Do you want to know how any business can survive for a long time? Well, the answer is simple- it’s growth. The corporation’s growth is important for business performance and profit. It also facilitates asset acquisition, investment financing, and talent attraction.
Business analytics and data science are important for driving innovation and business growth. Data science can be leveraged by businesses to mitigate unfavorable trends. For example, retail and financial services companies can utilize data science to tackle challenges such as insolvency, layoffs, or imminent closures. By applying data-driven insights and analysis, these firms can make informed decisions and take proactive measures to address these issues.
Moreover, data can guide your company toward success, and you only have to use it properly. In other words, data is the basis of your business analytics and the things you can do with it. To kickstart your business and equip yourself with the necessary skills to excel in this competitive environment, exploring the best data science courses like Great Learning's offerings can be a game-changer. These courses provide comprehensive and hands-on training in data analysis, machine learning, and artificial intelligence, giving you the expertise to harness the full potential of data-driven insights.
Furthermore, investing in continuous learning and upskilling has become paramount in today's rapidly evolving business landscape. Several other online platforms and educational institutions offer valuable courses and resources tailored to boost business growth and data-driven decision-making. For instance, Coursera offers a wide range of data science and business analytics courses from renowned universities and industry experts, enabling learners to stay up-to-date with cutting-edge methodologies.
Moreover, for professionals seeking more specialized skills, platforms like Udacity provide nanodegree programs in data science, AI, and advanced analytics. These nanodegree programs offer project-based learning, mentorship, and industry-focused curriculum, empowering individuals to gain practical experience and apply their knowledge to real-world business challenges.
What Is Data Science and Business Analytics?
Using machine learning algorithms, data science creates predictive models for the growth of your business. These pieces of information, used for analysis, are very crucial for your business. Also, these pieces of information come from a wide range of sources.
The business adores data science. They employ it in conjunction with analytics to comprehend consumer behavior and support in-the-moment decision-making.
In Business Analytics, data analysis, statistical models, and other quantitative techniques are used for business growth.
The information obtained for analysis is used for decision-making. Achieving success in business analytics relies on the availability of high-quality data, competent analysts with a deep understanding of the industry and relevant technologies, and a firm commitment to utilizing data to reveal valuable insights that inform strategic business decisions.
Uses of Data Science and Business Analytics
Data science allows for the extraction of meaningful insights and predictions from seemingly disorganized or unrelated data. On the other hand, business analytics enables the analysis of all available data. By utilizing business analytics, companies can comprehensively examine and interpret their data, gaining valuable insights to drive informed decision-making and optimize business processes.
Data collected by tech companies can be turned into valuable or profitable information by employing methods.
Data science has also helped the transportation sector. Using autonomous vehicles simplifies the task of minimizing the number of collisions.
With business analytics, you can utilize modern analytics and statistics to uncover hidden patterns in datasets. Inform stakeholders by distributing information through interactive dashboards and data-driven reports. Adapt and defend decisions in light of new facts. Keep an eye on KPIs and react quickly to shifting patterns.
Analytics is the way to go if your company wants to accomplish one or more of these objectives. The next step is choosing the best business analytics solution for your company's needs.
Let us learn the benefits of data science and business analytics for business growth.

Image source: https://blog.athenagt.com/wp-content/uploads/2018/09/Blog-info_1074698057-1.png
Consider two compelling case studies that reflect the impact of data science and business analytics on business growth.
- In Case Study 1, the strategy used was building a polynomial regression model to determine the influence of market level targets on Bid Success. Using linear and non-linear equations, predictors were identified that significantly influenced the probability of winning or retaining existing clients. This model proved successful as it led to a 30% improvement in client acquisition rate and a 40% boost in client retention rate.
This approach could be applied to various industries or businesses, adjusting the factors and variables to suit specific needs. This means by identifying and properly utilizing key market indicators or predictors, businesses can significantly enhance their client acquisition and retention rates.
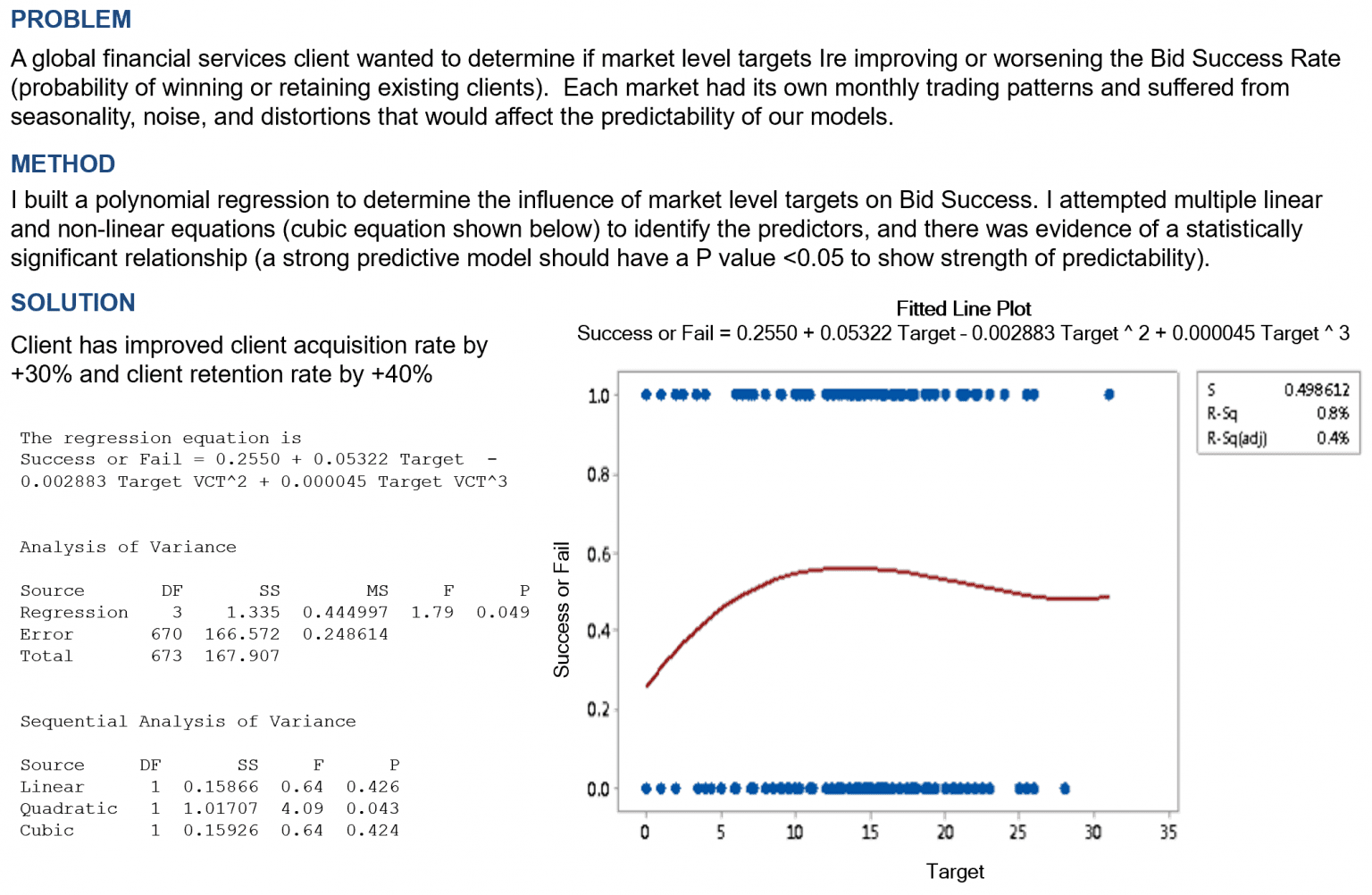
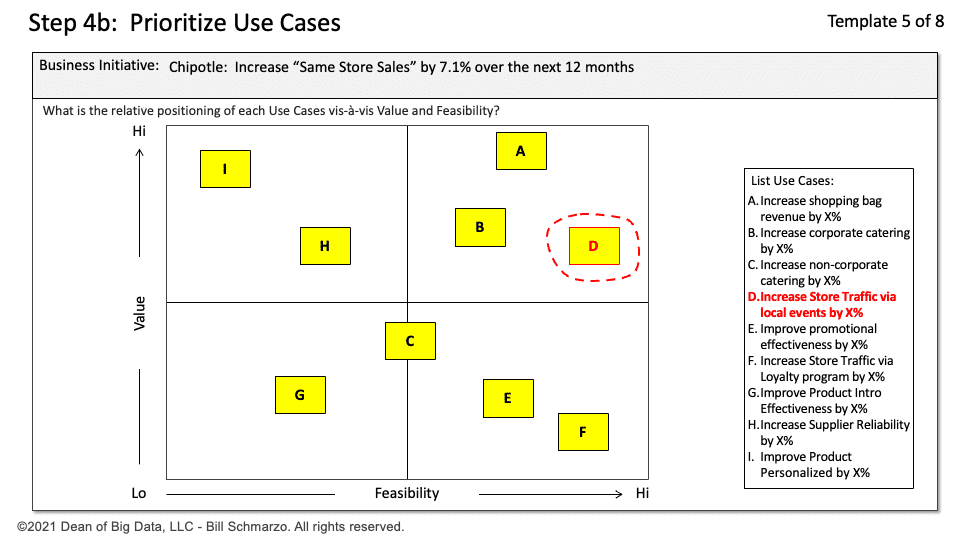
Image source: https://www.baselismail.com/wp-content/uploads/2019/03/2019-03-05-16_12_23-Basel-Ismail-Case-Studies.pptx-PowerPoint-1536×1002.png
- In Case Study 2, a sales incentive model was created to improve sales performance. This model was built using multivariate models with market factors and corresponding policy figures from previous years as inputs. It was found that there was a positive correlation between the target set for the sales team and their ability to close deals profitably. This model led to a 45% year-on-year improvement in sales performance.
This strategy emphasizes the significance of properly incentivizing sales teams and setting competitive market-specific targets to boost sales. By properly understanding the relationship between incentive structures and sales performance, companies can better motivate their sales teams and optimize their sales results.
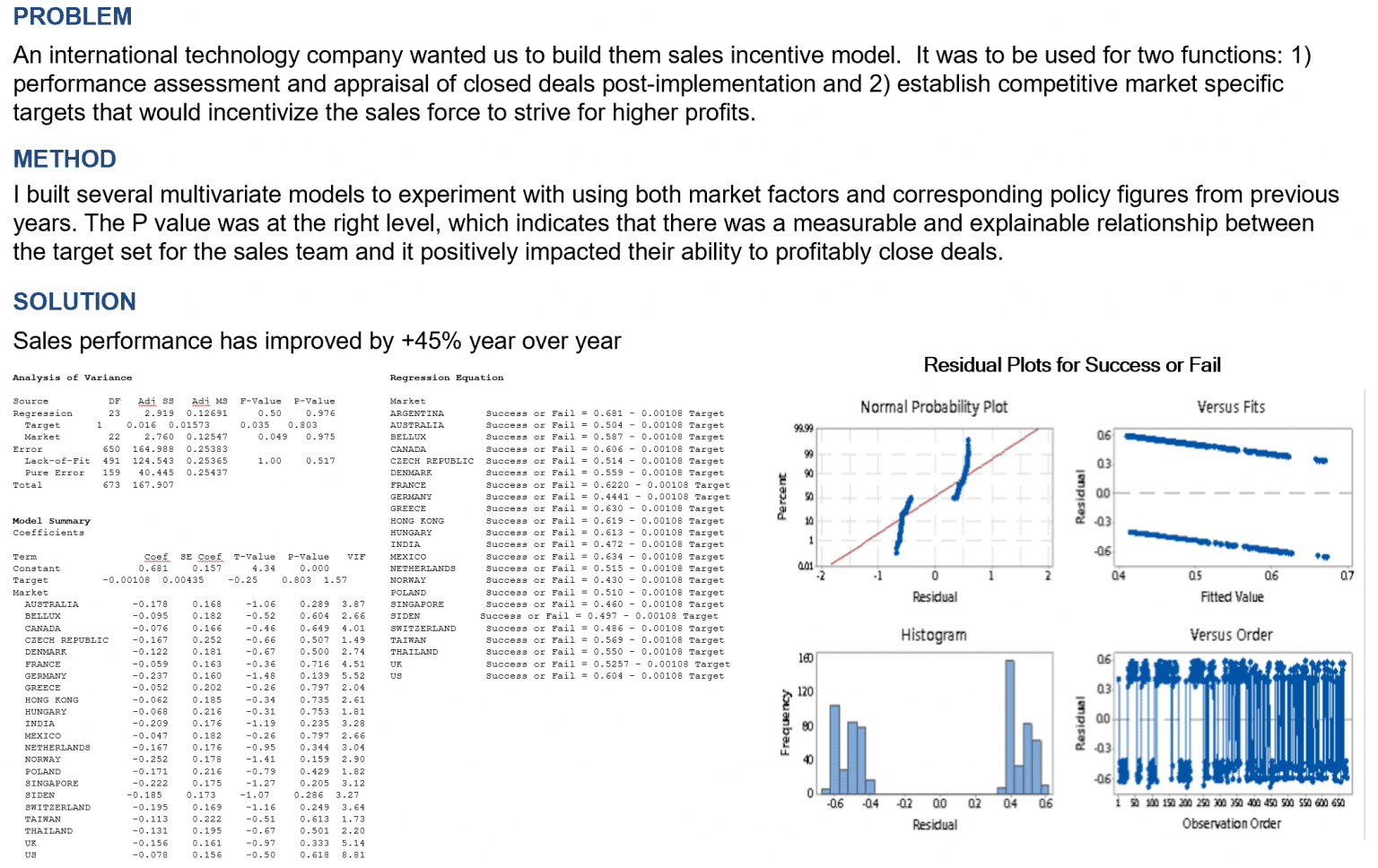
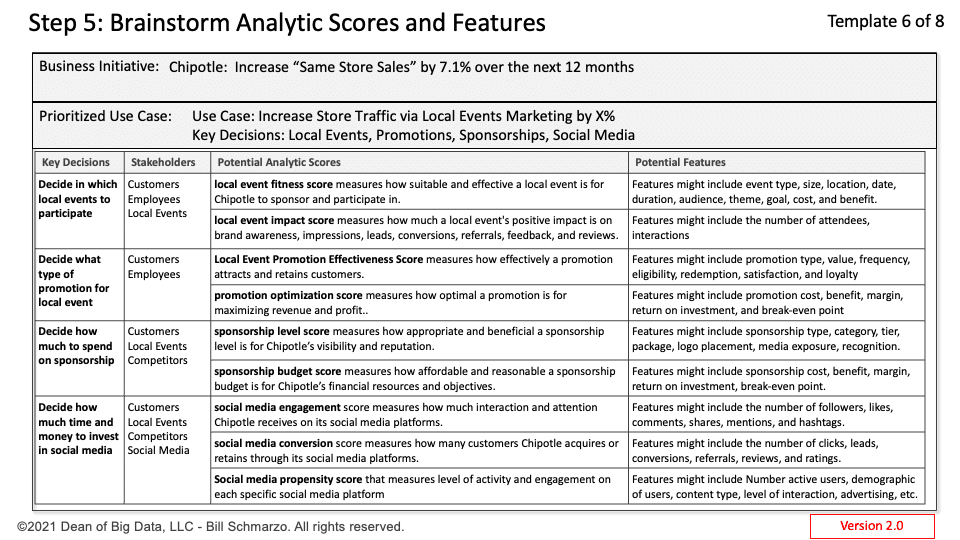
Image source: https://www.baselismail.com/wp-content/uploads/2019/03/2019-03-05-16_18_30-Basel-Ismail-Case-Studies.pptx-PowerPoint-1536×968.png Why Data Science and Business Analytics for Business?
Data science's importance in the current business environment is well known. That's because businesses must make decisions based on data if they want to remain competitive and continue to expand. Because it gives firms a method to use data more effectively, data science for business has gained popularity in recent years. Today, businesses, including hospitals, banks, and colleges, use data science to support various activities.
Commercial organizations will only be able to pay attention to the significance of data science in business in the near future because data is utilized in almost every part of our life. If they succeed, they have a decent chance of winning their competition without dropping a game. As a result, data science for small firms enables them to outperform larger corporations or businesses of a larger scale that need more data knowledge and experience.
The Benefits of Business Analytics
Business analytics provide actionable insights. The business makes predictions about the future via data visualization, and these perceptions support future planning and decision-making. Business analytics spurs growth and measures performance. After learning all of this, now is the time to know about business analytics, let's examine how it differs from business intelligence.
Data Science Certificate
To work as a data scientist, a bachelor's degree in data science or a computer-related field is typically required, and for certain positions, a master's degree may be necessary. Therefore, it is crucial to verify all the educational requirements before pursuing this career.
Additionally, various certifications, such as project model certification, internship certification, and qualification certificates, among others, are essential for enhancing your qualifications and marketability in this field. A diploma can also be pursued online if you hold a degree in any other discipline, in addition to this. You can immediately start taking a variety of quick online data science courses.
Business Analytics Certificate
A business analytics certificate allows you to make employers believe that you have the skills to make your business successful. You can convince them about you having the skills necessary to drive strategic decision-making and collect and analyze the data. It gives you the abilities required to work as a business analyst who uses data to enhance, expand, and optimize corporate processes.
What Your Business Can Gain From Data Science?
Smart strategies are always needed for business improvement. You can use data science in your business in the following ways:
- Data mining and analysis: To uncover patterns and relationships that can be used in data analysis to help solve business problems, large data sets are sorted in data mining. Businesses can foresee future trends and make better business decisions by utilizing data mining techniques and technologies.
- Final decision selection: The best and most effective decision should be picked from the analytic options. The business's success will depend on this ultimate decision.
- Information management: Data scientists who actuarially select useful data keep the company's data bank accurate and up-to-date. The company uses this data bank when required.
The Scope of Business Analytics and Data Science
Business analytics has many different applications. For people looking to advance their careers while earning a good salary, business analytics has emerged as one of the top employment options in the past decade.
For individuals with the appropriate skill set, there are several opportunities in India's large field of data science. Businesses can benefit from the services of data scientists by making better decisions, learning more about their consumers, and automating tasks with the right training.
Conclusion
Business analytics has helped many businesses grow with the help of insightful insights. Businesses can personalize their interactions with customers by using business analytics techniques, which can be learned through business analytics courses. They can even incorporate client feedback into the development of more profitable products. In the foreseeable future, data will remain indispensable for the operation of any company. Data represents actionable knowledge that can significantly impact the difference between a company's success and failure. As the saying goes, knowledge is power.
By integrating data science tools, businesses can now harness the power of data to predict future growth, identify potential issues proactively, and formulate effective plans for success. Embracing data-driven approaches empowers businesses to make informed decisions and stay ahead in today's competitive landscape.
In the foreseeable future, data will remain indispensable for the operation of any company. Data represents actionable knowledge that can significantly impact the difference between a company's success and failure. As the saying goes, knowledge is power.
Erika Balla is a a Hungarian content writer from Romania, specializing in AI and data science topics. Her goal is to help businesses simplify complex information and make data science more accessible to a wider audience, leveraging my expertise in writing and advanced technology knowledge.
- How to Better Leverage Data Science for Business Growth
- How to Use Analytics to Accelerate Business Growth?
- Applications of Data Science and Business Analytics
- Discover What It Takes to Scale Innovation & Data Science
- Learn modern forecasting techniques to help predict future business…
- KDnuggets News, May 4: 9 Free Harvard Courses to Learn Data Science; 15…