Meet Relume, the bootstrapped AI web builder that wants to supercharge Figma and Webflow Rita Liao 7 hours 
Despite the abundant venture capital available for startups in the current wave of generative AI breakthroughs, totaling $14 billion in equity funding as of August this year, Relume has turned down investments and instead relied on bootstrapping since its launch in November 2021.
“We are focusing more on building a product that we can get paid for. Bootstrapping pushes us in the direction to build a better product,” Dan Anisse, co-founder of Relume, told TechCrunch.
Sydney-based Relume started as a component library for web design giants Webflow and Figma providing over a thousand components, which are customizable blocks that contain content, nav bars footers, and other elements that can be easily reused across a website. When ChatGPT became a global sensation late last year, the Relume team, like many other productivity tools out there, began to contemplate how AI could enhance its features.
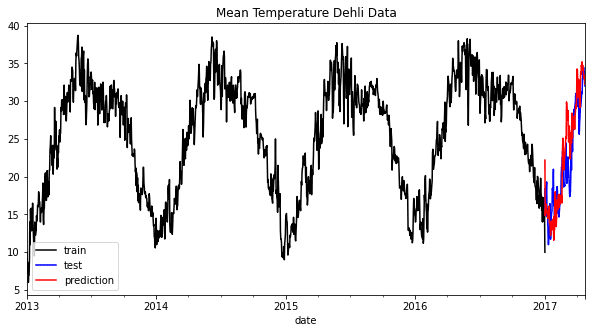
In August, Relume updated its web design platform with a generative AI twist. By inputting a text prompt to describe the website one is building, say, “XYZ is a food delivery app that brings local farm produce to your doorstep on the same day,” its AI can quickly sketch out a sitemap that is editable and can be regenerated with a click.
Next, users can preview what the site actually looks like by switching from the “sitemap” mode to “wireframe”, which is a visual representation of a site. Relume’s algorithms can automatically populate the wireframe with components from its library and, again, allow users to move these visual elements around. At this point, users already have a functional website.

Relume’s AI-generated sitemap / Image: Relume
Relume trains its web-building AI in-house by leveraging OpenAI’s large language model for prompt interpretation. The text output generated from the AI can then be converted into a visual wireframe in real time as the text matches the code of the site.
Relume has amassed some 54,000 users to date, 10,000 of whom signed up following the AI feature launch two weeks ago. The platform, which is the brainchild of a small team of seven who hail from the likes of design giant Canva and early-stage startup builder Antler, has been able to maintain a retention rate of around 90%, according to Anisse. With a starting price of $32/month, the company is targeting individuals, freelancers and web design agencies, who can now “get up to ten websites a month instead of three.”
Nonetheless, the goal isn’t for AI to complete everything; Relume is meant to empower rather than replace designers. “We are giving [designers] 70% of the project, but there is still 30% that needs to be done manually,” stressed Anisse. “We are just doing a lot of the heavy lifting. The remaining 30% is creating the style guide, working out things like the font, background, color, images and etc, decisions that need to be considered by humans.”
The fine-tuning part happens on Figma and Webflow. Through a web plug-in, Relume projects can be synced to the two popular web-building tools in a compatible format, upon which users can explore a myriad of editing options like changing the shape and color of buttons.
From giants like Wix to new entrants like Universe, there’s no lack of web design tools rushing to embrace generative AI. Relume differentiates, Anisse claimed, by building on top of established design systems while some of its rivals want to topple them. Being part of mature ecosystems allows the startup to tap a massive user base, but the strategy also carries the risk that the dominant players can sever access at any given moment.
“It’s a strategic choice,” the founder said, pointing out that the startup has actually “got some good reception from Webflow” with the company’s CEO giving a shoutout to Relume on Twitter.
Wow, this is absolutely incredible – huge props to the @relume_io team for bringing these amazing AI superpowers to more Webflow visual developers! https://t.co/t20gS5OTqX
— Vlad Magdalin (@callmevlad) August 7, 2023
“Anything is possible with a significant amount of resources and engineering,” said Anisse when asked about potential copycats. But he’s not too concerned, saying that “our moat is our strong community who likes what we are doing and the fact that competitors will have to manually build a component library from scratch and train it.”
Today, Relume’s Slack channel boasts almost 4,500 members who actively talk about job opportunities, post projects to seek feedback and share tips on running design agencies.
While not currently looking for funding, Relume is not ruling out external funding in the future but wants to seek ones that “serve us the best strategically” and “understand how design platforms work,” said Anisse.
Wix’s new tool can create entire websites from prompts