When the world celebrated Chandrayaan’s successful soft landing on the moon, International Prize in Statistics recipient C Radhakrishna Rao left for a heavenly abode at the age of 102 in the US.
Born on September 10, 1920, in Hadagali, Bellary district, C.R. Rao came from a Telugu family. The former director of ISI started his educational journey at the same institution, established by Dr. P.C. Mahalanobis. With guidance from Mahalanobis, Rao was selected to go to Cambridge University for applying statistical techniques to anthropological analysis. Influenced by his parents, he excelled academically. His father recognised his mathematical aptitude, prompting him to pursue the subject. Rao’s academic journey included an MA in Mathematics from Andhra University. His academic pursuits continued with a PhD and DSc from Cambridge University. Rao directed research at the Indian Statistical Institute before moving to the University of Pittsburgh. Even after retiring at 81, he remained active, continuing research and directing the Center for Multivariate Analysis at Pennsylvania State University.
The statistics genius’ remarkable life journey includes receiving an award for his influential 1945 paper ‘Information and Accuracy Attainable in the Estimation of Statistical Parameters’. This paper introduced key concepts like the Cramér-Rao inequality and Rao-Blackwellisation, shaping modern statistics. The paper was initially published in the ‘Bulletin of the Calcutta Mathematical Society’ and later included in ‘Breakthroughs in Statistics Vol.1, 1890 – 1990’. Its impact spans fields from quantum physics to biostatistics.
Rao’s accomplishments have been extensively recognised, earning him over 45 awards and honours, including the Padma Bhushan, Padma Vibhushan, and the National Medal of Science from the US President. His groundbreaking work influenced diverse fields and underlies statistical and machine learning methods used in AI.
CR Rao’s contributions and legacy will forever remain an inspiration to us all.
Read more: Delayed, But Not Forgotten!
The post Statistical Pioneer CR Rao Passes Away at 102 appeared first on Analytics India Magazine.
NVIDIA on Wednesday reported financial results for the second quarter ending on July 30 2023. The company’s revenue for this quarter soared to $13.51 billion, marking a phenomenal 101% increase compared to the same period last year and an impressive 88% rise from the previous quarter.
The Data Center segment stood out as a driving force, contributing a staggering $10.32 billion in revenue for this quarter reflecting a remarkable 171% growth from the same period last year and an astounding 141% surge from the previous quarter.
The company, who is the main supplier of A100 and H100 AI chips used to build and run AI applications, raked in $ 6.19 billion in profit in Q2 as compared to $ 656 million last year in corresponding quarter, up 843%.
“A new computing era has begun. Companies worldwide are transitioning from general-purpose to accelerated computing and generative AI,” said Jensen Huang, founder and CEO of NVIDIA.
Huang also highlighted noteworthy industry developments during this quarter. Major cloud service providers unveiled significant NVIDIA H100 AI infrastructures, and key enterprise IT system and software providers forged partnerships to bring NVIDIA AI capabilities to various industries.
NVIDIA predicts that its revenue for the third quarter of the fiscal year will be around $16 billion, surpassing the estimated $12.61 billion by Refinitiv. NVIDIA’s projection indicates a remarkable 170% increase in sales for this quarter compared to the same period last year.
“We expect sequential growth to be driven largely by data center,” says NVIDIA CFO Colette Kress on the earnings call. Following this announcement, the company’s stock price surged by 8.5 percent in after-hours trading.
NVIDIA’s gaming division, once the company’s core focus, witnessed a notable 22% surge in revenue compared to the previous year, reaching an impressive $2.49 billion. This growth outperformed expectations, surpassing the average estimate of $2.38 billion.
NVIDIA recently announced its latest innovation, the next-generation NVIDIA GH200 Grace Hopper platform. This platform centers around an innovative Grace Hopper Superchip, featuring the world’s pioneering HBM3e processor.
The new setup is a game-changer, offering 3.5 times more memory capacity and 3 times more bandwidth than the current version. This setup includes a single server with 144 Arm Neoverse cores, delivering eight petaflops of AI performance and featuring 282GB of the latest HBM3e memory technology.
The post NVIDIA Soars on Generative AI, Reports $6 Billion Profit appeared first on Analytics India Magazine.
The AI-as-a-copilot company Microsoft is moving beyond merely integrating generative AI on Azure and is planning to deploy it in Windows applications. This time, it is not just adding ChatGPT to everything, but much more.
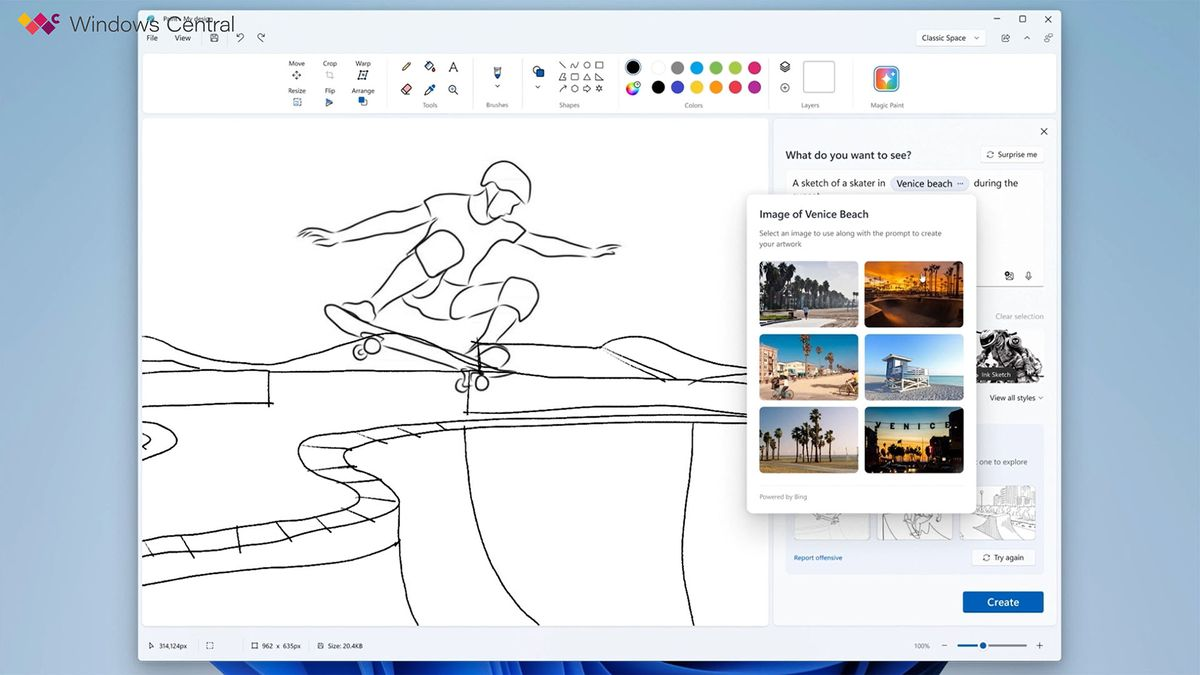
According to a recent report by Windows Central, the company is striving to integrate Windows 11 applications, including Photos, Snipping Tool, and Paint with generative AI capabilities. Undoubtedly, the image generation capabilities would be powered by OpenAI’s DALL-E, the same technology that company employs for Bing Image Generator.
Regarding the upgrade to the Camera and Photos app, there’s a possibility that Microsoft will incorporate optical character recognition (OCR) technology into both applications. This advancement has the potential to empower each app to recognise text, individuals, and objects within photos or screenshots, thereby significantly simplifying the process of copying and pasting information from these sources.
Snipping Tool is also expected to get an OCR technology update. This strategic enhancement would enable Windows 11 to promptly recognise and replicate text from screenshots onto the clipboard, streamlining information utilisation. Sounds interesting, but all of this comes with a mild hit of security issues.
All the way to the cloud
Another recent development by Microsoft, when it announced the integration of Python into Excel, has been met with some questions due to issues related to privacy and security. Developers have raised concerns as the program can not run locally but only on Azure Cloud. And the community is clearly not completely on board with this decision.
Same can be expected from the Paint application. Running text-to-image models locally is a herculean task and requires a lot of computation within a single device. On the other hand, Paint has always been a locally running software with minimal computation requirements. The ideal way to keep the load less on the device, Microsoft will have to link it to the cloud as well.
Coupling this with OCR on Snipping Tool, Photos, and Camera, people are concerned about sharing all of this information with Microsoft through the cloud connection. Ideally, it would make sense for Microsoft to run towards building edge capable products before deploying these on the Windows ecosystem.
The timeline for the rollout of these AI integrations remains ambiguous as Microsoft is meticulously fine-tuning these concepts. An imminent ‘special event’ scheduled for September 21, is anticipated to unveil new Surface hardware while shedding further light on Microsoft’s AI roadmap for Windows.
Microsoft is not that bad
On Microsoft’s credit, the company has been in talks with Intel, Qualcomm, AMD, and NVIDIA for developing support for AI on the silicon level, allowing edge computing on Windows devices. When it comes to current LLMs, such as Llama 2, the computation requirements have gone down significantly, but not enough to make it available for everyone on their devices locally without occupying massive amounts of storage and RAM usage. Releasing Llama 2 with Meta on Microsoft cloud was possibly a hint towards optimising it in the future as well.
Over the past year, the tech giant has consistently spotlighted AI functionalities across its product portfolio. Notably, the trend has transcended to its flagship operating system, Windows 11. Two prominent AI-driven features were announced at Microsoft Build 2023, Windows Studio Effects and the eagerly anticipated Windows Copilot, have already been announced, with the latter set to debut this fall.
Arguably, the hype around products like ChatGPT has been on the decline. It might be only a handful of people who would be eagerly waiting for their Windows 11 computer to be able to generate ChatGPT like text locally, though it would definitely prove to be very useful.
Even if Microsoft ends up integrating all of these products on Windows 11 locally, the only question that remains is – whether MineSweeper or Notepad get an AI upgrade as well?
Funnily enough, this move might even mark the revival of the loved and hated Clippy assistant on Office products. This time, with the integration of generative AI, it might be even more helpful, or even more annoying. Well, the company has already announced plans to invest in it, so who knows?
The post Microsoft is Hell Bent on Bringing AI to Windows appeared first on Analytics India Magazine.
Indian IT giant HCLTech has announced a collaboration with Amazon Web Services (AWS) to accelerate the adoption of generative AI at the company and by enterprises globally.
The collaboration aims to empower enterprises to harness the power of AWS’s advanced GenAI portfolio which includes Amazon CodeWhisperer, Amazon Bedrock, Amazon Titan, AWS Trainium and AWS Inferentia.
As part of the collaboration, HCLTech intends to use Amazon CodeWhisperer with over 50,000 HCLTech engineers, cloud practitioners and developers to build secure applications and leverage AI responsibly, internally and for clients.
HCLTech will also integrate its Advantage Cloud platform for automated mass application migration to cloud with Amazon CodeWhisperer, enabling automated rehosting, refactoring and re-platforming treatments with a centralized dashboard to monitor and plan migrations.
The AWS-HCLTech collaboration demonstrates a shared commitment to exploring industry solutions leveraging AI advancements. For instance, HCLTech developed Ziva on AWS, an AI bot for the financial services industry. HCLTech has also been recognized as an ML-powered Amazon Connect launch partner, further underscoring the strength of this strategic partnership.
“GenAI is a powerful technology that has the potential to revolutionize industries. By collaborating with AWS, we bring to our clients the latest GenAI capabilities to accelerate innovation and establish a robust global AI economy,” Prabhakar Appana, Senior Vice President and Head of AWS Ecosystem Business Unit, HCLTech, said.
The post HCL Partners With AWS To Accelerate GenAI Adoption appeared first on Analytics India Magazine.
Whether it’s the infamous Siddhu Moosewala case, Umesh Pal murder case in Prayagraj, or the controversial Vikas Dubey case, one company is at the center of all these cases—-Staqu Technologies and its AI-powered video analytics model Jarvis.
“We have identified more than 30,000 criminals in the country, we help identify around 100 criminals on a daily basis, “ said Atul Rai, CEO and co-founder, Staqu, in an exclusive interview with AIM.
Jarvis, developed by Staqu, finds application in law enforcement across various states. It is referred to as PAIS in Punjab, Trinetra in UP, Chakra in Bihar, and Eagle in Haryana. Staqu collaborates with a total of eight states, encompassing Rajasthan, Uttarakhand, and Telangana.
Beyond this, Staqu’s Jarvis incorporates a “Video Wall” technology and aggregates CCTV footage from 70 prisons and handles 700 cameras, aiding law enforcement with tasks like access monitoring, violence detection, and intrusion alerts in prisons across UP. This marked the first use of such AI-driven analytics in Indian prison departments.
Historically, criminals and illicit networks have operated from within prisons, accessing contraband items like mobile phones and weapons. With its solid support, JARVIS significantly empowers police forces in their efforts to combat crime.
Additionally, it is also efficient in tasks like frisking, access monitoring, crowd analysis, violence detection, facial recognition, camera status, and intrusion alerts. Beyond these applications, Staqu is actively developing JARVIS for diverse security scenarios as well.
The company’s image-based search and analytics platform serves businesses and security needs. It uses deep learning and machine learning technologies to offer video analytics, big data tools, and auditing solutions for security and data analytics domains. In the realm of big data analytics, Staqu provides tools such as a data aggregating tool and a data analysis tool.
There is More to that Meets the Eye
This is just one side of Staqu, it operates majorly in the B2B and SaaS sectors, specifically targeting the high tech and fintech market segments.
Founded in 2015 by Atul Rai, Anurag Saini. Co-Founder & CTO and Pankaj Kumar Sharma. The company works across several sectors, from retail, manufacturing, infrastructure, hospitality to public sector and has conglomerates as clients such as IBM, GMR group and Adani Power. In the retail front it caters to Starbucks coffee, Piramal Glass, Marico, Tata Consumer Products Ltd, Cafe Coffee Day, Chaayos, Crocs, Khadims, GMR, Croma, Metro.
Its business models are centered around offering a loss prevention module and a revenue enhancement module. Rai emphasised, “If you want to secure it, you will go for a loss prevention module. If you want to monetise it, you will go for the revenue enhancement module.”
The revenue enhancement module primarily targets the retail and real estate sectors. It aims to bridge the data gap in the retail industry, offering insights similar to e-commerce data. Leveraging existing camera infrastructure, JARVIS provides valuable insights to retailers. It tracks footfall, customer journey, gender demographics, product engagement, and queue analysis. By utilising a unique tracking algorithm, JARVIS accurately measures footfall excluding employees. This technology addresses the lack of critical data in the retail sector, offering valuable metrics for business optimisation. Now, it also finds its use case in catching criminals.
The working mechanism involves connecting observers from cameras to JARVIS through the internet, eliminating the need for extra hardware and associated costs. Data analysis occurs in the cloud via custom JARVIS, ensuring end-to-end encryption. This approach ensures data ownership and GDPR compliance. The camera’s features provide insights which, when combined with sales data, generate analyses like customer qualification percentages. The outcomes are tailored for clients like retail stores, enabling informed decision-making based on comprehensive insights.
Video management ensures centralised control for businesses with multiple locations. JARVIS, facilitates plug-and-play insights from various stores, covering occupancy analysis and beyond. Additionally, it offers security features like intrusion detection and identifying blacklisted individuals. JARVIS operates as a unified solution, eliminating the need for additional hardware—just an internet connection is required for implementation.
Questions about enterprise adoption and the possibility of integrating additional features were addressed by Rai by explaining the approach taken, he stated, “Imagine an enterprise adopting our system and wanting to expand its capabilities. We’ve structured it as a platform rather than a prescriptive solution, akin to Google’s modular approach with services like Gmail.”
“In our industry, lacking AI expertise is common, even when APIs are available. Major companies like Google and Microsoft provide APIs, but accessing them requires technical proficiency. By producing our platform, we provide solutions to real business challenges faced by industry giants like Starbucks, Raymond, and CCD. Our aim is to bridge the gap between AI potential and practical implementation.”
Funding-wise, Staqu has secured $2.11 million in total funding through four seed rounds and achieved a valuation of $8.57 million as of April 27, 2022. In the latest undisclosed seed round on May 25, 2022, Security and Intelligence Services led the investment. Staqu has 64 investors, including 5 institutional investors like Security and Intelligence Services and 59 Angel investors, including Bikky Khosla. Previous Seed rounds saw participation from Mount Judi Ventures, Ayushman Khanna, Ajay Gupta, and Neeraj Kumar Singal.
Innovations Powering Staqu
Staqu’s proprietary technology consists of two main components: the streamer algorithm and an IP portfolio with 25 research papers and four patents. The streamer algorithm handles diverse camera sources by unifying recommendations and analyses, compatible with existing systems like DVR NVR setups.
The IP portfolio focuses on advanced identification tech and big data search methods. It precisely pinpoints individuals and handles large-scale processing, aided by a specialised search patent using a pyramidal algorithmic approach, alongside leveraging machine learning techniques, including transformers, CNNs, and LSTMs. The foundational model, Vision Transformer (VIT), is optimised for real-time learning and adapted to handle a large number of diverse camera streams.
The technology excels in bimodal data analysis, combining text and visual info for comprehensive understanding. It supports audio-visual integration for enhanced insights and interactions.
“When you talk about the textual model forensic analysis then, of course, you are training on bimodal data so you are training with the text and images. For instance, if I’m searching for a green shirt and white t-shirt that means that need to be trained with the textual data and the image as well.”
In essence, the proprietary technology incorporates a sophisticated streamer algorithm and IP portfolio backed by advanced models. Customising the vision transformer ensures accurate, diverse, and real-time data processing, enabling efficient camera data management and actionable insights for better decision-making.
The post There’s No Escape for Criminals in India appeared first on Analytics India Magazine.
Generative AI, one of the hottest growing technologies, is used by OpenAI's ChatGPT and Google Bard for chat and by image generation systems such as Stable Diffusion and DALL-E. Still, it has certain limitations because these tools require the use of cloud-based data centers with hundreds of GPUs to perform the computing processes needed for every query.
But one day you could run generative AI tasks directly on your mobile device. Or your connected car. Or in your living room, bedroom, and kitchen on smart speakers like Amazon Echo, Google Home, or Apple HomePod.
Also: Your next phone will be able to run generative AI tools (even in Airplane Mode)
MediaTek believes this future is closer than we realize. Today, the Taiwan-based semiconductor company announced that it is working with Meta to port the social giant's Lllama 2 LLM — in combination with the company's latest-generation APUs and NeuroPilot software development platform — to run generative AI tasks on devices without relying on external processing.
Of course, there's a catch: This won't eliminate the data center entirely. Due to the size of LLM datasets (the number of parameters they contain) and the storage system's required performance, you still need a data center, albeit a much smaller one.
For example, Llama 2's "small" dataset is 7 billion parameters, or about 13GB, which is suitable for some rudimentary generative AI functions. However, a much larger version of 72 billion parameters requires a lot more storage proportionally, even using advanced data compression, which is outside the practical capabilities of today's smartphones. Over the next several years, LLMs in development will easily be 10 to 100 times the size of Llama 2 or GPT-4, with storage requirements in the hundreds of gigabytes and higher.
That's hard for a smartphone to store and have enough IOPS for database performance, but certainly not for specially designed cache appliances with fast flash storage and terabytes of RAM. So, for Llama 2, it is possible today to host a device optimized for serving mobile devices in a single rack unit without all the heavy compute. It's not a phone, but it's pretty impressive anyway!
Also: The best AI chatbots of 2023: ChatGPT and alternatives
MediaTek expects Llama 2-based AI applications to become available for smartphones powered by their next-generation flagship SoC, scheduled to hit the market by the end of the year.
For on-device generative AI to access these datasets, mobile carriers would have to rely on low-latency edge networks — small data centers/equipment closets with fast connections to the 5G towers. These data centers would reside directly on the carrier's network, so LLMs running on smartphones would not need to go through many network "hops" before accessing the parameter data.
In addition to running AI workloads on device using specialized processors such as MediaTek's, domain-specific LLMs can be moved closer to the application workload by running in a hybrid fashion with these caching appliances within the miniature datacenter — in a "constrained device edge" scenario.
Also: These are my 5 favorite AI tools for work
So, what are the benefits of using on-device generative AI?
Reduced latency: Because the data is being processed on the device itself, the response time is reduced significantly, especially if localized cache methodologies are used by frequently accessed parts of the parameter dataset.
Improved data privacy: By keeping the data on the device, that data (such as a chat conversation or training submitted by the user) isn't transmitted through the data center; only the model data is.
Improved bandwidth efficiency: Today, generative AI tasks require all data from the user conversation to go back and forth to the data center. With localized processing, a large amount of this occurs on the device.
Increased operational resiliency: With on-device generation, the system can continue functioning even if the network is disrupted, particularly if the device has a large enough parameter cache.
Energy efficiency: It doesn't require as many compute-intensive resources at the data center, or as much energy to transmit that data from the device to the data center.
However, achieving these benefits may involve splitting workloads and using other load-balancing techniques to alleviate centralized data center compute costs and network overhead.
In addition to the continued need for a fast-connected edge data center (albeit one with vastly reduced computational and energy requirements), there's another issue: Just how powerful an LLM can you really run on today's hardware? And while there is less concern about on-device data being intercepted across a network, there is the added security risk of sensitive data being penetrated on the local device if it isn't properly managed — as well as the challenge of updating the model data and maintaining data consistency on a large number of distributed edge caching devices.
Also: How edge-to-cloud is driving the next stage of digital transformation
And finally, there is the cost: Who will foot the bill for all these mini edge datacenters? Edge networking is employed today by Edge Service Providers (such as Equinix), which is needed by services such as Netflix and Apple's iTunes, traditionally not mobile network operators such as AT&T, T-Mobile, or Verizon. Generative AI services providers such as OpenAI/Microsoft, Google, and Meta would need to work out similar arrangements.
There are a lot of considerations with on-device generative AI, but it's clear that tech companies are thinking about it. Within five years, your on-device intelligent assistant could be thinking all by itself. Ready for AI in your pocket? It's coming — and far sooner than most people ever expected.
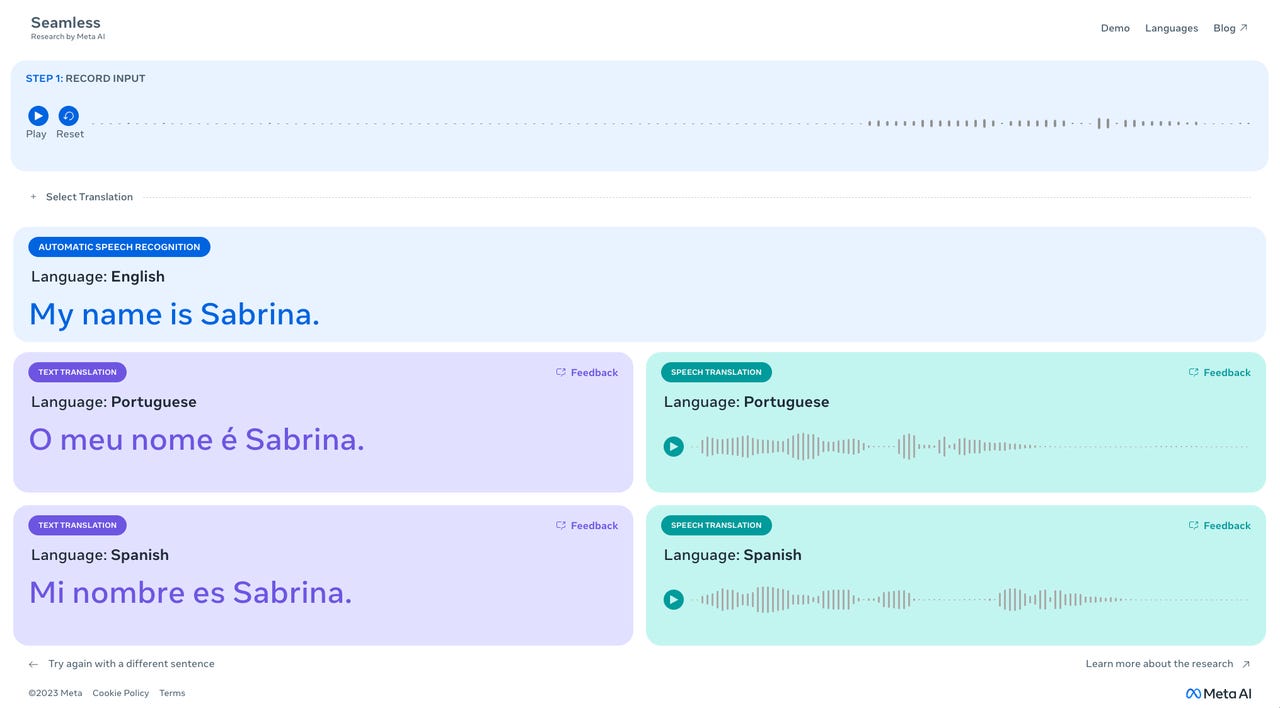
Within seconds of recording my audio, the model produced the text translation accompanied by an audio translation.
See you later, Google Translate. Bis später. Hasta luego.
Learning another language is hard work. Meta's new AI translation model is here to do the heavy lifting for you, and you can even try a demo for yourself.
Also: Meta releases big, new open-source AI large language model
On Tuesday, Meta announced SeamlessM4T, the first all-in-one multimodal and multilingual AI translation model that supports nearly 100 languages depending on the task. The model can perform speech-to-text, speech-to-speech, text-to-speech, and text-to-text translations.
Meta claims that the single-system approach of SeamlessM4T reduces errors and delays, increasing the efficiency and quality of the translation.
SeamlessM4T is publicly available with a research license, which allows researchers and developers to leverage and build on the model. However, even if you aren't a researcher or developer, there is a way for you to try out the model, too.
Also: 4 things Claude AI can do that ChatGPT can't
All you have to do is open this demo link in your browser and record a complete sentence you would like translated. For best results, Meta recommends trying this in a quiet environment.
Then, you can select up to three languages into which you want the sentence translated. Once you are done inputting your sentence, you can view a transcription and listen to the translations.
Also: Could you soon be running AI tasks right on your iPhone? MediaTek says yes
I tried the demo and was impressed with the accuracy and speed of the results. Within seconds of recording my audio, the model produced the text translation accompanied by an audio translation, as seen in the photo above.
Because this is an experimental research demo, Meta cautions that it can produce inaccurate translations or change the meaning of your input words. If users experience these inaccuracies, Meta encourages them to use the feedback feature to report the errors so the model can be improved.
Microsoft has made some big moves in AI over the last year, including partnering with ChatGPT-maker OpenAI and releasing its AI chatbot Bing Chat. Now, it looks like the company is expanding its AI efforts to Windows 11.
According to Windows Central's sources, Microsoft is working on bringing AI to many of its Windows 11 apps, including Photos, Snipping Tool, and Paint.
Also: Python is coming to Microsoft Excel
The reports say that Microsoft is working on an AI functionality for the Photos app, which would allow it to identify objects in a photo and copy and paste them somewhere else, similar to the drag-and-drop feature in iOS 16.
The Snipping tool will reportedly be revamped by incorporating optical character recognition (OCR) into the tool, which would allow it to identify text in screenshots, facilitating copy and pasting. The company is working on bringing the same OCR feature to the camera app, according to the report.
Lastly, the sources revealed that Microsoft is experimenting with AI in the Paint App by incorporating AI art generation into the tool by implementing a feature allowing users to "create a canvas" based on user criteria.
Also: Bing's search market share fails to budge despite big AI push
The company has experience in the AI art generation space with its own Bing Image Creator, which uses text to generate any image a user can think of in the same way DALL-E does.
Microsoft recently announced the date of its fall event on September 21. The company will likely use this opportunity to not only announce new hardware, such as the Surface Laptop 5 and Surface Pro 9, but also to announce its latest AI projects, such as the ones above.
Lex raises $2.75M for its AI writing tool that helps writers get past blocks Alex Wilhelm 12 hours
Lex, an AI-powered writing tool, today said it has raised a $2.75 million seed round led by True Ventures. The company has been spun out of Every, which Lex’s CEO Nathan Baschez helped start.
Baschez described Lex as a “modern writing platform,” emphasizing that ‘modern’ in this case means inclusive of AI. In the CEO’s eyes, the use of AI in writing tools is the continuation of the centuries-long arc of improvements to the practice of writing.
According to Baschez, most writers today do not use AI in their workflow. That claim tracks with what I have heard from my friends in the larger writing community. Lex, then, has to not only build a solid writing service in a market that has a number of incumbent and low-cost tools, but also get writers interested in using technology that some folks expect to take away their jobs.
So how does Lex meld AI into a writing tool so that writers would want to use it? After testing Lex, digesting its onboarding material and speaking to the company, it appears that the service wants to create a super-clean writing interface that has a fair number of features that power users — people who write a lot, I suppose — expect. The AI is included as a way to extend and smooth out the user’s workflow.
In practice, you get formatting tools and markdown-based shortcuts that let you easily add sub-heads and the like. The AI steps in when you either slow down or if there’s a halt in your writing process. “If you ever get stuck,” Lex explains to new users, “just hit CMD+Enter or type +++, and GPT-3 will fill in what it thinks should come next.”
You also can ask Lex’s AI questions inside of comments, which is neat. You can ask it to rewrite something to be shorter, or, in one example the company shared, get it to check if a particular sentence is extraneous or not. Lex also can generate headlines for documents, a feature that I’ve seen other AI-imbued digital tools offer.
So is this yet another tool that will help writers avoid writing? Sorta. Baschez’s introductory material explains that the AI tools will at times generate “rubbish,” but that the founder is “finding [its AI-generated output] really helpful” to get him unstuck when he’s not sure what to write next.
Lex’s “AI roadmap” says more features that will add the ability to “rephrase a sentence, generate a summary, and more” are coming.
What about privacy? Given that Lex is a writing tool, should writers worry about their words being absorbed into the system? Baschez told TechCrunch in an email that Lex is “not using any user content for training,” though he added that the company may want to “train (or fine tune)” its own models in the future.
When it does reach that point, the CEO said the company intends to be “very transparent about it and careful not to include anything our users wouldn’t want included.”
That seems reasonable. For now, with OpenAI’s models, Baschez thinks the company’s privacy policies satisfy “most users’ needs.”
The AI stuff is cool, but there was one thing about this app that made me want to keep using it: It has no historical baggage. I find it odd that many modern word processors like Google Docs and Word retain a bias toward pagination — the UX is intended for printing documents onto letter-sized paper. Lex, in contrast, does away with all that.
That’s not a small point. Baschez told TechCrunch that because he is building something that “can afford to be a little bit more focused [and] opinionated” than existing writing tools, he can excise cruft that often clutters writing tools. Small tweaks such as these, I think, can make the writing experience feel less like a digitized real-world process and more like you’re using a tool meant for writing today.
From idea to startup
It’s not hugely surprising to see Lex being spun out from Every, a subscription media service focused on technology and productivity topics. Baschez told TechCrunch that after taking parental leave, he had a “real itch to write software again,” which led to him tinkering with GPT-3 and coming up with the concept for Lex.
Lex started as a nights-and-weekends project, and initial interest was strong, per Baschez. With a simple YouTube video and a few writers on board, Lex signed up around 25,000 users in its first 24 hours. That initial burst of interest also caught TechCrunch’s attention. An AI-powered product getting early traction is almost catnip for investors in today’s market, so it’s understandable that Lex was able to raise capital so soon.
But Lex doesn’t intend to go on a hiring spree. Instead, Baschez intends to “keep the team really small until [it is] painful.” ‘Hire when it hurts’ is not a new approach to keeping headcount low, but it is one that we haven’t heard of much in recent years. An active focus on limiting burn means the company’s modest fundraise should keep it going for a “really, really long time,” Baschez said, and the company intends to start charging for its product in short order.
What will it cost to use, though? That’s a question worth pondering. Before the generative pre-trained transformer-led AI revolution, the venture and startup communities talked often about the gross margins AI-powered software products would be able to command. They hoped that while it would be expensive to train and run AI models, those costs would decline over time and could be offset by a larger number of customers, limiting their impact on profitability. Indeed, they prayed that software companies might be able to retain their SaaS-like gross margins.
But today, we know that some popular large language models (LLMs) charge usage fees. If you want to make a bunch of API calls using your AI implementations, those costs can add up. Of course, you could use open source LLMs instead, but that’s not always a good idea for startups, which may prefer commercially available tools over building an in-house LLM function. In turn, that means that the cost of hosting users won’t be insignificant. Ergo, Lex will not cost something like $2 per month.
Still, Baschez doesn’t think that Lex’s paid tier will cost much more than a couple $10 bills. And if it builds an enterprise plan, Lex will soon resemble a pretty run-of-the-mill SaaS company.
So what?
There is no shortage of AI-powered digital services, but what I like about Lex is that it makes for a good writing tool that is fast, simple to use and uses AI to help writers instead of trying to supplant them. With cash on hand and clear product-market interest, Lex could be an interesting startup to watch.
Hugging Face has introduced SafeCoder, an enterprise-focused code assistant that aims to improve software development efficiency through a secure, self-hosted pair programming solution. SafeCoder claims to be a comprehensive, security-driven commercial offering, ensuring code remains within the VPC throughout training and inference. Its customer-centric design, enables on-premises deployment and ownership of the Code Large Language Model, just like a personalised GitHub Copilot.
Additionally, Hugging Face has partnered with VMware to offer SafeCoder on the VMware Cloud platform. VMware is currently using SafeCoder internally and sharing a blueprint for swift deployment on their infrastructure, ensuring quick time-to-value.
But Why Is SafeCoder Needed?
Code assistants like GitHub Copilot, built on OpenAI Codex, boost productivity. Enterprises can enhance this by customising LLMs with their code, as seen with Google’s 25-34% completion rate from training on internal code. However, using closed-source LLMs for in-house assistants poses security risks, both during training (exposing sensitive code) and inference (potential code leakage).
Hugging Face’s SafeCoder addresses this, allowing proprietary LLMs built on open models, fine-tuned on internal code, without external sharing. It also offers secure, on-premises deployment for code privacy.
From StarCoder to SafeCoder
In May, Hugging Face and ServiceNow collaborated on the BigCode project, releasing StarCoder, an open-source language model tailored for code. Enhanced from StarCoderBase, it mastered 35B Python code segments. Impressively, StarCoder excelled on benchmarks like HumanEval, outperforming PaLM, LaMDA, and LLaMA. It matched or surpassed closed models like OpenAI’s code-Cushman-001, formerly behind GitHub Copilot. Boasting 15.5B parameters, 1T+ tokens, and an 8192-token context, it drew from GitHub data across 80+ languages, commits, issues, and notebooks. StarCoder powers SafeCoder, optimized for enterprise self-hosted use with efficient inference, adaptability, and ethical data sourcing.
Training Method
The SafeCoder model excels in over 80 programming languages, adapting code suggestions for users via collaborative training with Hugging Face. Proprietary data remains secure, resulting in a personalized code generation model for customers, promoting self-sufficiency, vendor independence, and control over AI capabilities.
SafeCoder’s inference capability encompasses diverse hardware selections, including NVIDIA Ampere GPUs, AMD Instinct GPUs, Habana Gaudi2, AWS Inferentia 2, Intel Xeon Sapphire Rapids CPUs, and other options, providing customers with a broad spectrum of choices.
Read more: The Peaks and Pits of Open-Source with Hugging Face
The post After StarCoder, Hugging Face Launches Enterprise Code Assistant SafeCoder appeared first on Analytics India Magazine.