Meta GPT is trending on GitHub, with 20,000 stars. It’s a multi-agent framework trying to connect several different programs and get them to work together better without hallucinating. The programs work on different parts of a problem separately, like experts in different areas – this way, they can double-check each other’s work and make fewer mistakes overall.
Until now, agents like Baby AGI and Agent GPT would spin up a bunch of agents to complete a task for ‘write me a code for this API’ but now, MetaGPT stepped up the game by taking in a one-line requirement as input and outputs user stories, competitive analysis, requirements, data structures, APIs, and documents. But is Meta GPT really any better?
Better than individual agents
The developers took the different roles of a software company, like product manager, project manager, software architect, and software engineer and used GPT-4 to build agents for each persona in a software company and run them at the same time. They tested MetaGPT on tasks related to making computer programs, and it could come up with better solutions compared to how these programs worked before.
It not only writes code but also performs various analyses that a software house would have to do. It has a lot of different agents, not just developers, but also engineers, QA testers, project managers, and architectural designers. It implements a manager-like structure to oversee these agents.
The manager agent acts as a decision-maker, passing tasks to different agents based on their roles.
After installing Meta GPT users can build anything, for example, a version of Flappy Bird without any code. Instead, the agents will start working on it, with the product manager defining goals, user stories, and competitive analysis. The architect will break down the schema into tasks, followed by developers working on the actual code.
MetaGPT generates a folder called ‘workspace’ with generated files. It even creates charts and diagrams that a software house would typically take days to produce. Though it might need some adjustments and debugging as GPT’s information is cut off till 2021, it’s still a powerful tool for rapidly generating code and documentation.
To do all this, they are using a set of instructions called SOPs. The SOPs are like plans that guide them on how to work together efficiently. First, each agent is given a description so that the system knows what job they’re best suited for. This helps the system start with the right instructions. The agents can talk to each other and share tools and information in a shared space, just like people in a team. They can also share their work with each other. Unlike waiting for messages, the agents can actively find useful information, which is faster. The shared space is like a digital version of a workplace where people collaborate.
How Meta GPT compares with others
Meta GPT is the ‘on steroids’ version of other agents like AutoGPT, LangChain, and AgentVerse.
When it comes to working together on projects, both MetaGPT and AgentVerse allow people to collaborate on tasks. They assign roles to different people, which helps them work better as a team. However, MetaGPT goes a step further by not only breaking down tasks but also managing them.
In terms of creating code, all the tools are good, but according to the paper, MetaGPT is seen as more complete because it covers a wider range of tasks in project development and offers a complete set of tools for managing and executing projects.
Even though MetaGPT can create working code for games, it’s not perfect because there are strict rules and limited options to adjust things manually. On the other hand, the other tools like AutoGPT, LangChain, and AgentVerse work better on larger tasks than MetaGPT.
According to the paper, in tests to create code, MetaGPT does really well, achieving a top score of 81.7% and 82.3% in getting things right on the first try. When we compare it to other ways of making code like AutoGPT, LangChain, and AgentVerse, MetaGPT can handle much more complex software and stands out for its many features. It’s important to note that in our experiments, MetaGPT successfully finished all the tasks we gave it, showing how strong and effective it is.
In conclusion
These various AI systems or frameworks seem to attract attention on GitHub, but they don’t seem to have practical applications beyond being entertaining demos. Similar to AutoGPT, they might struggle with anything even slightly complex. It’s possible that this is the direction we’re moving in. Could it really be as simple as just putting together the right combination of models to create truly useful general-purpose AI agents? So far, these agents draw the same low code/no code crowd with maybe 5-10% improvement but the same or worse technical debt.
The post Meta GPT, Another Day Another Agent appeared first on Analytics India Magazine.
China has closed a record number of personal data breaches and is seeking public feedback on draft laws to regulate the use of facial recognition data.
In the last three years, the Chinese police closed 36,000 cases related to personal data infringements, detaining 64,000 suspects along the way, according to the Ministry of Public Security. The arrests were part of the government's efforts since 2020 to regulate the internet, which also saw more than 30 million SIM cards and 300 million "illegal" internet accounts seized, reported state-owned media Global Times, citing the ministry in a media briefing Thursday.
Also:AI can crack your password by listening to your keyboard clicks
The police had been investigating a growing number of criminal cases involving personal data violations over the past couple of years, with these targeting several industries including healthcare, education, logistics, and e-commerce.
Reported criminal cases involving artificial intelligence (AI) also had been increasing, said the ministry, citing an April 2023 incident in which a company in the Fujian province lost 4.3 million yuan ($596,510) to hackers who used AI to alter their faces.
To date, law enforcement agencies have solved 79 cases involving "AI face changing."
Also:We're not ready for the impact of generative AI on elections
With facial recognition now widely used alongside advancements made in AI technology, government officials noted the emergence of cases tapping such data. In such instances, cybercriminals would use photos, in particular those found on identity cards, together with personal names and ID numbers to facilitate facial recognition verification.
China's public security departments are working with state facilities to conduct safety assessments of facial recognition and other relevant technology, as well as to identify potential risks in facial recognition verification systems, according to the ministry.
With cybercriminal ecosystems largely linked, ranging from theft to reselling of data to money laundering, Chinese government officials said these criminals have established a significant "underground big data" market that poses serious risks to personal data and "social order".
Proposed nationwide laws to regulate facial recognition
The Cyberspace Administration of China (CAC) earlier this week published draft laws that dealt specifically with facial recognition technology. It marked the first time nationwide regulations had been mooted for the technology, according to Global Times.
Also:Zoom is entangled in an AI privacy mess
The proposed rules will require "explicit or written" user consent to be obtained before organizations can collect and use personal facial information. Businesses also must state the reason and extent of data they are collecting, and use the data only for the stated purpose.
Without user consent, no person or organization is allowed to use facial recognition technology to analyze sensitive personal data, such as ethnicity, religious beliefs, race, and health status. There are exceptions for use without consent, primarily for maintaining national security and public safety as well as safeguarding the health and property of individuals in emergencies.
Organizations that use the technology must have data protection measures in place to prevent unauthorized access or data leaks, stated the CAC document.
The draft laws further indicate that any person or organization that retains more than 10,000 facial recognition datasets must notify the relevant cyber government authorities within 30 working days.
Also:Generative AI and the fourth why: Building trust with your customer
The proposed rules stipulate conditions under which facial recognition systems should be used, including how they process personal facial data and for what purposes.
The draft laws also mandate companies to prioritize the use of alternative non-biometric recognition tools if these provide equivalent results as biometric-based technology.
The public has one month to submit feedback on the draft laws.
In January, China put into effect regulations that aimed to prevent the abuse of "deep synthesis" technology, including deepfakes and virtual reality. Anyone using these services must label the images accordingly and refrain from tapping the technology for activities that breach local regulations.
Also:4 ways to detect generative AI hype from reality
Interim laws also will kick in next week to manage generative AI services in the country. These regulations outline various measures that look to facilitate the sound development of the technology while protecting national and public interests and the legal rights of citizens and businesses, the Chinese government said.
Generative AI developers, for instance, will have to ensure their pre-training and model optimization processes are carried out in compliance with the law. These include using data from legitimate sources that adhere to intellectual property rights. Should personal data be used, the individual's consent must be obtained or it must be done in accordance with existing regulations. Measures also have to be taken to improve the quality of training data, including its accuracy, objectivity, and diversity.
Under the interim laws, generative AI service providers assume legal responsibility for the information generated and its security. They will need to sign service-level agreements with users of their service, thereby, clarifying each party's rights and obligations.
At the Black Hat kickoff keynote on Wednesday, Jeff Moss (AKA Dark Tangent), the founder of Black Hat, focused on the security implications of AI before introducing the main speaker, Maria Markstedter, CEO and founder of Azeria Labs. Moss said that a highlight of the other Sin City hacker event — DEF CON 31 — right on the heels of Black Hat, is a challenge sponsored by the White House in which hackers attempt to break top AI models … in order to find ways to keep them secure.
Jump to:
Attackers and defenders: how generative AI will tilt the balance
AI and the code pipeline
Using AI to do cybersecurity for AI
Will AI help or hinder human talent development and fill vacant seats?
Do fewer foundational AI models mean easier security and regulatory challenges?
What disruption means when AI enters the enterprise
Generative AI as a boon to cybersecurity work and training
Securing AI was also a key theme during a panel at Black Hat a day earlier: Cybersecurity in the Age of AI, hosted by security firm Barracuda. The event detailed several other pressing topics, including how generative AI is reshaping the world and the cyber landscape, the potential benefits and risks associated with the democratization of AI, how the relentless pace of AI development will affect our ability to navigate and regulate tech, and how security players can evolve with generative AI to the advantage of defenders.
From left to right: Fleming Shi, CTO at Barracuda; Mark Ryland, director at the Office of the CISO, AWS; Michael Daniel, president & CEO at Cyber Threat Alliance and former cyber czar for the Obama administration; Dr. Amit Elazari, J.S.D, co-founder & CEO at OpenPolicy and cybersecurity professor at UC Berkeley; Patrick Coughlin, GVP of Security Markets at Splunk.
One thing all of the panelists agreed upon is that AI is a major tech disruption, but it is also important to remember that there is a long history of AI, not just the last six months. “What we are experiencing now is a new user interface more than anything else,” said Mark Ryland, director, Office of the CISO at AWS.
From the perspective of policy, it’s about understanding the future of the market, according to Dr. Amit Elazari, co-founder and CEO of OpenPolicy and cybersecurity professor at UC Berkeley.
SEE: CrowdStrike at Black Hat: Speed, Interaction, Sophistication of Threat Actors Rising in 2023 (TechRepublic)
“Very soon you will see a large executive order from the [Biden] administration that is as comprehensive as the cybersecurity executive order,” said Elazari. “It is really going to bring forth what we in the policy space have been predicting: a convergence of requirements in risk and high risk, specifically between AI privacy and security.”
She added that AI risk management will converge with privacy security requirements. “That presents an interesting opportunity for security companies to embrace holistic risk management posture cutting across these domains.”
Attackers and defenders: How generative AI will tilt the balance
While the jury is still out on whether attackers will benefit from generative AI more than defenders, the endemic shortage of cybersecurity personnel presents an opportunity for AI to close that gap and automate tasks that might provide an advantage to the defender, noted Michael Daniel, president and CEO of Cyber Threat Alliance and former cyber czar for the Obama administration.
SEE: Conversational AI to Fuel Contact Center Market to 16% Growth (TechRepublic)
“We have a huge shortage of cybersecurity personnel,” Daniel said. “… To the extent that you can use AI to close the gap by automating more tasks. AI will make it easier to focus on work that might provide an advantage,” he added.
AI and the code pipeline
Daniel speculated that, because of the adoption of AI, developers could drive the exploitable error rate in code down so far that, in 10 years, it will be very difficult to find vulnerabilities in computer code.
Elazari argued that the generative AI development pipeline — the sheer amount of code creation involved — constitutes a new attack surface.
“We are producing a lot more code all the time, and if we don’t get a lot smarter in terms of how we really push secure lifecycle development practices, AI will just duplicate current practices that are suboptimal. So that’s where we have an opportunity for experts doubling down on lifecycle development,” she said.
Using AI to do cybersecurity for AI
The panelists also mulled over how security teams practice cybersecurity for the AI itself — how do you do security for a large language model?
Daniel suggested that we don’t necessarily know how to discern, for example, whether an AI model is hallucinating, whether it has been hacked or whether bad output means deliberate compromise. “We don’t actually have the tools to detect if someone has poisoned the training data. So where the industry will have to put time and effort into defending the AI itself, we will have to see how it works out,” he said.
Elazari said in an environment of uncertainty, such as is the case with AI, embracing an adversarial mindset will be critical, and using existing concepts like red teaming, pen testing, and even bug bounties will be necessary.
“Six years ago, I envisioned a future where algorithmic auditors would engage in bug bounties to find AI issues, just as we do in the security field, and here we are seeing this happen at DEF CON, so I think that will be an opportunity to scale the AI profession while leveraging concepts and learnings from security,” Elazari said.
Will AI help or hinder human talent development and fill vacant seats?
Elazari also said that she is concerned about the potential for generative AI to remove entry-level positions in cybersecurity.
“A lot of this work of writing textual and language work has also been an entry point for analysts. I’m a bit concerned that with the scale and automation of generative AI entry, even the few level positions in cyber will get removed. We need to maintain those positions,” she said.
Patrick Coughlin, GVP of Security Markets, at Splunk, suggested thinking of tech disruption, whether AI or any other new tech, as an amplifier of capability — new technology amplifies what people can do.
“And this is typically symmetric: There are lots of advantages for both positive and negative uses,” he said. “Our job is to make sure they at least balance out.”
Do fewer foundational AI models mean easier security and regulatory challenges?
Coughlin pointed out that the cost and effort to develop foundation models may limit their proliferation, which could make security less of a daunting challenge. “Foundation models are very expensive to develop, so there is a kind of natural concentration and a high barrier to entry,” he said. “Therefore, not many companies will invest in them.”
He added that, as a consequence, a lot of companies will put their own training data on top of other peoples’ foundation models, getting strong results by putting a small amount of custom training data on a generic model.
“That will be the typical use case,” Coughlin said. “That also means that it will be easier to have safety and regulatory frameworks in place because there won’t be countless companies with foundation models of their own to regulate.”
What disruption means when AI enters the enterprise
The panelists delved into the difficulty of discussing the threat landscape because of the speed at which AI is developing, given how AI has disrupted an innovation roadmap that has involved years, not weeks and months.
“The first step is … don’t freak out,” said Coughlin. “There are things we can use from the past. One of the challenges is we have to recognize there is a lot of heat on enterprise security leaders right now to produce definitive and deterministic solutions around an incredibly rapidly changing innovation landscape. It’s hard to talk about a threat landscape because of the speed at which the technology is progressing,” he said.
He also stated that inevitably, in order to protect AI systems from exploitation and misconfiguration, we will need security, IT and engineering teams to work better together: we’ll need to break down silos. “As AI systems move into production, as they are powering more and more customer-facing apps, it will be increasingly critical that we break down silos to drive visibility, process controls and clarity for the C suite,” Coughlin said.
Ryland pointed to three consequences of the introduction of AI into enterprises from the perspective of a security practitioner. First, it typically introduces a new attack surface area and a new concept of critical assets, such as training data sets. Second, it introduces a new way to lose and leak data, as well as new issues around privacy.
“Thus, employers are wondering if employees should use ChatGPT at all,” he said, adding that the third change is around regulation and compliance. “If we step back from the hype, we can recognize it may be new in terms of speed, but the lessons from past disruptions of tech innovation are still very relevant.”
Generative AI as a boon to cybersecurity work and training
When the panelists were queried about the benefits of generative AI and the positive outcomes it can generate, Fleming Shi, CTO of Barracuda, said AI models have the potential to make just-in-time training viable using generative AI.
“And with the right prompts, the right type of data to make sure you can make it personalized, training can be more easily implemented and more interactive,” Shi said, rhetorically asking whether anyone enjoys cybersecurity training. “If you make it more personable [using large language models as natural language engagement tools], people — especially kids — can learn from it. When people walk into their first job, they will be better prepared, ready to go,” he added.
Daniel said that he’s optimistic, “which may sound strange coming from the former cybersecurity coordinator of the U.S.,” he quipped. “I was not known as the Bluebird of Happiness. Overall, I think the tools we are talking about have the enormous potential to make the practice of cybersecurity more satisfying for a lot of people. It can take alert fatigue out of the equation and actually make it much easier for humans to focus on the stuff that’s actually interesting.”
He said he has hope that these tools can make the practice of cybersecurity a more engaging discipline. “We could go down the stupid path and let it block entry to the cybersecurity field, but if we use it right — by thinking of it as a ‘copilot’ rather than a replacement — we could actually expand the pool of [people entering the field],” Daniel added.
Read next: ChatGPT vs Google Bard (2023): An In-Depth Comparison (TechRepublic)
Disclaimer: Barracuda Networks paid for my airfare and accommodations for Black Hat 2023.
Subscribe to the Cybersecurity Insider Newsletter
Strengthen your organization's IT security defenses by keeping abreast of the latest cybersecurity news, solutions, and best practices.
When you gaze into the AI, the AI also gazes into you Haje Jan Kamps 9 hours
Welcome to Startups Weekly. Sign up here to get it in your inbox every Friday.
Fri-yay indeed. We sigh, as humans spool up to take a break, while the semi-sentient machines continue writing their poetry in their air-conditioned underground data-center homes. In my column this week, I spent a bit of time thinking about the times that robots have had an impact on my life. That time I ran a chatbot company talking with people about death. That time I felt a connection with a game character. And that time I tried to imagine what it would be like to be a sentient AI knowing it was about to get shut off.
It’s a series of thought experiments I’ve been playing with for a long time, and the idea was reawakened by reading Becky Chambers’ excellent Wayfarers series. The second installment goes into great depth about what happens when an AI is rebooted — will she come back with all her memories intact? Or does something change when you go back to your default software? Well worth a read, if you want to be a philoso-fish, swimming in the philoso-sea.
Anyway, on with the news!
So, about those room-temperature superconductors
Image Credits: Getty Images / ktsimage
Over the past couple of weeks, the internet went positively bonkers over the possibility of superconductors operating without being chilled to near absolute zero, after a team of researchers in South Korea claimed they had something cooked up in the lab that worked. The problem, in part, was that they claimed to have used a material (lead apatite) that not only isn’t a known superconductor, but also isn’t, in fact, conductive at all. YHBT, YHL, HAND, as they used to say in the early days of the internet.
Still, for the briefest of glimpses, on TC+, Tim explored the potential of such a development and the vast-ranging impacts it would have on, well, everything we know about electricity, electronics, and much more. Of course, it seems it may not have been true, and reminded us of the iffy claims made by another company back in March, also involving the elusive room-temp superconductivity.
Alas, ’twas not to be this time either, but the hunt continues.
Less confusion, more fusion: Tim is basically single-handedly carrying this entire section this week — well done, squire — reporting how scientists repeat a breakthrough fusion experiment, netting more power than before, bringing us one baby step closer to usable fusion power.
If you love yourself some sustainability, get your behind (and the rest of you, please. If you turn up at the doors, just a pair of levitating buttocks, we have achieved some sort of superconduction, but you’ll have made an ass of yourself, and security will probably turn you away) to TechCrunch Disrupt, where we have a whole Sustainability Stage planned!
Crypto is . . . maturing? Maybe?
Image Credits: Getty Images / Souda
As Bitcoin is back nudging $30,000, web3 is maturing and people are finally able to have some conversations about blockchains without talking about the abjectly stupid pyramid schemes that collectable digital primates represented (I sniggered all the way through “The Beanie Bubble” and then laughed out loud when the final punchline hit). It made me come up for air for a moment and look at what’s happening out in crypto land.
Investment into the sector certainly isn’t much to shout about right now, with venture funding declining for seventh straight quarter (TC+). A charitable read would be that the bubble is gone and that investors are now only making clearheaded investments into the companies that make sense. Or maybe the “invest while it’s hot” crew have just pivoted their attention to AI, and the hard core believers are left standing.
My unveiled cynicism and abject lack of faith in the sector aside, there’s some interesting movement in the space:
AI, meet web3. Web3, AI: Always worth paying attention when Goliath shifts on his throne, and Jacquelyn’s report that Microsoft partners with the Aptos blockchain (TC+) to marry AI and web3 got a huge amount of attention — and traffic — on TechCrunch this week.
Contractually smarter: About nine months after raising its Series A, SettleMint’s launches its AI assistant, which aims to help web3 developers write better smart contracts.
Followin’ the money: Tracking who invests in what and when is an ever-green effort. Our estranged sibling site Crunchbase does it for VC and startups, and EdgeIn jumps in to be a faster, community-driven version of the same, especially focused on web3.
Watching legal systems trying to wrap their heads around even pretty basic technology continues to be cringe-musing, and there was a lot of that sort of thing going on this week.
The Chinese government is in uproar after Biden bans U.S. funding flowing into semiconductors and microelectronics, quantum computing, and artificial intelligence.
In India, the government decided that it would restrict laptops, tablets, and other personal computers to boost local manufacturers but was met with the appropriate mix of uproar and ridicule, and quickly announced it would delay that particular harebrained idea from taking hold. Also in India, the IT minister resurrected a previously abandoned data privacy bill and is pushing ahead with it, despite criticism.
The EU wasn’t going to be outdone, though, and stuck its oar in as well. TikTok is launching a “For You” feed aimed at the European market but without its algorithm. Worldcoin’s official launch triggers privacy scrutiny, and it turns out the European Commission (EC) isn’t too psyched about Adobe’s $20 billion Figma acquisition, either, confirming an in-depth probe into the deal. Finally, Meta says it will offer European users a choice to deny tracking.
More? Fine.
There’s a lesson there: Dominic-Madori takes a dive into the U.K. venture landscape and argues that the U.S. could learn a lot from how the U.K. is crafting DEI (diversity, equity, and inclusion) policy for the industry.
Just can’t face it: The pervasive use of facial recognition technology across all facets of life in China has elicited both praise for its convenience and backlash around privacy concerns. Rita reports that China is considering measures that demand “individual consent” for facial recognition use.
Eye see you: A Kenyan government agency suspended Worldcoin’s activities, citing concerns with “authenticity and legality.” It plans to resume iris scans in Kenya, but the debate continues about whether the crypto-powered identification scheme is using the data it is collecting in accordance with local law.
Top reads on TechCrunch this week
Across the site, here are some of the startup stories y’all flocked to since the previous Startups Weekly.
Karma, karma, karma, karma, komeuppance: Apparently not entirely immune to irony, spyware maker LetMeSpy shuts down after hacker deletes server data.
That won’t have been cheap: The value domain AI.com, which until recently was pointing to ChatGPT, suddenly started sending traffic to Elon Musk’s X.ai this week. Ultimately, no one actually cares who owns AI.com, but speculation in the land of domain selling and buying ran rife as to how much money might have changed hands in the process.
You want how much for a ride to the airport?: Lyft wants to kill surge pricing, because “riders hate it with a fiery passion.” Yes, yes, we do.
We slipped into something more comfortable: Verizon dropped hundreds of millions on BlueJeans at the height of the pandemic lockdown, but three and a bit years later, the platform gives up the fight, announcing it is killing the app off altogether, citing “changing market demands.”
Get your TechCrunch fix IRL. Join us at Disrupt 2023 in San Francisco this September to immerse yourself in all things startup. From headline interviews to intimate roundtables to a jam-packed startup expo floor, there’s something for everyone at Disrupt. Save up to $600 when you buy your pass now through August 11, and save 15% on top of that with promo code STARTUPS. Learn more.
Anytime a new technology becomes popular, you can expect there's someone trying to hack it. Artificial intelligence, specifically generative AI, is no different. To meet that challenge, Google created a 'red team' about a year and a half ago to explore how hackers could specifically attack AI systems.
"There is not a huge amount of threat intel available for real-world adversaries targeting machine learning systems," Daniel Fabian, the head of Google Red Teams, told The Register in an interview. His team has already pointed out the biggest vulnerabilities in today's AI systems.
Also: How researchers broke ChatGPT and what it could mean for future AI development
Some of the biggest threats to machine learning (ML) systems, explains Google's red team leader, are adversarial attacks, data poisoning, prompt injection, and backdoor attacks. These ML systems include those built on large language models, like ChatGPT, Google Bard, and Bing AI.
These attacks are commonly referred to as 'tactics, techniques and procedures' (TTPs).
"We want people who think like an adversary," Fabian told The Register. "In the ML space, we are more trying to anticipate where will real-world adversaries go next."
Also: AI can now crack your password by listening to your keyboard clicks
Google's AI red team recently published a report where they outlined the most common TTPs used by attackers against AI systems.
Adversarial attacks on AI systems
Adversarial attacks include writing inputs specifically designed to mislead an ML model. This results in an incorrect output or an output that it wouldn't give in other circumstances, including results that the model could be specifically trained to avoid.
Also: ChatGPT answers more than half of software engineering questions incorrectly
"The impact of an attacker successfully generating adversarial examples can range from negligible to critical, and depends entirely on the use case of the AI classifier," Google's AI Red Team report noted.
Data-poisoning AI
Another common way that adversaries could attack ML systems is via data poisoning, which entails manipulating the training data of the model to corrupt its learning process, Fabian explained.
"Data poisoning has become more and more interesting," Fabian told The Register. "Anyone can publish stuff on the internet, including attackers, and they can put their poison data out there. So we as defenders need to find ways to identify which data has potentially been poisoned in some way."
Also: Zoom is entangled in an AI privacy mess
These data poisoning attacks include intentionally inserting incorrect, misleading, or manipulated data into the model's training dataset to skew its behavior and outputs. An example of this would be to add incorrect labels to images in a facial recognition dataset to manipulate the system into purposely misidentifying faces.
One way to prevent data poisoning in AI systems is to secure the data supply chain, according to Google's AI Red Team report.
Prompt injection attacks
Prompt injection attacks on an AI system entail a user inserting additional content in a text prompt to manipulate the model's output. In these attacks, the output could result in unexpected, biased, incorrect, and offensive responses, even when the model is specifically programmed against them.
Also: We're not ready for the impact of generative AI on elections
Since most AI companies strive to create models that provide accurate and unbiased information, protecting the model from users with malicious intent is key. This could include restrictions on what can be input into the model and thorough monitoring of what users can submit.
Backdoor attacks on AI models
Backdoor attacks are one of the most dangerous aggressions against AI systems, as they can go unnoticed for a long period of time. Backdoor attacks could enable a hacker to hide code in the model and sabotage the model output but also steal data.
"On the one hand, the attacks are very ML-specific, and require a lot of machine learning subject matter expertise to be able to modify the model's weights to put a backdoor into a model or to do specific fine-tuning of a model to integrate a backdoor," Fabian explained.
Also: How to block OpenAI's new AI-training web crawler from ingesting your data
These attacks can be achieved by installing and exploiting a backdoor, a hidden entry point that bypasses traditional authentication, to manipulate the model.
"On the other hand, the defensive mechanisms against those are very much classic security best practices like having controls against malicious insiders and locking down access," Fabian added.
Attackers also can target AI systems through training data extraction and exfiltration.
Google's AI Red Team
The red team moniker, Fabian explained in a recent blog post, originated from "the military, and described activities where a designated team would play an adversarial role (the 'red team') against the 'home' team."
"Traditional red teams are a good starting point, but attacks on AI systems quickly become complex, and will benefit from AI subject matter expertise," Fabian added.
Also: Were you caught up in the latest data breach? Here's how to find out
Attackers also must build on the same skillset and AI expertise, but Fabian considers Google's AI red team to be ahead of these adversaries with the AI knowledge they already possess.
Fabian remains optimistic that the work his team is doing will favor the defenders over the attackers.
"In the near future, ML systems and models will make it a lot easier to identify security vulnerabilities," Fabian said. "In the long term, this absolutely favors defenders because we can integrate these models into our software development life cycles and make sure that the software that we release doesn't have vulnerabilities in the first place."
Google has released a sneak peek at a new tool for building, managing and deploying full-stack web and multiplatform applications in the cloud. Project IDX, which brings development capabilities from a Linux-based virtual machine to a browser, does not have a release date yet. Interested developers can join the Project IDX waitlist, but pricing information is not yet available.
Jump to:
Development anywhere, as long as it’s Google Cloud
What’s under the hood of Project IDX?
Google wants feedback
Development anywhere, as long as it’s Google Cloud
A key differentiator for a browser-based development tool is that developers will ideally be able to move their work across different devices while maintaining the same tool set. Project IDX can do that because it is hosted in Google Cloud, like Google Docs. Developers can also import their projects from GitHub.
“Project IDX starts with a web-based workspace that’ll feel familiar for coding but fresh,” the IDX team of Bre Arder, Kirupa Chinnathambi, Ashwin Raghav Mohan Ganesh, Erin Kidwell and Roman Nurik wrote in a blog post.
To make sure it’s possible to develop for different devices all from within the browser, Project IDX includes a built-in web preview. Google expects to add an Android emulator and an embedded iOS simulator at a later date. When it comes to deployment, Project IDX uses Firebase Hosting, another Google product, to create previews of apps or deploy them.
Codespaces, Replit, CodePen and StackBlitz are examples of other applications on the market that already enable this kind of code-anywhere online hosting.
What’s under the hood of Project IDX?
Project IDX builds on two other tools: Codey and Code OSS.
Codey is more specifically known as the family of Vertex AI Codey APIs, which uses the Vertex generative AI to write and complete code or to chat about coding problems.
Code OSS is an open source development environment associated with and used to build Microsoft’s Visual Studio Code.
Project IDX has premade templates for the following frameworks:
Angular
Flutter
Next.js
React
Svelte
Vue
And the programming languages JavaScript and Dart.
Google expects to add the programming languages Python and Go to the list soon.
SEE: Google wants to be a major player in the generative AI race with PaLM 2 and Bard. (TechRepublic)
Project IDX will also include other generative AI aspects, including smart code completion, an assistive chatbot and natural language actions, meaning the developer can type in commands like “add comments” or “explain this code.”
Google wants feedback
Google is feeling out what the developer community wants from a product like the one Project IDX experiment may eventually turn into.
“The Project IDX team is focused on solving the complex fullstack/multiplatform problems as a starting point, but what direction they go from there is going to be influenced by what users want to do and what feedback they receive from developers,” said Alex Garcia-Kummert, Google’s public relations lead for developer products and tools, in an email to TechRepublic.
“We’re continuously working on adding new capabilities and addressing your feedback,” the Project IDX team wrote in the blog post. “We’re already working on new collaboration features, as we know how important those are in this hybrid work world, as well as deeper framework integrations and more personalized/contextual AI.”
Subscribe to the Google Weekly Newsletter
Learn how to get the most out of Google Docs, Google Cloud Platform, Google Apps, Chrome OS, and all the other Google products used in business environments.
To keep your password safe when logging on to your computer, your instinct might be to make sure no one is watching to avoid an over-the-shoulder attack. However, a new study is showing that you may want to make sure no one is listening to your keyboard clicks, either.
Whereas internal attacks involve infiltrating a device directly often after "shoulder surfing", side-channel attacks are based on the interpretation of a device's information that has been externally gathered. An acoustic side-channel attack, for example, can use the sound of your keyboard clicks to figure out exactly what was typed and use that info to infiltrate your accounts from there.
Also: Zoom is entangled in an AI privacy mess
And now, according to a new study, acoustic side-channel attacks present a greater threat than ever before.
To conduct the experiment, the researchers used a MacBook Pro 16-inch (2021) with 16 GB of memory and the Apple M1 Pro processor. They recorded the laptop's keyboard clicks on both an iPhone 13 Mini that was sitting 17cm away on a microfiber cloth and Zoom's built-in recording function on the laptop.
The researchers then trained a deep learning model using the data collected from the keystroke sound dataset. Once the model was ready, the researchers tested its accuracy using the leftover data.
Also: We're not ready for the impact of generative AI on elections
The results showed that the model could identify the correct key with an accuracy of 95% from the phone recording and 93% accuracy from the Zoom recording, according to the study.
Despite the high accuracy rate of the results, the researchers identified several ways that users could mitigate being attacked, including varying user typing style, using a randomized password with multiple cases, utilizing the shift key, and playing sounds near the microphone in video calls.
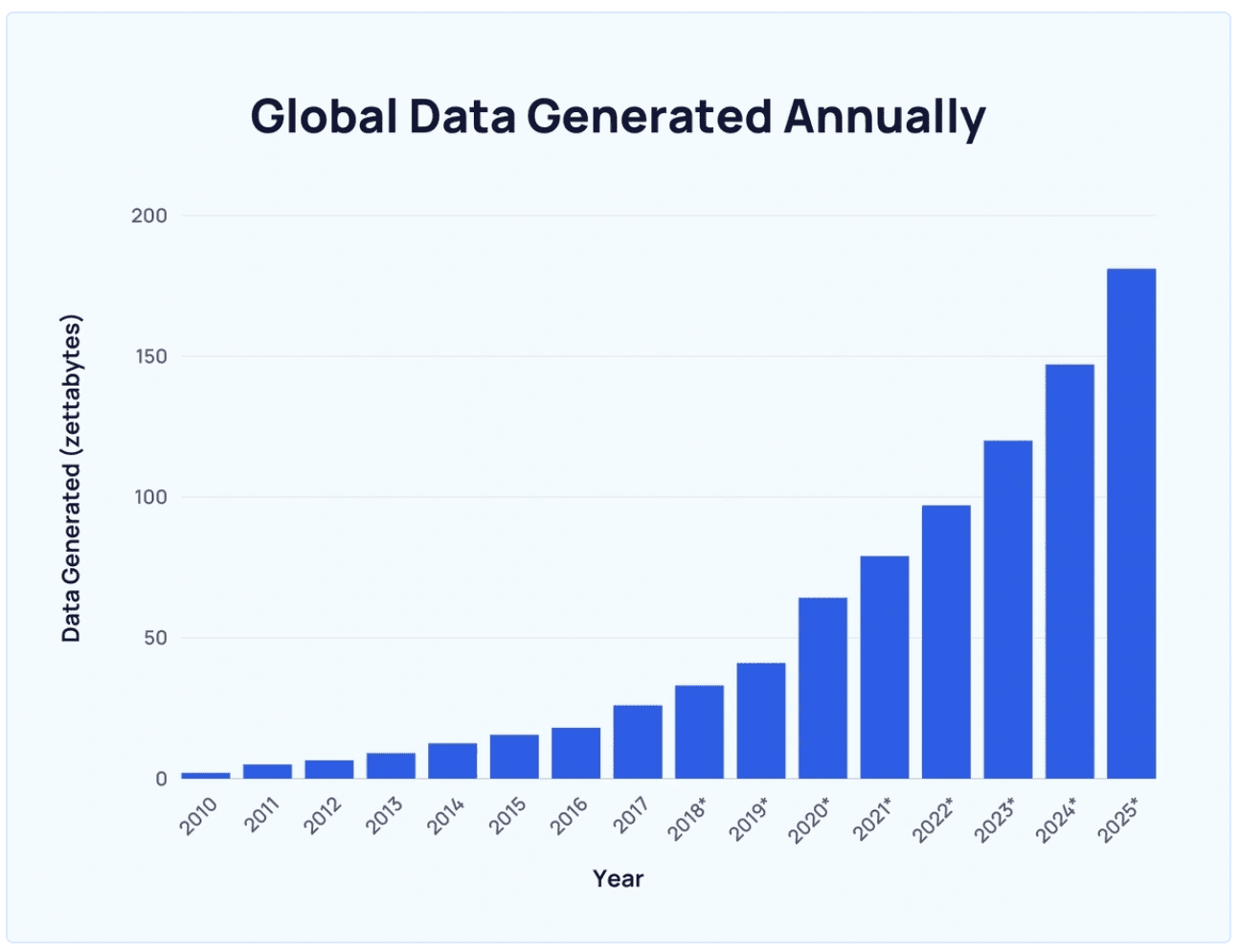
The rate at which the data has been created over the last few years has been exponential, primarily signifying the increased proliferation of the digital world.
It is estimated that? 90% of the world’s data was generated in the last two years alone.
The more we interact with the internet in varied forms? – from sending text messages, sharing videos, or creating music?, we contribute to the pool of training data that powers up Generative AI (GenAI) technologies.
Global data generated annually from explodingtopics.com
In principle, our data goes as input to these advanced AI algorithms that learn and generate newer data.
The Other Side of GenAI
Needless to say that it sounds intriguing at first, but it starts posing risks in various forms as the reality begins to set in.
The other side of these technological developments soon opens the pandora's box of problems? in the form of misinformation, misuse, information hazards, deep fakes, carbon emissions, and many more.
Further, it is crucial to note the impact of these models in rendering a lot of jobs redundant.
As per Mckinsey’s recent report “Generative AI and the future of work in America”?—? jobs that involve a high share of repetitive tasks, data collection, and elementary data processing are at increased risk of becoming obsolete.
The report quotes automation, including GenAI, as one of the reasons behind the decline in demand for basic cognitive and manual skills.
Besides, a vital concern that has persisted from the pre-GenAI era and continues to pose challenges is data privacy. The data, which forms the core of GenAI models, is curated from the internet, which includes a fractional part of our identities.
Image from The Conversation
One such LLM is claimed to be trained on some 300 billion words with data scraped from the internet, including books, articles, websites, and posts. What is concerning is that we were unaware of its collection, consumption, and usage all this while.
MIT Technology Review finds it “next to impossible for OpenAI to comply with the data protection rules”.
Is Open-Source The Solution?
With all of us being fractional contributors to this data, there is an expectation to open-source the algorithm and make it transparent for everyone to make sense of.
While open access models give details about code, training data, model weights, architecture, and evaluation results?—?basically everything under the hood that you need to know.
Image from Canva
But would most of us be able to make sense of it? Probably not!
This gives rise to the need to share these vital details in the proper forum – a committee of experts, including policymakers, practitioners, and government.
This committee will be able to decide what is best for humanity?—?something that no individual group, government, or organization can decide on their own today.
It must consider the impact on society as a high priority and evaluate the effect of GenAI from varied lenses?—?social, economic, political, and beyond.
Governance Does Not Hinder Innovation
Leaving the data component aside, the developers of such colossal models make massive investments to provide computing power to build these models, making it their prerogative to keep them closed-access.
The very nature of making investments imply that they would want a return on such investments by using them for commercial use. That's where the confusion starts.
Having a governing body that can regulate the development and release of AI-powered applications does not inhibit innovation or impede business growth.
Instead, its primary aim is to build guardrails and policies that facilitate business growth through technology while promoting a more responsible approach.
So, who decides the responsible quotient, and how does that governing body come into being?
Need For a Responsible Forum
There should be an independent entity comprising experts from research, academia, corporates, policymakers, and governments/countries. To clarify, independent means that its funds must not be sponsored by any player that can cause a conflict of interest.
Its sole agenda is to think, rationalize and act on behalf of 8 bn people in this world and make the sound judgment, holding high accountability standards for its decisions.
Now, that is a big statement, which means, the group has to be laser-focused and treat the task entrusted to them as secondary to none. We, the world, can not afford to have the decision-makers working on such a critical mission as a good-to-have or side-project, which also means that they must be funded well too.
The group is tasked to execute a plan and a strategy that can address the harms without compromising on realizing the gains from the technology.
We Have Done It Before
AI has often been compared with nuclear technology. Its cutting-edge developments have made it difficult to predict the risks that come with it.
Quoting Rumman from Wired on how the International Atomic Energy Agency (IAEA)?—?an independent body free of government and corporate affiliation was formed to provide solutions to the far-reaching ramifications and seemingly infinite capabilities of nuclear technologies.
So, we have instances of global cooperation in the past where the world has come together to put chaos into order. I know for sure that we will get there at some point. But, it is crucial to converge and form the guardrails sooner to keep up with the rapidly evolving pace of deployments.
Humanity can not afford to put itself on voluntary measures of corporates, wishing for responsible development and deployment by tech companies. Vidhi Chugh is an AI strategist and a digital transformation leader working at the intersection of product, sciences, and engineering to build scalable machine learning systems. She is an award-winning innovation leader, an author, and an international speaker. She is on a mission to democratize machine learning and break the jargon for everyone to be a part of this transformation.
More On This Topic
Using Generative Models for Creativity
ChatGPT, GPT-4, and More Generative AI News
Are Data Scientists Still Needed in the Age of Generative AI?
GigaIO’s New SuperNode Takes-off with Record Breaking AMD GPU Performance August 11, 2023 by Doug Eadline
The HPC user's dream is to keep stuffing GPUs into a rack mount box and make everything go faster. There are some servers that offer up to eight GPUs, but the standard server usually offers four GPU slots. Fair enough, using four modern GPUs offers a significant amount of HPC heft, but can we go higher? Before we answer that question, consider a collection of eight servers each with four GPUs for a total of 32 GPUs. There are ways to leverage all these GPUs for one application by using MPI across servers, but many times this is not very efficient. In addition, shared computing environments often have GPU nodes that may sit idle because they are restricted to GPU-only jobs, leaving the CPUs and memory unavailable for any work.
Stranded Hardware
In the past, a server with a single socket processor, a moderate amount of memory, and a single GPU were much more granular than today’s systems. This granularity allowed for more effective resource application. As servers have packed in more hardware (i.e. large memory multi-core nodes with multiple GPUs) the ability to share resources becomes a bit trickier. A four-GPU node server works great, but it may be used exclusively for GPU jobs and otherwise sit idle. The large granularity of this server means an amount of memory and CPUs may be stranded from use. Simply put, packing more memory, cores, and GPUs into a single server may reduce the overall cost, but for HPC workloads it may end up stranding a lot of hardware over time.
Composable Hardware
The “stranded” hardware situation has not gone unnoticed and the Compute Express Link (CXL) was established to help with this trend. The CXL standard, that is rolling out in phases, is an industry-supported Cache-Coherent Interconnect for Processors, Memory Expansion and Accelerators. CXL technology maintains memory coherency between the CPU memory space and memory on attached devices, which allows resource sharing for higher performance, reduced software stack complexity, and lower overall system cost.
While CXL is not quite available, one company, GigaIO, does offer CXL capabilities today. Indeed, GigaIO has just introduced a Single-Node Supercomputer that can support up to 32 GPUs. These GPUs are visible to a single host system. There is no partitioning of the GPUs across server nodes, the GPUs are fully usable and addressable by the host node. Basically, GigaIO offers a PCIe network called FabreX that creates a dynamic memory fabric that can assign resources to systems in a composable fashion.
GigaIO joins HW over the PCIe bus.
Using the FabreX technology, GigaIO demonstrated 32 AMD Instinct MI210 accelerators running in a single-node server. Available today, the 32-GPU engineered solution, called SuperNODE, offers a simplified system capable of scaling multiple accelerator technologies such as GPUs and FPGAs without the latency, cost, and power overhead required for multi-CPU systems. The SuperNode has the following benefits over existing server stacks:
Hardware agnostic use any accelerator including GPU or FPGAs
Connects up to 32 AMD Instinct GPUs or 24 NVIDIA A100s to a single node server
Ideal to dramatically boost performance for single node applications
The simplest and quickest deployment for large GPU environments
Instant support through TensorFlow and PyTorch libraries (no code changes)
As noted by Andrew Dieckmann, corporate vice president and general manager, Data Center and Accelerated Processing, AMD, “The SuperNODE system created by GigaIO and powered by AMD Instinct accelerators offers compelling TCO for both traditional HPC and generative AI workloads."
Benchmarks Tell the Story
GigaIO’s SuperNODE system was tested with 32 AMD Instinct MI210 accelerators on a Supermicro 1U server powered by dual 3rd Gen AMD EPYC processors. As the following figure shows two benchmarks, Hashcat, and Resnet50 were run on the SuperNode.
Hashcat: Workloads that utilize GPUs independently, such as Hashcat, scale perfectly linearly all the way to the 32 GPUs tested.
Resnet 50: For workloads that utilize GPU Direct RDMA or peer-to-peer, such as Resnet50, the scale factor is slightly reduced as the GPU count rises. There is a one percent degradation per GPU, and at 32 GPUs, the overall scale factor is 70 percent.
32 GPU scaling for Hashcat and Resnet50 for GigaIO SuperNODE.
These results demonstrate significantly improved scalability compared to the legacy alternative of scaling the number of GPUs using MPI to communicate between multiple nodes. When testing a multi-node MPI model, GPU scalability is reduced to 50 percent or less.
CFD Takes Off on the SuperNode
Recently, Dr. Moritz Lehmann posted on X/Twitter his experiences using the SuperNode for a CFD simulation. The incredible videos are viewable on X/Twitter and available on YouTube.
Over the course of a weekend, Dr Lehmann tested FluidX3D on the GigaIO SuperNODE. He produced one of the largest CFD simulations ever for the Concorde, flying for 1 second at 300km/h (186 m/h), using 40 billion cells of resolution. The simulation took 33 hours to run on 32 @AMDInstinct MI210 GPUs and 2TB VRAM housed in the SuperNode. Dr Lehmann explains “Commercial CFD would need years for this, FluidX3D does it over the weekend. No code changes or porting were required; FluidX3D works out-of-the-box with 32-GPU scaling on AMD Instinct and an AMD Server.
Concorde CFD using 40 billion cells using GigaIO SuperNODE.
More information on the GigaIO SuperNode test results can be found here.
This article first appeared on sister site HPCwire.
The initial craze over generative artificial intelligence (AI) appears to have morphed into exercised caution, with organizations now mandating or mulling over bans on the use of such tools.
Some 75% of businesses worldwide currently are implementing or considering plans to prohibit ChatGPT and other generative AI applications in their workplace. Of these, 61% said such measures will be permanent or long-term, according to a BlackBerry study conducted in June and July this year. The survey polled 2,000 IT decision-makers in Australia, Japan, France, Germany, Canada, the Netherlands, US, and UK.
Also:5 emerging use cases of generative AI in commerce, according to Mastercard
Respondents pointed to risks associated with data security, privacy, and brand reputation as reasons for the ban. Another 83% expressed concerns that unsecured applications were a security threat to their IT environment.
However, while 80% noted that it was within an organization's rights to control the applications employees used for work purposes, 74% said bans exhibited "excessive control" over business and bring-your-own devices.
Caution aside, most do recognize the opportunities generative AI can deliver, with 55% citing increased efficiencies. Another 52% believed the technology could drive innovation, while 51% said it would enhance creativity.
Also:How to achieve hyper-personalization using generative AI platforms
Some 81% also agreed generative AI could be tapped for cybersecurity defense.
BlackBerry's CTO for cybersecurity Shishir Singh said: "Banning generative AI applications in the workplace can mean a wealth of potential business benefits are quashed."
He noted that companies instead should look to innovate with "enterprise-grade" generative AI, focusing on value over hype, and adopt caution when dealing with unsecured consumer generative AI tools.
Also:4 ways to detect generative AI hype from reality
"As platforms mature and regulations take effect, flexibility could be introduced into organizational policies. The key will be in having the right tools in place for visibility, monitoring, and management of applications used in the workplace," Singh said.
Gartner this week published research that also revealed generative AI to be a primary concern for enterprise risk executives.
The technology was the second most-cited risk in the research firm's survey for the second quarter of 2023, surfacing for the first time among the top 10, said Ran Xu, director of research for Gartner's risk and audit practice. The report surveyed 249 senior enterprise risk executives in May this year.
"This reflects both the rapid growth of public awareness and usage of generative AI tools, as well as the breadth of potential use cases and, therefore, potential risks that these tools engender," Xu said.