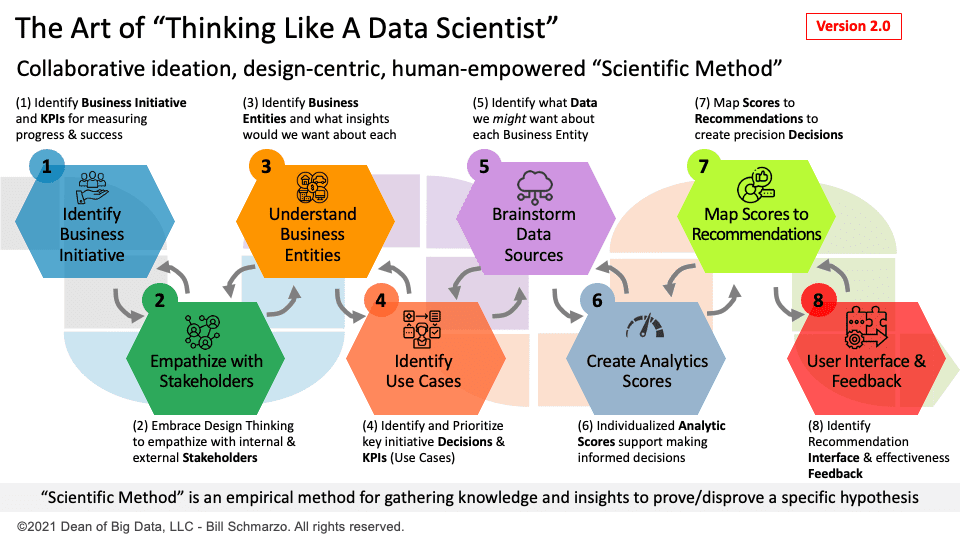
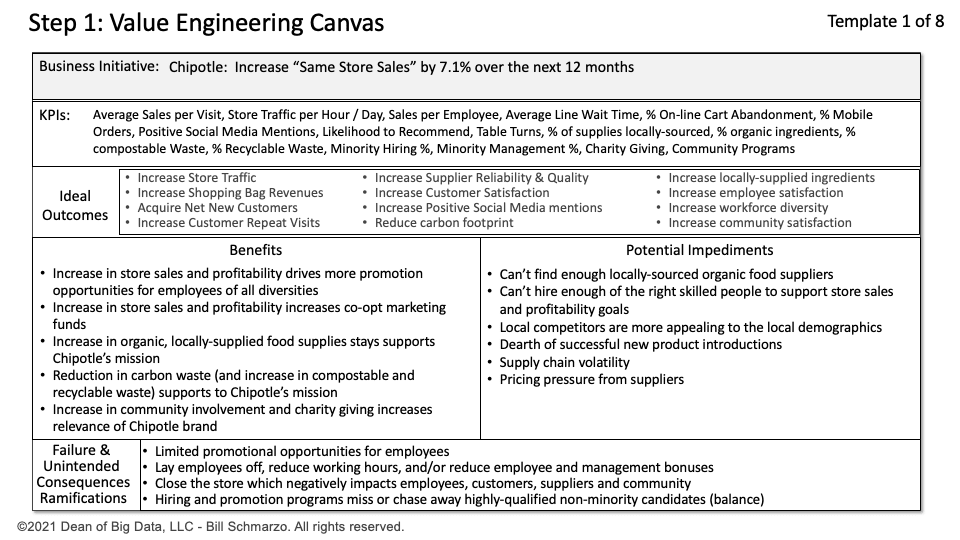
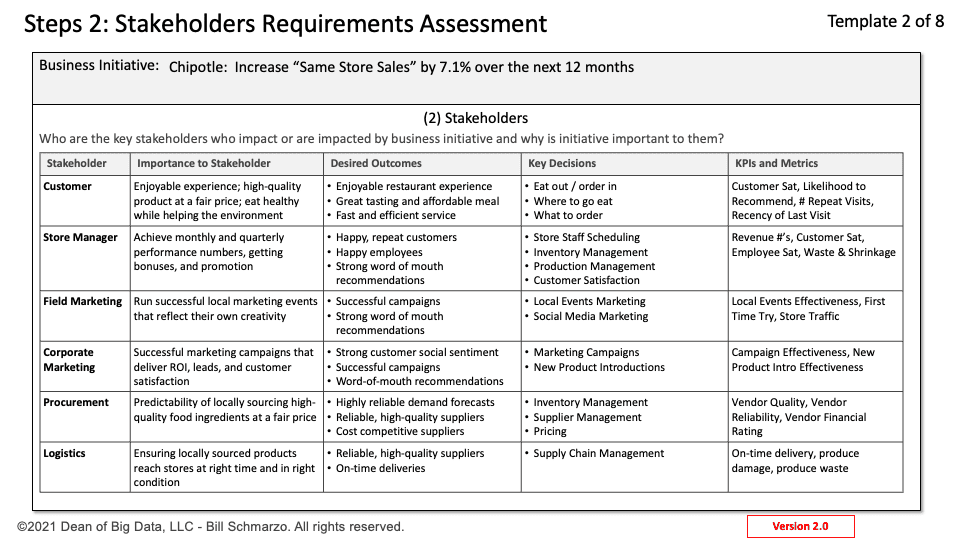
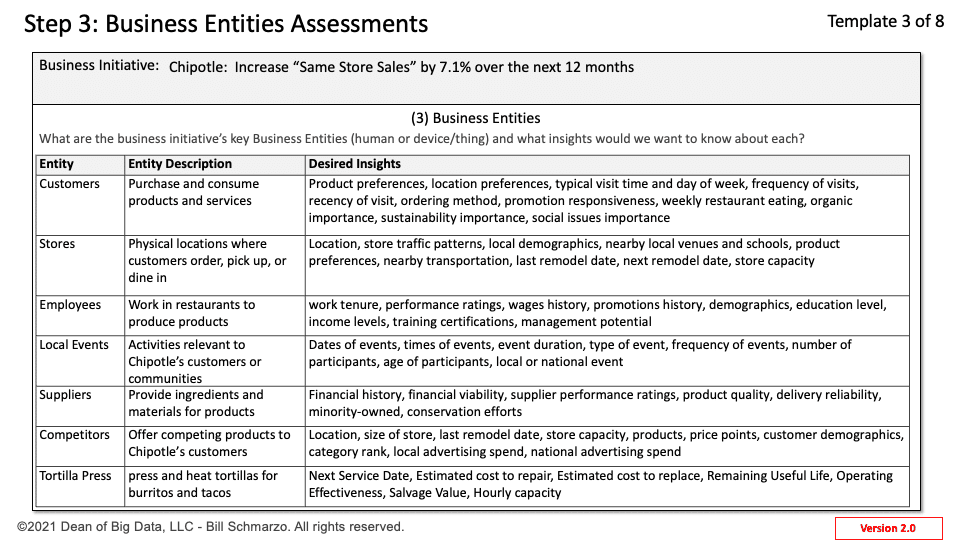
AI senate hearings are becoming more fun day by day. Like a never-ending series where the plot advances nowhere but the episodes continue, a second AI senate hearing on AI took place recently. With discussions on AI and this time on AGI too, the meeting led to pretty much nothing concrete – again!
Attempt For Enforcement
As opposed to the first hearing in May where the biggest man in the AI scene, Sam Altman participated, the second hearing held by the Subcommittee on Privacy, Technology, and the Law, featured Anthropic CEO Dario Amodei, AI expert Yoshua Bengio and Professor of Computer Science from Berkeley University Stuart Russell. The AI academics and leaders spoke about the potential AI regulations across various applications- which was the main agenda in the first hearing as well. This time though, the focus also fell on legal and national security concerns associated with AI development, and also on privacy risks affecting individuals – trying to address issues at a global scale.
This hearing emphasised the need to move from general principles to specific legal recommendations aiming to use insights gained from the hearing to draft real and enforceable laws.
Spreading Doomsday through AGI
When everyone is still trying to make peace with AI advancements, discussions on AGI and human-level intelligence took a substantial portion of the discussion. Youshua Bengio warned the Senate about how AI is on track to achieving human-level intelligence and emphasised about how there is very little time to frame technical and legal guidelines to prevent ‘rogue AI models.’ He believes that what was considered decades or centuries away, AGI can arrive within a few years, particularly five. Thereby, the need to address quickly.
Interestingly, last month OpenAI announced its ambitious prophecy of achieving AI alignment in four years, and set out to build a team to probably steer and control a potentially superintelligent AI.
Stuart Russell also pushed for the need to act soon as “$10 billion/month are going to AGI start-ups.” He even pushed for the need for ‘proof of safety’ before any public release and a US regulatory agency to strictly remove regulatory violators from the market.
Bengio proposed criminal penalties as a measure to decrease the possibility of malicious individuals employing AI to deceitfully imitate someone’s voice, image, or identity. He advocated that the penalties for AI-based counterfeiting of human attributes should be set at least at the same level as that for counterfeiting money to discourage potential wrongdoers.
However, the thoughts expressed were pure wishful thinking. Similar to the last hearing, the discussion on how or what will form the regulations lay hanging in the air.
Election Fear Looming?
AI was not let loose without blaming it as potential cause for disrupting the upcoming elections in 2024. In response, Dario Amodei emphasised on how models are trained using the method of constitutional AI in Anthropic , where principles can be laid out to guide the model’s behaviour and not generate misinformation- though he agrees that it will not always adhere to these principles.
A few days before the Senate hearing, seven companies including Anthropic, with adherence to White House, agreed to watermarking audio and visual content. Amodei believes that this would enhance he technical capability to detect AI-generated content. However, he pushed for enforcing it as a legal requirement – something that everyone is shying from.
Resonating with the Senate, Sam Altman also mentioned about election influence in a recent tweet.
i am nervous about the impact AI is going to have on future elections (at least until everyone gets used to it). personalized 1:1 persuasion, combined with high-quality generated media, is going to be a powerful force.
— Sam Altman (@sama) August 3, 2023
What Transpired?
The aftermath of each Senate hearing probably serves as a benchmark for future hearings. Within a day, big tech including OpenAI, Google, Microsoft and Anthropic formed a collaboration to launch the Frontier Model Forum. The forum aims to promote safe and responsible development of AI systems, and also lead to information sharing between policy makers and industry. The irony being the companies agreeing to form the frontier model works on closed source.
After the first AI senate hearing, OpenAI actively pushed programs that supported Altman’s assurances he committed to – the main being safety regulations. The company announced a million dollar grant for democratising AI regulatory frameworks and another million dollar grant for formulating their cybersecurity framework. Pushing the reins of safety control to people, OpenAI was the only company that actively laid out plans after the hearing.
While it’s two weeks since the last hearing, apart from the frontier model, there has been no other concrete action plans that have transpired. The whole act has been just another episode where AI needs to be regulated but no clue on how.
The post Another AI Senate Hearing- and Nothing appeared first on Analytics India Magazine.