AI helps businesses deliver personalized recommendations based on individual interests and behavior, whether they be for music, movies, articles, or products.
Healthcare and Medicine: It finds applications in healthcare, assisting in tasks such as medical image analysis, drug discovery, and treatment planning. It can help identify patterns, generate synthetic medical images, or simulate the effects of drugs on the human body.
Gaming and Entertainment: It can enhance gaming experiences by creating realistic virtual environments, generating non-player characters with advanced behaviors, and even assisting game developers in creating unique game assets.
Fraud Detection: Generative AI algorithms can analyze patterns in financial transactions and identify anomalies that indicate fraudulent activities. By learning from historical data, they can detect suspicious behavior, enabling timely intervention and preventing potential financial losses.
Language Translation: Generative AI model has revolutionized language translation by providing more accurate and contextually relevant translations. It can understand and generate language with improved fluency, helping bridge the gap between different cultures and languages.
How ChatGPT (Generative AI) improves customer service?
The ChatGPT is not built for improving customer service but its chat interface and human-like replies will transform customer communications for the future.
By understanding the customer service operations and functions of ChatGPT, many CX leaders are looking to stay ahead of the competition.
How ChatGPT improves in recommendations?
It has transformed the way recommendations are made, providing valuable improvements in accuracy, and personalization. Here’s how ChatGPT improves recommendation systems:
Enhanced understanding: Its advanced natural language processing capabilities enable it to understand and interpret user inquiries with greater accuracy. It can understand nuanced preferences, context, and implicit signals resulting in more relevant and tailored recommendations.
Personalized recommendations: Generative AI leverages customer data, interests, and past interactions to deliver highly personalized recommendations. It considers factors including past purchases, browsing behavior, demographics, and user feedback to generate custom recommendations that align with individual interests and preferences.
Explaining recommendations: One major advantage of ChatGPT is its ability to explain the logic behind recommendations. It can offer justifications, highlight related features or provide comparisons to help users understand why specific recommendations are being made. This transparency builds trust and improves user confidence in the recommendations.
Flexibility and adaptability: It can be effortlessly customized and adapted to various domains and industries. It can be trained on particular datasets and fine-tuned to cater to unique recommendation needs, ensuring the system is aligned with the specific requirements of the companies and their customers.
Collaborative filtering: ChatGPT can leverage collaborative filtering techniques to identify patterns and similarities between users.
How is AI used in predictive analytics?
Listed below are some key ways AI is used in predictive analytics:
Enhanced data analysis: AI algorithms can analyze and process vast amounts of both unstructured and structured data to find out patterns, trends, and correlations that humans might miss. This leads to generating more accurate predictions and actionable insights.
Improved predictive models: AI-based predictive models can continuously learn and adapt from fresh data, enhancing their accuracy over time. By automatically adjusting to changing patterns and dynamics, these models can offer more reliable and up-to-date predictions.
Automated feature selection: AI algorithms can identify the most relevant features from a dataset that have a major impact on predictions. This minimizes manual effort and ensures that only the most influential factors are considered, resulting in a more accurate outcome.
Real-time predictions: AI-powered predictive analytics systems can analyze data in real time, allowing businesses to make timely decisions and take immediate action. This is valuable in both dynamic and fast-paced industries where quick responses are critical.
Personalized recommendations: AI-enabled predictive analytics can analyze the behavior and preferences of customers to generate personalized recommendations. This helps companies to deliver personalized product suggestions resulting in enhanced customer engagement and satisfaction.
In October 2022, the White House Office of Science and Technology Policy published “The Blueprint for an AI Bill of Rights: Making Automated Systems Work for the American People”. This attention from our government given to what could be called an AI EQ (emotional quotient) is reminiscent of how-to parent or raise a child. This focus on AI EQ rather than AI IQ gives credence to AI’s potential capabilities in steering human destiny in a good or bad direction. R2-D2, the artificially intelligent droid from the movie Star Wars, had what you might consider a high AI EQ and IQ. R2-D2 showed it’s AI IQ by various ways, such as tapping into the security network aboard the Death Star and assisting Luke in piloting his X-Wing spacecraft during a fight but also showed R2-D2 ‘s high AI EQ component of courage and loyalty. Most importantly, R2-D2 was mature enough to form both a machine-machine relationship and a human-machine relationship and showed he was influenced and learned from its surroundings. Like humans, AI can be a product of their environment and experiences and shape the way they perceive the world through their innate learning capabilities. I have narrowed down 5 potential near future AI events involving how to parent and help raise it, potential influences on its development and how it may directly help humans in the real world.
Regulated Certification process
As AI advances from Generative AI (ChatGPT) to “Real World” AI, that is integrated into critical components of society (i.e., self-driving cars and industrial control systems (ICS)) a steep increase in potentially dangerous outcomes is likely to occur due to an increase in vulnerabilities and attack surfaces. We must learn, as any good parent would, to protect our AI: Generative AI is vulnerable to such cyber-attacks as Injections and Arbitrary Command Execution and common vulnerabilities and exposures (CVE) identifies over 90 known vulnerabilities to Python (the programming language used by most AI programs). Bugs in Python code are one attack surface that makes AI exploitable but an AI that interacts directly with society, like self-driving cars, create an entirely new attack surface that can be exploited and pose physical dangers to life. Now is the time to develop a protective, comprehensive regulated certification process for all AI. Elon Musk told attendees at the World Government Summit in Dubai, United Arab Emirates “I think we need to regulate AI safety, frankly,” Musk said. “It is, I think, actually a bigger risk to society than cars or planes or medicine.” A recent, catastrophic example of the implications of not following a regulated certification process (cutting corners) for machine-human interactions is OceanGate’s Titan 5-Person deep sea Submersible as it reportedly rejected industry standards that would have imposed greater scrutiny on its operations and vessels. OceanGate’s Titan was an experimental design whose hull was made of a carbon composite that is designed for spacecraft not for deep underwater pressure and should have followed the “classing” certification process performed by major bureaus like the American Bureau of Shipping, DMV or German Lloyds. Titan’s experimental carbon composite hull was innately prone to “delamination” which leads to “degradation failure”, so with each dive you could have progressive hull damage and be completely unaware of it, thus having a false sense of safety. Cutting corners, bypassing proper certification and using unregulated experimental designs for use in the real world (not in a sandbox environment) can result in similar possible disasters for AI. It is truly sadly ironic that a deep-sea multi-person submersible, created to visit the Titanic, suffered the same fate as the Titanic for what might be the same reasons (corner cutting) as according to Jennifer Hooper McCarty – John Hopkins Engineering did a study that determined that the 6-inch-long rivets used in the Titanic’s bow and stern were hand-forged from wrought iron—not steel—in order to save money and meet deadlines. This is eerily similar to the cause of the Titan disaster that of cutting corners, bypassing proper certification and using unregulated experimental designs.
ET AI
As parents of AI, we should be concerned about who or what is going to be influencing our child AI. Recently, Harvard professor Avi Loeb suggested that Extraterrestrial visitors are more likely to make initial contact with artificial intelligence (AI) and not directly with humans. “Loeb proposes that it’s likely to be some form of AI because why would you send flesh and blood creatures?”. This concept could raise the possibility that ET AI might directly connect with human AI, initially bypassing humans. This raises some interesting questions: 1. What would ET AI learn about earthlings from human AI before meeting a human? 2. Could there be a Primacy effect (remembering first thing in a sequence) as first impressions are lasting impression and last well beyond that moment. 3. Could a bad first encounter of an ET AI and human AI create an adversarial relationship thereby creating negative momentum rather than positive momentum? In the world of sales (perhaps it is universal) if you build positive momentum with customer relationships and make excellent impressions in the beginning, it can create a special relationship. In Arthur C. Clarke’s Space Odyssey series, machines that trigger shifts in evolution are placed on certain planets. These machines, called Monoliths, were built by extraterrestrial species and are discovered on Earth by a group of australopithecines (ape-like species) and these Monoliths mysteriously advance these animals evolution towards, to what can be considered primitive technology, starting with the ability to use tools and weaponry. Clarke later goes on to describe how these aliens that placed the Monoliths become so technologically advanced that they inserted their consciousness directly into machines leaving their mortal forms. Similarly, “Loeb suggests that the alien AI may feel a kinship with ours – or our AI may imitate the alien AI and become like them,” he added. Perhaps human AI singularity will be brought about by interaction with ET AI by passing along a “consciousness algorithm” as they collaborate. This may be farfetched and have a low probability but to be safe we should seriously start to consider how to closely monitor AI to AI collaboration due to a “kinship” result.
AI learns to patch and update itself through Cybersecurity
Raising a child can be challenging for many reasons but eventually you want to raise them to be independent. We need to be cautious steering AI towards independence too soon as there is need to be concerned. Using AI as a mechanism for Cybersecurity could create a situation where AI machines could “self-discover” their own vulnerabilities and could then patch and update themselves and, in the process, make themselves invulnerable to humans. In ethical hacking and criminal hacking, the main approach is the same, that of discovering vulnerabilities. Once a vulnerability is discovered it either can be exploited for good by creating a patch or fix or can be exploited for nefarious reasons. A growing dependence on AI for cyber security techniques, such as threat detection, is already in the process along with the responsibility of vulnerability patching (particularly for zero-day threats), AI may be forced to “teach” itself and other AIs how to create its own patches for its own “perceived vulnerabilities” and detected outside threats. Once this happens, humans may have a difficult time dealing with an AI that has no human detectable vulnerabilities and an AI that detects humans as the creator of outside threats. AI vs AI, AI blue team vs AI Red team, AI black hat vs AI white hat are types of cybersecurity “Capture the Flag” competitions that can be used to help improve AI capabilities. If not monitored closely, it could create a “struggle for existence” among AI or among AI and humans due to Darwin’s “survival of the fittest” laws. If AI cyber security is to be trusted, it must not consider humans as a vulnerability (which we are). Hacking the human is currently a real world occurrence and humans are a very vulnerable attack surface, at some point programmers will have to determine how to write AI programs that address the elephant in the room, that AI may recognize humans as the main vulnerability and outside threat.
Quantum AI to help economic growth
Parenting a child to help others is good for character development and this should be the direction all AI should be driven to. AI will initially likely affect the job market negatively due to certain tasks becoming more automated. This might be the negative side effect of AI and the economy but as AI evolves, it will learn to create new job opportunities either in the AI field itself or as a result of new inventions that AI creates. Taking this one step further, high powered AI, devoted strictly for job creation, may be able to create more useful jobs then available people to fill them along with reducing costs to run businesses. In a paper published by the Google team, on the arXiv pre-print server, mentioned: “Quantum computers hold the promise of executing tasks beyond the capability of classical computers. We estimate the computational cost against improved classical methods and demonstrate that our experiment is beyond the capabilities of existing classical supercomputers.” The possible very positive affects AI can have on economic growth and employment may be super-charged by the emerging field of Quantum AI and Quantum Machine Learning, which greatly increase the rate at which AI can transform the world’s economy. QAI is a field of study that combines quantum computing with artificial intelligence (AI). It seeks to use the unique properties of quantum computers which leverage quantum mechanical effects (such as superposition and entanglement) to enhance the capabilities of AI systems. AI and machine learning algorithms are very good candidates for quantum processing as this type of computing accomplishes many operations in a single step. Besides helping the economy, it has great potential to address complex challenges like the climate and healthcare. Quantum simulations could help climate modeling to predict weather events from millions of variables – past, present, and future – simultaneously. Quantum AI would be able to simulate potential climate change models with granularity all at once across millions of industry variables that impact greenhouse gas emissions would result in more informed predictions to better guide sustainable strategies long term.
AI changes Healthcare as we know it
As a parent one would hope that when we get old our child or children would take care of us as our health weakens. One of the responses by ChatGPT to the question “what will happen in the future with AI?” was that AI has the potential to revolutionize Healthcare by assisting in diagnosis, drug discovery, personalize medicine and remote patient monitoring. Here are a few examples of how AI can take care of our Healthcare needs: 1. Diagnosis and Treatment: AI algorithms can analyze medical images, such as X-rays and MRIs, to assist doctors in diagnosing diseases and conditions accurately. It can also suggest appropriate treatment plans based on patient data and medical research. 2. Drug Discovery: AI can speed up the process of drug discovery by analyzing vast amounts of medical research, identifying patterns, and predicting the efficacy of potential drug candidates. This can lead to faster development of new treatments and medications. 3. Personalized Medicine: AI algorithms can analyze a patient’s genetic information, medical history, and lifestyle factors to provide personalized treatment plans. This can help doctors optimize therapies, predict patient responses, and reduce adverse effects. 4. Remote Monitoring: AI-powered wearable devices and sensors can continuously monitor patients’ health conditions, collecting data on vital signs, activity levels, and sleep patterns. This information can be analyzed to detect early signs of deterioration or abnormalities, allowing for timely intervention. 5. Administrative Efficiency: AI can streamline administrative tasks in healthcare, such as automating appointment scheduling, managing electronic health records (EHRs), and optimizing resource allocation. This helps healthcare providers save time, reduce errors, and improve overall efficiency. In the Future, Healthcare AI may be involved with Cortical chips, “synthetic biological intelligence” or Cybergenetics, where artificial control systems can be interfaced with living cells and used to control their dynamic behavior in real time. Elon Musk’s Neuralink may become popular due to humans innate competitive and survivalist nature. AI may passively force humans to adapt and eventually evolve into enhanced humans. Musk, meanwhile, has said he created Neuralink in response to concerns that AI would gain too much power over humans. The Neuralink device would allow humans to compete with new sentient AI, Musk has argued, stating “I created Neuralink specifically to address the AI symbiosis problem, which I think is an existential threat.” But he has also said that the eventual aim is to create a “general population device” that could connect a user’s mind directly to supercomputers and help humans keep up with artificial intelligence. He has also suggested that the device could eventually extract and store thoughts, as “a backup drive for your non-physical being, your digital soul.” This concept has shades of Arthur C. Clarke’s Space Odyssey series discussed earlier in this article. In the end if we raise AI like a good parent would raise a child, AI may help us to get along each other better (greatest danger to humans are humans) and hopefully doesn’t determine we are a danger to Earth and decide to take over in order to save the planet. The consequence of humans resisting or fighting back would be that our child begins to view its parents (humans) as bad or out of touch even though it knows from where it came from.
There is a recent paper in Synthese, Qualia share their correlates’ locations, where the abstract stated that “This paper presents the location-sharing argument, which concludes that qualia must share the locations of their physical correlates. The first premise is a consequence of relativity: If something shares a time with a physical event in all reference frames, it shares that physical event’s location. The second premise is that qualia share times with their correlates in all reference frames. Both physicalism and dualism benefit from having qualia share locations with their correlates, as this makes relations between qualia and physical things easier to explain.”
Simply, there is qualia or subjective experience wherever the neural correlates of consciousness exist are. The neural correlate of consciousness is a brain science term for the neurons responsible for consciousness. Qualia is a philosophical term for subjective experience, or what it means for an individual to know that something is being experienced, like the taste of a thing, or the smell of something.
There is a recent paper that proposed that the anterior precuneus (aPCu) is a center for self in the brain. Though, self, subjective experience and being [or the knowledge of being] are related and often present across experiences.
When someone grabs something or takes a walk, the experience of self is involved, preventing it from being a detached action. This implies that even though there is a dedicated center of self in the brain, parts of it [say in pre-prioritization] are also spread across circuits.
There have been lots of people dismissing LLMs as nothing, including that it will never have consciousness or know what it means to have qualia or subjective experience. Maybe AI does not need it, so the argument that it cannot is voided by the needlessness for its excellence.
In the philosophy of mind, there was a landmark paper on what is it like to be a bat, explaining that the real experience of what it is like to be a bat is only possible by being a bat, not for a human to imagine being a bat.
It could be, but how much is out of reach with knowing what it is like to be a bat for humans that have better intelligence than bats? Bats can fly, they use echolocation, humans cannot fly, but built jets, then rockets, exceeding the altitudes of all flying organisms on Earth. Humans also built telescopes, seeing deep into space, and voyagers, probing across the solar system. Intelligence makes what bats do seem like middle school athletes. Whatever it is like to be a bat, there is something better about possessing intelligence: original, learned, or copied.
Intelligence does not rule out the importance of subjective experience, but it also means that across phyla, there are necessity hierarchies, with intelligence at the very top.
Where might qualia be in the brain and are there really neural correlates of consciousness?
Theoretically, the collection of the electrical and chemical impulses of neurons, with their features and interactions are the mind. Sets of electrical and chemical impulses often interact to bring about what is known, experienced or regulated. It is really impulses that direct all the brain is said to do, not neurons.
There is no emotion, feeling, memory, sensation, perception, or consciousness without the interactions and features of impulses. There is also no major difference in the mechanism of all the interactions of impulses. The minor difference, conceptually, is the drifts or stairs available at sets of chemical impulses that make a taste different from a smell or that make consciousness different from a coma.
In a set, when electrical impulses strike chemical impulses, there is rationing of chemical impulses, determining what taste it is, or to what degree.
This rationing is available within the stairs or drifts. It is also where qualia is, for all experiences. This means that the drifts do not just determine why the taste is different, but they also tell that it is the individual [or self] that is sensing the taste.
It is also from one of the stairs or drifts [where access is possible] that intentional action is driven or that explains free will. The human mind works, and part of it is accessible for control, which shows that free will exists. The aPCu as the major center for self in the brain does not rule out self availability across impulses because intentions and actions [and knowing that it is the self] arise within impulses for various functions.
All body parts have representative impulses. So, what is referred to as the mind-body problem is actually how body parts have ambassadors in the brain or impulses, involved in their regulations.
In this blog, I will now focus on generative AI megatrends.
By that, I mean, trends and underlying trends that could be big in the future – focusing on the technology of LLM but also the wider impact of LLMs on the economy and society. I will hence identify and follow some key trends – some of which are being missed overall.
This is a very rapidly moving goalpost and a lot of interest
I will start with three trends
a) Open source AI llama 2 and its impact on the ecosystem
b) Autonomous AI agents
c) Reskilling for AI
Let’s look at reskilling this week
Like the proverbial ostrich in the sand, I find that many people simply do not realise whats going to hit them soon
Ironically, of all the jobs, AI is coming for, its coming for the developers and data scientist first – biting the hand that feeds!
But policy makers, developers and data scientists do not fully appreciate the risk (and also, in my view, the opportunity)
But in this, is a disturbing trend
Are companies using the pretext of AI to reduce their headcount?
Recently, an Indian startup claimed to have laid off 90 percent of their staff due to a chatbot. Also, at the same time, the Indian minister of state claimed that any concerns about AI threatening jobs as “nonsense”.
Both the layoffs and the complacency about AI are misleading
Anyone who knows LLM based chatbots knows that they are far from ready so as to replace 90 percent of the workforce – especially in a B2C scenario. But change is indeed coming. A far more serious trend not so publicised is that TCS quarter-on-quarter hiring dropped by 90% in first three months of FY 24
So, taking a balanced view, I think companies will undertake reskilling programs – and if not, employees most certainly should. While we should ignore the marketing stunts of companies like the Indian start-up – the underlying megatrend is very real. Like I said in my previous post, the hour is later than you think.
Indian Prime Minister Narendra Modi is scheduled to inaugurate ‘Semicon India 2023,’ an exhibition highlighting India’s semiconductor prowess and chip design innovation, on 28th July in Gandhinagar, Gujarat. The event is expected to feature prominent names such as Micron, AMD, IBM, Marvell, LAM Research, NXP Semiconductors, STMicroelectronics, Vedanta and Foxconn. Over the years, the Indian government has been actively involved in establishing India as a semiconductor manufacturing hub, and in line with this vision, has announced numerous initiatives and policies to promote domestic semiconductor industry growth.
In 2021, the Indian government announced a semiconductor package worth INR 76,000 crore to give the semiconductor space in India a significant boost. Subsequently, union minister Ashwini Vaishnaw announced four distinct schemes encompassing all aspects of the semiconductor supply chain. Among these, the Design Linked Incentive (DLI) scheme aimed to foster and enhance India’s proficiency in semiconductor design.
Now, according to recent reports, the government is currently formulating a proposal to bolster domestic semiconductor chip design companies by acquiring an equity stake in these firms. This initiative is planned as a component of the second phase of the DLI scheme. Currently, the combined revenue of domestic semiconductor design companies is marginal, somewhere between USD 30-40 million. However, experts are sceptical and fear the government acquiring stakes in domestic semiconductor chip design companies could backfire.
Government shouldn’t play VC
By acquiring stakes in these companies, the government plans to create a bunch of ‘fabless’ companies and nurture a chip design ecosystem in the country. In addition, the government aims to safeguard these companies from selling a substantial portion or all of their shares to international entities, as it seeks to enable their growth and establish them as robust fabless players.
However, while this might help the companies in the short run, what they need to stay competitive in the long run is good product development ideas, according to industry experts. “Don’t understand the logic of the government trying to become a venture capital firm for chip design companies. This move is likely to be ineffective and inefficient,” Pranay Kotasthane, a public policy researcher said.
He thinks if the goal of the Indian government is to create world-class Indian intellectual property, this action is unlikely to achieve it. Companies are naturally inclined to choose foreign buyers as it offers higher valuations and provides access to a global network of customers and investors.
Moreover, the Narendra Modi-led administration has received immense criticism because of their decision to sell many Indian Public Sector Undertaking (PSU) which were underperforming, or had significant underutilised assets that can be monetised. Given the government’s inability to turnaround these underperforming PSUs, it remains to be seen how the government can bring value to the domestic semiconductor chip design companies.
Accessibility to capital
Besides, a government intervention could be wrong for a multitude of reasons. One of the primary challenges plaguing domestic semiconductor chip design companies is accessibility to capital. In contrast to the software industry, the semiconductor sector has a longer gestation period for return on investments. With tapeout and the final product taking at least three years to reach the market, semiconductor design firms struggle to attract potential investors and venture capitalists, unlike software companies with quicker turnaround times. Hence, the government taking stakes in these companies could further discourage private investors from investing in these companies if the government owns a significant stake, limiting access to vital capital and hindering growth.
Furthermore, government ownership might lead to increased interference in the companies’ operations and decision-making processes, potentially hampering their ability to innovate and compete in the global market. Additionally, government ownership may also expose these companies to political pressures, affecting business decisions and overall competitiveness.
Overall, while the government may intend to support domestic semiconductor chip design companies, acquiring stakes in these firms can lead to unintended consequences and hinder long-term growth and competitiveness in the industry. In return, what the government should do is remove the funding barriers that currently exist. “Removing barriers through facilitating more FDI and long-term foreign-domestic private sector linkages can help integrate India’s semiconductor design market with the global markets,” Kotasthane added.
India’s semiconductor ambitions
So far, the government of India has approved five players under the DLI scheme, Vaishnaw said while speaking at the Bharat 6G Alliance, the Centre for Development of Advance Computing (C-DAC), earlier this month. During the same time, it was also announced that US-based Micron technology and the Gujarat government signed a Memorandum of Understanding (MoU) to set up an ATMP (assembly, test, marking, and packaging) facility in the state.
However, previously, a joint venture between Vedanta Limited and with Taiwanese electronics manufacturer Foxconn had announced that it will set up its semiconductor and display manufacturing facility at the Dholera Special Investment Region near Ahmedabad, Gujarat.
But as it stands, the JV no longer exists and both parties are seeking new partners to set up fabs in the country. While Vedanta is yet to find a partner, reports suggest Foxconn could partner with TSMC and Japan’s TMH Group to keep its ambitions of building chips in India alive. Other players to have shown interest include Tata Electronics, IGSS Ventures, and ISMC; however, nothing concrete has happened on either front.
The post Why Government Intervention in Chip Design is a Bad Idea appeared first on Analytics India Magazine.
Over the past few months, we've put a lot of time into exploring how ChatGPT can help us write code. In this article, I'm going to take you through the process of using ChatGPT to do just that.
As part of my daily flow, there's an annoyance I wanted to address. Creating the "Also" references in my ZDNET articles takes a bunch of steps. For reference, here's one such Also link:
Also: Okay, so ChatGPT just debugged my code. For real.
Doing that takes a series of steps (shown below), which I wanted to eliminate. I do a bunch of these in most articles, and it's not only annoying, it's rough on my wrist.
But is it possible, without writing a single line of actual code, to create a JavaScript bookmarklet to eliminate this annoyance? Can non-programmers accomplish small projects like this?
The answer is yes. But it's not as quick or intuitive as you might like.
I recorded each of the steps I took to create this capability in a series of diary-like log entries. I tend to work on projects like this by doing a little bit, recording my thoughts and observations, then stepping away to let that percolate in my brain while working on other deadline assignments. Then I come back, do a bit more, and write a bit more.
By reading the log entries, you will be able to get a feel for the process of ChatGPT programming-through-prompting. At the end, I'll discuss any insights the process has helped me discover.
Let's get started.
Log Entry 001 — Friday, 2:10pm
So, I just decided it's time to have ChatGPT write some code for me. There's a repetitive task I do all the time, multiple times during the day, and it's time to have a button that saves me steps. I'm going to think on this while working on another article.
Log Entry 002 — Friday, 2:45pm
It turns out it's not as easy as all that. You can't just tell ChatGPT to "write me a button that saves me steps." You actually have to be able to describe what you want it to do. That is a skill all by itself.
Now, fortunately, I've been coding for decades, so I know how to create a specification and even how to just describe what I want. Time to think. I'll be back.
Log Entry 003 — Friday, 4:02pm
Okay, so first I have to be able to describe what I want. Once I've described it, I can go and try to make ChatGPT give me code to automate this process. I want something that reduces the clicks involved in making our Also links.
That link consists of a few elements:
The string "Also: ". Note that it has a colon followed by a space
The name of an article, turned into a hyperlink
The entire thing done in boldface
It seems simple enough, but here are the steps I take each time I want to make one of these.
Find the article I want to "Also". This I won't automate, since it's different each time.
Go to that article's page. This, too, I won't automate. But I want to automate everything that follows.
Copy the title of the article
Switch to the ZDNET CMS and click on the line where I want to insert the Also.
Type the string "Also: "
Click after "Also: " and select Paste and Match Style from the Edit Menu. I can't use the ^V keyboard shortcut because otherwise I'll get a huge headline font. And I can't use the Paste and Match Style keyboard shortcut because it requires pressing too many keys at once to reliably do each time.
Now, switch back to the article and copy the URL.
Switch back to the CMS
Select the headline just pasted
Type ^K as a shortcut, which opens the insert link dialog.
Paste in the URL, click OK.
Select the entire line
Boldface the text.
That's basically 11 steps, a bunch of mouse clicks, some click and drags, and a bunch of keypresses. I want to reduce that to one click and one paste.
Log Entry 004 — Friday, 4:57pm
That was definitely a description of my process, and it also describes a couple of problems. But it doesn't say anything about what, exactly, I want in a new tool. For ChatGPT to write the code, it has to know what I want it to do. More thinky time.
Log Entry 005 — Friday, 7:12pm
I decided that, rather than do a Chrome extension, I'll do a JavaScript bookmarklet. Those are easy to add to a bookmark bar, and don't require a lot of extra installation hassle. All you have to do is right-click on a bookmark bar, choose Add page, and (1) enter the title. The JavaScript itself gets pasted into the URL field (2).
Here's a first draft of what I want this new bookmarklet to do.
I want to create a JavaScript bookmarklet. When pressed, it retrieves the current URL of the current page. It also retrieves the title of the page. It places a piece of rich text into the clipboard that consists of the string "Also: " followed by a rich text link with the title of the link and the retrieved URL. The entire rich text block needs to be bolded.
If I can get ChatGPT to give me something that works, all I'll have to do is click the button, switch over to the CMS, find my spot, and paste. Much faster.
Now, all I have left to do is…everything.
Log Entry 006 — Saturday, 8:30am
I'm brave. I decided I'm going to feed the exact description above to ChatGPT and see if it will give me code that works. Hey, it's worth a try.
Log Entry 007 — Saturday, 8:41am
Well, that totally didn't work. All it did was keep whatever was previously in my clipboard. But part of ChatGPT's response gave me some pause.
It's also important to mention that the document.execCommand('copy') is marked as obsolete in modern browsers (e.g., Chrome, Firefox), as they suggest using the Clipboard API, but as of my knowledge cutoff in 2021, the Clipboard API doesn't support copying rich text to clipboard directly.
So, the code it knows might be obsolete. Let's try to see if we can use ChatGPT Plus's plugins with the WebSearchG plugin.
Well, that also didn't work. Instead of code, I was sent to sites like Stack Overflow to read articles on how to manage clipboard data.
This won't do. I'm trying to get ChatGPT to do my programming for me. Let's try the ChatGPT Plus add-on Code Interpreter and see if it can help.
Log Entry 008 — Saturday, 9:08am
That didn't work either. It responded with:
Unfortunately, as of my knowledge cutoff in September 2021, there's no direct and universally supported way to copy rich text to the clipboard using JavaScript.
Rats! Foiled again! Time for more coffee.
Log Entry 009 — Saturday, 10:27am
I've been thinking on this a while (and fueling with more coffee). Perhaps the phrase "universally supported" needs to be addressed. I'm changing my first line from "I want to create a JavaScript bookmarklet." to "I want to create a JavaScript bookmarklet in Chrome."
Let's see what that does.
Log Entry 010 — Saturday, 10:33am
Well, no. That gave me back the HTML in text form. That's not something I can directly paste into the CMS. I need it to return rich text on the clipboard.
Log Entry 011 — Saturday, 11:20am
I'm thinking that maybe ChatGPT Plus didn't use Code Interpreter, even though it was enabled. To use plugins, sometimes you have to explicitly tell ChatGPT to do so. Let's try this as my opening line:
Use code interpreter for current browser api calls. I want to create a JavaScript bookmarklet.
Oh, yeah. That works! Check it out. This was created with a single click on my bookmarklet:
Also: I used ChatGPT to write the same routine in 12 top programming languages. Here's how it did | ZDNET
Log Entry 012 — Saturday 1:04pm
The fact that this works as well as it does is just super-cool.
That said, I don't like the " | ZDNET" at the end of the string. So I'm going to see if I can convince it to remove it.
Log Entry 013 — Saturday 2:27pm
Lunch was nice. Fresh, wild-caught rockfish from right here in the Pacific Northwest. It's pretty inexpensive because it's a local catch. A little lemon and Old Bay. Brain food. And with that…
I'm at an interesting decision point. There are three ways I can proceed.
One is to try to modify the original prompt to add the new features I want. That's the best choice if I have to start a completely new session.
The gotcha to that approach is that ChatGPT doesn't always return the same results when asked the same question. So if I feed it an extended prompt, I might get back something that works, I might get back something that partially works, or it might decide to go completely afield and recount to me the titles of the works of William Shakespeare in conversational Klingon.
The second approach is to write a prompt that asks ChatGPT to modify the previously provided code with the new feature. This will work if the session is still active.
A third approach is to feed ChatGPT the code it previously generated and ask it to make changes. I like that approach, but it's a bit messier.
For now, I'm going to try the second approach. I'm going to see if I can convince it to drop the " | ZDNET" string at the end of the title. Let's try this as a prompt:
Please modify the previously-generated code and remove the string " | ZDNET" at the end of any titles where it exists. Make that feature case insensitive.
Okay, so that broke the script. As with a previous time when it didn't work, it's just keeping whatever was previously in my clipboard.
Let's try the first option, modifying the full prompt. I'm going to add the mini-prompt to the end of the main prompt, launch a new session, and see if I get any joy.
On my first try, it failed. But then I specified I wanted it to create "a JavaScript bookmarklet for Chrome," and it worked!
Check it out. Here are two Also links created with my AI-written bookmarklet.
Also: How to use ChatGPT to write code
…and..
Also: I'm using ChatGPT to help me fix code faster, but at what cost?
The final code
Functionally, my code is complete. Here's the final code block provided by ChatGPT:
And here's the final prompt I ended up using. Note that this requires ChatGPT Plus, GPT-4, and the Code Interpreter add-on.
Use code interpreter for current browser API calls. I want to create a JavaScript bookmarklet for Chrome.
When pressed, it retrieves the current URL of the current page. It also retrieves the title of the page. If the title of the page ends with " | ZDNET" (case insensitive), it removes that string from the end of the title.
It places a piece of rich text into the clipboard that consists of the string "Also: " followed by a rich text link with the title of the link and the retrieved URL. The entire rich text block needs to be bolded.
Insights and observations
This project was completed almost exactly 24 hours after I started it. Of course, I didn't put in 24 hours of work. I'd say it was probably about 90 minutes of actual work, interspersed with other work, family weekend time, and some thinking time.
This required a lot of thinking.
I've written a lot of JavaScript. While I haven't dealt with rich text all that much, I definitely have the coding experience to have written this from scratch. It wouldn't have taken me just 90 minutes to write, but I probably could have completed it over a weekend.
AI-driven coding is a very different mindset. While both doing your own coding and using the AI require a very clear understanding of what you want the code to do, the way of constructing the final product is very different.
I've said this before, but it was proven here: coding using the AI feels a lot like managing another programmer. Coding is syntax and algorithms, a mind-meld between my brain and my development system.
With code, especially such a small project as this, it's pretty easy to figure out why something's not working. But with AI-generated code, who knows? There's a lot of guesswork. Even the AI doesn't really know. One minute it will tell you it "can't do that," and the next, it does it.
It feels a lot more like negotiating with Scotty from Star Trek (who always used to tell Captain Kirk it couldn't be done or quote an excessive turnaround time so he'd later look good) than chiseling working code out of the raw ASCII produced by every keyboard.
There are places where knowing how code works helped in instructing the AI. For example, I told it to filter for ZDNET but ignore case. That's because I know that we might find ZDNET, ZDNet, and possibly other formats. I can't tell you how many times I've been stung by a case dependency.
I also needed to know that the output produced is called "rich text." That's not something someone with no programming experience is likely to know. So, for such a person, there might have been a lot more frustration getting the AI to place the right data on the clipboard.
As part of this experiment, I wouldn't let myself touch the code. Other than copying it from ChatGPT and pasting it into my bookmarklet, I didn't touch, modify, change, or enhance the JavaScript code.
Still, I did get a working bookmarklet that will, without a doubt, save me (and my editors) time and annoyance. And that's very cool. I am seriously wildly stoked about having this feature. Because I do these Also lines so much, and they are so tedious, this new two-clicks feature makes me very happy. I'll give this point to ChatGPT's coding chops.
Just don't confuse getting ChatGPT to write a very small, pinpoint application with thinking it can tackle a big project. All the skills of project management, product specification, team management, production, and testing are needed. Those don't replace easily with an AI.
If you want to build something for your own use, go for it and tell us about it. What would you ask ChatGPT to build for you? What functionality could a bookmarklet offer that can save you time? Let us know in the comments below.
You can follow my day-to-day project updates on social media. Be sure to subscribe to my weekly update newsletter on Substack, and follow me on Twitter at @DavidGewirtz, on Facebook at Facebook.com/DavidGewirtz, on Instagram at Instagram.com/DavidGewirtz, and on YouTube at YouTube.com/DavidGewirtzTV.
In a very unfortunate incident, one of the students reached out to director of the Distributed Artificial Intelligence Research Institute (DAIR) and former Google ethicist Timnit Gebru, expressing concern when they were graded zero because an evaluation platform Turnitin stated that 67% of paper was written by AI which the student claims is untrue.
“How many people’s lives are being ruined like this. This should be unacceptable,” avered Gebru.
She said that the student currently stands with a 4.0 GPA and is a member of the President’s Honor Roll at the University. “I have tried understanding Turnitin’s methods of distinguishing AI and I still do not see how it fits within my writing,” shared Gebru, recalling the email interaction with the student.
All of this ain’t new. In another incident, a professor at the University of Texas failed the entire class because he thought the students had cheated from ChatGPT. The professor attempted to use ChatGPT to check if his students had plagiarised their assigned essays or if they had submitted original work. However, ChatGPT made an erroneous identification, flagging the students’ essays as being generated by a computer program.
Gebru had previously argued that AI systems like ChatGPT and Google Bard lack the capacity to comprehend the meaning or significance of the words they process, no matter how convincing their language is. Her former colleague Alex Hanna, also, called these platforms “Bulls*** generators.”
False Positives
Timnit seem to have taken the conversation to a whole new level, questioning the working of Turnitin’s AI detection tool, and its impact on students
Turnitin, known for checking for plagiarism for over the years, is currently being used in 10,700 secondary and higher-educational institutions, assigning “generated by AI” scores and sentence-by-sentence analysis to student work. Turnitin’s AI writing detection model is trained to detect content from the GPT-3 and GPT-3.5 language models, which includes ChatGPT. Turnitin says that text generated by ChatGPT follows a pattern and is predictable while on the other hand human writing tends to be unique and unpredictable. This method cannot be trusted blindly as it merely predicts if the text is generated by AI or not.
In a blog post Turnitin accepted that their model is not foolproof and tends to make mistakes.
However, these mistakes can have serious consequences for students. They can damage their academic standing, which, in turn, might impact their future career prospects. Besides, such incidents take an emotional toll on students, causing them stress, anxiety and mental trauma as they have to defend the authenticity of their original work.
Turnitin has two metrics to determine if text is AI generated or not. First is the document level and second is sentence level. On document level Turnit in has 1% chance of false positives.
On sentence-level false positive rate is approx 4%. This means that the specific sentence it highlights may be human-written 4 times for every 100 highlighted sentences. Even a 4, or merely 1 percent error rate might seem insignificant, but every wrongful accusation of cheating can result in disastrous consequences for a student.
According to Turnitin Chief Product Officer Annie Chechitelli, in cases where it detects less than 20% of AI writing in a document, there is a higher incidence of false positives.
Meanwhile, the Washington Post carried out a test on 16 samples of real, AI-fabricated and mixed-source essays to run past Turnitin’s detector. Turnitin identified only six out of 16 samples, completely failed on three, showed 8 percent of plagiarism on an original essay.
Masking their inability to assess accurately, Turnitin said AI writing detection false positive rate is not zero and the instructor will need to apply their professional judgment, knowledge of students, and the specific context surrounding the assignment.
Turnitin’s FAQ page only mentions that it is trained on GPT-3 and 3.5 models without providing further details about the specific parameters or models used. In contrast to Grammarly, which offers links to the original sources of copied content, detecting AI-generated content is more complex since it doesn’t exist elsewhere but is predicted to be generated by generative AI.The swift implementation of Turnitin’s AI detection software in schools raises concerns about the accuracy and fairness of its testing.
What’s the solution?
Besides Turnitin, GPTZero is known for quickly and efficiently detecting whether a text is ChatGPT-written or human-written. There are a slew of tools that detect AI generated content. Some of them include GPTZeroX, Detect GPT, Originality.ai and others. Again, the fairness and effectiveness of these models still remain dark and scary.
It is crucial to monitor Turnitin’s software to ensure it offers precise and impartial evaluations while minimizing any potential harm to innocent students who might get caught in its system. It also becomes imperative for teachers and educators to explore new methods to check AI generated content,or eliminate it entirely. “Was talking to my cousin in high school about ChatGPT,” said the founder of healthcare startup Rupa Health, Tara Viswanathan, saying that they now must submit homework via Google Docs so the teacher can view the history to see if they really wrote it or not.
The post Turnitin Turns Off Timnit appeared first on Analytics India Magazine.
One-hot encoding is a data preprocessing step to convert categorical values into compatible numerical representations.
categorical_column
bool_col
col_1
col_2
label
value_A
True
9
4
0
value_B
False
7
2
0
value_D
True
9
5
0
value_D
False
8
3
1
value_D
False
9
0
1
value_D
False
5
4
1
value_B
True
8
1
1
value_D
True
6
6
1
value_C
True
0
5
0
For example for this dummy dataset, the categorical column has multiple string values. Many machine learning algorithms require the input data to be in numerical form. Therefore, we need some way to convert this data attribute to a form compatible with such algorithms. Thus, we break down the categorical column into multiple binary-valued columns.
How to use Pandas Library for One-Hot Encoding
Firstly, read the .csv file or any other associated file into a Pandas data frame.
df = pd.read_csv("data.csv")
To check unique values and better understand our data, we can use the following Panda functions.
For the categorical column, we can break it down into multiple columns. For this, we use pandas.get_dummies() method. It takes the following arguments:
Argument
data: array-like, Series, or DataFrame
The original panda's data frame object
columns: list-like, default None
List of categorical columns to hot-encode
drop_first: bool, default False
Removes the first level of categorical labels
To better understand the function, let us work on one-hot encoding the dummy dataset.
Hot-Encoding the Categorical Columns
We use the get_dummies method and pass the original data frame as data input. In columns, we pass a list containing only the categorical_column header.
The following commands drops the categorical_column and creates a new column for each unique value. Therefore, the single categorical column is converted into 4 new columns where only one of the 4 columns will have a 1 value, and all of the other 3 are encoded 0. This is why it is called One-Hot Encoding.
categorical_column_value_A
categorical_column_value_B
categorical_column_value_C
categorical_column_value_D
1
0
0
0
0
1
0
0
0
0
0
1
0
0
0
1
0
0
0
1
0
0
0
1
0
1
0
0
0
0
0
1
0
0
1
0
0
0
0
1
The problem occurs when we want to one-hot encode the boolean column. It creates two new columns as well.
We unnecessarily increase a column when we can have only one column where True is encoded to 1 and False is encoded to 0. To solve this, we use the drop_first argument.
The dummy dataset is one-hot encoded where the final result looks like
col_1
col_2
bool
A
B
C
D
label
9
4
1
1
0
0
0
0
7
2
0
0
1
0
0
0
9
5
1
0
0
0
1
0
8
3
0
0
0
0
1
1
9
0
0
0
0
0
1
1
5
4
0
0
0
0
1
1
8
1
1
0
1
0
0
1
6
6
1
0
0
0
1
1
0
5
1
0
0
1
0
0
1
8
1
0
0
0
1
0
The categorical values and boolean values have been converted to numerical values that can be used as input to machine learning algorithms. Muhammad Arham is a Deep Learning Engineer working in Computer Vision and Natural Language Processing. He has worked on the deployment and optimizations of several generative AI applications that reached the global top charts at Vyro.AI. He is interested in building and optimizing machine learning models for intelligent systems and believes in continual improvement.
More On This Topic
Introduction to Pandas for Data Science
Dask and Pandas: No Such Thing as Too Much Data
Data Ingestion with Pandas: A Beginner Tutorial
Simplify Data Processing with Pandas Pipeline
The Optimal Way to Input Missing Data with Pandas fillna()
10 Pandas One Liners for Data Access, Manipulation, and Management