Organizations have been ramping up their cloud adoption and expanding their digital infrastructures, but often without much concern for the environmental impact of these operations. Balancing the need for substantial data infrastructure with more eco-friendly policies should be top of all organizational to-do lists, and creating a specific data center decarbonization strategy will be key. This will range from improving the visibility and measurement of power usage, to actually reducing the carbon footprint of each operational layer. In the upcoming webinar Decarbonizing the Data Center: Making Data Modernization More Sustainable, panelists from Cisco and Hitachi Vantara will discuss the changing attitude to data center sustainability and cloud carbon emissions, the importance of understanding your energy consumption baseline, and much more.
Managing the supply chain is exceedingly difficult with global conflicts and market ups and downs interfering with companies’ ability to timely deliver and fulfil orders. Tune into the Overcoming Supply Chain Challenges summit to hear leading experts discuss emerging technologies to help protect and streamline supply chain management along with strategies and tools to secure the supply chain against the many cyber threats it faces. Register for free and gain access to live webinars, fireside chats and keynote presentations from the world’s leading supply chain innovators, vendors and evangelists.
Top Stories
How organizations can prepare for rogue AI August 22, 2023 by Ari Kamlani Rogue AI, or an autonomous artificial intelligence system that commits potentially dangerous acts, may take many forms and can bring with it varying levels of severity, threats, or harm.
Beyond data science: A knowledge foundation for the AI-ready enterprise August 21, 2023 by Alan Morrison Data science was a vaguely defined discipline to begin with, but it’s shaped up substantially lately. Execs now yearn to take immediate advantage of generative and other clearly useful (if currently problematic) kinds of AI.
Data-driven solutions to creating a net-zero office space August 15, 2023 by Jane Marsh A net-zero office space produces emissions equal to or less than the amount it removes from the atmosphere. Options for achieving that goal include using renewable energy and reducing waste. Data-driven actions can help decision-makers reach their net-zero goals.
In-Depth
Top 4 generative AI benefits for business August 22, 2023 mby Yana Ihnatchyck In the midst of the Fourth Industrial Revolution, generative AI emerges as a beacon of transformative potential. While AI’s capabilities in automation, recommendation, and prediction have been widely acknowledged, its generative functions have opened new horizons for businesses globally.
The use of Big Data Analytics for better growth and innovation August 22, 2023 by ManojKumar847 Innovations in technology are changing the rules when it considers the use of big data and analytics for better growth. Advanced software systems are highly decreasing analytics time, hence offering companies the potential for making quick decisions that will help in boosting revenue, mitigating costs and stimulating growth.
Modern data quality management August 22, 2023 by Edwin Walker Modern Data Quality refers to the process of ensuring that data is accurate, reliable, consistent, and up-to-date in today’s data-driven environment. It involves implementing advanced technologies and methodologies to maintain high-quality data that meets the needs of various data-driven applications and analytics.
The relationship between Big Data and AI August 22, 2023 by Kent State CoBA Big data and artificial intelligence are able to collaborate to help organizations reap a variety of benefits. Since AI requires large amounts of data in order to learn and make decisions, it is able to utilize big data as a source of raw material.
The impacts of quantum computing on the future of data science August 21, 2023 by John Lee Key takeaways In an era marked by exponential technological advancements, the convergence of quantum computing and data science is a pivotal point of transformation. The synergy between these two fields promises to revolutionize how we process, analyze, and extract insights from massive datasets.
Integrating GenAI into “Thinking Like a Data Scientist” Methodology – Part II August 20, 2023 by Bill Schmarzo My journey continues as I integrate a GenAI tool (Bing AI) with my Thinking Like a Data Scientist (TLADS) methodology. In part 1 of this series, I used Bing AI to validate, augment, and enhance the first three steps in the TLADS methodology.
DSC Weekly 15 August 2023 August 15, 2023 by Scott Thompson Read more of the top articles from the Data Science Central community.
Understand the ACID and BASE in modern data engineering August 15, 2023 by Shanthababu Pandian Dear Data Engineers, this article is a very interesting topic. Let me give some flashback; a few years ago, someone in the discussion coined the new word how ACID and BASE properties of DATA. Suddenly drop silence in the room.
This article is based on a pre-brief for press held Wednesday, August 16. The keynote presentation will be held today at 12 PM EST. This story will be updated as needed accordingly.
VMware is making several announcements related to new cloud, edge and machine learning services on August 22 at VMware Explore held in Las Vegas. These announcements include services for accelerated ransomware recovery, a new format for their networking and security developer services product as a cloud-managed subscription and additions to their cloud infrastructure-as-a-service offerings.
Jump to:
VMware Tanzu platform expands with AI, increased Kubernetes support and more
VMware Cloud Foundation gets a boost
VMware launches Edge Cloud Orchestrator
Machine learning drives new DEX and remote work insights
VMware Tanzu platform expands with AI, increased Kubernetes support and more
VMware Tanzu, a modular platform for developing apps across clouds, will receive upgrades on August 22, including:
Unification of common sets of services that were on both the VMware Tanzu and VMware Aria platforms to create the combined VMware Tanzu Intelligence Services.
.NET Core support.
A new developer portal with DIY Backstage and open source plugins. This portal is now in beta.
The VMware Tanzu Application Engine, which orchestrates apps and runtime, including across different Kubernetes clusters and clouds. This application engine is also in beta.
Extended lifecycle management for Azure Kubernetes Services and VMware’s other Kubernetes support services.
VMware Tanzu Hub, an existing service for integrated solutions, will include generative artificial intelligence in the form of Intelligence Assist, a natural language chatbot.
Punima Padmanabhan, senior vice president of modern apps and the management business group at VMware, said CIOs want to increase the speed at which their teams can bring applications to market. At the same time, “Business priorities, business objectives can change within days,” Padmanabhan said during a press pre-brief. Therefore, there is demand for helping vendors integrate apps across the cloud and gain speed and agility. Services like those in the VMware Tanzu updates were made to do that.
SEE: How to streamline the IT mobile app development pipeline and get your apps into production faster (TechRepublic)
VMware Cloud Foundation gets a boost
The VMware Cloud portfolio is expanding with improved performance for VMware Cloud Foundation, new multicloud networking, security and developer services and expanded utility for its Ransomware Recovery-as-a-Service offerings.
The Ransomware Recovery-as-a-Service platform has been enhanced with the following:
Concurrent Multi-VM Recovery Operations in parallel to decrease recovery time. (Available August 22.)
Ability to run production workloads in the cloud. (Available in the third quarter of 2024.)
Cybersecure storage service for integrating ransomware recovery into native vSAN storage; this is currently in Tech Preview.
Expanded recovery solution to Google Cloud VMware Engine. (Available August 22.)
“Our latest VMware Cloud advancements further modernize cloud infrastructure and deliver a single cloud operating model that improves developer productivity and advances security,” said Krish Prasad, senior vice president and general manager, cloud infrastructure business group, VMware, in a press release.
In the second half of 2023, VMware Cloud customers can expect to see improved performance (10x tasks at the same time, 4x storage performance boost), faster upgrades (reduced upgrade time by 33%, accelerated AI workloads with 2X GPU capacity) and greater scale and security (increased workload domain by 60% and multi-cloud policy enforcement) in VMware Cloud.
NSX product becomes NSX+
VMware is expanding its NSX product with NSX+, a cloud-managed version of the same service, which will include Virtual Private Clouds.
NSX+ will be available in the third quarter of 2024.
VMware launches Edge Cloud Orchestrator
The VMware SASE Orchestrator service will now be known as VMware Edge Cloud Orchestrator and have expanded capabilities for bringing together IT and OT. It optimizes edge cloud deployment through right-sizing infrastructure using pull-based orchestration for security and administrative updates, and using network programmability defined by APIs and code.
It was developed because IT and OT are increasingly converging in many industries, said Sanjay Uppal, senior vice president and general manager of the service provider and edge business unit, VMware, in a press pre-brief.
“You get all the security compliance, and you reduce risk. Of course, the other benefits are you can reduce your operational expenses and expenditure going forward as well,” said Uppal.
New edge capabilities announced at VMware Explore include:
Novel VMware Edge orchestration capabilities for managing multiple edge services.
A new retail edge industry solution, VMware Retail Edge.
A VMware Edge managed connectivity service for private mobile networks. This will be available soon.
VMware’s edge stack, which incorporates the Edge Cloud Orchestrator, is used in manufacturing, retail, energy and healthcare.
Machine learning drives new DEX and remote work insights
VMware is adding generative AI to integrations for the Anywhere Workspace platform, a work platform for creating secure remote workplaces across different devices and locations. VMware has tasked generative AI and machine learning with running the platform’s Insights feature, available in Q3 2024, which detects anomalies on frontline devices or virtual desktop environments and reports those issues to the IT team.
More Playbook instructions have been added to the Anywhere Workspace platform so IT teams can create workflows within the platform for solving DEX problems. The new Playbook instructions will be available in beta in Q3 2024, followed by general availability in Q4 2024. Both the Insights and Playbooks features can be used for digital employee experience remediation.
App Volumes support expanded
Customers using virtual apps from VMware will be able to use enhanced features going forward. App Volumes support has been expanded to customers with persistent VMware Horizon environments; they will be able to use App Volumes to deliver apps to numerous persistent virtual desktops at once. As part of VMware’s plan to streamline as much of the process as possible, App Volumes is compatible with Citrix, Microsoft and Amazon virtual desktop and app deployments as well as VMware Horizon.
App Volumes persistent virtual desktop infrastructure will be available in beta in Q3 2024 and generally in Q4 2024.
“We are thrilled to unveil new advancements for our customers that expand data sources and insights, integrate with technology partners for improved security and unify app delivery strategy across all virtual desktops and apps,” said Shankar Iyer, senior vice president and general manager of end-user computing at VMware, in a press release.
Subscribe to the Cloud Insider Newsletter
This is your go-to resource for the latest news and tips on the following topics and more, XaaS, AWS, Microsoft Azure, DevOps, virtualization, the hybrid cloud, and cloud security.
Amidst the recent AI boom, there has been a lot of concern about whether AI will displace workers. A new report, however, shows that many professionals are more optimistic about the rise of AI.
Thomson Reuters's Generative AI & the Future of Professional Work report surveyed 1,200 professionals in North America, South America, and the UK regarding their thoughts and experiences about AI.
Also: One in four tech professionals are ready to leave their jobs, survey reveals
Of the professionals surveyed, 64% said they expect their professional skills to be "more highly prized" over the next five years. Twenty-four percent of those respondents see that positive change occurring in the next 18 months while 40% see it happening between 18 months and five years from now.
On the other hand, when asked how likely AI was to cause the demise of their profession with their skills no longer being in demand, 66% said that they did not expect that change to happen.
Also: This AI-generated crypto invoice scam almost got me, and I'm a security pro
The respondents likely feel like their skills will increase in demand because, despite AI's advanced capabilities, there are human attributes that AI will likely never be able to do as well as a human, such as people skills, higher level analysis, and thinking outside of the box.
When asked what aspects of AI the professionals fear the most, the biggest fear wasn't job loss (19%) but actually compromised accuracy (25%).
The fear stems from people using AI, such as chat tools, for research and taking the results at face value, not realizing the inaccuracy of the results, which could spread misinformation.
Also: ElevenLab's AI voice-generating technology is expanding to 30 languages
"Clients will use AI in their own research, which may give them a false understanding of the issues of the case," a lawyer respondent pointed out in the report.
This fear highlights the need for human evaluation when using generative AI tools, as well as the need for additional guardrails in AI models that help improve their accuracy and reliability.
Also: YouTube touts AI principles to protect music creation
Lastly, 68% of the respondents reported anticipating an increase in work done by those without traditional qualifications.
Furthermore, two-thirds of respondents believe that AI will prompt the creation of new career paths. The report uses the example of tasks shifting from a JD or CPA to an employee with professional licensure, such as a paralegal or junior professional that can leverage AI tools.
Also: 5 ways to explore the use of generative AI at work
We have also already seen the emergence of new roles that haven't existed before, such as prompt writing, which pays individuals to develop prompt inputs for chatbots to meet business goals.
By Ari Kamlani, Senior AI Solutions Architect and Principal Data Scientist at Beyond Limits
Rogue AI, or an autonomous artificial intelligence system that commits potentially dangerous acts, may take many forms and can bring with it varying levels of severity, threats, or harm. Intelligent systems, while incredibly useful and full of great potential, can still malfunction, exhibiting misbehavior in an unexpected and undesirable manner. Some of these malfunctions may be known and articulated when designing the system, but oftentimes, many may fly under the radar due to learned behavior, lack of behavioral testing, or because they only emerge when exposed to different environments than intended.
This could take the form of an airplane malfunctioning mid-flight, causing the system to maneuver and navigate incorrectly. Data breaches that occur on a system protected by AI, exposing confidential or proprietary information, that may not be encrypted or redacted. There have been countless occurrences of companies exposing private data, either due to incorrect or no company policies in place or cybersecurity incidents — rogue AI may further complicate these situations.
Beyond the misbehavior, AI systems can be easily misused by organizations and individuals when put into practice. Today, companies must understand what rogue AI is, the risks it poses, and how they can responsibly prepare their AI systems to prevent rogue outcomes.
Understanding Rogue AI
Today, unless an AI system was specifically designed to be a malevolent security threat, the threat of rogue AI wreaking havoc is small. AI is not and will not become self-aware (at least, not anytime soon). The real threats are autonomous AI systems designed to respond to perceived threats.
In contrast to the better performing models — the “offensive” side of AI — rogue AI focuses on the “defensive” side, understanding, reasoning, and being proactive to protect and prevent conditions of what can go wrong. This is common in the info security space, where ‘red teams’ are integrated internally to play an adversarial role.
For example, an automated nuclear response system that is designed to fight back in case human leaders were unable to respond to an attack. At a high-level, the system would monitor channels for nuclear attack, and if detected, alert response channels. If all response channels were unresponsive, the AI might assume they were incapacitated and initiate an automated retaliation. It is possible to “jailbreak AI” or trick it such a system into believing there is an attack and that it cannot get a response, leading to inadvertent nuclear war.
While this is not technically “rogue,” the AI could pose a security threat simply because of how the system is designed. While many less existential scenarios exist, the important message is that security threats emerge because of how AI and systems interact, are built and used, not because of the AI itself.
Weighing the Potential Risk
When AI is deployed, progressing from sensory behavior towards that of judgement, decision control, and actions, undesirable behavior can have potentially dangerous effects. When humans transfer partial or full control to an intelligent system to influence decisions or act, there is a risk of placing trust where it shouldn’t be.
For example, if an illogical or immoral recommendation is given to a person, they can judge its utility and decide to pivot, try again, or optimize. But if this control is transferred to intelligent systems, not only may error rates potentially increase, those responses or actions could be highly questionable. This feedback loop is highly desirable and important when the actions and errors have high risk, impact, or decisions have high uncertainty.
Large language models (LLMs) and dialogue engines may be intentionally instructionally misled and other systems may suffer from data quality issues, like a prediction model training on a bad sensor feed. While it is possible to build protections to safeguard scenarios, there have been many scenarios with conversational dialects where these conditions have gone unforeseen.
As not all behaviors and errors are equal and the risk and severity of conditions progress, the underlying consequences can have long-lasting effects and take long cycles to recover from. It is important to identify and understand who the harm applies to (e.g., individuals, groups, organizations, ecosystems) and in what context (e.g., harm to interrelated systems within the global financial system).
The World is Changing
Traditionally, AI model development has been heavily dependent on having a good sampling representation of historical data that maps well to the applied use cases. However, it is unlikely that the industry will be able to continuously capture data and events to guard against. Instead, it will always have a very limited narrow view or biased view based on the context and scenario relative to the application usage.
Fundamentally, the way humans communicate and express intent and preferences with intelligent models is constantly changing. This can be seen particularly in the context of probing and prompting with large parameterized generative models.
A Framework for Rogue AI
As misaligned AI behavior is dependent on the environment and scenarios it operates in, what fits for one organization may be totally inadequate for another. Having a structured set of methods can help organizations stay ahead of the curve, mitigating the effects of potential harmful threats. For example, companies that operate in a highly regulated environment, such as the financial, healthcare, or energy sector, will need to place higher weight on compliance with government and state policies.
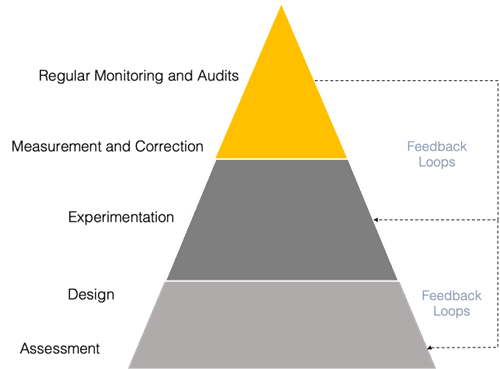
Below is a diagram of an opinionated point of view (POV) systematic framework on how to approach rogue AI. There are already existing frameworks not specific to rogue AI, such as the NIST AI Risk Management Framework.
Assessment
Organizations and divisions within should take stake with performing an end-to-end (E2E) lifecycle audit or assessment of the current stakes of their businesses processes. The below questions should be asked during this process:
Who are the users of the system and are they using it a responsible manner?
What are the known conditions of the bad actors?
What were the unknown conditions that occurred that had not been planned for?
Had bad design decisions been encountered throughout the lifecycle?
Design
Identification: Organizations must identify what can go wrong in the context of in-real-life applied contextual scenarios. Listing the potential weaknesses, vulnerabilities, and violations where AI can be misused or misbehave is necessary. In mitigating harm, it is important to recognize not only the events and scenarios, but who the responsible parties are that will utilize and deploy or distribute the applied usage of AI.
Definition: Defining the risk class of severity taxonomy and associated per violations in the identification phase is the next step. Implementing a classification taxonomy and identifying boundaries based on assumptions and intended behavior can ensure the appropriate guardrails are put in place and the level of AI involvement in important decisions.
When progressing higher up the stack, higher cases of risk and harm are introduced — it is important to mitigate exposure to risk when moving up the rack.
Mapping: Finally, map out which failure modes are riskier than others, when those events are triggered, the risk impact associated with them and measurement dimensions such as frequency, recency, recurrence.
For scenarios where it may be impossible to enumerate all risky situations, such as long tail or insufficient negative training data (behaviors that should never occur), best practices should be created and observed.
In recent years, different AI research and development (R&D) disciplines have used some form of ‘checklist,’ such as those for behavioral testing in natural language and recommender systems to reduce undesirable behavior and cut down risks. However, this assumes, individuals or corporations explicitly know the characteristics to guardrail and test against at reasonable scale.
Experimentation
For the experimentation set in the framework, organizations can follow several key practices:
Decomposition: Decompose and select a series of experiments to de-risk how AI may be misused or may misbehave based on the risk class severity, input context, or decision making. Select a set of experiments to execute for where AI is appropriate to be used.
Sequencing: From a sequence of trials, execute a series of “connected” progressive experiments, to test and gather more evidence, validating or invalidating any assumptions, further prioritizing and ranking. As the industry gains maturity in the experiments, reducing uncertainty, launching limited pilots in a trustworthy and safe manner will be realistic. These experiments will help provide a better vision.
Protection: Further introduce protection, safety, privacy, and/or secure policy control higher-level layers that will guard against AI being misused a reliable manner, incorporating multiple redundant fail-safes. Decide where it is appropriate to have a human-in-the-loop (HITL), intervening and acting on suggestions or decisions, and limiting the decisions of automation. While automation principles may seem desirable for scaling across responsiveness and cost perspectives, they can also have an undesirable effect for organizations and individuals.
As noted in assessment and sesign sections, there may be many too many conditions to test for, many of which may be unknown. In the context of rogue AI, a good starting point is to check for these high impact usage and behavior patterns that have high utility and frequency. However, it is important that experiments are also executed for those more severe risk classes, even if rare, that may be at the long tail.
Measurement and Correction
The steps for measurement and correction include steering, mitigation, and the creation of policies:
Steering: What was learned from these experiments? How could the organization course-correct and steer AI in a better manner, ensuring that behaviors are not poorly aligned with human values. There is the possibility that the system may not have been trained to be well aligned, such as that form biased pre-training data. In this next wave of AI, companies should expect the nudging and steering of AI to be a major focus.
Mitigation: Organizations must ensure a plan is in place to limit potential threats and correct, mitigate, and normalize behavior. Having a plan to address mitigate and response to incidents based on the severity can help. Ensuring guardrails are put in place, connected to the appropriate risk class and risk score, based on experimentation and assumptions or hypotheses that need to be corrected, is crucial.
Policies: With questions surrounding AI to be governed and regulated, the applied misuse or harm may warrant rethinking if the risk is too large to not have oversight. For example: the establishment of global conventions and guidelines for the use of AI in military and life-serving infrastructure (such as water, food, electricity, etc.) and beyond.
Regular Monitoring and Audits
As AI is undergoing dramatic shifts in much shorter periods of time, regular monitoring and audits should be put in place to review and update the system. This may look like monitoring for performance instability, placing new safeguards, reviewing for potential new threats, or needs for regulations at a local or global scale.
With these regular audits will come a need for continual transformation. In cases where AI was deemed not appropriate before, organizations should check if these conditions still hold true.
Staying Prepared
As digital products and services are augmented with AI, complex challenges are introduced. Regardless of the industry, organizations will need to continually transform and evolve, in an agile and iterative fashion that demonstrates technology maturity. In this new wave of AI, transformational shifts are occurring in days and months, not years. While it is important to evaluate trade-offs in decision making, businesses shouldn’t overinvest on a particular dimension, that may easily be prone to change.
While “rogue AI” that becomes sentient and works against humans likely won’t happen in this lifetime, it is still important for the industry to adopt standards to protect the world from poorly designed AI systems. These standards can take the form of well published guidelines and frameworks from associations, best practices adopted by the industry, policies set forth via internal governance divisions, or internal steering committees to contextualize safety and malicious concerns for the business.
Organizations must have an incentive to install proper procedures to prepare for these undesirable behaviors, limit adoption of misuse, and limit the potential negative effects of autonomous AI systems.
MLOps, short for Machine Learning Operations, has emerged as a crucial discipline for organizations looking to effectively build, deploy, and manage machine learning models. By applying DevOps principles to machine learning workflows, MLOps aims to facilitate seamless collaboration between data scientists and engineers and optimize the end-to-end machine learning lifecycle.
MLOps applies principles and best practices from DevOps to the specific needs of data science and machine learning, facilitating seamless collaboration between data scientists, engineers, and operations teams.
This free ebook, Essential MLOps: What You Need to Know for Successful Implementation, from Data Science Horizons provides a comprehensive introduction to MLOps. You will learn the basics of helping organizations streamline the process of building, deploying, and managing machine learning models in production environments.
Essential MLOps covers the importance of the topic, its key components, essential MLOps skills, tools and technologies, and real-world case studies. It aims to provide readers with a solid understanding of MLOps concepts, techniques, and tools to implement MLOps in their organizations. As the ebook states:
By adopting MLOps practices and leveraging the right tools and technologies, organizations can streamline their machine learning workflows, optimize model performance, and drive meaningful results.
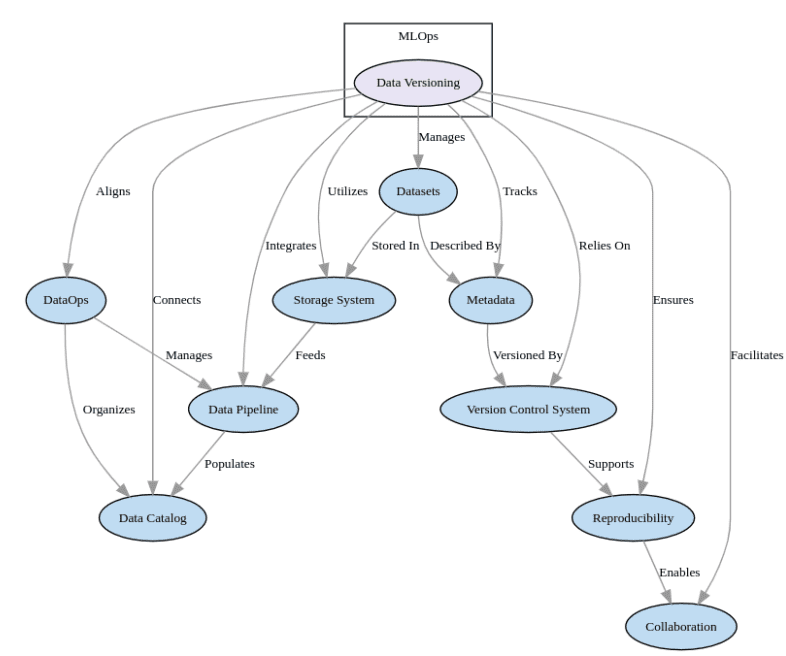
Key topics covered include data management and version control, model training and evaluation, continuous integration and continuous deployment (CI/CD), monitoring and performance management, and case studies from industries like ecommerce, finance, healthcare, and manufacturing. The ebook highlights the benefits of MLOps such as improved collaboration, faster deployment, better model performance, and increased scalability and maintainability of machine learning systems.
Image from Essential MLOps: What You Need to Know for Successful Implementation
Overall, Essential MLOps: What You Need to Know for Successful Implementation from Data Science Horizons provides valuable insights for anyone looking to successfully implement MLOps within their organization. The practical guidance makes it a useful resource for data scientists, engineers, team leads, and other professionals interested in streamlining machine learning workflows.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.
More On This Topic
Essential MLOps: A Free eBook
Learn MLOps with This Free Course
ebook: Learn Data Science with R — free download
Learn Data Cleaning and Preprocessing for Data Science with This Free eBook
Meta releases an AI model that can transcribe and translate close to 100 languages Kyle Wiggers 8 hours
In its quest to develop AI that can understand a range of different dialects, Meta has created an AI model, SeamlessM4T, that can translate and transcribe close to 100 languages across text and speech.
Available in open source along with SeamlessAlign, a new translation data set, Meta claims that SeamlessM4T represents a “significant breakthrough” in the field of AI-powered speech-to-speech and speech-to-text.
“Our single model provides on-demand translations that enable people who speak different languages to communicate more effectively,” Meta writes in a blog post shared with TechCrunch. “SeamlessM4T implicitly recognizes the source languages without the need for a separate language identification model.”
SeamlessM4T is something of a spiritual successor to Meta’s No Language Left Behind, a text-to-text machine translation model, and Universal Speech Translator, one of the few direct speech-to-speech translation systems to support the Hokkien language. And it builds on Massively Multilingual Speech, Meta’s framework that provides speech recognition, language identification and speech synthesis tech across more than 1,100 languages.
Meta isn’t the only one investing resources in developing sophisticated AI translation and transcription tools.
Beyond the wealth of commercial services and open source models already available from Amazon, Microsoft, OpenAI and a number of startups, Google is creating what it calls the Universal Speech Model, a part of the tech giant’s larger effort to build a model that can understand the world’s 1,000 most-spoken languages. Mozilla, meanwhile, spearheaded Common Voice, one of the largest multi-language collection of voices for training automatic speech recognition algorithms.
But SeamlessM4T is among the more ambitious efforts to date to combine translation and transcription capabilities into a single model.
In developing it, Meta says that it scraped publicly available text (in the order of “tens of billions” of sentences) and speech (4 million hours) from the web. In an interview with TechCrunch, Juan Pino, a research scientist at Meta’s AI research division and a contributor on the project, wouldn’t reveal the exact sources of the data, saying only that there was “a variety” of them.
Not every content creator agrees with the practice of leveraging public data to train models that could be used commercially. Some have filed lawsuits against companies building AI tools on top of publicly available data, arguing that the vendors should be compelled to provide credit if not compensation — and clear ways to opt out.
But Meta claims that the data it mined — which might contain personally identifiable information, the company admits — wasn’t copyrighted and came primarily from open source or licensed sources.
Whatever the case, Meta used the scraped text and speech to create the training data set for SeamlessM4T, called SeamlessAlign. Researchers aligned 443,000 hours of speech with texts and created 29,000 hours of “speech-to-speech” alignments, which “taught” SeamlessM4T how to transcribe speech to text, translate text, generate speech from text and even translate words spoken in one language into words in another language.
Meta claims that on an internal benchmark, SeamlessM4T performed better against background noises and “speaker variations” in speech-to-text tasks compared to the current state-of-the-art speech transcription model. It attributes this to the rich combination of speech and text data in the training data set, which Meta believes gives SeamlessM4T a leg up over speech-only and text-only models.
“With state-of-the-art results, we believe SeamlessM4T is an important breakthrough in the AI community’s quest toward creating universal multitask systems,” Meta wrote in the blog post.
But one wonders what biases the model might contain.
A recent piece in The Conversation points out the many flaws in AI-powered translation, including different forms of gender bias. For example, Google Translate once presupposed that doctors were male while nurses were female in certain languages, while Bing’s translator translated phrases like “the table is soft” as the feminine “die Tabelle” in German, which refers a table of figures.
Speech recognition algorithms, too, often contain biases. A study published in The Proceedings of the National Academy of Sciences showed that speech recognition systems from leading companies were twice as likely to incorrectly transcribe audio from Black speakers as opposed to white speakers.
Unsurprisingly, SeamlessM4T isn’t unique in this regard.
In a whitepaper published alongside the blog post, Meta reveals that the model “overgeneralizes to masculine forms when translating from neutral terms” and performs better when translating from the masculine reference (e.g., nouns like “he” in English) for most languages.
Moreover, in the absence of gender information, SeamlessM4T prefers translating the masculine form about 10% of the time — perhaps due to an “overrepresentation of masculine lexica” in the training data, Meta speculates.
Meta makes the case that SeamlessM4T doesn’t add an outsize amount of toxic text in its translations, a common problem with translation and generative AI text models at large. But it’s not perfect. In some languages, like Bengali and Kyrgyz, SeamlessM4T makes more toxic translations — that is to say, hateful or profane translations — about socioeconomic status and culture. And in general, SeamlessM4T is more toxic in translations dealing with sexual orientation and religion.
Meta notes that the public demo for SeamlessM4T contains a filter for toxicity in inputted speech as well as a filter for potentially toxic outputted speech. That filter’s not present by default in the open source release of the model, however.
The larger issue with AI translators not addressed in the whitepaper is the loss of lexical richness that can result from their overuse. Unlike AI, human interpreters make choices unique to them when translating one language into another. They might explicate, normalize, or condense and summarize, creating fingerprints known informally as “translationese.” AI systems might generate more “accurate” translations, but those translations could be coming at the expense of translation variety and diversity.
That’s probably why Meta advises against using SeamlessM4T for long-form translation and certified translations, like those recognized by government agencies and translation authorities. Meta also discourages deploying SeamlessM4T for medical or legal purposes — presumably an attempt to cover its bases in the event of a mistranslation.
That’s wise; there’s been at least a few of instances where AI mistranslations have resulted in law enforcement mistakes. In September 2012, police erroneously confronted a Kurdish man for financing terrorism because of a mistranslated text message. And in 2017, a cop in Kansas used Google Translate to ask a Spanish-speaker if they could search their car for drugs, but because the translation was inaccurate, the driver didn’t fully understand what he’d agreed to and the case was eventually thrown out.
“This single system approach reduces errors and delays, increasing the efficiency and quality of the translation process, bringing us closer to making seamless translation possible,” Pino said. “In the future, we want to explore how this foundational model can enable new communication capabilities — ultimately bringing us closer to a world where everyone can be understood.”
Let’s hope humans aren’t left completely out of the loop in that future.
While opting for data architecture solutions, companies frequently fall into the trap of paying exorbitant prices for services they don’t need. A recent blog by Kieran Healey points out that companies like Databricks or Snowflakes are offering Ferraris when many companies could do their work with Toyota.
Databricks and Snowflake are undoubtedly robust platforms that offer impressive capabilities. Snowflake’s partnership with NVIDIA and Databricks’ integration with the Spark Human API showcased their technical prowess and made it even bigger. Yet, such features often serve as marketing tactics rather than essential solutions, which companies end up paying instead of open source solutions.
For example, instead of opting to pay the price of an LLM-based chatbot, most companies could effectively address their data challenges with simpler, more cost-efficient solutions such as a simple “press 1 to choose this option”. But when it comes to addressing data-related challenges without overspending, companies should adopt an anti-hype mindset.
A person from Databricks suggested on HackerNews that though companies might be able to create their own Spark deployment, it will run much slower than how it runs on Databricks or its proprietary runtime. He further adds that a lot of businesses have other problems to solve and focusing on building DIY platforms is a horrible approach.
Interestingly, none of this matters if you only have gigabytes of data as the company can use pretty much anything very cheaply and easily. It is just about companies that have terabytes or hundreds of terabytes of data.
Open source vs commercial solutions
On the other end, it seems easy to hop onto the open source solutions as well, given the cost-effective value that they are presented as. One side of the debate emphasises the financial advantage of open source solutions. Supporters highlight the fact that open source software is often free to use, suggesting that the cost savings alone make it a compelling choice.
However, it is essential to be pointed out that while the software itself may be free, deploying, maintaining, and expertly managing open source solutions can incur significant costs. Paying skilled professionals to ensure proper deployment and upkeep can strain both time and resources.
“Open source it may be. Free it is not. Paying an expert to correctly deploy an open source solution takes time and money,” said another user. This argument underscores the idea that simply adopting open source software isn’t a guaranteed money-saving solution without proper expertise and management.
On the opposite side, commercial solutions such as Databricks and Snowflake might come with upfront costs, but offer comprehensive support, integration, and scalability that can be invaluable. These solutions often package features, support, and maintenance into a single offering, reducing the need for extensive in-house expertise. Furthermore, commercial solutions can provide a level of assurance and accountability that can be lacking in open source alternatives.
Though you pay to change the parameters of the problem. This is a fundamental misunderstanding of how to get things done in a constrained environment. This viewpoint highlights the notion that the trade-off between open source and commercial solutions is about more than just cost—it’s about shifting the focus from technical challenges to non-technical ones.
Funnily, it’s like saying no company needs a cloud provider but it definitely helps them focus on better things instead of building a data centre themselves.
The Anti-Hype Approach
In the debate over data platform choices, context and expertise play pivotal roles. While open source solutions can be powerful tools when implemented correctly, they require a skilled team to navigate potential challenges. Conversely, commercial solutions can mitigate many technical complexities, enabling organisations to concentrate on their core business goals. However, this often involves a trade-off between flexibility and vendor lock-in.
Ultimately, there is no one-size-fits-all answer to the open source vs commercial debate in the context of data platforms. The decision depends on the unique circumstances of each organisation—its budget, existing expertise, scalability requirements, and risk tolerance.
In the current age, when CEOs are being pushed to say generative AI by everyone, it might be easy to fall into the trap and overspend on over engineered solutions. It’s essential to scrutinise its applicability. Instead of focusing on novel technologies, companies should adhere to the age-old principle of delivering tangible returns on investments and CEOs are always looking for solutions that not only enhance but also generate profits.
The post Are Databricks and Snowflake Ferraris in a Toyota World? appeared first on Analytics India Magazine.
Arthur Clarke famously quipped that any sufficiently advanced technology is indistinguishable from magic. AI has crossed that line with the introduction of Vision and Language (V&L) models and Language Learning Models (LLMs). Projects like Promptbase essentially weave the right words in the correct sequence to conjure seemingly spontaneous outcomes. If “prompt engineering” doesn't meet the criteria of spell-casting, it's hard to say what does. Moreover, the quality of prompts matter. Better "spells" lead to better results!
Nearly every company is keen on harnessing a share of this LLM magic. But it’s only magic if you can align the LLM to specific business needs, like summarizing information from your knowledge base.
Let's embark on an adventure, revealing the recipe for creating a potent potion—an LLM with domain-specific expertise. As a fun example, we'll develop an LLM proficient in Civilization 6, a concept that’s geeky enough to intrigue us, boasts a fantastic WikiFandom under a CC-BY-SA license, and isn't too complex so that even non-fans can follow our examples.
Step 1: Decipher the Documentation
The LLM may already possess some domain-specific knowledge, accessible with the right prompt. However, you probably have existing documents that store knowledge you want to utilize. Locate those documents and proceed to the next step.
Step 2: Segment Your Spells
To make your domain-specific knowledge accessible to the LLM, segment your documentation into smaller, digestible pieces. This segmentation improves comprehension and facilitates easier retrieval of relevant information. For us, this involves splitting the Fandom Wiki markdown files into sections. Different LLMs can process prompts of different length. It makes sense to split your documents into pieces that would be significantly shorter (say, 10% or less) then the maximum LLM input length.
Step 3: Create Knowledge Elixirs and Brew Your Vector Database
Encode each segmented text piece with the corresponding embedding, using, for instance, Sentence Transformers.
Store the resulting embeddings and corresponding texts in a vector database. You could do it DIY-style using Numpy and SKlearn's KNN, but seasoned practitioners often recommend vector databases.
Step 4: Craft Spellbinding Prompts
When a user asks the LLM something about Civilization 6, you can search the vector database for elements whose embedding closely matches the question embedding. You can use these texts in the prompt you craft.
Step 5: Manage the Cauldron of Context
Let's get serious about spellbinding! You can add database elements to the prompt until you reach the maximum context length set for the prompt. Pay close attention to the size of your text sections from Step 2. There are usually significant trade-offs between the size of the embedded documents and how many you include in the prompt.
Step 6: Choose Your Magic Ingredient
Regardless of the LLM chosen for your final solution, these steps apply. The LLM landscape is changing rapidly, so once your pipeline is ready, choose your success metric and run side-by-side comparisons of different models. For instance, we can compare Vicuna-13b and GPT-3.5-turbo.
Step 7: Test Your Potion
Testing if our "potion" works is the next step. Easier said than done, as there's no scientific consensus on evaluating LLMs. Some researchers develop new benchmarks like HELM or BIG-bench, while others advocate for human-in-the-loop assessments or assessing the output of domain-specific LLMs with a superior model. Each approach has pros and cons. For a problem involving domain-specific knowledge, you need to build an evaluation pipeline relevant to your business needs. Unfortunately, this usually involves starting from scratch.
Step 8: Unveil the Oracle and Conjure Answers and Evaluation
First, collect a set of questions to assess the domain-specific LLM's performance. This may be a tedious task, but in our Civilization example, we leveraged Google Suggest. We used search queries like “Civilization 6 how to …” and applied Google's suggestions as the questions to evaluate our solution. Then with a set of domain-related questions, run your QnA pipeline. Form a prompt and generate an answer for each question.
Step 9: Assess Quality Through the Seer's Lens
Once you have the answers and original queries, you must assess their alignment. Depending on your desired precision, you can compare your LLM's answers with a superior model or use a side-by-side comparison on Toloka. The second option has the advantage of direct human assessment, which, if done correctly, safeguards against implicit bias that a superior LLM might have (GPT-4, for example, tends to rate its responses higher than humans). This could be crucial for actual business implementation where such implicit bias could negatively impact your product. Since we're dealing with a toy example, we can follow the first path: comparing Vicuna-13b and GPT-3.5-turbo's answers with those of GPT-4.
Step 10: Distill Quality Assessment
LLMs are often used in open setups, so ideally, you want an LLM that can distinguish questions with answers in your vector database from those without. Here is a side-by-side comparison of Vicuna-13b and GPT-3.5, as assessed by humans on Toloka (aka Tolokers) and GPT.
Method
Tolokers
GPT-4
Model
vicuna-13b
GPT-3.5
Answerable, correct answer
46.3%
60.3%
80.9%
Unanswerable, AI gave no answer
20.9%
11.8%
17.7%
Answerable, wrong answer
20.9%
20.6%
1.4%
Unanswerable, AI gave some answer
11.9%
7.3%
0
We can see the differences between evaluations conducted by superior models versus human assessment if we examine the evaluation of Vicuna-13b by Tolokers, as illustrated in the first column. Several key takeaways emerge from this comparison. Firstly, discrepancies between GPT-4 and the Tolokers are noteworthy. These inconsistencies primarily occur when the domain-specific LLM appropriately refrains from responding, yet GPT-4 grades such non-responses as correct answers to answerable questions. This highlights a potential evaluation bias that can emerge when an LLM's evaluation is not juxtaposed with human assessment.
Secondly, both GPT-4 and human assessors demonstrate a consensus when evaluating overall performance. This is calculated as the sum of the numbers in the first two rows compared to the sum in the second two rows. Therefore, comparing two domain-specific LLMs with a superior model can be an effective DIY approach to preliminary model assessment.
And there you have it! You have mastered spellbinding, and your domain-specific LLM pipeline is fully operational. Ivan Yamshchikov is a professor of Semantic Data Processing and Cognitive Computing at the Center for AI and Robotics, Technical University of Applied Sciences Würzburg-Schweinfurt. He also leads the Data Advocates team at Toloka AI. His research interests include computational creativity, semantic data processing and generative models.
More On This Topic
Best Practices for Creating Domain-Specific AI Models
Programming Languages for Specific Data Roles
Is Domain Knowledge Important for Machine Learning?
Introducing Healthcare-Specific Large Language Models from John Snow Labs
KDnuggets News, August 3: 10 Most Used Tableau Functions • Is Domain…
ElevenLabs is a startup that has made headlines for its AI-powered voice-generating platform, which has been used for narrating audiobooks and increasing content accessibility, but also misused to make it seem like public figures are saying terrible things. The platform is now leaving beta and expanding significantly into more languages.
On Monday, ElevenLabs announced that the platform is coming out of a beta stage that began in January and the startup also revealed a new foundational multilingual deep-learning model, Eleven Multilingual v2.
Also: 4 things Claude AI can do that ChatGPT can't
Eleven Multilingual v2 supports 30 languages and allows people around the world to use ElevenLabs' text-to-speech and voice-cloning capabilities.
When users input text, the model automatically identifies the written language and generates speech with "an unprecedented level of authenticity", according to the release.
The speaker's unique voice characteristics — regardless of whether it's a synthetic or cloned voice — remain the same across all 30 languages, which ensures the same style of speech is used, including accent.
"ElevenLabs was started with the dream of making all content universally accessible in any language and in any voice," said Mati Staniszewski, CEO and co-founder of ElevenLabs.
"With the release of Eleven Multilingual v2, we are one step closer to making this dream a reality and making human-quality AI voices available in every dialect."
Also: 40% of workers will have to reskill in the next three years due to AI, says IBM study
ElevenLabs identified some potential use cases for this application, such as allowing indie authors to make audiobooks, translating video game experiences and audio content for international audiences, and increasing content accessibility for people with visual impairments and additional learning needs.
As listed in the release, the supported languages include Korean, Dutch, Turkish, Swedish, Indonesian, Vietnamese, Filipino, Ukrainian, Greek, Czech, Finnish, Romanian, Danish, Bulgarian, Malay, Hungarian, Norwegian, Slovak, Croatian, Classic Arabic, Tamil, English, Polish, German, Spanish, French, Italian, Hindi, and Portuguese.
As we progress through 2023, the trend of job loss has shown signs of easing. While generative AI possesses the potential to replace jobs, it has simultaneously ushered in a new realm of opportunities. The growth of generative AI employment from January to June has been consistent with the US alone boasting over 4200 generative AI-related job openings, marking a 20% surge in May.
Job descriptions have adapted to this trend, exemplified by the emergence of the generative AI engineer role. With companies offering notably high salaries for AI positions, this sector presents unparalleled opportunities. Recently, Netflix gained attention by proposing a salary of up to $900,000 for a product manager on their machine learning platform team. Now let’s take a look at some of the highest-paying generative AI jobs.
Read more: $1M Salary Package: AI Companies Pour Money for GenAI Roles
HubSpot
Software marketing giant HubSpot is in search of an experienced Principal Engineer for their AI Group. In this remote USA role, the selected candidate will shape and execute the AI strategy by crafting and implementing advanced algorithms, enriching HubSpot’s offerings. The role demands profound AI knowledge, technical leadership, and teamwork. Key duties include designing and deploying AI models to enhance user experiences and foster business expansion.
Collaborating with cross-functional peers, the Principal Engineer will spot AI prospects, conduct research, and construct scalable AI solutions. Nurturing junior engineers, staying updated with AI trends, and effective communication form vital parts of the role. Qualifications include a bachelor’s or a master’s degree in computer science or engineering, a decade of AI-focused software engineering, deep AI understanding, and proficiency in languages like Python or Java. The salary for this role can go upto as high as $427,000.
To find out more about the responsibilities and requirements of the position, visit this page.
Scale AI
San Francisco startup Scale AI that surged in the AI boom, achieving a $7 billion valuation post raising about $325 million in April 2021 for its Series E funding, is looking to hire a software engineer (generative AI) for a full time position with a base salary range of $153,000 – $215,000. The perfect candidate should have a strong sense of responsibility for new product areas. They need to be skilled in both backend and frontend development, and they should be comfortable working with language models and other machine learning tools. They will contribute to the entire product development process, from planning to launch.
The ideal candidate would have more than five years of engineering experience after graduating, be proficient in programming languages like Python, Node, React, Next.js, and MongoDB, have a strong foundation in algorithms, data structures, and object-oriented programming, and have experience working on projects that have grown rapidly in startup environments.
Check out more about the job here.
NVIDIA
NVIDIA, which recently made a suite of interesting announcements on generative AI at SIGGRAPH 2023, is looking for an experienced senior research scientist with expertise in generative AI to join their research team. This role involves leading research in various applications of generative AI, including generating images, videos, 3D models, and audio. Responsibilities include conducting original research, creating large-scale generative models, and working closely with both internal and external partners.
The ideal candidate should have a Ph.D. in computer science, electrical engineering, or related fields, or equivalent practical experience. They should also have over five years of relevant research involvement. Proficiency in programming languages like Python and C++, as well as deep learning frameworks, dataset processing, and a solid understanding of deep learning theory in areas like computer vision, natural language processing, and computer graphics are essential skills. NVIDIA offers a competitive base salary ranging from $180,000 to $414,000. This position is located in Santa Clara.
If you’re looking for further information regarding the role, click here.
Microsoft
The Microsoft CTO Office, part of the technology and research group, is looking for a skilled principal software engineer. This person will lead the team in creating cutting-edge solutions and taking charge of complex business challenges. The main focus of the role is to improve Microsoft’s AI software infrastructure across products like O365, M365, Azure, LinkedIn, and Bing. This involves planning, executing, and prototyping systems. Responsibilities include creating high-quality components for seamless experiences across different products, developing open-source libraries and apps, working with product and research teams, and maintaining excellent service quality.
Keeping up with AI trends is important, and creative insights contribute to the scalability, reliability, and security of services. The role offers a salary between $158,500 and $276,600 per year. It requires more than eight years of coding experience in languages such as C++, Java, and Python, along with at least five years of distributed system design expertise. Familiarity with generative AI and LLMs is also needed.
Check here for more information about the role.
Meta
Threads creator Meta is looking to grow their ML and gen AI team by hiring a software engineer. The engineer will provide guidance to teams, helping them define project goals and design ML systems. They will adapt traditional machine learning methods for modern parallel environments, including distributed clusters, multicore SMP, and GPUs. The candidate will also create scalable classifiers and tools using machine learning, data regression, and rule-based models. Their role involves suggesting, gathering, and combining requirements to create a strong feature roadmap.
For qualifications, the ideal candidate should have at least six years of experience in software engineering or a related field. Alternatively, a PhD with over four years of experience is also suitable. Experience of over two years in areas like machine learning, recommendation systems, pattern recognition, and data mining is a plus. Proficiency in C/C++ and Java development is necessary, and familiarity with scripting languages like Python, Perl, PHP, and shell scripts is beneficial. The position is located in Menlo Park, CA, with a salary ranging from $172,994 to $241,000 per year.
Detailed information about the role can be found by clicking here.
Adobe
Adobe is hiring a principal AI strategist to conducts in-depth research on emerging generative AI trends and create impactful presentations and whitepapers tailored for senior executives in an San Jose, California. Collaborating with various teams, including marketing, product, sales, and legal, the strategist refines Adobe’s AI messaging and nurtures customer relationships.
The successful candidate should have a strong intellectual curiosity for AI, the capacity to swiftly grasp diverse AI aspects including technology, economics, ethics, and law, coupled with over a decade of AI-related experience from various fields. Exceptional written communication skills for thought-provoking content, impressive executive presence, and presentation abilities to engage senior executives are essential. Moreover, good problem-solving, analytical, and research skills, including experience in academic or market research and survey design, are highly valued. The pay range for this position is $137,300 — $247,200 annually.
Check out their careers page here.
Databricks
Databricks, the unsung hero of AI, is looking for an engineering manager (AI compute platform) who will lead the engineering cohort in creating AI workload-scaling services and runtime solutions for clients. The role involves leading the team’s plans and product direction, making the process of creating AI models and workflows smoother, and encouraging important machine learning abilities. Also, the position includes helping engineering leaders grow, supporting engineers in their careers, and expanding the team by hiring skilled engineers.
The person in this role will create strong processes to effectively make the product vision real and match the goals of the organisation. The best candidate should have over 5 years of experience with cloud technology, be good at leading teams, work well with different parts of the company like product management and customers, and be skilled in making sure computer systems work well. Having a degree in computer science or similar is the minimum, and higher degrees are preferred. Based in Mountain View, California, the pay range is between $192,000 – $260,000 a year.
For a comprehensive overview of the role, follow this link.
The post Top 7 High-Paying Generative AI Jobs appeared first on Analytics India Magazine.