
Image by Author
Data science is an interdisciplinary field that relies heavily on extracting insights and making informed decisions from vast amounts of data. One of the fundamental tools in a data scientist's toolbox is SQL (Structured Query Language), a programming language designed for managing and manipulating relational databases.
In this article, I will focus on one of the most powerful features of SQL: joins.
What Are Joins in SQL?
SQL Joins allow you to combine data from multiple database tables based on common columns. That way, you can merge information together and create meaningful connections between related datasets.
Types of Joins in SQL
There are several types of SQL joins:
- Inner join
- Left outer join
- Right outer join
- Full outer join
- Cross join
Let’s explain each type.
SQL Inner Join
An inner join returns only the rows where there is a match in both tables being joined. It combines rows from two tables based on a shared key or column, discarding non-matching rows.
We visualize this in the following way.
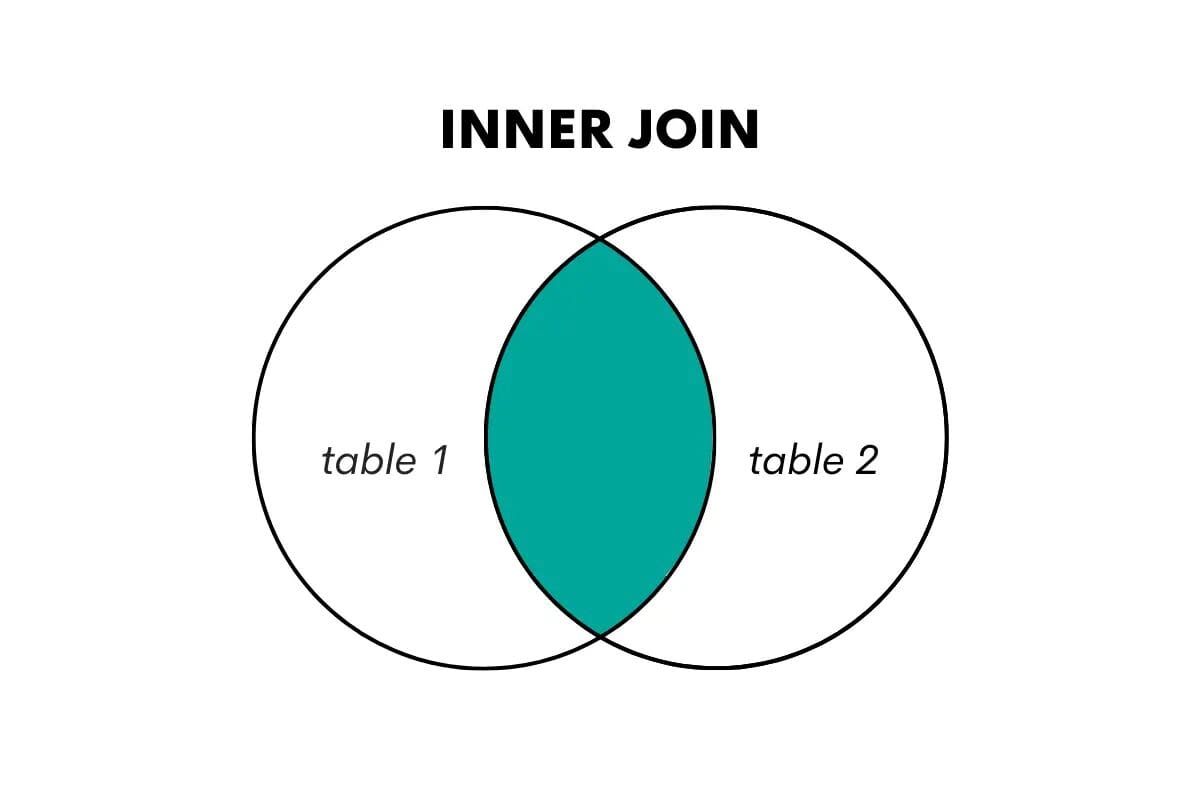
Image by Author
In SQL, this type of join is performed using the keywords JOIN or INNER JOIN.
SQL Left Outer Join
A left outer join returns all the rows from the left (or first) table and the matched rows from the right (or second) table. If there is no match, it returns NULL values for the columns from the right table.
We can visualize it like this.
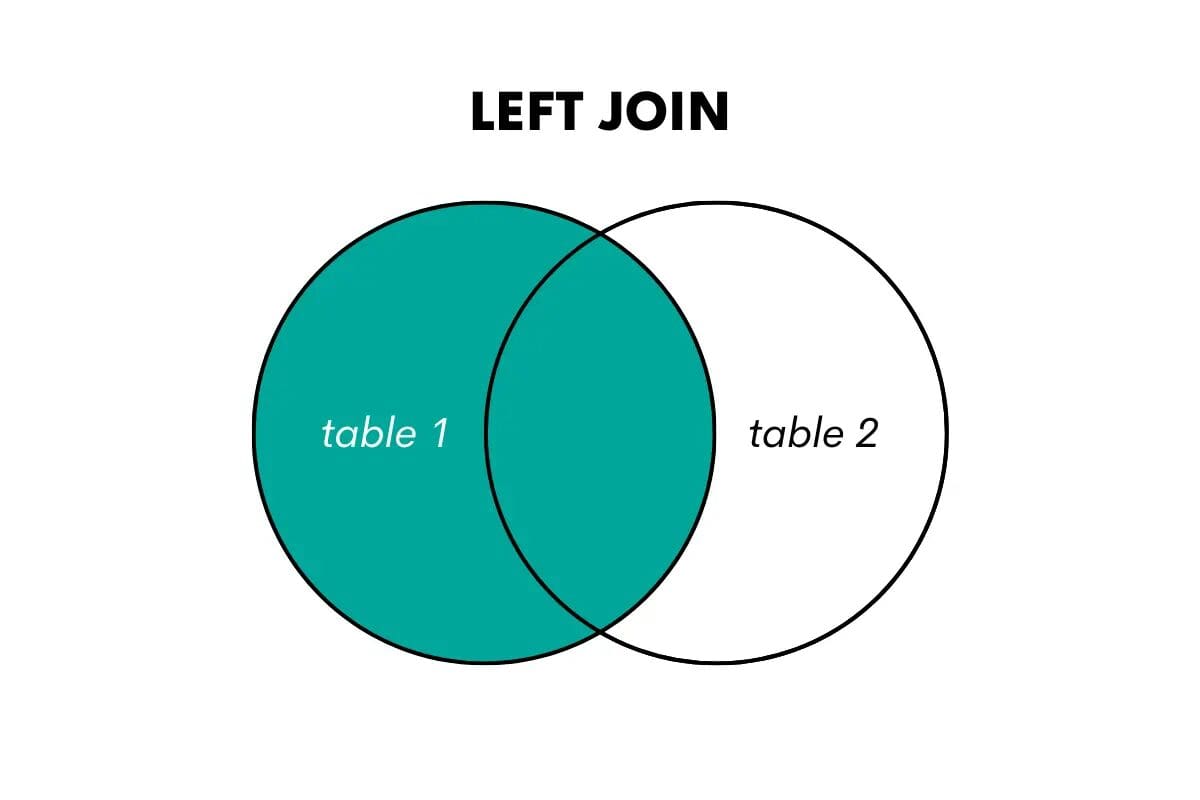
Image by Author
When wanting to use this join in SQL, you can do that by using LEFT OUTER JOIN or LEFT JOIN keywords. Here’s an article that talks about left join vs left outer join.
SQL Right Outer Join
A right join is the opposite of a left join. It returns all the rows from the right table and the matched rows from the left table. If there is no match, it returns NULL values for the columns from the left table.
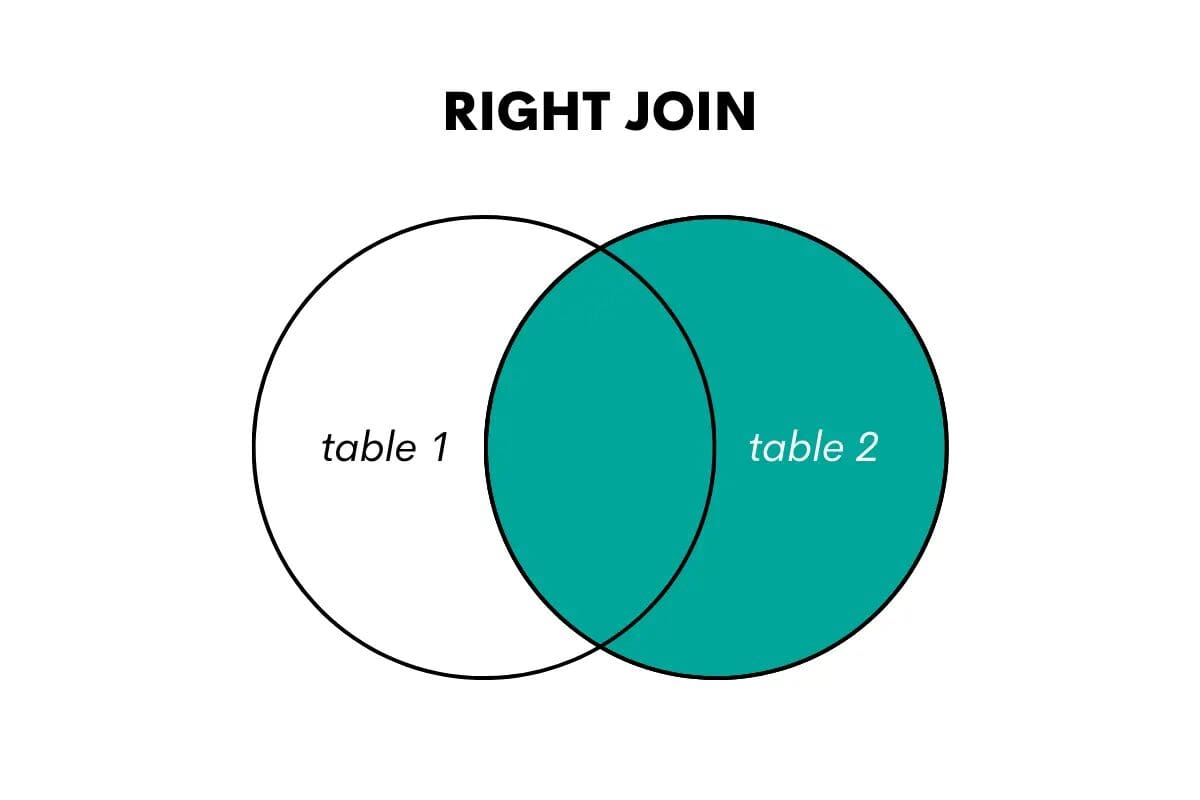
Image by Author
In SQL, this join type is performed using the keywords RIGHT OUTER JOIN or RIGHT JOIN.
SQL Full Outer Join
A full outer join returns all the rows from both tables, matching rows where possible and filling in NULL values for non-matching rows.
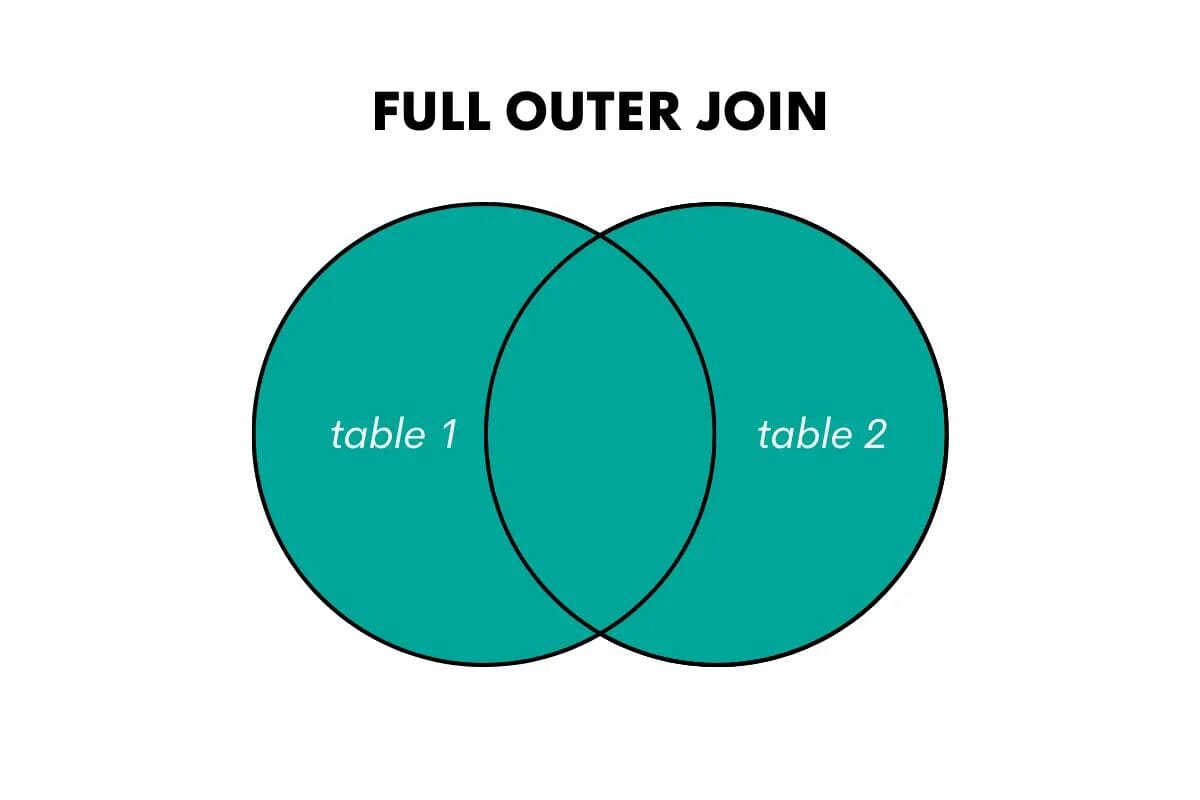
Image by Author
The keywords in SQL for this join are FULL OUTER JOIN or FULL JOIN.
SQL Cross Join
This type of join combines all the rows from one table with all the rows from the second table. In other words, it returns the Cartesian product, i.e., all possible combinations of the two tables’ rows.
Here’s the visualization that will make it easier to understand.
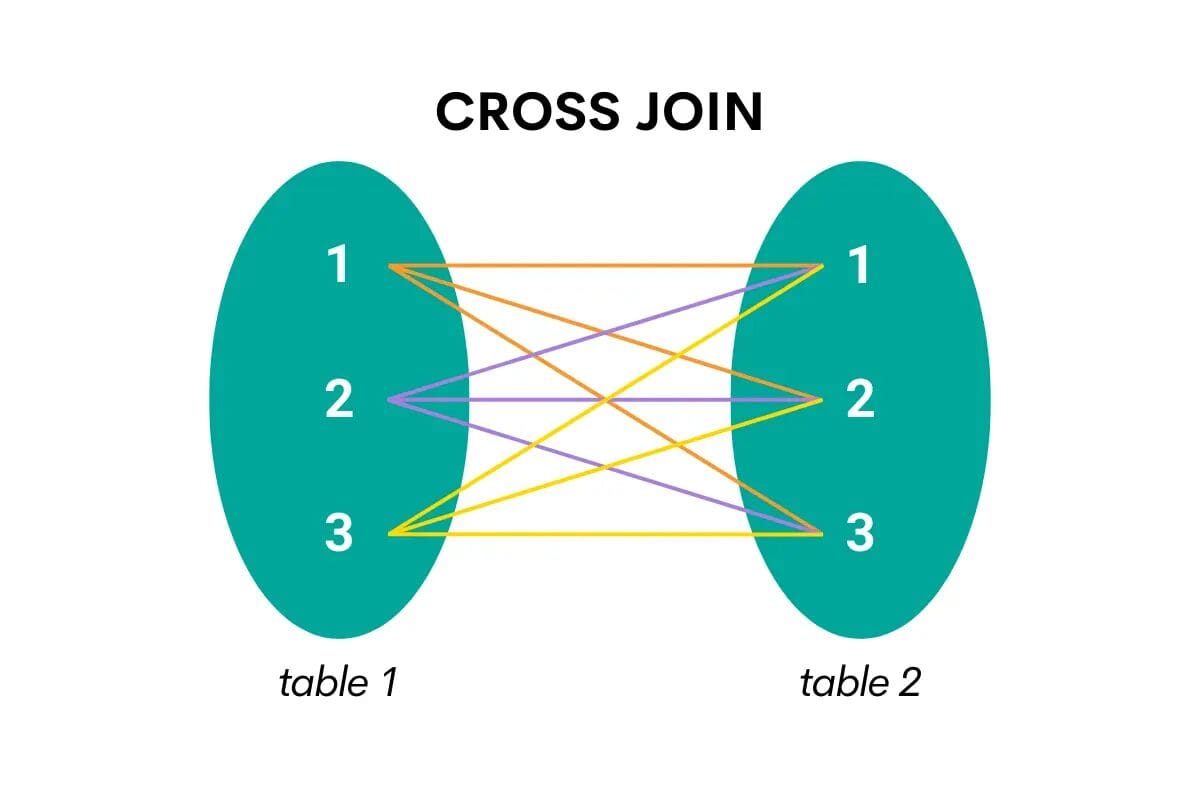
Image by Author
When cross-joining in SQL, the keyword is CROSS JOIN.
Understanding SQL Join Syntax
To perform a join in SQL, you need to specify the tables we want to join, the columns used for matching, and the type of join we want to perform. The basic syntax for joining tables in SQL is as follows:
SELECT columns FROM table1 JOIN table2 ON table1.column = table2.column;
This example shows how to use JOIN.
You reference the first (or left) table in the FROM clause. Then you follow it with JOIN and reference the second (or right) table.
Then comes the joining condition in the ON clause. This is where you specify which columns you’ll use to join the two tables. Usually, it’s a shared column that’s a primary key in one table and the foreign key in the second table.
Note: A primary key is a unique identifier for each record in a table. A foreign key establishes a link between two tables, i.e., it’s a column in the second table that references the first table. We’ll show you in the examples what that means.
If you want to use LEFT JOIN, RIGHT JOIN, or FULL JOIN, you just use these keywords instead of JOIN – everything else in the code is exactly the same!
Things are a little different with the CROSS JOIN. In its nature is to join all the rows’ combinations from both tables. That’s why the ON clause is not needed, and the syntax looks like this.
SELECT columns FROM table1 CROSS JOIN table2;
In other words, you simply reference one table in FROM and the second in CROSS JOIN.
Alternatively, you can reference both tables in FROM and separate them with a comma – this is a shorthand for CROSS JOIN.
SELECT columns FROM table1, table2;
Self Join: A Special Type of Join in SQL
There’s also one specific way of joining the tables – joining the table with itself. This is also called self joining the table.
It’s not exactly a distinct type of join, as any of the earlier-mentioned join types can also be used for self joining.
The syntax for self joining is similar to what I showed you earlier. The main difference is the same table is referenced in FROM and JOIN.
SELECT columns FROM table1 t1 JOIN table1 t2 ON t1.column = t2.column;
Also, you need to give the table two aliases to distinguish between them. What you’re doing is joining the table with itself and treating it as two tables.
I just wanted to mention this here, but I won’t be going into further detail. If you’re interested in self join, please see this illustrated guide on self join in SQL.
SQL Join Examples
It’s time to show you how everything I mentioned works in practice. I’ll use SQL JOIN interview questions from StrataScratch to showcase each distinct type of join in SQL.
1. JOIN Example
This question by Microsoft wants you to list each project and calculate the project’s budget by the employee.
Expensive Projects
“Given a list of projects and employees mapped to each project, calculate by the amount of project budget allocated to each employee . The output should include the project title and the project budget rounded to the closest integer. Order your list by projects with the highest budget per employee first.”
Data
The question gives two tables.
ms_projects
| id: |
int |
| title: |
varchar |
| budget: |
int |
ms_emp_projects
| emp_id: |
int |
| project_id: |
int |
Now, the column id in the table ms_projects is the table’s primary key. The same column can be found in the table ms_emp_projects, albeit with a different name: project_id. This is the table’s foreign key, referencing the first table.
I’ll use these two columns to join the tables in my solution.
Code
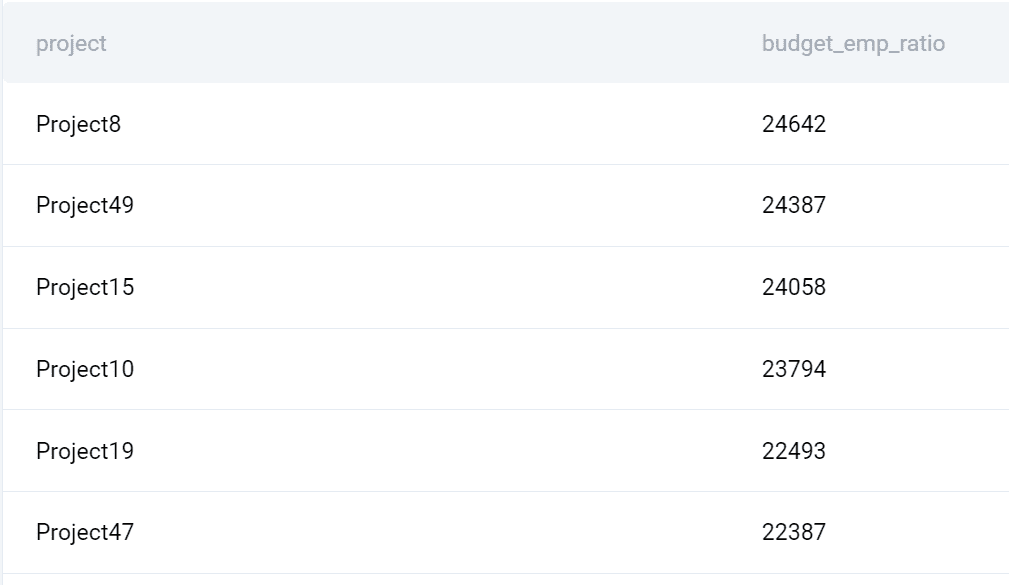
SELECT title AS project, ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio FROM ms_projects a JOIN ms_emp_projects b ON a.id = b.project_id GROUP BY title, budget ORDER BY budget_emp_ratio DESC;
I joined the two tables using JOIN. The table ms_projects is referenced in FROM, while ms_emp_projects is referenced after JOIN. I’ve given both tables an alias, allowing me not to use the table’s long names later on.
Now, I need to specify the columns on which I want to join the tables. I already mentioned which columns are the primary key in one table and the foreign key in another table, so I’ll use them here.
I equal these two columns because I want to get all the data where the project ID is the same. I also used the tables’ aliases in front of each column.
Now that I have access to data in both tables, I can list columns in SELECT. The first column is the project name, and the second column is calculated.
This calculation uses the COUNT() function to count the number of employees by each project. Then I divide each project’s budget by the number of employees. I also convert the result to decimal values and round it to zero decimal places.
Output
Here’s what the query returns.
2. LEFT JOIN Example
Let’s practice this join on the Airbnb interview question. It wants you to find the number of orders, the number of customers, and the total cost of orders for each city.
Customer Orders and Details
“Find the number of orders, the number of customers, and the total cost of orders for each city. Only include cities that have made at least 5 orders and count all customers in each city even if they did not place an order.
Output each calculation along with the corresponding city name.”
Data
You’re given the tables customers, and orders.
customers
| id: |
int |
| first_name: |
varchar |
| last_name: |
varchar |
| city: |
varchar |
| address: |
varchar |
| phone_number: |
varchar |
orders
| id: |
int |
| cust_id: |
int |
| order_date: |
datetime |
| order_details: |
varchar |
| total_order_cost: |
int |
The shared columns are id from the table customers and cust_id from the table orders. I’ll use these columns to join the tables.
Code
Here’s how to solve this question using LEFT JOIN.
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city FROM customers c LEFT JOIN orders o ON c.id = o.cust_id GROUP BY c.city HAVING COUNT(o.id) >=5;
I reference the table customers in FROM (this is our left table) and LEFT JOIN it with orders on the customer ID columns.
Now I can select the city, use COUNT() to get the number of orders and customers by city, and use SUM() to calculate the total orders cost by city.
To get all these calculations by city, I group the output by city.
There’s one extra request in the question: “Only include cities that have made at least 5 orders…” I use HAVING to show only cities with five or more orders to achieve that.
The question is, why did I use LEFT JOIN and not JOIN? The clue is in the question:”…and count all customers in each city even if they did not place an order.” It’s possible that not all customers have placed orders. This means I want to show all customers from the table customers, which perfectly fits the definition of the LEFT JOIN.
Had I used JOIN, the result would’ve been wrong, as I would’ve missed the customers that didn’t place any orders.
Note: The complexity of joins in SQL isn’t reflected in their syntax but in their semantics! As you saw, each join is written the same way, only the keyword changes. However, each join works differently and, therefore, can output different results depending on the data. Because of that, it’s crucial that you fully understand what each join does and choose the one that will return exactly what you want!
Output
Now, let’s have a look at the output.

3. RIGHT JOIN Example
The RIGHT JOIN is the mirror image of LEFT JOIN. That’s why I could’ve easily solved the previous problem using RIGHT JOIN. Let me show you how to do it.
Data
The tables stay the same; I’ll just use a different type of join.
Code
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city FROM orders o RIGHT JOIN customers c ON o.cust_id = c.id GROUP BY c.city HAVING COUNT(o.id) >=5;
Here’s what’s changed. As I’m using RIGHT JOIN, I switched the order of the tables. Now the table orders becomes the left one, and the table customers the right one. The joining condition stays the same. I just switched the order of the columns to reflect the order of the tables, but it’s not necessary to do it.
By switching the order of the tables and using RIGHT JOIN, I again will output all the customers, even if they haven’t placed any orders.
The rest of the query is the same as in the previous example. The same goes for the output.
Note: In practice, RIGHT JOIN is relatively rarely used. The LEFT JOIN seems more natural to SQL users, so they use it much more often. Anything that can be done with RIGHT JOIN can also be done with LEFT JOIN. Because of that, there’s no specific situation where RIGHT JOIN might be preferred.
Output
4. FULL JOIN Example
The question by Salesforce and Tesla wants you to count the net difference between the number of products companies launched in 2020 with the number of products companies launched in the previous year.
New Products
“You are given a table of product launches by company by year. Write a query to count the net difference between the number of products companies launched in 2020 with the number of products companies launched in the previous year. Output the name of the companies and a net difference of net products released for 2020 compared to the previous year.”
Data
The question provides one table with the following columns.
car_launches
| year: |
int |
| company_name: |
varchar |
| product_name: |
varchar |
How the hell will I join tables when there’s only one table? Hmm, let’s see that, too!
Code
This query is a little more complicated, so I’ll reveal it gradually.
SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020;
The first SELECT statement finds the company and the product name in 2020. This query will later be turned into a subquery.
The question wants you to find the difference between 2020 and 2019. So let’s write the same query but for 2019.
SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019;
I’ll now make these queries into subqueries and join them using the FULL OUTER JOIN.
SELECT * FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name;
Subqueries can be treated as tables and, therefore, can be joined. I gave the first subquery an alias, and I placed it in the FROM clause. Then I use FULL OUTER JOIN to join it with the second subquery on the company name column.
By using this type of SQL join, I’ll get all the companies and products in 2020 merged with all the companies and products in 2019.
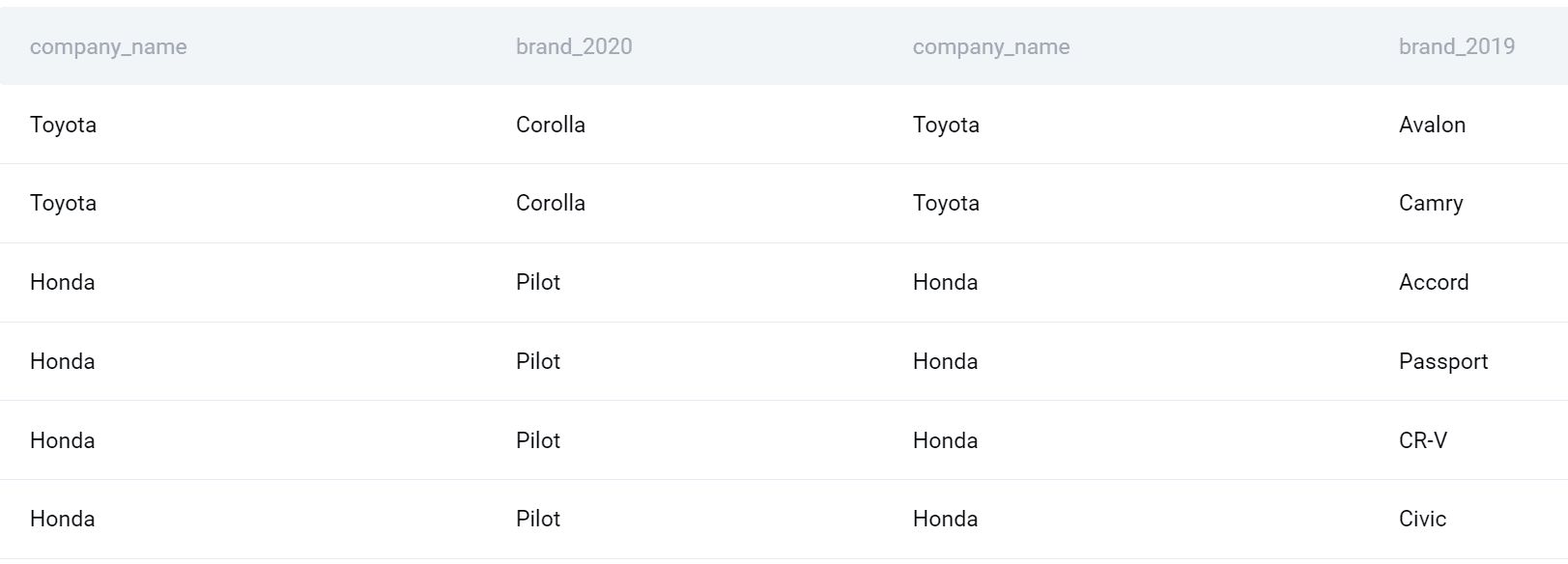
Now I can finalize my query. Let’s select the company name. Also, I’ll use the COUNT() function to find the number of products launched in each year and then subtract it to get the difference. Finally, I’ll group the output by company and sort it also by company alphabetically.
Here’s the whole query.
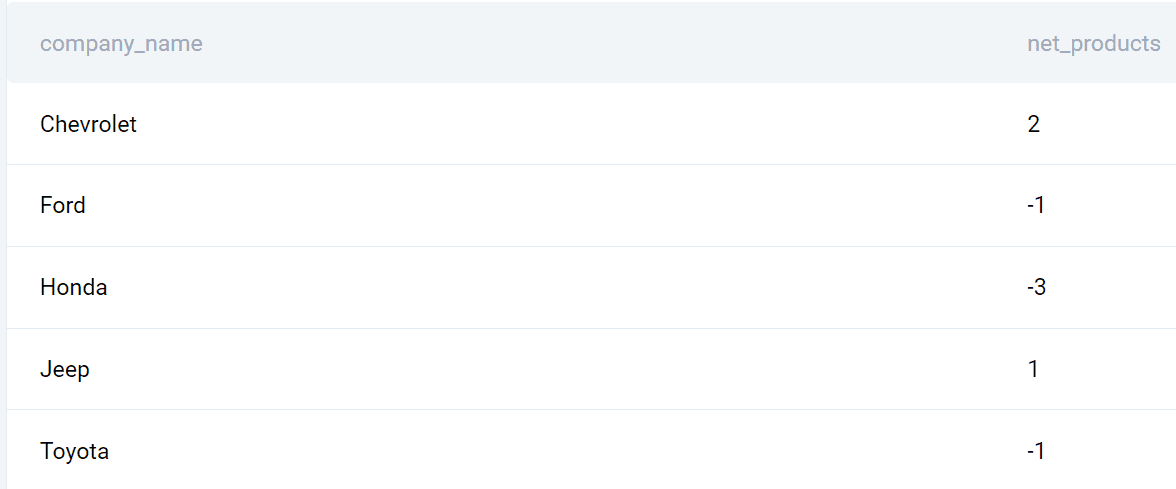
SELECT a.company_name, (COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name GROUP BY a.company_name ORDER BY company_name;
Output
Here’s the list of companies and the launched products difference between 2020 and 2019.
5. CROSS JOIN Example
This question by Deloitte is great for showing how CROSS JOIN works.
Maximum of Two Numbers
“Given a single column of numbers, consider all possible permutations of two numbers assuming that pairs of numbers (x,y) and (y,x) are two different permutations. Then, for each permutation, find the maximum of the two numbers.
Output three columns: the first number, the second number and the maximum of the two.”
The question wants you to find all possible permutations of two numbers assuming that pairs of numbers (x,y) and (y,x) are two different permutations. Then, we need to find the maximum of the numbers for each permutation.
Data
The question gives us one table with one column.
deloitte_numbers
Code
This code is an example of CROSS JOIN, but also of self join.
SELECT dn1.number AS number1, dn2.number AS number2, CASE WHEN dn1.number > dn2.number THEN dn1.number ELSE dn2.number END AS max_number FROM deloitte_numbers AS dn1 CROSS JOIN deloitte_numbers AS dn2;
I reference the table in FROM and give it one alias. Then I CROSS JOIN it with itself by referencing it after CROSS JOIN and giving the table another alias.
Now it’s possible to use one table as they’re two. I select the column number from each table. Then I use the CASE statement to set a condition that will show the maximum number of the two numbers.
Why is CROSS JOIN used here? Remember, it’s a type of SQL join that will show all combinations of all rows from all tables. That’s exactly what the question is asking!
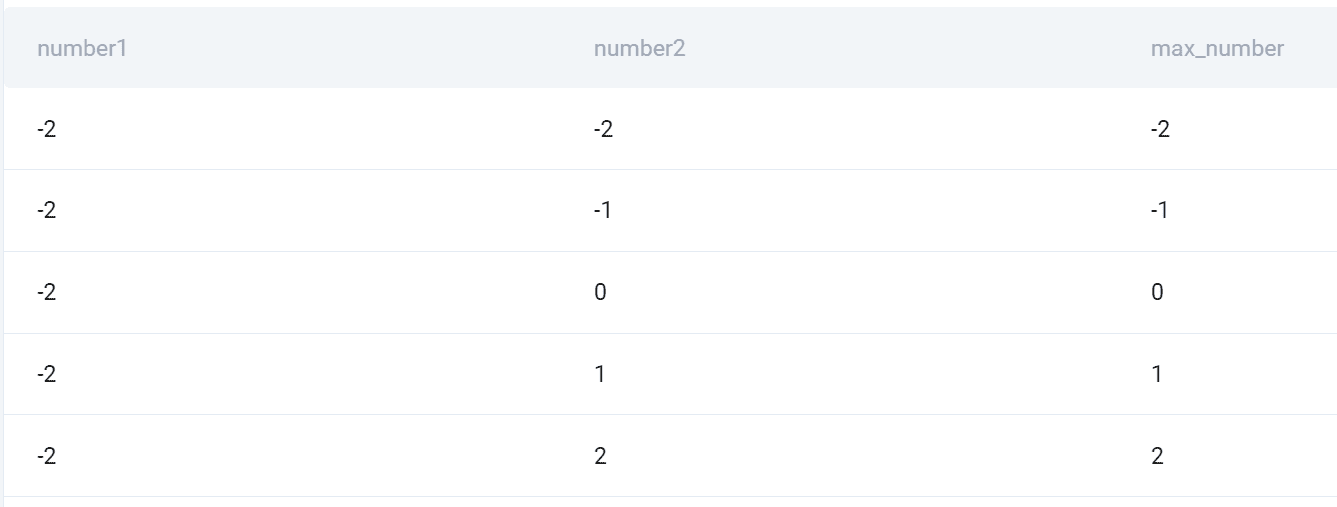
Output
Here’s the snapshot of all the combinations and the higher number of the two.
 Utilizing SQL Joins for Data Science
Utilizing SQL Joins for Data Science
Now that you know how to use SQL joins, the question is how to utilize that knowledge in data science.
SQL Joins play a crucial role in data science tasks such as data exploration, data cleaning, and feature engineering.
Here are a few examples of how SQL joins can be leveraged:
- Combining Data: Joining tables allows you to bring together different sources of data, enabling you to analyze relationships and correlations across multiple datasets. For example, joining a customer table with a transaction table can provide insights into customer behavior and purchasing patterns.
- Data Validation: Joins can be used to validate data quality and integrity. By comparing data from different tables, you can identify inconsistencies, missing values, or outliers. This helps you in data cleaning and ensures that the data used for analysis is accurate and reliable.
- Feature Engineering: Joins can be instrumental in creating new features for machine learning models. By merging relevant tables, you can extract meaningful information and generate features that capture important relationships within the data. This can enhance the predictive power of your models.
- Aggregation and Analysis: Joins enable you to perform complex aggregations and analyses across multiple tables. By combining data from various sources, you can gain a comprehensive view of the data and derive valuable insights. For example, joining a sales table with a product table can help you analyze sales performance by product category or region.
Best Practices for SQL Joins
As I already mentioned, the complexity of joins doesn’t show in their syntax. You saw that syntax is relatively straightforward.
The best practices for joins also reflect that, as they are not concerned with coding itself but what join does and how it performs.
To make the most out of joins in SQL, consider the following best practices.
- Understand Your Data: Familiarize yourself with the structure and relationships within your data. This will help you choose the appropriate type of join and select the right columns for matching.
- Use Indexes: If your tables are large or frequently joined, consider adding indexes on the columns used for joining. Indexes can significantly improve query performance.
- Be Mindful of Performance: Joining large tables or multiple tables can be computationally expensive. Optimize your queries by filtering data, using appropriate join types, and considering the use of temporary tables or subqueries.
- Test and Validate: Always validate your join results to ensure correctness. Perform sanity checks and verify that the joined data aligns with your expectations and business logic.
Conclusion
SQL Joins are a fundamental concept that empowers you as a data scientist to merge and analyze data from multiple sources. By understanding the different types of SQL joins, mastering their syntax, and leveraging them effectively, data scientists can unlock valuable insights, validate data quality, and drive data-driven decision-making.
I showed you how to do it in five examples. Now it’s up to you to harness the power of SQL and joins for your data science projects and achieve better results.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.
More On This Topic
- Understanding Functions for Data Science
- In-Database Analytics: Leveraging SQL's Analytic Functions
- 3 Ways Understanding Bayes Theorem Will Improve Your Data Science
- Speeding up data understanding by interactive exploration
- Understanding Agent Environment in AI
- Understanding Central Tendency




















