July 6th 2022 will be marked down as a landmark in AI history because it was on this day when YOLOv7 was released. Ever since its launch, the YOLOv7 has been the hottest topic in the Computer Vision developer community, and for the right reasons. YOLOv7 is already being regarded as a milestone in the object detection industry.
Shortly after the YOLOv7 paper was published, it turned up as the fastest, and most accurate real-time objection detection model. But how does YOLOv7 outcompete its predecessors? What makes YOLOv7 so efficient in performing computer vision tasks?
In this article we will try to analyze the YOLOv7 model, and try to find the answer to why YOLOv7 is now becoming industry standard? But before we can answer that, we will have to have a look at the brief history of object detection.
What is Object Detection?
Object detection is a branch in computer vision that identifies and locates objects in an image, or a video file. Object detection is the building block of numerous applications including self-driving cars, monitored surveillance, and even robotics.
An object detection model can be classified into two different categories, single-shot detectors, and multi-shot detectors.
Real Time Object Detection
To truly understand how YOLOv7 works, it’s essential for us to understand YOLOv7’s main objective, “Real Time Object Detection”. Real Time Object Detection is a key component of modern computer vision. The Real Time Object Detection models try to identify & locate objects of interest in real time. Real Time Object Detection models made it really efficient for developers to track objects of interest in a moving frame like a video, or a live surveillance input.

Real Time Object Detection models are essentially a step ahead from the conventional image detection models. While the former is used to track objects in video files, the latter locates & identifies objects within a stationary frame like an image.
As a result, Real Time Object Detection models are really efficient for video analytics, autonomous vehicles, object counting, multi-object tracking, and much more.
What is YOLO?
YOLO or “You Only Look Once” is a family of real time object detection models. The YOLO concept was first introduced in 2016 by Joseph Redmon, and it was the talk of the town almost instantly because it was much quicker, and much more accurate than the existing object detection algorithms. It wasn’t long before the YOLO algorithm became a standard in the computer vision industry.

The fundamental concept that the YOLO algorithm proposes is to use an end-to-end neural network using bounding boxes & class probabilities to make predictions in real time. YOLO was different from the previous object detection model in the sense that it proposed a different approach to perform object detection by repurposing classifiers.
The change in approach worked as YOLO soon became the industry standard as the performance gap between itself, and other real time object detection algorithms were significant. But what was the reason why YOLO was so efficient?
When compared to YOLO, object detection algorithms back then used Region Proposal Networks to detect possible regions of interest. The recognition process was then performed on each region separately. As a result, these models often performed multiple iterations on the same image, and hence the lack of accuracy, and higher execution time. On the other hand, the YOLO algorithm uses a single fully connected layer to perform the prediction at once.
How Does YOLO Work?
There are three steps that explain how a YOLO algorithm works.
Reframing Object Detection as a Single Regression Problem
The YOLO algorithm tries to reframe object detection as a single regression problem, including image pixels, to class probabilities, and bounding box coordinates. Hence, the algorithm has to look at the image only once to predict & locate the target objects in the images.
Reasons the Image Globally
Furthermore, when the YOLO algorithm makes predictions, it reasons the image globally. It’s different from region proposal-based, and sliding techniques as the YOLO algorithm sees the complete image during training & testing on the dataset, and is able to encode contextual information about the classes, and how they appear.
Before YOLO, Fast R-CNN was one of the most popular object detection algorithms that couldn’t see the larger context in the image because it used to mistake background patches in an image for an object. When compared to the Fast R-CNN algorithm, YOLO is 50% more accurate when it comes to background errors.
Generalizes Representation of Objects
Finally, the YOLO algorithm also aims at generalizing the representations of objects in an image. As a result, when a YOLO algorithm was run on a dataset with natural images, and tested for the results, YOLO outperformed existing R-CNN models by a wide margin. It’s because YOLO is highly generalizable, the chances of it breaking down when implemented on unexpected inputs or new domains were slim.
YOLOv7: What’s New?
Now that we have a basic understanding of what real time object detection models are, and what is the YOLO algorithm, it’s time to discuss the YOLOv7 algorithm.
Optimizing the Training Process
The YOLOv7 algorithm not only tries to optimize the model architecture, but it also aims at optimizing the training process. It aims at using optimization modules & methods to improve the accuracy of object detection, strengthening the cost for training, while maintaining the interference cost. These optimization modules can be referred to as a trainable bag of freebies.
Coarse to Fine Lead Guided Label Assignment
The YOLOv7 algorithm plans to use a new Coarse to Fine Lead Guided Label Assignment instead of the conventional Dynamic Label Assignment. It is so because with dynamic label assignment, training a model with multiple output layers causes some issues, the most common one of it being how to assign dynamic targets for different branches and their outputs.
Model Re-Parameterization
Model re-parametrization is an important concept in object detection, and its use is generally followed with some issues during training. The YOLOv7 algorithm plans on using the concept of gradient propagation path to analyze the model re-parametrization policies applicable to different layers in the network.
Extend and Compound Scaling
The YOLOv7 algorithm also introduces the extended and compound scaling methods to utilize and effectively use the parameters & computations for real time object detection.

YOLOv7 : Related Work
Real Time Object Detection
YOLO is currently the industry standard, and most of the real time object detectors deploy YOLO algorithms, and FCOS (Fully Convolutional One-Stage Object-Detection). A state of the art real time object detector usually has the following characteristics
- Stronger & faster network architecture.
- An effective feature integration method.
- An accurate object detection method.
- A robust loss function.
- An efficient label assignment method.
- An efficient training method.
The YOLOv7 algorithm does not use self-supervised learning & distillation methods that often require large amounts of data. Conversely, the YOLOv7 algorithm uses a trainable bag-of-freebies method.
Model Re-Parameterization
Model re-parameterization techniques is regarded as an ensemble technique that merges multiple computational modules in an interference stage. The technique can be further divided into two categories, model-level ensemble, and module-level ensemble.
Now, to obtain the final interference model, the model-level reparameterization technique uses two practices. The first practice uses different training data to train numerous identical models, and then averages the weights of the trained models. Alternatively, the other practice averages the weights of models during different iterations.
Module level re-parameterization is gaining immense popularity recently because it splits a module into different module branches, or different identical branches during the training phase, and then proceeds to integrate these different branches into an equivalent module while interference.
However, re-parameterization techniques cannot be applied to all kinds of architecture. It’s the reason why the YOLOv7 algorithm uses new model re-parameterization techniques to design related strategies suited for different architectures.
Model Scaling
Model scaling is the process of scaling up or down an existing model so it fits across different computing devices. Model scaling generally uses a variety of factors like number of layers(depth), size of input images(resolution), number of feature pyramids(stage), and number of channels(width). These factors play a crucial role in ensuring a balanced trade off for network parameters, interference speed, computation, and accuracy of the model.
One of the most commonly used scaling methods is NAS or Network Architecture Search that automatically searches for suitable scaling factors from search engines without any complicated rules. The major downside of using the NAS is that it’s an expensive approach for searching suitable scaling factors.
Almost every model re-parameterization model analyzes individual & unique scaling factors independently, and furthermore, even optimizes these factors independently. It’s because the NAS architecture works with non-correlated scaling factors.
It’s worth noting that concatenation-based models like VoVNet or DenseNet change the input width of a few layers when the depth of the models is scaled. YOLOv7 works on a proposed concatenation-based architecture, and hence uses a compound scaling method.

The figure mentioned above compares the extended efficient layer aggregation networks (E-ELAN) of different models. The proposed E-ELAN method maintains the gradient transmission path of the original architecture, but aims at increasing the cardinality of the added features using group convolution. The process can enhance the features learned by different maps, and can further make the use of calculations & parameters more efficient.
YOLOv7 Architecture
The YOLOv7 model uses the YOLOv4, YOLO-R, and the Scaled YOLOv4 models as its base. The YOLOv7 is a result of the experiments carried out on these models to improve the results, and make the model more accurate.
Extended Efficient Layer Aggregation Network or E-ELAN
E-ELAN is the fundamental building block of the YOLOv7 model, and it is derived from already existing models on network efficiency, mainly the ELAN.
The main considerations when designing an efficient architecture are the number of parameters, computational density, and the amount of computation. Other models also consider factors like influence of input/output channel ratio, branches in the architecture network, network interference speed, number of elements in the tensors of convolutional network, and more.
The CSPVoNet model not only considers the above-mentioned parameters, but it also analyzes the gradient path to learn more diverse features by enabling the weights of different layers. The approach allows the interferences to be much faster, and accurate. The ELAN architecture aims at designing an efficient network to control the shortest longest gradient path so that the network can be more effective in learning, and converging.
ELAN has already reached a stable stage regardless of the stacking number of computational blocks, and gradient path length. The stable state might be destroyed if computational blocks are stacked unlimitedly, and the parameter utilization rate will diminish. The proposed E-ELAN architecture can solve the issue as it uses expansion, shuffling, and merging cardinality to continuously enhance the network’s learning ability while retaining the original gradient path.
Furthermore, when comparing the architecture of E-ELAN with ELAN, the only difference is in the computational block, while the transition layer’s architecture is unchanged.
E-ELAN proposes to expand the cardinality of the computational blocks, and expand the channel by using group convolution. The feature map will then be calculated, and shuffled into groups as per the group parameter, and will then be concatenated together. The number of channels in each group will remain the same as in the original architecture. Lastly, the groups of feature maps will be added to perform cardinality.
Model Scaling for Concatenation Based Models
Model scaling helps in adjusting attributes of the models that helps in generating models as per the requirements, and of different scales to meet the different interference speeds.

The figure talks about model scaling for different concatenation-based models. As you can in figure (a) and (b), the output width of the computational block increases with an increase in the depth scaling of the models. Resultantly, the input width of the transmission layers is increased. If these methods are implemented on concatenation-based architecture the scaling process is performed in depth, and it’s depicted in figure (c).
It can thus be concluded that it’s not possible to analyze the scaling factors independently for concatenation-based models, and rather they must be considered or analyzed together. Therefore, for a concatenation based model, it's suitable to use the corresponding compound model scaling method. Additionally, when the depth factor is scaled, the output channel of the block must be scaled as well.
Trainable Bag of Freebies
A bag of freebies is a term that developers use to describe a set of methods or techniques that can alter the training strategy or cost in an attempt to boost model accuracy. So what are these trainable bags of freebies in YOLOv7? Let’s have a look.
Planned Re-Parameterized Convolution
The YOLOv7 algorithm uses gradient flow propagation paths to determine how to ideally combine a network with the re-parameterized convolution. This approach by YOLov7 is an attempt to counter RepConv algorithm that although has performed serenely on the VGG model, performs poorly when applied directly to the DenseNet and ResNet models.
To identify the connections in a convolutional layer, the RepConv algorithm combines 3×3 convolution, and 1×1 convolution. If we analyze the algorithm, its performance, and the architecture we will observe that RepConv destroys the concatenation in DenseNet, and the residual in ResNet.

The image above depicts a planned re-parameterized model. It can be seen that the YOLov7 algorithm found that a layer in the network with concatenation or residual connections should not have an identity connection in the RepConv algorithm. Resultantly, it's acceptable to switch with RepConvN with no identity connections.
Coarse for Auxiliary and Fine for Lead Loss
Deep Supervision is a branch in computer science that often finds its use in the training process of deep networks. The fundamental principle of deep supervision is that it adds an additional auxiliary head in the middle layers of the network along with the shallow network weights with assistant loss as its guide. The YOLOv7 algorithm refers to the head that’s responsible for the final output as the lead head, and the auxiliary head is the head that assists in training.
Moving along, YOLOv7 uses a different method for label assignment. Conventionally, label assignment has been used to generate labels by referring directly to the ground truth, and on the basis of a given set of rules. However, in recent years, the distribution, and quality of the prediction input plays an important role to generate a reliable label. YOLOv7 generates a soft label of the object by using the predictions of bounding box and ground truth.
Furthermore, the new label assignment method of the YOLOv7 algorithm uses lead head’s predictions to guide both the lead & the auxiliary head. The label assignment method has two proposed strategies.
Lead Head Guided Label Assigner
The strategy makes calculations on the basis of the lead head’s prediction results, and the ground truth, and then uses optimization to generate soft labels. These soft labels are then used as the training model for both the lead head, and the auxiliary head.
The strategy works on the assumption that because the lead head has a greater learning capability, the labels it generates should be more representative, and correlate between the source & the target.
Coarse-to-Fine Lead Head Guided Label Assigner
This strategy also makes calculations on the basis of the lead head’s prediction results, and the ground truth, and then uses optimization to generate soft labels. However, there’s a key difference. In this strategy, there are two sets of soft labels, coarse level, and fine label.
The coarse label is generated by by relaxing the constraints of the positive sample
assignment process that treats more grids as positive targets. It’s done to avoid the risk of losing information because of the auxiliary head’s weaker learning strength.

The figure above explains the use of a trainable bag of freebies in the YOLOv7 algorithm. It depicts coarse for the auxiliary head, and fine for the lead head. When we compare a Model with Auxiliary Head(b) with the Normal Model (a), we will observe that the schema in (b) has an auxiliary head, while it’s not in (a).
Figure (c) depicts the common independent label assigner while figure (d) & figure (e) respectively represent the Lead Guided Assigner, and the Coarse-toFine Lead Guided Assigner used by YOLOv7.
Other Trainable Bag of Freebies
In addition to the ones mentioned above, the YOLOv7 algorithm uses additional bags of freebies, although they were not proposed by them originally. They are
- Batch Normalization in Conv-Bn-Activation Technology: This strategy is used to connect a convolutional layer directly to the batch normalization layer.
- Implicit Knowledge in YOLOR: The YOLOv7 combines the strategy with the Convolutional feature map.
- EMA Model: The EMA model is used as a final reference model in YOLOv7 although its primary use is to be used in the mean teacher method.
YOLOv7 : Experiments
Experimental Setup
The YOLOv7 algorithm uses the Microsoft COCO dataset for training and validating their object detection model, and not all of these experiments use a pre-trained model. The developers used the 2017 train dataset for training, and used the 2017 validation dataset for selecting the hyperparameters. Finally, the performance of the YOLOv7 object detection results are compared with state of the art algorithms for object detection.
Developers designed a basic model for edge GPU (YOLOv7-tiny), normal GPU (YOLOv7), and cloud GPU (YOLOv7-W6). Furthermore, the YOLOv7 algorithm also uses a basic model for model scaling as per different service requirements, and gets different models. For the YOLOv7 algorithm the stack scaling is done on the neck, and proposed compounds are used to upscale the depth & width of the model.
Baselines
The YOLOv7 algorithm uses previous YOLO models, and the YOLOR object detection algorithm as its baseline.

The above figure compares the baseline of the YOLOv7 model with other object detection models, and the results are quite evident. When compared with the YOLOv4 algorithm, YOLOv7 not only uses 75% less parameters, but it also uses 15% less computation, and has 0.4% higher accuracy.
Comparison with State of the Art Object Detector Models

The above figure shows the results when YOLOv7 is compared against state of the art object detection models for mobile & general GPUs. It can be observed that the method proposed by the YOLOv7 algorithm has the best speed-accuracy trade-off score.
Ablation Study : Proposed Compound Scaling Method

The figure shown above compares the results of using different strategies for scaling up the model. The scaling strategy in the YOLOv7 model scales up the depth of the computational block by 1.5 times, and scales the width by 1.25 times.
When compared with a model that only scales up the depth, the YOLOv7 model performs better by 0.5% while using less parameters, and computation power. On the other hand, when compared with models that only scale up the depth, YOLOv7’s accuracy is improved by 0.2%, but the number of parameters need to be scaled by 2.9%, and computation by 1.2%.
Proposed Planned Re-Parameterized Model
To verify the generality of its proposed re-parameterized model, the YOLOv7 algorithm uses it on residual-based, and concatenation based models for verification. For the verification process, the YOLOv7 algorithm uses 3-stacked ELAN for the concatenation-based model, and CSPDarknet for residual-based model.
For the concatenation-based model, the algorithm replaces the 3×3 convolutional layers in the 3-stacked ELAN with RepConv. The figure below shows the detailed configuration of Planned RepConv, and 3-stacked ELAN.
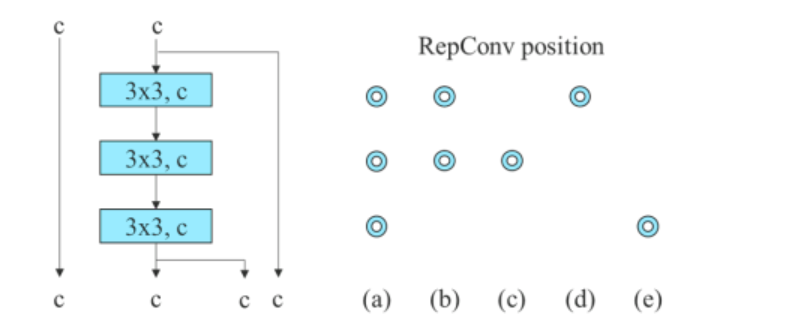
Furthermore, when dealing with the residual-based model, the YOLOv7 algorithm uses a reversed dark block because the original dark block does not have a 3×3 convolution block. The below figure shows the architecture of the Reversed CSPDarknet that reverses the positions of the 3×3 and the 1×1 convolutional layer. 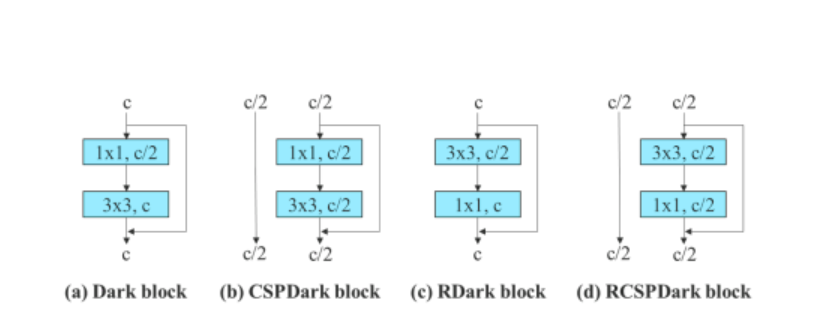
Proposed Assistant Loss for Auxiliary Head
For the assistant loss for auxiliary head, the YOLOv7 model compares the independent label assignment for the auxiliary head & lead head methods.

The figure above contains the results of the study on the proposed auxiliary head. It can be seen that the overall performance of the model increases with an increase in the assistant loss. Furthermore, the lead guided label assignment proposed by the YOLOv7 model performs better than independent lead assignment strategies.
YOLOv7 Results
Based on the above experiments, here’s the result of YOLov7’s performance when compared to other object detection algorithms.

The above figure compares the YOLOv7 model with other object detection algorithms, and it can be clearly observed that the YOLOv7 surpasses other objection detection models in terms of Average Precision (AP) v/s batch interference.
Furthermore, the below figure compares the performance of YOLOv7 v/s other real time objection detection algorithms. Once again, YOLOv7 succeeds other models in terms of the overall performance, accuracy, and efficiency.

Here are some additional observations from the YOLOv7 results & performances.
- The YOLOv7-Tiny is the smallest model in the YOLO family, with over 6 million parameters. The YOLOv7-Tiny has an Average Precision of 35.2%, and it outperforms the YOLOv4-Tiny models with comparable parameters.
- The YOLOv7 model has over 37 million parameters, and it outperforms models with higher parameters like YOLov4.
- The YOLOv7 model has the highest mAP and FPS rate in the range of 5 to 160 FPS.
Conclusion
YOLO or You Only Look Once is the state of the art object detection model in modern computer vision. The YOLO algorithm is known for its high accuracy, and efficiency, and as a result, it finds extensive application in the real time object detection industry. Ever since the first YOLO algorithm was introduced back in 2016, experiments have allowed developers to improve the model continuously.
The YOLOv7 model is the latest addition in the YOLO family, and it’s the most powerful YOLo algorithm till date. In this article, we have talked about the fundamentals of YOLOv7, and tried to explain what makes YOLOv7 so efficient.







































 HPCwire: Generative AI is still an early development. It’s generally still within the realm of so-called path problems, where a human provides the machine with a desired outcome and the machine obeys the human command by following a step-by-step path to pursue that outcome. At some future point machines should be able to handle insight problems, where they pursue and sometimes achieve innovations without prescribed outcomes. That has great potential benefits for humanity but is that also a cause for concern?
HPCwire: Generative AI is still an early development. It’s generally still within the realm of so-called path problems, where a human provides the machine with a desired outcome and the machine obeys the human command by following a step-by-step path to pursue that outcome. At some future point machines should be able to handle insight problems, where they pursue and sometimes achieve innovations without prescribed outcomes. That has great potential benefits for humanity but is that also a cause for concern?  Muzio: If you grew up with a pet or with animals, you recognized that they could think, plan, and had feelings, i.e., they had intelligence. Two millennia ago, the ancient Romans recognized that octopodes were uniquely intelligent. Some birds are able to count. Researchers have found that plants can recognize insect threats and communicate. In my presentation, I mentioned two books, both published in 2022, An Immense World by Ed Yong and Ways of Being: Animals, Plants, Machines-The Search for Planetary Intelligence by James Bridle. Both books have extensive citations to refereed research publications. Both books give you a different perspective on intelligence.
Muzio: If you grew up with a pet or with animals, you recognized that they could think, plan, and had feelings, i.e., they had intelligence. Two millennia ago, the ancient Romans recognized that octopodes were uniquely intelligent. Some birds are able to count. Researchers have found that plants can recognize insect threats and communicate. In my presentation, I mentioned two books, both published in 2022, An Immense World by Ed Yong and Ways of Being: Animals, Plants, Machines-The Search for Planetary Intelligence by James Bridle. Both books have extensive citations to refereed research publications. Both books give you a different perspective on intelligence.